Configura un ambiente prima di avviare un esperimento Vertex AI Neural Architecture Search.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init -
Dopo aver inizializzato gcloud CLI, aggiornala e installa i componenti richiesti:
gcloud components update gcloud components install beta
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init -
Dopo aver inizializzato gcloud CLI, aggiornala e installa i componenti richiesti:
gcloud components update gcloud components install beta
- Per concedere a tutti gli utenti di Neural Architecture Search il ruolo
Vertex AI User (
roles/aiplatform.user), contatta l'amministratore del progetto. - Installa Docker.
Se utilizzi un sistema operativo basato su Linux, come Ubuntu o Debian, aggiungi il tuo nome utente al gruppo
dockerin modo da poter eseguire Docker senza utilizzaresudo:sudo usermod -a -G docker ${USER}Potresti dover riavviare il sistema dopo esserti aggiunto al gruppo
docker. - Apri Docker. Per assicurarti che Docker sia in esecuzione, esegui questo comando Docker,
che restituisce la data e l'ora correnti:
docker run busybox date
- Utilizza
gcloudcome assistente per le credenziali per Docker:gcloud auth configure-docker
-
(Facoltativo) Se vuoi eseguire il container utilizzando la GPU in locale,
installa
nvidia-docker. -
Specifica un nome per il nuovo bucket. Il nome deve essere univoco in tutti i bucket di Cloud Storage.
BUCKET_NAME="YOUR_BUCKET_NAME"
Ad esempio, utilizza il nome del progetto con
-vertexai-nasaggiunto:PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
Controlla il nome del bucket che hai creato.
echo $BUCKET_NAME
-
Seleziona una regione per il bucket e imposta una variabile di ambiente
REGION.Utilizza la stessa regione in cui prevedi di eseguire i job di Neural Architecture Search.
Ad esempio, il seguente codice crea
REGIONe lo imposta suus-central1:REGION=us-central1
-
Crea il nuovo bucket:
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
- Per Servizio, seleziona API Vertex AI.
- Per regione, seleziona la regione in base alla quale vuoi filtrare.
- In Quota, seleziona un nome di acceleratore il cui prefisso sia
Addestramento modello personalizzato.
- Per le GPU V100, il valore è Addestramento di modelli personalizzati GPU Nvidia V100 per regione.
- Per le CPU, il valore può essere CPU per l'addestramento di modelli personalizzati per i tipi di macchine N1/E2 per regione. Il numero della CPU rappresenta l'unità di CPU. Se
vuoi 8 CPU
highmem-16, la richiesta di quota deve essere per 8 * 16 = 128 unità CPU. Inserisci anche il valore desiderato per region.
Imposta le variabili di ambiente di base:
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default loginConfigura l'autenticazione Docker per il tuo registro degli artefatti:
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(Facoltativo) Configura un ambiente virtuale Python 3. L'utilizzo di Python 3 è consigliato ma non obbligatorio:
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activateInstalla librerie aggiuntive:
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0Crea un account di servizio:
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAMEConcedi i ruoli
aiplatform.userestorage.objectAdminal account di servizio:gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdminApri un nuovo terminale Shell.
Esegui il comando Git clone:
git clone https://github.com/google/vertex-ai-nas.git
Configurare il bucket Cloud Storage
Questa sezione mostra come creare un nuovo bucket. Puoi utilizzare un bucket esistente, ma deve trovarsi nella stessa regione in cui esegui i job AI Platform. Inoltre, se non fa parte del progetto che utilizzi per eseguire Neural Architecture Search, devi concedere esplicitamente l'accesso ai service account Neural Architecture Search.
Richiedi una quota di dispositivi aggiuntiva per il progetto
I tutorial utilizzano circa cinque macchine CPU e non richiedono alcuna quota aggiuntiva. Dopo aver eseguito i tutorial, esegui il job Neural Architecture Search.
Il job Neural Architecture Search addestra un batch di modelli
in parallelo. Ogni modello addestrato corrisponde a una prova.
Leggi la sezione relativa all'impostazione di number-of-parallel-trials
per stimare la quantità di CPU e GPU necessarie per un job di ricerca.
Ad esempio, se ogni prova utilizza 2 GPU T4 e imposti
number-of-parallel-trials su 20, hai bisogno
di una quota totale di 40 GPU T4 per un job di ricerca. Inoltre,
se ogni prova utilizza una CPU highmem-16, sono necessarie 16 unità CPU
per prova, ovvero 320 unità CPU per 20 prove parallele.
