Con Vertex AI Neural Architecture Search, puoi cercare architetture neurali ottimali in termini di accuratezza, latenza, memoria, una combinazione di queste o una metrica personalizzata.
Determinare se Vertex AI Neural Architecture Search è lo strumento migliore per me
- Vertex AI Neural Architecture Search è uno strumento di ottimizzazione di alta gamma utilizzato per trovare le migliori architetture neurali in termini di accuratezza con o senza vincoli come latenza, memoria o una metrica personalizzata. Lo spazio di ricerca delle possibili scelte di architetture neurali può essere grande fino a 10^20. Si basa su una tecnica che negli ultimi anni ha generato con successo diversi modelli di visione artificiale all'avanguardia, tra cui NasNet, MNasNet, EfficientNet, NAS-FPN e SpineNet.
- Neural Architecture Search non è una soluzione in cui puoi semplicemente inserire i tuoi dati e aspettarti un buon risultato senza sperimentazione. È uno strumento di sperimentazione.
- Neural Architecture Search non è pensata per l'ottimizzazione degli iperparametri, come la regolazione del tasso di apprendimento o delle impostazioni dell'ottimizzatore. È pensato solo per una ricerca dell'architettura. Non devi combinare la regolazione degli iperparametri con Neural Architecture Search.
- Neural Architecture Search non è consigliata con dati di addestramento limitati o per set di dati altamente sbilanciati in cui alcune classi sono molto rare. Se utilizzi già potenziamenti elevati per l'addestramento di riferimento a causa della mancanza di dati, Neural Architecture Search non è consigliato.
- Per prima cosa, dovresti provare altri metodi e tecniche di machine learning tradizionali e convenzionali, come l'ottimizzazione degli iperparametri. Ti consigliamo di utilizzare Neural Architecture Search solo se non vedi ulteriori guadagni con questi metodi tradizionali.
- Devi avere un team interno per l'ottimizzazione del modello, che abbia una vaga idea dei parametri dell'architettura da modificare e provare. Questi parametri di architettura possono includere le dimensioni del kernel, il numero di canali o connessioni e molte altre possibilità. Se hai in mente uno spazio di ricerca da esplorare, Neural Architecture Search è di grande valore e può ridurre di almeno sei mesi circa il tempo di progettazione necessario per esplorare un ampio spazio di ricerca: fino a 10^20 scelte di architettura.
- Neural Architecture Search è pensata per i clienti aziendali che possono spendere diverse migliaia di dollari per un esperimento.
- Neural Architecture Search non è limitato al caso d'uso solo di visione. Al momento, vengono forniti solo spazi di ricerca predefiniti e trainer predefiniti basati sulla visione, ma i clienti possono anche utilizzare i propri spazi di ricerca e trainer non basati sulla visione.
- Neural Architecture Search non utilizza un approccio basato su supernet (one-shot-NAS o NAS basato sulla condivisione del peso) in cui devi solo fornire i tuoi dati e utilizzarli come soluzione. La personalizzazione di una superrete richiede un impegno non banale (mesi di lavoro). A differenza di una supernet, Neural Architecture Search è altamente personalizzabile per definire spazi di ricerca personalizzati e premi. La personalizzazione può essere eseguita in circa uno o due giorni.
- Neural Architecture Search è supportata in otto regioni in tutto il mondo. Controlla la disponibilità nella tua regione.
Prima di utilizzare Neural Architecture Search, ti consigliamo di leggere anche la sezione seguente relativa a costi previsti, miglioramenti dei risultati e requisiti di quota GPU.
Costo previsto, miglioramenti dei risultati e requisiti della quota GPU
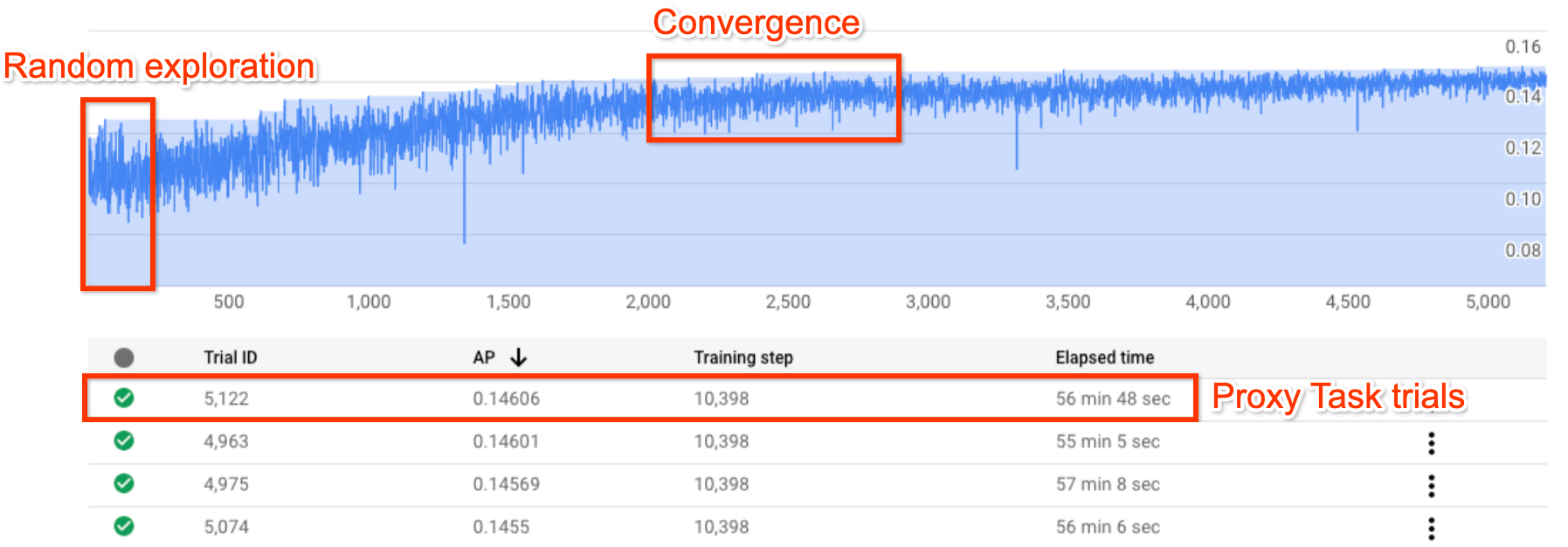
La figura mostra una tipica curva di ricerca di architetture neurali.
