Visão geral do BigQuery
O BigQuery é uma plataforma de dados totalmente gerenciada e pronta para IA que ajuda você a gerenciar e analisar seus dados com recursos integrados como aprendizado de máquina, pesquisa, análise geoespacial e Business Intelligence. A arquitetura sem servidor do BigQuery permite usar linguagens como SQL e Python para responder às maiores dúvidas da sua organização sem nenhum gerenciamento de infraestrutura.
O BigQuery oferece uma maneira uniforme de trabalhar com dados estruturados e não estruturados e oferece suporte a formatos de tabelas abertas, como Apache Iceberg, Delta e Hudi. O streaming do BigQuery oferece suporte à ingestão e análise contínua de dados, enquanto o mecanismo de análise distribuído e escalonável do BigQuery permite consultar terabytes em segundos e petabytes em minutos.
O BigQuery oferece recursos de governança integrados que permitem descobrir e organizar dados, além de gerenciar metadados e qualidade de dados. Com recursos como pesquisa semântica e linhagem de dados, é possível encontrar e validar dados relevantes para análise. Você pode compartilhar dados e recursos de IA em toda a organização com os benefícios do controle de acesso. Esses recursos são alimentados pelo Dataplex Universal Catalog, uma solução de governança unificada e inteligente para recursos de dados e IA no Google Cloud.
A arquitetura do BigQuery consiste em duas partes: uma camada de armazenamento que ingere, armazena e otimiza dados e uma camada de computação que fornece recursos de análise. Essas camadas de computação e armazenamento operam com eficiência de maneira independente umas das outras, graças à rede em escala de petabits do Google, que permite a comunicação necessária entre elas.
Os bancos de dados legados geralmente precisam compartilhar recursos entre operações de leitura e gravação e operações analíticas. Isso pode resultar em conflitos de recursos e tornar as consultas mais lentas enquanto os dados são gravados ou lidos a partir do armazenamento. Os pools de recursos compartilhados podem ficar ainda mais sobrecarregados quando são necessários recursos para tarefas de gerenciamento de banco de dados, como atribuição ou revogação de permissões. Com a separação das camadas de computação e armazenamento do BigQuery, cada uma delas pode alocar recursos dinamicamente sem afetar o desempenho ou a disponibilidade da outra.
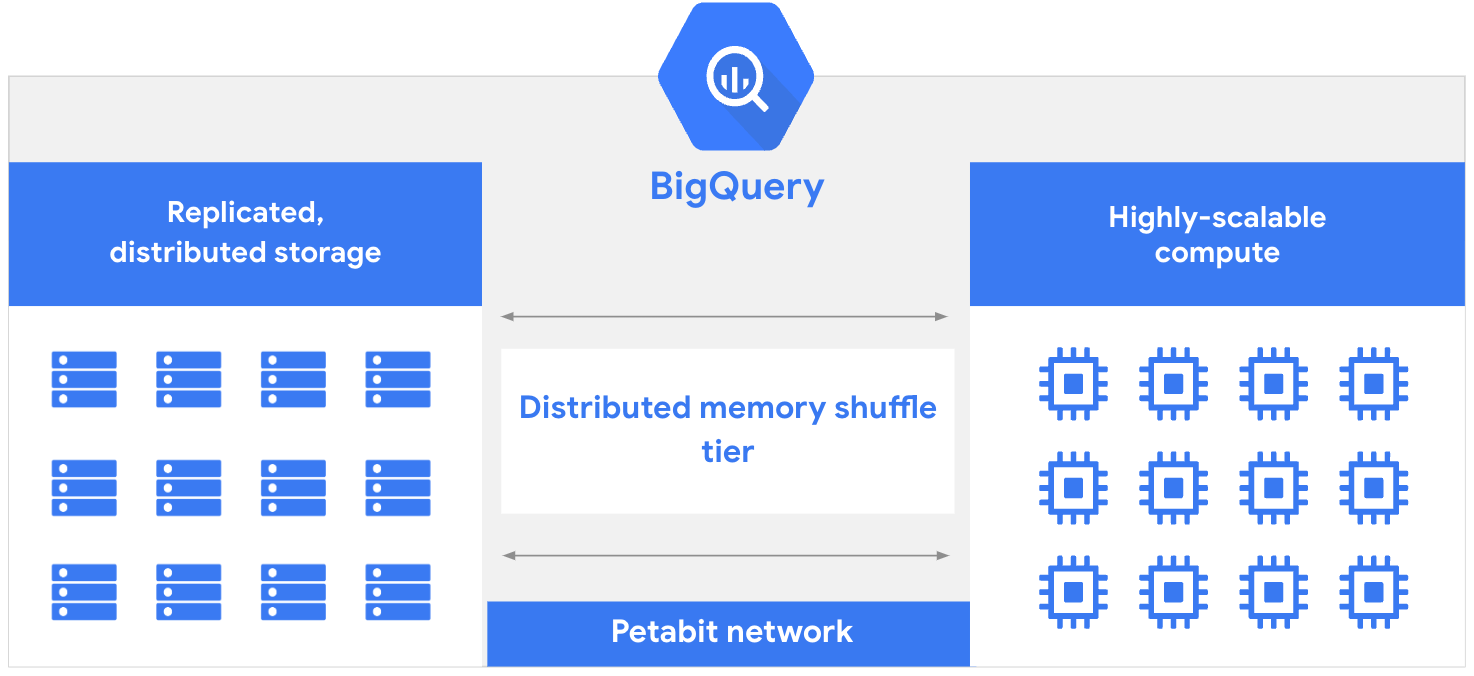
