En este tutorial se explican los distintos métodos que puedes usar para migrar una base de datos de Microsoft SQL Server en Amazon Elastic Compute Cloud (AWS EC2) a Compute Engine.
En esta página se describen los siguientes enfoques:
- Migrar con una copia de seguridad completa y una restauración
- Migrar con un archivo BACPAC
- Migrar con grupos de disponibilidad Always On
- Migrar mediante grupos de disponibilidad distribuidos
Cada método de migración tiene sus ventajas e inconvenientes. La estrategia de migración más adecuada depende de tus circunstancias y prioridades específicas. Te recomendamos que elijas el método de migración que mejor se adapte a tus necesidades en función de los siguientes aspectos:
Disponibilidad: comprueba si todas las versiones y licencias de tu base de datos SQL Server admiten un enfoque de migración.
Tamaño de la base de datos: el tamaño de la base de datos puede influir significativamente en las opciones de migración viables, ya que las bases de datos más grandes pueden requerir estrategias diferentes a las más pequeñas. Al elegir un método de migración, ten en cuenta la duración de la transferencia de datos, el posible tiempo de inactividad y los requisitos de recursos.
Tolerancia al tiempo de inactividad: el nivel aceptable de tiempo de inactividad durante la migración es un factor crucial. Algunos métodos permiten que el tiempo de inactividad sea mínimo o casi nulo, mientras que otros requieren un tiempo de inactividad más prolongado. Elige un método de migración que te permita disfrutar de un tiempo de inactividad aceptable.
Complejidad: la complejidad del esquema de la base de datos, las dependencias de las aplicaciones y el entorno en general pueden influir en el enfoque de la migración. Asegúrate de que el método de migración que elijas admita la migración de objetos que no sean de bases de datos, como trabajos de agente SQL, servidores vinculados, permisos y objetos de usuario.
Coste: el aspecto económico de la migración también puede ser un factor a tener en cuenta. Los distintos métodos de migración conllevan costes diferentes asociados a la transferencia de datos, los recursos de computación y otros servicios. Elige el método de migración que mejor se adapte a tus necesidades.
Seguridad y cumplimiento de los datos: asegúrate de que el método de migración elegido cumpla tus requisitos de seguridad y cumplimiento de los datos. Ten en cuenta el cifrado de datos, los controles de acceso y los requisitos específicos del sector que se apliquen a tus datos.
Preparar el proyecto y la red
Para preparar tu proyecto de Google Cloud y tu nube privada virtual (VPC) para desplegar SQL Server para la migración, haz lo siguiente:
En la Google Cloud consola, haz clic en Activar Cloud Shell
 para abrir Cloud Shell.
para abrir Cloud Shell.Configura tu ID de proyecto predeterminado:
gcloud config set project
PROJECT_IDSustituye
PROJECT_IDpor el ID de tu Google Cloud proyecto.Define tu región predeterminada:
gcloud config set compute/region
REGIONSustituye
REGIONpor el ID de la región en la que quieras hacer el despliegue.Define tu zona predeterminada:
gcloud config set compute/zone
ZONESustituye
ZONEpor el ID de la zona en la que quieras implementar el servicio. Asegúrate de que la zona sea válida en la región que has especificado en el paso anterior.
Crear una instancia de SQL Server en Compute Engine
Antes de migrar tu base de datos de SQL Server a Compute Engine, debes crear una máquina virtual (VM) en Compute Engine para alojarla.
Usa el siguiente comando para crear una instancia de SQL Server en Compute Engine:
Estándar del 2022
gcloud compute instances create sql-server-std-migrate-vm \ --project=PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-standard-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write
Haz los cambios siguientes:
PROJECT_ID: con el ID de tu proyecto de Google Cloud .ZONE: con el ID de la zona.SUBNET_NAME: con el nombre de tu subred de VPC.
2022 Enterprise
gcloud compute instances create sql-server-ent-migrate-vm \ --project=PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-enterprise-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write
Haz los cambios siguientes:
PROJECT_ID: con el ID de tu proyecto de Google Cloud .ZONE: con el ID de la zona.SUBNET_NAME: con el nombre de tu subred de VPC.
Para obtener más información sobre cómo crear instancias de SQL Server en Compute Engine, consulta Crear una instancia de SQL Server.