Y-axis mostra i premi della prova, mentre X-axis mostra il numero di prove lanciate.
Con l'aumento del numero di prove, il controller inizia a trovare modelli migliori. Di conseguenza, il premio inizia ad aumentare e, in seguito, la varianza e la crescita del premio iniziano a diminuire e mostrano la convergenza. Al punto di convergenza, il numero di prove può variare in base alle dimensioni dello spazio di ricerca, ma è dell'ordine di circa 2000 prove.
Ogni prova è progettata per essere una versione più piccola dell'addestramento completo chiamata proxy-task che viene eseguita per circa 1-2 ore su due GPU Nvidia V100. Il cliente può interrompere la ricerca manualmente in qualsiasi momento e potrebbe trovare modelli di premio più elevati rispetto al valore di riferimento prima che si verifichi il punto di convergenza.
Potrebbe essere meglio attendere il punto di convergenza per scegliere i risultati migliori.
Dopo la ricerca, la fase successiva consiste nel scegliere i 10 esperimenti (modelli) migliori ed eseguire un'addestramento completo su di essi.
(Facoltativo) Prova lo spazio di ricerca e l'addestramento MNasNet predefiniti
In questa modalità, osserva la curva di ricerca o alcune prove, circa 25, e fai un test drive con uno spazio di ricerca e un trainer MNasNet predefiniti.
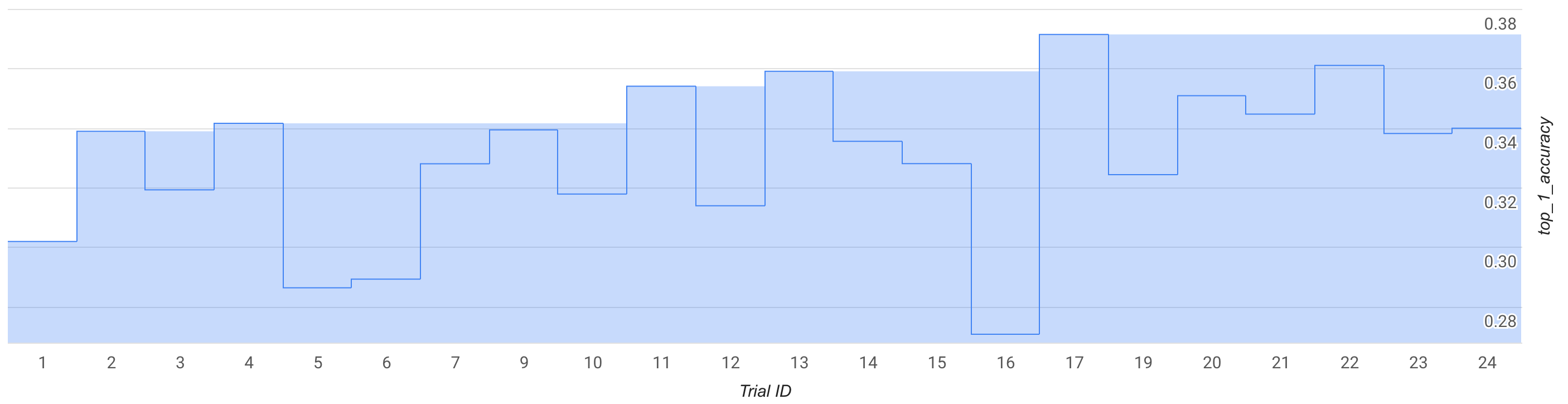
Nella figura, il premio migliore della fase 1 inizia a salire da circa 0,30 nella prova 1 a circa 0,37 nella prova 17. La corsa esatta potrebbe essere leggermente diversa a causa della casualità del campionamento, ma dovresti notare un piccolo aumento del premio migliore. Tieni presente che si tratta ancora di un test di prova e non rappresenta una prova del concetto o una convalida del benchmark pubblico.