Esse princípio de separação permite que o BigQuery inove mais rapidamente porque as melhorias de armazenamento e computação podem ser implantadas de forma independente, sem tempo de inatividade ou impacto negativo no desempenho do sistema. Também é essencial oferecer um data warehouse sem servidor totalmente gerenciado, em que a equipe de engenharia do BigQuery consiga lidar com atualizações e manutenção. Como resultado, você não precisará provisionar ou escalonar recursos manualmente e ficará livre para se concentrar na entrega de valor em vez de nas tarefas tradicionais de gerenciamento de um banco de dados.
As interfaces do BigQuery incluem a interface do console Google Cloud e a ferramenta de linha de comando do BigQuery. Desenvolvedores e cientistas de dados podem usar bibliotecas de cliente com uma programação familiar, incluindo Python, Java, JavaScript e Go, além da API REST e da API RPC do BigQuery para transformar e gerenciar dados. Os drivers ODBC e JDBC fornecem interação com aplicativos atuais, incluindo ferramentas e utilitários de terceiros.
Quer você seja analista de dados, engenheiro de dados, administrador de data warehouse ou cientista de dados, o BigQuery irá ajudá-lo a carregar, processar e analisar dados para alimentar com informações decisões cruciais para o seu negócio.
Noções básicas sobre o BigQuery
Comece a explorar o BigQuery em minutos. Aproveite o nível de uso gratuito do BigQuery ou o Sandbox sem custo para começar a carregar e consultar dados.
- Sandbox do BigQuery: comece a usar o sandbox do BigQuery, sem riscos e sem custo.
- Google Cloud Guia de início rápido do console: conheça os recursos do BigQuery Studio.
- Conjuntos de dados públicos: confira o desempenho do BigQuery com dados grandes e reais do Programa de conjuntos de dados públicos.
Conhecer o BigQuery
A infraestrutura sem servidor do BigQuery permite que você se concentre nos dados em vez de gerenciar recursos. O BigQuery combina um armazenamento de dados baseado na nuvem e ferramentas analíticas avançadas.
armazenamento do BigQuery;
O BigQuery armazena dados usando um formato de armazenamento em colunas otimizado para consultas analíticas. O BigQuery apresenta dados em tabelas, linhas e colunas e fornece suporte completo à semântica de transações de banco de dados (ACID). O armazenamento do BigQuery é replicado automaticamente em vários locais para proporcionar alta disponibilidade.
