Ce tutoriel vous présente les différentes approches que vous pouvez utiliser pour migrer une base de données Microsoft SQL Server sur Amazon Elastic Compute Cloud (AWS EC2) vers Compute Engine.
Cette page aborde les approches suivantes :
- Migrer à l'aide d'une sauvegarde complète et d'une restauration
- Migrer à l'aide d'un fichier BACPAC
- Migrer à l'aide des groupes de disponibilité Always On
- Migrer à l'aide de groupes de disponibilité distribués
Chaque méthode de migration présente des avantages et des inconvénients différents. La stratégie de migration la plus adaptée dépend de votre situation et de vos priorités spécifiques. Nous vous recommandons de choisir la méthode de migration qui vous convient le mieux en fonction des éléments suivants :
Disponibilité : vérifiez si une approche de migration est compatible avec toutes les versions et licences de votre base de données SQL Server.
Taille de la base de données : la taille de la base de données peut avoir un impact significatif sur les options de migration possibles, car les bases de données plus volumineuses peuvent nécessiter des stratégies différentes de celles plus petites. Lorsque vous choisissez une approche de migration, tenez compte de la durée du transfert de données, des temps d'arrêt potentiels et des besoins en ressources.
Tolérance aux temps d'arrêt : le niveau de temps d'arrêt acceptable pendant la migration est un facteur crucial. Certaines méthodes permettent de réduire au minimum, voire d'éliminer les temps d'arrêt, tandis que d'autres nécessitent un temps d'arrêt plus long. Choisissez une approche de migration qui vous offre un temps d'arrêt acceptable.
Complexité : la complexité du schéma de base de données, des dépendances des applications et de l'environnement global peut influencer l'approche de la migration. Assurez-vous que la méthode de migration que vous choisissez est compatible avec la migration des objets non liés à la base de données, tels que les jobs de l'agent SQL, les serveurs associés, les autorisations et les objets utilisateur.
Coût : l'aspect financier de la migration peut également être un facteur à prendre en compte. Différentes méthodes de migration entraînent des coûts variables associés au transfert de données, aux ressources de calcul et à d'autres services. Choisissez la méthode de migration qui vous convient le mieux.
Sécurité et conformité des données : assurez-vous que la méthode de migration choisie respecte vos exigences en termes de sécurité et de conformité des données. Pensez au chiffrement des données, aux contrôles d'accès et à toute exigence spécifique au secteur qui s'applique à vos données.
Préparer le projet et le réseau
Pour préparer votre projet Google Cloud et votre cloud privé virtuel (VPC) pour le déploiement de SQL Server pour la migration, procédez comme suit :
Dans la console Google Cloud , cliquez sur Activer Cloud Shell
 pour ouvrir Cloud Shell.
pour ouvrir Cloud Shell.Définissez votre ID de projet par défaut :
gcloud config set project
PROJECT_IDRemplacez
PROJECT_IDpar l'ID de votre projet Google Cloud .Définissez votre région par défaut :
gcloud config set compute/region
REGIONRemplacez
REGIONpar l'ID de la région dans laquelle vous souhaitez effectuer le déploiement.Définissez votre zone par défaut :
gcloud config set compute/zone
ZONERemplacez
ZONEpar l'ID de la zone dans laquelle vous souhaitez effectuer le déploiement. Assurez-vous que la zone est valide dans la région que vous avez spécifiée à l'étape précédente.
Créer une instance SQL Server sur Compute Engine
Avant de migrer votre base de données SQL Server vers Compute Engine, vous devez créer une machine virtuelle (VM) sur Compute Engine pour l'héberger.
Exécutez la commande suivante pour créer une instance SQL Server sur Compute Engine :
Standard 2022
gcloud compute instances create sql-server-std-migrate-vm \ --project=PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-standard-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write
Remplacez les éléments suivants :
PROJECT_ID: ID de votre projet Google Cloud .ZONEavec l'ID de la zone.SUBNET_NAMEavec le nom de votre sous-réseau VPC.
2022 Enterprise
gcloud compute instances create sql-server-ent-migrate-vm \ --project=PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-enterprise-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write
Remplacez les éléments suivants :
PROJECT_ID: ID de votre projet Google Cloud .ZONEavec l'ID de la zone.SUBNET_NAMEavec le nom de votre sous-réseau VPC.
