NVIDIA Triton su Vertex AI
Vertex AI supporta il deployment di modelli sul server di inferenza Triton in esecuzione su un container personalizzato pubblicato da NVIDIA GPU Cloud (NGC), ovvero l'immagine del server di inferenza NVIDIA Triton. Le immagini Triton di NVIDIA contengono tutti i pacchetti e le configurazioni richiesti che soddisfano i requisiti di Vertex AI per le immagini di container di serving personalizzato. L'immagine contiene il server di inferenza Triton con supporto per i modelli TensorFlow, PyTorch, TensorRT, ONNX e OpenVINO. L'immagine include anche il backend FIL (Forest Inference Library) che supporta l'esecuzione di framework di ML come XGBoost, LightGBM e Scikit-Learn.
Triton carica i modelli ed espone endpoint REST di inferenza, integrità e gestione dei modelli che utilizzano protocolli di inferenza standard. Durante il deployment di un modello in Vertex AI, Triton riconosce gli ambienti Vertex AI e adotta il protocollo di inferenza Vertex AI per controlli di integrità e richieste di inferenza.
Il seguente elenco descrive le funzionalità e i casi d'uso principali del server di inferenza NVIDIA Triton:
- Supporto di più framework di deep learning e machine learning: Triton supporta il deployment di più modelli e un mix di framework e formati di modelli: TensorFlow (SavedModel e GraphDef), PyTorch (TorchScript), TensorRT, ONNX, OpenVINO e backend FIL per supportare framework come XGBoost, LightGBM, Scikit-Learn e qualsiasi formato di modello Python o C++ personalizzato.
- Esecuzione simultanea di più modelli: Triton consente l'esecuzione simultanea di più modelli, più istanze dello stesso modello o entrambi sulla stessa risorsa di calcolo con zero o più GPU.
- Ensemble di modelli (concatenamento o pipeline): Triton ensemble supporta i casi d'uso in cui più modelli sono composti come una pipeline (o un DAG, Directed Acyclic Graph) con tensori di input e output collegati tra loro. Inoltre, con un backend Python Triton, puoi includere qualsiasi logica di pre-elaborazione, post-elaborazione o flusso di controllo definita da Business Logic Scripting (BLS).
- Esegui sui backend CPU e GPU: Triton supporta l'inferenza per i modelli di cui è stato eseguito il deployment sui nodi con CPU e GPU.
- Batch dinamico delle richieste di inferenza:per i modelli che supportano il batch, Triton dispone di algoritmi di pianificazione e batch integrati. Questi algoritmi combinano dinamicamente le singole richieste di inferenza in batch lato server per migliorare la velocità effettiva dell'inferenza e aumentare l'utilizzo della GPU.
Per saperne di più su NVIDIA Triton Inference Server, consulta la documentazione di Triton.
Immagini container NVIDIA Triton disponibili
La tabella seguente mostra le immagini Docker di Triton disponibili nel catalogo NVIDIA NGC. Scegli un'immagine in base al framework del modello, al backend e alle dimensioni dell'immagine container che utilizzi.
xx e yy si riferiscono rispettivamente alle versioni principali e secondarie di Triton.
