Transmita atualizações de tabelas com a captura de dados de alterações
A captura de dados de alterações (CDC) do BigQuery atualiza as tabelas do BigQuery processando e aplicando alterações transmitidas aos dados existentes. Esta sincronização é realizada através de operações de inserção/atualização e eliminação de linhas que são transmitidas em tempo real pela API BigQuery Storage Write, que deve conhecer antes de continuar.
Antes de começar
Conceda funções de gestão de identidades e acessos (IAM) que dão aos utilizadores as autorizações necessárias para realizar cada tarefa neste documento e certifique-se de que o seu fluxo de trabalho cumpre cada pré-requisito.
Autorizações necessárias
Para receber a autorização de que
precisa para usar a API Storage Write,
peça ao seu administrador para lhe conceder a função do IAM de
editor de dados do BigQuery (roles/bigquery.dataEditor).
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
Esta função predefinida contém a autorização
bigquery.tables.updateData
, que é necessária para
usar a API Storage Write.
Também pode obter esta autorização com funções personalizadas ou outras funções predefinidas.
Para mais informações acerca das funções e autorizações do IAM no BigQuery, consulte o artigo Introdução ao IAM.
Pré-requisitos
Para usar o CDC do BigQuery, o seu fluxo de trabalho tem de cumprir as seguintes condições:
- Tem de usar a API Storage Write no stream predefinido.
- Tem de usar o formato protobuf como formato de carregamento. O formato Apache Arrow não é suportado.
- Tem de declarar chaves primárias para a tabela de destino no BigQuery. As chaves primárias compostas que contêm até 16 colunas são suportadas.
- Têm de estar disponíveis recursos de computação do BigQuery suficientes para realizar as operações de linhas de CDC. Tenha em atenção que, se as operações de modificação de linhas de CDC falharem, pode reter involuntariamente dados que pretendia eliminar. Para mais informações, consulte a secção Considerações sobre os dados eliminados.
Especifique as alterações aos registos existentes
No CDC do BigQuery, a pseudocoluna _CHANGE_TYPE indica o
tipo de alteração a ser processada para cada linha. Para usar a CDC, defina _CHANGE_TYPE quando
faz streaming de modificações de linhas através da Storage Write API. A pseudocoluna _CHANGE_TYPE só aceita os valores UPSERT e DELETE.
Uma tabela é considerada com CDC ativado enquanto a API Storage Write está a transmitir modificações de linhas para a tabela desta forma.
Exemplo com valores UPSERT e DELETE
Considere a seguinte tabela no BigQuery:
| ID | Nome | Salário |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
As seguintes modificações de linhas são transmitidas pela API Storage Write:
| ID | Nome | Salário | _CHANGE_TYPE |
|---|---|---|---|
| 100 | ELIMINAR | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
A tabela atualizada é agora a seguinte:
| ID | Nome | Salário |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
Faça a gestão da desatualização das tabelas
Por predefinição, sempre que executa uma consulta, o BigQuery devolve os resultados mais
atualizados. Para fornecer os resultados mais recentes quando consulta uma tabela com CDC ativado, o BigQuery tem de aplicar cada modificação de linha transmitida em stream até à hora de início da consulta, para que a versão mais atualizada da tabela seja consultada. A aplicação destas modificações de linhas no momento da execução da consulta aumenta a latência e o custo da consulta. No entanto, se não precisar de resultados de consultas totalmente atualizados, pode reduzir o custo e a latência das suas consultas definindo a opção max_staleness
na sua tabela. Quando esta opção está definida, o BigQuery aplica modificações de linhas, pelo menos, uma vez no intervalo definido pelo valor max_staleness, o que lhe permite executar consultas sem esperar que as atualizações sejam aplicadas, à custa de alguma desatualização dos dados.
Este comportamento é especialmente útil para painéis de controlo e relatórios para os quais a atualização dos dados não é essencial. Também é útil para a gestão de custos, pois dá-lhe mais controlo sobre a frequência com que o BigQuery aplica modificações de linhas.
Consultar tabelas com a opção max_staleness definida
Quando consulta uma tabela com a opção max_staleness definida, o BigQuery devolve o resultado com base no valor de max_staleness e na hora em que ocorreu a última tarefa de aplicação, que é representada pela data/hora upsert_stream_apply_watermark da tabela.
