Questo documento descrive i nodi single-tenant. Per informazioni su come eseguire il provisioning delle VM sui nodi single-tenant, consulta Provisioning delle VM sui nodi single-tenant.
La modalità single-tenancy ti consente di avere accesso esclusivo a un nodo single-tenant, ovvero un server fisico Compute Engine dedicato all'hosting solo delle VM del tuo progetto. Utilizza i nodi single-tenant per mantenere le tue VM fisicamente separate dalle VM di altri progetti o per raggrupparle sullo stesso hardware host, come mostrato nel seguente diagramma. Puoi anche creare un gruppo di nodi di proprietà esclusiva e specificare se vuoi condividerlo con altri progetti o con l'intera organizzazione.

Le VM in esecuzione su nodi single-tenant possono utilizzare le stesse funzionalità di Compute Engine delle altre VM, tra cui la pianificazione trasparente e l'archiviazione a blocchi, ma con un livello aggiuntivo di isolamento hardware. Per darti il pieno controllo sulle VM sul server fisico, ogni nodo single-tenant mantiene una mappatura uno a uno con il server fisico di supporto del nodo.
All'interno di un nodo single-tenant, puoi eseguire il provisioning di più VM su tipi di macchine di varie dimensioni, il che ti consente di utilizzare in modo efficiente le risorse sottostanti dell'hardware host dedicato. Inoltre, se scegli di non condividere l'hardware dell'host con altri progetti, puoi soddisfare i requisiti di sicurezza o conformità con i carichi di lavoro che richiedono l'isolamento fisico da altri carichi di lavoro o VM. Se il tuo carico di lavoro richiede la proprietà esclusiva solo temporaneamente, puoi modificare la proprietà esclusiva della VM in base alle necessità.
I nodi single-tenant possono aiutarti a soddisfare i requisiti hardware dedicati per gli scenari BYOL (Bring Your Own License) che richiedono licenze per core o per processore. Quando utilizzi i nodi monoproprietario, hai una certa visibilità sull'hardware sottostante, il che ti consente di monitorare l'utilizzo del core e del processore. Per monitorare questo utilizzo, Compute Engine registra l'ID del server fisico su cui è pianificata una VM. Poi, utilizzando Cloud Logging, puoi visualizzare l'utilizzo storico del server di una VM.
Per ottimizzare l'utilizzo dell'hardware host, puoi:
Tramite un criterio di manutenzione dell'host configurabile, puoi controllare il comportamento delle VM single-tenant mentre l'host è in manutenzione. Puoi specificare quando avviene la manutenzione e se le VM mantengono l'affinità con un server fisico specifico o vengono spostate in altri nodi single-tenant all'interno di un gruppo di nodi.
Considerazioni sul workload
I seguenti tipi di carichi di lavoro potrebbero trarre vantaggio dall'utilizzo di nodi single-tenant:
Carichi di lavoro di gioco con requisiti di prestazioni.
Carichi di lavoro finanziari o sanitari con requisiti di sicurezza e conformità.
Workload Windows con requisiti di licenza.
Carichi di lavoro di machine learning, elaborazione di dati o rendering di immagini. Per questi carichi di lavoro, valuta la possibilità di prenotare GPU.
Carichi di lavoro che richiedono un aumento operazioni di I/O al secondo (IOPS) e una minore latenza oppure carichi di lavoro che utilizzano spazio di archiviazione temporaneo sotto forma di cache, spazio di elaborazione o dati di basso valore. Per questi carichi di lavoro, valuta la possibilità di prenotare SSD locali.
Modelli di nodo
Un modello di nodo è una risorsa di regione che definisce le proprietà di ciascun nodo in un gruppo di nodi. Quando crei un gruppo di nodi da un modello di nodo, le proprietà del modello di nodo vengono copiate in modo immutabile in ogni nodo del gruppo di nodi.