Tuttavia, chiediamo una quota minima di 10 prove parallele
(o 20 quote GPU).
La quota iniziale predefinita per le GPU varia in base alla regione e al tipo di GPU
e di solito è 0, 6 o 12 per Tesla_T4
e 0 o 6 per Tesla_V100. La quota iniziale predefinita per le CPU
varia in base alla regione e di solito è 20, 450 o 2200.
(Facoltativo) Se prevedi di eseguire più job di ricerca in parallelo, aumenta il requisito di quota. La richiesta di una quota non comporta un addebito immediato. L'addebito viene effettuato una volta eseguito un job.
Se non disponi di quota sufficiente e provi ad avviare un job che richiede più risorse di quelle della tua quota, il job non verrà avviato e verrà visualizzato un errore simile al seguente:
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
In alcuni casi, se sono stati avviati più job per lo stesso progetto contemporaneamente e la quota non è sufficiente per tutti, uno dei job rimane in stato di coda e non inizia l'addestramento. In questo caso, annulla il job in coda e richiedi una quota maggiore o attendi il completamento del job precedente.
Puoi richiedere la quota aggiuntiva di dispositivi dalla pagina Quote.
Puoi applicare filtri per trovare la quota che vuoi modificare:
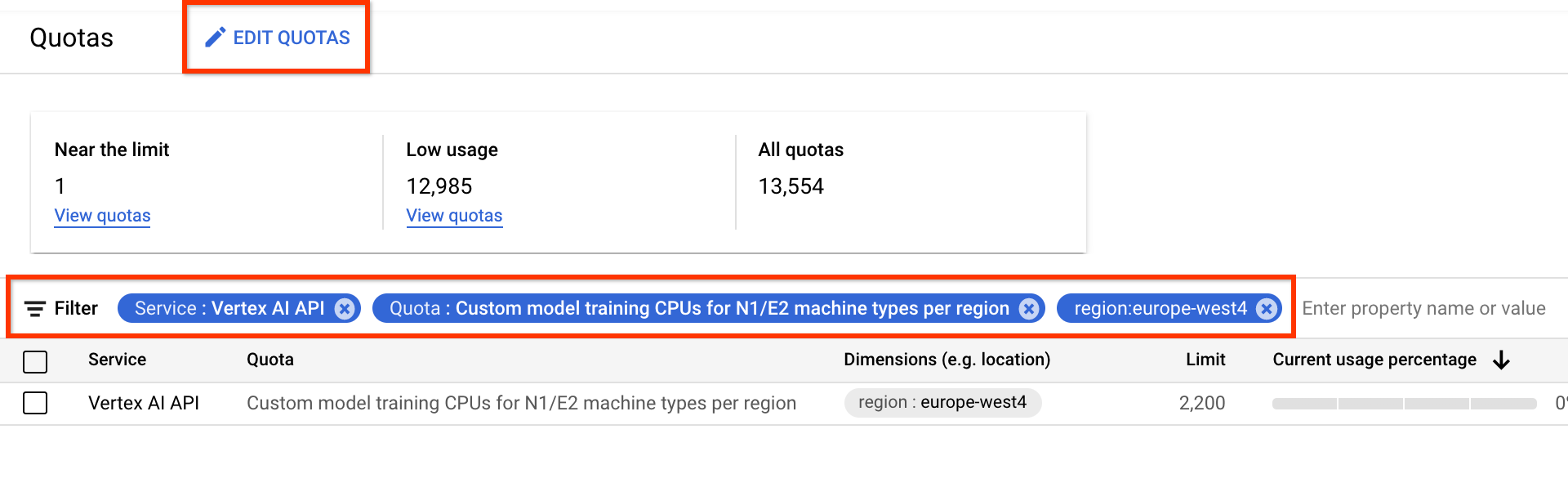
Dopo aver creato una richiesta di quota, riceverai un Case number e
email di follow-up sullo stato della richiesta. L'approvazione di una quota GPU
potrebbe richiedere circa 2-5 giorni lavorativi. In generale,
l'approvazione di una quota di circa 20-30 GPU dovrebbe essere più rapida
e richiedere circa 2-3 giorni, mentre l'approvazione di
circa 100 GPU potrebbe richiedere 5 giorni lavorativi. L'approvazione di una quota CPU
potrebbe richiedere fino a due giorni lavorativi.