Considere o seguinte exemplo, em que uma tabela tem a opção max_staleness definida como 10 minutos e a tarefa de aplicação mais recente ocorreu às 20:00:
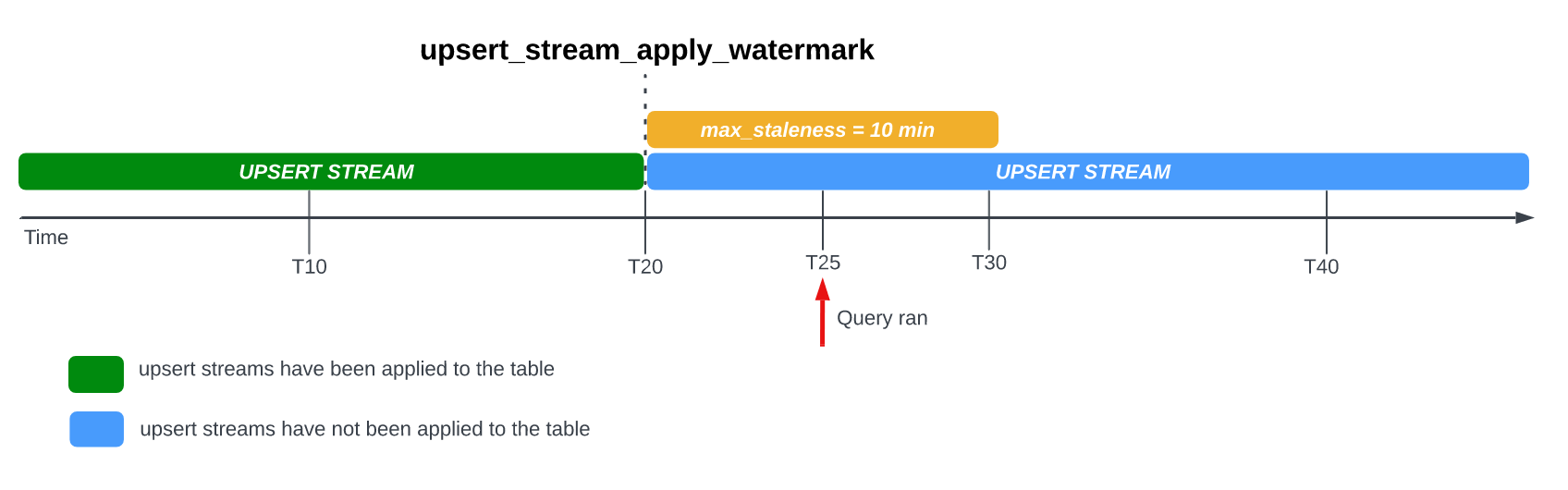
Se consultar a tabela em T25, a versão atual da tabela está desatualizada há 5 minutos, o que é inferior ao intervalo de max_staleness de 10 minutos. Neste caso, o BigQuery devolve a versão da tabela em T20, o que significa que os dados devolvidos também estão desatualizados há 5 minutos.
Quando define a opção max_staleness na sua tabela, o BigQuery aplica as modificações pendentes das linhas, pelo menos, uma vez no intervalo max_staleness. No entanto, em alguns casos, o BigQuery pode não concluir o processo de aplicação destas modificações de linhas pendentes dentro do intervalo.