| Immagine NVIDIA Triton | Supporti |
|---|---|
xx.yy-py3 |
Contenitore completo con supporto per i modelli TensorFlow, PyTorch, TensorRT, ONNX e OpenVINO |
xx.yy-pyt-python-py3 |
Solo backend PyTorch e Python |
xx.yy-tf2-python-py3 |
Solo backend TensorFlow 2.x e Python |
xx.yy-py3-min |
Personalizza il container Triton in base alle esigenze. |
Per iniziare: pubblicazione di inferenze con NVIDIA Triton
La seguente figura mostra l'architettura di alto livello di Triton su Vertex AI Inference:
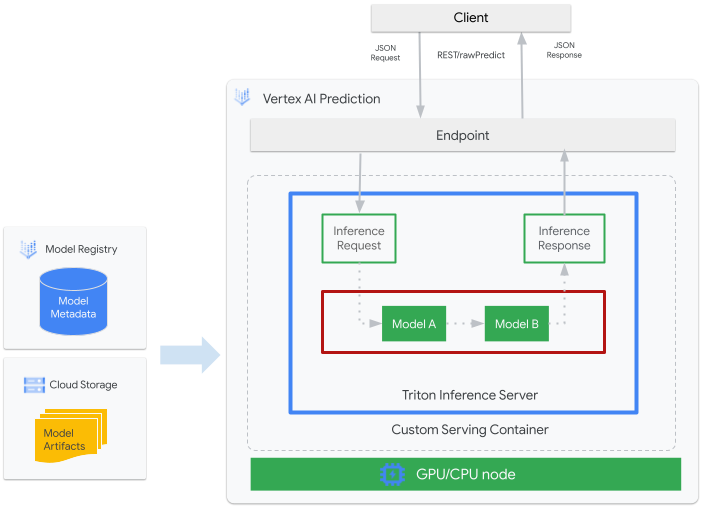
- Un modello di ML da pubblicare con Triton è registrato in Vertex AI Model Registry. I metadati del modello fanno riferimento a una posizione degli artefatti del modello in Cloud Storage, al container di servizio personalizzato e alla relativa configurazione.
- Il modello di Vertex AI Model Registry viene sottoposto a deployment in un endpoint Vertex AI Inference che esegue il server di inferenza Triton come container personalizzato su nodi di computing con CPU e GPU.
- Le richieste di inferenza arrivano al server di inferenza Triton tramite un endpoint Vertex AI Inference e vengono indirizzate allo scheduler appropriato.
- Il backend esegue l'inferenza utilizzando gli input forniti nelle richieste batch e restituisce una risposta.
- Triton fornisce endpoint di controllo dell'integrità di readiness e liveness, che consentono l'integrazione di Triton in ambienti di deployment come Vertex AI.
Questo tutorial mostra come utilizzare un container personalizzato che esegue il server di inferenza NVIDIA Triton per eseguire il deployment di un modello di machine learning (ML) su Vertex AI, che gestisce le inferenze online. Esegui il deployment di un container che esegue Triton per fornire inferenze da un modello di rilevamento di oggetti da TensorFlow Hub che è stato preaddestrato sul set di dati COCO 2017. Puoi quindi utilizzare Vertex AI per rilevare oggetti in un'immagine.
Per eseguire questo tutorial in formato notebook:
Apri in Colab | Apri in Colab Enterprise | Visualizza su GitHub | Apri in Vertex AI Workbench |Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Segui la documentazione di Artifact Registry per installare Docker.
- LOCATION_ID: la regione del repository Artifact Registry, come specificato in una sezione precedente
- PROJECT_ID: l'ID del tuo Google Cloud progetto
Per eseguire l'immagine container in locale, esegui questo comando nella shell:
docker run -t -d -p 8000:8000 --rm \ --name=local_object_detector \ -e AIP_MODE=True \ LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \ --model-repository MODEL_ARTIFACTS_REPOSITORY \ --strict-model-config=falseSostituisci quanto segue, come hai fatto nella sezione precedente:
- LOCATION_ID: la regione del repository Artifact Registry, come specificato in una sezione precedente.
- PROJECT_ID: l'ID del tuo Google Cloud. progetto
- MODEL_ARTIFACTS_REPOSITORY: il percorso Cloud Storage in cui si trovano gli artefatti del modello.