Il costo di questa esecuzione è descritto nel dettaglio di seguito:
- Fase 1:
- Numero di prove: 25
- Numero di GPU per prova: 2
- Tipo di GPU: TESLA_T4
- Numero di CPU per prova: 1
- Tipo di CPU: n1-highmem-16
- Tempo di addestramento medio per una singola prova: 3 ore
- Numero di prove parallele: 6
- Quota GPU utilizzata: (num-gpus-per-trial * num-parallel-trials) = 12 GPU. Utilizza la regione us-central1 per il test drive e ospita i dati di addestramento nella stessa regione. Non è necessaria alcuna quota aggiuntiva.
- Tempo di esecuzione: (total-trials * training-time-per-trial)/(num-parallel-trials) = 12 ore
- Ore GPU: (totale-prove * tempo-addestramento-per-prova * numero-gpu-per-prova) = 150 ore GPU T4
- Ore CPU: (total-trials * training-time-per-trial * num-cpus-per-trial) = 75 ore n1-highmem-16
- Costo: circa 185 $. Puoi interrompere il job prima per ridurre il costo. Per calcolare il prezzo esatto, consulta la pagina dei prezzi.
Poiché si tratta di un'esecuzione di prova, non è necessario eseguire un addestramento completo della fase 2 per i modelli della fase 1. Per scoprire di più sull'esecuzione della fase 2, consulta il tutorial 3.
Per questa esecuzione viene utilizzato il notebook MnasNet.
(Facoltativo) Esecuzione di una proof of concept (PoC) dello spazio di ricerca e dell'addestramento MNasNet predefiniti
Se ti interessa replicare quasi esattamente un risultato di MNasnet pubblicato, puoi utilizzare questa modalità. Secondo il documento, MnasNet raggiunge una precisione top-1 del 75,2% con una latenza di 78 ms su uno smartphone Pixel, ovvero è 1,8 volte più veloce di MobileNetV2 con una precisione superiore dello 0,5% e 2,3 volte più veloce di NASNet con una precisione superiore dell'1,2%. Tuttavia, questo esempio utilizza GPU anziché TPU per l'addestramento e CPU cloud (n1-highmem-8) per valutare la latenza. In questo esempio, l'accuratezza top-1 di Stage2 prevista su MNasNet è del 75,2% con una latenza di 50 ms su cloud-CPU (n1-highmem-8).
Il costo di questa esecuzione è descritto nel dettaglio di seguito:
Ricerca di fase 1:
- Numero di prove: 2000
- Numero di GPU per prova: 2
- Tipo di GPU: TESLA_T4
- Tempo di addestramento medio per una singola prova: 3 ore
- Numero di prove parallele: 10
- Quota GPU utilizzata: (num-gpus-per-trial * num-parallel-trials) = 20 GPU T4. Poiché questo numero è superiore alla quota predefinita, crea una richiesta di quota dall'interfaccia utente del progetto. Per ulteriori informazioni, consulta setting_up_path.
- Tempo di esecuzione: (totale-prove * tempo-di-addestramento-per-prova)/(num-prove-parallele)/24 = 25 giorni. Nota: il job termina dopo 14 giorni. Dopo questo periodo, puoi riprendere il job di ricerca con un solo comando per altri 14 giorni. Se la quota GPU è più elevata, il tempo di esecuzione diminuisce proporzionalmente.
- Ore GPU: (total-trials * training-time-per-trial * num-gpus-per-trial) = 12000 ore GPU T4.
- Costo: circa 15.000 $
Addestramento completo della fase 2 con i 10 migliori modelli:
- Numero di prove: 10
- Numero di GPU per prova: 4
- Tipo di GPU: TESLA_T4
- Tempo di addestramento medio per una singola prova: circa 9 giorni
- Numero di prove parallele: 10
- Quota GPU utilizzata: (num-gpus-per-trial * num-parallel-trials) = 40 GPU T4. Poiché questo numero è superiore alla quota predefinita, crea una richiesta di quota dall'interfaccia utente del progetto. Per ulteriori informazioni, consulta setting_up_path. Puoi eseguire questo comando anche con 20 GPU T4 eseguendo il job due volte con cinque modelli alla volta anziché tutti e 10 in parallelo.
- Tempo di esecuzione: (totale-prove * tempo-di-addestramento-per-prova)/(num-prove-parallele)/24 = circa 9 giorni
- Ore GPU: (total-trials * training-time-per-trial * num-gpus-per-trial) = 8960 ore GPU T4.
- Costo: circa 8000 $
Costo totale: circa 23.000 $. Per calcolare il prezzo esatto, consulta la pagina dei prezzi. Nota: questo esempio non è un job di addestramento normale medio. L'addestramento completo viene eseguito per circa nove giorni su quattro GPU TESLA_T4.