- Conheça os padrões comuns para organizar recursos do BigQuery no armazenamento de dados e em data marts.
- Saiba mais sobre conjuntos de dados, o contêiner de nível superior do BigQuery com tabelas e visualizações.
- O serviço de transferência de dados do BigQuery automatiza a ingestão de dados.
- Carregue dados no BigQuery usando:
- Faça streaming de dados com a API Storage Write (visualização).
- Carregar dados em lote a partir de arquivos locais ou do Cloud Storage usando formatos que incluem: Avro, Parquet, ORC, CSV, JSON, Datastore e Firestore.
Saiba mais em Visão geral do armazenamento do BigQuery.
Análise do BigQuery
Os usos de análises descritivas e prescritivas incluem Business Intelligence, análise ad-hoc, análise geoespacial e machine learning. É possível consultar dados armazenados no BigQuery ou executar consultas em dados onde eles residem usando tabelas externas ou consultas federadas, incluindo o Google Cloud Storage, Bigtable, Spanner ou Planilhas Google armazenados no Google Drive.
- Consultas SQL padrão ANSI (Suporte para SQL:2011) incluindo suporte para mesclagens, campos aninhados e repetidos, funções de análise e agregação, consultas de várias instruções e uma variedade de funções espaciais com análises geoespaciais, isto é, os Sistemas de informações geográficas.
- Crie visualizações para compartilhar sua análise.
- Compatibilidade com a ferramenta de Business Intelligence, incluindo BI Engine com Looker Studio, Looker, Google Planilhas, e ferramentas de terceiros, como Tableau e Power BI.
- O BigQuery ML fornece machine learning e análise preditiva.
- O BigQuery Studio oferece recursos como notebooks Python e o controle de versão para notebooks e consultas salvas. Esses recursos facilitam a conclusão da de fluxos de trabalho de análise de dados e machine learning (ML) no BigQuery.
- Consulte dados fora do BigQuery com consultas federadas e tabelas externas.
Saiba mais em Visão geral das análises do BigQuery.
Administração do BigQuery
O BigQuery oferece gerenciamento centralizado de dados e recursos de computação, enquanto o Identity and Access Management (IAM) ajuda a proteger esses recursos com o modelo de acesso usado em todo o Google Cloud. As Google Cloud práticas recomendadas de segurança fornecem uma abordagem sólida, mas flexível, que pode incluir segurança de perímetro ou uma abordagem de defesa em profundidade mais complexa e granular.
- A introdução à segurança e à governança de dados ajuda a entender a governança de dados e quais controles são necessários para proteger os recursos do BigQuery.
- Jobs são ações que o BigQuery executa em seu nome para carregar, exportar, consultar ou copiar dados.
- As reservas permitem alternar entre preços sob demanda e baseados em capacidade.
Para mais informações, consulte Introdução ao BigQuery.
Recursos do BigQuery
Explore os recursos do BigQuery:
- As Notas de lançamento fornecem registros de alterações de recursos, alterações e suspensões de uso.
- Preços para análise e armazenamento. Consulte também os preços do BigQuery ML, BI Engine e Serviço de transferência de dados.
- Os locais definem onde você cria e armazena conjuntos de dados (locais regionais e multirregionais).
- O Stack Overflow hospeda uma comunidade engajada de desenvolvedores e analistas que trabalham com o BigQuery.
- O suporte do BigQuery ajuda você com o BigQuery.
- Google BigQuery: o guia definitivo: armazenamento de dados, análise e machine learning em escala, de Valliappa Lakshmanan e Jordan Tigani, explica como o BigQuery funciona e fornece um tutorial completo sobre como usar o serviço.
APIs, ferramentas e referências
Materiais de referência para desenvolvedores e analistas do BigQuery:
- A API BigQuery e as bibliotecas de cliente apresentam visões gerais dos recursos do BigQuery e o uso deles.
- Sintaxe de consulta SQL com detalhes sobre como usar o GoogleSQL.
