Questo tutorial illustra i diversi approcci che puoi utilizzare per eseguire la migrazione di un database Microsoft SQL Server su Amazon Elastic Compute Cloud (AWS EC2) a Compute Engine.
Questa pagina illustra i seguenti approcci:
- Esegui la migrazione utilizzando il backup completo e il ripristino
- Eseguire la migrazione utilizzando un file BACPAC
- Eseguire la migrazione utilizzando i gruppi di disponibilità Always On
- Eseguire la migrazione utilizzando i gruppi di disponibilità distribuiti
Ogni metodo di migrazione presenta vantaggi e svantaggi diversi. La strategia di migrazione più adatta dipende dalle tue circostanze e priorità specifiche. Ti consigliamo di scegliere il metodo di migrazione più adatto alle tue esigenze in base alle seguenti considerazioni:
Disponibilità:valuta se un approccio di migrazione è supportato da tutte le versioni e le licenze del tuo database SQL Server.
Dimensioni del database:le dimensioni del database possono influire in modo significativo sulle opzioni di migrazione fattibili, in quanto i database più grandi potrebbero richiedere strategie diverse rispetto a quelli più piccoli. Quando scegli un approccio di migrazione, considera la durata del trasferimento dei dati, i potenziali tempi di inattività e i requisiti delle risorse.
Tolleranza al downtime:il livello accettabile di downtime durante la migrazione è un fattore cruciale. Alcuni metodi consentono tempi di inattività minimi o quasi nulli, mentre altri richiedono un tempo di inattività più lungo. Valuta un approccio di migrazione che offra un downtime accettabile per te.
Complessità:la complessità dello schema del database, delle dipendenze delle applicazioni e dell'ambiente complessivo può influenzare l'approccio alla migrazione. Assicurati che il metodo di migrazione scelto supporti la migrazione di oggetti non di database come job SQL Agent, server collegati, autorizzazioni e oggetti utente.
Costo:anche l'aspetto finanziario della migrazione può essere un fattore da considerare. I diversi metodi di migrazione comportano costi variabili associati al trasferimento dei dati, alle risorse di computing e ad altri servizi. Valuta un metodo di migrazione più adatto alle tue esigenze.
Sicurezza e conformità dei dati: assicurati che il metodo di migrazione scelto rispetti i tuoi requisiti di sicurezza e conformità dei dati. Prendi in considerazione la crittografia dei dati, i controlli dell'accesso e tutti i requisiti specifici del settore che si applicano ai tuoi dati.
Prepara il progetto e la rete
Per preparare il progetto Google Cloud e il Virtual Private Cloud (VPC) per il deployment di SQL Server per la migrazione, segui questi passaggi:
Nella console Google Cloud , fai clic su Attiva Cloud Shell
 per aprire Cloud Shell.
per aprire Cloud Shell.Imposta l'ID progetto predefinito:
gcloud config set project
PROJECT_IDSostituisci
PROJECT_IDcon l'ID del tuo progetto Google Cloud .Imposta la regione predefinita:
gcloud config set compute/region
REGIONSostituisci
REGIONcon l'ID della regione in cui vuoi eseguire il deployment.Imposta la zona predefinita:
gcloud config set compute/zone
ZONESostituisci
ZONEcon l'ID della zona in cui vuoi eseguire il deployment. Assicurati che la zona sia valida nella regione specificata nel passaggio precedente.
Crea un'istanza SQL Server su Compute Engine
Prima di eseguire la migrazione del database SQL Server a Compute Engine, devi creare una macchina virtuale (VM) su Compute Engine per ospitarlo.
Utilizza il comando seguente per creare un'istanza SQL Server su Compute Engine:
2022 Standard
gcloud compute instances create sql-server-std-migrate-vm \ --project=PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-standard-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write
Sostituisci quanto segue:
PROJECT_ID: con l'ID del tuo progetto Google Cloud .ZONE: con l'ID della zona.SUBNET_NAME: con il nome della tua subnet VPC.
2022 Enterprise
gcloud compute instances create sql-server-ent-migrate-vm \ --project=PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-enterprise-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write
Sostituisci quanto segue:
PROJECT_ID: con l'ID del tuo progetto Google Cloud .ZONE: con l'ID della zona.SUBNET_NAME: con il nome della tua subnet VPC.
Per saperne di più sulla creazione di istanze SQL Server su Compute Engine, consulta Crea un'istanza SQL Server.
