Ce tutoriel décrit un processus complet de basculement et de remplacement pour la reprise après sinistre (DR) dans Cloud SQL pour MySQL à l'aide d'instances dupliquées interrégionales avec accès en lecture.
Dans ce tutoriel, vous allez configurer une instance Cloud SQL pour MySQL haute disponibilité (HA) pour la reprise après sinistre et simuler une indisponibilité du service. Vous suivrez ensuite la procédure de reprise après sinistre pour récupérer votre déploiement initial une fois la panne résolue.
Ce tutoriel est destiné aux architectes, aux administrateurs et aux ingénieurs de bases de données.
Pour lire une présentation du fonctionnement de la reprise après sinistre SQL, consultez la page À propos de la reprise après sinistre dans Cloud SQL.
Objectifs
- Créer une instance Cloud SQL pour MySQL haute disponibilité
- Déployer une instance dupliquée interrégionale avec accès en lecture sur Google Cloud à l'aide de Cloud SQL pour MySQL
- Simuler un sinistre et effectuer un basculement avec Cloud SQL pour MySQL
- Comprendre la procédure à suivre pour récupérer votre déploiement initial en effectuant un remplacement avec Cloud SQL pour MySQL
Ce document traite uniquement des processus de basculement et de remplacement pour la reprise après sinistre entre deux régions différentes. Pour plus d'informations sur un processus de basculement d'instance haute disponibilité au sein d'une même région, consultez la page Présentation de la configuration de la haute disponibilité.
Coûts
Dans ce document, vous utilisez les composants facturables de Google Cloudsuivants :
Vous pouvez obtenir une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, supprimez les ressources que vous avez créées pour éviter que des frais vous soient facturés. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Phase 1 : Configurer une instance de base de données à haute disponibilité pour la reprise après sinistre
Les phases suivantes (1 à 3) vous guident dans un processus complet de basculement et de remplacement. Vous exécutez toutes les commandes à l'aide de la commande
gclouddans Cloud Shell. Pour simplifier le processus, le tutoriel utilise, dans la mesure du possible, les paramètres par défaut (par exemple, la version Cloud SQL par défaut). Dans votre environnement de production, vous pouvez ajouter d'autres configurations.Définir des variables d'environnement
Cette section fournit des exemples de variables d'environnement qui définissent les différents noms et régions requis pour les commandes que vous exécutez dans ce tutoriel. Vous pouvez ajuster ces exemples de variables selon vos besoins.
Les tableaux suivants indiquent les noms des instances, leurs rôles et leurs régions de déploiement pour chaque phase du processus de reprise après sinistre et de remplacement décrit dans ce tutoriel. Vous pouvez également indiquer vos propres noms et régions.
Phase initiale Nom de l'instance Rôle Région instance-1Instance principale us-west1instance-2Instance de secours us-west1instance-3Instance dupliquée interrégionale avec accès en lecture us-west2Phase de sinistre Nom de l'instance Rôle Région instance-3Instance principale us-west2instance-4Instance de secours us-west2instance-5Instance dupliquée interrégionale avec accès en lecture us-west3instance-6Instance dupliquée interrégionale avec accès en lecture us-west1Phase de remplacement (phase finale) Nom de l'instance Rôle Région instance-6Instance principale us-west1instance-7Instance de secours us-west1instance-8Instance dupliquée interrégionale avec accès en lecture us-west2Les noms d'instance dans les tables précédentes ne sont pas encodés avec leur rôle. En situation de reprise après sinistre, la fonction d'une instance peut changer. Par exemple, une instance dupliquée peut devenir l'instance principale. Si le nom de la nouvelle instance principale contient le mot
replica, une confusion et des conflits peuvent survenir. Par conséquent, nous vous recommandons de ne pas encoder les noms d'instance avec la fonction ou le rôle que vous leur attribuez à l'origine.Les tableaux précédents répertorient les noms des instances de secours. Même si ce tutoriel ne traite pas du basculement d'instance haute disponibilité, il inclut les noms des instances de secours à des fins d'exhaustivité.
La phase de remplacement recrée le déploiement d'origine de la phase initiale dans les mêmes régions d'origine. Notez toutefois que, dans une opération de remplacement, les noms des instances doivent changer, car les noms d'origine ne redeviennent pas immédiatement disponibles après la suppression des instances d'origine. Pour faciliter la création des instances lors de la phase de remplacement, vous devez utiliser des noms d'instances qui ne correspondent pas aux noms utilisés lors de la phase initiale.
Dans Cloud Shell, définissez des variables d'environnement basées sur les spécifications décrites dans les tableaux précédents :
export primary_name=instance-1 export primary_tier=db-n1-standard-2 export primary_region=us-west1 export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-3 export cross_region_replica_region=us-west2Si vous souhaitez utiliser un autre niveau pour votre instance principale, répertoriez les niveaux disponibles, puis attribuez une valeur différente au niveau principal (primary_tier) :
gcloud sql tiers listPour obtenir la liste des régions dans lesquelles vous pouvez déployer Cloud SQL, consultez la page Paramètres des instances.
Créer une instance de base de données principale
Dans Cloud Shell, créez une instance unique de Cloud SQL :
gcloud sql instances create $primary_name \ --tier=$primary_tier \ --region=$primary_regionLa commande
gcloudse met en pause jusqu'à ce que l'instance soit créée.Définissez le mot de passe racine :
gcloud sql users set-password root \ --host=% \ --instance $primary_name \ --password $primary_root_password
Créer une base de données principale
Dans Cloud Shell, connectez-vous à l'interface système MySQL et saisissez le mot de passe racine lorsque l'invite s'affiche :
gcloud sql connect $primary_name --user=rootÀ l'invite MySQL, créez une base de données et importez des données de test :
CREATE DATABASE guestbook; USE guestbook; CREATE TABLE entries (guestName VARCHAR(255), content VARCHAR(255), entryID INT NOT NULL AUTO_INCREMENT, PRIMARY KEY(entryID)); INSERT INTO entries (guestName, content) values ("first guest", "I got here!"); INSERT INTO entries (guestName, content) values ("second guest", "Me too!");Vérifiez que les données ont bien été validées :
SELECT * FROM entries;Vérifiez que deux lignes de données sont renvoyées.
Quittez l'interface système MySQL :
exit;
À ce stade, vous disposez d'une base de données unique contenant une table et des données de test.
Convertir l'instance principale en instance de base de données à haute disponibilité
Vous ne pouvez configurer Cloud SQL qu'en tant que système à haute disponibilité régional, et non en tant que système interrégional. (la configuration d'une instance dupliquée interrégionale avec accès en lecture est différente de la configuration de Cloud SQL en tant que système interrégional). Pour en savoir plus, consultez la page Activer et désactiver la haute disponibilité sur une instance.
Dans Cloud Shell, créez une instance Cloud SQL compatible avec la haute disponibilité :
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$primary_backup_start_time
Ajouter une instance dupliquée interrégionale avec accès en lecture pour la reprise après sinistre avec mise à jour automatique
Les étapes suivantes sont suffisantes pour créer une instance dupliquée interrégionale avec accès en lecture pour ce tutoriel :
Dans Cloud Shell, configurez une instance dupliquée interrégionale avec accès en lecture :
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region(Facultatif) Pour vérifier que la base de données a bien été répliquée, accédez à la page Instances Cloud SQL dans la consoleGoogle Cloud .
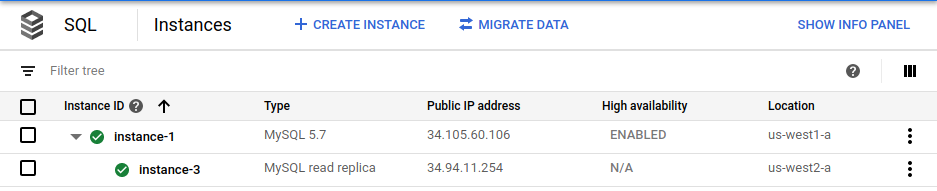
La console Google Cloud indique que l'instance principale (
instance-1) est activée pour la haute disponibilité et qu'une instance dupliquée interrégionale avec accès en lecture (instance-3) existe.En utilisant le même mot de passe racine que pour l'instance principale, connectez-vous à l'instance dupliquée interrégionale avec accès en lecture :
gcloud sql connect $cross_region_replica_name --user=rootLorsque MySQL vous y invite, sélectionnez les données pour vous assurer que la réplication fonctionne :
USE guestbook; SELECT * FROM entries;Quittez l'interface système MySQL :
exit;
Pour savoir comment configurer une instance dupliquée interrégionale avec accès en lecture complet, consultez la documentation de Cloud SQL.
Pour les bases de données volumineuses exploitées en environnement de production, nous vous recommandons de sauvegarder la base de données principale et de créer l'instance dupliquée interrégionale avec accès en lecture à partir de la sauvegarde. Cette étape permet de réduire le temps nécessaire pour synchroniser l'instance dupliquée avec accès en lecture à la base de données principale. Ce processus est décrit dans la section suivante. Vous pouvez toutefois ignorer cette étape et passer directement à la phase 2 si vous le souhaitez.
Ajouter une instance dupliquée interrégionale avec accès en lecture basée sur un fichier de vidage
Une façon d'optimiser la création d'une instance dupliquée interrégionale avec accès en lecture consiste à synchroniser l'instance dupliquée à partir d'un état antérieur cohérent de la base de données principale, plutôt que de la synchroniser avec l'état de la base principale au moment où l'instance dupliquée devient la nouvelle instance principale. Cette optimisation nécessite la création d'un fichier de vidage que l'instance dupliquée utilise comme état de départ.
Pour connaître les étapes de création d'une instance dupliquée basée sur un fichier de vidage, consultez la page Réplication depuis un serveur externe vers Cloud SQL (v1.1). Cette approche peut être utile pour les bases de données de production volumineuses. Toutefois, dans ce tutoriel, nous ignorons cette étape, car l'ensemble de données de test est suffisamment petit pour une réplication complète.
Phase 2 : Simuler un sinistre (interruption de la région)
Au cours de cette phase, vous allez simuler la panne d'une région principale dans un environnement de production en rendant la base de données principale indisponible.
Déterminer la latence de l'instance dupliquée interrégionale avec accès en lecture
Dans les étapes suivantes, vous allez déterminer le délai de réplication de l'instance dupliquée interrégionale avec accès en lecture :
Dans la console Google Cloud , accédez à la page Instances Cloud SQL.
Cliquez sur l'instance dupliquée avec accès en lecture (instance-3).
Dans la liste déroulante des métriques, cliquez sur Replication Lag (Délai de réplication) :
La métrique affichée est désormais Replication Lag (Délai de réplication). Le graphique ne montre aucun délai :
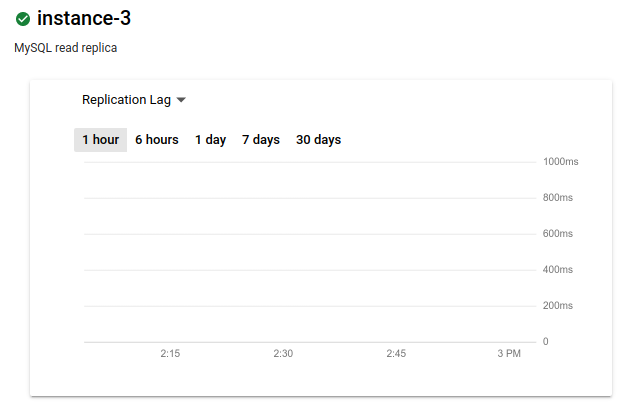
Dans l'idéal, le délai de réplication doit être nul lorsqu'une indisponibilité de région principale survient. En effet, un retard nul garantit que toutes les transactions sont bien répliquées. Si ce délai n'est pas nul, certaines transactions peuvent ne pas être répliquées. En pareil cas, l'instance dupliquée interrégionale avec accès en lecture ne contient pas toutes les transactions validées sur l'instance principale.
Rendre l'instance principale indisponible
Dans les étapes suivantes, vous allez simuler un sinistre en arrêtant l'instance principale. Si une instance dupliquée interrégionale avec accès en lecture est associée à l'instance principale, vous devez d'abord dissocier l'instance dupliquée, sinon vous ne pourrez pas arrêter l'instance Cloud SQL.
Dans Cloud Shell, dissociez l'instance dupliquée interrégionale avec accès en lecture de l'instance principale.
gcloud sql instances patch $cross_region_replica_name \ --no-enable-database-replicationLorsque vous y êtes invité, acceptez l'option permettant de continuer.
Arrêtez l'instance de base de données principale :
gcloud sql instances patch $primary_name --activation-policy NEVER
Mettre en œuvre la reprise après sinistre
Dans Cloud Shell, convertissez l'instance dupliquée interrégionale avec accès en lecture en instance autonome :
gcloud sql instances promote-replica $cross_region_replica_nameLorsque vous y êtes invité, acceptez l'option permettant de continuer. Sur la page des Instances Cloud SQL, on peut voir que l'ancienne instance dupliquée interrégionale avec accès en lecture (
instance-3) est répertoriée en tant que nouvelle instance principale, et que l'ancienne instance principale (instance-1) est bien considérée comme arrêté :
Après avoir promu l'instance dupliquée interrégionale avec accès en lecture en tant que nouvelle instance principale, activez-la pour la haute disponibilité. Il est recommandé de mettre à jour les variables d'environnement avec un nom approprié.
Mettez à jour les variables d'environnement :
export former_primary_name=$primary_name export primary_name=$cross_region_replica_name export primary_tier=db-n1-standard-2 export primary_region=$cross_region_replica_region export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-5 export cross_region_replica_region=us-west3Démarrez la nouvelle instance principale :
gcloud sql instances patch $primary_name --activation-policy ALWAYSActivez la nouvelle instance principale en tant qu'instance régionale à haute disponibilité :
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$backup_start_timeCréez une instance dupliquée interrégionale avec accès en lecture dans une troisième région :
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_regionDans une étape précédente, vous avez défini la variable d'environnement
cross_region_replica_regionsurus-west3.Une fois le basculement terminé, la page Instances Cloud SQL dans la console Google Cloud indique que la nouvelle instance principale (
instance-3) est activée pour la haute disponibilité et comporte une instance dupliquée interrégionale avec accès en lecture (instance-5) :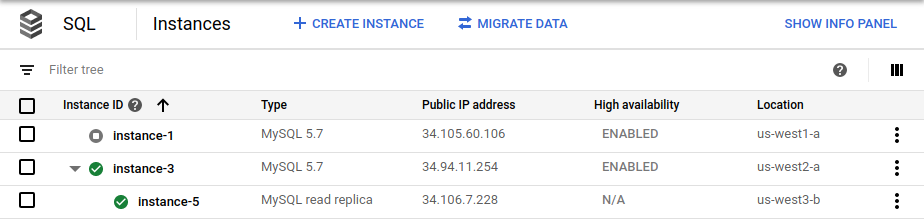
(Facultatif) Si vous disposez de sauvegardes régulières, suivez le processus décrit précédemment pour synchroniser la nouvelle instance principale avec la dernière version de sauvegarde.
(Facultatif) Si vous utilisez un proxy Cloud SQL, configurez-le de manière à utiliser la nouvelle instance principale afin de reprendre le traitement de l'application.
Gérer une indisponibilité régionale temporaire
Il est possible que l'indisponibilité qui déclenche un basculement soit résolue avant l'achèvement de celui-ci. Dans ce cas, il peut être judicieux d'annuler le processus de basculement et de continuer à utiliser l'instance Cloud SQL principale d'origine dans la région où l'indisponibilité est survenue.
Selon l'état spécifique du processus de basculement, l'instance dupliquée interrégionale avec accès en lecture a peut-être déjà été promue. Dans ce cas, vous devez la supprimer et recréer une instance dupliquée interrégionale avec accès en lecture.
Supprimer l'instance principale d'origine pour éviter une situation de split-brain
Pour éviter une situation de split-brain, vous devez supprimer l'instance principale d'origine (ou la rendre inaccessible aux clients de la base de données).
Après un basculement, une situation de split-brain peut se produire lorsque des clients écrivent simultanément dans la base de données principale d'origine et dans la nouvelle base de données principale. Dans ce cas, un risque d'incohérence entre les contenus des deux bases existe. Après un basculement, la base de données principale d'origine doit être considérée comme obsolète et ne doit recevoir aucun trafic de lecture ou d'écriture.
Dans Cloud Shell, supprimez l'instance principale d'origine :
gcloud sql instances delete $former_primary_nameLorsque vous y êtes invité, acceptez l'option permettant de continuer.
Dans la console Google Cloud , la page Instances Cloud SQL n'affiche plus l'instance principale d'origine (
instance-1) dans le cadre du déploiement :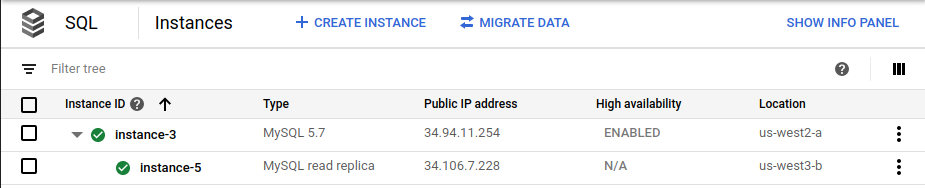
Phase 3 : Mettre en œuvre une solution de remplacement
Pour mettre en œuvre une solution de remplacement pointant vers votre région d'origine (R1) une fois que celle-ci sera à nouveau disponible, suivez la même procédure que celle décrite à la phase 2. Cette procédure peut se résumer comme suit :
Créez une deuxième instance dupliquée interrégionale avec accès en lecture dans la région d'origine (R1). À ce stade, l'instance principale dispose de deux instances dupliquées interrégionales avec accès en lecture, une dans la région R3 et une dans la région R1.
Promouvez l'instance dupliquée interrégionale avec accès en lecture de la région R1 en tant qu'instance principale finale.
Activez la haute disponibilité pour la dernière instance principale.
Créez une instance dupliquée interrégionale avec accès en lecture pour l'instance principale finale dans
us-west2.Pour éviter une situation de split-brain, supprimez toutes les instances qui ne sont plus nécessaires (instance principale d'origine et instance dupliquée interrégionale avec accès en lecture dans la région R3).
Comme indiqué précédemment, il est recommandé de créer une sauvegarde initiale contenant l'état de départ défini pour la nouvelle base de données principale.
Le déploiement final dispose désormais d'une instance principale haute disponibilité (avec le nom
instance-6) et d'une instance dupliquée interrégionale avec accès en lecture (nomméeinstance-8).Comparer les avantages et les inconvénients des reprises après sinistre manuelles et automatiques
Le tableau suivant présente les avantages et les inconvénients de la mise en œuvre des processus de reprise après sinistre manuels et automatiques. L'objectif ici n'est pas de déterminer quelle approche est correcte et quelle approche ne l'est pas, mais de fournir des critères pour vous aider à déterminer celle qui est la mieux adaptée à vos besoins.
Exécution manuelle Exécution automatique Avantages :
- Vous disposez d'un contrôle strict sur chaque étape.
- Vous pouvez voir, résoudre et signaler immédiatement un problème dans le processus.
- Vous pouvez visualiser et examiner chaque étape du processus au cours d'un basculement.
Avantages :
- Vous pouvez mettre en œuvre et tester des processus de basculement.
- L'automatisation permet une implémentation plus rapide et réduit les délais.
- La mise en œuvre est totalement indépendante des opérateurs humains, de leurs compétences et de leur disponibilité.
Inconvénients :
- La mise en œuvre manuelle des étapes du processus peut le ralentir.
- Les erreurs de saisie humaine peuvent poser des problèmes.
- Les procédures de test impliquent généralement plusieurs rôles et durent un certain temps, ce qui peut décourager l'exécution de tests réguliers.
Inconvénients :
- En cas d'erreur imprévue, vous devez procéder à un débogage pendant le basculement en production.
- Si vous rencontrez des erreurs au cours du processus, vous avez besoin de scripts pour récupérer le processus lorsqu'il s'est arrêté.
- Une bonne connaissance du script et de sa mise en œuvre est nécessaire pour comprendre le comportement du script, en particulier dans les situations d'erreur.
Nous vous recommandons de commencer avec une mise en œuvre manuelle. Ensuite, exécutez volontairement la mise en œuvre régulièrement (de préférence en production) pour vous assurer que le processus manuel fonctionne et que tous les membres de l'équipe connaissent leurs rôles et leurs responsabilités. Nous vous recommandons de définir votre processus manuel dans un document présentant en détail ses différentes étapes. Après chaque mise en œuvre, vous devez confirmer ou modifier/affiner le document décrivant le processus.
Une fois que vous avez optimisé le processus et que vous êtes sûr de sa fiabilité, vous devez déterminer si vous souhaitez l'automatiser. Si vous sélectionnez et mettez en œuvre un processus automatisé, vous devez le tester régulièrement en production pour vous assurer de pouvoir l'exécuter de manière fiable.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel ne soient facturées sur votre compte Google Cloud , vous pouvez supprimer le Google Cloud projet que vous avez créé pour ce tutoriel.
Supprimer le projet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Documentez-vous sur la reprise après sinistre Cloud SQL.
- Documentez-vous sur la reprise après sinistre pour MySQL sur Compute Engine.
- Découvrez les architectures de reprise après sinistre en cas d'indisponibilité de l'infrastructure cloud.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.