Questo tutorial spiega come eseguire inferenze del deep learning su workload su larga scala utilizzando GPU NVIDIA TensorRT5 in esecuzione su Compute Engine.
Prima di iniziare, ecco alcuni elementi essenziali:
- L'inferenza del deep learning è la fase del processo di machine learning in cui viene utilizzato un modello addestrato per riconoscere, elaborare e classificare i risultati.
- NVIDIA TensorRT è una piattaforma ottimizzata per l'esecuzione di workload di deep learning.
- Le GPU vengono utilizzate per accelerare i workload ad alta intensità di dati, come il machine learning e l'elaborazione dei dati. Su Compute Engine sono disponibili diverse GPU NVIDIA. Questo tutorial utilizza GPU T4, poiché sono progettate specificamente per i workload di inferenza del deep learning.
Obiettivi
Questo tutorial illustra le seguenti procedure:
- Preparazione di un modello utilizzando un grafo preaddestrato.
- Test della velocità di inferenza di un modello con diverse modalità di ottimizzazione.
- Conversione di un modello personalizzato in TensorRT.
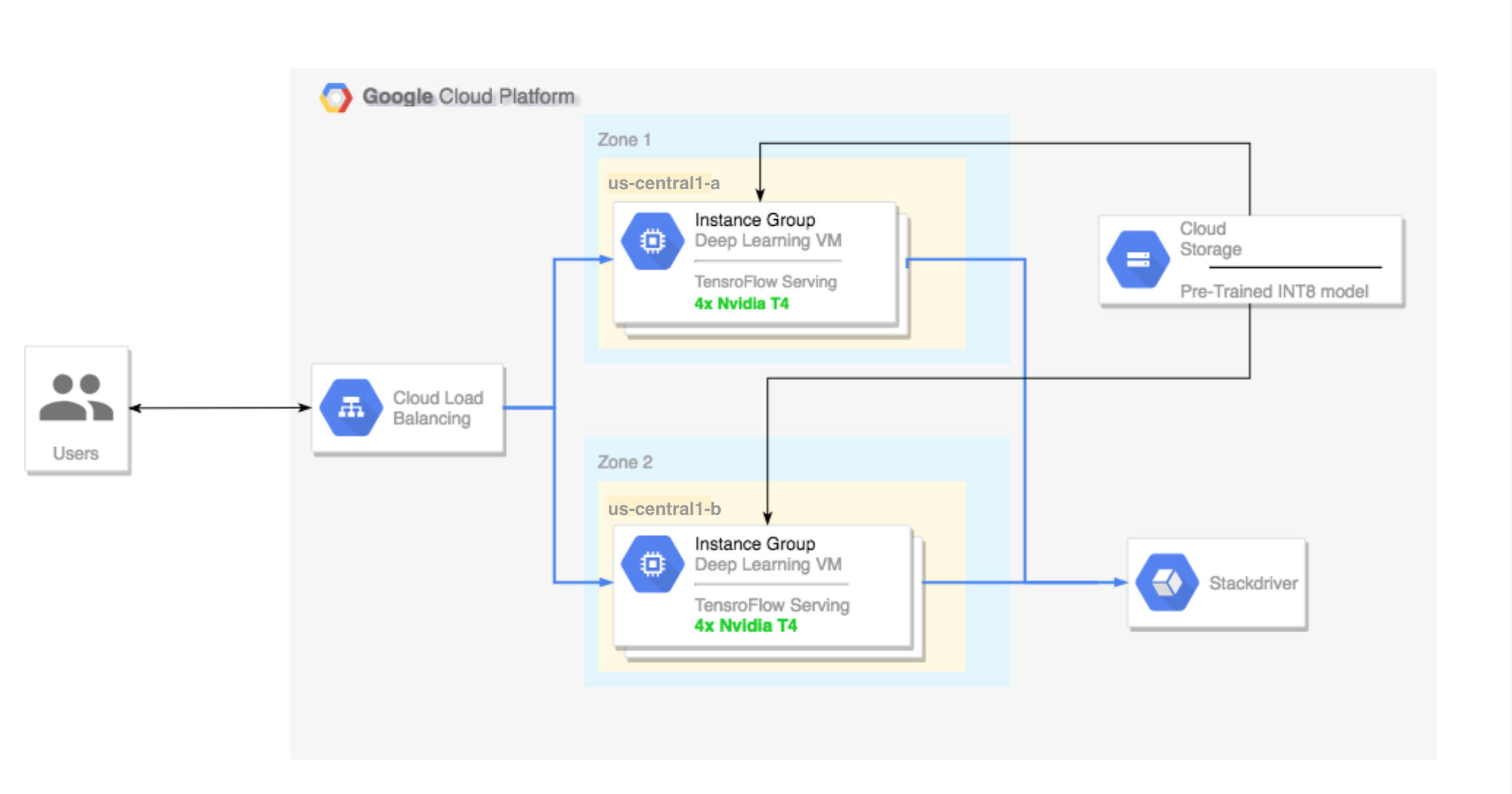
- Configurazione di un cluster multizona. Questo cluster multizona è configurato come segue:
- Creato su immagini Deep Learning VM Image. Queste immagini sono preinstallate con TensorFlow, TensorFlow Serving e TensorRT5.
- Scalabilità automatica abilitata. La scalabilità automatica in questo tutorial si basa sull'utilizzo delle GPU.
- Bilanciamento del carico abilitato.
- Firewall abilitato.
- Esecuzione di un workload di inferenza nel cluster multizona.
Prerequisiti
Configurazione del progetto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Installa o esegui l'aggiornamento all'ultima versione di Google Cloud CLI.
- (Facoltativo) Imposta una regione e una zona predefinite.
Configurazione degli strumenti
Per utilizzare Google Cloud CLI in questo tutorial:
Preparazione del modello
Questa sezione illustra come creare un'istanza di una macchina virtuale (VM) utilizzata per eseguire il modello. Spiega inoltre come scaricare un modello dal catalogo ufficiale dei modelli di TensorFlow
