Migração da Oracle para BigQuery
Este documento apresenta orientações avançadas sobre como migrar do Oracle para o BigQuery. Ele descreve as diferenças fundacionais da arquitetura e sugere maneiras de migrar de data warehouses e data marts em execução no Oracle RDBMS (incluindo o Exadata) para o BigQuery. Neste documento, você verá detalhes que também se aplicam ao Exadata, ExaCC e Oracle Autonomous Data Warehouse, porque eles usam um software Oracle compatível.
Este documento é destinado a arquitetos corporativos, DBAs, desenvolvedores de aplicativos e profissionais de segurança de TI que querem migrar do Oracle para o BigQuery e resolver desafios técnicos no processo de migração.
Também é possível usar tradução de SQL em lote para migrar os scripts SQL em massa ou a tradução de SQL interativo para traduzir consultas ad hoc. As duas ferramentas na prévia oferecem suporte para Oracle SQL, PL/SQL e Exadata.
Pré-migração
Para garantir uma migração bem-sucedida de data warehouses, comece a planejar sua estratégia de migração antecipadamente, no cronograma do seu projeto. Para informações sobre como planejar sistematicamente seu trabalho de migração, consulte O que e como migrar: o framework de migração.
Planejamento de capacidade do BigQuery
Internamente, a capacidade de análise do BigQuery é medida em slots. Um slot do BigQuery é a unidade reservada de capacidade computacional do Google necessária para executar consultas SQL.
O BigQuery calcula continuamente quantos slots são necessários para as consultas enquanto elas são executadas, mas aloca slots para consultas com base em um programador justo.
É possível escolher entre os seguintes modelos de preços ao planejar a capacidade dos slots do BigQuery:
Preços sob demanda: o BigQuery cobra pelo número de bytes processados (tamanho dos dados) sob demanda, então você paga apenas pelas consultas que executa. Para mais informações sobre como o BigQuery determina o tamanho dos dados, consulte Cálculo do tamanho dos dados. Como os slots determinam a capacidade computacional subjacente, é possível pagar pelo uso do BigQuery de acordo com o número de slots necessários, em vez de por bytes processados. Por padrão, Google Cloud os projetos são limitados a um máximo de 2.000 slots.
Preços baseados em capacidade : com preços baseados em capacidade, você compra reservas de slot do BigQuery (no mínimo 100), em vez de pagar pelos bytes processados pelas consultas executadas. Recomendamos o preço baseado em capacidade para cargas de trabalho de data warehouse corporativas, que geralmente têm várias consultas simultâneas de relatório e de extração-carregamento-transformação (ELT) com consumo previsível.
Para ajudar na estimativa de slots, recomendamos configurar o monitoramento do BigQuery usando o Cloud Monitoring e analisar seus registros de auditoria usando o BigQuery. Muitos clientes usamLooker Studio Por exemplo, veja umaexemplo de código aberto de umPainel do Looker Studio ),Looker ou Tableau como front-ends para visualizar dados de registro de auditoria do BigQuery, especificamente para uso de slots em consultas e projetos. Também é possível aproveitar os dados das tabelas do sistema do BigQuery para monitorar a utilização de slots em jobs e reservas. Consulte um exemplo de código aberto de um painel do Looker Studio.
Monitorar e analisar regularmente a utilização de slots ajuda a estimar o número total de slots de que sua organização precisa à medida que seu uso do Google Cloudaumenta.
Por exemplo, suponha que você reserve inicialmente 4.000 slots do BigQuery para executar 100 consultas de complexidade média simultaneamente. Se você perceber tempos de espera altos nos planos de execução das consultas e seus painéis mostrarem alta utilização de slots, isso pode indicar que você precisa de mais slots do BigQuery para ajudar a dar suporte às cargas de trabalho. Se você quiser comprar slots por conta própria com compromissos anuais ou de três anos, comece a usar as reservas do BigQuery usando o Google Cloud console ou a ferramenta de linha de comando bq.
Se você tiver dúvidas relacionadas ao plano atual e às opções anteriores, fale com seu representante de vendas.
Segurança em Google Cloud
As seções a seguir descrevem controles de segurança comuns do Oracle e como garantir que o data warehouse permaneça protegido em um ambiente Google Cloud.
Identity and Access Management (IAM)
O Oracle fornece usuários, privilégios, papéis e perfis para gerenciar o acesso aos recursos.
O BigQuery usa o IAM para gerenciar o acesso aos recursos e fornece gerenciamento de acesso centralizado a recursos e ações. Os tipos de recursos disponíveis no BigQuery são organizações, projetos, conjuntos de dados, tabelas e visualizações. Na hierarquia de políticas de IAM, conjuntos de dados são recursos filhos de projetos. Uma tabela herda permissões do conjunto de dados que a contém.
Para conceder acesso a um recurso, atribua um ou mais papéis a um usuário, um grupo ou uma conta de serviço. Os papéis de organização e de projeto afetam a capacidade de executar jobs ou gerenciar o projeto. Por outro lado, os papéis de conjunto de dados afetam a capacidade de acessar ou modificar os dados dentro de um projeto.
O IAM fornece estes tipos de papéis:
- O objetivo dos papéis predefinidos é oferecer suporte a casos de uso comuns e padrões de controle de acesso. Os papéis predefinidos fornecem acesso granular a um serviço específico e são gerenciados por Google Cloud.
Papéis básicos incluem os papéis de proprietário, editor e leitor.
Papéis personalizados. Fornecem acesso granular conforme uma lista de permissões especificada pelo usuário.
Quando você atribui papéis predefinidos e básicos a um usuário, as permissões concedidas são uma combinação das permissões de cada papel individual.
Segurança no nível da linha
A Oracle Label Security (OLS) permite a restrição de acesso aos dados linha por linha. Um caso de uso típico para a segurança no nível da linha é restringir o acesso de um vendedor às contas que ele gerencia. Ao implementar a segurança no nível da linha, você tem um controle de acesso refinado.
Para garantir a segurança na linha no BigQuery, use visualizações autorizadas e políticas de acesso na linha. Para mais informações sobre como projetar e implementar essas políticas, consulte Introdução à segurança no nível da linha do BigQuery.
Criptografia de disco completo
A Oracle oferece criptografia de dados transparente (TDE, na sigla em inglês) e criptografia de rede para criptografia de dados em repouso e em trânsito. O TDE exige a opção de Segurança Avançada, licenciada separadamente.
O BigQuery criptografa todos os dados em repouso e em trânsito por padrão, independentemente da origem ou de qualquer outra condição, e isso não pode ser desativado. O BigQuery também oferece suporte a chaves de criptografia gerenciadas pelo cliente (CMEK), se o objetivo é controlar e gerenciar chaves de criptografia no Cloud Key Management Service. Para mais informações sobre a criptografia em Google Cloud, consulte Criptografia padrão em repouso e Criptografia em trânsito.
Mascaramento e edição de dados
O Oracle usa o mascaramento de dados em testes de aplicativos reais e a edição de dados, que permite mascarar (editar) os dados retornados das consultas exibidas pelos aplicativos.
O BigQuery suporta o mascaramento de dados dinâmicos no nível da coluna. É possível usar o mascaramento de dados para ocultar seletivamente dados de coluna para grupos de usuários, sem deixar de permitir o acesso à coluna.
Use a Proteção de dados confidenciais para identificar e editar informações sensíveis de identificação pessoal (PII, na sigla em inglês) no BigQuery.
Comparação entre BigQuery e Oracle
Nesta seção, descrevemos as principais diferenças entre o BigQuery e o Oracle. Esses destaques ajudam você a identificar obstáculos da migração e a planejar as mudanças necessárias.
Arquitetura do sistema
Uma das principais diferenças entre o Oracle e o BigQuery é que o BigQuery é um EDW em nuvem sem servidor com camadas de computação e armazenamento separadas, que podem ser escalonadas com base nas necessidades da consulta. Devido à natureza da oferta sem servidor do BigQuery, você não está limitado a decisões de hardware. é possível solicitar mais recursos para consultas e usuários por reservas. O BigQuery também não requer configuração do software e da infraestrutura subjacentes, como sistema operacional (SO), sistemas de rede e sistemas de armazenamento, incluindo escalonamento e alta disponibilidade. O BigQuery cuida das operações administrativas, de escalonabilidade e gerenciamento. O diagrama a seguir ilustra a hierarquia de armazenamento do BigQuery.