Questo comando esegue un container in modalità detached, mappando la porta
8000del container alla porta8000dell'ambiente locale. L'immagine Triton di NGC configura Triton per utilizzare la porta8000.Per inviare al server del container un controllo di integrità, esegui il seguente comando nella shell:
curl -s -o /dev/null -w "%{http_code}" http://localhost:8000/v2/health/readyIn caso di esito positivo, il server restituisce il codice di stato
200.Esegui questo comando per inviare al server del container una richiesta di inferenza utilizzando il payload generato in precedenza e ottenere risposte di inferenza:
curl -X POST \ -H "Content-Type: application/json" \ -d @instances.json \ localhost:8000/v2/models/object_detector/infer | jq -c '.outputs[] | select(.name == "detection_classes")'Questa richiesta utilizza una delle immagini di test incluse nell'esempio di rilevamento di oggetti TensorFlow.
Se l'operazione ha esito positivo, il server restituisce la seguente inferenza:
{"name":"detection_classes","datatype":"FP32","shape":[1,300],"data":[38,1,...,44]}Per arrestare il container, esegui il seguente comando nella shell:
docker stop local_object_detectorPer concedere all'installazione locale di Docker l'autorizzazione a eseguire il push su Artifact Registry nella regione scelta, esegui questo comando nella shell:
gcloud auth configure-docker LOCATION_ID-docker.pkg.dev- Sostituisci LOCATION_ID con la regione in cui hai creato il repository in una sezione precedente.
Per eseguire il push dell'immagine container appena creata in Artifact Registry, esegui questo comando nella shell:
docker push LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inferenceSostituisci quanto segue, come hai fatto nella sezione precedente:
- LOCATION_ID: la regione del repository Artifact Registry, come specificato in una sezione precedente.
- PROJECT_ID: l'ID del tuo Google Cloud progetto.
- LOCATION_ID: la regione in cui utilizzi Vertex AI.
- PROJECT_ID: l'ID del tuo Google Cloud progetto
-
DEPLOYED_MODEL_NAME: un nome per
DeployedModel. Puoi utilizzare il nome visualizzato diModelanche perDeployedModel. - LOCATION_ID: la regione in cui utilizzi Vertex AI.
- ENDPOINT_NAME: Il nome visualizzato per l'endpoint.
- LOCATION_ID: la regione in cui utilizzi Vertex AI.
- ENDPOINT_NAME: Il nome visualizzato per l'endpoint.
-
DEPLOYED_MODEL_NAME: un nome per
DeployedModel. Puoi utilizzare il nome visualizzato diModelanche perDeployedModel. -
MACHINE_TYPE: (Facoltativo) Le risorse macchina utilizzate per ogni nodo di questo
deployment. L'impostazione predefinita è
n1-standard-2. Scopri di più sui tipi di macchina. - MIN_REPLICA_COUNT: il numero minimo di nodi per questo deployment. Il conteggio di nodi può essere aumentato o diminuito in base al carico di inferenza, fino al numero massimo di nodi e mai al di sotto di questo numero di nodi.
- MAX_REPLICA_COUNT: il numero massimo di nodi per questo deployment. Il conteggio di nodi può essere aumentato o diminuito in base al carico di inferenza, fino a questo numero di nodi e mai al di sotto del numero minimo di nodi.
ACCELERATOR_COUNT: il numero di acceleratori da collegare a ogni macchina che esegue il job. In genere è 1. Se non è specificato, il valore predefinito è 1.
ACCELERATOR_TYPE: gestisci la configurazione dell'acceleratore per il servizio GPU. Quando viene eseguito il deployment di un modello con tipi di macchine Compute Engine, è possibile selezionare anche un acceleratore GPU e specificarne il tipo. Le opzioni sono
nvidia-tesla-a100,nvidia-tesla-p100,nvidia-tesla-p4,nvidia-tesla-t4envidia-tesla-v100.- LOCATION_ID: la regione in cui utilizzi Vertex AI.
- ENDPOINT_NAME: Il nome visualizzato per l'endpoint.