Quando crei un modello di nodo, devi specificare un tipo di nodo. Facoltativamente, puoi specificare le etichette di affinità dei nodi quando crei un modello di nodo. Puoi specificare le etichette di affinità dei nodi solo in un modello di nodo. Non puoi specificare le etichette di affinità dei nodi su un gruppo di nodi.
Tipi di nodo
Quando configuri un modello di nodo, specifica un tipo di nodo da applicare a tutti i nodi all'interno di un gruppo di nodi creato in base al modello. Il tipo di nodo single-tenant, a cui fa riferimento il modello di nodo, specifica la quantità totale di core vCPU e memoria per i nodi creati nei gruppi di nodi che utilizzano il modello. Ad esempio, il tipo di nodo n2-node-80-640 ha 80 vCPU e 640 GB di memoria.
Le VM aggiunte a un nodo single-tenant devono avere lo stesso tipo di macchina del tipo di nodo specificato nel modello di nodo. Ad esempio, i tipi di nodi n2
single-tenant sono compatibili solo con le VM create con il tipo di macchina n2. Puoi aggiungere VM a un nodo single-tenant finché la quantità totale di vCPU o memoria non supera la capacità del nodo.
Quando crei un gruppo di nodi utilizzando un modello di nodo, ogni nodo del gruppo eredita le specifiche del tipo di nodo del modello. Un tipo di nodo si applica a ogni singolo nodo all'interno di un gruppo di nodi, non a tutti i nodi del gruppo in modo uniforme. Pertanto, se crei un gruppo di nodi con due nodi entrambi di tipo n2-node-80-640, a ogni nodo vengono allocate 80 vCPU e 640 GB di memoria.
A seconda dei requisiti del carico di lavoro, puoi riempire il nodo con più VM più piccole in esecuzione su tipi di macchine di varie dimensioni, inclusi tipi di macchine predefinite, tipi di macchine personalizzate e tipi di macchine con memoria estesa. Quando un nodo è pieno, non puoi pianificare altre VM su quel nodo.
La tabella seguente mostra i tipi di nodi disponibili. Per visualizzare un elenco dei tipi di nodi disponibili per il tuo progetto, esegui il comando gcloud compute sole-tenancy
node-types list o crea una richiesta REST nodeTypes.list.
| Tipo di nodo | Processore | vCPU | GB | vCPU:GB | Socket | Cores:Socket | Core totali |
|---|---|---|---|---|---|---|---|
c2-node-60-240 |
Cascade Lake | 60 | 240 | 1:4 | 2 | 18 | 36 |
c3-node-176-352 |
Sapphire Rapids | 176 | 352 | 1:2 | 2 | 48 | 96 |
c3-node-176-704 |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 |
c3-node-176-1408 |
Sapphire Rapids | 176 | 1408 | 1:8 | 2 | 48 | 96 |
c3d-node-360-708 |
AMD EPYC Genoa | 360 | 708 | 1:2 | 2 | 96 | 192 |
c3d-node-360-1440 |
AMD EPYC Genoa | 360 | 1440 | 1:4 | 2 | 96 | 192 |
c3d-node-360-2880 |
AMD EPYC Genoa | 360 | 2880 | 1:8 | 2 | 96 | 192 |
c4-node-192-384 |
Emerald Rapids | 192 | 384 | 1:2 | 2 | 52 | 104 |
c4-node-192-720 |
Emerald Rapids | 192 | 720 | 1:3,75 | 2 | 52 | 104 |
c4-node-192-1488 |
Emerald Rapids | 192 | 1488 | 1:7,75 | 2 | 52 | 104 |
c4a-node-72-144 |
Google Axion | 72 | 144 | 1:2 | 2 | 1 | 72 |
c4a-node-72-288 |
Google Axion | 72 | 288 | 1:4 | 2 | 1 | 72 |
c4a-node-72-576 |