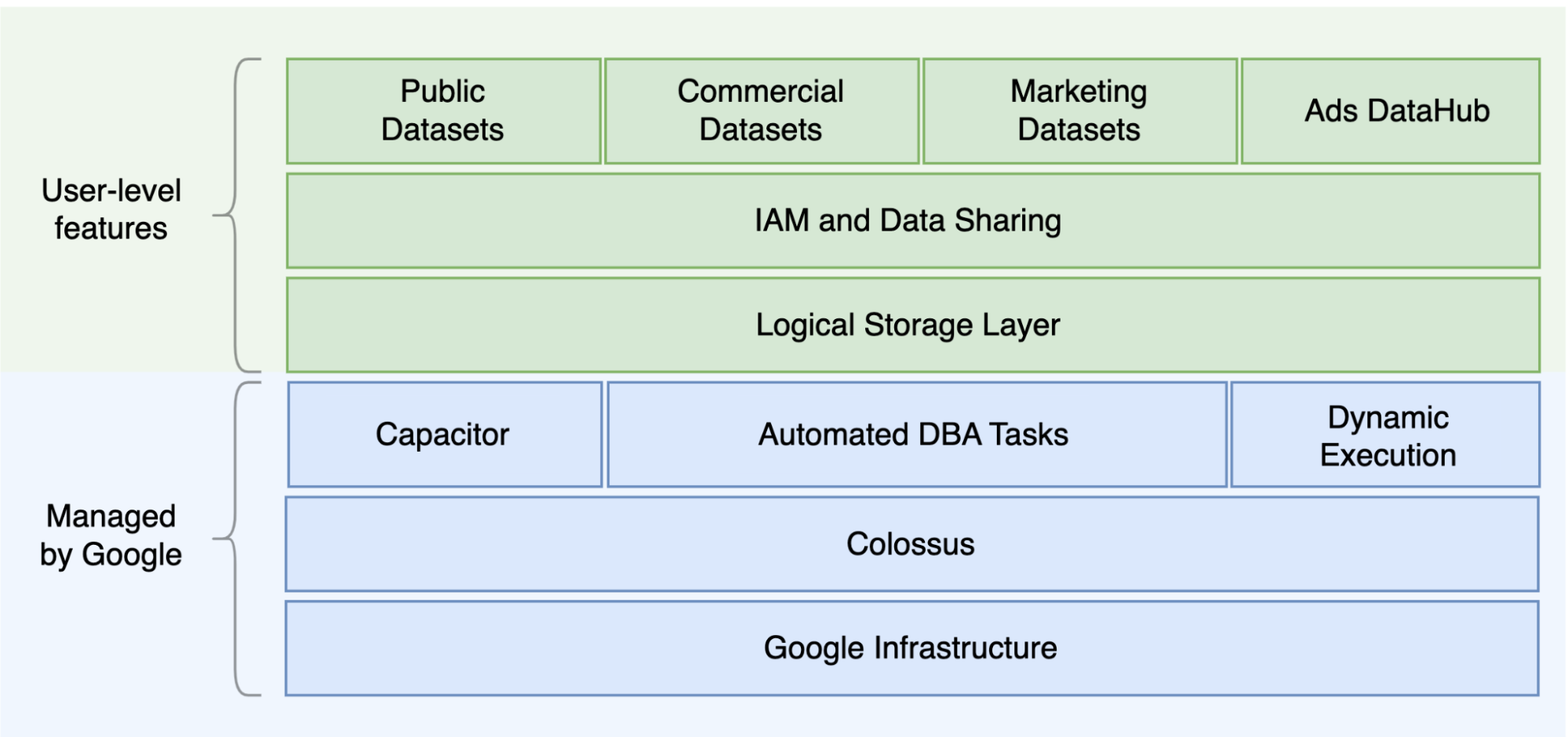
O conhecimento da arquitetura de armazenamento e processamento de consultas, como a separação entre armazenamento (Colossus) e execução de consultas (Dremel) e como oGoogle Cloud aloca recursos (Borg), pode ser útil para entender as diferenças comportamentais e otimizar a performance da consulta e a eficiência em custos. Para mais detalhes, consulte as arquiteturas do sistema de referência do BigQuery, Oracle e Exadata.
Arquitetura de dados e armazenamento
A estrutura de dados e armazenamento é uma parte importante de qualquer sistema de análise de dados, porque afeta o desempenho, o custo, a escalonabilidade e a eficiência da consulta.
O BigQuery desacopla o armazenamento e a computação e armazena dados no Colossus, em que os dados são compactados e armazenados em um formato de colunas chamado Capacitor (em inglês).
O BigQuery opera diretamente em dados compactados sem descompactar usando o Capacitor. O BigQuery fornece conjuntos de dados como a abstração de nível mais alto para organizar o acesso às tabelas, conforme mostrado no diagrama anterior. Esquemas e rótulos podem ser usados para organizar melhor as tabelas. O BigQuery oferece particionamento para melhorar o desempenho e os custos de consultas, além de gerenciar o ciclo de vida das informações. Os recursos de armazenamento são alocados à medida que são utilizados, e dispensados conforme os dados ou as tabelas são removidos.
O Oracle armazena dados em formato de linha usando o formato de bloco Oracle organizado em segmentos. Os esquemas (pertencentes aos usuários) são usados para organizar tabelas e outros objetos do banco de dados. A partir do Oracle 12c, o multilocação é usado para criar bancos de dados conectáveis em uma instância de banco de dados para maior isolamento. O particionamento pode ser usado para melhorar o desempenho da consulta e as operações do ciclo de vida das informações. O Oracle oferece várias opções de armazenamento para bancos de dados autônomos e de clusters reais de aplicativos (RAC) (na sigla em inglês), como ASM, um sistema de arquivos do SO e um sistema de arquivos de cluster.
O Exadata fornece infraestrutura de armazenamento otimizada em servidores de células de armazenamento e permite que servidores Oracle acessem esses dados de maneira transparente utilizando o ASM. O Exadata oferece opções de Compactação de coluna híbrida (HCC, na sigla em inglês) para que os usuários possam compactar tabelas e partições.
O Oracle requer capacidade de armazenamento pré-provisionada, dimensionamento cuidadoso e configurações de incremento automático em segmentos, arquivos de dados e espaços de tabela.
Execução e desempenho da consulta
O BigQuery gerencia o desempenho e escalona no nível da consulta para maximizar o desempenho pelo custo. O BigQuery usa muitas otimizações, por exemplo:
- Execução de consultas na memória
- Arquitetura de árvore de vários níveis com base no mecanismo de execução Dremel
- Otimização automática de armazenamento no Capacitor
- 1 petabit por segundo no total da largura de banda de bissecção com Jupiter
- Escalonamento automático do gerenciamento de recursos para fornecer consultas rápidas em escala de petabytes
O BigQuery coleta estatísticas de colunas ao carregar os dados e inclui informações de diagnóstico do plano de consulta e do tempo. Os recursos de consulta são alocados de acordo com o tipo e a complexidade da consulta. Cada uma usa uma quantidade de slots, que representam unidades de computação que compreendem uma quantidade específica de CPU e RAM.
O Oracle fornece estatísticas de coleta de dados. O otimizador de banco de dados usa estatísticas para fornecer planos de execução ideais. Índices podem ser necessários para pesquisas rápidas de linhas. O Oracle também fornece um armazenamento de colunas na memória para análise na memória. O Exadata fornece várias melhorias de desempenho, como verificação inteligente de célula, índices de armazenamento, cache flash e conexões InfiniBand entre servidores de armazenamento e de banco de dados. Os clusters reais de aplicativos (RAC, na sigla em inglês) podem ser usados para alcançar alta disponibilidade do servidor e escalonar aplicativos com uso intensivo da CPU do banco de dados usando o mesmo armazenamento.
A otimização do desempenho da consulta com o Oracle requer uma consideração cuidadosa dessas opções e parâmetros do banco de dados. A Oracle fornece várias ferramentas, como o Active Session History (ASH), Automatic Database Diagnostic Monitor (ADDM), Auto Workload Repository (AWR), relatórios de monitoramento e ajuste de SQL e Desfazer e ajuste de memória Consultores para ajuste de desempenho.
Análise ágil
No BigQuery, é possível permitir que diferentes projetos, usuários e grupos consultem conjuntos de dados em diferentes projetos. A separação da execução de consultas permite que equipes autônomas trabalhem nos projetos sem afetar outros usuários e projetos, separando cotas de slots e consultando o faturamento de outros e dos projetos que hospedam os conjuntos de dados.