Configura e connettiti alla tua VM SQL Server
Per configurare la VM SQL Server e connetterti, segui questi passaggi:
Imposta la password iniziale di Windows per il tuo account:
Nella console Google Cloud , vai alla pagina Istanze VM.
Fai clic sul nome della VM SQL Server.
Fai clic sul pulsante Imposta password di Windows.
Inserisci una password e fai clic su Imposta quando ti viene chiesto di impostare la nuova password di Windows.
Salva il nome utente e la password.
Connettiti alla VM SQL Server:
Utilizza l'indirizzo IP pubblico della VM SQL Server dalla pagina Istanze VM e le credenziali salvate nel passaggio precedente per connetterti alla VM SQL Server utilizzando Microsoft Remote Desktop (RDP).
Esegui SQL Server Management Studio (SSMS) come amministratore.
Verifica che la casella di controllo Considera attendibile il certificato del server sia selezionata e fai clic su Connetti.
La VM SQL Server è ora pronta per essere utilizzata per la migrazione del database. Per creare nuovi accessi utente per connetterti e gestire la tua VM SQL Server, consulta Crea un accesso.
Backup e ripristino completi del database
Il backup e il ripristino completi del database sono il metodo più comune e semplice di migrazione del database. Con questo approccio, viene eseguito un backup completo del database SQL Server dall'ambiente di origine, che viene poi ripristinato nell'ambiente di destinazione Google Cloud . Sebbene questo metodo sia relativamente semplice, può richiedere molto tempo per i database di grandi dimensioni a causa del tempo necessario per creare e ripristinare il backup.
Questa sezione illustra come utilizzare SSMS per esportare il database SQL Server utilizzando un database AdventureWorks2022 di esempio.
Crea un backup completo del database
Per creare un backup completo del database:
Accedi alla tua VM AWS EC2 utilizzando Microsoft RDP.
Connettiti a SQL Server utilizzando SSMS.
Espandi la cartella dei database in Esplora oggetti.
Fai clic con il tasto destro del mouse sul nome del database, poi fai clic su Tasks dal menu.
Fai clic su Backup per aprire la procedura guidata per il backup del database.
Verifica che il nome del database di cui eseguire il backup e il tipo di backup siano impostati su Completo.
Fai clic su Aggiungi sotto la destinazione per il backup completo.
Fai clic sull'icona con i tre puntini (…) per selezionare la cartella e il nome del file di backup.
Fai clic su Ok per impostare il nome del file e di nuovo su Ok per impostare la destinazione.

Fai clic su Ok per avviare il backup del database e attendi il completamento del backup.
Al termine della procedura di backup, viene creato un file di backup. Ora puoi utilizzare questo file di backup per eseguire la migrazione dei contenuti del database a una VM di Compute Engine.
Fai clic su Ok per uscire dalla procedura guidata di backup del database.
Trasferisci il file di backup a una VM di Compute Engine
Per eseguire la migrazione dei contenuti del database SQL Server, devi trasferire il file di backup creato nel passaggio precedente alla VM Compute Engine che hai creato. Per informazioni sulle varie opzioni di trasferimento, consulta Trasferisci i file nelle VM Windows.
Ripristina il database SQL Server dal file di backup
Per ripristinare il database dal file di backup:
Accedi alla tua VM di Compute Engine utilizzando RDP.
Connettiti a SQL Server utilizzando SSMS.
In Esplora oggetti, fai clic con il tasto destro del mouse sulla cartella Database e poi su Ripristina database.
Per Origine, fai clic su Dispositivo e sull'icona con i tre puntini (…) per aprire la pagina Seleziona dispositivo di backup.
Verifica che il tipo di supporto di backup sia impostato su File e fai clic su Aggiungi per selezionare il file di backup.
