Este documento forma parte de una serie que proporciona información y directrices clave relacionadas con la planificación y la realización de migraciones de bases de datos Oracle® 11g/12c a la versión 12 de Cloud SQL para PostgreSQL. Además de la parte de configuración inicial, la serie incluye las siguientes partes:
- Migrar usuarios de Oracle a Cloud SQL para PostgreSQL: terminología y funciones (este documento)
- Migrar usuarios de Oracle a Cloud SQL para PostgreSQL: tipos de datos, usuarios y tablas
- Migrar usuarios de Oracle a Cloud SQL para PostgreSQL: consultas, procedimientos almacenados, funciones y activadores
- Migrar usuarios de Oracle a Cloud SQL para PostgreSQL: seguridad, operaciones, monitorización y registro
- Migrar usuarios y esquemas de bases de datos de Oracle a Cloud SQL para PostgreSQL
Terminología
En esta sección se detallan las similitudes y diferencias en la terminología de las bases de datos entre Oracle y Cloud SQL para PostgreSQL. Revisa y compara los aspectos principales de cada una de las plataformas de bases de datos. La comparación distingue entre las versiones 11g y 12c de Oracle debido a las diferencias arquitectónicas (por ejemplo, Oracle 12c introduce la función de multitenancy). La versión de Cloud SQL para PostgreSQL a la que se hace referencia en este artículo es la 12.
En esta sección se destacan las principales diferencias de terminología entre Oracle y Cloud SQL para PostgreSQL. Más adelante en este documento se ofrece una descripción de bajo nivel.
| Oracle 11g | Descripción | Cloud SQL para PostgreSQL | Diferencias principales |
|---|---|---|---|
| instancia | Una sola instancia de Oracle 11g solo puede contener una base de datos. | instancia | Una instancia de Cloud SQL para PostgreSQL contiene exactamente un clúster de bases de datos. Un clúster de bases de datos es un conjunto de bases de datos que se almacena en un área de datos común. |
| base de datos | Una base de datos se considera una sola instancia (el nombre de la base de datos es idéntico al nombre de la instancia). | base de datos | Varias bases de datos o una sola sirven a varias aplicaciones. |
| esquema | El esquema y los usuarios son idénticos porque ambos se consideran propietarios de objetos de la base de datos (se puede crear un usuario sin especificar o asignar un esquema). | esquema | Una base de datos contiene uno o varios esquemas. Los objetos, como las tablas, se encuentran en los esquemas. Se puede usar el mismo nombre de objeto en diferentes esquemas de la misma base de datos sin que haya conflictos. |
| usuario | Es idéntico al esquema, ya que ambos son propietarios de objetos de base de datos. Por ejemplo, instancia → base de datos → esquemas/usuarios → objetos de base de datos. | rol | Un rol puede ser un usuario de la base de datos o un grupo de usuarios de la base de datos, según cómo se configure. Puede ser propietario de objetos de base de datos, como tablas.
Los roles se limitan a todo un clúster de bases de datos y se puede conceder la pertenencia de un rol a otro. |
| rol | Conjunto definido de permisos de base de datos que se pueden encadenar como un grupo y que se pueden asignar a usuarios de la base de datos. | ||
| admin/ Usuarios de SYSTEM |
Usuarios administradores de Oracle con el nivel de acceso más alto:SYS
|
cloudsqlsuperuser | Cloud SQL para PostgreSQL incluye el postgres
usuario predeterminado. Este usuario tiene el rol cloudsqlsuperuser y los siguientes atributos (privilegios): CREATEROLE, CREATEDB y LOGIN. Como Cloud SQL para PostgreSQL es un servicio gestionado, restringe el acceso a ciertos procedimientos y tablas del sistema que requieren privilegios avanzados. Por lo tanto, el usuario postgres no tiene los atributos SUPERUSER ni REPLICATION. No puedes crear ni acceder a usuarios con atributos de superuser. |
| dictionary/ metadata |
Oracle usa las siguientes tablas de metadatos:USER_TableName
|
dictionary/ metadata |
Cloud SQL para PostgreSQL usa el estándar ANSI INFORMATION_SCHEMA para proporcionar información de diccionario y metadatos. |
| Vistas dinámicas del sistema | Vistas dinámicas de Oracle:V$ViewName |
sistema vistas dinámicas |
Cloud SQL para PostgreSQL tiene las siguientes vistas de estadísticas dinámicas:pg_stat_ViewNamepg_statio_ViewName |
| tablespace | Las estructuras de almacenamiento lógicas principales de las bases de datos de Oracle. Cada tablespace puede contener uno o varios archivos de datos. | tablespace | En Cloud SQL para PostgreSQL, los archivos de datos se almacenan juntos en el directorio de datos de un clúster de bases de datos PGDATA mediante una estructura de directorios predefinida. Los espacios de tablas de Cloud SQL para PostgreSQL proporcionan un mecanismo para definir ubicaciones personalizadas en el sistema de archivos donde se pueden almacenar los archivos de datos.Como Cloud SQL para PostgreSQL es un servicio gestionado, Google Cloud gestiona el sistema de archivos subyacente de la máquina host por ti. No puedes crear espacios de tablas en Cloud SQL para PostgreSQL. |
| archivos de datos | Los elementos físicos de una base de datos de Oracle que contienen los datos y se definen en un tablespace específico. Un archivo de datos se define por el tamaño inicial y el tamaño máximo, y puede contener datos de varias tablas. Los archivos de datos de Oracle usan el sufijo .dbf (no es obligatorio). |
archivos de datos | Cloud SQL para PostgreSQL almacena cada base de datos en un clúster de bases de datos en su propio subdirectorio. Cada tabla e índice de una base de datos se almacena en un archivo independiente de ese subdirectorio. |
| tablespace del sistema | Contiene las tablas del diccionario de datos y los objetos de vistas de toda la base de datos de Oracle. | No existe | Las tablas y los objetos de vistas del diccionario de datos se almacenan en INFORMATION_SCHEMAPGDATA en el directorio de datos de un clúster de bases de datos mediante una estructura de directorios predefinida. |
| espacio de tablas temporal | Contiene objetos de esquema válidos durante una sesión. Además, admite operaciones que no caben en la memoria del servidor. |
archivos temporales | Los archivos temporales se usan para almacenar operaciones en curso que no caben en la memoria del servidor. Estos archivos se almacenan en un directorio llamado
pgsql_tmp y se crean solo mientras se ejecuta la instrucción SQL. |
| Espacio de tabla de deshacer | Un tipo especial de tablespace permanente del sistema que usa Oracle para gestionar las operaciones de rollback cuando la base de datos se ejecuta en el modo de gestión automática de deshacer (predeterminado). |
