이 튜토리얼에서는 Compute Engine에서 실행되는 NVIDIA TensorRT5 GPU를 이용해 대규모 워크로드에서 딥 러닝 추론을 실행하는 방법을 설명합니다.
시작하기 전에 알아두어야 할 몇 가지 필수 정보가 있습니다.
- 딥 러닝 추론은 학습된 모델을 이용해 결과를 인식하고, 처리하고, 분류하는 머신러닝 프로세스의 한 단계입니다.
- NVIDIA TensorRT는 딥 러닝 작업 부하 실행에 최적화된 플랫폼입니다.
- GPU는 머신러닝과 데이터 처리 같은 데이터 집약적인 작업 부하의 속도를 높이는 데 사용됩니다. 다양한 NVIDIA GPU를 Compute Engine에서 사용할 수 있습니다. 이 튜토리얼에서는 딥 러닝 추론 워크로드를 위해 특별히 설계된 T4 GPU를 사용합니다.
목표
이 튜토리얼에서는 다음 절차를 다룹니다.
- 선행 학습된 그래프를 이용한 모델을 준비합니다.
- 최적화 모드가 다양하게 갖춰진 모델의 추론 속도를 테스트합니다.
- 커스텀 모델을 TensorRT로 변환합니다.
- 멀티 영역 클러스터를 설정합니다. 멀티 영역 클러스터를 다음과 같이 구성됩니다.
- Deep Learning VM 이미지를 기반으로 구축합니다. 이러한 이미지는 TensorFlow, TensorFlow Serving, TensorRT5와 함께 사전 설치됩니다.
- 자동 확장을 사용 설정합니다. 이 튜토리얼에서 자동 확장은 GPU 사용률을 바탕으로 합니다.
- 부하 분산을 사용 설정합니다.
- 방화벽을 사용 설정합니다.
- 멀티 영역 클러스터에서 추론 워크로드를 실행합니다.
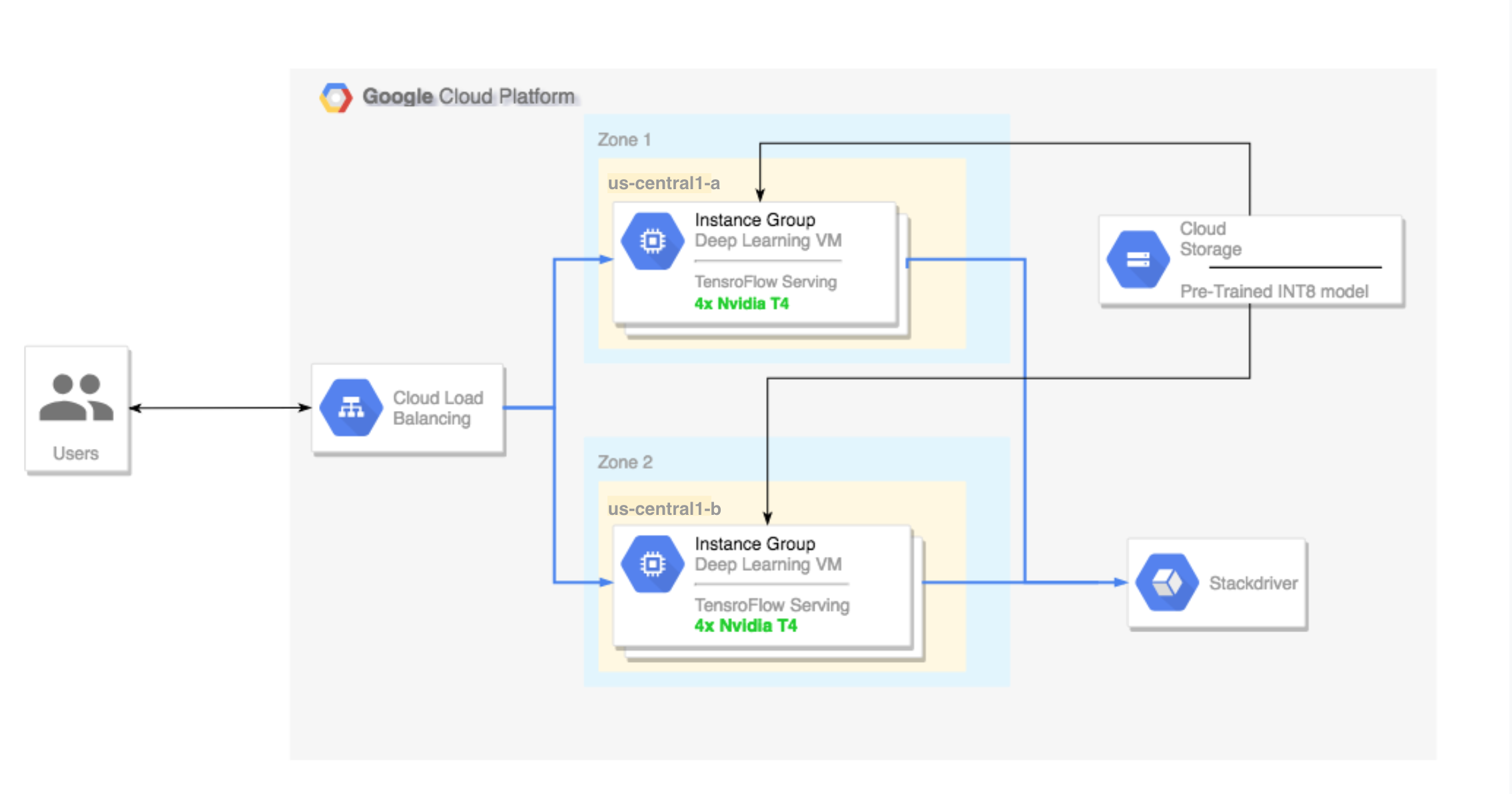
기본 요건
프로젝트 설정
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - 최신 버전의 Google Cloud CLI를 설치하거나 업데이트합니다.
- (선택사항) 기본 리전 및 영역을 설정합니다.
도구 설정
이 튜토리얼에서 Google Cloud CLI를 사용하려면 다음 안내를 따르세요.
모델 준비
이 섹션에서는 모델을 실행하기 위해 사용되는 가상 머신(VM) 인스턴스 생성을 설명합니다. 또한 TensorFlow 공식 모델 카탈로그에서 모델을 다운로드하는 방법도 설명합니다.
VM 인스턴스를 만듭니다. 이 튜토리얼은
tf-ent-2-10-cu113을 사용하여 생성됩니다. 최신 이미지 버전은 Deep Learning VM Image 문서의 운영체제 선택을 참조하세요.export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
모델을 선택합니다. 이 튜토리얼에서는 ResNet 모델을 사용합니다. 이 ResNet 모델은 TensorFlow에 있는 ImageNet 데이터세트에서 학습됩니다.
ResNet 모델을 VM 인스턴스에 다운로드하려면 다음 명령어를 실행하세요.
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
ResNet 모델의 위치를
$WORKDIR변수에 저장합니다.MODEL_LOCATION을 다운로드한 모델이 포함된 작업 디렉터리로 바꿉니다.export WORKDIR=MODEL_LOCATION
추론 속도 테스트 실행
이 섹션에서는 다음 절차를 설명합니다.
- ResNet 모델 설정
- 다양한 최적화 모드에서 추론 테스트 실행
- 추론 테스트 결과 검토
테스트 과정 개요
TensorRT도 추론 워크로드의 성능 속도를 개선할 수 있지만, 가장 중요한 개선은 양자화 프로세스를 통해 제공됩니다.
모델 양자화는 모델 가중치의 정밀도를 줄이는 과정입니다. 예를 들어 모델의 초기 가중치가 FP32라면 정밀도를 FP16, INT8 또는 INT4까지 줄일 수 있습니다. 모델의 속도(가중치의 정밀도)와 정확성 간의 적절한 절충안을 선택하는 것이 중요합니다. 다행히 TensorFlow에는 정확성을 속도 또는 처리량, 지연 시간, 노드 전환율, 총 학습 시간 같은 다른 측정항목과 비교해 측정하는 기능이 포함됩니다.
절차
ResNet 모델을 설정합니다. 모델을 설정하려면 다음 명령어를 실행하세요.
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
테스트를 실행합니다. 이 명령어는 완료하는 데 다소 시간이 걸릴 수 있습니다.
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
각 항목의 의미는 다음과 같습니다.
$WORKDIR은 ResNet 모델을 다운로드한 디렉터리입니다.--native인수는 테스트할 다양한 양자화 모드를 의미합니다.
결과를 검토합니다. 테스트가 완료되면 각 최적화 모드에 대한 추론 결과를 비교할 수 있습니다.
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
전체 결과를 보려면 다음 명령어를 실행하세요.
cat $WORKDIR/log.txt

결과에서 FP32와 FP16이 동일함을 알 수 있습니다. 따라서 TensorRT 사용에 익숙하다면 FP16을 바로 사용할 수 있습니다. INT8은 약간 나쁜 결과를 보여줍니다.
또한 TensorRT5를 이용한 모델 실행은 다음과 같은 결과를 표시합니다.
- FP32 최적화를 이용하면 처리량이 314fps에서 440fps로 40% 증가합니다. 동시에 지연 시간은 0.40ms에서 약 30% 감소해 0.28ms가 됩니다.
- 기본 TensorFlow 그래프 대신 FP16 최적화를 사용하면 속도가 214% 증가해 314fps에서 988fps가 됩니다. 동시에 지연 시간은 약 3배 감소해 0.12ms가 됩니다.
- INT8을 이용하면 속도는 385% 상승해 314fps에서 1524fps로 증가하고, 지연 시간은 0.08ms로 감소합니다.
커스텀 모델을 TensorRT로 변환
이 변환에는 INT8 모델을 사용할 수 있습니다.
모델을 다운로드합니다. 커스텀 모델을 TensorRT 그래프로 변환하려면 저장된 모델이 있어야 합니다. 저장된 INT8 ResNet 모델을 얻으려면 다음 명령어를 실행하세요.
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
TFTools를 이용해 모델을 TensorRT 그래프로 변환합니다. TFTools를 이용해 모델을 변환하려면 다음 명령어를 실행하세요.
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
이제
$WORKDIR/resnet_v2_int8_NCHW/00001디렉터리에 INT8 모델이 생겼습니다.모든 요소가 제대로 설정되었는지 확인하기 위해 추론 테스트를 실행해 보세요.
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
모델을 Cloud Storage에 업로드합니다. 다음 섹션에서 설정하는 멀티 영역 클러스터에서 모델을 사용하려면 이 단계를 꼭 실행해야 합니다. 모델을 업로드하려면 다음 단계를 완료하세요.
모델을 보관처리합니다.
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
보관 파일을 업로드합니다.
GCS_PATH를 Cloud Storage 버킷 경로로 바꿉니다.export GCS_PATH=GCS_PATH gcloud storage cp model.tar.gz $GCS_PATH
필요하다면 다음 URL을 이용해 Cloud Storage에서 INT8 고정 그래프를 얻을 수도 있습니다.
gs://cloud-samples-data/dlvm/t4/model.tar.gz
멀티 영역 클러스터 설정
이 섹션에서는 멀티 영역 클러스터를 설정하는 동안 따라야 하는 단계를 설명합니다.
클러스터 만들기
이제 Cloud Storage 플랫폼에 모델이 있으므로 클러스터를 만들 수 있습니다.
인스턴스 템플릿을 만듭니다. 인스턴스 템플릿은 새 인스턴스를 만드는 데 유용한 리소스입니다. 자세한 내용은 인스턴스 템플릿을 참조하세요.
YOUR_PROJECT_NAME는 프로젝트 ID로 바꿉니다.export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- 이 인스턴스 템플릿에는 메타데이터 파라미터로 지정된 시작 스크립트가 포함되어 있습니다.
- 인스턴스 생성 중 이 템플릿을 사용하는 모든 인스턴스에서 이 시작 스크립트를 실행합니다.
- 이 시작 스크립트는 다음 단계를 수행합니다.
- 인스턴스의 GPU 사용량을 모니터링하는 모니터링 에이전트를 설치합니다.
- 모델을 다운로드합니다.
- 추론 서비스를 시작합니다.
- 시작 스크립트에서
tf_serve.py는 추론 로직을 포함합니다. 이 예시에는 TFServe 패키지를 기반으로 하는 아주 작은 Python 파일이 포함되어 있습니다. - 시작 스크립트를 보려면 startup_inf_script.sh를 확인하세요.
- 이 인스턴스 템플릿에는 메타데이터 파라미터로 지정된 시작 스크립트가 포함되어 있습니다.