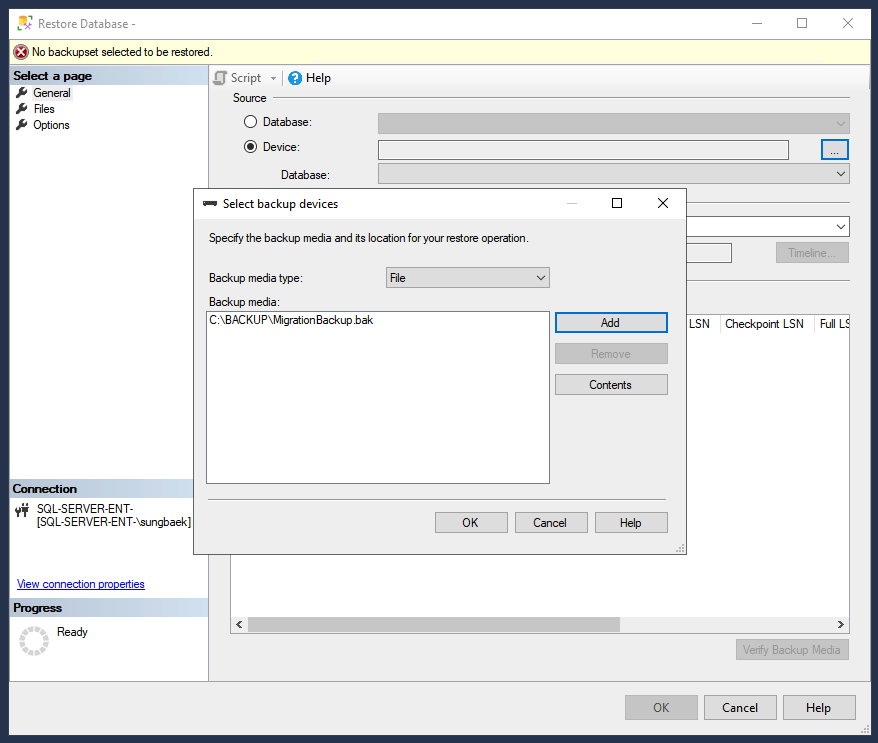
Fai clic su Ok per impostare il file di backup come dispositivo di ripristino.
Fai clic su Ok per ripristinare il database.
Al termine della procedura, il database viene migrato al server SQL di destinazione su Compute Engine.
Per verificare se la procedura è stata completata correttamente, puoi espandere la cartella database in Esplora oggetti e verificare se riesci a visualizzare il database di cui è stata eseguita la migrazione.
Esegui la migrazione utilizzando un file BACPAC
Un file del pacchetto di backup (BACPAC) è una rappresentazione logica di un database SQL Server. Può essere esportato dall'ambiente AWS di origine e poi importato nell'ambiente di destinazione. Google Cloud Questo metodo è in genere più veloce di un backup e ripristino completo per i database più piccoli, ma potrebbe non essere adatto a database molto grandi o a quelli con dipendenze complesse.
La sezione seguente descrive come eseguire la migrazione del database SQL Server utilizzando un file BACPAC.
Creare un'esportazione BACPAC
Per creare un'esportazione BACPAC:
Accedi alla VM AWS EC2 utilizzando Microsoft RDP.
Connettiti a SQL Server utilizzando SSMS.
Espandi la cartella database in Esplora oggetti.
Fai clic con il tasto destro del mouse sul nome del database e poi su Attività.
Fai clic su Esporta applicazione livello dati per aprire la procedura guidata per l'esportazione.
Fai clic su Avanti.
Fai clic su Sfoglia nell'opzione Salva su disco locale e seleziona il file BACPAC.
Fai clic sulla scheda Avanzate e seleziona gli schemi che vuoi esportare.
Fai clic su Avanti per passare al riepilogo.
Fai clic su Fine per esportare il file BACPAC e attendi il completamento dell'esportazione.
Fai clic su Chiudi per uscire dalla procedura guidata.
Trasferisci il file BACPAC creato nei passaggi precedenti alla VM di destinazione su Compute Engine. Per informazioni sulle opzioni di trasferimento, consulta Trasferisci i file nelle VM Windows.
Ripristina il database SQL Server da un file BACPAC
Per ripristinare il database dal file BACPAC:
Accedi alla VM di Compute Engine utilizzando RDP.
Connettiti a SQL Server utilizzando SSMS.
In Esplora oggetti, fai clic con il tasto destro del mouse sulla cartella Database e fai clic su Importa applicazione a livello di dati.
Fai clic su Avanti.
Fai clic su Sfoglia, seleziona il file BACPAC che vuoi ripristinare e poi fai clic su Avanti.
Verifica il nuovo nome del database e fai clic su Avanti.
Fai clic su Fine e attendi il completamento dell'importazione.
Fai clic su Chiudi per uscire dalla procedura guidata.
Per verificare se la procedura è stata completata correttamente, puoi espandere la cartella database in Esplora oggetti e verificare se riesci a visualizzare il database di cui è stata eseguita la migrazione.
