In diesem Dokument werden die häufigsten Gründe für unerwartete Shutdowns und Neustarts von Compute Engine-Instanzen beschrieben und wie Sie diese verhindern.
Das Herunterfahren oder Neustarten von Instanzen kann durch Systemereignisse oder Administratoraktivitäten verursacht werden. Shutdown- und Neustarts von Systemereignissen werden von Google-Systemen oder dem Betriebssystem Ihrer Instanzen generiert. Das Herunterfahren und Neustarten von Administratoraktivitäten werden durch einen vom Nutzer oder Dienstkonto generierten API-Aufruf generiert. Alle Shutdown- und Neustarts werden protokolliert, mit Ausnahme der Neustarts, die innerhalb der Instanz initiiert werden.
Hinweise
-
Richten Sie die Authentifizierung ein, falls Sie dies noch nicht getan haben.
Bei der Authentifizierung wird Ihre Identität für den Zugriff auf Google Cloud -Dienste und APIs überprüft. Zum Ausführen von Code oder Beispielen aus einer lokalen Entwicklungsumgebung können Sie sich so bei Compute Engine authentifizieren:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Installieren Sie die Google Cloud CLI. Initialisieren Sie die Google Cloud CLI nach der Installation mit dem folgenden Befehl:
gcloud initWenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
- Set a default region and zone.
Shutdowns und Neustarts von Instanzen diagnostizieren
Sie können die Logs einer Instanz abfragen, um die Ursache für das Herunterfahren oder Neustarten einer Instanz zu ermitteln. Damit Sie in Zukunft schnell die Ursache für Shutdowns oder Neustarts von VMs finden können, erstellen Sie ein Dashboard, das die Logs enthält. Prüfen Sie nach dem Abfragen der Logs in den Feldern
methodundprincipalEmail, welches Ereignis oder welcher Nutzer bzw. Dienst den Herunterfahren oder Neustart initiiert hat.Cloud-Audit-Logs abfragen
Fragen Sie Cloud-Audit-Logs ab, um eine Liste der Systemereignisse und Administratoraktivitäten anzeigen zu lassen, die zu einem Herunterfahren oder Neustart geführt haben.
Console
Rufen Sie in der Google Cloud Console die Seite Log-Explorer auf:
Geben Sie im Feld Query die folgende Abfrage ein:
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")Ersetzen Sie
VM_NAMEdurch den Namen der VM, die heruntergefahren oder neu gestartet wird.Wenn das gewünschte Ereignis vor mehr als einer Stunde aufgetreten ist, legen Sie einen benutzerdefinierten Zeitraum fest. Klicken Sie dazu auf das Uhrsymbol und geben Sie einen benutzerdefinierten Bereich ein.
Klicken Sie auf Abfrage ausführen. Die Ergebnisse werden im Abschnitt Abfrageergebnisse angezeigt.
Klicken Sie auf den Erweiterungspfeil neben jedem Ergebnis, um detaillierte Informationen aufzurufen.
Unter Cloud-Audit-Logs überprüfen erfahren Sie mehr über die Felder
methodundprincipalEmail, die ein Herunterfahren und Neustarten verursachen, und wie Sie sie verhindern können.
gcloud
Sehen Sie sich Cloud-Audit-Logs mit dem Befehl
gcloud logging readan:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'Dabei gilt:
TIME: die Zeitspanne, die Sie abfragen möchten. Zum Beispiel fragt1hLogeinträge aus der letzten Stunde ab. Weitere Informationen zu Datums- und Uhrzeitformaten finden Sie unter gcloud topic datetimes.VM_NAME: der Name der VM, die heruntergefahren oder neu gestartet wird.
Die Ergebnisanzeige.
Unter Cloud-Audit-Logs überprüfen erfahren Sie mehr über die Felder
methodundprincipalEmail, die ein Herunterfahren und Neustarten verursachen, und wie Sie sie verhindern können.
Cloud-Audit-Logs prüfen
Prüfen Sie die Felder
methodundprincipalEmailder Cloud-Audit-Logs, um festzustellen, warum Ihre VM heruntergefahren oder neu gestartet wurde.Überprüfen Sie die
method-Felder der Cloud-Audit-Logs und vergleichen Sie sie mit den in der folgenden Tabelle aufgeführten Methoden.Methode Shutdown-Typ Beschreibung compute.instances.repair.recreateInstanceSystemereignis Wenn Ihre VM zu einer verwalteten Instanzgruppe gehört, erstellt die MIG die VM neu, wenn sich der Status der VM von
RUNNINGändert und die MIG den Änderungsstatus nicht initiiert hat.Zu den Änderungen des Instanzstatus, die nicht von der MIG initiiert werden, gehören:
- Hardwarefehler.