Alta disponibilidade, backups e recuperação de desastres
O Oracle fornece o Data Guard como solução de recuperação de desastres e replicação de bancos de dados. Clusters reais de aplicativos (RAC) pode ser configurado para disponibilidade do servidor. Os backups do Gerenciador de recuperação (RMAN) podem ser configurados para backups de banco de dados e arquivo de registro e também usados para operações de restauração e recuperação. O recurso banco de dados Flashback pode ser usado para flashbacks do banco de dados para retroceder o banco de dados para um ponto específico no tempo. Desfazer "spacespace" armazena snapshots da tabela. É possível consultar snapshots antigos com a consulta de flashback e cláusulas de consulta a partir de, dependendo das operações DML/DDL feitas anteriormente e das configurações de desfazer retenção. No Oracle, toda a integridade do banco de dados precisa ser gerenciada em espaços de tabela que dependem dos metadados do sistema, de desfazer e dos espaços correspondentes, porque a consistência forte é importante para o backup do Oracle, e os procedimentos de recuperação precisam incluir dados principais completos. É possível programar exportações no nível do esquema da tabela se a recuperação pontual não for necessária no Oracle.
O BigQuery é totalmente gerenciado e diferente dos sistemas de banco de dados tradicionais na funcionalidade completa de backup. Não é preciso considerar servidores, falhas de armazenamento, bugs do sistema e corrupções de dados físicos. O BigQuery replica dados em diferentes data centers, dependendo do local do conjunto de dados, para maximizar a confiabilidade e a disponibilidade. A funcionalidade multirregional do BigQuery replica dados em diferentes regiões e protege contra a indisponibilidade de uma única zona dentro da região. A funcionalidade de região única do BigQuery replica dados em diferentes zonas dentro da mesma região.
Com o BigQuery, é possível consultar snapshots históricos de tabelas de até sete dias e restaurar tabelas excluídas em até dois dias usando a viagem no tempo.
Você pode copiar uma tabela excluída
para restaurá-lasintaxe de snapshot (dataset.table@timestamp
exportar dados das tabelas do BigQuery para outras necessidades de backup, como a recuperação de operações acidentais do usuário. Estratégias e programações de backup comprovadas usadas para
sistemas de data warehouse (DWH) existentes podem ser usadas para backups.
As operações em lote e a técnica de snapshots permitem estratégias de backup diferentes para o BigQuery. Por isso, não é necessário exportar tabelas e partições inalteradas com frequência. Um backup de exportação da partição ou da tabela é suficiente após o término da operação de carregamento ou ETL. Para reduzir o custo do backup, é possível armazenar arquivos exportados no Nearline Storage ou no Coldline Storage do Cloud Storage e definir uma política de ciclo de vida para excluir arquivos após um determinado período, dependendo dos requisitos de retenção de dados.
Armazenamento em cache
O BigQuery oferece um cache por usuário. Se os dados não mudarem, os resultados das consultas serão armazenados em cache por aproximadamente 24 horas. Se os resultados forem recuperados do cache, a consulta não terá custos.
O Oracle oferece vários caches para resultados de consultas e dados, como cache de buffer, cache de resultado, cache Flash do Exadata e armazenamento de coluna na memória.
Conexões
O BigQuery lida com o gerenciamento de conexões e não exige que você faça nenhuma configuração do lado do servidor. O BigQuery fornece drivers JDBC e
ODBC. É possível usar o
consoleGoogle Cloud ou o
bq command-line tool para consultas
interativas. É possível usar APIs REST e bibliotecas
de cliente para interagir
programaticamente com o BigQuery. Conecte
as Planilhas Google
diretamente ao BigQuery e use drivers ODBC e JDBC
para se conectar ao Excel. Se você estiver procurando um cliente de desktop, existem ferramentas
gratuitas como o DBeaver.
O Oracle fornece listeners, serviços, gerenciadores de serviço, vários parâmetros de configuração e ajuste e servidores compartilhados e dedicados para gerenciar conexões de banco de dados. A Oracle fornece drivers JDBC, JDBC Thin, ODBC, Oracle Client e TNS. Os listeners de verificação, os endereços IP de verificação e o nome de verificação são necessários para as configurações de RAC.
Preços e licenciamento
O Oracle requer taxas de licença e suporte com base nas contagens principais de edições do Database e opções do Database, como RAC, multilocatário, Proteção de dados ativa, particionamento, na memória, Teste de aplicativo real, GoldenGate e Spatial and Graph.
O BigQuery oferece opções flexíveis de preços com base no uso de armazenamento, consulta e inserção de streaming. O BigQuery oferece preços baseados em capacidade para clientes que precisam de custo e capacidade de slot previsíveis em regiões específicas. Os slots usados para inserções e carregamentos de streaming não são contabilizados na capacidade de slot do projeto. Para decidir quantos slots você quer comprar para o data warehouse, consulte Planejamento de capacidade do BigQuery.
O BigQuery também corta automaticamente os custos pela metade para dados não modificados armazenados por mais de 90 dias.
Rotulação
Conjuntos de dados, tabelas e visualizações do BigQuery podem ser rotulados com pares de chave-valor. Os rótulos podem ser usados para diferenciar custos de armazenamento e estornos internos.
Monitoramento e geração de registros de auditoria
A Oracle oferece diferentes níveis e tipos de opções de auditoria de banco de dados, auditoria de Vault e recursos de firewall de banco de dados, que são licenciadas separadamente. O Oracle fornece o Enterprise Manager para monitoramento de banco de dados.
Para o BigQuery, os registros de auditoria do Cloud são usados para registros de acesso a dados e de auditoria, que são ativados por padrão. Os registros de acesso a dados ficam disponíveis por 30 dias, e os outros eventos de sistema e registros de atividades do administrador ficam disponíveis por 400 dias. Se você precisar de uma retenção mais longa, exporte os registros para o BigQuery, o Cloud Storage ou o Pub/Sub, conforme descrito em Análise de registros de segurança no Google Cloud. Se a integração com uma ferramenta de monitoramento de incidentes existente for necessária, o Pub/Sub poderá ser usado para exportações, e o desenvolvimento personalizado precisará ser feito na ferramenta atual para ler registros do Pub/Sub.
Os registros de auditoria incluem todas as chamadas de API, instruções de consulta e status dos jobs. É possível usar o Cloud Monitoring para monitorar a alocação de slots, bytes verificados em consultas e armazenados, além de outras métricas do BigQuery. O plano de consulta e o cronograma do BigQuery podem ser usados para analisar os estágios e o desempenho da consulta.
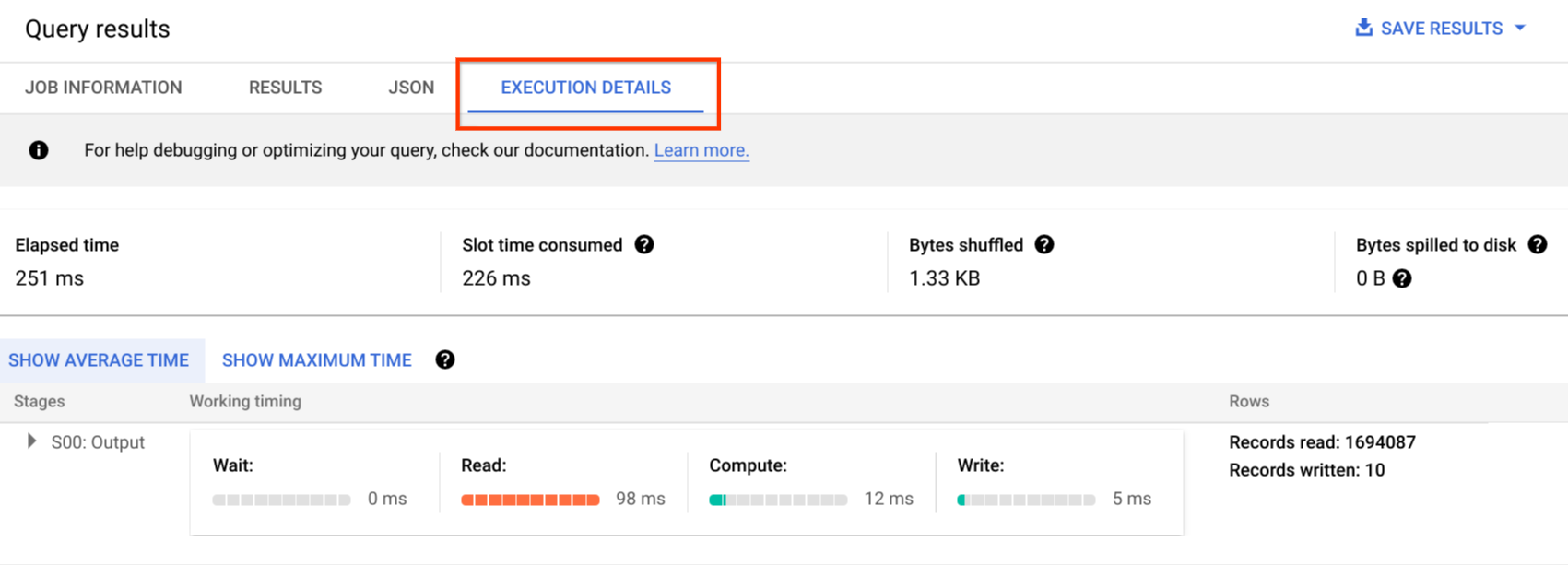
Use a tabela de mensagens de erro para solucionar erros de jobs de consulta e de APIs. Para distinguir alocações de slot por consulta ou job, use esse utilitário, que é útil para clientes que usam preços fixos e têm muitos projetos distribuídos em várias equipes.