Per questa esecuzione viene utilizzato il notebook MnasNet.
Utilizzare lo spazio di ricerca e gli istruttori
Forniamo un costo approssimativo per un utente personalizzato medio. Le tue esigenze possono variare a seconda dell'attività di addestramento e delle GPU e delle CPU utilizzate. Per un'esecuzione end-to-end, è necessaria una quota di almeno 20 GPU come descritto qui. Nota: il miglioramento del rendimento dipende completamente dalla tua attività. Possiamo fornire solo esempi come MNasnet come riferimenti per l'aumento del rendimento.
Il costo di questa ipotetica esecuzione personalizzata è descritto nel dettaglio di seguito:
Ricerca di fase 1:
- Numero di prove: 2000
- Numero di GPU per prova: 2
- Tipo di GPU: TESLA_T4
- Tempo di addestramento medio di una singola prova: 1,5 ore
- Numero di prove parallele: 10
- Quota GPU utilizzata: (num-gpus-per-trial * num-parallel-trials) = 20 GPU T4. Poiché questo numero è superiore alla quota predefinita, devi creare una richiesta di quota dall'interfaccia utente del progetto. Per ulteriori informazioni, consulta la sezione Richiedi una quota aggiuntiva di dispositivi per il progetto.
- Tempo di esecuzione: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = 12,5 giorni
- Ore GPU: (total-trials * training-time-per-trial * num-gpus-per-trial) = 6000 ore GPU T4.
- Costo: circa 7400 $
Addestramento completo della fase 2 con i 10 migliori modelli:
- Numero di prove: 10
- Numero di GPU per prova: 2
- Tipo di GPU: TESLA_T4
- Tempo di addestramento medio per una singola prova: circa 4 giorni
- Numero di prove parallele: 10
- Quota GPU utilizzata: (num-gpus-per-trial * num-parallel-trials) = 20 GPU T4. **Poiché questo numero è superiore alla quota predefinita, devi creare una richiesta di quota dall'interfaccia utente del progetto. Per ulteriori informazioni, consulta la sezione Richiedere una quota aggiuntiva di dispositivi per il progetto. Consulta la stessa documentazione per le esigenze relative alle quote personalizzate.
- Tempo di esecuzione: (total-trials * training-time-per-trial)/(num-parallel-trials)/24 = circa 4 giorni
- Ore GPU: (total-trials * training-time-per-trial * num-gpus-per-trial) = 1920 ore GPU T4.
- Costo: circa 2400 $
Per ulteriori informazioni sul costo del design delle attività proxy, consulta Design delle attività proxy. Il costo è simile all'addestramento di 12 modelli (la fase 2 nella figura utilizza 10 modelli):
- Quota GPU utilizzata: uguale a quella dell'esecuzione della fase 2 nella figura.
- Costo: (12/10) * costo-fase-2-per-10-modelli = circa 2880 $
Costo totale: circa 12.680 $. Per calcolare il prezzo esatto, consulta la pagina dei prezzi.
Questi costi di ricerca della fase 1 si riferiscono alla ricerca fino al raggiungimento del punto di convergenza e al guadagno in termini di rendimento massimo. Tuttavia, non aspettare che la ricerca converga. Se la curva del premio per la ricerca ha iniziato a crescere, puoi aspettarti un aumento minore del rendimento con un costo per la ricerca inferiore eseguendo l'addestramento completo di fase 2 con il modello migliore finora. Ad esempio, per il grafico di ricerca mostrato in precedenza, non attendere di raggiungere i 2000 tentativi per la convergenza. Potresti aver trovato modelli migliori con 700 o 1200 prove e puoi eseguire l'addestramento completo di fase 2 per questi modelli. Puoi sempre interrompere la ricerca in anticipo per ridurre il costo. Puoi anche eseguire l'addestramento completo di fase 2 in parallelo durante l'esecuzione della ricerca, ma assicurati di disporre della quota GPU per supportare un job parallelo aggiuntivo.
Riepilogo di prestazioni e costi
La tabella seguente riassume alcuni punti dati con casi d'uso diversi e rendimento e costi associati.