Configurar una máquina virtual de SQL Server y conectarse a ella
Para configurar tu máquina virtual de SQL Server y conectarte a ella, sigue estos pasos:
Establece la contraseña inicial de Windows para tu cuenta:
En la consola de Google Cloud , ve a la página Instancias de VM.
Haz clic en el nombre de la VM del servidor SQL.
Haz clic en el botón Definir contraseña de Windows.
Introduce una contraseña y haz clic en Configurar cuando se te pida que establezcas la nueva contraseña de Windows.
Guarda el nombre de usuario y la contraseña.
Conéctate a la VM de SQL Server:
Usa la dirección IP pública de la máquina virtual de SQL Server de la página Instancias de VM y las credenciales guardadas en el paso anterior para conectarte a tu máquina virtual de SQL Server mediante Escritorio remoto de Microsoft (RDP).
Ejecuta SQL Server Management Studio (SSMS) como administrador.
Comprueba que la casilla Confiar en el certificado del servidor esté marcada y haz clic en Conectar.
Tu VM de SQL Server ya está lista para usarse en la migración de bases de datos. Para crear nuevos inicios de sesión de usuario para conectarte a tu VM de SQL Server y gestionarla, consulta Crear un inicio de sesión.
Copia de seguridad y restauración completas de bases de datos
La copia de seguridad y restauración completas de la base de datos es el método más habitual y sencillo para migrar bases de datos. Con este método, se crea una copia de seguridad completa de la base de datos de SQL Server en el entorno de origen y, a continuación, se restaura en el entorno de destino. Google Cloud Aunque este método es relativamente sencillo, puede llevar mucho tiempo en bases de datos grandes, ya que se tarda en crear y restaurar la copia de seguridad.
En esta sección se explica cómo puedes usar SSMS para exportar tu base de datos de SQL Server con una base de datos de ejemplo AdventureWorks2022.
Crear una copia de seguridad completa de la base de datos
Para crear una copia de seguridad completa de la base de datos, sigue estos pasos:
Inicia sesión en tu máquina virtual de AWS EC2 con RDP de Microsoft.
Conéctate a SQL Server mediante SSMS.
Expanda la carpeta de bases de datos en el Explorador de objetos.
Haz clic con el botón derecho en el nombre de la base de datos y, en el menú, selecciona Tareas.
Haz clic en Crear copia de seguridad para abrir el asistente de copia de seguridad de la base de datos.
Verifica el nombre de la base de datos de la que quieres crear una copia de seguridad y que el tipo de copia de seguridad sea Completa.
Haz clic en Añadir debajo del destino de la copia de seguridad completa.
Haz clic en el icono de los puntos suspensivos (...) para seleccionar la carpeta y el nombre del archivo de copia de seguridad.
Haz clic en Aceptar para definir el nombre del archivo y, de nuevo, en Aceptar para definir el destino.
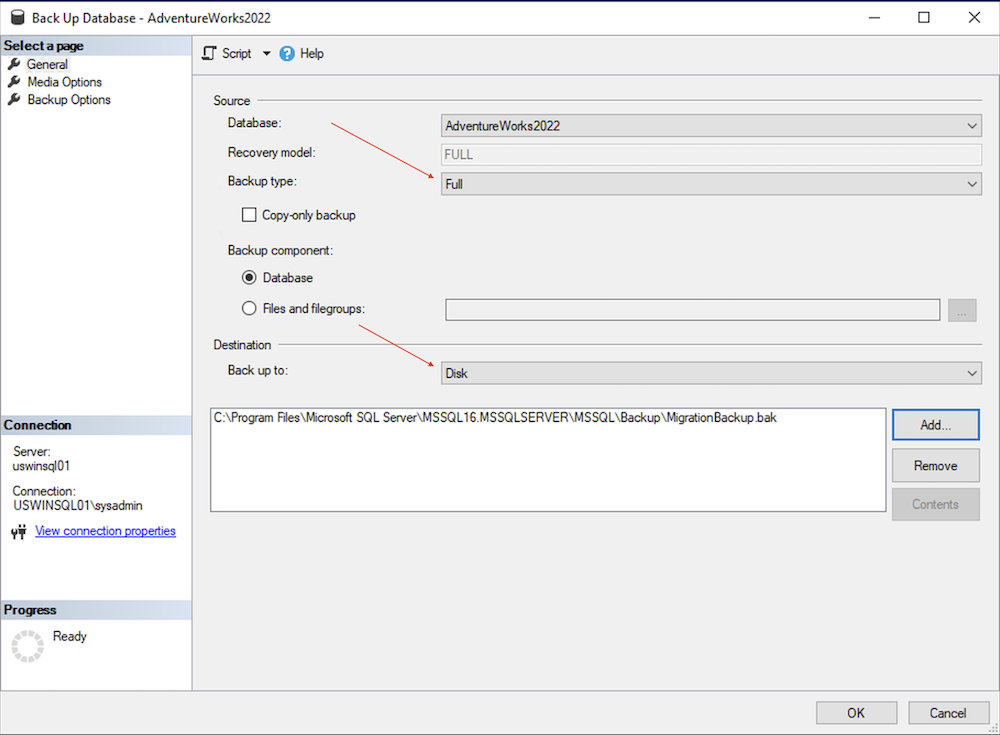
Haz clic en Aceptar para iniciar la copia de seguridad de la base de datos y espera a que se complete.