Pour en savoir plus sur la création d'instances SQL Server sur Compute Engine, consultez Créer une instance SQL Server.
Configurer votre VM SQL Server et vous y connecter
Pour configurer votre VM SQL Server et vous y connecter, procédez comme suit :
Définissez le mot de passe Windows initial pour votre compte :
Dans la console Google Cloud , accédez à la page Instances de VM.
Cliquez sur le nom de la VM SQL Server.
Cliquez sur le bouton Définir un mot de passe Windows.
Saisissez un mot de passe, puis cliquez sur Définir lorsque vous êtes invité à définir le nouveau mot de passe Windows.
Enregistrez le nom d'utilisateur et le mot de passe.
Connectez-vous à la VM SQL Server :
Utilisez l'adresse IP publique de la VM SQL Server sur la page Instances de VM et les identifiants enregistrés à l'étape précédente pour vous connecter à votre VM SQL Server à l'aide du Bureau à distance Microsoft (RDP).
Exécutez SQL Server Management Studio (SSMS) en tant qu'administrateur.
Vérifiez que la case Faire confiance au certificat du serveur est cochée, puis cliquez sur Se connecter.
Votre VM SQL Server est désormais prête à être utilisée pour la migration de la base de données. Pour créer des identifiants utilisateur afin de vous connecter à votre VM SQL Server et de la gérer, consultez Créer un identifiant.
Sauvegarde et restauration complètes de la base de données
La sauvegarde et la restauration complètes de la base de données constituent la méthode de migration de base de données la plus courante et la plus simple. Avec cette approche, une sauvegarde complète de la base de données SQL Server est effectuée à partir de l'environnement source, puis restaurée dans l'environnement de destination Google Cloud . Bien que cette méthode soit relativement simple, elle peut prendre du temps pour les bases de données volumineuses en raison du temps nécessaire pour créer et restaurer la sauvegarde.
Cette section explique comment utiliser SSMS pour exporter votre base de données SQL Server à l'aide d'un exemple de base de données AdventureWorks2022.
Créer une sauvegarde complète de la base de données
Pour créer une sauvegarde complète de la base de données, procédez comme suit :
Connectez-vous à votre VM AWS EC2 à l'aide de Microsoft RDP.
Connectez-vous à SQL Server à l'aide de SSMS.
Développez le dossier des bases de données dans l'explorateur d'objets.
Effectuez un clic droit sur le nom de la base de données, puis cliquez sur Tasks (Tâches) dans le menu.
Cliquez sur Sauvegarder pour ouvrir l'assistant de sauvegarde de la base de données.
Vérifiez que le nom de la base de données à sauvegarder et le type de sauvegarde sont définis sur "Complète".
Cliquez sur Ajouter sous la destination de la sauvegarde complète.
Cliquez sur l'icône (...) pour sélectionner le dossier et le nom du fichier de sauvegarde.
Cliquez sur OK pour définir le nom du fichier, puis de nouveau sur OK pour définir la destination.
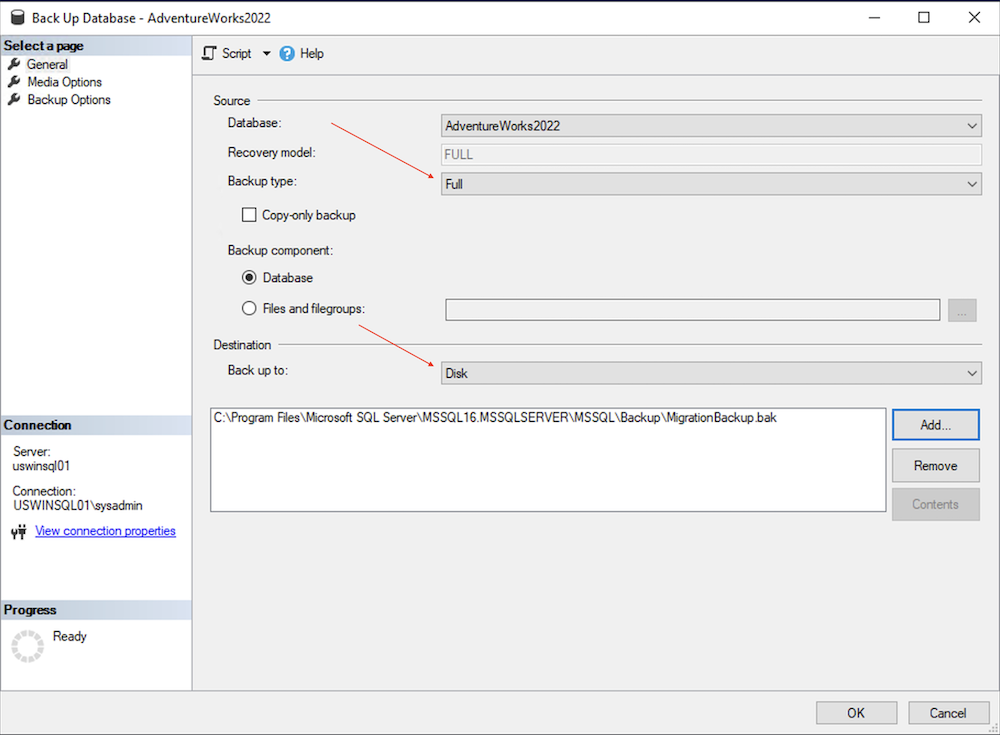
Cliquez sur OK pour démarrer la sauvegarde de la base de données et attendez qu'elle se termine.
Une fois le processus de sauvegarde terminé, un fichier de sauvegarde est créé. Vous pouvez désormais utiliser ce fichier de sauvegarde pour migrer le contenu de la base de données vers une VM Compute Engine.
Cliquez sur OK pour quitter l'assistant de sauvegarde de la base de données.
Transférer le fichier de sauvegarde vers une VM Compute Engine
Pour migrer le contenu de votre base de données SQL Server, vous devez transférer le fichier de sauvegarde créé à l'étape précédente vers la VM Compute Engine que vous avez créée. Pour en savoir plus sur les différentes options de transfert, consultez Transférer des fichiers vers des VM Windows.
Restaurer votre base de données SQL Server à partir du fichier de sauvegarde
Pour restaurer la base de données à partir du fichier de sauvegarde, procédez comme suit :
Connectez-vous à votre VM Compute Engine à l'aide de RDP.
Connectez-vous à SQL Server à l'aide de SSMS.
Dans l'explorateur d'objets, effectuez un clic droit sur le dossier Databases (Bases de données), puis cliquez sur Restore Database (Restaurer la base de données).
Pour la Source, cliquez sur Appareil, puis sur l'icône en forme de points de suspension (...) pour ouvrir la page "Sélectionner un appareil de sauvegarde".
Vérifiez que le type de support de sauvegarde est défini sur "Fichier", puis cliquez sur Ajouter pour sélectionner le fichier de sauvegarde.
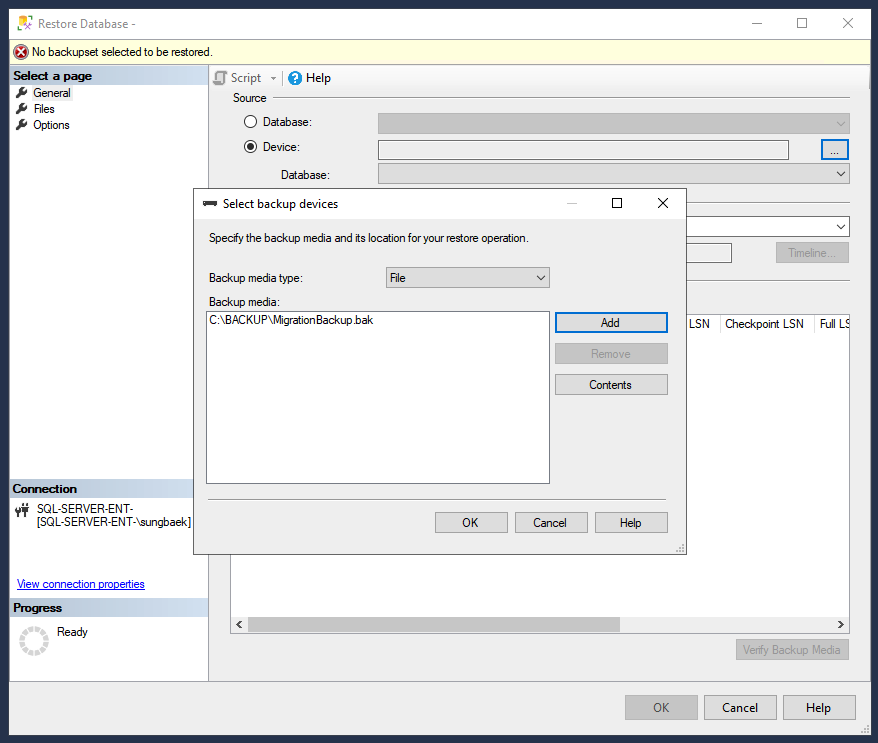
Cliquez sur OK pour définir le fichier de sauvegarde comme appareil de restauration.