Per annullare il deployment del modello dall'endpoint ed eliminare l'endpoint, esegui questo comando nella shell:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID \ --filter=display_name=ENDPOINT_NAME \ --format="value(name)") DEPLOYED_MODEL_ID=$(gcloud ai endpoints describe $ENDPOINT_ID \ --region=LOCATION_ID \ --format="value(deployedModels.id)") gcloud ai endpoints undeploy-model $ENDPOINT_ID \ --region=LOCATION_ID \ --deployed-model-id=$DEPLOYED_MODEL_ID gcloud ai endpoints delete $ENDPOINT_ID \ --region=LOCATION_ID \ --quietSostituisci LOCATION_ID con la regione in cui hai creato il modello in una sezione precedente.
Per eliminare il modello, esegui questo comando nella shell:
MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID \ --filter=display_name=DEPLOYED_MODEL_NAME \ --format="value(name)") gcloud ai models delete $MODEL_ID \ --region=LOCATION_ID \ --quietSostituisci LOCATION_ID con la regione in cui hai creato il modello in una sezione precedente.
Per eliminare il repository Artifact Registry e l'immagine container al suo interno, esegui questo comando nella shell:
gcloud artifacts repositories delete getting-started-nvidia-triton \ --location=LOCATION_ID \ --quietSostituisci LOCATION_ID con la regione in cui hai creato il repository Artifact Registry in una sezione precedente.
- Il container personalizzato Triton non è compatibile con Vertex Explainable AI o Vertex AI Model Monitoring.
- Per scoprire di più sui pattern di deployment con NVIDIA Triton Inference Server su Vertex AI, consulta i tutorial sui notebook NVIDIA Triton.
Durante questo tutorial, ti consigliamo di utilizzare Cloud Shell per interagire con Google Cloud. Se vuoi utilizzare una shell Bash diversa da Cloud Shell, esegui la seguente configurazione aggiuntiva:
Crea ed esegui il push dell'immagine container
Per utilizzare un container personalizzato, devi specificare un'immagine container Docker che soddisfi i requisiti del container personalizzato. Questa sezione descrive come creare l'immagine container e come eseguirne il push in Artifact Registry.
Scaricare gli artefatti del modello
Gli artefatti del modello sono file creati dall'addestramento ML che puoi utilizzare per pubblicare inferenze. Contengono, come minimo, la struttura e i pesi del modello di ML addestrato. Il formato degli artefatti del modello dipende dal framework ML che utilizzi per l'addestramento.
Per questo tutorial, anziché addestrare un modello da zero, scarica il modello di rilevamento degli oggetti da TensorFlow Hub, che è stato addestrato sul set di dati COCO 2017.
Triton prevede che il
repository di modelli
sia organizzato nella seguente struttura per la pubblicazione
del formato TensorFlow SavedModel:
└── model-repository-path
└── model_name
├── config.pbtxt
└── 1
└── model.savedmodel
└── <saved-model-files>
Il file config.pbtxt descrive la
configurazione del modello
per il modello. Per impostazione predefinita, deve essere fornito il file di configurazione del modello che contiene le impostazioni richieste. Tuttavia, se Triton viene avviato con l'opzione --strict-model-config=false, in alcuni casi la configurazione del modello può essere generata automaticamente da Triton e non deve essere fornita in modo esplicito.
In particolare, i modelli TensorRT, TensorFlow SavedModel e ONNX non richiedono un file di configurazione del modello perché Triton può derivare automaticamente tutte le impostazioni richieste. Tutti gli altri tipi di modelli devono fornire un file di configurazione del modello.
# Download and organize model artifacts according to the Triton model repository spec
mkdir -p models/object_detector/1/model.savedmodel/
curl -L "https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1?tf-hub-format=compressed" | \
tar -zxvC ./models/object_detector/1/model.savedmodel/
ls -ltr ./models/object_detector/1/model.savedmodel/
Dopo aver scaricato il modello localmente, il repository dei modelli verrà organizzato come segue:
./models
└── object_detector
└── 1
└── model.savedmodel
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
Copia gli artefatti del modello in un bucket Cloud Storage
Gli artefatti del modello scaricati, incluso il file di configurazione del modello, vengono inviati a
un bucket Cloud Storage specificato da MODEL_ARTIFACTS_REPOSITORY, che può essere utilizzato
quando crei la risorsa modello Vertex AI.
gcloud storage cp ./models/object_detector MODEL_ARTIFACTS_REPOSITORY/ --recursive
Crea un repository Artifact Registry
Crea un repository Artifact Registry per archiviare l'immagine container che creerai nella sezione successiva.