Una vez completado el proceso de copia de seguridad, se crea un archivo de copia de seguridad. Ahora puedes usar este archivo de copia de seguridad para migrar el contenido de la base de datos a una VM de Compute Engine.
Haga clic en Aceptar para salir del asistente de copia de seguridad de la base de datos.
Transferir el archivo de copia de seguridad a una máquina virtual de Compute Engine
Para migrar el contenido de tu base de datos de SQL Server, debes transferir el archivo de copia de seguridad creado en el paso anterior a la VM de Compute Engine que has creado. Para obtener información sobre las distintas opciones de transferencia, consulta Transferir archivos a máquinas virtuales de Windows.
Restaurar la base de datos de SQL Server desde el archivo de copia de seguridad
Para restaurar la base de datos a partir del archivo de copia de seguridad, sigue estos pasos:
Inicia sesión en tu VM de Compute Engine mediante RDP.
Conéctate a SQL Server mediante SSMS.
En el Explorador de objetos, haga clic con el botón derecho en la carpeta Bases de datos y, a continuación, en Restaurar base de datos.
En Fuente, haz clic en Dispositivo y en el icono de los puntos suspensivos (...) para abrir la página Seleccionar dispositivo de copia de seguridad.
Comprueba que el tipo de medio de copia de seguridad sea Archivo y haz clic en Añadir para seleccionar el archivo de copia de seguridad.
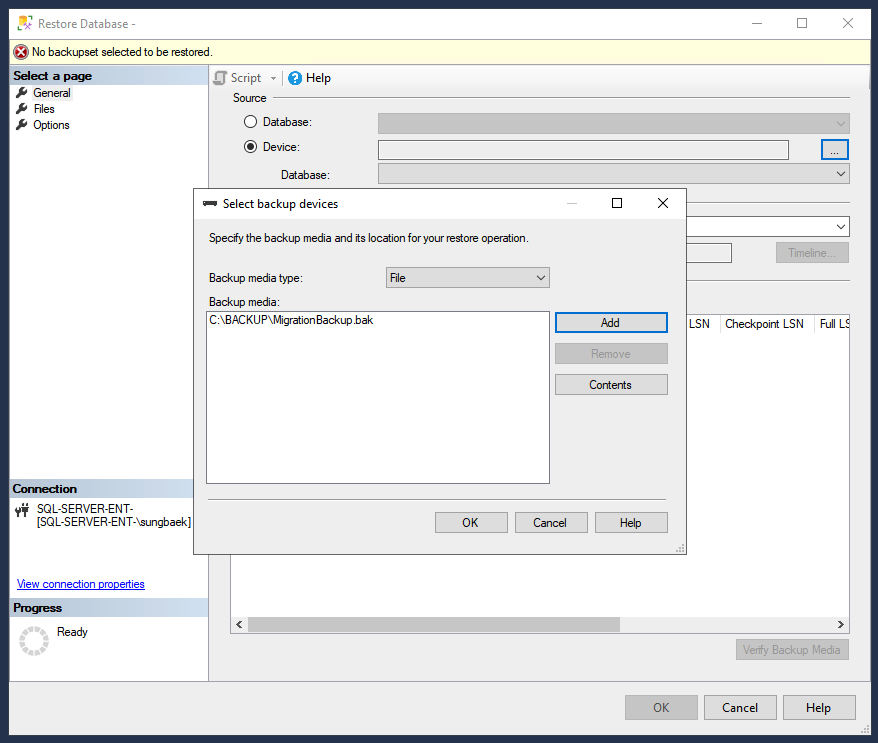
Haz clic en Aceptar para definir el archivo de copia de seguridad como dispositivo de restauración.
