In dieser Anleitung wird ein vollständiger Failover- und Fallback-Prozess für die Notfallwiederherstellung (DR) in Cloud SQL for MySQL mithilfe von regionenübergreifenden Lesereplikaten beschrieben.
In dieser Anleitung richten Sie eine Cloud SQL for MySQL-Instanz mit Hochverfügbarkeit für die Notfallwiederherstellung ein und simulieren Sie einen Ausfall. Anschließend führen Sie den DR-Prozess durch, um Ihre erste Bereitstellung wiederherzustellen, nachdem der Ausfall behoben wurde.
Diese Anleitung richtet sich an Datenbankarchitekten, Administratoren und Entwickler.
Eine Übersicht über die Funktionsweise der SQL-Notfallwiederherstellung finden Sie unter Notfallwiederherstellung in Cloud SQL.
Ziele
- Erstellen Sie eine Cloud SQL for MySQL-Instanz für hohe Verfügbarkeit.
- Mit Cloud SQL for MySQL ein regionsübergreifendes Lesereplikat in Google Cloud bereitstellen
- Simulieren Sie eine Notfallwiederherstellung und ein Failover mit Cloud SQL for MySQL.
- Schritte zum Wiederherstellen der ersten Bereitstellung mit einem Fallback mit Cloud SQL for MySQL
Dieses Dokument konzentriert sich nur auf regionsübergreifende DR-Failover- und Fallback-Prozesse. Informationen zum HA-Failover-Prozess für eine einzelne Region finden Sie unter Hochverfügbarkeit konfigurieren – Übersicht.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweise
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Phase 1: HA-Datenbankinstanz für DR einrichten
Die folgenden Phasen (1–3) führen Sie durch einen vollständigen Failover- und Fallback-Prozess. Alle Befehle werden mit dem Befehl
gcloudin Cloud Shell ausgeführt. Zur Vereinfachung des Vorgangs werden in der Anleitung Standardeinstellungen verwendet, z. B. die Cloud SQL-Standardversion. In der Produktionsumgebung können Sie auch andere Konfigurationen hinzufügen.Umgebungsvariablen festlegen
Dieser Abschnitt enthält Beispiele für Umgebungsvariablen, die die verschiedenen Namen und Regionen definieren, die für die in dieser Anleitung ausgeführten Befehle erforderlich sind. Sie können diese Beispielvariablen an Ihre Anforderungen anpassen.
In den folgenden Tabellen werden Instanznamen, ihre Rollen und die Bereitstellungsregionen für jede Phase des DR- und Fallback-Prozesses in dieser Anleitung beschrieben. Sie können auch Ihre eigenen Namen und Regionen angeben.
Erste Phase Instanzname Rolle Region instance-1Primär us-west1instance-2Standby us-west1instance-3Regionenübergreifendes Lesereplikat us-west2Katastrophenphase Instanzname Rolle Region instance-3Primär us-west2instance-4Standby us-west2instance-5Regionenübergreifendes Lesereplikat us-west3instance-6Regionenübergreifendes Lesereplikat us-west1
.Fallback-Phase (final) Instanzname Rolle Region instance-6Primär us-west1instance-7Standby us-west1instance-8Regionenübergreifendes Lesereplikat us-west2Die Instanznamen in den vorherigen Tabellen sind nicht mit ihren Rollen codiert. In einer DR-Situation kann sich die Funktion einer Instanz ändern. Ein Replikat könnte dann beispielsweise zur primären Instanz werden. Wenn der Name der neuen primären Entität das Wort
replicaenthält, können Konflikte und Verwirrung auftreten. Deshalb empfehlen wir, Instanznamen nicht mit der Funktion oder Rolle zu codieren, die sie ausführen.Die obigen Tabellen enthalten die Namen der Standby-Instanzen. Auch wenn in dieser Anleitung kein HA-Failover ausgeführt wird, enthält die Anleitung die Namen von Standby-Instanzen zur Vollständigkeit.
In der Fallback-Phase wird die ursprüngliche Bereitstellung der ersten Phase in denselben ursprünglichen Regionen wiederhergestellt. In einem Fallback müssen sich die Namen der Instanzen jedoch ändern, da die ursprünglichen Namen nicht sofort verfügbar sind, auch nachdem die ursprüngliche Instanz gelöscht wurde. Für eine schnelle Erstellung von Instanzen in der Fallback-Phase sollten Sie Instanznamen verwenden, die nicht mit den Namen in der Anfangsphase übereinstimmen.
Legen Sie in Cloud Shell Umgebungsvariablen fest, die auf den Spezifikationen in den vorherigen Tabellen basieren:
export primary_name=instance-1 export primary_tier=db-n1-standard-2 export primary_region=us-west1 export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-3 export cross_region_replica_region=us-west2Wenn Sie für Ihre primäre Instanz eine andere Stufe verwenden möchten, listen Sie die verfügbaren Stufen auf und weisen Sie dem primary_tier dann einen anderen Wert zu:
gcloud sql tiers listEine Liste der Regionen, in denen Sie Cloud SQL bereitstellen können, finden Sie unter Instanzeinstellungen.
Primäre Datenbankinstanz erstellen
Erstellen Sie in Cloud Shell eine einzelne Instanz von Cloud SQL:
gcloud sql instances create $primary_name \ --tier=$primary_tier \ --region=$primary_regionDer Befehl
gcloudwird pausiert, bis die Instanz erstellt wird.Root-Passwort festlegen:
gcloud sql users set-password root \ --host=% \ --instance $primary_name \ --password $primary_root_password
Primäre Datenbank erstellen
Melden Sie sich in Cloud Shell bei MySQL-Shell an und geben Sie das Root-Passwort an der Eingabeaufforderung ein:
gcloud sql connect $primary_name --user=rootErstellen Sie in der MySQL-Eingabeaufforderung eine Datenbank und laden Sie Testdaten hoch:
CREATE DATABASE guestbook; USE guestbook; CREATE TABLE entries (guestName VARCHAR(255), content VARCHAR(255), entryID INT NOT NULL AUTO_INCREMENT, PRIMARY KEY(entryID)); INSERT INTO entries (guestName, content) values ("first guest", "I got here!"); INSERT INTO entries (guestName, content) values ("second guest", "Me too!");Prüfen Sie, ob die Daten erfolgreich übergeben wurden:
SELECT * FROM entries;Überprüfen Sie, ob zwei Datenzeilen zurückgegeben werden.
Beenden Sie MySQL-Shell:
exit;
Sie haben eine einzige Datenbank mit einer Tabelle und einigen Testdaten.
Primäre Instanz zu einer HA-Datenbankinstanz ändern
Sie können Cloud SQL nur als regionales HA-System, nicht als regionenübergreifendes System konfigurieren. Das Einrichten eines regionenübergreifenden Lesereplikats unterscheidet sich von der Konfiguration von Cloud SQL als regionenübergreifendes System. Weitere Informationen finden Sie unter Hochverfügbarkeit für eine Instanz aktivieren und deaktivieren.
Erstellen Sie in Cloud Shell eine HA-fähige Cloud SQL-Instanz:
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$primary_backup_start_time
Regionenübergreifendes Lesereplikat für die Notfallwiederherstellung mit automatischer Aktualisierung hinzufügen
Die folgenden Schritte reichen aus, um ein regionenübergreifendes Lesereplikat für diese Anleitung zu erstellen:
Richten Sie in Cloud Shell ein regionenübergreifendes Lesereplikat ein:
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region(Optional) Wenn Sie prüfen möchten, ob die Datenbank repliziert wurde, rufen Sie in derGoogle Cloud -Konsole die Cloud SQL-Seite Instanzen auf.
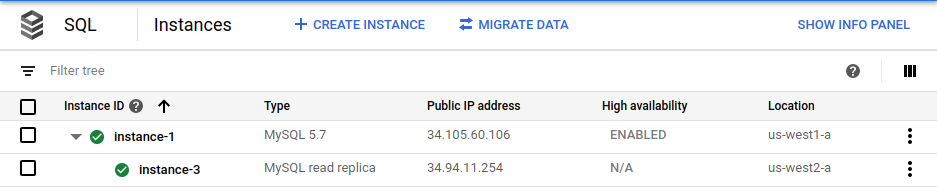
In der Google Cloud Console wird angezeigt, dass die primäre Instanz (
instance-1) HA-fähig ist und ein regionenübergreifendes Lesereplikat (instance-3) bereits vorhanden ist.Melden Sie sich mit dem gleichen Root-Passwort für das primäre Replikat im regionenübergreifenden Lesereplikat an:
gcloud sql connect $cross_region_replica_name --user=rootWählen Sie in der MySQL-Eingabeaufforderung die Daten aus, damit die Replikation funktioniert:
USE guestbook; SELECT * FROM entries;Beenden Sie MySQL-Shell:
exit;
Weitere Informationen zum Einrichten eines vollständigen regionenübergreifenden Lesereplikats finden Sie in der Cloud SQL-Dokumentation.
Für große Datenbanken in einer Produktionsumgebung empfehlen wir, die primäre Datenbank zu sichern und das regionenübergreifende Lesereplikat aus der Sicherung zu erstellen. Mit diesem Schritt reduzieren Sie die Zeit, die das Lesereplikat benötigt, um mit der primären Datenbank zu synchronisieren. Dieser Vorgang wird im nächsten Abschnitt beschrieben. Sie können diesen Schritt jedoch überspringen und mit Phase 2 fortfahren.
Regionenübergreifendes Lesereplikat basierend auf einer Dumpdatei hinzufügen
Eine Möglichkeit zur Optimierung der Erstellung eines regionenübergreifenden Lesereplikats besteht darin, das Replikat von einem früheren, konsistenten primären Datenbankzustand aus zu synchronisieren, anstatt erst zum Zeitpunkt des Zugriffs auf das neue Primärsystem zu synchronisieren. Für diese Optimierung müssen Sie eine Dumpdatei erstellen, die das Replikat als Startzustand verwendet.
Die Schritte zum Erstellen eines Replikats anhand einer Dumpdatei finden Sie unter Von externem Server in Cloud SQL replizieren (v1.1). Dieser Ansatz kann für große Produktionsdatenbanken nützlich sein. In dieser Anleitung wird dieser Schritt jedoch übersprungen, da das Test-Dataset klein genug für eine vollständige Replikation ist.
Phase 2: Notfallwiederherstellung simulieren (regionaler Ausfall)
In dieser Phase simulieren Sie den Ausfall einer primären Region in einer Produktionsumgebung, indem Sie die Verfügbarkeit der primären Datenbank unterbrechen.
Regionsübergreifende Lesereplikat-Verzögerung prüfen
In den folgenden Schritten bestimmen Sie die Replikationsverzögerung des regionenübergreifenden Lesereplikats:
Wechseln Sie in der Google Cloud Console zur Seite Cloud SQL-Instanzen.
Klicken Sie auf das Lesereplikat (instance-3).
