Neste tutorial, mostramos as diferentes abordagens que podem ser usadas para migrar um banco de dados do Microsoft SQL Server no Amazon Elastic Compute Cloud (AWS EC2) para o Compute Engine.
Nesta página, discutimos as seguintes abordagens:
- Migrar usando backup e restauração completos
- Migrar usando um arquivo BACPAC
- Migrar usando grupos de disponibilidade Always On
- Migrar usando grupos de disponibilidade distribuídos
Cada método de migração tem vantagens e desvantagens diferentes. A estratégia de migração mais adequada depende das suas circunstâncias e prioridades específicas. Recomendamos que você escolha um método de migração que funcione melhor para você com base nas seguintes considerações:
Disponibilidade:considere se uma abordagem de migração é compatível com todas as versões e licenças do seu banco de dados SQL Server.
Tamanho do banco de dados:o tamanho do banco de dados pode afetar significativamente as opções de migração viáveis, já que bancos de dados maiores podem exigir estratégias diferentes dos menores. Considere a duração da transferência de dados, o possível tempo de inatividade e os requisitos de recursos ao escolher uma abordagem de migração.
Tolerância a tempo de inatividade:o nível aceitável de tempo de inatividade durante a migração é um fator crucial. Alguns métodos permitem inatividade mínima ou quase zero, enquanto outros exigem um período mais longo. Considere uma abordagem de migração que ofereça um tempo de inatividade aceitável para você.
Complexidade:a complexidade do esquema do banco de dados, das dependências do aplicativo e do ambiente geral pode influenciar a abordagem de migração. Verifique se o método de migração escolhido oferece suporte à migração de objetos que não são de banco de dados, como jobs do agente SQL, servidores vinculados, permissões e objetos de usuário.
Custo:o aspecto financeiro da migração também pode ser uma consideração. Diferentes métodos de migração têm custos variados associados à transferência de dados, recursos de computação e outros serviços. Considere um método de migração que funcione melhor para você.
Segurança e compliance de dados:verifique se o método de migração escolhido atende aos requisitos de segurança e compliance de dados. Considere a criptografia de dados, os controles de acesso e os requisitos específicos do setor que se aplicam aos seus dados.
Objetivos
Neste tutorial, mostramos como concluir as seguintes tarefas para migrar seu banco de dados SQL Server da AWS EC2 para o Compute Engine:
- Implante uma instância do SQL Server no Compute Engine
- Migrar usando o backup e restauração completos
- Migrar usando um arquivo BACPAC
- Migrar usando grupos de disponibilidade AlwaysOn
- Migrar usando grupos de disponibilidade distribuídos
Custos
Neste tutorial, usamos componentes faturáveis do Google Cloud, incluindo:
Use a Calculadora de preços para gerar uma estimativa de custo com base no uso previsto.
Antes de começar
Conclua as tarefas a seguir antes de começar:
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Preparar o projeto e a rede
Para preparar seu Google Cloud projeto e a nuvem privada virtual (VPC) para a implantação do SQL Server para migração, faça o seguinte:
No console do Google Cloud , clique em Ativar o Cloud Shell
 para abrir o Cloud Shell.
para abrir o Cloud Shell.Defina o ID do projeto padrão:
gcloud config set project
PROJECT_IDSubstitua
PROJECT_IDpelo ID do seu projeto do Google Cloud .Defina sua região padrão:
gcloud config set compute/region
REGIONSubstitua
REGIONpelo ID da região em que você quer implantar.Defina a zona padrão:
gcloud config set compute/zone
ZONESubstitua
ZONEpelo ID da zona em que você quer implantar. Verifique se a zona é válida na região especificada na etapa anterior.
Criar uma instância do SQL Server no Compute Engine
Antes de migrar seu banco de dados do SQL Server para o Compute Engine, crie uma máquina virtual (VM) no Compute Engine para hospedá-lo.
Use o comando a seguir para criar uma instância do SQL Server no Compute Engine:
2022 Standard
gcloud compute instances create sql-server-std-migrate-vm \ --project=
PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-standard-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_writeSubstitua:
PROJECT_ID:com o ID do seu projeto Google Cloud .ZONE:com o ID da zona.SUBNET_NAME: com o nome da sua sub-rede VPC.