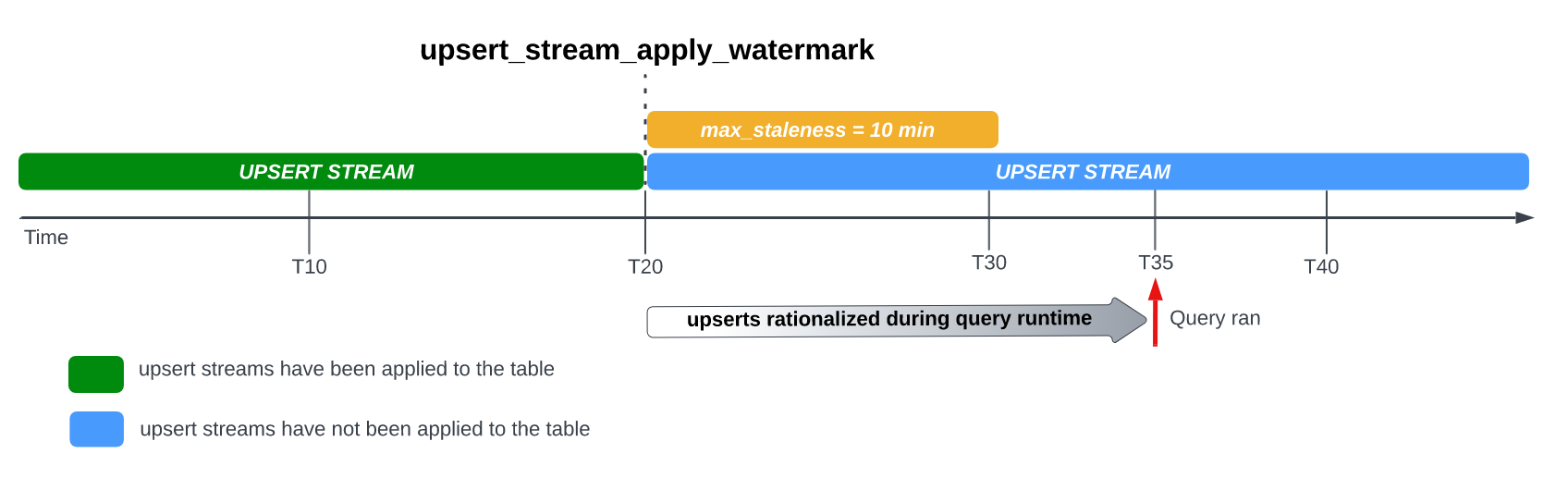
Por exemplo, se consultar a tabela em T35 e o processo de aplicação das modificações de linhas pendentes não tiver sido concluído, a versão atual da tabela está desatualizada há 15 minutos, o que é superior ao intervalo de max_staleness de 10 minutos.
Neste caso, no tempo de execução da consulta, o BigQuery aplica todas as modificações de linhas entre T20 e T35 para a consulta atual, o que significa que os dados consultados estão completamente atualizados, ao custo de alguma latência de consulta adicional.
Isto é considerado uma tarefa de união em tempo de execução.
Valor da tabela max_staleness recomendado
Geralmente, o valor max_staleness de uma tabela deve ser o mais elevado dos dois valores seguintes:
- O nível máximo de desatualização de dados tolerável para o seu fluxo de trabalho.
- O dobro do tempo máximo necessário para aplicar as alterações inseridas/atualizadas na sua tabela, mais alguma margem adicional.
Para calcular o tempo necessário para aplicar alterações inseridas/atualizadas a uma tabela existente, use a seguinte consulta SQL para determinar a duração do percentil 95 dos trabalhos de aplicação em segundo plano, mais um buffer de sete minutos para permitir a conversão do armazenamento otimizado para escrita do BigQuery (buffer de streaming).
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
Substitua o seguinte:
REGION: o nome da região onde o seu projeto está localizado. Por exemplo,us.PROJECT_ID: o ID do projeto que contém as tabelas do BigQuery que estão a ser modificadas pelo CDC do BigQuery.
A duração das tarefas de aplicação em segundo plano é afetada por vários fatores, incluindo o número e a complexidade das operações de CDC emitidas no intervalo de desatualização, o tamanho da tabela e a disponibilidade de recursos do BigQuery. Para mais informações sobre a disponibilidade de recursos, consulte o artigo Dimensionar e monitorizar reservas EM SEGUNDO PLANO.
Crie uma tabela com a opção max_staleness
Para criar uma tabela com a opção max_staleness, use a
declaração CREATE TABLE.
O exemplo seguinte cria a tabela employees com um limite de max_staleness de 10 minutos:
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
Modifique a opção max_staleness para uma tabela existente
Para adicionar ou modificar um limite max_staleness numa tabela existente, use a declaração ALTER TABLE.
O exemplo seguinte altera o limite de max_staleness da tabela employees para 15 minutos:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
Determinar o valor max_staleness atual de uma tabela
Para determinar o valor max_staleness atual de uma tabela, consulte a vista INFORMATION_SCHEMA.TABLE_OPTIONS.