Crea l'istanza VM. Questo tutorial viene creato utilizzando
tf-ent-2-10-cu113. Per le versioni immagine più recenti, consulta Scelta di un sistema operativo nella documentazione di Deep Learning VM Image.export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
Seleziona un modello. Questo tutorial utilizza il modello ResNet. Questo modello è stato addestrato sul set di dati ImageNet in TensorFlow.
Per scaricare il modello ResNet nell'istanza VM, esegui questo comando:
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
Salva la località del modello ResNet nella variabile
$WORKDIR. SostituisciMODEL_LOCATIONcon la directory di lavoro che contiene il modello scaricato.export WORKDIR=MODEL_LOCATION
Esecuzione del test della velocità di inferenza
Questa sezione illustra le seguenti procedure:
- Configurazione del modello ResNet.
- Esecuzione dei test di inferenza in diverse modalità di ottimizzazione.
- Esame dei risultati dei test di inferenza.
Panoramica del processo di test
TensorRT può migliorare la velocità di esecuzione dei workload di inferenza, ma il miglioramento più significativo deriva dal processo di quantizzazione.
La quantizzazione del modello è il processo mediante il quale la precisione dei pesi di un modello viene ridotta. Ad esempio, se il peso iniziale di un modello è FP32, puoi ridurre la precisione a FP16, INT8 o persino INT4. È importante scegliere il giusto compromesso tra velocità (precisione dei pesi) e accuratezza di un modello. Fortunatamente, TensorFlow include funzionalità che fanno esattamente questo, misurando l'accuratezza rispetto alla velocità o altre metriche come throughput, latenza, tassi di conversione dei nodi e tempo di addestramento totale.
Procedura
Configura il modello ResNet. Per configurare il modello, esegui questi comandi:
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
Esegui il test. Il completamento di questo comando richiede del tempo.