2022 Enterprise
gcloud compute instances create sql-server-ent-migrate-vm \ --project=
PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-enterprise-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_writeSubstitua:
PROJECT_ID:com o ID do seu projeto Google Cloud .ZONE:com o ID da zona.SUBNET_NAME: com o nome da sua sub-rede VPC.
Para mais informações sobre como criar instâncias do SQL Server no Compute Engine, consulte Criar uma instância do SQL Server.
Configurar e se conectar à VM do SQL Server
Para configurar e se conectar à VM do SQL Server, siga estas etapas:
Defina a senha inicial do Windows para sua conta:
No console do Google Cloud , acesse a página Instâncias de VM.
Clique no nome da VM do servidor SQL.
Clique no botão Definir senha do Windows.
Digite uma senha e clique em Definir quando for solicitado a definir a nova senha do Windows.
Salve o nome de usuário e a senha.
Conecte-se à VM do SQL Server:
Use o endereço IP público da VM do SQL Server na página Instâncias de VM e as credenciais salvas na etapa anterior para se conectar à VM do SQL Server usando a Área de trabalho remota da Microsoft (RDP).
Execute o SQL Server Management Studio (SSMS) como administrador.
Verifique se a caixa de seleção Confiar no certificado do servidor está marcada e clique em Conectar.
Sua VM do SQL Server agora está pronta para ser usada na migração de banco de dados. Para criar novos logins de usuário para se conectar e gerenciar sua VM do SQL Server, consulte Criar um login.
Backup e restauração completos do banco de dados
Um backup e restauração completos do banco de dados é o método mais comum e simples de migração. Com essa abordagem, um backup completo do banco de dados do SQL Server é feito no ambiente de origem e restaurado no ambiente de destino Google Cloud . Embora esse método seja relativamente simples, ele pode ser demorado para bancos de dados grandes devido ao tempo necessário para criar e restaurar o backup.
Nesta seção, vamos discutir como usar o SSMS para exportar seu banco de dados do SQL Server usando um banco de dados de exemplo AdventureWorks2022.
Criar um backup completo do banco de dados
Para criar um backup completo do banco de dados, siga estas etapas:
Faça login na VM do AWS EC2 usando o RDP da Microsoft.
Conecte-se ao SQL Server usando o SSMS.
Expanda a pasta de bancos de dados no Pesquisador de objetos.
Clique com o botão direito do mouse no nome do banco de dados e clique em Tarefas no menu.
Clique em Fazer backup para abrir o assistente de backup do banco de dados.
Verifique se o nome do banco de dados a ser copiado e o tipo de backup estão definidos como "Completo".
Clique em Adicionar abaixo do destino do backup completo.
Clique no ícone de reticências (...) para selecionar a pasta e o nome do arquivo de backup.
Clique em OK para definir o nome do arquivo e em OK novamente para definir o destino.

Clique em OK para iniciar o backup do banco de dados e aguarde a conclusão.
Depois que o processo de backup for concluído, um arquivo de backup será criado. Agora é possível usar esse arquivo de backup para migrar o conteúdo do banco de dados para uma VM do Compute Engine.
Clique em OK para sair do assistente de backup do banco de dados.
Transferir o arquivo de backup para uma VM do Compute Engine
Para migrar o conteúdo do banco de dados do SQL Server, transfira o arquivo de backup criado na etapa anterior para a VM do Compute Engine que você criou. Para informações sobre as várias opções de transferência, consulte Transferir arquivos para VMs do Windows.
Restaurar o banco de dados do SQL Server do arquivo de backup
Para restaurar o banco de dados do arquivo de backup, siga estas etapas:
Faça login na VM do Compute Engine usando o RDP.
Conecte-se ao SQL Server usando o SSMS.
No Pesquisador de Objetos, clique com o botão direito do mouse na pasta Bancos de Dados e clique em Restaurar Banco de Dados.
Em Origem, clique em Dispositivo e no ícone de reticências (...) para abrir a página "Selecionar dispositivo de backup".
Verifique se o tipo de mídia de backup está definido como "Arquivo" e clique em Adicionar para selecionar o arquivo de backup.
