このセクションでは、Vertex AI Workbench インスタンスで Jupyter ノートブックを作成する方法について説明します。Vertex AI Workbench インスタンスは、データ サイエンス ワークフロー全体に対応する Jupyter ノートブック ベースの開発環境です。Vertex AI Workbench インスタンスは、JupyterLab で事前にパッケージ化され、ディープ ラーニング パッケージ一式(TensorFlow と PyTorch のフレームワークのサポートを含む)がプリインストールされています。詳細については、Vertex AI Workbench インスタンスの概要をご覧ください。
Vertex AI Workbench でノートブックを作成した後、Python コードを順番に実行して、予測を生成するためのほとんどの作業を行います。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Google Cloud コンソールで、 Google Cloud プロジェクトを開きます(まだ開いていない場合)。
Google Cloud コンソールで、Vertex AI Workbench の [インスタンス] ページに移動します。
Notebooks API を有効にするオプションが表示されたら、[有効にする] をクリックします。有効化が完了するまでに少し時間がかかることがあります。
[新規作成] をクリックします。
[新しいインスタンス] ダイアログの [名前] に、インスタンスの名前を入力します。
[リージョン] で [us-central1(アイオワ)] を選択します。
[ゾーン] で [us-central1-a] を選択します。
[作成] をクリックします。インスタンスの詳細を確認するには、インスタンスのリストに表示されたインスタンスの名前をクリックして、プロパティを表示します。
Google Cloud コンソールで [インスタンス] ページに移動します。
インスタンス名の横にある [JupyterLab を開く] をクリックします。
Vertex AI Workbench インスタンスで JupyterLab 環境が開きます。
JupyterLab で、[File] > [New] > [Notebook] の順に選択します。
新しいノートブック ファイルが開き、[Select kernel] ダイアログが表示されます。
[Select kernel] ダイアログで、Python 3 カーネルを選択します。
JupyterLab の左側のナビゲーション パネルで、Untitled.ipynb という名前の新しいノートブックを見つけます。名前を変更するには、ノートブック名を右クリックし、[Rename] をクリックして、新しい名前を入力します。
Cloud Storage - Vertex AI SDK for Python を使用して Vertex AI API 呼び出しを行う場合、Vertex AI がアーティファクトを Cloud Storage バケットに保存します。このバケットはステージング バケットと呼ばれます。ステージング バケットは、Vertex AI SDK for Python を初期化するときに指定します。詳細については、 Google Cloud ストレージ API 用の Python クライアントをご覧ください。
BigQuery - Vertex AI は、BigQuery の一般公開データセットを使用してモデルをトレーニングします。このチュートリアルで使用するデータセットにアクセスしてダウンロードするには、BigQuery SDK をインストールする必要があります。詳細については、BigQuery API クライアント ライブラリをご覧ください。
Google Cloud プロジェクト ID を確認します。詳細については、プロジェクト ID を確認するをご覧ください。
ノートブックのコードセルで、次のコマンドを実行します。コードで、PROJECT_ID は先ほど確認したプロジェクト ID に置き換えます。このコマンドで生成される出力は
Updated property [core/project].です。project_id = "PROJECT_ID" # @param {type:"string"} # Set the project id ! gcloud config set project ${project_id}次のコードを実行して、Vertex AI で使用される
region変数をus-central1に設定します。このコマンドでは出力は生成されません。詳細については、ロケーションを選択するをご覧ください。region = "us-central1" # @param {type: "string"}バケットの名前と URI を設定するには、次のコードを実行します。最後の行に Cloud Storage バケットの URI が表示されます。
bucket_name = "bucket-name-placeholder" # @param {type:"string"} bucket_uri = f"gs://{bucket_name}" from datetime import datetime timestamp = datetime.now().strftime("%Y%m%d%H%M%S") if bucket_name == "" or bucket_name is None or bucket_name == "bucket-name-placeholder": bucket_name = project_id + "aip-" + timestamp bucket_uri = "gs://" + bucket_name ! echo $bucket_uriCloud Storage クライアント ライブラリとバケット URI を使用してバケットを作成するには、次のコードを実行します。このコードでは出力は生成されません。
from google.cloud import storage client = storage.Client(project=project_id) # Create a bucket bucket = client.create_bucket(bucket_name, location=region)バケットが正常に作成されたことを確認するには、次のコマンドを実行します。
print("Bucket {} created.".format(bucket.name))project-projectには、Vertex AI SDK for Python を使用して Vertex AI API を呼び出すときに使用する Google Cloud プロジェクトを指定します。このチュートリアルでは、名前で Google Cloud プロジェクトを指定します。プロジェクト番号でプロジェクトを指定することもできます。location-locationには、API 呼び出し時に使用する Google Cloud リージョンを指定します。ロケーションを指定しない場合、Vertex AI SDK for Python はus-central1を使用します。staging_bucket-staging_bucketには、Vertex AI SDK for Python の使用時にアーティファクトをステージングするために使用する Cloud Storage バケットを指定します。gs://で始まる URI を使用してバケットを指定します。このチュートリアルでは、前に Cloud Storage バケットを作成するで作成した URI を使用します。