O exemplo seguinte verifica o valor max_staleness atual da tabelamytable:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
Substitua o seguinte:
DATASET_NAME: o nome do conjunto de dados no qual a tabela ativada para CDC reside.TABLE_NAME: o nome da tabela com CDC ativado.
Os resultados mostram que o valor de max_staleness é de 10 minutos:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
Monitorize o progresso da operação de inserção/atualização da tabela
Para monitorizar o estado de uma tabela e verificar quando as modificações de linhas foram aplicadas pela última vez, consulte a vista INFORMATION_SCHEMA.TABLES para obter a data/hora upsert_stream_apply_watermark.
O exemplo seguinte verifica o valor de upsert_stream_apply_watermark da tabela mytable:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
Substitua o seguinte:
DATASET_NAME: o nome do conjunto de dados no qual a tabela ativada para CDC reside.TABLE_NAME: o nome da tabela com CDC ativado.
O resultado é semelhante ao seguinte:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
As operações de inserção/atualização são realizadas pela conta de serviço e aparecem no histórico de tarefas do projeto que contém a tabela com CDC ativado.bigquery-adminbot@system.gserviceaccount.com
Faça a gestão da ordenação personalizada
Quando faz upserts com streaming para o BigQuery, o comportamento predefinido de ordenação de registos com chaves primárias idênticas é determinado pela hora do sistema do BigQuery à qual o registo foi carregado para o BigQuery. Por outras palavras, o registo ingerido mais recentemente com a data/hora mais recente tem precedência sobre o registo ingerido anteriormente com uma data/hora mais antiga. Para determinados exemplos de utilização, como aqueles em que podem ocorrer atualizações/inserções muito frequentes na mesma chave primária num período muito curto ou em que a ordem de atualização/inserção não é garantida, isto pode não ser suficiente. Nestes cenários, pode ser necessária uma chave de ordenação fornecida pelo utilizador.
Para configurar chaves de ordenação fornecidas pelo utilizador, a pseudocoluna _CHANGE_SEQUENCE_NUMBER é usada para indicar a ordem em que o BigQuery deve aplicar os registos, com base no valor _CHANGE_SEQUENCE_NUMBER mais elevado entre dois registos correspondentes com a mesma chave principal. A pseudocoluna _CHANGE_SEQUENCE_NUMBER é uma coluna opcional e apenas aceita valores num formato fixo STRING.
Formato _CHANGE_SEQUENCE_NUMBER
A pseudocoluna _CHANGE_SEQUENCE_NUMBER só aceita valores STRING, escritos num formato fixo. Este formato fixo usa valores STRING escritos em hexadecimal, separados em secções por uma barra /. Cada secção pode ser
expressa em, no máximo, 16 carateres hexadecimais e são permitidas até quatro secções
por _CHANGE_SEQUENCE_NUMBER. O intervalo permitido de _CHANGE_SEQUENCE_NUMBER suporta valores entre 0/0/0/0 e FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF.
Os valores de _CHANGE_SEQUENCE_NUMBER suportam carateres maiúsculos e minúsculos.
A expressão de chaves de ordenação básicas pode ser feita através de uma única secção. Por exemplo, para ordenar chaves apenas com base na data/hora de processamento de um registo de um servidor de aplicações, pode usar uma secção: '2024-04-30 11:19:44 UTC', expressa como hexadecimal convertendo a data/hora para os milissegundos desde a época, '18F2EBB6480' neste caso. A lógica para converter dados em hexadecimal é da responsabilidade do cliente que emite a gravação no BigQuery através da API Storage Write.
O suporte de várias secções permite combinar vários valores de lógica de processamento numa chave para exemplos de utilização mais complexos. Por exemplo, para ordenar chaves com base na data/hora de processamento de um registo de um servidor de aplicações, num número de sequência de registos e no estado do registo, pode usar três secções: '2024-04-30 11:19:44 UTC' / '123' / 'complete', cada uma expressa em hexadecimal.
A ordem das secções é uma consideração importante para a classificação da sua lógica de processamento. O BigQuery compara os valores _CHANGE_SEQUENCE_NUMBER
comparando a primeira secção e, em seguida, comparando a secção seguinte apenas se
as secções anteriores forem iguais.