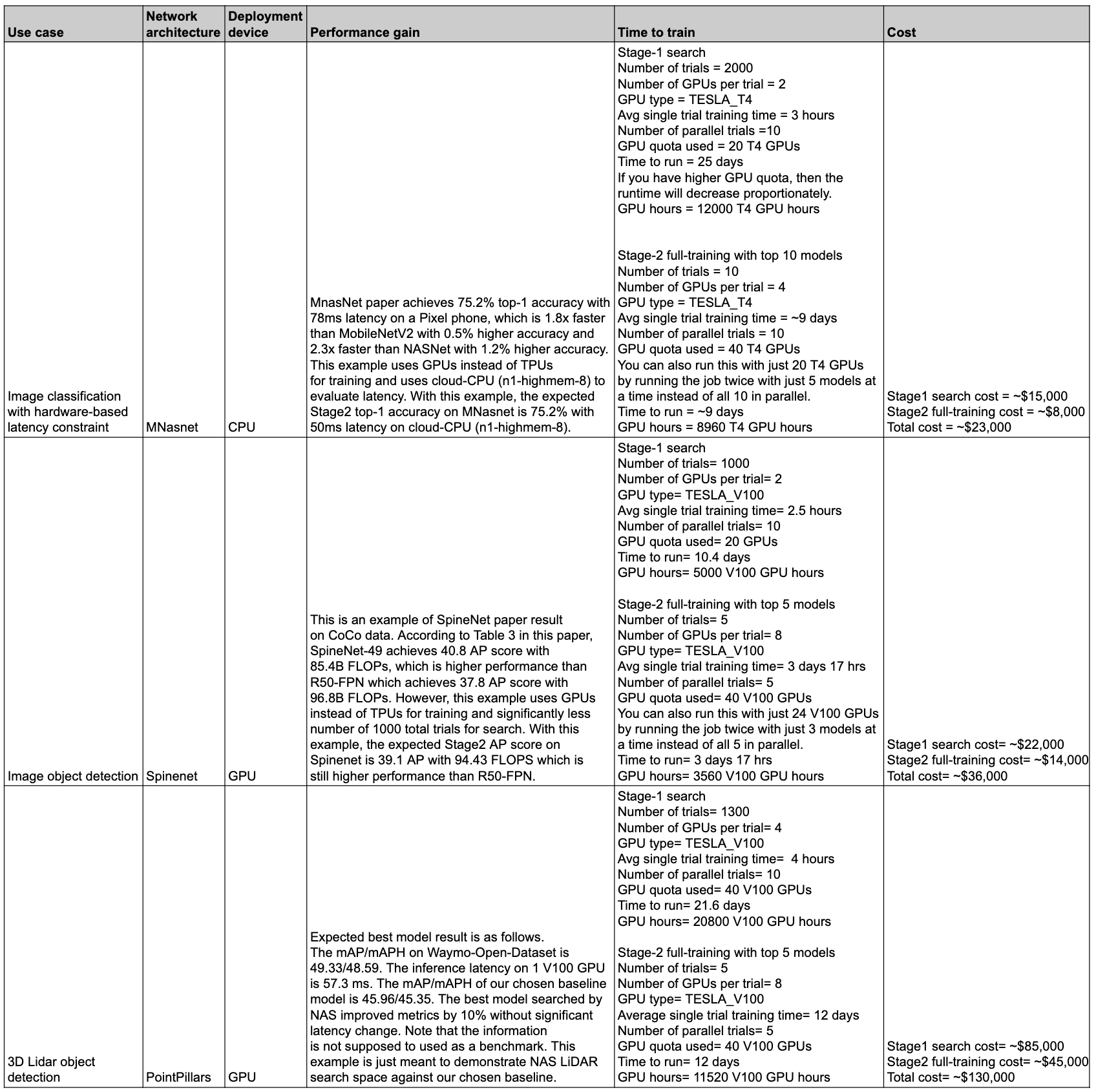
Casi d'uso e funzionalità
Le funzionalità di Neural Architecture Search sono flessibili e facili da usare. Un utente principiante può utilizzare spazi di ricerca predefiniti, addestramento predefinito e notebook senza alcuna ulteriore configurazione per iniziare a esplorare Vertex AI Neural Architecture Search per il proprio set di dati. Allo stesso tempo, un utente esperto può utilizzare Neural Architecture Search con il proprio trainer personalizzato, lo spazio di ricerca personalizzato e il dispositivo di inferenza personalizzato, nonché estendere la ricerca di architetture anche per casi d'uso non di visione.
Neural Architecture Search offre trainer e spazi di ricerca predefiniti da eseguire su GPU per i seguenti casi d'uso:
- Addestratori TensorFlow con risultati basati su set di dati pubblici pubblicati in un notebook
- Gli allenatori PyTorch devono essere utilizzati solo come esempio di tutorial
- Esempio di spazio di ricerca per la segmentazione delle immagini mediche 3D di PyTorch
- Classificazione MNasNet basata su PyTorch
- Ricerca dei dispositivi di targeting con vincoli di latenza e memoria
- Ulteriori spazi di ricerca all'avanguardia predefiniti basati su TensorFlow con codice
- Scalabilità del modello
- Aumentazione dei dati
L'intero insieme di funzionalità offerte da Neural Architecture Search può essere utilizzato facilmente anche per architetture e casi d'uso personalizzati:
- Un linguaggio Neural Architecture Search per definire uno spazio di ricerca personalizzato per le possibili architetture neurali e integrarlo con il codice dell'addestratore personalizzato.
- Spazi di ricerca all'avanguardia predefiniti e pronti all'uso con codice.
- Trainer precompilato pronto all'uso, con codice, che funziona su GPU.
- Un Managed Service per la ricerca dell'architettura, tra cui:
- Un controller di ricerca di architetture neurali che esegue il campionamento dello spazio di ricerca per trovare l'architettura migliore.