MIG(관리형 인스턴스 그룹)를 만듭니다. 이 관리형 인스턴스 그룹은 특정 영역에 여러 실행 인스턴스를 설정하는 데 필요합니다. 인스턴스는 이전 단계에서 생성된 인스턴스 템플릿을 기반으로 생성됩니다.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
이 인스턴스는 T4 GPU를 지원하는 모든 가용 영역에서 만들 수 있습니다. 영역에 사용 가능한 GPU 할당량이 있는지 확인하세요.
인스턴스 생성에는 다소 시간이 걸립니다. 다음 명령어를 실행하면 진행 상황을 확인할 수 있습니다.
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

관리형 인스턴스 그룹이 생성되면 다음과 비슷한 출력이 표시됩니다.

측정항목을 Google Cloud Cloud Monitoring 페이지에서 사용할 수 있는지 확인합니다.
Google Cloud 콘솔에서 Monitoring 페이지로 이동합니다.
탐색창에 측정항목 탐색기가 표시되면 측정항목 탐색기를 클릭합니다. 아니면 리소스를 선택한 다음 측정항목 탐색기를 선택합니다.
gpu_utilization을 검색합니다.
데이터가 들어오면 다음과 비슷한 내용이 표시됩니다.

자동 확장 사용 설정
관리형 인스턴스 그룹에 자동 확장을 사용 설정합니다.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilization은 측정항목의 전체 경로입니다. 샘플에 레벨 85가 지정되었는데, 이는 GPU 사용률이 85에 도달하면 플랫폼이 그룹에 새 인스턴스를 만든다는 뜻입니다.자동 확장을 테스트합니다. 자동 확장을 테스트하려면 다음 단계를 수행해야 합니다.
- 인스턴스에 SSH를 통해 연결합니다. 자세한 내용은 인스턴스에 연결을 참조하세요.
gpu-burn도구를 이용해 GPU를 600초 동안 100% 사용률로 로드합니다.git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
Cloud Monitoring 페이지를 봅니다. 자동 확장을 관찰합니다. 클러스터는 인스턴스를 추가함으로써 확장됩니다.

Google Cloud 콘솔에서 인스턴스 그룹 페이지로 이동합니다.
deeplearning-instance-group관리형 인스턴스 그룹을 클릭합니다.모니터링 탭을 클릭합니다.
이 시점에서 자동 확장 로직은 운에 의지하지 않고 부하를 줄일 수 있도록 최대한 많은 인스턴스를 회전해야 합니다.

이 시점에서 인스턴스 굽기를 중단하고 시스템이 어떻게 축소되는지 관찰할 수도 있습니다.
부하 분산기 설정
이제까지 확보한 요소를 다시 확인해 보겠습니다.
- TensorRT5(INT8)로 최적화되고 학습된 모델
- 인스턴스의 관리형 그룹. 이러한 인스턴스는 활성화된 GPU 사용률에 따라 자동 확장을 사용 설정합니다.
이제 인스턴스 전면에 부하 분산기를 만들 수 있습니다.
상태 확인을 만듭니다. 상태 확인은 백엔드의 특정 호스트가 트래픽을 처리할 수 있는지를 결정하는 데 사용합니다.
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
인스턴스 그룹과 상태 점검을 포함하는 백엔드 서비스를 만듭니다.
상태 점검을 만듭니다.
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
새 백엔드 서비스에 인스턴스 그룹을 추가합니다.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
전달 URL을 설정합니다. 부하 분산기는 백엔드 서비스에 전달할 수 있는 URL을 파악해야 합니다.
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
부하 분산기를 만듭니다.
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
부하 분산기에 외부 IP 주소를 추가합니다.
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
할당된 IP 주소를 찾습니다.
gcloud compute addresses list
공용 IP 주소의 모든 요청을 부하 분산기로 전달하도록 Google Cloud 에 지시하는 전달 규칙을 설정합니다.
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80전역 전달 규칙을 만든 후 구성이 적용되는 데 몇 분 정도 걸릴 수 있습니다.
방화벽 사용 설정
외부 소스에서 VM 인스턴스로의 연결을 허용하는 방화벽 규칙이 있는지 확인합니다.
gcloud compute firewall-rules list
이러한 연결을 허용하는 방화벽 규칙이 없으면 직접 만들어야 합니다. 방화벽 규칙을 만들려면 다음 명령어를 실행하세요.
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
추론 실행
다음 Python 스크립트를 사용하면 이미지를 서버에 업로드 할 수 있는 형식으로 변환할 수 있습니다.
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))추론을 실행합니다.
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json