O BigQuery usa o _CHANGE_SEQUENCE_NUMBER para realizar a ordenação comparando dois ou mais campos _CHANGE_SEQUENCE_NUMBER como valores numéricos não assinados.
Considere os seguintes _CHANGE_SEQUENCE_NUMBERexemplos de comparação e os respetivos resultados de precedência:
Exemplo 1:
- Registo n.º 1:
_CHANGE_SEQUENCE_NUMBER= "77" - Registo n.º 2:
_CHANGE_SEQUENCE_NUMBER= "7B"
Resultado: o registo n.º 2 é considerado o registo mais recente porque "7B" > "77" (ou seja, "123" > "119")
- Registo n.º 1:
Exemplo 2:
- Registo n.º 1:
_CHANGE_SEQUENCE_NUMBER= "FFF/B" - Registo n.º 2:
_CHANGE_SEQUENCE_NUMBER= "FFF/ABC"
Resultado: o registo n.º 2 é considerado o registo mais recente porque "FFF/ABC" > "FFF/B" (ou seja, "4095/2748" > "4095/11")
- Registo n.º 1:
Exemplo 3:
- Record #1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - Registo n.º 2:
_CHANGE_SEQUENCE_NUMBER= "ABC"
Resultado: o registo n.º 2 é considerado o registo mais recente porque "ABC" > "BA/FFFFFFFF" (ou seja, "2748" > "186/4294967295")
- Record #1:
Exemplo 4:
- Registo n.º 1:
_CHANGE_SEQUENCE_NUMBER= "FFF/ABC" - Registo n.º 2:
_CHANGE_SEQUENCE_NUMBER= "ABC"
Resultado: o registo n.º 1 é considerado o registo mais recente porque "FFF/ABC" > "ABC" (ou seja, "4095/2748" > "2748")
- Registo n.º 1:
Se os valores de _CHANGE_SEQUENCE_NUMBER forem idênticos, o registo com a hora de carregamento do sistema do BigQuery mais recente tem precedência sobre os registos carregados anteriormente.
Quando a ordenação personalizada é usada para uma tabela, o valor _CHANGE_SEQUENCE_NUMBER deve ser sempre fornecido. Todos os pedidos de gravação que não especifiquem o valor _CHANGE_SEQUENCE_NUMBER, o que leva a uma combinação de linhas com e sem valores _CHANGE_SEQUENCE_NUMBER, resultam numa ordenação imprevisível.
Configure uma reserva do BigQuery para utilização com o CDC
Pode usar reservas do BigQuery para alocar recursos de computação do BigQuery dedicados para operações de modificação de linhas de CDC. As reservas permitem-lhe definir um limite para o custo de realização destas operações. Esta abordagem é particularmente útil para fluxos de trabalho com operações de CDC frequentes em tabelas grandes, que, de outra forma, teriam custos a pedido elevados devido ao grande número de bytes processados quando se realiza cada operação.
As tarefas de CDC do BigQuery que aplicam modificações de linhas pendentes no intervalo de max_staleness são consideradas tarefas em segundo plano e usam o tipo de atribuição BACKGROUND, em vez do tipo de atribuição QUERY.
Por outro lado, as consultas fora do intervalo max_staleness que requerem modificações de linhas a serem aplicadas no tempo de execução da consulta usam o tipo de atribuição QUERY. As tabelas sem uma definição max_staleness ou as tabelas com max_staleness definido como 0 também usam o tipo de atribuição QUERY.
As tarefas em segundo plano da CDC do BigQuery realizadas sem uma atribuição usam os preços a pedido.BACKGROUND
Esta consideração é importante quando conceber a sua estratégia de gestão da carga de trabalho para o CDC do BigQuery.
Para configurar uma reserva do BigQuery para utilização com CDC, comece por
configurar uma reserva
na região onde as suas tabelas do BigQuery
estão localizadas. Para orientações sobre o tamanho da sua reserva, consulte o artigo
Dimensionar e monitorizar BACKGROUND reservas.
Depois de criar uma reserva,
atribua o projeto do BigQuery
à reserva e defina a opção job_type como BACKGROUND executando a seguinte
declaração CREATE ASSIGNMENT:
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
Substitua o seguinte:
ADMIN_PROJECT_ID: o ID do projeto de administração que detém a reserva.REGION: o nome da região onde o seu projeto está localizado. Por exemplo,us.RESERVATION_NAME: o nome da reserva.ASSIGNMENT_ID: o ID da atribuição. O ID tem de ser exclusivo do projeto e da localização, começar e terminar com uma letra minúscula ou um número, e conter apenas letras minúsculas, números e traços.PROJECT_ID: o ID do projeto que contém as tabelas do BigQuery que estão a ser modificadas pelo CDC do BigQuery. Este projeto está atribuído à reserva.
Dimensionar e monitorizar as reservas BACKGROUND
As reservas determinam a quantidade de recursos de computação disponíveis para realizar operações de computação do BigQuery. A subdimensionamento de uma reserva pode aumentar o tempo de processamento das operações de modificação de linhas de CDC. Para dimensionar uma reserva com precisão, monitorize o consumo histórico de espaços para o projeto que executa as operações de CDC consultando a vista INFORMATION_SCHEMA.JOBS_TIMELINE:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
Substitua REGION pelo
nome da região onde o seu projeto está localizado. Por
exemplo, us.
Considerações sobre dados eliminados
- As operações de CDC do BigQuery usam recursos de computação do BigQuery. Se as operações de CDC estiverem configuradas para usar a
faturação a pedido, as operações de CDC são
realizadas regularmente através de recursos internos do BigQuery. Se as operações de CDC estiverem configuradas com uma
BACKGROUNDreserva, as operações de CDC estão, em alternativa, sujeitas à disponibilidade de recursos da reserva configurada. Se não existirem recursos suficientes disponíveis na reserva configurada, o processamento das operações de CDC, incluindo a eliminação, pode demorar mais do que o previsto. - Uma operação de CDC
DELETEé considerada aplicada apenas quando a data/horaupsert_stream_apply_watermarktiver passado a data/hora em que a API Storage Write transmitiu a operação. Para mais informações sobre a data/horaupsert_stream_apply_watermark, consulte o artigo Monitorize o progresso da operação de inserção/atualização da tabela. - Para aplicar operações de CDC
DELETEque chegam fora de ordem, o BigQuery mantém um período de retenção de eliminação de dois dias. As operações da tabelaDELETEsão armazenadas durante este período antes de o Google Cloud processo de eliminação de dados padrão começar. As operaçõesDELETEdentro do período de retenção de eliminação usam os preços de armazenamento do BigQuery padrão.
Limitações
- A CDC do BigQuery não aplica chaves, pelo que é essencial que as chaves primárias sejam únicas.
- As chaves primárias não podem exceder 16 colunas.
- As tabelas com CDC não podem ter mais de 2000 colunas de nível superior definidas pelo esquema da tabela.
- As tabelas com CDC ativado não suportam o seguinte:
- Alterar declarações de linguagem de manipulação de dados (DML), como
DELETE,UPDATEeMERGE - Consultar tabelas com carateres universais
- Índices de pesquisa
- Alterar declarações de linguagem de manipulação de dados (DML), como
- As tabelas com CDC ativado que executam tarefas de união em tempo de execução porque o valor
max_stalenessda tabela é demasiado baixo não podem suportar o seguinte: - As operações de exportação do BigQuery em tabelas com CDC ativado não exportam modificações de linhas transmitidas recentemente que ainda não foram aplicadas por uma tarefa em segundo plano. Para exportar a tabela completa, use uma declaração
EXPORT DATA. - Se a sua consulta acionar uma união em tempo de execução numa tabela particionada, toda a tabela é analisada, quer a consulta esteja ou não restrita a um subconjunto das partições.
- Se estiver a usar a edição padrão, as reservas não estão disponíveis. Por isso, a aplicação de modificações pendentes de linhas usa o modelo de preços a pedido.
BACKGROUNDNo entanto, pode consultar tabelas com CDC ativado, independentemente da sua edição. - As pseudocolunas
_CHANGE_TYPEe_CHANGE_SEQUENCE_NUMBERnão são colunas consultáveis quando se faz uma leitura de tabelas. - A combinação de linhas com valores
UPSERTouDELETEpara_CHANGE_TYPEcom linhas que têm valoresINSERTou não especificados para_CHANGE_TYPEna mesma associação não é suportada e resulta no seguinte erro de validação:The given value is not a valid CHANGE_TYPE.