- Docker/librerie precompilate, con codice, per calcolare latenza/FLOP/memoria su hardware personalizzato.
- Tutorial per insegnare l'utilizzo del NAS.
- Un insieme di strumenti per progettare attività proxy.
- Indicazioni ed esempio per un addestramento PyTorch efficiente con Vertex AI.
- Supporto della libreria per la generazione di report e l'analisi delle metriche personalizzate.
- Google Cloud console per monitorare e gestire i job.
- Blocchi di appunti facili da usare per iniziare la ricerca.
- Supporto della libreria per la gestione dell'utilizzo delle risorse GPU/CPU a livello di progetto o di job.
- Client NAS basato su Python per creare docker, lanciare job NAS e riprendere un job di ricerca precedente.
- Google Cloud assistenza clienti basata sull'interfaccia utente della console.
Sfondo
Neural Architecture Search è una tecnica per automatizzare la progettazione di reti neurali. Negli ultimi anni ha generato diversi modelli di visione artificiale all'avanguardia, tra cui:
Questi modelli risultanti sono all'avanguardia in tutte e tre le classi principali di problemi di visione artificiale: classificazione delle immagini, rilevamento di oggetti e segmentazione.
Con la ricerca di architetture neurali, gli ingegneri possono ottimizzare i modelli in base ad accuratezza, latenza e memoria nella stessa prova, riducendo il tempo necessario per il deployment dei modelli. La ricerca di architetture neurali esplora molti tipi diversi di modelli: il controller propone modelli di ML, poi li addestra e valuta e li esegue più di 1000 volte per trovare le soluzioni migliori con vincoli di latenza e/o memoria sui dispositivi di targeting. La figura seguente mostra i componenti chiave del framework di ricerca dell'architettura:
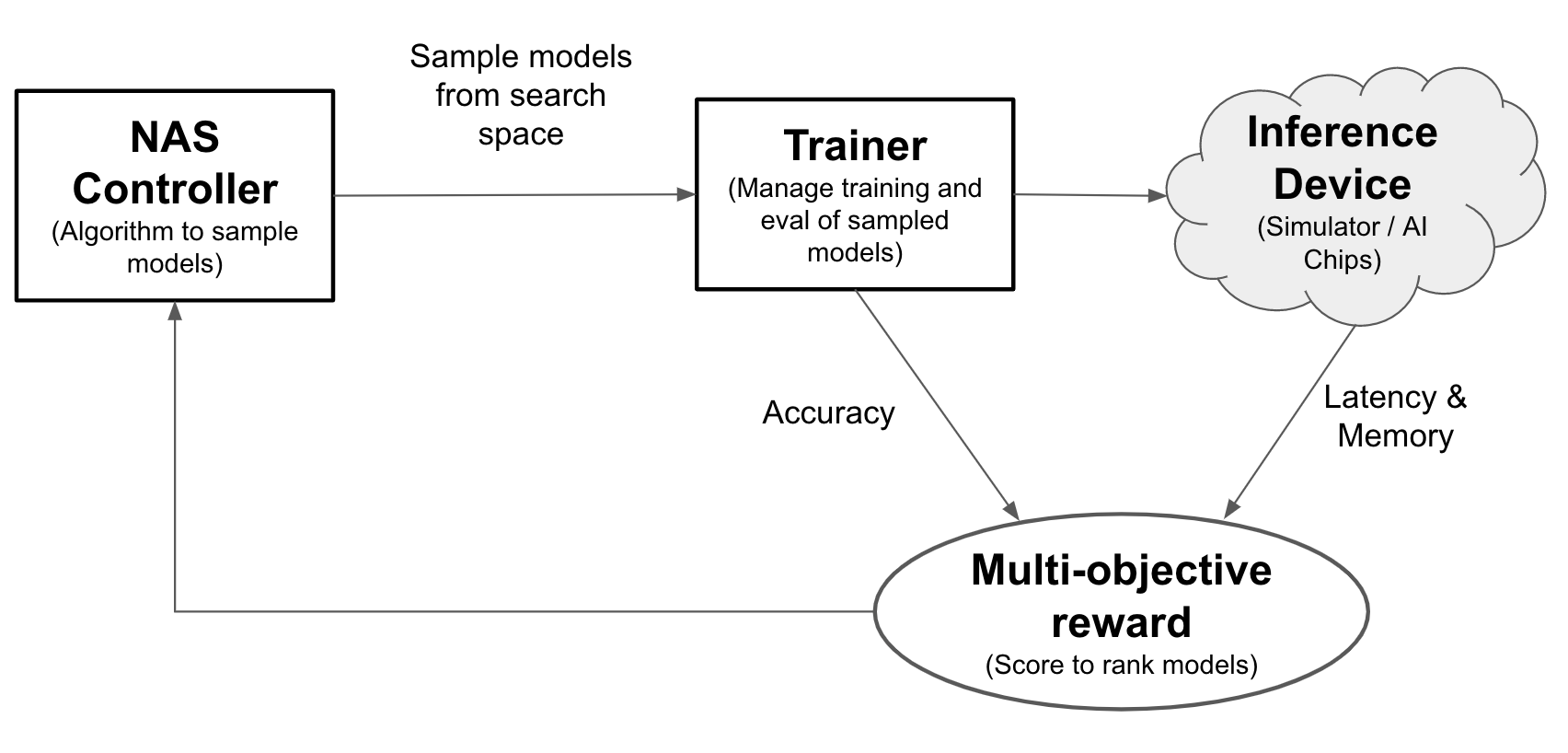
- Modello: un'architettura neurale con operazioni e connessioni.