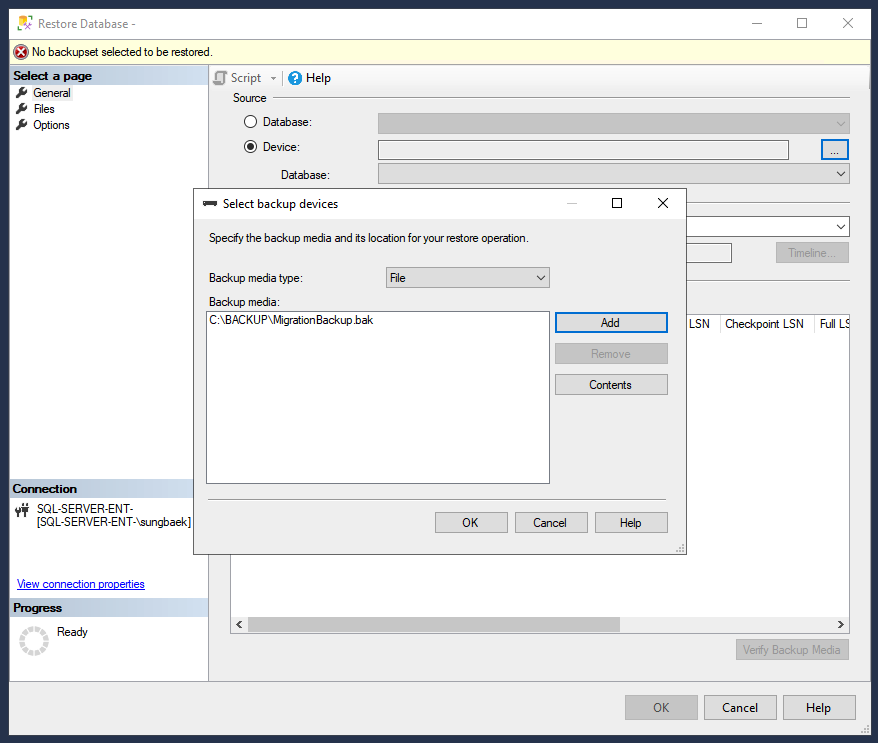
Clique em OK para definir o arquivo de backup como o dispositivo de restauração.
Clique em OK para restaurar o banco de dados.
Quando o processo for concluído, o banco de dados será migrado para o SQL Server de destino no Compute Engine.
Para verificar se o processo foi concluído com êxito, expanda a pasta databases no Pesquisador de objetos e verifique se o banco de dados migrado aparece.
Migrar usando um arquivo BACPAC
Um arquivo de pacote de backup (BACPAC) é uma representação lógica de um banco de dados do SQL Server. Ele pode ser exportado do ambiente de origem da AWS e importado para o ambiente de destino Google Cloud . Esse método geralmente é mais rápido do que um backup e restauração completos para bancos de dados menores, mas pode não ser adequado para bancos de dados muito grandes ou com dependências complexas.
Na seção a seguir, explicamos como migrar seu banco de dados do SQL Server usando um arquivo BACPAC.
Criar uma exportação BACPAC
Para criar uma exportação BACPAC, siga estas etapas:
Faça login na VM do AWS EC2 usando o RDP da Microsoft.
Conecte-se ao SQL Server usando o SSMS.
Expanda a pasta databases no Pesquisador de objetos.
Clique com o botão direito do mouse no nome do banco de dados e clique em Tarefas.
Clique em Exportar aplicativo de camada de dados para abrir o assistente de exportação.
Clique em Próxima.
Clique em Procurar na opção Salvar no disco local e selecione o arquivo BACPAC.
Clique na guia Avançado e selecione os esquemas que você quer exportar.
Clique em Próxima para acessar o resumo.
Clique em Concluir para exportar o arquivo BACPAC e aguarde a conclusão da exportação.
Clique em Fechar para sair do assistente.
Transfira o arquivo BACPAC criado nas etapas anteriores para a VM de destino no Compute Engine. Para informações sobre as opções de transferência, consulte Transferir arquivos para VMs do Windows.
Restaurar o banco de dados do SQL Server de um arquivo BACPAC
Para restaurar o banco de dados do arquivo BACPAC, siga estas etapas:
Faça login na VM do Compute Engine usando o RDP.
Conecte-se ao SQL Server usando o SSMS.
No Pesquisador de Objetos, clique com o botão direito do mouse na pasta Bancos de Dados e clique em Importar aplicativo de camada de dados.