Manutenção, upgrades e versões
O BigQuery é um serviço totalmente gerenciado e não requer nenhuma manutenção ou atualização. O BigQuery não oferece versões diferentes. Os upgrades são contínuos e não exigem inatividade nem impedem o desempenho do sistema. Para mais informações, consulte as notas da versão.
O Oracle e o Exadata exigem que você faça patches, upgrades e manutenção no nível do banco de dados e da infraestrutura. Há muitas versões do Oracle, e uma nova versão principal será lançada todos os anos. Embora as novas versões sejam compatíveis com versões anteriores, o desempenho, o contexto e os recursos da consulta podem mudar.
Alguns apps precisam de versões específicas, como 10 g, 11 g ou 12c. Planejamento e testes cuidadosos são necessários para grandes upgrades de banco de dados. A migração de diferentes versões pode incluir diferentes necessidades técnicas de conversão em cláusulas de consulta e objetos de banco de dados.
Cargas de trabalho
O Oracle Exadata é compatível com cargas de trabalho mistas, incluindo OLTP. O BigQuery foi projetado para análise e não para processar cargas de trabalho OLTP. As cargas de trabalho OLTP que usam o mesmo Oracle precisam ser migradas para o Cloud SQL, o Spanner ou o Firestore no Google Cloud. A Oracle oferece outras opções, como análise avançada e recursos espaciais e gráficos. Essas cargas de trabalho podem precisar ser reescritas para migração para o BigQuery. Para mais informações, consulte Como migrar opções do Oracle.
Parâmetros e configurações
A Oracle oferece e requer muitos parâmetros para ser configurado e ajustado nos níveis do Sistema operacional eBanco de dados eRAC eASM e Listener para cargas de trabalho e aplicativos diferentes. O BigQuery é um serviço totalmente gerenciado. Ele não exige a configuração de parâmetros de inicialização.
Limites e cotas
O Oracle tem limites rígidos e flexíveis com base na infraestrutura, na capacidade de hardware, nos parâmetros, nas versões de software e no licenciamento. O BigQuery tem cotas e limites para ações e objetos específicos.
Provisionamento do BigQuery
O BigQuery é uma plataforma como serviço (PaaS) e um data warehouse de processamento em paralelo para a nuvem. A capacidade dela aumenta e diminui sem intervenção do usuário enquanto o Google gerencia o back-end. Como resultado, ao contrário de muitos sistemas RDBMS, o BigQuery não precisa provisionar recursos antes do uso. porque ele aloca dinamicamente armazenamento e recursos de consulta com base nos padrões de uso. Os recursos de armazenamento são alocados à medida que são utilizados, e dispensados conforme os dados ou as tabelas são removidos. Os recursos de consulta são alocados de acordo com o tipo e a complexidade da consulta. Cada consulta usa slots. Um programador de imparcialidade posterior é usado. Portanto, pode haver períodos curtos em que algumas consultas recebem uma parcela maior de slots, mas o programador acaba corrigindo isso.
Em termos de VMs tradicionais, o BigQuery oferece o equivalente a:
- Faturamento por segundo
- escalonamento por segundo.
Para realizar essa tarefa, o BigQuery faz o seguinte:
- Mantém recursos vastos implantados para evitar a necessidade de escalonamento rápido.
- Usa recursos multilocatários para alocar instantaneamente blocos grandes por segundos.
- Aloca recursos entre usuários de maneira eficiente com economias de escalonamento.
- Você paga apenas pelos jobs executados, então pelos recursos implantados. Portanto, você paga pelos recursos que usar.
Para mais informações sobre preços, consulte Noções básicas sobre escalonamento rápido e preços simples do BigQuery.
Migração de esquema..
Para migrar dados do Oracle para o BigQuery, você precisa saber os tipos de dados do Oracle e os mapeamentos do BigQuery.
Tipos de dados do Oracle e mapeamentos do BigQuery
Os tipos de dados do Netezza são diferentes dos tipos de dados do BigQuery. Para mais informações sobre os tipos de dados do BigQuery, consulte a documentação oficial.
Para ver uma comparação detalhada entre os tipos de dados do Oracle e do BigQuery, consulte o guia de tradução do Oracle SQL.
Índices
Em muitas cargas de trabalho analíticas, as tabelas em colunas são usadas em vez de armazenamentos de linhas. Isso aumenta muito as operações baseadas em colunas e elimina o uso de índices para análises em lote. O BigQuery também armazena dados em um formato de coluna, portanto, os índices não são necessários no BigQuery. Se a carga de trabalho de análise exigir um único conjunto de acesso baseado em linhas, o Bigtable pode ser uma alternativa melhor. Se a carga de trabalho exigir o processamento de transações com fortes dependências relacionais, o Spanner ou o Cloud SQL podem ser melhores alternativas.
Em suma, nenhum índice é necessário e oferecido no BigQuery para análise em lote. É possível usar o particionamento ou o clustering. Para mais informações sobre como ajustar e melhorar o desempenho da consulta no BigQuery, consulte Introdução à otimização do desempenho da consulta.
Visualizações
Assim como o Oracle, o BigQuery permite criar visualizações personalizadas. No entanto, as visualizações no BigQuery não são compatíveis com instruções DML.
Visualizações materializadas
As visualizações materializadas são usadas para melhorar o tempo de renderização do relatório em tipos de relatórios e cargas de trabalho de gravação única e várias leituras.
As visualizações materializadas são oferecidas no Oracle para melhorar o desempenho das visualizações. Basta criar e manter uma tabela para armazenar o conjunto de dados de resultados da consulta. Há duas maneiras de atualizar visualizações materializadas no Oracle: sob confirmação e sob demanda.
A funcionalidade de visualização materializada também está disponível no BigQuery. O BigQuery usa os resultados pré-calculados das visualizações materializadas e, sempre que possível, lê só as alterações delta da tabela base para computar resultados atualizados.
As funcionalidades de armazenamento em cache no Looker Studio ou outras ferramentas modernas de BI também podem melhorar o desempenho e eliminar a necessidade de executar novamente a mesma consulta, economizando.
Particionamento de tabelas
O particionamento de tabelas é muito usado em data warehouses da Oracle. Ao contrário do Oracle, o BigQuery não oferece suporte ao particionamento hierárquico.
O BigQuery implementa três tipos de particionamento de tabelas, que permitem que as consultas especifiquem filtros de predicado com base na coluna de particionamento para reduzir a quantidade de dados verificados.
- Tabelas particionadas por tempo de ingestão: particionamento com base no tempo de ingestão de dados.
- Tabelas particionadas por coluna:
particionamento com base em uma coluna
TIMESTAMPouDATE. - Tabelas particionadas por intervalo de números inteiros: particionamento com base em uma coluna de número inteiro.
Para mais informações sobre limites e cotas aplicados a tabelas particionadas no BigQuery, consulte Introdução às tabelas particionadas.
Se as restrições do BigQuery afetarem a funcionalidade do banco de dados migrado, considere o uso da fragmentação em vez do particionamento.