- Spazio di ricerca: lo spazio dei possibili modelli (operazioni e connessioni) che possono essere progettati e ottimizzati.
- Docker per l'addestramento: utilizza il codice dell'addestramento personalizzabile per addestrare e valutare un modello e calcolarne l'accuratezza.
- Dispositivo di inferenza: un dispositivo hardware come CPU/GPU su cui vengono calcolati la latenza e l'utilizzo della memoria del modello.
- Premia: una combinazione di metriche del modello, come accuratezza, latenza e memoria, utilizzata per classificare i modelli come migliori o peggiori.
- Neural Architecture Search Controller: l'algoritmo di orchestrazione che (a) esegue il campionamento dei modelli dallo spazio di ricerca, (b) riceve i premi del modello e (c) fornisce il successivo insieme di suggerimenti per i modelli da valutare per trovare i modelli più ottimali.
Attività di configurazione utente
Neural Architecture Search offre un trainer predefinito integrato con gli spazi di ricerca predefiniti che possono essere facilmente utilizzati con i notebook forniti senza alcuna ulteriore configurazione.
Tuttavia, la maggior parte degli utenti deve utilizzare il proprio addestramento personalizzato, gli spazi di ricerca personalizzati, le metriche personalizzate (ad esempio memoria, latenza e tempo di addestramento) e il premio personalizzato (combinazione di elementi come accuratezza e latenza). A questo scopo, devi:
- Definisci uno spazio di ricerca personalizzato utilizzando il linguaggio di Neural Architecture Search fornito.
- Integra la definizione dello spazio di ricerca nel codice dell'addestratore.
- Aggiungi i report sulle metriche personalizzate al codice dell'addestratore.
- Aggiungi un premio personalizzato al codice dell'addestratore.
- Crea il contenitore di addestramento e utilizzalo per avviare i job di ricerca di architetture neurali.
Il seguente diagramma lo illustra:
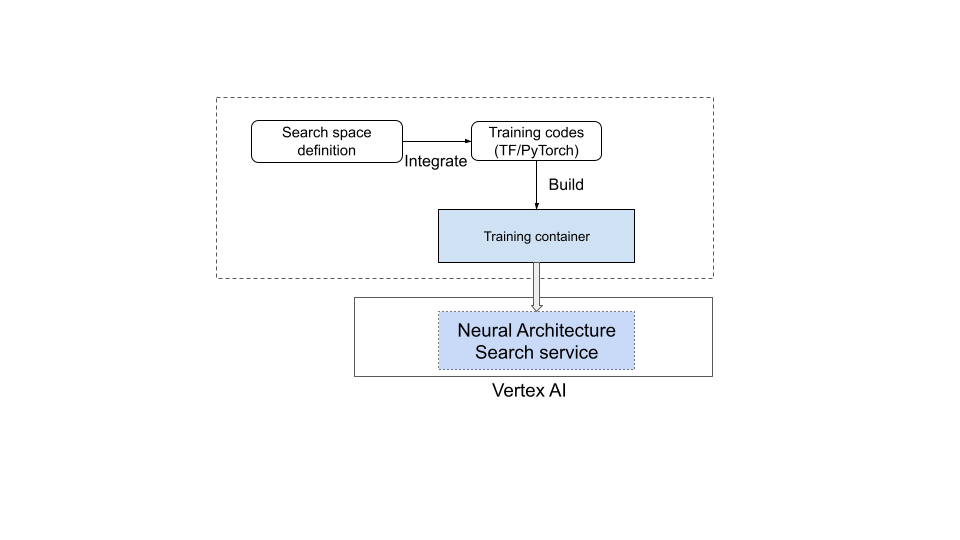
Servizio Neural Architecture Search in funzione
Dopo aver configurato il contenitore di addestramento da utilizzare, il servizio Neural Architecture Search avvia più contenitori di addestramento in parallelo su più dispositivi GPU. Puoi controllare quante prove utilizzare in parallelo per l'addestramento e quante prove totali avviare. A ogni training-container viene fornita un'architettura suggerita dallo spazio di ricerca. Il contenitore di addestramento crea il modello suggerito, esegue l'addestramento/la valutazione e poi riporta i premi al servizio Neural Architecture Search. Man mano che questo processo procede, il servizio di ricerca di architetture neurali utilizza il feedback sul premio per trovare architetture di modelli sempre migliori. Dopo la ricerca, hai accesso alle metriche registrate per ulteriori analisi.