Preços da CDC do BigQuery
A CDC do BigQuery usa a API Storage Write para o carregamento de dados, o armazenamento do BigQuery para o armazenamento de dados e a computação do BigQuery para operações de modificação de linhas, que incorrem em custos. Para informações sobre preços, consulte os preços do BigQuery.
Estime os custos da CDC do BigQuery
Além das
práticas recomendadas gerais de estimativa de custos do BigQuery,
a estimativa dos custos da CDC do BigQuery pode ser importante para
fluxos de trabalho com grandes quantidades de dados, uma
max_staleness configuração ou dados que mudam com frequência.
A determinação de preços do carregamento de dados do BigQuery e a determinação de preços do armazenamento do BigQuery são calculadas diretamente pela quantidade de dados que carrega e armazena, incluindo pseudocolunas. No entanto, o preço de computação do BigQuery pode ser mais difícil de estimar, uma vez que está relacionado com o consumo de recursos de computação usados para executar tarefas de CDC do BigQuery.
As tarefas de CDC do BigQuery estão divididas em três categorias:
- Tarefas de aplicação em segundo plano: tarefas executadas em segundo plano a intervalos regulares definidos pelo valor
max_stalenessda tabela. Estas tarefas aplicam as modificações de linhas transmitidas recentemente à tabela com CDC ativado. - Consultar tarefas: consultas GoogleSQL executadas na janela
max_stalenesse que apenas leem a partir da tabela de base da CDC. - Tarefas de união de tempo de execução: tarefas acionadas por consultas GoogleSQL ad hoc executadas fora do período de
max_staleness. Estas tarefas têm de fazer uma união em tempo real da tabela de base da CDC e das modificações de linhas transmitidas recentemente no tempo de execução da consulta.
Apenas as tarefas de consulta tiram partido da particionamento do BigQuery. As tarefas de aplicação em segundo plano e as tarefas de união de tempo de execução não podem usar a partição porque, quando aplicam modificações de linhas transmitidas recentemente, não existe garantia de a que partição da tabela são aplicadas as inserções/atualizações transmitidas recentemente. Por outras palavras, a tabela de base completa é lida durante as tarefas de aplicação em segundo plano e as tarefas de união em tempo de execução. Pelo mesmo motivo, apenas as tarefas de consulta podem beneficiar de filtros em colunas de agrupamento do BigQuery. Compreender a quantidade de dados que estão a ser lidos para realizar operações de CDC é útil para estimar o custo total.
Se a quantidade de dados lidos da base de referência da tabela for elevada, considere usar o modelo de preços de capacidade do BigQuery, que não se baseia na quantidade de dados processados.
Práticas recomendadas de custos da CDC do BigQuery
Além das práticas recomendadas gerais de custos do BigQuery, use as seguintes técnicas para otimizar os custos das operações de CDC do BigQuery:
- A menos que seja necessário, evite configurar a opção
max_stalenessde uma tabela com um valor muito baixo. O valormax_stalenesspode aumentar a ocorrência de tarefas de aplicação em segundo plano e tarefas de união em tempo de execução, que são mais caras e mais lentas do que as tarefas de consulta. Para ver orientações detalhadas, consulte o valor recomendado da tabelamax_staleness. - Considere configurar uma reserva do BigQuery para utilização com tabelas de CDC.
Caso contrário, as tarefas de aplicação em segundo plano e as tarefas de união de tempo de execução usam os preços a pedido, o que pode ser mais caro devido ao maior processamento de dados. Para mais detalhes, saiba mais
acerca das
reservas do BigQuery e
siga as orientações sobre
como dimensionar e monitorizar uma reserva
BACKGROUNDpara utilização com o CDC do BigQuery.
O que se segue?
- Saiba como implementar a stream predefinida da API Google Storage Write.
- Saiba mais acerca das práticas recomendadas para a API Storage Write.
- Saiba como usar o Datastream para replicar bases de dados transacionais para o BigQuery com o CDC do BigQuery.