Haz clic en Aceptar para restaurar la base de datos.
Cuando se complete el proceso, tu base de datos se migrará a la instancia de SQL Server de destino en Compute Engine.
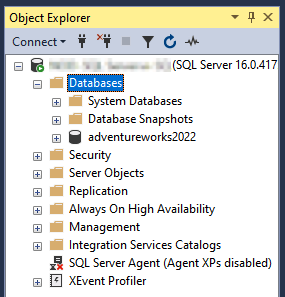
Para comprobar si el proceso se ha completado correctamente, puedes desplegar la carpeta bases de datos en el Explorador de objetos y verificar si puedes ver la base de datos migrada.
Migrar con un archivo BACPAC
Un archivo de paquete de copia de seguridad (BACPAC) es una representación lógica de una base de datos de SQL Server. Se puede exportar desde el entorno de AWS de origen y, a continuación, importarlo al entorno de destino. Google Cloud Este método suele ser más rápido que una copia de seguridad completa y una restauración en bases de datos más pequeñas, pero puede que no sea adecuado para bases de datos muy grandes o con dependencias complejas.
En la siguiente sección se explica cómo migrar la base de datos de SQL Server mediante un archivo BACPAC.
Crear una exportación BACPAC
Para crear una exportación BACPAC, sigue estos pasos:
Inicia sesión en la máquina virtual de AWS EC2 con RDP de Microsoft.
Conéctate a SQL Server mediante SSMS.
Expanda la carpeta bases de datos en el Explorador de objetos.
Haz clic con el botón derecho en el nombre de la base de datos y, a continuación, en Tareas.
Haz clic en Exportar aplicación de nivel de datos para abrir el asistente de exportación.
Haz clic en Siguiente.
Haga clic en Examinar en la opción Guardar en disco local y seleccione el archivo BACPAC.
Haz clic en la pestaña Avanzado y selecciona los esquemas que quieras exportar.
Haz clic en Siguiente para ir al resumen.
Haz clic en Finalizar para exportar el archivo BACPAC y espera a que se complete la exportación.
Haz clic en Cerrar para salir del asistente.
Transfiere el archivo BACPAC creado en los pasos anteriores a la máquina virtual de destino en Compute Engine. Para obtener información sobre las opciones de transferencia, consulta Transferir archivos a máquinas virtuales de Windows.
Restaurar una base de datos de SQL Server a partir de un archivo BACPAC
Para restaurar la base de datos a partir del archivo BACPAC, sigue estos pasos:
Inicia sesión en la VM de Compute Engine mediante RDP.
Conéctate a SQL Server mediante SSMS.
En el Explorador de objetos, haga clic con el botón derecho en la carpeta Bases de datos y, a continuación, haga clic en Importar aplicación de nivel de datos.
Haz clic en Siguiente.
Haga clic en Examinar, seleccione el archivo BACPAC que quiera restaurar y, a continuación, haga clic en Siguiente.
Verifica el nombre de la nueva base de datos y haz clic en Siguiente.
Haz clic en Finalizar y espera a que se complete la importación.
Haz clic en Cerrar para salir del asistente.
Para comprobar si el proceso se ha completado correctamente, puedes desplegar la carpeta bases de datos en el Explorador de objetos y verificar si puedes ver la base de datos migrada.
Migrar mediante grupos de disponibilidad Always On
Un grupo de disponibilidad Always On es una función de alta disponibilidad y recuperación tras fallos de SQL Server. Puedes usar un grupo de disponibilidad AlwaysOn para migrar clústeres de grupos de disponibilidad AlwaysOn, servidores SQL independientes y clústeres de conmutación por error de Windows Server. Con este método, se crea una réplica de la base de datos en el entorno de destino y los datos se sincronizan entre el origen y el destino. Google Cloud Una vez completada la sincronización, la réplica del entorno de destino Google Cloud se puede convertir en principal. Este método minimiza el tiempo de inactividad, pero requiere una configuración adicional. En el caso de migraciones sencillas con una tolerancia significativa al tiempo de inactividad, puede que otros métodos sean más sencillos y rentables.