Além disso, o BigQuery não oferece suporte a EXCHANGE PARTITION, SPLIT PARTITION ou conversão de uma tabela não particionada em uma tabela particionada.
Cluster
O clustering ajuda a organizar e recuperar com eficiência os dados armazenados em várias colunas que geralmente são acessadas juntas. No entanto, o Oracle e o BigQuery têm circunstâncias diferentes em que o clustering funciona melhor. No BigQuery, se uma tabela geralmente é filtrada e agregada a colunas específicas, use o clustering. O clustering pode ser considerado para migrar tabelas particionadas por lista ou organizadas por índice do Oracle.
Tabelas temporárias
Tabelas temporárias costumam ser usadas em pipelines ETL da Oracle. Uma tabela temporária contém dados durante uma sessão de usuário. Esses dados são excluídos automaticamente no final da sessão.
O BigQuery usa tabelas temporárias para armazenar em cache os resultados da consulta que não são gravados em uma tabela permanente. Após a conclusão de uma consulta, as tabelas temporárias existem por até 24 horas. As tabelas são criadas em um conjunto de dados especial e nomeadas aleatoriamente. Também é possível criar tabelas temporárias para seu próprio uso. Para mais informações, consulte Tabelas temporárias.
Tabelas externas
Assim como no Oracle, o BigQuery permite consultar fontes de dados externas. O BigQuery oferece suporte para consulta de dados diretamente de fontes de dados externas, incluindo:
- Amazon Simple Storage Service (Amazon S3)
- Armazenamento de blobs do Azure
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google Drive
Modelagem de dados
Modelos de dados em estrela ou floco de neve podem ser eficientes para armazenamento de análise e são geralmente usados para data warehouses no Oracle Exadata.
Tabelas desnormalizadas eliminam operações de mesclagem caras e, na maioria dos casos, oferecem melhor desempenho para análise no BigQuery. Modelos de dados em estrela e floco de neve também são compatíveis com o BigQuery. Para mais detalhes sobre o design de data warehouse no BigQuery, consulte Como projetar um esquema.
Formato de linha x formato de coluna e limites de servidor x sem servidor
O Oracle usa um formato de linha em que a linha da tabela é armazenada em blocos de dados. Portanto, as colunas desnecessárias são buscadas no bloco para consultas analíticas, com base na filtragem e na agregação de colunas específicas.
O Oracle tem uma arquitetura de tudo compartilhado, com dependências fixas de recursos de hardware, como memória e armazenamento, atribuídas ao servidor. Essas são as duas principais forças subjacentes a muitas técnicas de modelagem de dados que evoluíram para melhorar a eficiência do armazenamento e o desempenho de consultas analíticas. Esquemas de estrelas e flocos de neve e modelagem de armazenamento de dados são alguns deles.
O BigQuery usa um formato de colunas para armazenar dados e não tem limites fixos de armazenamento e memória. Essa arquitetura permite desnormalizar e projetar esquemas com base em leituras e necessidades de negócios, reduzindo a complexidade e melhorando a flexibilidade, a escalonabilidade e o desempenho.
Desnormalização
Um dos principais objetivos da normalização de banco de dados relacional é reduzir a redundância de dados. Embora esse modelo seja mais adequado para um banco de dados relacional que usa um formato de linha, a desnormalização de dados é preferível para bancos de dados em colunas. Para saber mais informações sobre as vantagens de desnormalizar dados e outras estratégias de otimização de consulta no BigQuery, consulte Desnormalização.
Técnicas para nivelar o esquema atual
A tecnologia do BigQuery aproveita uma combinação de acesso e processamento de dados em colunas, armazenamento na memória e processamento distribuído para fornecer desempenho de consulta de qualidade.
Ao criar um esquema DWH do BigQuery, criar uma tabela de fatos em uma
estrutura de tabela simples (consolidando todas as tabelas de dimensão em um único
registro na tabela fato) é melhor para o uso do armazenamento do que usar várias
dimensões DWH tabelas. Além de menos uso de armazenamento, ter uma tabela fixa no BigQuery reduz o uso de JOIN. O diagrama a seguir ilustra um exemplo de estabilização do esquema.
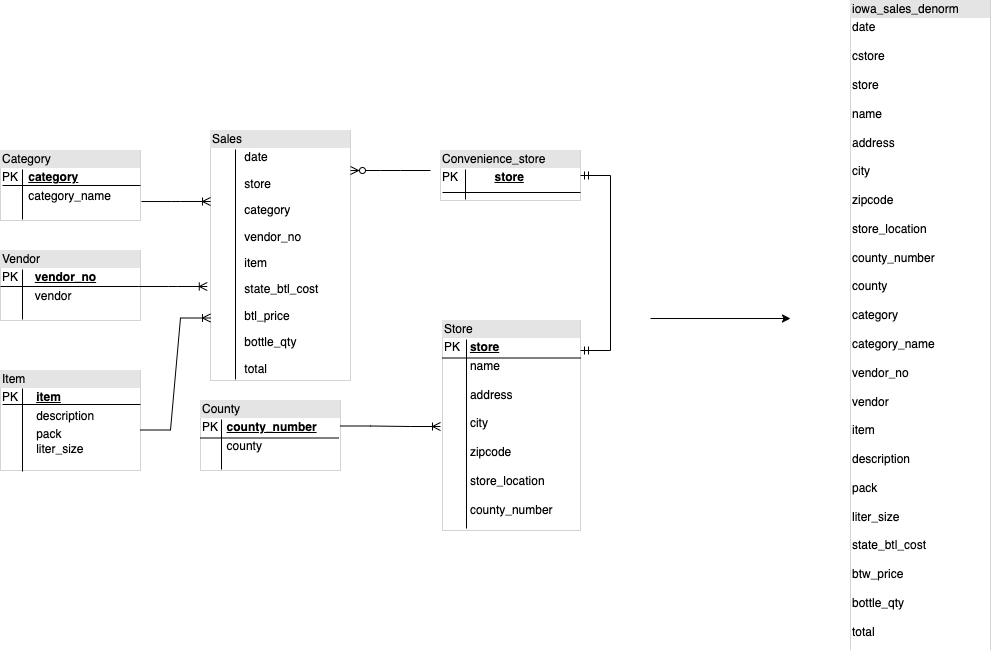
Exemplo de nivelamento de um esquema em estrela
A Figura 1 mostra um banco de dados fictício de gerenciamento de vendas que inclui quatro tabelas:
- Tabela de pedidos/vendas (tabela de fatos)
- Tabela "Employee"
- Tabela de locais
- Tabela de clientes
A chave primária da tabela de vendas é OrderNum, que também contém
chaves estrangeiras para as outras três tabelas.
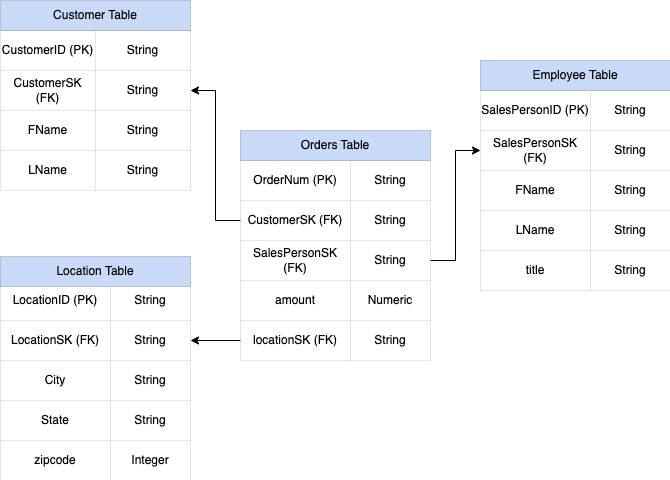
Figura 1: exemplo de dados de vendas em um esquema em estrela
Dados de amostra
Pedidos/conteúdo da tabela de fatos
| Número do pedido | ID do cliente | ID do vendedor | amount | Local |
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14.66 | 18 | |
| O-4 | 4567 | 4 | 182.00 | 26 |
Conteúdo da tabela de funcionários
| ID do vendedor | FName | LName | title |
| 1 | Alex | Smith | Representante de vendas |
| 4 | Lisa | Silva | Representante de vendas |
| 12 | John | Silva | Representante de vendas |
Conteúdo da tabela do cliente
| ID do cliente | FName | LName |
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
Conteúdo da tabela de locais
| Local | cidade | cidade | cidade |
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | Chicago | IL | 60613 |
Consultar para nivelar os dados usando LEFT OUTER JOIN
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
Saída dos dados nivelados
| Número do pedido | ID do cliente | FName | LName | ID do vendedor | FName | LName | amount | Local | cidade | estado oculto final | CEP |
| O-1 | 1234 | Amanda | Léo | 12 | John | Silva | 234.22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192.10 | 27 | Chicago | IL | 60613 |
| O-3 | 12 | John | Silva | 14.66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Silva | 182.00 | 26 | Montanha
Ver |
CA | 90210 |
Campos aninhados e repetidos
Para projetar e criar um esquema DWH a partir de um esquema relacional (por exemplo, esquemas em estrela e floco de neve contendo tabelas de dimensão e fatos), o BigQuery apresenta a funcionalidade de campos aninhados e repetidos. Portanto, as relações podem ser preservadas de maneira semelhante a um esquema de DWH relacional normalizado (ou parcial) sem afetar o desempenho. Para mais informações, consulte as práticas recomendadas de desempenho.