Abilita il servizio API Artifact Registry per il tuo progetto.
gcloud services enable artifactregistry.googleapis.com
Esegui questo comando nella shell per creare il repository Artifact Registry:
gcloud artifacts repositories create getting-started-nvidia-triton \
--repository-format=docker \
--location=LOCATION_ID \
--description="NVIDIA Triton Docker repository"
Sostituisci LOCATION_ID con la regione in cui Artifact Registry
memorizza l'immagine container. In un secondo momento, devi creare una risorsa modello Vertex AI su un endpoint localizzato che corrisponda a questa regione, quindi scegli una regione in cui Vertex AI ha un endpoint localizzato, ad esempio us-central1.
Al termine dell'operazione, il comando stampa il seguente output:
Created repository [getting-started-nvidia-triton].
Crea l'immagine container
NVIDIA fornisce
immagini Docker
per creare un'immagine container che esegue Triton
e che è in linea con i
requisiti dei container personalizzati di Vertex AI per
la pubblicazione. Puoi estrarre l'immagine utilizzando docker e taggare il percorso di Artifact Registry in cui verrà eseguito il push dell'immagine.
NGC_TRITON_IMAGE_URI="nvcr.io/nvidia/tritonserver:22.01-py3"
docker pull $NGC_TRITON_IMAGE_URI
docker tag $NGC_TRITON_IMAGE_URI LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference
Sostituisci quanto segue:
L'esecuzione del comando potrebbe richiedere diversi minuti.
Prepara il file di payload per testare le richieste di inferenza
Per inviare una richiesta di inferenza al server del container, prepara il payload con un file immagine di esempio che utilizza Python. Esegui il seguente script Python per generare il file di payload:
import json
import requests
# install required packages before running
# pip install pillow numpy --upgrade
from PIL import Image
import numpy as np
# method to generate payload from image url
def generate_payload(image_url):
# download image from url and resize
image_inputs = Image.open(requests.get(image_url, stream=True).raw)
image_inputs = image_inputs.resize((200, 200))
# convert image to numpy array
image_tensor = np.asarray(image_inputs)
# derive image shape
image_shape = [1] + list(image_tensor.shape)
# create payload request
payload = {
"id": "0",
"inputs": [
{
"name": "input_tensor",
"shape": image_shape,
"datatype": "UINT8",
"parameters": {},
"data": image_tensor.tolist(),
}
],
}
# save payload as json file
payload_file = "instances.json"
with open(payload_file, "w") as f:
json.dump(payload, f)
print(f"Payload generated at {payload_file}")
return payload_file
if __name__ == '__main__':
image_url = "https://github.com/tensorflow/models/raw/master/research/object_detection/test_images/image2.jpg"
payload_file = generate_payload(image_url)
Lo script Python genera il payload e stampa la seguente risposta:
Payload generated at instances.json
(Facoltativo) Esegui il container localmente
Prima di eseguire il push dell'immagine container in Artifact Registry per utilizzarla con Vertex AI, puoi eseguirla come container nel tuo ambiente locale per verificare che il server funzioni come previsto:
{kind=link}
Esegui il push dell'immagine container in Artifact Registry
Configura Docker per accedere ad Artifact Registry. Poi esegui il push dell'immagine container nel repository Artifact Registry.
Esegui il deployment del modello
In questa sezione, crei un modello e un endpoint, quindi esegui il deployment del modello nell'endpoint.
crea un modello
Per creare una risorsa Model che utilizza un container personalizzato che esegue
Triton, utilizza il comando gcloud ai models upload.