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
Dove:
$WORKDIRè la directory in cui hai scaricato il modello ResNet.- Gli argomenti
--nativesono le diverse modalità di quantizzazione da testare.
Esamina i risultati. Al termine del test, puoi confrontare i risultati dell'inferenza per ogni modalità di ottimizzazione.
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
Per visualizzare i risultati completi, esegui questo comando:
cat $WORKDIR/log.txt

Dai risultati, si può vedere che FP32 e FP16 sono identici. Ciò significa che, se hai dimestichezza con TensorRT, puoi iniziare subito a utilizzare FP16. INT8 mostra risultati leggermente peggiori.
Inoltre, puoi vedere che l'esecuzione del modello con TensorRT5 fornisce i seguenti risultati:
- L'utilizzo dell'ottimizzazione FP32 migliora il throughput del 40%, passando da 314 fps a 440 fps. Allo stesso tempo, la latenza diminuisce di circa il 30%, passando da 0,40 ms a 0,28 ms.
- L'utilizzo dell'ottimizzazione FP16, anziché del grafo TensorFlow nativo, aumenta la velocità del 214%, da 314 a 988 fps. Allo stesso tempo, la latenza si riduce di 0,12 ms, quasi tre volte in meno.
- Con INT8, puoi osservare un aumento della velocità del 385%, da 314 fps a 1524 fps, con una latenza ridotta a 0,08 ms.
Conversione di un modello personalizzato in TensorRT
Per questa conversione, puoi utilizzare un modello INT8.
Scarica il modello. Per convertire un modello personalizzato in un grafo TensorRT, è necessario un modello salvato. Per ottenere un modello ResNet INT8 salvato, esegui questo comando:
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
Converti il modello in un grafo TensorRT utilizzando TFTools. Per convertire il modello utilizzando TFTools, esegui questo comando:
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
Ora hai un modello INT8 nella directory
$WORKDIR/resnet_v2_int8_NCHW/00001.Per assicurarti che tutto sia configurato correttamente, prova a eseguire un test di inferenza.
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
Carica il modello su Cloud Storage. Questo passaggio è necessario per poter utilizzare il modello dal cluster multizona configurato nella sezione successiva. Per caricare il modello, completa i seguenti passaggi:
Archivia il modello.
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
Carica l'archivio. Sostituisci
GCS_PATHcon il percorso del tuo bucket Cloud Storage.export GCS_PATH=GCS_PATH gcloud storage cp model.tar.gz $GCS_PATH
Se necessario, puoi ottenere un grafo bloccato INT8 da Cloud Storage all'URL:
gs://cloud-samples-data/dlvm/t4/model.tar.gz
Configurazione di un cluster multizona
Questa sezione spiega i passaggi da seguire per configurare un cluster multizona.
Crea il cluster
Ora che hai un modello sulla piattaforma Cloud Storage, puoi creare un cluster.
Crea un modello di istanza. Un modello di istanza è una risorsa utile per creare nuove istanze. Consulta Modelli di istanza. Sostituisci
YOUR_PROJECT_NAMEcon l'ID progetto.export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- Questo modello di istanza include uno script di avvio specificato dal parametro metadati.
- Esegui questo script di avvio durante la creazione di ogni istanza che utilizza questo modello.
- Questo script di avvio esegue i seguenti passaggi:
- Installa un agente di monitoraggio che controlla l'utilizzo della GPU nell'istanza.
- Scarica il modello.
- Avvia il servizio di inferenza.
- Nello script di avvio,
tf_serve.pycontiene la logica di inferenza. Questo esempio include un file Python di dimensioni minime basato sul pacchetto TFServe - Per visualizzare lo script di avvio, consulta startup_inf_script.sh.
- Questo modello di istanza include uno script di avvio specificato dal parametro metadati.