No existe | Para permitir las operaciones de reversión, Cloud SQL para PostgreSQL conserva las filas que se actualizan o eliminan en el propio archivo de datos de la tabla. El vaciado es el proceso de recuperar o reutilizar el espacio en disco ocupado por filas actualizadas o eliminadas. |
| ASM | Oracle Automatic Storage Management es un sistema de archivos de base de datos integrado y de alto rendimiento, así como un gestor de discos que se realiza automáticamente mediante una base de datos de Oracle configurada con ASM. | No se admite | Cloud SQL para PostgreSQL se basa en el sistema de archivos del SO para almacenar archivos de datos y no tiene un equivalente de Oracle ASM. Sin embargo, Cloud SQL para PostgreSQL admite muchas funciones que proporcionan automatización del almacenamiento, como el aumento automático del almacenamiento, el rendimiento y la escalabilidad. |
| tablas o vistas | Objetos de base de datos fundamentales creados por el usuario. | tablas o vistas | Idéntico a Oracle. |
| Vistas materializadas | Se definen con declaraciones SQL específicas y se pueden actualizar manualmente o automáticamente en función de configuraciones concretas. |
Vistas materializadas | Las vistas materializadas funcionan de forma similar a Oracle. Se actualizan manualmente
mediante instrucciones REFRESH
MATERIALIZED VIEW. |
| sequence | Generador de valores únicos de Oracle. | sequence | Similar a Oracle. |
| sinónimo | Objetos de base de datos de Oracle que sirven como identificadores alternativos de otros objetos de base de datos. | No se admite | Cloud SQL para PostgreSQL no ofrece sinónimos. Como solución alternativa, se pueden usar vistas al configurar los permisos adecuados. |
| partición | Oracle ofrece muchas soluciones de partición para dividir tablas grandes en partes gestionadas más pequeñas. | partición | Cloud SQL para PostgreSQL admite tanto la partición declarativa de estilo Oracle como la partición mediante herencia, lo que permite una mayor flexibilidad en la partición. |
| Base de datos Flashback | Función propietaria de Oracle que se puede usar para inicializar una base de datos de Oracle en un momento definido anteriormente, lo que te permite consultar o restaurar datos que se hayan modificado o dañado por error. | No se admite | Como alternativa, puedes usar las copias de seguridad de Cloud SQL y la recuperación a un momento dado para restaurar una base de datos a un estado anterior (por ejemplo, restaurarla antes de que se eliminara una tabla). |
| sqlplus | Interfaz de línea de comandos de Oracle que te permite consultar y gestionar la instancia de la base de datos. | psql | Interfaz de línea de comandos equivalente a Cloud SQL para PostgreSQL para consultar y gestionar. Se puede conectar desde cualquier cliente con los permisos adecuados para Cloud SQL. |
| PL/SQL | Lenguaje procedimental ampliado de Oracle a ANSI SQL. | PL/pgSQL | Cloud SQL para PostgreSQL tiene su propio lenguaje de procedimiento, llamado PL/pgSQL, que es similar a PL/SQL de Oracle en muchos aspectos. Para ver un resumen de las principales diferencias entre los dos lenguajes, consulta Portar desde Oracle PL/SQL. |
| paquete y cuerpo del paquete | Funcionalidad específica de Oracle para agrupar procedimientos y funciones almacenados en la misma referencia lógica. | No compatible | Cloud SQL para PostgreSQL organiza las funciones mediante esquemas. |
| Procedimientos y funciones almacenados | Usa PL/SQL para implementar la funcionalidad del código. | Procedimientos y funciones almacenados | Cloud SQL para PostgreSQL admite la implementación de procedimientos y funciones almacenados mediante varios lenguajes de programación, como PL/pgSQL y C. |
| activador | Objeto de Oracle que se usa para controlar la implementación de DML en las tablas. | activador | Similar a Oracle. |
| PFILE/SPFILE | Los parámetros de nivel de instancia y de base de datos de Oracle se conservan en un archivo binario conocido como SPFILE (en versiones anteriores, el archivo se llamaba PFILE), que se puede usar como archivo de texto para definir parámetros manualmente. |
Marcas de base de datos de Cloud SQL para PostgreSQL | Puedes definir o modificar los parámetros de Cloud SQL para PostgreSQL mediante la utilidad marcas de bases de datos. |
| SGA/PGA/ AMM |
Parámetros de memoria de Oracle que controlan la asignación de memoria a la instancia de la base de datos. | Varios parámetros relacionados con la memoria | Cloud SQL para PostgreSQL tiene sus propios parámetros de memoria. Otros parámetros similares son shared_buffers, temp_buffers y work_mem. En Cloud SQL para PostgreSQL, estos parámetros están predefinidos por el tipo de instancia elegido y el valor cambia en consecuencia. Puede ajustar algunos de estos parámetros mediante la utilidad de marcas de bases de datos. |
| caché de búfer | Reduce las operaciones de E/S de SQL al recuperar datos almacenados en caché de la caché de búfer. Los parámetros de memoria se pueden gestionar a nivel de base de datos y de sesión mediante sugerencias de consulta. | Funciones similares | El tamaño de la caché de búfer de Cloud SQL para PostgreSQL se controla mediante el parámetro shared_buffer, que no se expone en Cloud SQL. Cloud SQL proporciona una métrica de uso de memoria, que se utiliza para dimensionar correctamente la instancia. |
| sugerencias de bases de datos | Capacidad de Oracle para proporcionar un impacto controlado en las instrucciones SQL que influyan en el comportamiento del optimizador para obtener un mejor rendimiento. Oracle tiene más de 50 sugerencias de bases de datos diferentes. | No se admite | Cloud SQL para PostgreSQL no admite sugerencias de bases de datos. Puedes controlar el planificador de consultas de Cloud SQL para PostgreSQL hasta cierto punto mediante la sintaxis JOIN explícita. |
| RMAN | Utilidad Recovery Manager de Oracle. Se usa para crear copias de seguridad de bases de datos con funciones ampliadas para admitir varios escenarios de recuperación tras desastres y más (clonación, etc.). | Copia de seguridad de Cloud SQL para PostgreSQL | Cloud SQL para PostgreSQL ofrece dos métodos para aplicar copias de seguridad completas: copias de seguridad bajo demanda y automáticas. |
| Data Pump (EXPDP/ IMPDP) |