Para entender melhor a implementação de campos aninhados e repetidos, veja um esquema relacional simples de uma tabela CUSTOMERS e uma tabela ORDER/SALES. Elas
são duas tabelas diferentes, uma para cada entidade, e as relações são definidas
usando uma chave como uma primária e uma externa como o link entre as
tabelas enquanto consulta usando JOINs. Com os campos repetidos e aninhados do BigQuery, é possível preservar a mesma relação entre as entidades em uma única tabela. Isso pode ser implementado com todos os dados do cliente, enquanto os dados dos pedidos são aninhados para cada um dos clientes. Para mais informações, consulte Como especificar colunas aninhadas e repetidas.
Para converter a estrutura simples em um esquema aninhado ou repetido, aninhe os campos da seguinte maneira:
CustomerID,FName,LNameaninhados em um novo campo chamadoCustomer.SalesPersonID,FName,LNameaninhados em um novo campo chamadoSalesperson.LocationID,city,state,zip codeaninhados em um novo campo chamadoLocation.
Os campos OrderNum e amount não estão aninhados porque representam elementos
exclusivos.
Você quer tornar o esquema flexível o suficiente para permitir que todos os pedidos tenham mais de um cliente: um primário e um secundário. O campo "Cliente" é marcado como repetido. O esquema resultante é mostrado na Figura 2, que ilustra os campos aninhados e repetidos.
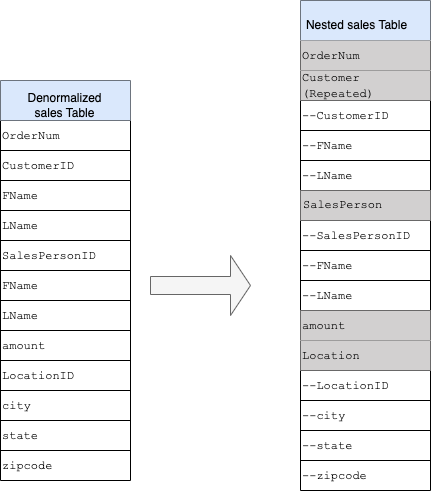
Figura 2: representação lógica de uma estrutura aninhada
Em alguns casos, a desnormalização usando campos aninhados e repetidos não leva a melhorias de desempenho. Para mais informações sobre limitações e restrições, consulte Especificar colunas aninhadas e repetidas em esquemas de tabelas.
Chaves alternativas
É comum identificar linhas com chaves exclusivas nas tabelas. As sequências costumam ser usadas no Oracle para criar essas chaves. No BigQuery, é possível criar chaves substitutas usando as funções row_number e partition by. Para mais informações, consulte BigQuery e
chaves substitutas: uma abordagem
prática.
Acompanhamento de mudanças e histórico
Ao planejar uma migração de DWH do BigQuery, considere o conceito de dimensões com alterações lentas (SCD, na sigla em inglês). Em geral, o termo SCD descreve o processo de alteração (operações DML) nas tabelas de dimensão.
Por vários motivos, os data warehouses tradicionais usam tipos diferentes para processar alterações de dados e manter os dados históricos em dimensões que mudam lentamente. Esses tipos de uso são necessários devido às limitações de hardware e aos requisitos de eficiência discutidos anteriormente. Como o armazenamento é muito mais barato que a computação e infinitamente escalonável, a redundância e a duplicação de dados são incentivadas se isso resultar em consultas mais rápidas no BigQuery. É possível usar técnicas de snapshot de dados em que todos os dados são carregados em novas partições diárias.
Visualizações específicas a funções e usuários
Use visualizações específicas de papéis e usuários quando os usuários pertencerem a equipes diferentes e precisarem ver apenas os registros e resultados necessários.
O BigQuery oferece suporte à coluna e à segurança no nível da linha. A segurança no nível da coluna fornece acesso detalhado a colunas confidenciais usando tags de política ou classificação de dados baseada em tipos. Segurança no nível da linha, que permite filtrar dados e acessar linhas específicas em uma tabela, com base nas condições de qualificação do usuário.
Migração de dados
Nesta seção, fornecemos informações sobre a migração de dados do Oracle para o BigQuery, incluindo carregamento inicial, captura de dados alterados (CDC) e ferramentas e abordagens ETL/ELT.
Atividades de migração
Recomendamos realizar a migração em fases, identificando casos de uso adequados. Há várias ferramentas e serviços disponíveis para migrar dados do Oracle para o Google Cloud. Essa lista não é completa, mas dá uma ideia do tamanho e do escopo da iniciativa de migração.
Como exportar dados do Oracle:para mais informações, consulte Carregamento inicial e CDC e ingestão de streaming do Oracle para o BigQuery. As ferramentas de ETL podem ser usadas para o carregamento inicial.
Preparação de dados (no Cloud Storage): o Cloud Storage é o local de destino recomendado (área de preparo) para dados exportados do Oracle. O Cloud Storage foi projetado para ingestão rápida e flexível de dados estruturados ou não estruturados.
Processo de ETL: para mais informações, consulte Migração ETL/ELT.
Carregamento de dados diretamente no BigQuery: é possível carregar dados no BigQuery diretamente do Cloud Storage, pelo Dataflow ou por streaming em tempo real. Use o Dataflow quando a transformação de dados for necessária.
Carregamento inicial
A migração dos dados iniciais do data warehouse Oracle para o BigQuery pode ser diferente dos pipelines de ETL/ELT incrementais, dependendo do tamanho dos dados e da largura de banda da rede. Os mesmos pipelines ETL/ELT podem ser usados se o tamanho dos dados for de alguns terabytes.
Se os dados chegam a alguns terabytes, o despejo de dados e o uso de gcloud storage
para a transferência podem ser muito mais eficientes do que usar a metodologia de extração de banco de dados
programática semelhante à JdbcIO, porque as abordagens programáticas podem precisar
de um ajuste de desempenho mais granular. Se o tamanho dos dados for de poucos terabytes e
eles estiverem armazenados na nuvem ou em armazenamento on-line (como Amazon Simple Storage Service (Amazon S3)), considere
usar o serviço de transferência de dados do BigQuery. Para transferências em grande escala
(especialmente transferências com largura de banda de rede limitada), o Transfer Appliance
é uma opção útil.
Restrições para o carregamento inicial
Ao planejar a migração de dados, considere o seguinte:
- Tamanho de dados de Oracle DWH: o tamanho de origem do seu esquema tem um peso significativo no método de transferência de dados escolhido, especialmente quando ele é grande (terabytes ou mais). Quando o tamanho dos dados é relativamente pequeno, o processo de transferência de dados pode ser concluído em menos etapas. Lidar com tamanhos de dados de grande escala torna o processo geral mais complexo.
Inatividade: decidir se a inatividade é uma opção para sua migração para o BigQuery é importante. Para reduzir a inatividade, carregue em massa os dados históricos estáveis e tenha uma solução de CDC para acompanhar as alterações que ocorrem durante o processo de transferência.
Preços: em alguns cenários, você precisará de ferramentas de integração de terceiros, como ETL ou replicação, que exigem licenças adicionais.
Transferência de dados inicial (lote)
A transferência de dados usando um método de lote indica que os dados seriam exportados de maneira consistente em um único processo (por exemplo, exportar os dados do esquema Oracle DWH para arquivos CSV, Avro ou Parquet ou importar para o Cloud Storage para criar conjuntos de dados no BigQuery. Todas as ferramentas e conceitos de ETL explicados na migração de ETL/ELT podem ser usados no carregamento inicial.