Google Axion | 72 | 576 | 1:8 | 2 | 1 | 72 |
g2-node-96-384 |
Cascade Lake | 96 | 384 | 1:4 | 2 | 28 | 56 |
g2-node-96-432 |
Cascade Lake | 96 | 432 | 1:4,5 | 2 | 28 | 56 |
h3-node-88-352 |
Sapphire Rapids | 88 | 352 | 1:4 | 2 | 48 | 96 |
m1-node-96-1433 |
Skylake | 96 | 1433 | 1:14,93 | 2 | 28 | 56 |
m1-node-160-3844 |
Broadwell E7 | 160 | 3844 | 1:24 | 4 | 22 | 88 |
m2-node-416-8832 |
Cascade Lake | 416 | 8832 | 1:21,23 | 8 | 28 | 224 |
m2-node-416-11776 |
Cascade Lake | 416 | 11776 | 1:28,31 | 8 | 28 | 224 |
m3-node-128-1952 |
Ice Lake | 128 | 1952 | 1:15,25 | 2 | 36 | 72 |
m3-node-128-3904 |
Ice Lake | 128 | 3904 | 1:30,5 | 2 | 36 | 72 |
n1-node-96-624 |
Skylake | 96 | 624 | 1:6,5 | 2 | 28 | 56 |
n2-node-80-640 |
Cascade Lake | 80 | 640 | 1:8 | 2 | 24 | 48 |
n2-node-128-864 |
Ice Lake | 128 | 864 | 1:6,75 | 2 | 36 | 72 |
n2d-node-224-896 |
AMD EPYC Rome | 224 | 896 | 1:4 | 2 | 64 | 128 |
n2d-node-224-1792 |
AMD EPYC Milan | 224 | 1792 | 1:8 | 2 | 64 | 128 |
Per informazioni sui prezzi di questi tipi di nodi, consulta la sezione Prezzi dei nodi single-tenant.
Tutti i nodi ti consentono di pianificare VM di forme diverse. I nodi di tipo n sono
nodi di uso generale su cui puoi pianificare VM con tipo di macchina personalizzata. Per consigli su quale tipo di nodo scegliere, consulta la sezione Consigli sui tipi di macchine.
Per informazioni sul rendimento, consulta Piattaforme CPU.
Gruppi di nodi e provisioning delle VM
I modelli di nodi single-tenant definiscono le proprietà di un gruppo di nodi e devi creare un modello di nodo prima di creare un gruppo di nodi in una zona Google Cloud. Quando crei un gruppo, specifica il criterio di manutenzione dell'host per le VM nel gruppo di nodi, il numero di nodi per il gruppo di nodi e se condividerlo con altri progetti o con l'intera organizzazione.
Un gruppo di nodi può avere zero o più nodi. Ad esempio, puoi ridurre a zero il numero di nodi in un gruppo di nodi quando non devi eseguire VM sui nodi del gruppo oppure puoi attivare il gestore della scalabilità automatica del gruppo di nodi per gestire automaticamente le dimensioni del gruppo di nodi.
Prima di eseguire il provisioning delle VM sui nodi single-tenant, devi creare un gruppo di nodi single-tenant. Un gruppo di nodi è un insieme omogeneo di nodi single-tenant in una zona specifica. I gruppi di nodi possono contenere più VM in esecuzione su tipi di macchine di varie dimensioni, purché il tipo di macchina abbia due o più vCPU.
Quando crei un gruppo di nodi, abilita la scalabilità automatica in modo che le dimensioni del gruppo si aggiustino automaticamente in base ai requisiti del tuo carico di lavoro. Se i requisiti del tuo workload sono statici, puoi specificare manualmente la dimensione del gruppo di nodi.
Dopo aver creato un gruppo di nodi, puoi eseguire il provisioning delle VM nel gruppo o su un nodo specifico al suo interno. Per un maggiore controllo, utilizza le etichette di affinità nodo per pianificare le VM su qualsiasi nodo con etichette di affinità corrispondenti.