Cliquez sur OK pour restaurer la base de données.
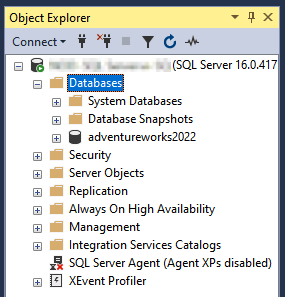
Une fois le processus terminé, votre base de données est migrée vers le serveur SQL Server de destination sur Compute Engine.
Pour vérifier que le processus s'est terminé correctement, vous pouvez développer le dossier databases (bases de données) dans l'explorateur d'objets et vérifier si la base de données migrée est visible.
Migrer à l'aide d'un fichier BACPAC
Un fichier de package de sauvegarde (BACPAC) est une représentation logique d'une base de données SQL Server. Il peut être exporté depuis l'environnement AWS source, puis importé dans l'environnement Google Cloud de destination. Cette méthode est généralement plus rapide qu'une sauvegarde et une restauration complètes pour les petites bases de données, mais elle peut ne pas convenir aux très grandes bases de données ni à celles qui présentent des dépendances complexes.
La section suivante explique comment migrer votre base de données SQL Server à l'aide d'un fichier BACPAC.
Créer une exportation BACPAC
Pour créer une exportation BACPAC, procédez comme suit :
Connectez-vous à la VM AWS EC2 à l'aide de Microsoft RDP.
Connectez-vous à SQL Server à l'aide de SSMS.
Développez le dossier databases dans l'explorateur d'objets.
Effectuez un clic droit sur le nom de la base de données, puis cliquez sur Tasks (Tâches).
Cliquez sur Exporter l'application de niveau Données pour ouvrir l'assistant d'exportation.
Cliquez sur Suivant.
Cliquez sur Parcourir dans l'option Enregistrer sur le disque local, puis sélectionnez le fichier BACPAC.
Cliquez sur l'onglet Avancé, puis sélectionnez le ou les schémas que vous souhaitez exporter.
Cliquez sur Suivant pour accéder au récapitulatif.
Cliquez sur Terminer pour exporter le fichier BACPAC et attendez que l'exportation se termine.
Cliquez sur Fermer pour quitter l'assistant.
Transférez le fichier BACPAC créé lors des étapes précédentes vers votre VM de destination sur Compute Engine. Pour en savoir plus sur les options de transfert, consultez Transférer des fichiers vers des VM Windows.
Restaurer votre base de données SQL Server à partir d'un fichier BACPAC
Pour restaurer la base de données à partir du fichier BACPAC, procédez comme suit :
Connectez-vous à la VM Compute Engine à l'aide de RDP.
Connectez-vous à SQL Server à l'aide de SSMS.
Dans l'explorateur d'objets, effectuez un clic droit sur le dossier Databases (Bases de données), puis cliquez sur Import Data-tier Application (Importer une application de niveau Données).
Cliquez sur Suivant.
Cliquez sur Parcourir, sélectionnez le fichier BACPAC que vous souhaitez restaurer, puis cliquez sur Suivant.
Vérifiez le nom de la nouvelle base de données, puis cliquez sur Suivant.
Cliquez sur Terminer et attendez que l'importation soit terminée.
Cliquez sur Fermer pour quitter l'assistant.
Pour vérifier que le processus s'est terminé correctement, vous pouvez développer le dossier databases (bases de données) dans l'explorateur d'objets et vérifier si la base de données migrée est visible.
Migrer à l'aide des groupes de disponibilité Always On
Un AOAG est une fonctionnalité de haute disponibilité et de reprise après sinistre de SQL Server. Vous pouvez utiliser un groupe de disponibilité AlwaysOn pour migrer des clusters de groupes de disponibilité AlwaysOn existants, des serveurs SQL autonomes et des clusters de basculement Windows Server (WSFC). Avec cette méthode, une réplique de la base de données est créée dans l'environnement de destination Google Cloud et les données sont synchronisées entre la source et la cible. Une fois la synchronisation terminée, l'instance répliquée dans l'environnement Google Cloud de destination peut être définie comme principale. Cette méthode minimise les temps d'arrêt, mais nécessite une configuration et une configuration supplémentaires. Pour les migrations simples avec une tolérance aux temps d'arrêt importante, d'autres méthodes peuvent être plus simples et plus économiques.