Utilidad de generación de volcado de Oracle que se puede usar para muchas funciones, como la exportación o importación, la copia de seguridad de bases de datos (a nivel de esquema u objeto), los metadatos de esquemas, la generación de archivos SQL de esquemas y más. | Exportación e importación de Cloud SQL para PostgreSQL | Cloud SQL para PostgreSQL ofrece dos formatos de exportación e importación a y desde los contenedores de Cloud Storage: SQL y CSV. También puedes conectarte a la instancia de base de datos mediante utilidades de exportación o importación, como pg_dump. |
| SQL*Loader | Herramienta que te permite subir datos de archivos externos, como archivos de texto, archivos CSV y más. | psql \copy |
El comando \copy
del cliente psql te permite cargar archivos de texto, CSV o binarios (Oracle admite otros formatos de archivo) en una tabla de base de datos con una estructura correspondiente. |
| Data Guard | Solución de recuperación ante desastres de Oracle que usa una instancia de espera, lo que permite a los usuarios realizar operaciones READ desde la instancia de espera. |
Alta disponibilidad y replicación de Cloud SQL para PostgreSQL | Para conseguir la recuperación tras fallos o la alta disponibilidad, Cloud SQL para PostgreSQL ofrece la arquitectura de réplica de failover y, para las operaciones de solo lectura (separación READ/WRITE), la réplica de lectura. |
| Active Data Guard/ GoldenGate |
Las principales soluciones de replicación de Oracle, que pueden servir para varios propósitos, como la instancia de espera (recuperación ante desastres), la instancia de solo lectura, la replicación bidireccional (multimaestro) y el almacenamiento de datos, entre otros. | Réplica de lectura de Cloud SQL para PostgreSQL | Cloud SQL para PostgreSQL Réplica de lectura para implementar la agrupación en clústeres con separación de lectura y escritura. Actualmente, no se admite la configuración multimaestro, como la replicación bidireccional de GoldenGate o la replicación heterogénea. |
| RAC | Oracle Real Application Cluster. Solución de clustering propiedad de Oracle para proporcionar alta disponibilidad mediante el despliegue de varias instancias de base de datos con una sola unidad de almacenamiento. | No se admite | Cloud SQL para PostgreSQL no admite una arquitectura multimaestro. Cloud SQL para PostgreSQL ofrece alta disponibilidad a través de una instancia de espera y mayor escalabilidad de lectura mediante réplicas de lectura. |
| Control de la red o de la nube (OEM) | Software de Oracle para gestionar y monitorizar bases de datos y otros servicios relacionados en formato de aplicación web. Esta herramienta es útil para analizar bases de datos en tiempo real y comprender cargas de trabajo elevadas. | Google Cloud consola, Cloud Monitoring |
Usa Cloud SQL para PostgreSQL para monitorizar, incluidos gráficos detallados basados en el tiempo y los recursos. También puedes usar Cloud Monitoring para conservar métricas de monitorización específicas de Cloud SQL para PostgreSQL y análisis de registros para disfrutar de funciones de monitorización avanzadas. |
| Registros de rehacer | Registros de transacciones de Oracle que constan de dos o más archivos definidos preasignados que almacenan todas las modificaciones de datos a medida que se producen. El objetivo principal del registro de rehacer es proteger la base de datos en caso de que se produzca un fallo en la instancia. | Registros WAL | Cloud SQL para PostgreSQL usa Write-Ahead Logging (WAL) para que los cambios en los archivos de datos se guarden en el almacenamiento permanente y se pueda recuperar el sistema tras un fallo. |
| archivar registros | Los registros de archivo admiten operaciones de copia de seguridad y replicación, entre otras. Oracle escribe en los registros de archivo (si están habilitados) después de cada operación de cambio de registro de rehacer. | Archivado de WAL | Implementación de Cloud SQL para PostgreSQL de la conservación de registros WAL. El archivado de WAL se usa y se habilita con la recuperación a un momento dado. |
| archivo de control | El archivo de control de Oracle contiene información sobre la base de datos, como los archivos de datos, los nombres y las ubicaciones de los archivos de registro de rehacer, el número de secuencia de registro actual e información sobre el punto de comprobación de la instancia. | PGDATA and pg_control
|
La arquitectura de Cloud SQL para PostgreSQL no comparte un concepto equivalente a un archivo de control de Oracle. Los archivos relacionados con la base de datos se organizan en un directorio que suele denominarse PGDATA. La información de WAL relacionada con los registros y los puntos de control se almacena en pg_control. |
| Número de cambio del sistema (SCN) | El SCN marca un momento específico en una base de datos Oracle. | Número de secuencia de registro (LSN) | El equivalente de Cloud SQL para PostgreSQL es el LSN. Al igual que los SCNs, los LSNs aumentan de forma monótona con el tiempo. |
| AWR | Oracle AWR (Automatic Workload Repository) es un informe detallado que proporciona información sobre el rendimiento de la instancia de la base de datos de Oracle y se considera una herramienta de administrador de bases de datos para el diagnóstico del rendimiento. | Recopilador de estadísticas | Cloud SQL para PostgreSQL no tiene un informe equivalente a Oracle AWR, pero PostgreSQL recoge los datos de rendimiento recogidos por el recogedor de estadísticas. Las estadísticas recogidas se muestran en las vistas pg_stat_* y pg_statio_*. |
DBMS_SCHEDULER
|
Utilidad de Oracle que se usa para definir y programar operaciones predefinidas. | No se admite | Cloud SQL para PostgreSQL no proporciona una utilidad de programación integrada. Google Cloud proporciona Cloud Scheduler, que te permite programar tareas de bases de datos, como las exportaciones. |
| Cifrado de datos transparente | Cifra los datos almacenados en discos para protegerlos en reposo. | Estándar de cifrado avanzado de Cloud SQL | Cloud SQL para PostgreSQL usa el estándar de cifrado avanzado (AES-256) de 256 bits para proteger los datos en reposo y en tránsito. |
| Compresión avanzada | Para mejorar la huella de almacenamiento de la base de datos, reducir los costes de almacenamiento y mejorar el rendimiento de la base de datos, Oracle ofrece funciones de compresión avanzada de datos (tablas o índices). | TOAST | Aunque no se puede comparar directamente con la compresión avanzada de Oracle, Cloud SQL para PostgreSQL usa una infraestructura llamada TOAST para comprimir de forma automática y transparente los datos de longitud variable que son demasiado grandes para caber en una sola página de datos. |