Klicken Sie in der Drop-down-Liste der Messwerte auf Replikationsverzögerung:
Der Messwert ändert sich in Replikationsverzögerung. Das Diagramm zeigt keine Verzögerung an:
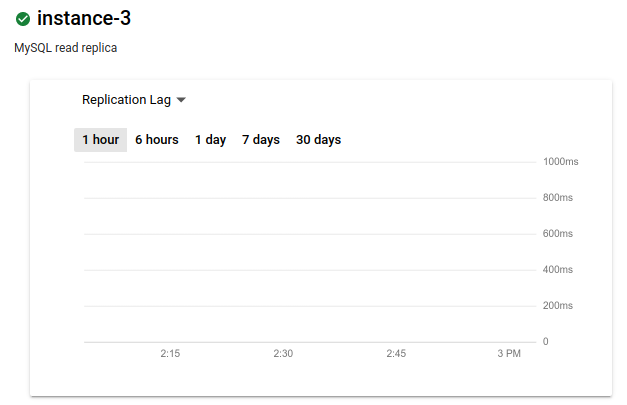
Im Idealfall beträgt die Replikationsverzögerung null, wenn ein Ausfall der primären Region auftritt, da bei einer Verzögerung von null sichergestellt ist, dass alle Transaktionen repliziert werden. Wenn es nicht null ist, werden einige Transaktionen möglicherweise nicht repliziert. In diesem Fall enthält das regionenübergreifende Lesereplikat nicht alle Transaktionen, die mit dem primären Commit durchgeführt wurden.
Primäre Instanz nicht verfügbar machen
In den folgenden Schritten simulieren Sie eine Katastrophe, indem Sie die primäre Datenbank beenden. Wenn ein regionenübergreifendes Lesereplikat mit der primären Datenbank verbunden ist, müssen Sie zuerst die Replikatdatenbank trennen. Andernfalls können Sie die Cloud SQL-Instanz nicht beenden.
Entfernen Sie in Cloud Shell das regionenübergreifende Lesereplikat aus der primären Datenbank:
gcloud sql instances patch $cross_region_replica_name \ --no-enable-database-replicationWenn Sie dazu aufgefordert werden, akzeptieren Sie die Option zum Fortfahren.
Stoppen Sie die primäre Datenbankinstanz:
gcloud sql instances patch $primary_name --activation-policy NEVER
DR implementieren
Stufen Sie in Cloud Shell das regionenübergreifende Lesereplikat in eine eigenständige Instanz hoch:
gcloud sql instances promote-replica $cross_region_replica_nameWenn Sie dazu aufgefordert werden, akzeptieren Sie die Option zum Fortfahren. Auf der Cloud SQL-Seite Instanzen wird das frühere regionenübergreifende Lesereplikat (
instance-3) als neue primäre Datenbank gelesen und die vorherige primäre Datenbank (instance-1) gestoppt:
Nachdem Sie das regionenübergreifende Lesereplikat als die neue primäre Datenbank heraufgestuft haben, aktivieren Sie es für Hochverfügbarkeit. Als Best Practice sollten Sie die Umgebungsvariablen mit dem richtigen Namen aktualisieren.
Aktualisieren Sie die Umgebungsvariablen.
export former_primary_name=$primary_name export primary_name=$cross_region_replica_name export primary_tier=db-n1-standard-2 export primary_region=$cross_region_replica_region export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-5 export cross_region_replica_region=us-west3Neue primäre Domain erstellen:
gcloud sql instances patch $primary_name --activation-policy ALWAYSAktivieren Sie die neue primäre Instanz als regionale HA-Instanz:
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$backup_start_timeErstellen Sie ein regionsübergreifendes Lesereplikat in einer dritten Region:
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_regionIn einem vorherigen Schritt legen Sie die Umgebungsvariable
cross_region_replica_regionaufus-west3fest.Wenn das Failover abgeschlossen ist, wird auf der Seite Cloud SQL-Instanzen in der Google Cloud Console angezeigt, dass die neue primäre Datenbank (
instance-3) als Hochverfügbarkeit aktiviert ist und ein regionenübergreifendes Lesereplikat (instance-5) hat: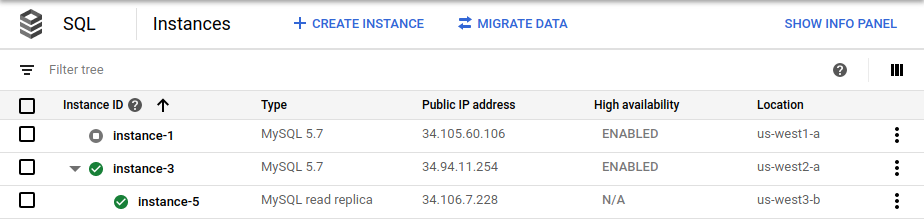
(Optional) Wenn Sie regelmäßige Sicherungen haben, führen Sie die oben beschriebenen Schritte aus, um die neue primäre Datenbank mit der neuesten Sicherungsversion zu synchronisieren.