Crea un gruppo di istanze gestite (MIG). Questo gruppo di istanze gestite è necessario per configurare più istanze in esecuzione in zone specifiche. Le istanze vengono create in base al modello di istanza generato nel passaggio precedente.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
Puoi creare questa istanza in qualsiasi zona disponibile che supporta le GPU T4. Assicurati di disporre di quote GPU disponibili nella zona.
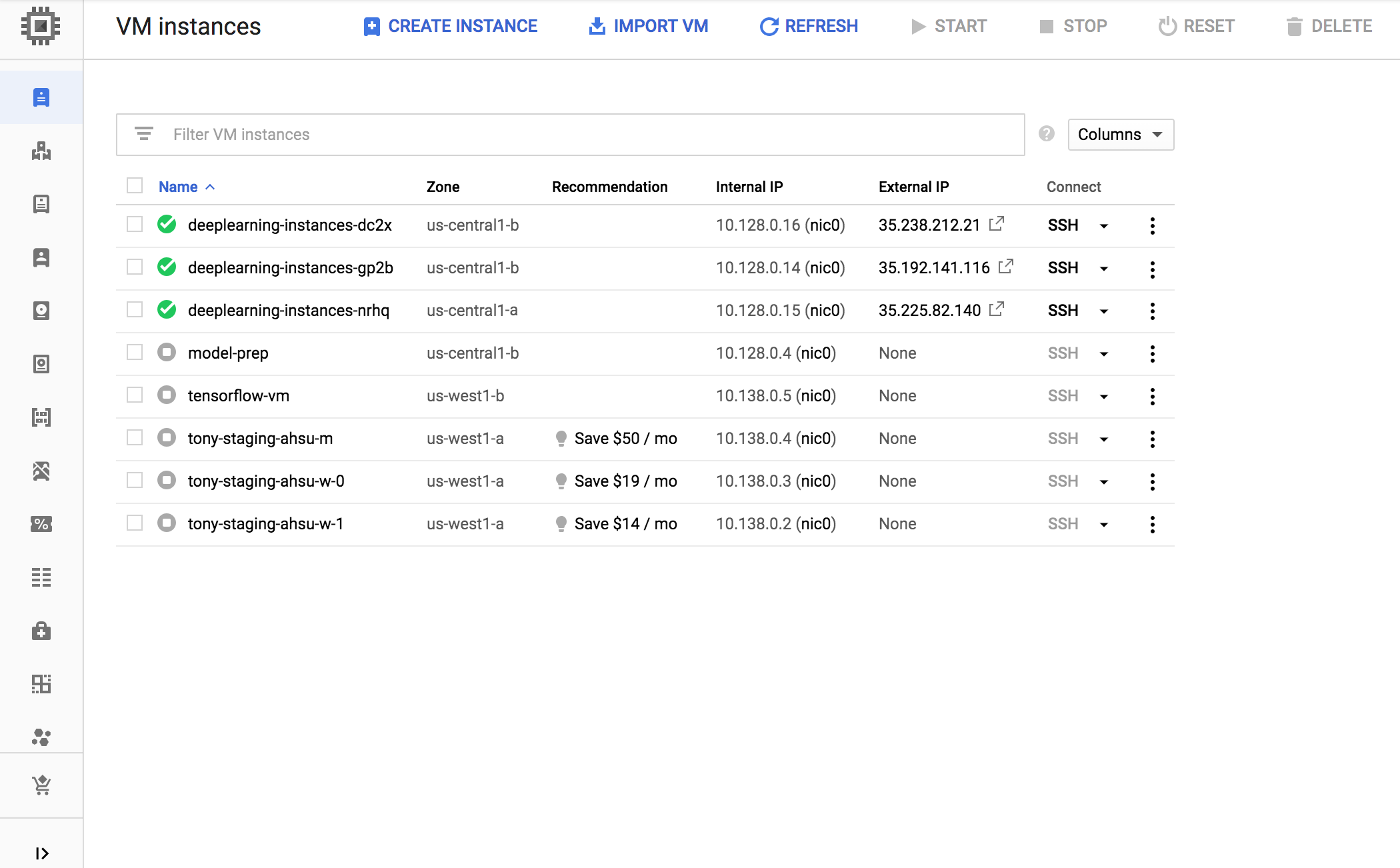
La creazione dell'istanza richiede del tempo. Puoi monitorare l'avanzamento eseguendo questi comandi:
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

Quando il gruppo di istanze gestite viene creato, dovresti visualizzare un output simile al seguente:

Verifica che le metriche siano disponibili nella pagina Cloud Monitoring di Google Cloud .