Antes de empezar
Antes de empezar la migración, asegúrate de lo siguiente:
Para asegurar una transición de datos segura y fluida, establece una conexión de emparejamiento entre AWS y Google Cloud. Para obtener más información, consulta Crear conexiones VPN de alta disponibilidad entre Google Cloud y AWS.
Asegúrate de que la base de datos de origen se esté ejecutando en modo independiente y de que los servidores de origen y de destino estén unidos a un Active Directory (AD). Si la base de datos de origen ya forma parte de un clúster WSFC que usa un grupo de disponibilidad Always On, consulta Migrar mediante grupos de disponibilidad distribuidos.
Asegúrate de que todas las claves de cifrado de la base de datos de SQL Server de origen estén instaladas en todas las instancias de SQL Server que se unirán al grupo de disponibilidad Always On.
Preparar SQL Server para que forme parte de un grupo de disponibilidad Always On
Para poder añadir servidores SQL a un grupo de disponibilidad Always On, debes habilitar la función de grupo de disponibilidad Always On en todas las instancias de SQL Server que quieras añadir al grupo.
Para habilitar la función de grupo de disponibilidad Always On en todas las máquinas virtuales de SQL Server que quieras añadir a un grupo de disponibilidad Always On, sigue estos pasos:
Habilita AOAG en tu SQL Server.
Inicia sesión en tu máquina virtual de SQL Server mediante RDP.
Abre PowerShell en modo administrador.
Ejecuta el siguiente comando para habilitar AOAG en tu SQL Server.
Enable-SqlAlwaysOn -ServerInstance $env:COMPUTERNAME -Force
Ejecuta el siguiente comando para abrir un puerto de cortafuegos para la replicación de datos.
netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022
Repita el paso 1 para todas las máquinas virtuales de SQL Server que quiera añadir al grupo de disponibilidad Always On.
Crea un usuario para tu SQL Server en tu AD.
$Credential = Get-Credential -UserName sql_server -Message 'Enter password' New-ADUser ` -Name "sql_server" ` -Description "SQL Admin account." ` -AccountPassword $Credential.Password ` -Enabled $true -PasswordNeverExpires $true
Sigue estos pasos en todas las instancias de SQL Server que formen parte del grupo de disponibilidad Always On:
- Abre SQL Server Configuration Manager.
- En el panel de navegación, selecciona Servicios de SQL Server.
- En la lista de servicios, haz clic con el botón derecho en SQL Server (MSSQLSERVER) y selecciona Propiedades.
- En Iniciar sesión como, cambia la cuenta de la siguiente manera:
- Nombre de la cuenta:
DOMAIN\sql_server, donde DOMINIO es el nombre NetBIOS de tu dominio de AD. - Contraseña: introduce la contraseña que has elegido en el paso 2 de esta sección.
- Nombre de la cuenta:
Haz clic en Aceptar.
Cuando se te pida que reinicies SQL Server, selecciona Sí.
SQL Server ahora se ejecuta con una cuenta de usuario de dominio.
Configurar el endpoint de creación de reflejo de la base de datos de SQL Server
Para crear el endpoint de tu AOAG, sigue estos pasos:
Si la base de datos de SQL Server de origen está cifrada con cifrado de datos transparente (TDE), sigue este paso para crear una copia de seguridad, transferir e instalar los certificados y las claves en el servidor de SQL de destino.
Inicia sesión en la base de datos de origen de AWS mediante SSMS.
Ejecuta el siguiente comando de T-SQL para crear el endpoint del grupo de disponibilidad.
USE [master] GO CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO USE [DATABASE_NAME] GO CREATE USER [NET_DOMAIN\sql_server] FOR LOGIN [NET_DOMAIN\sql_server] GO USE [master] GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GOSustituye
NET_DOMAINpor el nombre NetBIOS de tu dominio de AD yDATABASE_NAMEpor el nombre de la base de datos que quieras migrar.Conéctate al servidor SQL de destino en Google Cloud mediante SSMS y ejecuta el siguiente comando de Transact-SQL para crear el endpoint de creación de reflejo de la base de datos.
CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GOSustituye
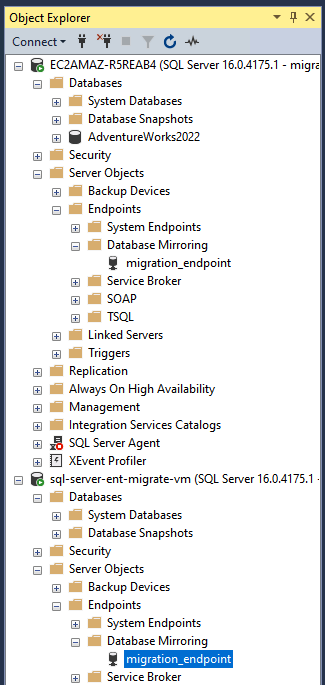
NET_DOMAINpor el nombre NetBIOS de tu dominio de AD.Para verificar los endpoints, vaya a Objetos de servidor > Endpoints > Creación de reflejo de la base de datos en el Explorador de objetos de SSMS.
Crear el AOAG
Para crear un AOAG, sigue estos pasos:
Inicia sesión en la base de datos de origen de AWS mediante SSMS.
Ejecuta el siguiente comando T-SQL para definir el modo de recuperación de la base de datos como completo y crear una copia de seguridad completa.
USE [master] GO ALTER DATABASE [
DATABASE_NAME] SET RECOVERY FULL; BACKUP DATABASE [DATABASE_NAME] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Backup\DATABASE_NAME.bak';Sustituye
DATABASE_NAMEpor el nombre de la base de datos que quieras migrar.Ejecuta el siguiente comando de T-SQL para crear el grupo de disponibilidad Always On.
USE [master] GO CREATE AVAILABILITY GROUP [migration-ag] WITH ( AUTOMATED_BACKUP_PREFERENCE = SECONDARY, DB_FAILOVER = OFF, DTC_SUPPORT = NONE, REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0 ) FOR DATABASE [DATABASE_NAME] REPLICA ON N'SOURCE_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://SOURCE_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ), N'DEST_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://DEST_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ); GOHaz los cambios siguientes:
DATABASE_NAME: con el nombre de la base de datos que se va a migrar.SOURCE_SERVERNAME: con el nombre del servidor de la base de datos de origen.DEST_SERVERNAME: con el nombre del servidor de la base de datos de destino.SOURCE_HOSTNAME: con el nombre de dominio completo (FQDN) de la fuente.DEST_HOSTNAME: con el FQDN del objetivo.
Ejecuta el siguiente comando T-SQL en la base de datos de destino para añadirla al grupo de disponibilidad Always On.
USE [master] GO ALTER AVAILABILITY GROUP [migration-ag] JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP [migration-ag] GRANT CREATE ANY DATABASE; GO
Verifica el estado del grupo de disponibilidad Always On y de la base de datos recién creados en el Explorador de objetos o ejecutando el siguiente comando de Transact-SQL.
SELECT * FROM sys.dm_hadr_availability_group_states GO
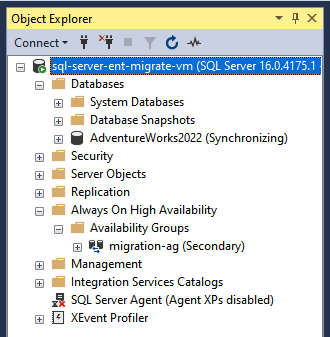
El grupo de disponibilidad Always On de SQL Server ya está configurado y sigue sincronizándose entre AWS y Google Cloud. A continuación, debe configurar un WSFC y un receptor para la alta disponibilidad y la recuperación tras desastres. Para obtener más información, consulta Clústeres de conmutación por error de Windows Server con SQL Server y ¿Qué es un agente de escucha de grupo de disponibilidad?
Migrar con grupos de disponibilidad distribuidos
Un grupo de disponibilidad distribuido es un tipo especial de grupo de disponibilidad que abarca dos grupos de disponibilidad independientes. Está diseñado para ofrecer alta disponibilidad y recuperación tras fallos en ubicaciones geográficamente dispersas. Esta arquitectura permite la replicación de datos y la conmutación por error entre los grupos de disponibilidad principal y secundario, lo que resulta ideal para la migración de datos. Para obtener información más detallada, consulta Grupos de disponibilidad distribuidos.
.En las siguientes secciones se explica cómo migrar tu base de datos de SQL Server mediante grupos de disponibilidad distribuidos.
Antes de empezar
Asegúrate de que tienes un clúster de conmutación por error de Windows Server (WSFC) con SQL Server que usa un grupo de disponibilidad con un receptor de nombres de red virtual (VNN) que se ejecuta en AWS.