Dopo aver eseguito il provisioning delle VM sui gruppi di nodi e, facoltativamente, aver assegnato etichette di affinità per eseguire il provisioning delle VM su gruppi di nodi o nodi specifici, ti consigliamo di etichettare le risorse per gestire più facilmente le VM. Le etichette sono coppie chiave/valore che possono aiutarti a classificare le VM in modo da poterle visualizzare in modo aggregato per motivi quali la fatturazione. Ad esempio, puoi utilizzare le etichette per contrassegnare il ruolo di una VM, il relativo tenant, il tipo di licenza o la sua posizione.
Criterio di manutenzione dell'host
A seconda degli scenari di licenza e dei carichi di lavoro, potresti voler limitare il numero di core fisici utilizzati dalle VM. Il criterio di manutenzione dell'host scelto potrebbe dipendere, ad esempio, dai requisiti di licenza o conformità oppure potresti scegliere un criterio che ti consenta di limitare l'utilizzo dei server fisici. Con tutti questi criteri, le VM rimangono su hardware dedicato.
Quando pianifichi le VM su nodi single-tenant, puoi scegliere tra le seguenti tre diverse opzioni di criteri di manutenzione dell'host, che ti consentono di determinare in che modo e se Compute Engine esegue la migrazione live delle VM durante gli eventi dell'host, che si verificano circa ogni 4-6 settimane. Durante la manutenzione, Compute Engine esegue la migrazione live, come gruppo, di tutte le VM sull'host a un altro nodo single-tenant, ma in alcuni casi, Compute Engine potrebbe suddividere le VM in gruppi più piccoli ed eseguire la migrazione live di ogni gruppo più piccolo di VM a nodi single-tenant separati.
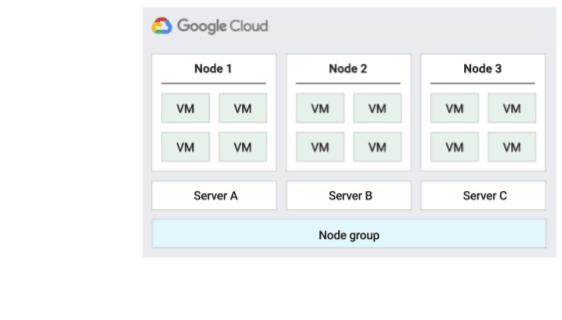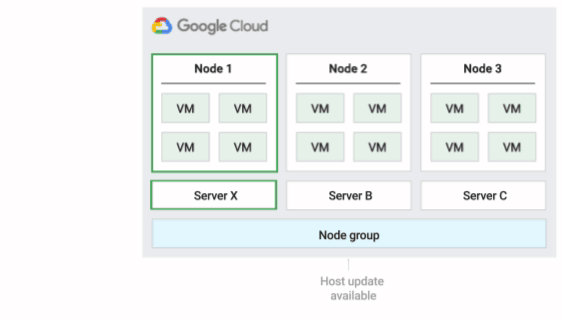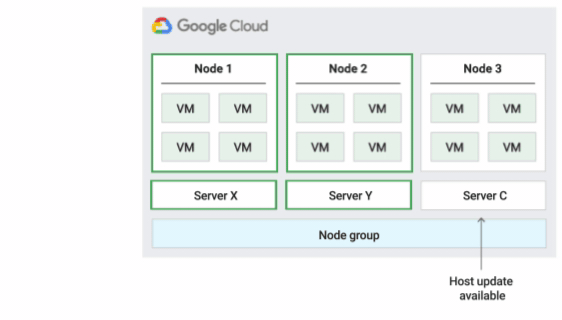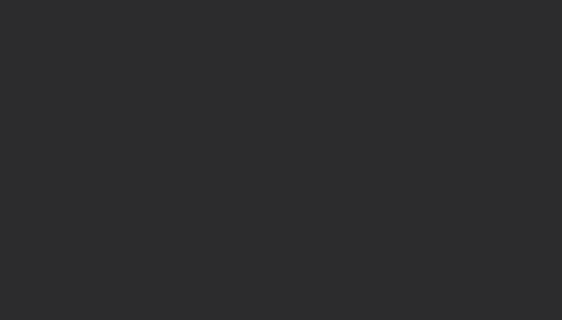
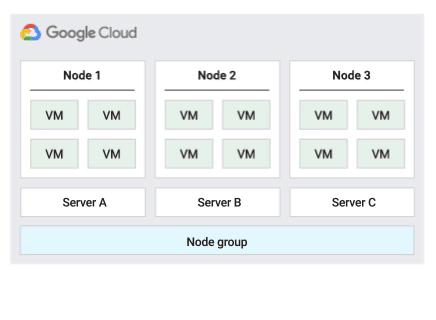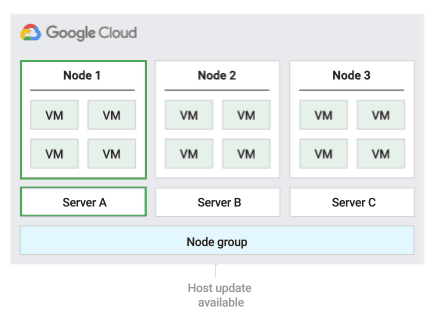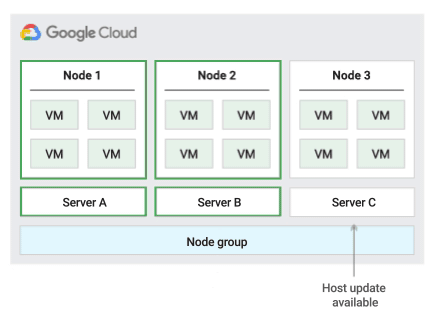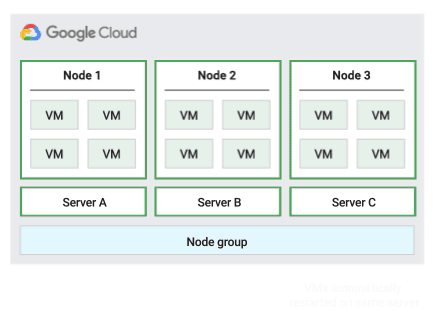