Prima di creare il modello, leggi
Impostazioni per i container personalizzati
per scoprire se devi specificare i campi facoltativi sharedMemorySizeMb, startupProbe e
healthProbe per il container.
gcloud ai models upload \
--region=LOCATION_ID \
--display-name=DEPLOYED_MODEL_NAME \
--container-image-uri=LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \
--artifact-uri=MODEL_ARTIFACTS_REPOSITORY \
--container-args='--strict-model-config=false'
L'argomento --container-args='--strict-model-config=false' consente
a Triton di generare automaticamente la configurazione del modello.
Creazione di un endpoint
Devi eseguire il deployment del modello in un endpoint prima di poterlo utilizzare per fornire inferenze online. Se esegui il deployment di un modello in un endpoint esistente,
puoi saltare questo passaggio. L'esempio seguente utilizza il
comando gcloud ai endpoints create:
gcloud ai endpoints create \
--region=LOCATION_ID \
--display-name=ENDPOINT_NAME
Sostituisci quanto segue:
La creazione dell'endpoint potrebbe richiedere alcuni secondi.
Esegui il deployment del modello sull'endpoint
Quando l'endpoint è pronto, esegui il deployment del modello sull'endpoint. Quando esegui il deployment di un modello in un endpoint, il servizio associa risorse fisiche al modello che esegue Triton per fornire inferenze online.
L'esempio seguente utilizza il comando gcloud ai endpoints deploy-model per eseguire il deployment di Model in un endpoint che esegue Triton su GPU per accelerare la gestione dell'inferenza e senza dividere il traffico tra più risorse DeployedModel:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID\ --filter=display_name=ENDPOINT_NAME\ --format="value(name)") MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID\ --filter=display_name=DEPLOYED_MODEL_NAME\ --format="value(name)") gcloud ai endpoints deploy-model $ENDPOINT_ID \ --region=LOCATION_ID\ --model=$MODEL_ID \ --display-name=DEPLOYED_MODEL_NAME\ --machine-type=MACHINE_TYPE\ --min-replica-count=MIN_REPLICA_COUNT\ --max-replica-count=MAX_REPLICA_COUNT\ --accelerator=count=ACCELERATOR_COUNT,type=ACCELERATOR_TYPE\ --traffic-split=0=100
Sostituisci quanto segue:
L'interfaccia a riga di comando di Google Cloud potrebbe richiedere alcuni secondi per il deployment del modello sull'endpoint. Quando il modello viene implementato correttamente, questo comando stampa il seguente output:
Deployed a model to the endpoint xxxxx. Id of the deployed model: xxxxx.
Ottenere inferenze online dal modello di cui è stato eseguito il deployment
Per richiamare il modello tramite l'endpoint Vertex AI Inference, formatta
la richiesta di inferenza utilizzando un oggetto JSON di richiesta di inferenza standard
o un oggetto JSON di richiesta di inferenza con un'estensione binaria
e invia una richiesta all'endpoint REST rawPredict
di Vertex AI.
L'esempio seguente utilizza il comando gcloud ai endpoints raw-predict:
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION_ID \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
gcloud ai endpoints raw-predict $ENDPOINT_ID \
--region=LOCATION_ID \
--http-headers=Content-Type=application/json \
--request=@instances.json
Sostituisci quanto segue:
L'endpoint restituisce la seguente risposta per una richiesta valida:
{
"id": "0",
"model_name": "object_detector",
"model_version": "1",
"outputs": [{
"name": "detection_anchor_indices",
"datatype": "FP32",
"shape": [1, 300],
"data": [2.0, 1.0, 0.0, 3.0, 26.0, 11.0, 6.0, 92.0, 76.0, 17.0, 58.0, ...]
}]
}
Esegui la pulizia
Per evitare ulteriori addebiti per Vertex AI e addebiti per Artifact Registry, elimina le Google Cloud risorse che hai creato durante questo tutorial: