Tabellarische Workflows sind eine Reihe integrierter, vollständig verwalteter und skalierbarer Pipelines für End-to-End-ML mit tabellarischen Daten. Sie nutzt die Technologie von Google für die Modellentwicklung und bietet Ihnen Optionen zur Anpassung an Ihre Anforderungen.
Vorteile
- Vollständig verwaltet: Sie müssen sich keine Gedanken über Aktualisierungen, Abhängigkeiten und Konflikte machen.
- Einfach zu skalieren: Wenn die Arbeitslast oder die Datasets wachsen, müssen Sie die Infrastruktur nicht neu entwickeln.
- Auf Leistung optimiert: Die richtige Hardware wird automatisch für die Anforderungen des Workflows konfiguriert.
- Durchdacht: Die Kompatibilität mit Produkten in der Vertex AI MLOps-Suite, wie Vertex AI Pipelines und Vertex AI Experiments, ermöglicht Ihnen das Ausführen vieler Experimente in kurzer Zeit.
Technische Übersicht
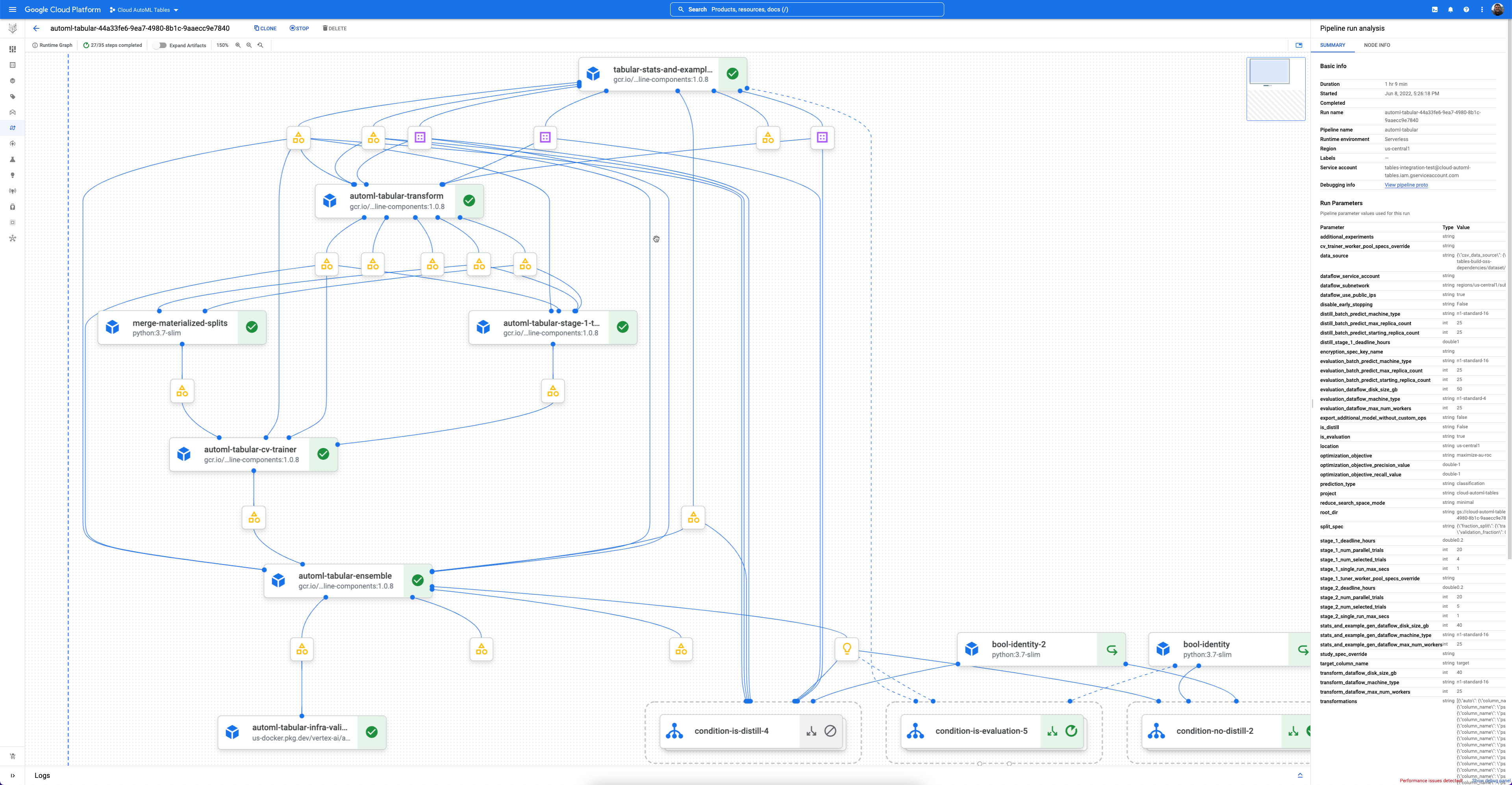
Jeder Workflow ist eine verwaltete Instanz von Vertex AI Pipelines.