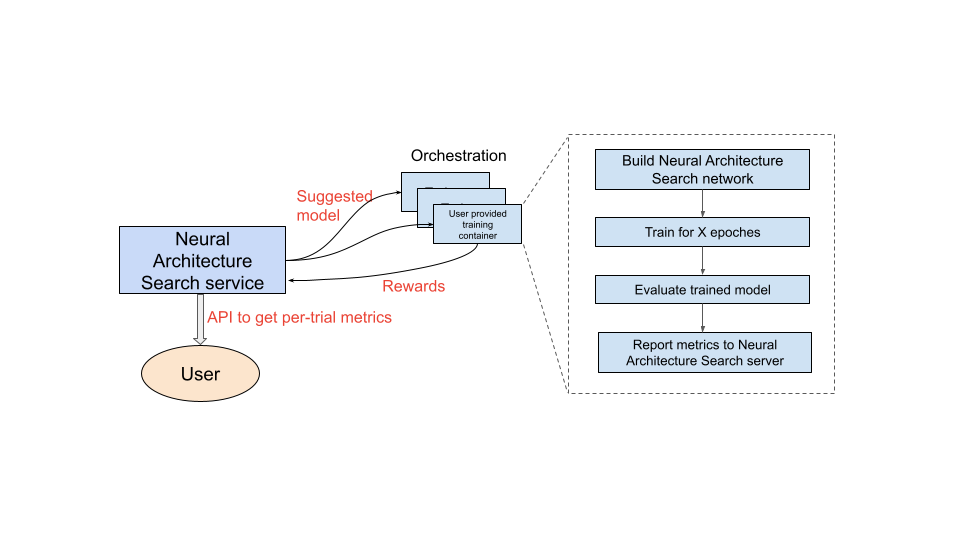
Panoramica del percorso dell'utente per Neural Architecture Search
I passaggi di alto livello per eseguire un esperimento di ricerca di architetture neurali sono i seguenti:
Configurazioni e definizioni:
- Identifica il set di dati etichettato e specifica il tipo di attività (ad esempio rilevamento o segmentazione).
- Personalizza il codice dell'istruttore:
- Utilizza uno spazio di ricerca predefinito o definisci uno spazio di ricerca personalizzato utilizzando il linguaggio di Neural Architecture Search.
- Integra la definizione dello spazio di ricerca nel codice dell'addestratore.
- Aggiungi i report sulle metriche personalizzate al codice dell'addestratore.
- Aggiungi un premio personalizzato al codice dell'addestratore.
- Crea un container di trainer.
- Configura i parametri di prova di ricerca per l'addestramento parziale (attività proxy). L'addestramento della ricerca dovrebbe idealmente terminare rapidamente (ad esempio 30-60 minuti) per addestrare parzialmente i modelli:
- Epoche minime necessarie per consentire ai modelli campionati di raccogliere il premio (le epoche minime non devono garantire la convergenza del modello).
- Iperparametri (ad esempio il tasso di apprendimento).
Esegui la ricerca localmente per assicurarti che il contenitore integrato dello spazio di ricerca possa funzionare correttamente.
Avvia il Google Cloud job di ricerca (fase 1) con cinque prove di test e verifica che le prove di ricerca soddisfino gli obiettivi di tempo di esecuzione e accuratezza.
Avvia il job Google Cloud di ricerca (fase 1) con più di 1000 prove.
Nell'ambito della ricerca, imposta anche un intervallo regolare per addestrare i migliori modelli N (fase 2):
- Iperparametri e algoritmo per la ricerca degli iperparametri. la fase 2 utilizza normalmente una configurazione simile alla fase 1, ma con impostazioni più elevate per determinati parametri, come i passaggi/le epoche di addestramento e il numero di canali.
- Criteri di interruzione (il numero di epoche).
Analizza le metriche registrate e/o visualizza le architetture per ottenere informazioni.
Un esperimento di ricerca dell'architettura può essere seguito da un esperimento di ricerca di scalabilità e da un esperimento di ricerca di aumento.
Ordine di lettura della documentazione
- (Obbligatorio) Configura l'ambiente
- (Obbligatorio) Tutorial
- (Obbligatorio solo per i clienti PyTorch) Addestramento efficiente di PyTorch con i dati del cloud
- (Obbligatorio) Best practice e flusso di lavoro consigliato
- (Obbligatorio) Design dell'attività proxy
- (Obbligatorio solo se utilizzi trainer predefiniti) Come utilizzare gli spazi di ricerca predefiniti e un trainer predefinito
Riferimenti
- Utilizzare il machine learning per esplorare l'architettura delle reti neurali
- MnasNet: verso l'automazione della progettazione di modelli di machine learning mobile
- EfficientNet: miglioramento della precisione e dell'efficienza tramite AutoML e scalabilità dei modelli
- NAS-FPN: apprendimento di un'architettura a piramide di caratteristiche scalabile per il rilevamento di oggetti
- SpineNet: apprendimento di una struttura di base con permutazione della scala per il riconoscimento e la localizzazione
- RandAugment