Clique em Próxima.
Clique em Procurar, selecione o arquivo BACPAC que você quer restaurar e clique em Próxima.
Verifique o nome do novo banco de dados e clique em Próxima.
Clique em Concluir e aguarde a conclusão da importação.
Clique em Fechar para sair do assistente.
Para verificar se o processo foi concluído com êxito, expanda a pasta databases no Pesquisador de objetos e verifique se o banco de dados migrado aparece.
Migrar usando grupos de disponibilidade AlwaysOn
Um AOAG é um recurso de alta disponibilidade e recuperação de desastres do SQL Server. É possível usar um AOAG para migrar clusters AOAG, servidores SQL autônomos e clusters de failover do Windows Server (WSFC). Com esse método, uma réplica do banco de dados é criada no ambiente de destino Google Cloud , e os dados são sincronizados entre a origem e o destino. Quando a sincronização for concluída, a réplica no ambiente de destino Google Cloud poderá ser definida como principal. Esse método minimiza o tempo de inatividade, mas exige mais configuração e instalação. Para migrações simples com tolerância significativa a tempo de inatividade, outros métodos podem ser mais simples e econômicos.
Antes de começar
Antes de iniciar a migração, verifique se:
Para garantir uma transição segura e sem problemas dos dados, estabeleça uma conexão de peering entre a AWS e o Google Cloud. Para mais informações, consulte Criar conexões de VPN de alta disponibilidade entre Google Cloud e a AWS.
Verifique se o banco de dados de origem está sendo executado no modo independente e se os servidores de origem e de destino estão associados a um Active Directory (AD). Se o banco de dados de origem já fizer parte de um cluster do WSFC usando um AOAG, consulte Migrar usando grupos de disponibilidade distribuídos.
Verifique se todas as chaves de criptografia no banco de dados de origem do SQL Server estão instaladas em todas as instâncias do SQL Server que vão participar do AOAG.
Prepare seu SQL Server para fazer parte de um AOAG
Para adicionar servidores SQL a um AOAG, ative o recurso em todas as instâncias que você quer adicionar ao grupo.
Para ativar o recurso AOAG em todas as VMs do SQL Server que você quer adicionar a um AOAG, siga estas etapas:
Ative o AOAG no SQL Server.
Faça login na VM do SQL Server usando o RDP.
Abra o PowerShell no modo de administrador.
Execute o comando a seguir para ativar o AOAG no SQL Server.
Enable-SqlAlwaysOn -ServerInstance $env:COMPUTERNAME -Force
Execute o comando a seguir para abrir uma porta de firewall para a replicação de dados.
netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022
Repita a etapa 1 para todas as VMs do SQL Server que você quer adicionar ao AOAG.
Crie um novo usuário para o SQL Server no AD.
$Credential = Get-Credential -UserName sql_server -Message 'Enter password' New-ADUser ` -Name "sql_server" ` -Description "SQL Admin account." ` -AccountPassword $Credential.Password ` -Enabled $true -PasswordNeverExpires $true
Siga estas etapas em todas as instâncias do SQL Server que fazem parte do AOAG:
- Abra o SQL Server Configuration Manager.
- No painel de navegação, selecione Serviços do SQL Server.
- Na lista de serviços, clique com o botão direito do mouse em SQL Server (MSSQLSERVER) e selecione Propriedades.
- Em Fazer logon como, mude a conta da seguinte forma:
- Nome da conta:
DOMAIN\sql_serverem que DOMAIN é o nome do NetBIOS do seu domínio do AD. - Senha:digite a senha que você escolheu na etapa 2 da seção anterior.
- Nome da conta:
Clique em OK.
Quando solicitado a reiniciar o SQL Server, selecione Sim.
O SQL Server agora é executado em uma conta de usuário do domínio.
Configurar o endpoint de espelhamento para seu banco de dados do SQL Server
Para criar o endpoint do seu AOAG, siga estas etapas:
Se o banco de dados de origem do SQL Server estiver criptografado com a criptografia de dados transparente (TDE), siga esta etapa para fazer backup, transferir e instalar os certificados e as chaves no SQL Server de destino.
Faça login no banco de dados de origem na AWS usando o SSMS.
Execute o comando T-SQL a seguir para criar o endpoint do grupo de disponibilidade.