| SQL Developer | GUI de SQL gratuita de Oracle para gestionar y ejecutar instrucciones de SQL y PL/SQL. | pgAdmin | GUI de SQL gratuita de Cloud SQL para PostgreSQL para gestionar y ejecutar instrucciones de código SQL y PostgreSQL. |
| Registro de alertas | Registro principal de Oracle para operaciones y errores generales de la base de datos. | Informes de errores y registros de PostgreSQL | Usa el visor de registros de Cloud Logging para inspeccionar los registros de errores de PostgreSQL. |
| Tabla DUAL | Tabla especial de Oracle para obtener valores de pseudocolumnas, como SYSDATE o USER. |
No existe | Cloud SQL para PostgreSQL permite omitir las cláusulas FROM de las instrucciones SQL. Por ejemplo:SELECT NOW();
es una instrucción válida en PostgreSQL. |
| tabla externa | Oracle permite a los usuarios crear tablas externas con los datos de origen en archivos fuera de la base de datos. | No se admite | Como servicio gestionado, Cloud SQL para PostgreSQL no expone el sistema de archivos subyacente del host que ejecuta la instancia de base de datos. Como solución alternativa, puedes importar los datos de origen en una tabla de PostgreSQL para consultar los datos. |
| Listener | Proceso de red de Oracle encargado de escuchar las conexiones de bases de datos entrantes. | Redes autorizadas de Cloud SQL | Cloud SQL para PostgreSQL acepta conexiones de fuentes remotas una vez que se han permitido en la página de configuración redes autorizadas de Cloud SQL. |
| TNSNAMES | Archivo de configuración de red de Oracle que define las direcciones de la base de datos para establecer conexiones mediante alias de conexión. | No existe | Cloud SQL para PostgreSQL acepta conexiones externas mediante el nombre de conexión de la instancia de Cloud SQL o la dirección IP privada o pública. Proxy de Cloud SQL es un método de acceso seguro adicional para conectarse a Cloud SQL para PostgreSQL sin tener que permitir direcciones IP específicas ni configurar SSL. |
| Puerto predeterminado de la instancia | 1521 | Puerto predeterminado de la instancia | 5432 |
| Enlace de base de datos | Objetos de esquema de Oracle que se pueden usar para interactuar con objetos de bases de datos locales o remotos. | Envoltorio de datos externos (FDW) | La extensión postgres_fdw de Cloud SQL para PostgreSQL permite que las tablas de otras bases de datos PostgreSQL ("externas") se expongan como tablas "externas" en la base de datos actual. Estas tablas se pueden usar casi como si fueran tablas locales. |
Diferencias en la terminología entre Oracle 12c y Cloud SQL para PostgreSQL
| Oracle 12c | Descripción | Cloud SQL para PostgreSQL | Diferencias principales |
|---|---|---|---|
| Instancia | La función multiinquilino introducida en Oracle 12c permite que una instancia contenga varias bases de datos como bases de datos conectables (PDBs), a diferencia de Oracle 11g, donde una instancia de Oracle puede alojar una sola base de datos. | Instancia | Una instancia de Cloud SQL para PostgreSQL contiene exactamente un clúster de bases de datos. Un clúster de bases de datos es una colección de bases de datos que se almacena en un área de datos común. |
| CDB | Una base de datos de contenedor multiinquilino (CDB) puede admitir una o varias PDBs, mientras que se pueden crear objetos globales de CDB (que afectan a todas las PDBs), como los roles. | Instancia de PostgreSQL | La instancia de Cloud SQL para PostgreSQL es comparable a la CDB de Oracle. Ambos proporcionan una capa de sistema para las bases de datos alojadas. |
| PDB | Las PDBs (bases de datos conectables) se pueden usar para aislar servicios y aplicaciones entre sí, así como para crear colecciones portátiles de esquemas. | Bases de datos de PostgreSQL/ esquemas |
Una base de datos de Cloud SQL para PostgreSQL puede dar servicio a varias aplicaciones y servicios, así como a muchos usuarios de bases de datos. |
| Secuencias de sesión | A partir de Oracle 12c, las secuencias se pueden crear a nivel de sesión (devuelven valores únicos solo dentro de una sesión) o a nivel global (por ejemplo, al usar tablas temporales). | Secuencia temporal | Se crea una secuencia temporal para la sesión de base de datos actual y se elimina automáticamente al salir de la sesión. |
| Columnas de identidad | El tipo IDENTITY de Oracle 12c genera una secuencia y la asocia a una columna de tabla sin necesidad de crear manualmente un objeto de secuencia independiente. |
Columna SERIAL | Si defines el tipo de datos de una columna como SERIAL, Cloud SQL para PostgreSQL crea automáticamente una secuencia y rellena el valor de la columna con esa secuencia cuando se insertan filas nuevas en la tabla. |
| Fragmentación | El particionamiento de Oracle es una solución en la que una base de datos de Oracle se divide en varias bases de datos más pequeñas (particiones) para permitir la escalabilidad, la disponibilidad y la distribución geográfica en entornos OLTP. | No disponible (como función) | Cloud SQL para PostgreSQL no tiene una función de partición equivalente. La fragmentación se puede implementar con Cloud SQL para PostgreSQL (como plataforma de datos) con una capa de aplicación compatible. |
| Base de datos en memoria | Oracle ofrece un conjunto de funciones que pueden mejorar el rendimiento de las bases de datos para OLTP, así como para cargas de trabajo mixtas. | No se admite | Cloud SQL para PostgreSQL no tiene una función equivalente integrada. Sin embargo, puedes usar nuestro servicio de Redis gestionado, Memorystore, como alternativa. |
| Redacción | Como parte de las funciones de seguridad avanzadas de Oracle, la redacción puede realizar un enmascaramiento de columnas para evitar que los usuarios y las aplicaciones recuperen datos sensibles. | No se admite | Cloud SQL para PostgreSQL no tiene una función equivalente integrada. Sin embargo, Protección de Datos Sensibles se puede usar para desidentificar datos sensibles. |
Funcionalidad
Aunque las bases de datos de Oracle 11g/12c y Cloud SQL para PostgreSQL se basan en arquitecturas diferentes (infraestructura y lenguajes procedimentales ampliados), ambas comparten los mismos aspectos fundamentales de un sistema de bases de datos relacionales. Admiten objetos de base de datos, cargas de trabajo simultáneas de varios usuarios y transacciones con propiedades ACID. También gestionan las disputas de bloqueo con varios niveles de aislamiento (en función de las necesidades de la aplicación) y satisfacen los requisitos continuos de la aplicación para las operaciones de procesamiento de transacciones online (OLTP) y de procesamiento analítico online (OLAP).