- Beenden einer Instanz auf Abruf.
- Infrastrukturwartungsereignisse, wenn die VM-Instanz nicht auf Live-Migration eingestellt ist.
- Eine MIG-Instanz mit einer der folgenden Methoden löschen:
- Der API-Methode
instances.delete. - Befehl
gcloud compute instances delete
- Der API-Methode
compute.instances.hostErrorSystemereignis Ein Hostfehler (
compute.instances.hostError) bedeutet, dass auf der physischen Maschine oder der Rechenzentrumsinfrastruktur, die Ihre Compute-Instanz hostet, ein Problem mit der Hardware oder Software aufgetreten ist, das zum Absturz der Instanz führte. Ein Hostfehler, der einen völligen Hardwareausfall oder andere Hardwareprobleme nach sich zieht, kann eine Live-Migration Ihrer Instanz verhindern. Wenn Ihre Instanz so eingestellt ist, dass sie automatisch neu startet (dies ist die Standardeinstellung), startet Compute Engine Ihre Instanz in der Regel innerhalb von drei Minuten ab dem Fehler. Je nach Problem kann der Neustart bis zu 5,5 Minuten dauern.Manchmal reagiert eine Compute-Instanz möglicherweise nicht mehr, bevor ein Hostfehler signalisiert wird. Sie können die Zeit verkürzen, die Compute Engine auf den Neustart oder die Beendigung der Instanz wartet. Legen Sie dazu das Zeitlimit für die Fehlerbehebung des Hosts fest. Weitere Informationen finden Sie unter Verfügbarkeitsrichtlinien festlegen.
Physische Hardware- und Softwarefehler können von Zeit zu Zeit auftreten, sind jedoch eher selten. Um Ihre Anwendungen und Dienste solchen potenziell störenden Systemereignissen zu schützen, sollten Sie folgende Ressourcen prüfen:
- Robuste Systeme konzipieren
- Skalierbare und robuste Anwendungen erstellen
- Verwaltete Instanzgruppen erstellen
Google bietet auch verwaltete Dienste wie App Engine und die flexible App Engine-Umgebung.
compute.instances.automaticRestartSystemereignis Dieses Ereignis tritt nach einem
hostError- oderterminateOnHostMaintenance-Ereignis auf, wenn dieautomaticRestart-Hostwartungsrichtlinie Ihrer VM auftruefestgelegt ist. In den Logs steht vor diesem Log einhostError- oderterminateOnHostMaintenance-Logeintrag.Informationen zum Ändern der Hostwartungsrichtlinie Ihrer VM finden Sie unter Aktualisierungsoptionen für eine Instanz.
compute.instances.guestTerminateSystemereignis Das Betriebssystem Ihrer VM hat die Shutdown-Funktion gestartet. compute.instances.terminateOnHostMaintenanceSystemereignis Wenn Sie die
onHostMaintenance-Wartungsrichtlinie Ihrer VM aufTERMINATEsetzen, beendet Compute Engine die VM, wenn ein Wartungsereignis vorliegt, bei dem Google die VM auf einen anderen Host verschieben muss.Wenn Sie die Richtlinie
onHostMaintenanceIhrer VM ändern möchten, finden Sie weitere Informationen unter Aktualisierungsoptionen für eine Instanz.compute.instances.preemptedSystemereignis Ihre Spot-VM oder die Legacy-VM auf Abruf wurde von Compute Engine vorzeitig beendet:
- Wenn Compute Engine eine Spot-VM vorzeitig beendet, wird die Spot-VM entsprechend ihrer Beendigungsaktion von Compute Engine beendet oder gelöscht. Spot-VMs haben keine maximale Laufzeit.
- Wenn Compute Engine eine VM auf Abruf vorzeitig beendet, wird sie nach einer maximalen Laufzeit von 24 Stunden beendet. Verwenden Sie stattdessen Spot-VMs, um diese Einschränkungen zu vermeiden.
Spot-VMs und VMs auf Abruf sind überschüssige Compute Engine-Kapazitäten. Daher kann Compute Engine sie vorzeitig beenden, wenn die Kapazität an anderer Stelle benötigt wird. Sie können die Auswirkungen des vorzeitigen Beendens mindern, indem Sie die Best Practices befolgen. Wenn Sie hingegen VMs mit nutzergesteuerten Laufzeiten benötigen, erstellen Sie stattdessen Standard-VMs.
compute.instances.stopAdministratoraktivität Die VM wurde von einem Nutzer oder Dienstkonto beendet.