Vertex AI Pipelines ist ein serverloser Dienst, der Kubeflow-Pipelines ausführt. Mithilfe von Pipelines können Sie Ihre Aufgaben für maschinelles Lernen und die Datenvorbereitung automatisieren und überwachen. Jeder Schritt in einer Pipeline führt einen Teil des Workflows der Pipeline aus. Eine Pipeline kann beispielsweise Schritte zum Aufteilen von Daten, zum Transformieren von Datentypen und zum Trainieren eines Modells enthalten. Da Schritte Instanzen von Pipeline-Komponenten sind, haben Schritte Eingaben, Ausgaben und ein Container-Image. Schritteingaben können aus den Eingaben der Pipeline festgelegt werden oder von der Ausgabe anderer Schritte in dieser Pipeline abhängen. Diese Abhängigkeiten definieren den Workflow der Pipeline als gerichtetes azyklisches Diagramm.
Jetzt starten
In den meisten Fällen müssen Sie die Pipeline mit dem Google Cloud Pipeline Components SDK definieren und ausführen. Der folgende Beispielcode veranschaulicht diesen Prozess. Beachten Sie, dass die tatsächliche Implementierung des Codes abweichen kann.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
Wenden Sie sich an Ihren Vertriebsmitarbeiter oder füllen Sie ein Anfrageformular aus, wenn Sie Beispiel-Colabs und -Notebooks nutzen möchten.
Versionsverwaltung und Wartung
Tabellarische Workflows haben ein effektives Versionsverwaltungssystem, das kontinuierliche Updates und Verbesserungen ermöglicht, ohne funktionsgefährdende Änderungen an Ihren Anwendungen vorzunehmen.
Jeder Workflow wird als Teil des Google Cloud Pipeline Components SDK veröffentlicht und aktualisiert. Aktualisierungen und Änderungen an einem Workflow werden als neue Versionen dieses Workflows veröffentlicht. Frühere Versionen eines Workflows sind immer über die älteren Versionen des SDK verfügbar. Wenn die SDK-Version angepinnt ist, wird auch die Version des Workflows angepinnt.
Verfügbare Workflows
Vertex AI bietet die folgenden tabellarischen Workflows:
| Name | Typ | Verfügbarkeit |
|---|---|---|
| Feature Transform Engine | Feature Engineering | Öffentliche Vorschau |
| End-to-End-AutoML | Klassifizierung und Regression | Allgemein verfügbar |
| TabNet | Klassifizierung und Regression | Öffentliche Vorschau |
| Wide & Deep | Klassifizierung und Regression | Öffentliche Vorschau |
| Vorhersage | Prognosen | Öffentliche Vorschau |
Weitere Informationen und Beispiel-Notebooks erhalten Sie von Ihrem Vertriebsmitarbeiter oder indem Sie ein Anfrageformular ausfüllen.