Criterio di manutenzione dell'host predefinito
Si tratta del criterio di manutenzione dell'host predefinito e le VM nei gruppi di nodi configurati con questo criterio seguono il comportamento di manutenzione tradizionale per le VM non single-tenant. In altre parole, a seconda dell'impostazione della manutenzione on-host dell'host della VM, le VM eseguono la migrazione live a un nuovo nodo single-tenant nel gruppo di nodi prima di un evento di manutenzione dell'host e questo nuovo nodo single-tenant esegue solo le VM del cliente.
Questo criterio è più adatto per le licenze per utente o per dispositivo che richiedono la migrazione live durante gli eventi host. Questa impostazione non limita la migrazione delle VM all'interno di un pool fisso di server fisici ed è consigliata per i carichi di lavoro generali senza requisiti di server fisici e che non richiedono licenze esistenti.
Poiché le VM vengono migrate in tempo reale su qualsiasi server senza considerare l'affinità esistente del server con questo criterio, questo criterio non è adatto per gli scenari che richiedono la minimizzazione dell'utilizzo dei core fisici durante gli eventi host.
La figura seguente mostra un'animazione del criterio di manutenzione dell'host Predefinito.
Criterio di manutenzione dell'host di riavvio in situ
Quando utilizzi questo criterio di manutenzione dell'host, Compute Engine arresta le VM durante gli eventi dell'host e poi le riavvia sullo stesso server fisico dopo l'evento. Quando utilizzi questo criterio, devi impostare l'impostazione di manutenzione sull'host della VM su
TERMINATE.
Questo criterio è più adatto per i carichi di lavoro a tolleranza di errore che possono subire circa un'ora di tempo di riposo durante gli eventi host, i carichi di lavoro che devono rimanere sullo stesso server fisico, i carichi di lavoro che non richiedono la migrazione live o se disponi di licenze basate sul numero di core o processori fisici.