Se você não quiser usar uma ferramenta ETL/ELT no carregamento inicial, poderá criar
scripts personalizados para exportar dados para arquivos (CSV, Avro ou Parquet) e fazer upload desses
dados para o Cloud Storage usando gcloud storage, o serviço de transferência de dados do BigQuery ou
o Transfer Appliance. Para mais informações sobre como ajustar o desempenho a grandes transferências de dados
e opções de transferência, consulte Como transferir seus grandes
conjuntos de dados. Em seguida, carregue dados do Cloud Storage no BigQuery.
O Cloud Storage é ideal para processar o destino inicial dos dados. Nesse serviço de armazenamento de objetos durável e altamente disponível, não existe limitações quanto ao número de arquivos e você paga apenas pelo armazenamento usado. O serviço é otimizado para funcionar com outros Google Cloud serviços, como o BigQuery e o Dataflow.
CDC e ingestão de streaming do Oracle para o BigQuery
Há várias maneiras de capturar os dados alterados do Oracle. Cada opção tem vantagens, principalmente no impacto no desempenho do sistema de origem, nos requisitos de desenvolvimento e configuração, nos preços e no licenciamento.
CDC baseada em registro
O Oracle GoldenGate é a ferramenta recomendada do Oracle para extrair registros de redo, e você pode usar o GoldenGate for Big Data para transmitir registros para o BigQuery. O GoldenGate requer licenciamento por CPU. Para mais informações sobre o preço, consulte a Lista de preços globais da Oracle. Se estiver disponível, caso as licenças já tenham sido adquiridas, o GoldenGate pode ser uma boa opção para criar pipelines de dados e transferir dados (carregamento inicial) e depois sincronizar toda a modificação de dados.
Oracle XStream
O Oracle armazena todas as confirmações nos arquivos de registros de refazer, que podem ser usados para o CDC. O Oracle XStream Out foi criado com base no LogMiner e fornecido por ferramentas de terceiros, como o Debezium (a partir da versão 0.8), ou com uso comercial usando ferramentas como a Striim. O uso de APIs XStream requer a compra de uma licença para o Oracle GoldenGate, mesmo que o GoldGen não esteja instalado e seja usado. Com o XStream, é possível propagar mensagens do Streams entre o Oracle e outro software de maneira eficiente.
LogMiner do Oracle
Nenhuma licença especial é necessária para LogMiner. Você pode usar a opção LogMiner no conector da comunidade do Debezium. Ele também está disponível comercialmente usando ferramentas como Attunity, Striim ou StreamSets. O LogMiner pode ter algum impacto no desempenho de um banco de dados de origem muito ativo e deve ser usado com cuidado nos casos em que o volume de mudanças (o tamanho da recriação) é maior que 10 GB por hora, dependendo da CPU, memória, capacidade de E/S e utilização do servidor.
CDC baseado em SQL
Essa é a abordagem ETL incremental, em que as consultas SQL consultam continuamente as
tabelas de origem em busca de alterações, dependendo de uma chave monotonicamente crescente e de uma
coluna de carimbo de data/hora que contém a data da última modificação ou inserida. Se não houver
uma chave monotonicamente crescente, usar a coluna de carimbo de data/hora (data modificada) com uma
precisão pequena (segundos) pode causar registros duplicados ou dados perdidos, dependendo
do volume e do operador de comparação, como > ou >=.
Para superar esses problemas, use a precisão mais alta em colunas de carimbo de data/hora, como seis dígitos fracionários (microssegundos, que é a precisão máxima suportada no BigQuery), ou adicionar tarefas de eliminação de duplicação em seu ETL/ELT pipeline, dependendo das chaves de negócios e das características de dados.
É necessário que haja um índice na chave ou na coluna de carimbo de data/hora para melhor desempenho de extração e menos impacto no banco de dados de origem. As operações de exclusão são um
desafio dessa metodologia porque precisam ser processadas no aplicativo de origem
de maneira reversível, como colocar uma sinalização excluída e atualizar
last_modified_date. Uma solução alternativa pode ser registrar essas operações em
outra tabela usando um gatilho.
Gatilhos
Os gatilhos de bancos de dados podem ser criados em tabelas de origem para registrar mudanças em tabelas de diários
sinceros. As tabelas de diário podem conter linhas inteiras para acompanhar cada
alteração de coluna ou só podem manter a chave primária com o tipo de operação
(inserir, atualizar ou excluir). Depois, os dados alterados podem ser capturados com uma abordagem
baseada em SQL, descrita em CDC baseado em SQL. O uso de gatilhos pode
afetar o desempenho da transação e dobrar a latência da operação DML de linha única
se uma linha completa estiver armazenada. Armazenar apenas a chave primária pode reduzir essa sobrecarga, mas, nesse caso, uma operação JOIN com a tabela original é necessária na extração baseada em SQL, que perde a alteração intermediária.
Migração de ETL/ELT
Há muitas possibilidades para lidar com ETL/ELT no Google Cloud. As orientações técnicas sobre conversões de carga de trabalho ETL específicas não estão no escopo deste documento. Considere uma abordagem de migração lift-and-shift ou rearquitete sua plataforma de integração de dados, dependendo de restrições como custo e tempo. Para mais informações sobre como migrar seus pipelines de dados para Google Cloud e muitos outros conceitos de migração, consulte Migrar pipelines de dados.
Abordagem de migração lift-and-shift
Se a plataforma atual for compatível com o BigQuery e você quiser continuar usando a ferramenta de integração de dados:
- É possível manter a plataforma ETL/ELT como está e alterar os estágios de armazenamento necessários com o BigQuery nos jobs ETL/ELT.
- Se você também quiser migrar a plataforma ETL/ELT para Google Cloud , pergunte ao fornecedor se a ferramenta está licenciada no Google Cloud. Se estiver, instale-a no Compute Engine ou verifique no Google Cloud Marketplace.
Para saber mais sobre os provedores de solução de integração de dados, consulte Parceiros do BigQuery.
Como reformular a plataforma ETL/ELT
Se você quiser reformular seus pipelines de dados, recomendamos usar os serviços Google Cloud .
Cloud Data Fusion
O Cloud Data Fusion é um CDAP gerenciado no Google Cloud que oferece uma interface visual com muitos plug-ins para tarefas como desenvolvimento com recurso de arrastar e soltar e pipelines. O Cloud Data Fusion pode ser usado para capturar dados de muitos tipos diferentes de sistemas de origem e oferece recursos de replicação em lote e de streaming. Os plug-ins do Cloud Data Fusion ou do Oracle podem ser usados para capturar dados de um Oracle. Um plug-in do BigQuery pode ser usado para carregar os dados no BigQuery e processar atualizações de esquema.
Nenhum esquema de saída é definido nos plug-ins de origem e de coletor, e
select * from é usado no plug-in de origem para replicar novas colunas.
Use o recurso Wrangle do Cloud Data Fusion para limpeza e preparação de dados.
Dataflow
O Dataflow é uma plataforma de processamento de dados sem servidor que pode fazer o escalonamento automático, assim como o processamento de dados em lote e streaming. O Dataflow pode ser uma boa opção para desenvolvedores Python e Java que querem codificar seus pipelines de dados e usar o mesmo código para cargas de trabalho em lote e de streaming. Use o modelo JDBC para BigQuery para extrair dados do Oracle ou de outros bancos de dados relacionais e carregá-los no BigQuery.
Cloud Composer
O Cloud Composer é Google Cloud um serviço de orquestração de fluxo de trabalho totalmente gerenciado criado no Apache Airflow. Ele permite criar, programar e monitorar pipelines que abrangem vários ambientes de nuvem e data centers no local. O Cloud Composer fornece operadores e contribuições que podem executar tecnologias de várias nuvens em casos de uso, incluindo extração e carregamento e transformações de ELT. e as chamadas da API REST.
O Cloud Composer usa grafos acíclicos dirigidos (DAGs) para programar e organizar fluxos de trabalho. Para entender os conceitos gerais sobre o Airflow, consulte Conceitos do Apache Airflow. Para ver mais informações sobre DAGs, consulte Como escrever DAGs (fluxos de trabalho). Para ver exemplos de práticas recomendadas de ETL com o Apache Airflow, consulte Práticas recomendadas de ETL com o site de documentação do Airflow. Nesse caso, é possível substituir o operador Hive pelo operador do BigQuery, e os mesmos conceitos são aplicáveis.