Feature Transform Engine
Feature Transform Engine führt eine Featureauswahl und Featuretransformationen durch. Wenn die Auswahl von Merkmalen aktiviert ist, erstellt Feature Transform Engine eine Reihe von wichtigen Features. Wenn Featuretransformationen aktiviert sind, verarbeitet Feature Transform Engine die Features, damit die Eingabe für das Modelltraining und die Modellbereitstellung konsistent ist. Feature Transform Engine kann eigenständig oder mit jedem der tabellarischen Workflows für das Training verwendet werden. Sie unterstützen sowohl TensorFlow- als auch Nicht-TensorFlow-Frameworks.
Weitere Informationen finden Sie unter Feature-Engineering.
Tabellarische Workflows für Klassifizierung und Regression
Tabellarischer Workflow für End-to-End-AutoML
Tabellarischer Workflow für End-to-End-AutoML ist eine vollständige AutoML-Pipeline für Klassifizierungs- und Regressionsaufgaben. Sie ähnelt der AutoML API, Sie können jedoch auswählen, was Sie steuern möchten und was automatisiert werden soll. Statt Steuerelemente für die gesamte Pipeline haben Sie Steuerelemente für jeden Schritt in der Pipeline. Folgende Steuerelemente der Pipeline sind verfügbar:
- Datenaufteilung
- Feature Engineering
- Architektursuche
- Modelltraining
- Modellsortierung
- Modelldestillation
Vorteile
- Unterstützt große Datasets mit mehreren TB und bis zu 1.000 Spalten.
- Ermöglicht die Verbesserung der Stabilität und niedrigere Trainingszeit, indem der Suchbereich der Architekturtypen begrenzt wird oder die Architektursuche übersprungen wird.
- Ermöglicht die Verbesserung der Trainingsgeschwindigkeit durch manuelle Auswahl der Hardware für das Training und die Architektursuche.
- Ermöglicht die Reduzierung der Modellgröße und die Verbesserung der Latenz mit der Destillation oder durch Ändern der Ensemblegröße.
- Jede AutoML-Komponente kann in einer leistungsstarken Benutzeroberfläche für Pipelinediagramme überprüft werden, auf der Sie die transformierten Datentabellen, bewerteten Modellarchitekturen und viele weitere Details sehen können.
- AutoML-Komponenten bieten erweiterte Flexibilität und Transparenz. So können Sie beispielsweise Parameter anpassen, Hardware auswählen, den Prozessstatus und Logs aufrufen und vieles mehr.
Eingabe-Ausgabe
- Sie nimmt eine BigQuery-Tabelle oder eine CSV-Datei aus Cloud Storage als Eingabe an.
- Erzeugt ein Vertex AI-Modell als Ausgabe.
- Zu den Zwischenausgaben gehören Dataset-Statistiken und Dataset-Aufteilungen.
Weitere Informationen finden Sie unter Tabellarischer Workflow für End-to-End-AutoML.
Tabellarischer Workflow für TabNet
Der tabellarische Workflow für TabNet ist eine Pipeline, mit der Sie Klassifizierungs- oder Regressionsmodelle trainieren können. TabNet verwendet sequenzielle Aufmerksamkeit, um die Features auszuwählen, die bei jedem Entscheidungsschritt berücksichtigt werden sollen. Dadurch werden Interpretierbarkeit und effizientes Lernen ermöglicht, da die Lernkapazität für die wichtigsten Features verwendet wird.
Vorteile
- Wählt automatisch den entsprechenden Hyperparameter-Suchbereich anhand der Dataset-Größe, des Inferenztyps und des Trainingsbudgets aus.
- In Vertex AI eingebunden. Das trainierte Modell ist ein Vertex AI-Modell. Sie können sofort Batchinferenzen ausführen oder das Modell für Onlineinferenzen bereitstellen.
- Bietet inhärente Modellinterpretierbarkeit. Sie erhalten einen Einblick in die Features, die TabNet für seine Entscheidung verwendet hat.