Vertex AI Workbench インスタンスを作成する
Vertex AI Workbench インスタンスを作成するには、次の操作を行います。
ノートブックを準備する
Vertex AI Workbench インスタンスはすでに認証され、 Google Cloud プロジェクトを使用できるようになっています。ただし、Vertex AI SDK for Python をインストールして初期化する必要があります。以下では、この手順について説明します。
このチュートリアルでは、ノートブックを作成した後、そのノートブックを使用して、連続したコード スニペットを入力して実行します。コードの各スニペットは順番に実行する必要があります。
ノートブックを作成して開く
ノートブックは、このチュートリアルのコードを実行する場所です。これは、拡張子が .ipynb のファイルです。作成したときは無題になります。開いた後に名前を変更できます。ノートブックを作成して開く手順は次のとおりです。
Vertex AI SDK for Python をインストールする
ノートブックを開いたら、Vertex AI SDK for Python をインストールする必要があります。Vertex AI SDK for Python を使用して Vertex AI API を呼び出し、データセットの作成、モデルの作成、モデルのトレーニングとデプロイ、予測を行います。詳細については、Vertex AI SDK for Python を使用するをご覧ください。
Vertex AI SDK for Python をインストールすると、依存するほかの Google Cloud SDK もインストールされます。このチュートリアルでは、次の 2 つの SDK を使用します。
Vertex AI SDK for Python とそれに依存する SDK をインストールするには、次のコードを実行します。
# Install the Vertex AI SDK
! pip3 install --upgrade --quiet google-cloud-aiplatform
--quiet フラグを指定すると、出力が抑制されるため、エラーが存在する場合はエラーのみが表示されます。感嘆符(!)は、これがシェルコマンドであることを示します。
これは新しいノートブックで実行する最初のコードであるため、ノートブックの上部にある空白のコードセルに入力します。コードセルにコードを入力したら、「選択したセルを実行して次に進む」アイコン をクリックするか、キーボード ショートカット Shift + Enter を使用してコードを実行します。
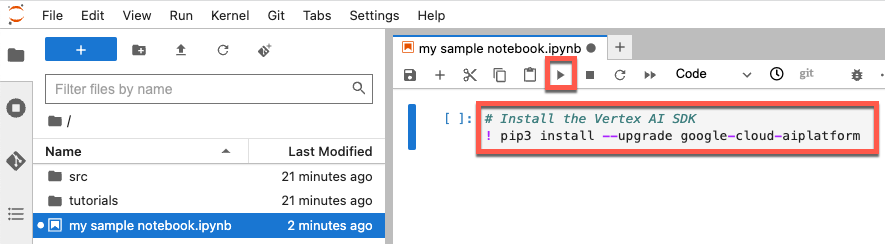
このチュートリアルを進めていくと、最後に実行したコードの下に空のコードセルが自動的に表示されます。このセルでコードを実行します。新しいコードセルを手動で追加する場合は、ノートブック ファイルの「下にセルを挿入」ボタン をクリックします。

プロジェクト ID とリージョンを設定する
このステップでは、プロジェクト ID とリージョンを設定します。最初に、変数に割り当てます。これにより、このチュートリアルの後半で簡単に参照できるようになります。次に、gcloud config コマンドを使用して Google Cloud セッションに設定します。後で、これらと Cloud Storage バケットの URI を使用して、Vertex AI SDK for Python を初期化します。
プロジェクト ID を設定する
プロジェクト ID を設定する手順は次のとおりです。
リージョンを設定する
このチュートリアルでは、us-central1 リージョンを使用します。リージョンを設定する手順は次のとおりです。
Cloud Storage バケットを作成する
このチュートリアルでは、Vertex AI がアーティファクトのステージングに使用する Cloud Storage バケットが必要です。Vertex AI は、作成したデータセットに関連付けられたデータとモデルリソースをステージング バケットに保存します。このデータは、セッションをまたいで保持され、利用できます。このチュートリアルでは、Vertex AI はデータセットもステージング バケットに保存します。ステージング バケットは、Vertex AI SDK for Python を初期化するときに指定します。
すべての Cloud Storage バケット名は、グローバルに一意である必要があります。すでに使用されている名前を選択すると、バケットを作成するコマンドが失敗します。次のコードでは、日時スタンプとプロジェクト名を使用して、一意のバケット名を作成します。gs:// にバケット名を付加して、Cloud Storage バケットの URI を作成します。echo シェルコマンドによって URI が表示されるため、正しく作成されていることを確認できます。
Vertex AI SDK for Python を初期化する
Vertex AI SDK for Python を初期化するには、まず、ライブラリ aiplatform をインポートします。次に、aiplatform.init を呼び出し、次のパラメータの値を渡します。
Google Cloud プロジェクト、リージョン、ステージング バケットを設定するには、次のコマンドを実行します。このコマンドでは出力は生成されません。
from google.cloud import aiplatform
# Initialize the Vertex AI SDK
aiplatform.init(project=project_id, location=region, staging_bucket=bucket_uri)
BigQuery を初期化する
このチュートリアルでは、ペンギンの BigQuery 一般公開データセットを使用してモデルをトレーニングします。Vertex AI がモデルをトレーニングした後、ペンギンの特徴を表すパラメータを指定します。モデルは、これらの特徴を使用してペンギンの種を予測します。一般公開データセットの詳細については、BigQuery の一般公開データセットをご覧ください。
BigQuery データセットを使用する前に、プロジェクト ID で BigQuery を初期化する必要があります。これを行うには、次のコマンドを実行します。このコマンドでは出力は生成されません。
from google.cloud import bigquery
# Set up BigQuery client
bq_client = bigquery.Client(project=project_id)