En la siguiente sección se ofrece una descripción general de algunas de las principales diferencias funcionales entre Oracle y Cloud SQL para PostgreSQL. En algunos casos, cuando se considera necesario destacar las diferencias, la sección incluye comparaciones técnicas detalladas.
Crear y ver bases de datos
| Oracle 11g/12c | Cloud SQL para PostgreSQL 12 |
|---|---|
Normalmente, las bases de datos se crean y se consultan con la utilidad Database Creation Assistant (DBCA) de Oracle. En las bases de datos o instancias creadas manualmente, debe especificar parámetros adicionales:SQL> CREATE DATABASE ORADB
|
Usa una instrucción con el formato CREATE DATABASE Name;, como en este ejemplo:postgres=> CREATE DATABASE PGSQLDB;
|
| Oracle 12c | Cloud SQL para PostgreSQL 12 |
En Oracle 12c, puedes crear PDBs a partir de la semilla, ya sea a partir de una plantilla de base de datos de contenedor (CDB) o clonando una PDB de una PDB existente. Se usan varios parámetros:SQL> CREATE PLUGGABLE DATABASE PDB
|
Usa una instrucción con el formato CREATE DATABASE Name;, como en este ejemplo:postgres=> CREATE DATABASE PGSQLDB;
|
Mostrar todas las PDBs:SQL> SHOW is PDBS; |
Mostrar todas las bases de datos:postgres=> \list |
Conéctate a otra PDB:SQL> ALTER SESSION SET CONTAINER=pdb; |
Conectarse a otra base de datos:postgres=> \connect databaseName;
O bien: postgres=> \c databaseName |
Abrir o cerrar un archivo PDB específico (abrir o abrir solo lectura):SQL> ALTER PLUGGABLE DATABASE pdb CLOSE; |
No se admite en una sola base de datos. Todas las bases de datos están en la misma instancia de Cloud SQL para PostgreSQL, por lo que todas están activas o inactivas. |
Gestionar una base de datos a través de la consola Google Cloud
En la Google Cloud consola, ve a Bases de datos>SQL>Instancia>(selecciona tu instancia de PostgreSQL)>Bases de datos.
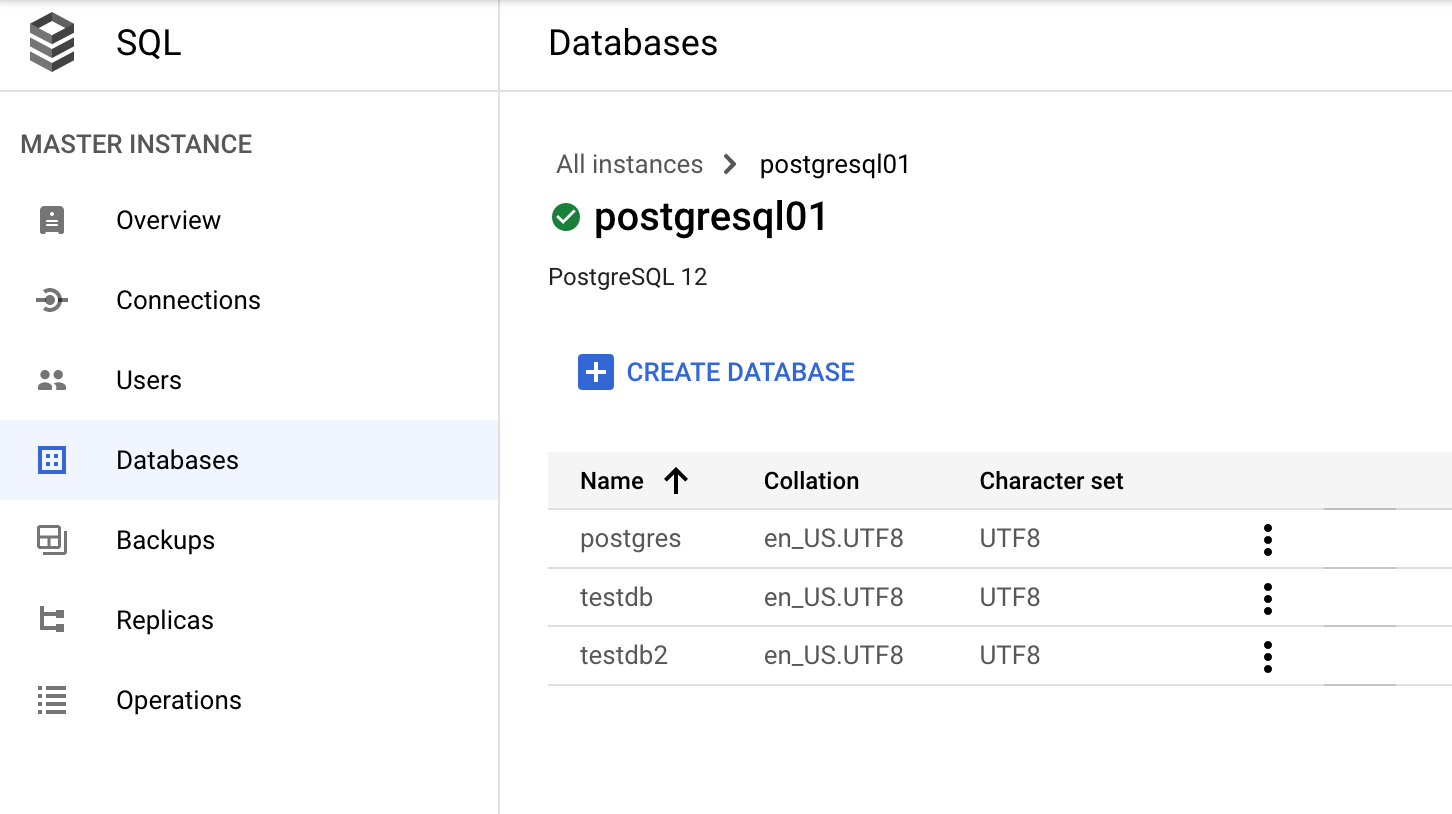
Diccionario de datos y vistas dinámicas
Las bases de datos de Oracle proporcionan un diccionario de datos junto con vistas de rendimiento dinámicas (vistas V$) que facilitan una gran variedad de tareas de mantenimiento y monitorización de bases de datos. El diccionario de datos almacena toda la información que se usa para gestionar los objetos de la base de datos, mientras que las vistas de rendimiento dinámicas contienen mucha información relacionada con el rendimiento de la base de datos. Estas vistas se actualizan continuamente mientras se ejecuta la base de datos.
Por el contrario, PostgreSQL proporciona varios catálogos de metadatos que tienen un propósito similar al del diccionario de datos y las vistas de rendimiento dinámicas de Oracle:
- Catálogo del sistema: metadatos sobre todos los objetos de la base de datos.
- Vistas de recogida de estadísticas: informes sobre las actividades de PostgreSQL.
- Vistas de esquema de información: metadatos sobre todos los objetos de la base de datos, según el estándar ANSI SQL.
Ver metadatos y vistas dinámicas del sistema
En esta sección se ofrece una descripción general de algunas de las tablas de metadatos y vistas dinámicas del sistema más comunes que se usan en Oracle, así como de los objetos de base de datos correspondientes en Cloud SQL para PostgreSQL versión 12.
Oracle proporciona cientos de tablas y vistas de metadatos del sistema (en determinados esquemas del sistema, como SYS o SYSTEM), mientras que PostgreSQL solo tiene varias docenas. En cada caso, puede haber más de un objeto de base de datos que cumpla un propósito específico.