Con questo criterio, l'istanza può essere assegnata al gruppo di nodi utilizzando node-name, node-group-name o l'etichetta di affinità nodo.
La figura seguente mostra un'animazione del criterio di manutenzione Riavvia in situ.
Criterio di manutenzione dell'host per la migrazione all'interno del gruppo di nodi
Quando utilizzi questo criterio di manutenzione dell'host, Compute Engine esegue la migrazione live delle VM all'interno di un gruppo di server fisici di dimensioni fisse durante gli eventi dell'host, il che contribuisce a limitare il numero di server fisici univoci utilizzati dalla VM.
Questo criterio è più adatto per i carichi di lavoro con disponibilità elevata e licenze basate sul numero di core o processori fisici, perché con questo criterio di manutenzione dell'host ogni nodo single-tenant del gruppo è bloccato su un insieme fisso di server fisici, diversamente dal criterio predefinito che consente alle VM di eseguire la migrazione su qualsiasi server.
Per garantire la capacità per la migrazione live, Compute Engine riserva 1 nodo inutilizzato per ogni 20 nodi prenotati. La tabella seguente mostra quanti nodi di riserva vengono riservati da Compute Engine in base al numero di nodi riservati per il gruppo di nodi.
| Nodi totali nel gruppo | Nodi in blocco riservati per la migrazione live |
|---|---|
| 1 | Non applicabile. Devi prenotare almeno 2 nodi. |
| Da 2 a 20 | 1 |
| 21-40 | 2 |
| Da 41 a 60 | 3 |
| Da 61 a 80 | 4 |
| Da 81 a 100 | 5 |
Con questo criterio, ogni istanza deve avere come target un singolo gruppo di nodi utilizzando l'node-group-nameetichetta di affinità e non può essere assegnata a nessun nodo specificonode-name. Questo è necessario per consentire a Compute Engine di eseguire la migrazione live delle VM al nodo di blocco quando si verifica un evento host. Tieni presente che le VM possono utilizzare qualsiasi etichetta di affinità dei nodi personalizzata, a condizione che sia assegnata node-group-name e non node-name.
La figura seguente mostra un'animazione del criterio di manutenzione dell'host Esegui la migrazione all'interno del gruppo di nodi.

Periodi di manutenzione
Se gestisci carichi di lavoro, ad esempio database ottimizzati, che potrebbero essere sensibili all'impatto sulle prestazioni della migrazione live, puoi determinare quando inizia la manutenzione in un gruppo di nodi single-tenant specificando un periodo di manutenzione al momento della creazione del gruppo di nodi. Non puoi modificare il periodo di manutenzione dopo aver creato il gruppo di nodi.
I periodi di manutenzione sono intervalli di tempo di 4 ore che puoi utilizzare per specificare quando Google esegue la manutenzione sulle VM monoutente. Gli eventi di manutenzione si verificano circa una volta ogni 4-6 settimane.
Il periodo di manutenzione si applica a tutte le VM del gruppo di nodi sole-tenant e specifica solo quando inizia la manutenzione. Non è garantito che la manutenzione venga completata durante il periodo di manutenzione e non è garantita la frequenza con cui viene eseguita. I periodi di manutenzione non sono supportati per i gruppi di nodi con il criterio di manutenzione dell'host Esegui la migrazione all'interno del gruppo di nodi.
Simulare un evento di manutenzione dell'host
Puoi simulare un evento di manutenzione dell'host per verificare il comportamento dei carichi di lavoro in esecuzione sui nodi single-tenant durante un evento di manutenzione dell'host. In questo modo puoi vedere gli effetti del criterio di manutenzione dell'host della VM single-tenant sulle applicazioni in esecuzione sulle VM.
Errori dell'host
In caso di un raro guasto hardware critico sull'host, sia monoutente che multiutente, Compute Engine esegue le seguenti operazioni:
Ritira il server fisico e il relativo identificatore univoco.