Tuttavia, se una regione sta vivendo una grave carenza di un tipo di GPU,
non c'è alcuna garanzia anche con una piccola richiesta di quota.
In questo caso, potrebbe esserti chiesto di scegliere un'altra regione o un altro tipo di GPU. In generale, le GPU T4 sono
più facili da ottenere rispetto alle V100. Le GPU T4 richiedono più tempo di esecuzione, ma
sono più convenienti.
Per ulteriori informazioni, consulta Richiedi un aggiustamento delle quote.
Configura Artifact Registry per il tuo progetto
Devi configurare un registro degli artefatti per il tuo progetto e la tua regione in cui esegui il push delle immagini Docker.
Vai alla pagina Artifact Registry del tuo progetto. Se non è già abilitata, abilita prima l'API Artifact Registry per il tuo progetto:
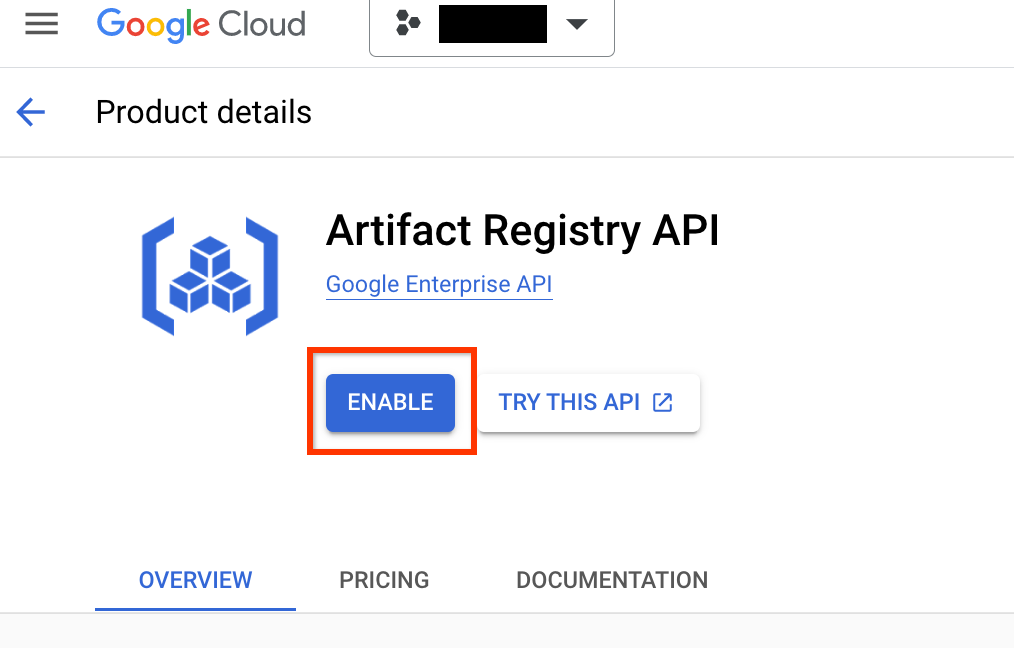