Eseguire la migrazione utilizzando i gruppi di disponibilità Always On
Un AOAG è una funzionalità di alta disponibilità e ripristino di emergenza di SQL Server. Puoi utilizzare un gruppo di disponibilità AlwaysOn per eseguire la migrazione di cluster di gruppi di disponibilità AlwaysOn esistenti, istanze SQL Server autonome e cluster di failover di Windows Server (WSFC). Con questo metodo, viene creata una replica del database nell'ambiente di destinazione Google Cloud e i dati vengono sincronizzati tra l'origine e la destinazione. Una volta completata la sincronizzazione, la replica nell'ambiente Google Cloud di destinazione può essere impostata come principale. Questo metodo riduce al minimo i tempi di inattività, ma richiede una configurazione e una configurazione aggiuntive. Per le migrazioni semplici con una tolleranza significativa ai tempi di inattività, altri metodi potrebbero essere più semplici ed economici.
Prima di iniziare
Prima di iniziare la migrazione, assicurati di:
Per garantire una transizione sicura e senza interruzioni dei dati, stabilisci una connessione di peering tra AWS e Google Cloud. Per ulteriori informazioni, consulta Crea connessioni VPN ad alta disponibilità tra Google Cloud e AWS.
Assicurati che il database di origine sia in esecuzione in modalità autonoma e che i server di origine e di destinazione siano uniti a un Active Directory (AD). Se il database di origine fa già parte di un cluster WSFC che utilizza un gruppo di disponibilità AlwaysOn, consulta Eseguire la migrazione utilizzando i gruppi di disponibilità distribuiti.
Assicurati che tutte le chiavi di crittografia nel database SQL Server di origine siano installate su tutte le istanze di SQL Server che si uniranno al gruppo di disponibilità AlwaysOn.
Prepara SQL Server a far parte di un gruppo di disponibilità Always On
Per poter aggiungere server SQL a un gruppo di disponibilità Always On, devi abilitare la funzionalità AOAG su tutte le istanze SQL Server che vuoi aggiungere al gruppo.
Per attivare la funzionalità AOAG su tutte le VM SQL Server che vuoi aggiungere a un AOAG, segui questi passaggi:
Abilita AOAG su SQL Server.
Accedi alla VM SQL Server utilizzando RDP.
Apri PowerShell in modalità amministratore.
Esegui questo comando per abilitare AOAG su SQL Server.
Enable-SqlAlwaysOn -ServerInstance $env:COMPUTERNAME -Force
Esegui questo comando per aprire una porta firewall per la replica dei dati.
netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022
Ripeti il passaggio 1 per tutte le VM SQL Server che vuoi aggiungere al gruppo di disponibilità Always On.
Crea un nuovo utente per SQL Server in AD.
$Credential = Get-Credential -UserName sql_server -Message 'Enter password' New-ADUser ` -Name "sql_server" ` -Description "SQL Admin account." ` -AccountPassword $Credential.Password ` -Enabled $true -PasswordNeverExpires $true
Esegui i seguenti passaggi su tutte le istanze SQL Server che fanno parte di AOAG:
- Apri SQL Server Configuration Manager.
- Nel riquadro di navigazione, seleziona Servizi SQL Server.
- Nell'elenco dei servizi, fai clic con il tasto destro del mouse su SQL Server (MSSQLSERVER) e seleziona Proprietà.
- In Accedi come, modifica l'account come segue:
- Nome account:
DOMAIN\sql_server, dove DOMAIN è il nome NetBIOS del tuo dominio AD. - Password:inserisci la password che hai scelto nel passaggio 2 precedente di questa sezione.
- Nome account:
Fai clic su OK.
Quando ti viene chiesto di riavviare SQL Server, seleziona Sì.
Ora SQL Server viene eseguito con un account utente del dominio.
Configura l'endpoint di mirroring per il database SQL Server
Per creare l'endpoint per il tuo AOAG, segui questi passaggi:
Se il database SQL Server di origine è criptato con Transparent Data Encryption (TDE), esegui questo passaggio per eseguire il backup, trasferire e installare i certificati e le chiavi nel server SQL Server di destinazione.
Accedi al database di origine su AWS utilizzando SSMS.
Esegui questo comando T-SQL per creare l'endpoint per il gruppo di disponibilità.
USE [master] GO CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO USE [DATABASE_NAME] GO CREATE USER [NET_DOMAIN\sql_server] FOR LOGIN [NET_DOMAIN\sql_server] GO USE [master] GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GOSostituisci
NET_DOMAINcon il nome NetBIOS del tuo dominio AD eDATABASE_NAMEcon il nome del database di cui eseguire la migrazione.Connettiti a SQL Server di destinazione su Google Cloud utilizzando SSMS ed esegui il seguente comando T-SQL per creare l'endpoint di mirroring del database.
CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GOSostituisci
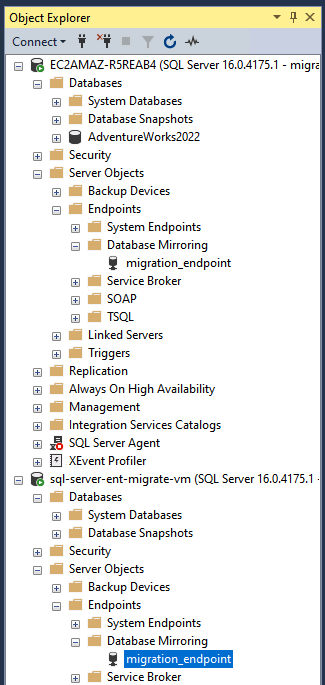
NET_DOMAINcon il nome NetBIOS del tuo dominio AD.Verifica gli endpoint andando a Oggetti server > Endpoint > Mirroring del database in Esplora oggetti in SSMS.
Creare il gruppo AOAG
Per creare un AOAG, segui questi passaggi:
Accedi al database di origine su AWS utilizzando SSMS.
Esegui il seguente comando T-SQL per impostare la modalità di recupero del database su completa ed esegui un backup completo.
USE [master] GO ALTER DATABASE [
DATABASE_NAME] SET RECOVERY FULL; BACKUP DATABASE [DATABASE_NAME] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Backup\DATABASE_NAME.bak';Sostituisci
DATABASE_NAMEcon il nome del database da migrare.Esegui questo comando T-SQL per creare l'AOAG.
USE [master] GO CREATE AVAILABILITY GROUP [migration-ag] WITH ( AUTOMATED_BACKUP_PREFERENCE = SECONDARY, DB_FAILOVER = OFF, DTC_SUPPORT = NONE, REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0 ) FOR DATABASE [DATABASE_NAME] REPLICA ON N'SOURCE_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://SOURCE_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ), N'DEST_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://DEST_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ); GOSostituisci quanto segue:
DATABASE_NAME: con il nome del database di cui eseguire la migrazione.SOURCE_SERVERNAME: con il nome del server del database di origine.DEST_SERVERNAME: con il nome del server del database di destinazione.SOURCE_HOSTNAME: con il nome di dominio completo (FQDN) dell'origine.DEST_HOSTNAME: con il nome di dominio completo della destinazione.
Esegui questo comando T-SQL sul database di destinazione per aggiungerlo all'AOAG.
USE [master] GO ALTER AVAILABILITY GROUP [migration-ag] JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP [migration-ag] GRANT CREATE ANY DATABASE; GO
Verifica lo stato del database e dell'AOAG appena creato in Esplora oggetti o eseguendo questo comando T-SQL.
SELECT * FROM sys.dm_hadr_availability_group_states GO
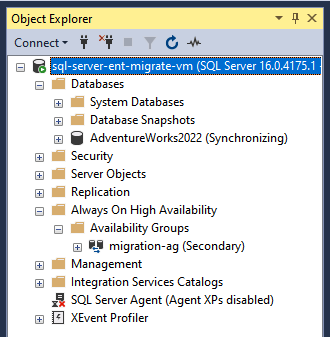
Il gruppo di disponibilità AlwaysOn di SQL Server è ora configurato e continua a sincronizzarsi tra AWS e Google Cloud. Il passaggio successivo consiste nel configurare un cluster WSFC e un listener per l'alta disponibilità e il ripristino di emergenza. Per ulteriori informazioni, vedi Clustering di failover di Windows Server con SQL Server e Che cos'è un listener del gruppo di disponibilità.
Eseguire la migrazione utilizzando i gruppi di disponibilità distribuiti
Un gruppo di disponibilità distribuito è un tipo speciale di gruppo di disponibilità che si estende su due gruppi di disponibilità separati. È progettato per fornire funzionalità di alta affidabilità eripristino di emergenzay in località geograficamente disperse. Questa architettura consente la replica e il failover dei dati senza interruzioni tra i gruppi di disponibilità primario e secondario, ideale per la migrazione dei dati. Per informazioni più dettagliate, consulta Gruppi di disponibilità distribuiti.
Le sezioni seguenti descrivono come eseguire la migrazione del database SQL Server utilizzando i gruppi di disponibilità distribuiti.