Nella console Google Cloud , vai alla pagina Monitoring.
Se nel riquadro di navigazione è mostrato Esplora metriche, fai clic su Esplora metriche. In caso contrario, seleziona Risorse e poi Esplora metriche.
Cerca
gpu_utilization.
Se i dati vengono ricevuti, dovresti vedere qualcosa di simile a questo:

Abilita la scalabilità automatica
Abilita la scalabilità automatica per il gruppo di istanze gestite.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilizationè il percorso completo della metrica. L'esempio specifica il livello 85, il che significa che ogni volta che l'utilizzo della GPU raggiunge 85, la piattaforma crea una nuova istanza nel gruppo.Testa la scalabilità automatica. Per testare la scalabilità automatica, segui questi passaggi:
- Accedi all'istanza tramite SSH. Consulta Connessione alle istanze.
Utilizza lo strumento
gpu-burnper caricare la GPU al 100% di utilizzo per 600 secondi:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
Visualizza la pagina Cloud Monitoring. Osserva la scalabilità automatica. Il cluster esegue lo scale up aggiungendo un'altra istanza.

Nella console Google Cloud , vai alla pagina Gruppi di istanze.
Fai clic sul gruppo di istanze gestite
deeplearning-instance-group.Fai clic sulla scheda Monitoraggio.
A questo punto, la logica di scalabilità automatica dovrebbe provare ad avviare il maggior numero possibile di istanze per ridurre il carico, ma senza ottenere alcun risultato:
A questo punto puoi interrompere l'utilizzo delle istanze e osservare lo scale down del sistema.
Configura un bilanciatore del carico
Ripercorriamo cosa hai creato finora:
- Un modello addestrato, ottimizzato con TensorRT5 (INT8)
- Un gruppo di istanze gestite. Queste istanze hanno la scalabilità automatica abilitata in base all'utilizzo della GPU
Ora puoi creare un bilanciatore del carico davanti alle istanze.
Crea i controlli di integrità. I controlli di integrità vengono utilizzati per determinare se un determinato host sul backend può gestire il traffico.
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
Crea un servizio di backend che include un gruppo di istanze e un controllo di integrità.
Crea il controllo di integrità.
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
Aggiungi il gruppo di istanze al nuovo servizio di backend.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
Configura l'URL di forwarding. Il bilanciatore del carico deve sapere quale URL può essere inoltrato ai servizi di backend.
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
Crea il bilanciatore del carico.
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
Aggiungi un indirizzo IP esterno al bilanciatore del carico.
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
Trova l'indirizzo IP allocato.
gcloud compute addresses list
Configura la regola di forwarding che indica a Google Cloud di inoltrare tutte le richieste dall'indirizzo IP pubblico al bilanciatore del carico.
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80Dopo la creazione delle regole di forwarding globali, possono trascorrere alcuni minuti prima che la configurazione venga propagata.
Attiva il firewall
Controlla se sono presenti regole firewall che accettano le connessioni da origini esterne alle tue istanze VM.
gcloud compute firewall-rules list
Se non hai regole firewall per accettare queste connessioni, devi crearle. Per creare le regole firewall, esegui questi comandi:
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
Esecuzione di un'inferenza
Puoi utilizzare il seguente script Python per convertire le immagini in un formato che può essere caricato sul server.
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))Esegui l'inferenza.
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json