Una volta attivata, inizia a creare un nuovo repository facendo clic su CREA REPOSITORY:
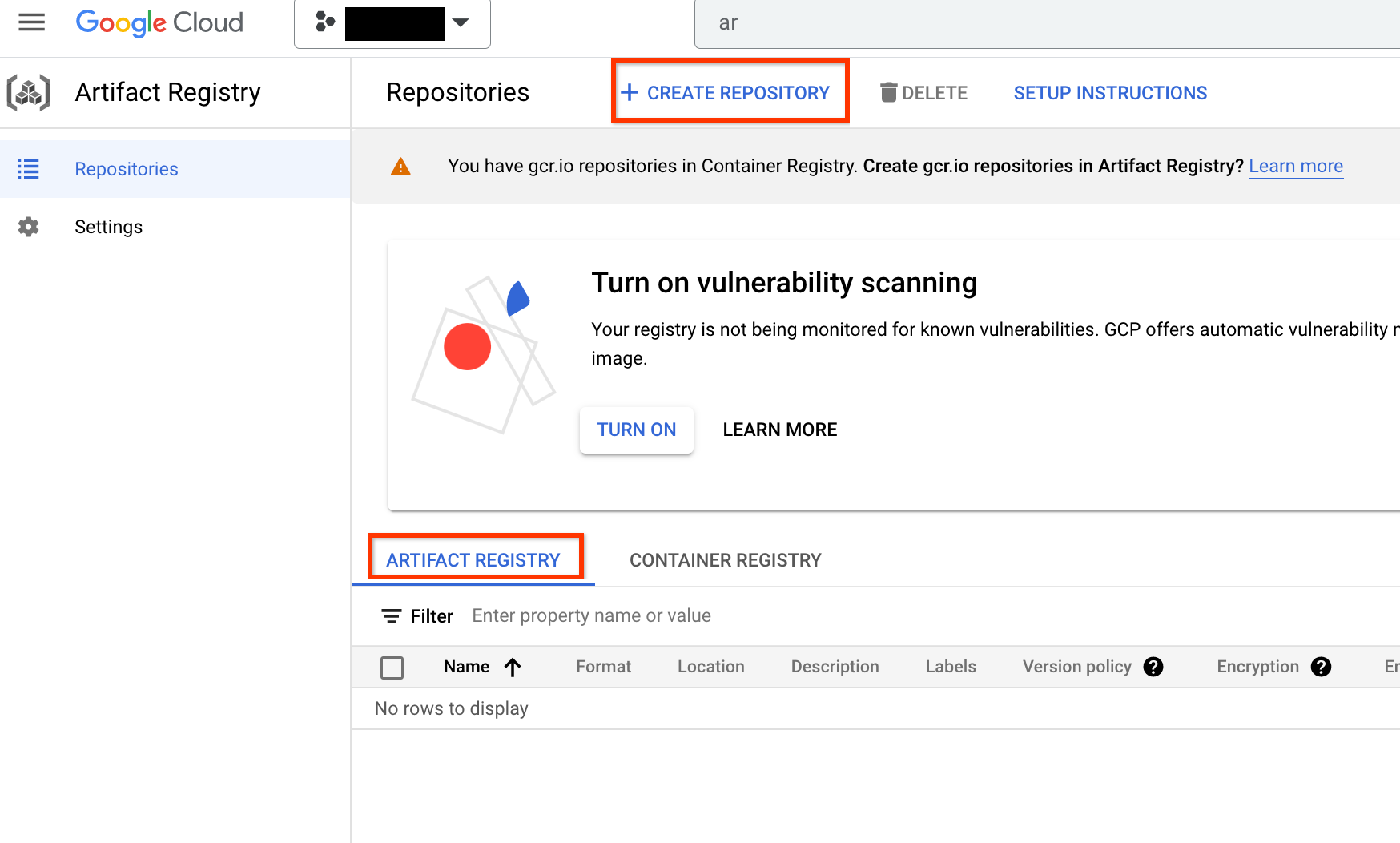
Scegli Nome come nas, Formato come Docker e Tipo di località come Regione. Per Regione, seleziona la località in cui esegui i job e poi fai clic su CREA.
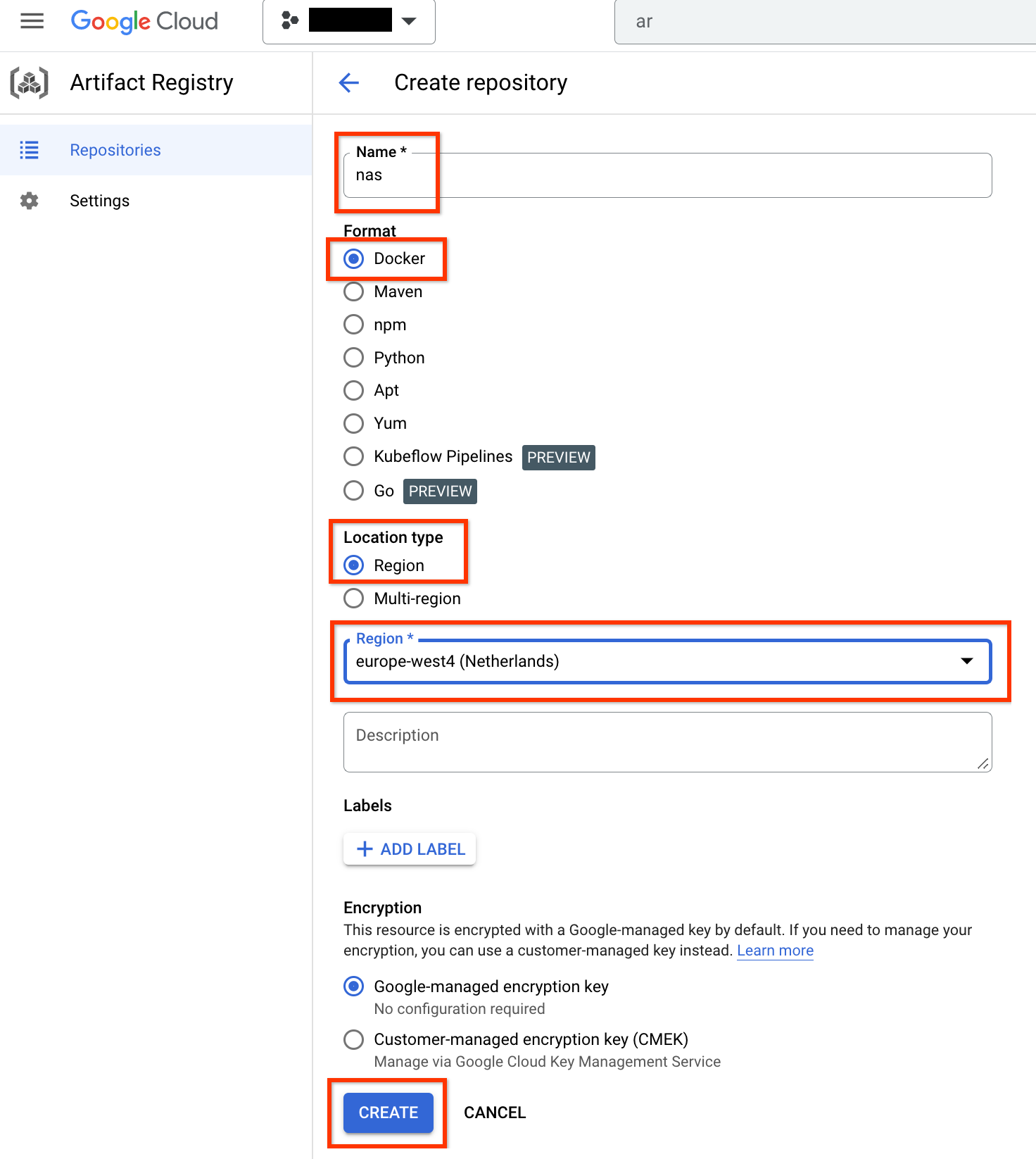
In questo modo dovrebbe essere creato il repository Docker che ti interessa, come mostrato di seguito:
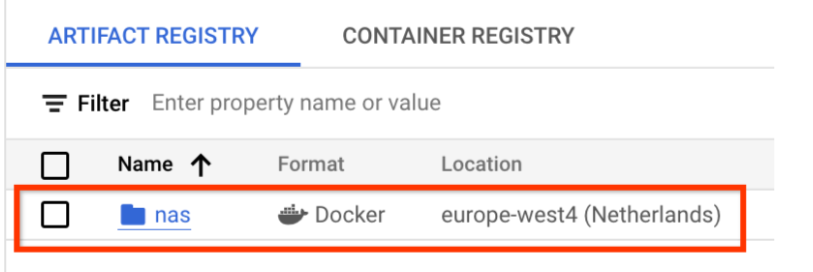
Devi anche configurare l'autenticazione per eseguire il push dei Docker in questo repository. Questo passaggio è descritto nella sezione Configurazione dell'ambiente locale riportata di seguito.
Configura l'ambiente locale
Puoi eseguire questi passaggi utilizzando la shell Bash nel tuo ambiente locale oppure eseguirli da un blocco note in un'istanza di Vertex AI Workbench.
Configura un service account
Prima di eseguire i job NAS, devi configurare un service account. Puoi eseguire questi passaggi utilizzando la shell Bash nel tuo ambiente locale oppure eseguirli da un blocco note in un'istanza di Vertex AI Workbench.
Ad esempio, i seguenti comandi creano un account di servizio denominato my-nas-sa
nel progetto my-nas-project con i ruoli aiplatform.user e storage.objectAdmin:
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
Scarica codice
Per avviare un esperimento Neural Architecture Search, devi scaricare il codice Python di esempio, che include trainer predefiniti, definizioni dello spazio di ricerca e librerie client associate.
Esegui i seguenti passaggi per scaricare il codice sorgente.