- Unterstützt GPU-Training.
Eingabe-Ausgabe
Verwendet eine BigQuery-Tabelle oder eine CSV-Datei aus Cloud Storage als Eingabe und stellt ein Vertex AI-Modell als Ausgabe bereit.
Weitere Informationen finden Sie unter Tabellarischer Workflow für TabNet.
Tabellarischer Workflow für Wide & Deep
Tabellarischer Workflow für Wide & Deep ist eine Pipeline, mit der Sie Klassifizierungs- oder Regressionsmodelle trainieren können. Wide & Deep trainiert gemeinsam breite lineare Modelle und neuronale Deep-Learning-Netzwerke. Sie vereint die Vorteile von Speicherung und Generalisierung. Bei einigen Online-Experimenten zeigten die Ergebnisse, dass Wide & Deep die Anwendungsgewinnung im Google Store im Vergleich zu reinen und tiefgehenden Modellen erheblich erhöht hat.
Vorteile
- In Vertex AI eingebunden. Das trainierte Modell ist ein Vertex AI-Modell. Sie können sofort Batchinferenzen ausführen oder das Modell für Onlineinferenzen bereitstellen.
Eingabe-Ausgabe
Verwendet eine BigQuery-Tabelle oder eine CSV-Datei aus Cloud Storage als Eingabe und stellt ein Vertex AI-Modell als Ausgabe bereit.
Weitere Informationen finden Sie unter Tabellarischer Workflow für Wide & Deep.
Tabellarische Workflows für Prognosen
Tabellarischer Workflow für Prognosen
Der tabellarische Workflow für Prognosen ist die vollständige Pipeline für Prognoseaufgaben. Sie ähnelt der AutoML API, Sie können jedoch auswählen, was Sie steuern möchten und was automatisiert werden soll. Statt Steuerelemente für die gesamte Pipeline haben Sie Steuerelemente für jeden Schritt in der Pipeline. Folgende Steuerelemente der Pipeline sind verfügbar:
- Datenaufteilung
- Feature Engineering
- Architektursuche
- Modelltraining
- Modellsortierung
Vorteile
- Unterstützt große Datasets mit bis zu 1 TB und bis zu 200 Spalten.
- Ermöglicht die Verbesserung der Stabilität und niedrigere Trainingszeit, indem der Suchbereich der Architekturtypen begrenzt wird oder die Architektursuche übersprungen wird.
- Ermöglicht die Verbesserung der Trainingsgeschwindigkeit durch manuelle Auswahl der Hardware für das Training und die Architektursuche.
- Ermöglicht die Reduzierung der Modellgröße und die Verbesserung der Latenz durch Ändern der Ensemblegröße.
- Jede Komponente kann in einer leistungsstarken Benutzeroberfläche für Pipelinediagramme überprüft werden, auf der Sie die transformierten Datentabellen, bewerteten Modellarchitekturen und viele weitere Details sehen können.
- Alle Komponenten bieten erweiterte Flexibilität und Transparenz. So können Sie beispielsweise Parameter anpassen, Hardware auswählen, den Prozessstatus und Logs aufrufen und vieles mehr.
Eingabe-Ausgabe
- Sie nimmt eine BigQuery-Tabelle oder eine CSV-Datei aus Cloud Storage als Eingabe an.
- Erzeugt ein Vertex AI-Modell als Ausgabe.
- Zu den Zwischenausgaben gehören Dataset-Statistiken und Dataset-Aufteilungen.
Weitere Informationen finden Sie unter Tabellarischer Workflow für Prognosen.
Nächste Schritte
- Weitere Informationen zum tabellarischen Workflow für End-to-End-AutoML
- Weitere Informationen zum tabellarischen Workflow für TabNet
- Weitere Informationen zum tabellarischen Workflow für Wide & Deep.
- Weitere Informationen zum tabellarischen Workflow für Prognosen.
- Feature Engineering
- Preise für tabellarische Workflows