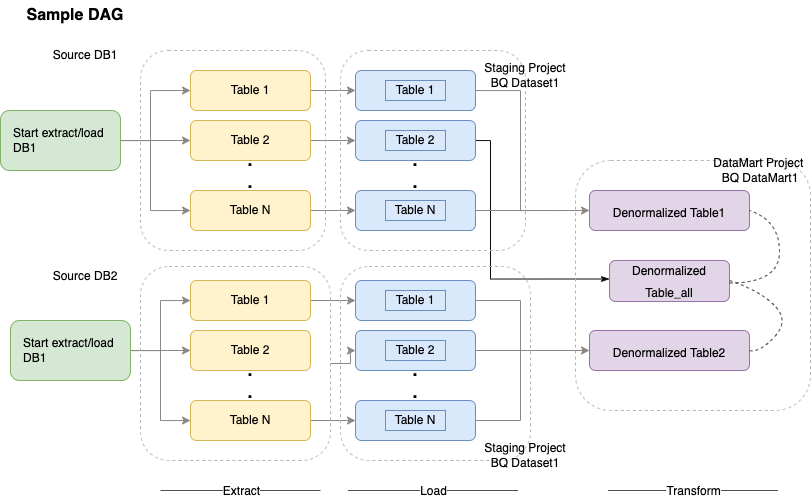
O exemplo de código a seguir é uma parte de alto nível de um DAG de amostra do diagrama anterior:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
O código anterior é fornecido para fins de demonstração e não pode ser usado como está.
Dataprep by Trifacta
O Dataprep é um serviço de dados inteligente para explorar visualmente, limpar e preparar os dados estruturados e não estruturados para análise, geração de relatórios e aprendizado de máquina. Você exporta os dados de origem para arquivos JSON ou CSV, transforma os dados usando o Dataprep e os carrega usando o Dataflow. Por exemplo, consulte Dados do Oracle (ETL) para o BigQuery usando o Dataflow e o Dataprep.
Dataproc
O Dataproc é um serviço Hadoop gerenciado pelo Google. É possível usar o Sqoop para exportar dados do Oracle e de muitos bancos de dados relacionais para o Cloud Storage como arquivos Avro. Depois, é possível carregar arquivos Avro no BigQuery usando a bq tool. É muito comum instalar ferramentas de ETL, como CDAP, no Hadoop que usam JDBC para extrair dados e o Apache Spark ou MapReduce para transformações dos dados.
Ferramentas de parceiros para a migração de dados
Há vários fornecedores no espaço de extração, transformação e carregamento (ETL). Líderes de mercado de ETL, como Informatica, Talend, Matillion, Infoworks, Stitch, Fivetran e Striim, têm uma integração profunda com o BigQuery e o Oracle e podem ajudar a extrair, transformar, carregar dados e gerenciar fluxos de trabalho de processamento.
As ferramentas de ETL existem há muitos anos. Algumas organizações podem achar conveniente aproveitar um investimento atual em scripts ETL confiáveis. Algumas das nossas principais soluções para parceiros estão incluídas no site de parceiros do BigQuery. Saber quando escolher ferramentas de parceiros em vez dos utilitários integrados doGoogle Cloud depende da sua infraestrutura atual e do conforto da equipe de TI com o desenvolvimento de pipelines de dados em código Java ou Python.
Migração da ferramenta Business Intelligence (BI)
O BigQuery é compatível com um pacote flexível de soluções de Business Intelligence (BI) para relatórios e análises que você pode aproveitar. Para mais informações sobre a migração da ferramenta de BI e a integração com o BigQuery, consulte Visão geral da análise do BigQuery.
Conversão de consultas (SQL)
O GoogleSQL do BigQuery está em conformidade com o SQL 2011 padrão e tem extensões compatíveis com a consulta de dados aninhados e repetidos. Todas as funções e operadores SQL compatíveis com as normas ANSI podem ser usados com modificações mínimas. Para uma comparação detalhada entre a sintaxe e as funções SQL do Oracle e do BigQuery, consulte a referência de conversão SQL do Oracle para o BigQuery.
Use a tradução SQL em lote para migrar os códigos SQL em massa ou a tradução de SQL interativo para traduzir consultas ad-hoc.
Como migrar opções da Oracle
Nesta seção, apresentamos recomendações e referências de arquitetura para aplicativos de conversão que usam as funcionalidades de mineração de dados Oracle, R e espacial e de gráfico.
Opção do Oracle Advanced Analytics
A Oracle oferece opções de análises avançadas de mineração de dados, algoritmos fundamentais de machine learning (ML) e uso de R. A opção "Advanced Analytics" requer licenciamento. Escolha uma opção em uma lista abrangente de produtos de IA/ML do Google, dependendo das suas necessidades, desde o desenvolvimento até a produção em escala.
Oracle R Enterprise
O Oracle R Enterprise (ORE), um componente da opção de análise avançada do Oracle, faz com que a linguagem de programação estatística R de código aberto se integre com o Oracle Database. Nas implantações ORE padrão, o R é instalado em um servidor Oracle.
Para escalas muito grandes de dados ou abordagens de armazenamento, a integração do R com o BigQuery é a escolha ideal. É possível usar a biblioteca R bigrquery de código aberto para integrar o R com o BigQuery.
O Google fez uma parceria com o RStudio para disponibilizar as ferramentas de ponta do campo aos usuários. O RStudio pode ser usado para acessar terabytes de dados em modelos do BigQuery Fit no TensorFlow e executar modelos de machine learning em escala com o AI Platform. No Google Cloud, o R pode ser instalado no Compute Engine em escala.
Extração de dados do Oracle
O Oracle Data Mining (ODM), um componente da opção Oracle Advanced Analytics, permite que os desenvolvedores criem modelos de machine learning usando o Oracle PL/SQL Developer no Oracle.
O BigQuery ML permite que os desenvolvedores executem muitos tipos diferentes de modelos, como regressão linear, regressão logística binária, regressão logística multiclasse, clustering k-means e importações de modelos do TensorFlow. Para mais informações, consulte Introdução ao BigQuery ML.
A conversão de jobs de ODM pode exigir a reescrita do código. É possível escolher entre ofertas abrangentes de produtos de IA do Google, como BigQuery ML, APIs de IA (Speech-to-Text, Text-to-Speech, Dialogflow, Cloud Translation, Cloud Natural Language API, Cloud Vision, API SeriesSeries Insights e mais) ou Vertex AI.
O Vertex AI Workbench pode ser usado como um ambiente de desenvolvimento para cientistas de dados, e o Vertex AI Training pode ser usado para executar treinamento e pontuar cargas de trabalho em escala.
Opção espacial e de gráfico
O Oracle oferece a opção de Espacial e de Gráfico para consultar geometria e gráficos e requer licenciamento para essa opção. É possível usar as funções de geometria no BigQuery sem custos extras ou licenças e usar outros bancos de dados gráficos em Google Cloud.
Espacial
O BigQuery oferece funções e tipos de dados de análise geoespacial. Para mais informações, consulte Como trabalhar com dados de análise geoespacial. Os tipos e funções de dados do Oracle Spatial podem ser convertidos em funções geográficas no SQL padrão do BigQuery. As funções geográficas não adicionam custos aos preços padrão do BigQuery.
Gráfico
O JanusGraph é uma solução de banco de dados de gráficos de código aberto que pode usar o Bigtable como um back-end de armazenamento. Para mais informações, consulte Como executar o JanusGraph no GKE com o Bigtable.
O Neo4j é outra solução de banco de dados de gráficos entregue como um Google Cloud serviço executado no Google Kubernetes Engine (GKE).
Aplicativo Oracle Express
Os aplicativos Oracle Express (APEX) são exclusivos da Oracle e precisam ser regravados. As funcionalidades de geração de relatórios e visualização de dados podem ser desenvolvidas usando o Looker Studio ou o mecanismo de BI. Já as funcionalidades no nível do aplicativo, como criar e editar linhas, podem ser desenvolvidas sem programação. no AppSheet usando o Cloud SQL.
A seguir
- Saiba como otimizar cargas de trabalho para otimização geral de desempenho e redução de custos.
- Saiba como otimizar o armazenamento no BigQuery.
- Para atualizações do BigQuery, consulte as notas da versão.
- Consulte o guia de tradução do SQL do Oracle.