Oracle ofrece varios niveles de objetos de metadatos, cada uno de los cuales requiere diferentes privilegios:
USER_TableName: visible para el usuario.ALL_TableName: visible para todos los usuarios.DBA_TableName: solo pueden verla los usuarios con el privilegio de administrador de bases de datos, comoSYSySYSTEM.
En las vistas de rendimiento dinámicas, Oracle usa los prefijos V$/GV$. Por el contrario, los metadatos y las vistas de Cloud SQL para PostgreSQL se encuentran en los esquemas information_schema y pg_catalog.
| Tipo de metadatos | Tabla o vista de Oracle | Tabla, vista o consulta de Cloud SQL para PostgreSQL |
|---|---|---|
| Sesiones abiertas | V$SESSION |
pg_catalog.pg_stat_activity |
| Ejecutar transacciones | V$TRANSACTION |
No es compatible. Como solución alternativa, pg_locks proporciona una lista de
transacciones abiertas que contienen uno o varios bloqueos. |
| Objetos de base de datos | DBA_OBJECTS |
pg_catalog.pg_class |
| Tablas | DBA_TABLES |
pg_catalog.pg_tables |
| Columnas de tabla | DBA_TAB_COLUMNS |
pg_catalog.pg_attribute |
| Privilegios de tabla y columna | TABLE_PRIVILEGES |
information_schema.table_privileges
information_schema.column_privileges |
| Particiones | DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS |
pg_catalog.pg_partitioned_table |
| Visualizaciones | DBA_VIEWS |
pg_catalog.pg_views |
| Restricciones | DBA_CONSTRAINTS |
pg_catalog.pg_constraint |
| Índices | DBA_INDEXES |
pg_catalog.pg_index |
| Vistas materializadas | DBA_MVIEWS |
pg_catalog.pg_matviews |
| Procedimientos almacenados | DBA_PROCEDURES |
pg_catalog.pg_proc |
| Funciones almacenadas | DBA_PROCEDURES |
pg_catalog.pg_proc |
| Activadores | DBA_TRIGGERS |
pg_catalog.pg_trigger |
| Usuarios | DBA_USERS |
pg_catalog.pg_user |
| Privilegios de usuario | DBA_SYS_PRIVS |
pg_catalog.pg_roles |
| Tareas/ programador |
DBA_JOBS |
No es compatible. |
| Espacios de tabla | DBA_TABLESPACES |
pg_catalog.pg_tablespace |
| Archivos de datos | DBA_DATA_FILES |
No es compatible. |
| Sinónimos | DBA_SYNONYMS |
No es compatible. |
| Secuencias | DBA_SEQUENCES |
pg_catalog.pg_sequence |
| Enlaces de bases de datos | DBA_DB_LINKS |
pg_catalog.pg_foreign_server |
| Estadísticas | DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_SQLTUNE_STATISTICS
DBA_CPU_USAGE_STATISTICS |
pg_catalog.pg_stats |
| Cerraduras | DBA_LOCK |
pg_catalog.pg_locks |
| Parámetros de la base de datos | V$PARAMETER |
pg_catalog.pg_settings
show |
| Segmentos | DBA_SEGMENTS |
No es compatible. |
| Roles | DBA_ROLES |
pg_catalog.pg_roles |
| Historial de sesiones | V$ACTIVE_SESSION_HISTORY |
No es compatible. |
| Versión | V$VERSION |
select version(); |
| Eventos de espera | V$WAITCLASSMETRIC |
No es compatible. |
| Ajuste y análisis de SQL |
V$SQL |
No es compatible. |
| Ajuste de la memoria de la instancia |
V$SGA
V$SGASTAT
V$SGAINFO
V$SGA_CURRENT_RESIZE_OPS
V$SGA_RESIZE_OPS
V$SGA_DYNAMIC_COMPONENTS
V$SGA_DYNAMIC_FREE_MEMORY
V$PGASTAT |
No está integrada en Cloud SQL para PostgreSQL. Usa la extensión pg_buffercache para examinar la caché de búfer compartida en tiempo real. |
Parámetros del sistema
Las bases de datos de Oracle y Cloud SQL para PostgreSQL se pueden configurar específicamente para conseguir determinadas funciones que van más allá de la configuración predeterminada. Para modificar los parámetros de configuración en Oracle, se necesitan ciertos permisos de administración (principalmente, los permisos de usuario SYS/SYSTEM).