Preparar el entorno de destino
Para preparar el entorno de destino, siga estos pasos:
Para configurar un clúster de conmutación por error de Windows Server con SQL Server mediante un grupo de disponibilidad con un balanceador de carga interno en Google Cloud, consulta Configurar grupos de disponibilidad Always On de SQL Server con confirmación síncrona mediante un balanceador de carga interno.
En el Explorador de objetos, comprueba que se ha creado
bookshelf-agy que está replicando la base de datosbookshelf. Una vez verificados, sigue los pasos que se indican a continuación para quitar el grupo de disponibilidad y la base de datos de ambos nodos del clúster de conmutación por error.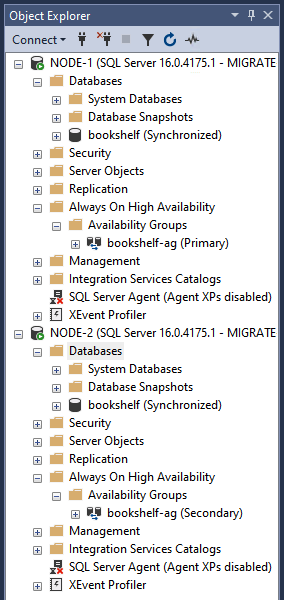
Conéctate a
node-1en SSMS y guarda la dirección IP del receptorbookshelf.SELECT * FROM sys.availability_group_listeners
Ejecuta el siguiente comando de T-SQL para quitar el grupo de disponibilidad
bookshelf-agy la base de datosbookshelf.USE master GO DROP AVAILABILITY GROUP [bookshelf-ag] GO ALTER DATABASE [bookshelf] SET SINGLE_USER WITH ROLLBACK IMMEDIATE GO DROP DATABASE [bookshelf] GO
Ejecuta el siguiente T-SQL en
node-2en SSMS para quitar la base de datos replicada.USE master GO DROP DATABASE [bookshelf] GO
Crear un grupo de disponibilidad distribuido
Para crear un grupo de disponibilidad que se usará en el grupo de disponibilidad distribuido, siga estos pasos:
Ejecuta el siguiente comando T-SQL en
node-1.USE master GO CREATE AVAILABILITY GROUP [gcp-dest-ag] FOR REPLICA ON N'NODE-1' WITH ( ENDPOINT_URL = N'TCP://NODE-1:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ), N'NODE-2' WITH ( ENDPOINT_URL = N'TCP://NODE-2:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ); GOCrea un detector.
USE master; GO ALTER AVAILABILITY GROUP [gcp-dest-ag] ADD LISTENER N'gcp-dest-lsnr' ( WITH IP ( (N'
LISTENER_IP', N'255.255.255.0') ), PORT = 1433); GOSustituye
LISTENER_IPpor la dirección IP del receptor.Conéctate a
node-2mediante SSMS y ejecuta el siguiente comando de Transact-SQL para añadirlo al grupo de disponibilidad degcp-dest-ag.USE master GO ALTER AVAILABILITY GROUP [gcp-dest-ag] JOIN; ALTER AVAILABILITY GROUP [gcp-dest-ag] GRANT CREATE ANY DATABASE;
Conéctate a la réplica principal de la instancia de SQL Server de origen en AWS mediante SSMS y ejecuta el siguiente comando de T-SQL para crear un grupo de disponibilidad distribuido.
USE [master] GO CREATE AVAILABILITY GROUP [distributed-ag] WITH (DISTRIBUTED) AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOSustituye
AWS_AGpor el nombre del grupo de disponibilidad en AWS yAWS_LISTENERpor el del receptor del grupo de disponibilidad de AWS.Ejecuta el siguiente comando T-SQL en SSMS en
node-1para añadirlo al grupo de disponibilidad distribuido.USE [master] GO ALTER AVAILABILITY GROUP [distributed-ag] JOIN AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOSustituye
AWS_AGpor el nombre del grupo de disponibilidad en AWS yAWS_LISTENERpor el del receptor del grupo de disponibilidad de AWS.Ejecuta el siguiente comando de T-SQL en `node-1' para verificar que todos los grupos de disponibilidad están en buen estado y se replican en el grupo de disponibilidad distribuido en el nuevo clúster de SQL Server en Google Cloud
SELECT * FROM sys.dm_hadr_availability_group_states GO