USE [master] GO CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO USE [DATABASE_NAME] GO CREATE USER [NET_DOMAIN\sql_server] FOR LOGIN [NET_DOMAIN\sql_server] GO USE [master] GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GOSubstitua
NET_DOMAINpelo nome do NetBIOS do seu domínio do AD eDATABASE_NAMEpelo nome do banco de dados a ser migrado.Conecte-se ao SQL Server de destino em Google Cloud usando o SSMS e execute o seguinte comando T-SQL para criar o endpoint de espelhamento de banco de dados.
CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GOSubstitua
NET_DOMAINpelo nome do NetBIOS do seu domínio do AD.Para verificar os endpoints, acesse Objetos de servidor > Endpoints > Espelhamento de banco de dados no Pesquisador de objetos do SSMS.

Criar o AOAG
Para criar um AOAG, siga estas etapas:
Faça login no banco de dados de origem na AWS usando o SSMS.
Execute o seguinte comando T-SQL para definir o modo de recuperação do banco de dados como "completo" e fazer um backup completo.
USE [master] GO ALTER DATABASE [
DATABASE_NAME] SET RECOVERY FULL; BACKUP DATABASE [DATABASE_NAME] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Backup\DATABASE_NAME.bak';Substitua
DATABASE_NAMEpelo nome do banco de dados a ser migrado.Execute o comando T-SQL a seguir para criar o AOAG.
USE [master] GO CREATE AVAILABILITY GROUP [migration-ag] WITH ( AUTOMATED_BACKUP_PREFERENCE = SECONDARY, DB_FAILOVER = OFF, DTC_SUPPORT = NONE, REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0 ) FOR DATABASE [DATABASE_NAME] REPLICA ON N'SOURCE_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://SOURCE_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ), N'DEST_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://DEST_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ); GOSubstitua:
DATABASE_NAME: com o nome do banco de dados a ser migrado.SOURCE_SERVERNAME: com o nome do servidor do banco de dados de origem.DEST_SERVERNAME: com o nome do servidor do banco de dados de destino.SOURCE_HOSTNAME:com o nome de domínio totalmente qualificado (FQDN) da origem.DEST_HOSTNAME: com o FQDN do destino.
Execute o comando T-SQL a seguir no banco de dados de destino para adicioná-lo ao AOAG.
USE [master] GO ALTER AVAILABILITY GROUP [migration-ag] JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP [migration-ag] GRANT CREATE ANY DATABASE; GO
Verifique o estado do AOAG e do banco de dados recém-criados no Pesquisador de objetos ou executando o seguinte comando T-SQL.
SELECT * FROM sys.dm_hadr_availability_group_states GO
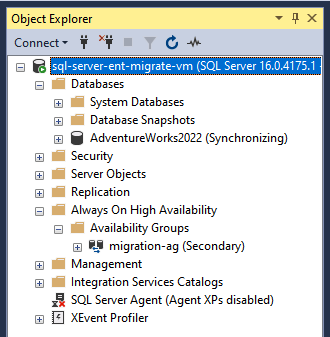
O AOAG do SQL Server agora está configurado e continua sincronizando entre a AWS e Google Cloud. Como próxima etapa, configure um WSFC e um listener para alta disponibilidade e recuperação de desastres. Para mais informações, consulte Clustering de failover do Windows Server com o SQL Server e O que é um listener de grupo de disponibilidade?.
Migrar usando grupos de disponibilidade distribuídos
Um grupo de disponibilidade distribuído é um tipo especial que abrange dois grupos de disponibilidade separados. Ele foi projetado para oferecer alta disponibilidade e recursos de recuperação de desastres em locais dispersos geograficamente. Essa arquitetura permite a replicação de dados e o failover entre os grupos de disponibilidade primário e secundário, ideal para migração de dados. Para mais informações, consulte Grupos de disponibilidade distribuídos.
.As seções a seguir explicam como migrar seu banco de dados do SQL Server usando grupos de disponibilidade distribuídos.
Antes de começar
Verifique se você tem um WSFC com o SQL Server usando um grupo de disponibilidade com um listener de nome de rede virtual (VNN) em execução na AWS.