Avant de commencer
Avant de commencer la migration, assurez-vous des points suivants :
Pour assurer une transition sécurisée et fluide des données, établissez une connexion d'appairage entre AWS et Google Cloud. Pour en savoir plus, consultez Créer des connexions VPN haute disponibilité entre Google Cloud et AWS.
Assurez-vous que la base de données source est exécutée en mode autonome et que les serveurs source et de destination sont associés à un annuaire Active Directory (AD). Si la base de données source fait déjà partie d'un cluster WSFC à l'aide d'un groupe de disponibilité AlwaysOn, consultez Migrer à l'aide de groupes de disponibilité distribués.
Assurez-vous que toutes les clés de chiffrement de la base de données SQL Server source sont installées sur toutes les instances SQL Server qui rejoindront le groupe AOAG.
Préparer votre serveur SQL Server à faire partie d'un groupe AOAG
Pour pouvoir ajouter des serveurs SQL à un groupe AOAG, vous devez activer la fonctionnalité AOAG sur toutes les instances SQL Server que vous souhaitez ajouter au groupe.
Pour activer la fonctionnalité AOAG sur toutes les VM SQL Server que vous souhaitez ajouter à un AOAG, procédez comme suit :
Activez AOAG sur votre serveur SQL.
Connectez-vous à votre VM SQL Server à l'aide de RDP.
Ouvrez PowerShell en mode administrateur.
Exécutez la commande suivante pour activer AOAG sur votre serveur SQL Server.
Enable-SqlAlwaysOn -ServerInstance $env:COMPUTERNAME -Force
Exécutez la commande suivante pour ouvrir un port de pare-feu pour la réplication des données.
netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022
Répétez l'étape 1 pour toutes les VM SQL Server que vous souhaitez ajouter au groupe AOAG.
Créez un utilisateur pour votre serveur SQL sur votre AD.
$Credential = Get-Credential -UserName sql_server -Message 'Enter password' New-ADUser ` -Name "sql_server" ` -Description "SQL Admin account." ` -AccountPassword $Credential.Password ` -Enabled $true -PasswordNeverExpires $true
Procédez comme suit sur toutes les instances SQL Server qui font partie du groupe de disponibilité AlwaysOn :
- Accédez à l'outil Gestionnaire de configuration SQL Server.
- Dans le volet de navigation, sélectionnez Services SQL Server.
- Dans la liste des services, faites un clic droit sur SQL Server (MSSQLSERVER), puis sélectionnez Propriétés.
- Sous Se connecter en tant que, modifiez le compte comme suit :
- Nom du compte :
DOMAIN\sql_server, où DOMAIN est le nom NetBIOS de votre domaine AD. - Mot de passe : saisissez le mot de passe que vous avez choisi à l'étape 2 de cette section.
- Nom du compte :
Cliquez sur OK.
Lorsque vous êtes invité à redémarrer SQL Server, sélectionnez Oui.
Votre serveur SQL Server s'exécute désormais sous un compte utilisateur de domaine.
Configurer le point de terminaison de mise en miroir pour votre base de données SQL Server
Pour créer le point de terminaison de votre AOAG, procédez comme suit :
Si la base de données SQL Server source est chiffrée avec le chiffrement TDE (Transparent Data Encryption), suivez cette procédure pour sauvegarder, transférer et installer les certificats et les clés sur le serveur SQL Server de destination.
Connectez-vous à la base de données source sur AWS à l'aide de SSMS.
Exécutez la commande T-SQL suivante pour créer le point de terminaison du groupe de disponibilité.
USE [master] GO CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO USE [DATABASE_NAME] GO CREATE USER [NET_DOMAIN\sql_server] FOR LOGIN [NET_DOMAIN\sql_server] GO USE [master] GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GORemplacez
NET_DOMAINpar le nom NetBIOS de votre domaine AD etDATABASE_NAMEpar le nom de la base de données à migrer.Connectez-vous au serveur SQL de destination sur Google Cloud à l'aide de SSMS et exécutez la commande T-SQL suivante pour créer le point de terminaison de mise en miroir de la base de données.
CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GORemplacez
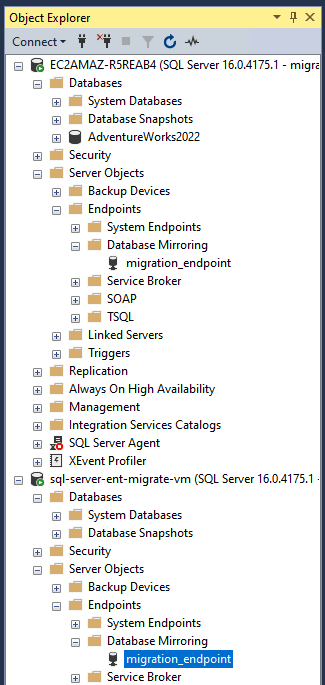
NET_DOMAINpar le nom NetBIOS de votre domaine AD.Vérifiez les points de terminaison en accédant à Objets serveur> Points de terminaison> Mise en miroir de la base de données dans l'explorateur d'objets de SSMS.
Créer le groupe d'accès aux objets
Pour créer un AOAG, procédez comme suit :
Connectez-vous à la base de données source sur AWS à l'aide de SSMS.
Exécutez la commande T-SQL suivante pour définir le mode de récupération de la base de données sur "complet" et effectuer une sauvegarde complète.
USE [master] GO ALTER DATABASE [
DATABASE_NAME] SET RECOVERY FULL; BACKUP DATABASE [DATABASE_NAME] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Backup\DATABASE_NAME.bak';Remplacez
DATABASE_NAMEpar le nom de la base de données à migrer.Exécutez la commande T-SQL suivante pour créer le groupe AOAG.
USE [master] GO CREATE AVAILABILITY GROUP [migration-ag] WITH ( AUTOMATED_BACKUP_PREFERENCE = SECONDARY, DB_FAILOVER = OFF, DTC_SUPPORT = NONE, REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0 ) FOR DATABASE [DATABASE_NAME] REPLICA ON N'SOURCE_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://SOURCE_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ), N'DEST_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://DEST_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ); GORemplacez les éléments suivants :
DATABASE_NAMEavec le nom de la base de données à migrer.SOURCE_SERVERNAMEavec le nom du serveur de la base de données source.DEST_SERVERNAMEavec le nom du serveur de la base de données de destination.SOURCE_HOSTNAME: nom de domaine complet (FQDN) de la source.DEST_HOSTNAMEavec le nom de domaine complet de la cible.
Exécutez la commande T-SQL suivante sur la base de données de destination pour l'ajouter au groupe AOAG.
USE [master] GO ALTER AVAILABILITY GROUP [migration-ag] JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP [migration-ag] GRANT CREATE ANY DATABASE; GO
Vérifiez l'état du groupe AOAG et de la base de données nouvellement créés dans l'Explorateur d'objets ou en exécutant la commande T-SQL suivante.
SELECT * FROM sys.dm_hadr_availability_group_states GO

Le groupe AOAG SQL Server est maintenant configuré et continue de se synchroniser entre AWS et Google Cloud. L'étape suivante consiste à configurer un WSFC et un écouteur pour la haute disponibilité et la reprise après sinistre. Pour en savoir plus, consultez Clustering de basculement Windows Server avec SQL Server et Qu'est-ce qu'un écouteur de groupe de disponibilité ?.
Migrer à l'aide de groupes de disponibilité distribués
Un groupe de disponibilité distribué est un type particulier de groupe de disponibilité qui couvre deux groupes de disponibilité distincts. Il est conçu pour offrir des fonctionnalités de haute disponibilité et de reprise après sinistre dans des zones géographiques dispersées. Cette architecture permet une réplication des données et un basculement fluides entre les groupes de disponibilité principal et secondaire, ce qui est idéal pour la migration de données. Pour en savoir plus, consultez la section Groupes de disponibilité distribués.
.Les sections suivantes expliquent comment migrer votre base de données SQL Server à l'aide de groupes de disponibilité distribués.
Avant de commencer
Assurez-vous de disposer d'un WSFC avec SQL Server utilisant un groupe de disponibilité avec un écouteur de nom de réseau virtuel (VNN), exécuté sur AWS.