Revoca l'accesso del progetto al server fisico.
Sostituisce l'hardware guasto con un nuovo server fisico con un nuovo identificatore unico.
Sposta le VM dall'hardware non funzionante al nodo sostitutivo.
Riavvia le VM interessate se le hai configurate per il riavvio automatico.
Affinità e anti-affinità dei nodi
I nodi single-tenant assicurano che le VM non condividano l'host con le VM di altri progetti, a meno che non utilizzi gruppi di nodi single-tenant condivisi. Con i gruppi di nodi single-tenant condivisi, altri progetti all'interno dell'organizzazione possono eseguire il provisioning delle VM sullo stesso host. Tuttavia, potresti comunque voler raggruppare più carichi di lavoro sullo stesso nodo single-tenant o isolarli l'uno dall'altro su nodi diversi. Ad esempio, per contribuire a soddisfare alcuni requisiti di conformità, potresti dover utilizzare le etichette di affinità per separare i carichi di lavoro sensibili da quelli non sensibili.
Quando crei una VM, richiedi la proprietà esclusiva specificando l'affinità dei nodi o l'anti-affinità, facendo riferimento a una o più etichette di affinità dei nodi. Specifichi le etichette di affinità dei nodi personalizzate quando crei un modello di nodo e Compute Engine include automaticamente alcune etichette di affinità predefinite su ogni nodo. Se specifichi l'affinità quando crei una VM, puoi pianificare le VM insieme su un nodo o su più nodi specifici in un gruppo di nodi. Se specifichi l'anti-affinità quando crei una VM, puoi assicurarti che determinate VM non vengano pianificate insieme sullo stesso nodo o sugli stessi nodi in un gruppo di nodi.
Le etichette di affinità nodo sono coppie chiave-valore assegnate ai nodi e vengono ereditate da un modello di nodo. Le etichette di affinità ti consentono di:
- Controlla in che modo le singole istanze VM vengono assegnate ai nodi.
- Controlla in che modo le istanze VM create da un modello, ad esempio quelle create da un gruppo di istanze gestite, vengono assegnate ai nodi.
- Raggruppa le istanze VM sensibili su nodi o gruppi di nodi specifici, separati dalle altre VM.
Etichette di affinità predefinite
Compute Engine assegna le seguenti etichette di affinità predefinite a ciascun nodo:
- Un'etichetta per il nome del gruppo di nodi:
- Chiave:
compute.googleapis.com/node-group-name - Valore: il nome del gruppo di nodi.
- Chiave:
- Un'etichetta per il nome del nodo:
- Chiave:
compute.googleapis.com/node-name - Valore: nome del singolo nodo.
- Chiave:
- Un'etichetta per i progetti con cui è condiviso il gruppo di nodi:
- Chiave:
compute.googleapis.com/projects - Valore: ID del progetto contenente il gruppo di nodi.
- Chiave:
Etichette di affinità personalizzata
Puoi creare etichette di affinità dei nodi personalizzate quando crei un modello di nodo. Queste etichette di affinità vengono assegnate a tutti i nodi dei gruppi di nodi creati dal modello di nodo. Non puoi aggiungere altre etichette di affinità personalizzate ai nodi di un gruppo di nodi dopo aver creato il gruppo.
Per informazioni su come utilizzare le etichette di affinità, consulta Configurare l'affinità dei nodi.
Prezzi
Per aiutarti a ridurre al minimo il costo dei tuoi nodi di proprietà, Compute Engine fornisce sconti per impegno di utilizzo e sconti per utilizzo sostenuto. Inoltre, poiché ti viene già addebitato il costo delle vCPU e della memoria dei tuoi nodi single-tenant, non paghi un extra per le VM sui tuoi nodi single-tenant.
Se esegui il provisioning di nodi single-tenant con GPU o SSD locali, ti viene addebitato il costo di tutte le GPU o SSD locali su ogni nodo di cui esegui il provisioning. Il supplemento per l'uso esclusivo non si applica alle GPU o alle unità SSD locali.