A continuación, se muestra un ejemplo de cómo modificar la configuración de Oracle mediante la instrucción ALTER SYSTEM. En este ejemplo, el usuario cambia el parámetro "maximum
attempts for failed logins" (máximo número de intentos de inicio de sesión fallidos) solo en el nivel de configuración spfile (la modificación solo es válida después de reiniciar):
SQL> ALTER SYSTEM SET SEC_MAX_FAILED_LOGIN_ATTEMPTS=2 SCOPE=spfile;
En el siguiente ejemplo, el usuario solicita ver el valor del parámetro de Oracle:
SQL> SHOW PARAMETER SEC_MAX_FAILED_LOGIN_ATTEMPTS;
El resultado debería ser similar al siguiente:
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sec_max_failed_login_attempts integer 2
La modificación de parámetros de Oracle funciona en tres ámbitos:
- SPFILE las modificaciones de los parámetros se escriben en el archivo
spfilede Oracle y es necesario reiniciar la instancia para que el parámetro surta efecto. - MEMORY las modificaciones de los parámetros solo se aplican en la capa de memoria y no se permite ningún cambio de parámetro estático.
- BOTH las modificaciones de los parámetros se aplican tanto en el archivo de parámetros del servidor como en la memoria de la instancia, donde no se permite ningún cambio de parámetro estático.
Marcas de configuración de Cloud SQL para PostgreSQL
Puedes modificar los parámetros del sistema de Cloud SQL para PostgreSQL mediante las marcas de configuración en la Google Cloud consola, la CLI de gcloud o CURL. Consulta la lista completa de todos los parámetros que puedes modificar y que son compatibles con Cloud SQL para PostgreSQL.
Los parámetros de PostgreSQL se pueden dividir en varios ámbitos:
- Parámetros dinámicos: se pueden modificar durante el tiempo de ejecución.
- Parámetros de la base de datos: se aplican solo a una base de datos específica de una instancia de PostgreSQL.
- Parámetros de rol: se aplican solo a un rol de base de datos específico.
- Parámetros estáticos: requieren reiniciar la instancia para que se apliquen.
- Parámetros de sesión: se pueden modificar a nivel de sesión solo durante el tiempo de vida de la sesión actual, aislados de otras sesiones.
- Parámetros globales: tendrán un efecto global en todas las sesiones actuales y futuras.
Ejemplos de modificación de parámetros de Cloud SQL para PostgreSQL
Consola
Usa la consola Google Cloud para habilitar el parámetro log_connections.
Ve a la página Editar instancia de Cloud Storage.
En Flags (Marcas), haz clic en Add item (Añadir elemento) y busca
log_connections, como se muestra en la siguiente captura de pantalla.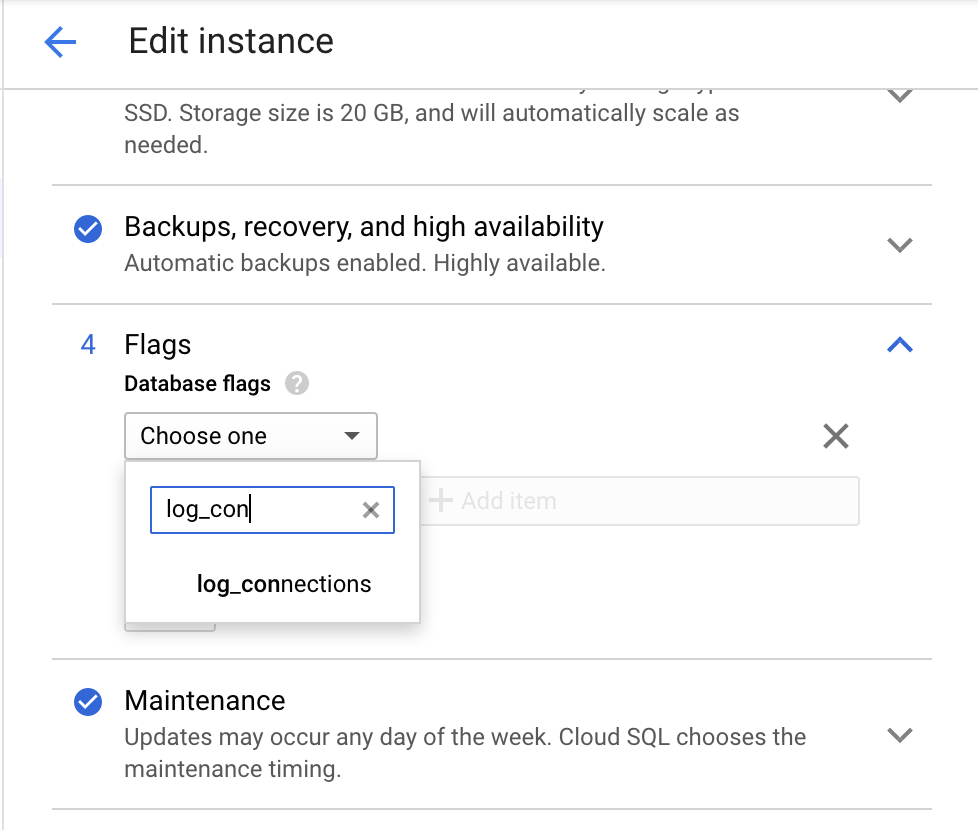
gcloud
- Usa la CLI de gcloud para habilitar el parámetro
log_connections:
gcloud sql instances patch INSTANCE_NAME \
--database-flags log_connections=on
El resultado es el siguiente:
WARNING: This patch modifies database flag values, which may require your instance to be restarted. Check the list of supported flags - /sql/docs/postgres/flags - to see if your instance will be restarted when this patch is submitted. Do you want to continue (Y/n)?