- As amostras de código do BigQuery oferecem centenas de snippets para bibliotecas de cliente em C#, Go, Java, Node.js, Python e Ruby. ou confira o navegador de exemplo.
- A sintaxe de DML, DDL, e funções definidas pelo usuário (UDF) permite gerenciar e transformar seus dados do BigQuery.
- A referência da ferramenta de linha de comando bq documenta a sintaxe, os comandos, as sinalizações e os argumentos da interface da CLI
bq. - A integração de ODBC / JDBC conecta o BigQuery às suas ferramentas e infraestrutura atuais.
Recursos do Gemini no BigQuery
O Gemini no BigQuery faz parte do pacote de produtos Gemini para Google Cloud, que oferece assistência com tecnologia de IA para ajudar você a trabalhar com seus dados.
O Gemini no BigQuery oferece assistência de IA para ajudar você a fazer o seguinte:
- Analisar e entender seus dados com insights. Os insights de dados oferecem uma maneira automatizada e intuitiva de descobrir padrões e realizar análises estatísticas usando consultas úteis geradas com base nos metadados das suas tabelas. Esse recurso é especialmente útil para resolver os desafios de inicialização a frio da exploração inicial de dados. Para mais informações, consulte Gerar insights de dados no BigQuery.
- Descobrir, transformar, consultar e visualizar dados com a tela de dados do BigQuery. Você pode usar a linguagem natural com o Gemini no BigQuery para encontrar, unir e consultar recursos de tabela, visualizar resultados e colaborar com outras pessoas durante todo o processo. Para mais informações, consulte Analisar com a tela de dados.
- Receber ajuda com a análise de dados em SQL e Python. Você pode usar o Gemini no BigQuery para gerar ou sugerir código em SQL ou Python e explicar uma consulta SQL atual. Você também pode usar consultas em linguagem natural para começar a análise de dados. Para saber como gerar, completar e resumir código, consulte a seguinte documentação:
- Assistente de código em SQL
- Assistente de código Python
- Preparar os dados para análise. A preparação de dados no BigQuery apresenta recomendações de transformação geradas com IA e contextuais para limpar dados para análise. Para mais informações, consulte Preparar dados com o Gemini.
- Personalizar suas conversões de SQL com regras de conversão. (Prévia) Crie regras de conversão aprimoradas com o Gemini para personalizar as conversões de SQL usando o conversor de SQL interativo. É possível descrever mudanças na saída da conversão de SQL usando comandos em linguagem natural ou especificar padrões de SQL para encontrar e substituir. Para mais informações, consulte Criar uma regra de conversão.
Para saber como configurar o Gemini no BigQuery, consulte Configurar o Gemini no BigQuery.
Papéis e recursos do BigQuery
O BigQuery atende às necessidades dos profissionais de dados com relação aos seguintes papéis e responsabilidades.
Analista de dados
Orientação da tarefa para ajudar se você precisar fazer o seguinte:
- Consultar dados do BigQuery usando consultas interativas ou em lote com a sintaxe de consulta SQL
- Faça referência a funções, operadores e expressões condicionais do SQL para consultar dados.
Use ferramentas para analisar e visualizar dados do BigQuery, incluindo: Looker, Looker Studio e Planilhas Google.
Use a análise geoespacial para analisar e visualizar dados geoespaciais com os sistemas de informações geográficas do BigQuery.
Otimize o desempenho da consulta usando:
- Tabelas particionadas: como as tabelas grandes são removidas com base em intervalos de tempo ou inteiros.
- Visualizações materializadas: defina visualizações em cache para otimizar consultas ou fornecer resultados persistentes.
- BI Engine: o serviço de análise rápido na memória do BigQuery.
Para fazer um tour pelos recursos de análise de dados do BigQuery diretamente no console do Google Cloud , clique em Fazer o tour.
Administrador de dados
Orientação da tarefa para ajudar se você precisar fazer o seguinte:
- Gerencie custos com reservas para equilibrar os preços sob demanda e com base na capacidade.
- Entenda a segurança e a governança dos dados para proteger dados por conjunto de dados, tabela, coluna, linha ou visualização.