Préparer l'environnement de destination
Pour préparer l'environnement de destination, procédez comme suit :
Pour configurer un WSFC avec SQL Server à l'aide d'un groupe de disponibilité avec un équilibreur de charge interne sur Google Cloud, consultez Configurer des groupes de disponibilité AlwaysOn SQL Server avec commit synchrone à l'aide d'un équilibreur de charge interne.
Dans l'explorateur d'objets, vérifiez que
bookshelf-aga été créé et réplique la base de donnéesbookshelf. Une fois la validation effectuée, suivez les étapes suivantes pour supprimer le groupe de disponibilité et la base de données des deux nœuds de votre cluster de basculement.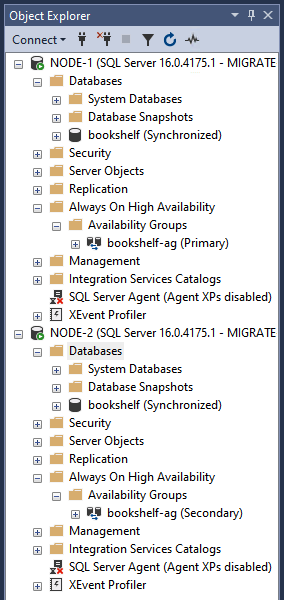
Connectez-vous à
node-1dans SSMS et enregistrez l'adresse IP du récepteurbookshelf.SELECT * FROM sys.availability_group_listeners
Exécutez la commande T-SQL suivante pour supprimer le groupe de disponibilité
bookshelf-aget la base de donnéesbookshelf.USE master GO DROP AVAILABILITY GROUP [bookshelf-ag] GO ALTER DATABASE [bookshelf] SET SINGLE_USER WITH ROLLBACK IMMEDIATE GO DROP DATABASE [bookshelf] GO
Exécutez le code T-SQL suivant sur
node-2dans SSMS pour supprimer la base de données répliquée.USE master GO DROP DATABASE [bookshelf] GO
Créer un groupe de disponibilité distribué
Pour créer un groupe de disponibilité à utiliser pour le groupe de disponibilité distribué, procédez comme suit :
Exécutez la commande T-SQL suivante sur
node-1.USE master GO CREATE AVAILABILITY GROUP [gcp-dest-ag] FOR REPLICA ON N'NODE-1' WITH ( ENDPOINT_URL = N'TCP://NODE-1:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ), N'NODE-2' WITH ( ENDPOINT_URL = N'TCP://NODE-2:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ); GOCréez un écouteur.
USE master; GO ALTER AVAILABILITY GROUP [gcp-dest-ag] ADD LISTENER N'gcp-dest-lsnr' ( WITH IP ( (N'
LISTENER_IP', N'255.255.255.0') ), PORT = 1433); GORemplacez
LISTENER_IPpar l'adresse IP de l'écouteur.Connectez-vous à
node-2à l'aide de SSMS et exécutez la commande T-SQL suivante pour l'ajouter au groupe de disponibilitégcp-dest-ag.USE master GO ALTER AVAILABILITY GROUP [gcp-dest-ag] JOIN; ALTER AVAILABILITY GROUP [gcp-dest-ag] GRANT CREATE ANY DATABASE;
Connectez-vous au réplica principal du serveur SQL source sur AWS à l'aide de SSMS, puis exécutez la commande T-SQL suivante pour créer un groupe de disponibilité distribué.
USE [master] GO CREATE AVAILABILITY GROUP [distributed-ag] WITH (DISTRIBUTED) AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GORemplacez
AWS_AGpar le nom du groupe de disponibilité dans AWS etAWS_LISTENERpar l'écouteur du groupe de disponibilité AWS.Exécutez la commande T-SQL suivante dans SSMS sur
node-1pour l'ajouter au groupe de disponibilité distribué.USE [master] GO ALTER AVAILABILITY GROUP [distributed-ag] JOIN AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GORemplacez
AWS_AGpar le nom du groupe de disponibilité dans AWS etAWS_LISTENERpar l'écouteur du groupe de disponibilité AWS.Exécutez la commande T-SQL suivante sur "node-1" pour vérifier que tous les groupes de disponibilité sont en bon état et qu'ils sont répliqués dans le groupe de disponibilité distribué vers le nouveau cluster SQL Server sur Google Cloud
SELECT * FROM sys.dm_hadr_availability_group_states GO