Disponibilità
I nodi single-tenant sono disponibili in determinate zone. Per garantire l'alta disponibilità, pianifica le VM su nodi single-tenant in zone diverse.
Prima di utilizzare GPU o SSD locali su nodi single-tenant, assicurati di disporre di una quota sufficiente di GPU o SSD locali nella zona in cui stai prenotando la risorsa.
Compute Engine supporta le GPU sui tipi di nodi
n1eg2sole-tenant che si trovano nelle zone con supporto GPU. La tabella seguente mostra i tipi di GPU che puoi collegare ai nodin1eg2e il numero di GPU da collegare quando crei il modello di nodo.Tipo di GPU Quantità di GPU Tipo di nodo single-tenant NVIDIA L4 8 g2NVIDIA P100 4 n1NVIDIA P4 4 n1NVIDIA T4 4 n1NVIDIA V100 8 n1Compute Engine supporta le unità SSD locali sui tipi di nodi
n1,n2,n2deg2proprietari che si trovano in zone con supporto delle SSD locali.
Limitazioni
Non puoi utilizzare le VM sole-tenant con le seguenti serie e tipi di macchine: T2D, T2A, E2, C2D, A2, A3 o istanze bare metal.
Le VM single-tenant non possono specificare una piattaforma CPU minima.
Non puoi eseguire la migrazione di una VM a un nodo di proprietà singola se la VM specifica una piattaforma CPU minima. Per eseguire la migrazione di una VM a un nodo di proprietà esclusiva, rimuovi la specifica della piattaforma CPU minima impostandola su automatica prima di aggiornare le etichette di affinità dei nodi della VM.
I nodi single-tenant non supportano le istanze VM prerilasciabili.
Per informazioni sulle limitazioni dell'utilizzo delle unità SSD locali sui nodi di proprietà singola, consulta Persistenza dei dati delle unità SSD locali.
Per informazioni su come l'utilizzo delle GPU influisce sulla migrazione live, consulta le limitazioni della migrazione live.
I nodi single-tenant con GPU non supportano le VM senza GPU.
- I nodi single-tenant C3 e C3D non supportano l'overcommit delle CPU.
I nodi single-tenant C3 non supportano configurazioni diverse delle VM C3 sullo stesso nodo single-tenant. Ad esempio, non puoi posizionare una VM
c3-standardsullo stesso nodo single-tenant di una VMc3-highmem.Non puoi aggiornare il criterio di manutenzione in un gruppo di nodi attivo.
Configurazioni VM supportate dai nodi single-tenant M3
La proprietà esclusiva supporta le seguenti configurazioni VM per i nodi single-tenant M3:
Su un nodo
m3-node-128-3904, la proprietà esclusiva supporta le seguenti configurazioni VM:- 1 x
m3-ultramem-128 - 2 x
m3-ultramem-64 - 1 x
m3-megamem-128 - 2 x
m3-megamem-64
Se vuoi eseguire istanze VM
m3-ultramem-32, puoi farlo nelle seguenti configurazioni:- 1 x
m3-ultramem-64(o 1 xm3-megamem-64) + 1 xm3-ultramem-32 - 2 x
m3-ultramem-32
- 1 x
Su un nodo
m3-node-128-1952, la proprietà esclusiva supporta le seguenti configurazioni VM:- 2 x
m3-ultramem-32 - 1 x
m3-megamem-128 - 2 x
m3-megamem-64
Se vuoi eseguire istanze VM
m3-ultramem-32, puoi farlo nelle seguenti configurazioni:- 1 x
m3-megamem-64+ 1 xm3-ultramem-32 - 2 x
m3-ultramem-32
- 2 x
Passaggi successivi
- Scopri come eseguire l'overcommit delle CPU su VM single-tenant.
Scopri come utilizzare le licenze che hai già.
Consulta le nostre best practice per l'utilizzo di nodi monoproprietario per eseguire carichi di lavoro VM.