- Dados de backup com snapshots de tabelas para preservar o conteúdo de uma tabela em um horário específico.
- Confira o INFORMATION_SCHEMA do BigQuery para entender os metadados de Conjuntos de dados, vagas de emprego, controle de acesso, reservas, tabelas e outros benefícios
- Use Jobs para que o BigQuery carregue, exporte, consulte ou copie dados são ações em seu nome.
- Monitore registros e recursos para entender o BigQuery e as cargas de trabalho.
Para mais informações, consulte Introdução à administração do BigQuery.
Para fazer um tour pelos recursos de administração de dados do BigQuery diretamente no console do Google Cloud , clique em Fazer o tour.
Cientista de dados
Orientação da tarefa para ajudar se você precisar usar o machine learning do BigQuery ML para fazer o seguinte:
- Entenda a jornada do usuário de ponta a ponta para modelos de machine learning
- Gerenciar o controle de acesso do BigQuery ML
- Crie e treine modelos de BigQuery ML, incluindo:
- Previsão de regressão linear
- Classificações de regressão logística binária e logística multiclasse
- Cluster K-means para segmentação de dados.
- Série temporal de previsões com modelos do Arima+
Desenvolvedor de dados
Orientação da tarefa para ajudar se você precisar fazer o seguinte:
- Carregue dados no BigQuery com:
Use a biblioteca de amostra de código, incluindo:
Google Cloud pesquisa de exemplos de código (escopo do BigQuery)
Tutoriais em vídeo do BigQuery
A série de tutoriais em vídeo a seguir ajudará você a começar a usar o BigQuery:
Título |
Descrição |
|---|---|
| Introdução ao BigQuery (17:18) | Uma visão geral que resume o que é o BigQuery e como usá-lo. Os segmentos incluem: pipelines de ETL, preços e otimização, BigQuery ML e BI Engine e conclusão com uma demonstração do BigQuery no console do Google Cloud . |
| O que é o BigQuery? (4:39) | Uma visão geral do BigQuery sobre como o BigQuery foi projetado para ingerir e armazenar grandes quantidades de dados para ajudar analistas e desenvolvedores |
| Como usar o sandbox do BigQuery (3:05) | Como configurar um sandbox do BigQuery para executar consultas sem precisar de um cartão de crédito |
| Como fazer perguntas, executar consultas (5:11) | Como escrever e executar consultas SQL na IU do BigQuery, além de escolher um número de jersey vencedor |
| Como carregar dados no BigQuery (5:31) | Como ingerir e analisar dados em tempo real ou apenas em uma análise em lote única de dados, além de gatos em comparação a cães |
| Como visualizar resultados de consulta (5:38) | Como a visualização de dados é útil para facilitar a compreensão e a internalização de conjuntos de dados complexos |
| Como gerenciar o acesso com o IAM (5:23) | Como permitir que outros usuários consultem seus conjuntos de dados no BigQuery com permissões do IAM e controle de acesso |
| Como salvar e compartilhar consultas (6:17) | Como salvar e compartilhar suas consultas no BigQuery sem complicações |
| Como proteger dados confidenciais com visualizações autorizadas (7:12) | Como compartilhar conjuntos de dados com diferentes usuários ao configurar controles de acesso personalizados |
| Como consultar dados externos com o BigQuery (5:49) | Como configurar uma fonte de dados externa no BigQuery e consultar dados do Cloud Storage, Cloud SQL, Google Drive e muito mais |
| O que são funções definidas pelo usuário? (4:59) | Como criar funções definidas pelo usuário (UDFs) para analisar conjuntos de dados no BigQuery |
A seguir
- Para uma visão geral do armazenamento do BigQuery, consulte Visão geral do armazenamento do BigQuery.
- Para uma visão geral das consultas do BigQuery, consulte Visão geral do BigQuery Analytics.
- Para uma visão geral da administração do BigQuery, consulte Introdução à administração do BigQuery.
- Para uma visão geral da segurança do BigQuery, consulte Visão geral da segurança e governança de dados.