Cloud SQL para PostgreSQL
Defina timezone a nivel de sesión. Esta modificación se mantiene durante la sesión actual y solo se aplica durante la duración de la sesión.
Mostrar el parámetro de configuración
timezone:postgres=> SHOW timezone;Verás el siguiente resultado, donde
timezoneesset to UTC:TimeZone ---------- UTC (1 row)
Define
timezonecomo UTC-9:postgres=> SET timezone='UTC-9';Mostrar el parámetro de configuración
timezone:postgres> SHOW timezone;Verá el siguiente resultado, donde
timezonese ha definido comoUTC-9:TimeZone ---------- UTC-9 (1 row)
Transacciones y niveles de aislamiento
En esta sección se describen las principales diferencias en la ejecución de transacciones y los niveles de aislamiento entre Oracle y Cloud SQL para PostgreSQL.
Modo de confirmación
Oracle funciona de forma predeterminada en el modo de confirmación automática, en el que cada transacción DML debe determinarse con las instrucciones COMMIT/ROLLBACK. Una de las diferencias fundamentales entre Oracle y PostgreSQL es que PostgreSQL emite implícitamente un COMMIT después de cada comando que no sigue a START TRANSACTION (o BEGIN). Otros motores de bases de datos también lo conocen como autocommit.
Aunque la confirmación automática está habilitada de forma predeterminada, se puede inhabilitar a nivel de sesión mediante SET AUTOCOMMIT OFF.
Niveles de aislamiento
El estándar SQL ANSI/ISO (SQL:92) define cuatro niveles de aislamiento. Cada nivel proporciona un enfoque diferente para gestionar la ejecución simultánea de transacciones de bases de datos:
- Lectura de datos no confirmados: una transacción que se esté procesando puede ver los datos no confirmados de otra transacción. Si se realiza una reversión, todos los datos se restauran a su estado anterior.
- Lectura confirmada: una transacción solo ve los cambios de datos que se han confirmado. No se pueden realizar cambios no confirmados ("lecturas sucias").
- Lectura repetible: una transacción puede ver los cambios realizados por otra transacción solo después de que ambas hayan emitido un
COMMITo se hayan revertido. - Serializable: el nivel de aislamiento más estricto o sólido. Este nivel bloquea todos los registros a los que se accede y bloquea el recurso para que no se puedan añadir registros a la tabla.
Los niveles de aislamiento de las transacciones gestionan la visibilidad de los datos modificados que ven otras transacciones en curso. Además, cuando varias transacciones simultáneas acceden a los mismos datos, el nivel de aislamiento de las transacciones seleccionado afecta a la forma en que interactúan las diferentes transacciones.
Oracle admite los siguientes niveles de aislamiento:
- Confirmación de lectura (predeterminado)
- Serializable
- Solo lectura (no forma parte del estándar SQL ANSI/ISO [SQL:92])
MVCC (control de simultaneidad multiversión) de Oracle:
- Oracle usa el mecanismo MVCC para proporcionar coherencia de lectura automática en toda la base de datos y en todas las sesiones.
- Oracle se basa en el número de cambio del sistema (SCN) de la transacción actual para obtener una vista coherente de la base de datos. Por lo tanto, todas las consultas de la base de datos solo devuelven datos confirmados con respecto al SCN en el momento de la ejecución de la consulta.
- Los niveles de aislamiento se pueden cambiar a nivel de transacción y de sesión.
A continuación, se muestra un ejemplo de cómo definir niveles de aislamiento:
-- Transaction Level
SQL> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SQL> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SQL> SET TRANSACTION READ ONLY;
-- Session Level
SQL> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
SQL> ALTER SESSION SET ISOLATION_LEVEL = READ COMMITTED;
Cloud SQL para PostgreSQL admite los cuatro niveles de aislamiento de transacciones especificados en el estándar ANSI SQL:92:
- Lectura no confirmada (equivalente a Lectura confirmada)
- Confirmación de lectura (predeterminado)
- Lectura repetible
- Serializable
El nivel de aislamiento predeterminado de Cloud SQL para PostgreSQL es READ COMMITTED.
Estos niveles de aislamiento se pueden modificar a nivel de SESSION, TRANSACTION y INSTANCE.
Para verificar los niveles de aislamiento actuales tanto en TRANSACTION como en SESSION, usa la siguiente instrucción:
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
El resultado es el siguiente:
current_setting ----------------- read committed (1 row)
Puedes modificar la sintaxis del nivel de aislamiento de la siguiente manera:
SET [SESSION CHARACTERISTICS AS] TRANSACTION ISOLATION LEVEL [ REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE]
También puedes modificar el nivel de aislamiento a nivel de SESIÓN:
postgres=> SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Verify
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
El resultado es el siguiente:
current_setting ----------------- repeatable read (1 row)
El nivel de aislamiento en los niveles INSTANCE se controla mediante la marca de base de datos
default_transaction_isolation. Puedes verificarlo con la siguiente instrucción:
postgres=> SHOW DEFAULT_TRANSACTION_ISOLATION;
El resultado es el siguiente:
default_transaction_isolation ------------------------------- repeatable read (1 row)
Siguientes pasos
- Consulta más información sobre las cuentas de usuario de Cloud SQL para PostgreSQL.
- Consulta arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Centro de arquitectura de Cloud.