(Optional) Wenn Sie einen Cloud SQL-Proxy verwenden, konfigurieren Sie den Proxy so, dass er die neue primäre Datenbank verwendet, um die Anwendungsverarbeitung fortzusetzen.
Umgang mit kurzlebigen Regionenausfällen
Es ist möglich, dass der Ausfall, der ein Failover auslöst, behoben wird, bevor der Failover abgeschlossen ist. In diesem Fall kann es sinnvoll sein, den Failover-Prozess abzubrechen und die ursprüngliche primäre Cloud SQL-Instanz in der Region zu verwenden, in der der Ausfall aufgetreten ist.
Abhängig vom spezifischen Status des Failover-Prozesses wurde das regionenübergreifende Lesereplikat möglicherweise bereits beworben. In diesem Fall müssen Sie es löschen und ein regionenübergreifendes Lesereplikat neu erstellen.
Löschen der ursprünglichen primären Instanz, um die Aufteilung in mehreren Situationen zu vermeiden
Um eine Split-Brain-Situation zu vermeiden, müssen Sie die ursprüngliche primäre Datenbank löschen oder für Datenbankclients nicht zugänglich machen.
Nach einem Failover kann es zu einer Split-Brain-Situation kommen, wenn Clients gleichzeitig in die ursprüngliche primäre Datenbank und die neue primäre Datenbank schreiben. In diesem Fall ist der Inhalt der beiden Datenbanken inkonsistent. Nach einem Failover ist die ursprüngliche primäre Datenbank veraltet und darf keinen Lese- oder Schreibzugriff empfangen.
Löschen Sie in Cloud Shell die ursprüngliche primäre Datenbank:
gcloud sql instances delete $former_primary_nameWenn Sie dazu aufgefordert werden, akzeptieren Sie die Option zum Fortfahren.
In der Google Cloud Console wird die ursprüngliche primäre Instanz (
instance-1) im Rahmen der Bereitstellung nicht mehr auf der Cloud SQL-Seite Instanzen angezeigt: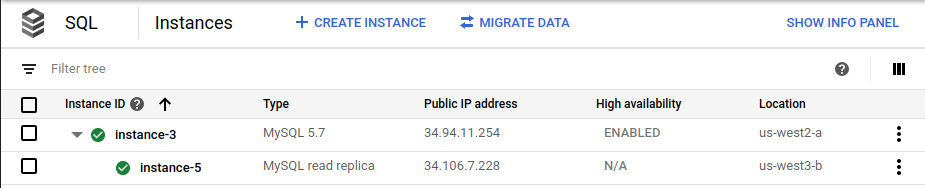
Phase 3: Fallback implementieren
Um ein Fallback auf Ihre ursprüngliche Region (R1) anzuwenden, sobald es verfügbar ist, gehen Sie genauso vor wie in Phase 2 beschrieben. Dieser Prozess wird so zusammengefasst:
Erstellen Sie ein zweites regionenübergreifendes Lesereplikat in der ursprünglichen Region (R1). An diesem Punkt hat die primäre Zone zwei regionenübergreifende Lesereplikate: eins in Region R3 und eins in Region R1.
Das regionenübergreifende Lesereplikat in R1 als letztes primäres Replikat hochstufen
Aktivieren Sie HA für die endgültige primären Domain.