Prima di iniziare
Assicurati di avere un cluster WSFC con SQL Server che utilizza un gruppo di disponibilità con un listener del nome di rete virtuale (VNN) in esecuzione su AWS.
Prepara l'ambiente di destinazione
Per preparare l'ambiente di destinazione:
Per configurare un cluster di failover di Windows Server con SQL Server utilizzando un gruppo di disponibilità con un bilanciatore del carico interno su Google Cloud, consulta Configura i gruppi di disponibilità AlwaysOn di SQL Server con commit sincrono utilizzando un bilanciatore del carico interno.
In Esplora oggetti, verifica che
bookshelf-agsia stato creato e stia replicando il databasebookshelf. Una volta verificato, segui i passaggi successivi per rimuovere sia il gruppo di disponibilità sia il database da entrambi i nodi del cluster di failover.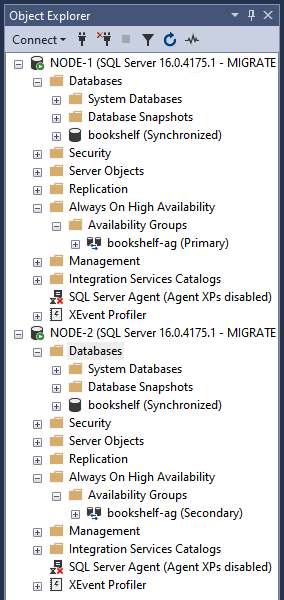
Connettiti a
node-1in SSMS e salva l'indirizzo IP del listenerbookshelf.SELECT * FROM sys.availability_group_listeners
Esegui questo comando T-SQL per rimuovere il gruppo di disponibilità
bookshelf-age il databasebookshelf.USE master GO DROP AVAILABILITY GROUP [bookshelf-ag] GO ALTER DATABASE [bookshelf] SET SINGLE_USER WITH ROLLBACK IMMEDIATE GO DROP DATABASE [bookshelf] GO
Esegui il seguente comando T-SQL su
node-2in SSMS per rimuovere il database replicato.USE master GO DROP DATABASE [bookshelf] GO
Crea un gruppo di disponibilità distribuito
Per creare un nuovo gruppo di disponibilità da utilizzare per il gruppo di disponibilità distribuito, segui questi passaggi:
Esegui questo comando T-SQL su
node-1.USE master GO CREATE AVAILABILITY GROUP [gcp-dest-ag] FOR REPLICA ON N'NODE-1' WITH ( ENDPOINT_URL = N'TCP://NODE-1:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ), N'NODE-2' WITH ( ENDPOINT_URL = N'TCP://NODE-2:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ); GOCrea un listener.
USE master; GO ALTER AVAILABILITY GROUP [gcp-dest-ag] ADD LISTENER N'gcp-dest-lsnr' ( WITH IP ( (N'
LISTENER_IP', N'255.255.255.0') ), PORT = 1433); GOSostituisci
LISTENER_IPcon l'indirizzo IP del listener.Connettiti a
node-2utilizzando SSMS ed esegui questo comando T-SQL per aggiungerlo al gruppo di disponibilitàgcp-dest-ag.USE master GO ALTER AVAILABILITY GROUP [gcp-dest-ag] JOIN; ALTER AVAILABILITY GROUP [gcp-dest-ag] GRANT CREATE ANY DATABASE;
Connettiti alla replica primaria dell'origine SQL Server su AWS utilizzando SSMS ed esegui questo comando T-SQL per creare un gruppo di disponibilità distribuito.
USE [master] GO CREATE AVAILABILITY GROUP [distributed-ag] WITH (DISTRIBUTED) AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOSostituisci
AWS_AGcon il nome del gruppo di disponibilità in AWS eAWS_LISTENERcon il listener del gruppo di disponibilità AWS.Esegui questo comando T-SQL in SSMS su
node-1per aggiungerlo al gruppo di disponibilità distribuito.USE [master] GO ALTER AVAILABILITY GROUP [distributed-ag] JOIN AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOSostituisci
AWS_AGcon il nome del gruppo di disponibilità in AWS eAWS_LISTENERcon il listener del gruppo di disponibilità AWS.Esegui questo comando T-SQL su "node-1" per verificare che tutti i gruppi di disponibilità siano integri e vengano replicati nel gruppo di disponibilità distribuito nel nuovo cluster SQL Server su Google Cloud
SELECT * FROM sys.dm_hadr_availability_group_states GO