Preparar o ambiente de destino
Para preparar o ambiente de destino, siga estas etapas:
Para configurar um WSFC com o SQL Server usando um grupo de disponibilidade com um balanceador de carga interno em Google Cloud, consulte Configurar grupos de disponibilidade AlwaysOn do SQL Server com confirmação síncrona usando um balanceador de carga interno.
No Pesquisador de Objetos, verifique se
bookshelf-agfoi criado e está replicando o banco de dadosbookshelf. Depois de verificar, siga as próximas etapas para remover o grupo de disponibilidade e o banco de dados dos dois nós no cluster de failover.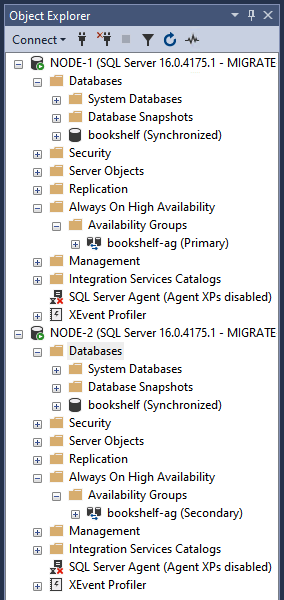
Conecte-se a
node-1no SSMS e salve o endereço IP do listenerbookshelf.SELECT * FROM sys.availability_group_listeners
Execute o seguinte comando T-SQL para remover o grupo de disponibilidade
bookshelf-age o banco de dadosbookshelf.USE master GO DROP AVAILABILITY GROUP [bookshelf-ag] GO ALTER DATABASE [bookshelf] SET SINGLE_USER WITH ROLLBACK IMMEDIATE GO DROP DATABASE [bookshelf] GO
Execute o seguinte T-SQL em
node-2no SSMS para remover o banco de dados replicado.USE master GO DROP DATABASE [bookshelf] GO
Criar um grupo de disponibilidade distribuído
Para criar um grupo de disponibilidade que será usado no grupo de disponibilidade distribuído, siga estas etapas:
Execute o comando T-SQL a seguir em
node-1.USE master GO CREATE AVAILABILITY GROUP [gcp-dest-ag] FOR REPLICA ON N'NODE-1' WITH ( ENDPOINT_URL = N'TCP://NODE-1:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ), N'NODE-2' WITH ( ENDPOINT_URL = N'TCP://NODE-2:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ); GOCrie um listener.
USE master; GO ALTER AVAILABILITY GROUP [gcp-dest-ag] ADD LISTENER N'gcp-dest-lsnr' ( WITH IP ( (N'
LISTENER_IP', N'255.255.255.0') ), PORT = 1433); GOSubstitua
LISTENER_IPpelo endereço IP do listener.Conecte-se a
node-2usando o SSMS e execute o seguinte comando T-SQL para adicionar ao grupo de disponibilidadegcp-dest-ag.USE master GO ALTER AVAILABILITY GROUP [gcp-dest-ag] JOIN; ALTER AVAILABILITY GROUP [gcp-dest-ag] GRANT CREATE ANY DATABASE;
Conecte-se à réplica principal do SQL Server de origem na AWS usando o SSMS e execute o seguinte comando T-SQL para criar um grupo de disponibilidade distribuído.
USE [master] GO CREATE AVAILABILITY GROUP [distributed-ag] WITH (DISTRIBUTED) AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOSubstitua
AWS_AGpelo nome do grupo de disponibilidade na AWS eAWS_LISTENERpelo listener do grupo de disponibilidade da AWS.Execute o comando T-SQL a seguir no SSMS em
node-1para adicioná-lo ao grupo de disponibilidade distribuído.USE [master] GO ALTER AVAILABILITY GROUP [distributed-ag] JOIN AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOSubstitua
AWS_AGpelo nome do grupo de disponibilidade na AWS eAWS_LISTENERpelo listener do grupo de disponibilidade da AWS.Execute o comando T-SQL a seguir em "node-1" para verificar se todos os grupos de disponibilidade estão íntegros e replicando no grupo de disponibilidade distribuído para o novo cluster do SQL Server em Google Cloud.
SELECT * FROM sys.dm_hadr_availability_group_states GO
Limpar
Depois de concluir o tutorial, você pode limpar os recursos que criou para que eles parem de usar a cota e gerar cobranças. Nas seções a seguir, você aprenderá a excluir e desativar esses recursos.
Excluir o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para o tutorial.
Para excluir o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.