Erstellen Sie ein regionenübergreifendes Lesereplikat der endgültigen primären Datenbank in
us-west2.Löschen Sie alle nicht mehr erforderlichen Instanzen (das ursprüngliche primäre und das regionenübergreifende Lesereplikat in R3), um eine Split-Brain-Situation zu vermeiden.
Wie zuvor erwähnt, hat es sich bewährt, eine erste Sicherung zu erstellen, die den definierten Startstatus der neuen primären Datenbank enthält.
Die endgültige Bereitstellung hat jetzt eine Hochverfügbarkeit mit HA (mit dem Namen
instance-6) und ein regionenübergreifendes Lesereplikat mit dem Nameninstance-8.Vorteile und Nachteile einer manuellen und automatischen Notfallwiederherstellung im Vergleich
In der folgenden Tabelle werden die Vor- und Nachteile der Implementierung eines DR-Prozesses entweder manuell oder automatisch beschrieben. Das Ziel besteht nicht darin, einen richtigen und nicht ordnungsgemäßen Ansatz zu bestimmen, sondern Kriterien zur Bestimmung des besten Ansatzes für Ihre Anforderungen.
Manuelle Ausführung Automatische Ausführung Vorteile:
- Sie haben genaue Kontrolle über jeden Schritt.
- Sie können sofort alle Probleme im Prozess anzeigen, beheben und dokumentieren.
- Sie können jeden Prozessschritt während eines Failovers aufrufen und überprüfen.
Vorteile:
- Sie können Failover-Prozesse implementieren und testen.
- Automatisierung ermöglicht die schnellste Implementierung und minimiert Verzögerungen.
- Die Implementierung ist unabhängig von menschlichen Operatoren, ihrem Wissen und ihrer Verfügbarkeit.
Nachteile:
- Durch manuelles Implementieren von Prozessschritten wird der Prozess verlangsamt.
- Fehler bei der Eingabe können zu Problemen führen.
- Das Testen umfasst in der Regel mehrere Rollen und Zeitpunkte, was für regelmäßige Tests unter Umständen verwirrend ist.
Nachteile:
- Wenn ein unvorhergesehener Fehler auftritt, müssen Sie die Fehlerbehebung während Ihres Produktions-Failover durchführen.
- Wenn während des Prozesses Fehler auftreten, benötigen Sie Skripts (zum Wiederherstellen), an denen der Prozess abgebrochen wurde.
- Ihr Skript und seine Implementierung sind ausreichend umfangreich, um das Verhalten des Skripts, insbesondere in Fehlersituationen, zu verstehen.
Als Best Practice empfehlen wir, mit einer manuellen Implementierung zu beginnen. Führen Sie anschließend die Implementierung regelmäßig aus (vorzugsweise in der Produktion), um sicherzugehen, dass der manuelle Prozess funktioniert und allen Teammitgliedern ihre Rollen und Verantwortlichkeiten bekannt sind. Wir empfehlen Ihnen, den manuellen Prozess in einem schrittweisen Dokument zu definieren. Nach jeder Implementierung sollten Sie das Prozessdokument bestätigen oder optimieren.
Nachdem Sie den Prozess optimiert haben und sicher sind, dass er zuverlässig ist, müssen Sie entscheiden, ob der Prozess automatisiert werden soll. Wenn Sie einen automatisierten Prozess auswählen und implementieren, müssen Sie diesen Prozess in der Produktion regelmäßig testen, um sicherzustellen, dass er zuverlässig implementiert werden kann.
Bereinigen
Wenn Sie vermeiden möchten, dass Ihrem Google Cloud -Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden, können Sie das Google Cloud Projekt löschen, das Sie für diese Anleitung erstellt haben.
Projekt löschen
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Cloud SQL-Notfallwiederherstellung
- Notfallwiederherstellung für MySQL in Compute Engine
- Mehr über Architekturen zur Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center