Fahren Sie mit dem nächsten Schritt fort, um den Nutzer oder das Dienstkonto zu identifizieren, das die VM beendet hat. Weitere Informationen zum Neustarten der VM finden Sie unter Angehaltene Instanz neu starten.
compute.instances.deleteAdministratoraktivität oder Systemereignis Die VM wurde von einem Nutzer oder Dienstkonto gelöscht oder die VM wurde so konfiguriert, dass sie automatisch gelöscht wird.
Ein Log für die Methode
compute.instances.deletekann auf eine der folgenden Anfragen für Ihre VM hinweisen:- Anfragen von einem Nutzer oder Dienstkonto zum direkten Löschen Ihrer VM werden nur durch eine
compute.instances.delete-Methode des Nutzers oder Dienstkontos angezeigt. Anfragen, die Ihre VM automatisch löschen, werden durch die Methode
compute.instances.deleteaussystem@google.comangegeben. Die Methode, die den Grund für das automatische Löschen erklärt, wird möglicherweise in Cloud-Audit-Logs angezeigt.Wenn beispielsweise eine Spot-VM so konfiguriert ist, dass sie bei einem vorzeitigen Beenden automatisch gelöscht wird, und sie vorzeitig beendet wird, sehen Sie die Methode
compute.instances.deletevonsystem@google.com, aber möglicherweise auch die Methodecompute.instances.preempted.Anfragen an die VM, die kurz vor oder nach einer
compute.instances.delete-Methode erfolgen, werden möglicherweise in Cloud-Audit-Logs angezeigt.Wenn beispielsweise eine VM aufgrund von Hostwartung kurz vor dem Löschen angehalten wird, sehen Sie eine
compute.instances.delete-Methode, aber möglicherweise auch einecompute.instances.terminateOnHostMaintenance-Methode.
Fahren Sie mit dem nächsten Schritt fort, um den Nutzer oder das Dienstkonto zu identifizieren, das Ihre VM gelöscht hat. Informationen zum Erstellen einer neuen VM finden Sie unter VM erstellen und starten.
compute.instances.insertAdministratoraktivität Die VM wurde von einem Nutzer oder Dienstkonto erstellt.
Fahren Sie mit dem nächsten Schritt fort, um den Nutzer oder das Dienstkonto zu identifizieren, der/das Ihre VM erstellt hat. Informationen zum Erstellen einer neuen VM finden Sie unter VM erstellen und starten.
compute.instances.resetAdministratoraktivität Ein Nutzer oder ein Dienstkonto setzt Ihre VM zurück.
Fahren Sie mit dem nächsten Schritt fort, um den Nutzer oder das Dienstkonto zu identifizieren, das die VM beendet hat.
Überprüfen Sie die
principalEmail-Felder der Cloud-Audit-Logs, um den Nutzer oder Dienst zu identifizieren, der das Herunterfahren oder den Neustart initiiert hat. Die folgende Tabelle enthält gängige von Google verwaltete Dienste, die das Herunterfahren oder Neustarten der Instanzen auslösen.E-Mail Beschreibung system@google.comEin Systemereignis hat das Herunterfahren oder den Neustart verursacht. project-number@cloudservices.gserviceaccount.comEin Dienst-Agent hat das Herunterfahren eingeleitet.
Sehen Sie sich die
project-numberdes Dienst-Agents an, um festzustellen, über welches Projekt der Dienst gestartet wurde.Sehen Sie sich das Feld
protoPayload.requestMetadata.callerSuppliedUserAgentan, um festzustellen, welcher Google-Dienst die Anfrage gesendet hat.Wenn ein Nutzer das Herunterfahren oder einen Neustart ausgelöst hat, wird seine E-Mail-Adresse im Feld
principalEmailangezeigt. Beispiel:cloudysanfrancisco@gmail.com.Administratoren können Nutzer daran hindern, den Status von Projekt-VMs zu ändern, indem sie die Berechtigungen der Identitäts- und Zugriffsverwaltung für Nutzerkonten ändern. Weitere Informationen finden Sie unter Zugriff auf Ressourcen erteilen, ändern und entziehen.
VM-Lifecycle-Events überwachen
Sie können VM-Lifecycle-Ereignisse (einschließlich Herunterfahren, Neustarts und Hostfehler) überwachen, indem Sie ein Cloud Monitoring-Dashboard erstellen.
In diesem Dashboard können Sie Systemereignisse und Administratoraktivitäten visualisieren, die im Abschnitt „Audit-Logs prüfen“ dieses Dokuments genauer beschrieben werden.
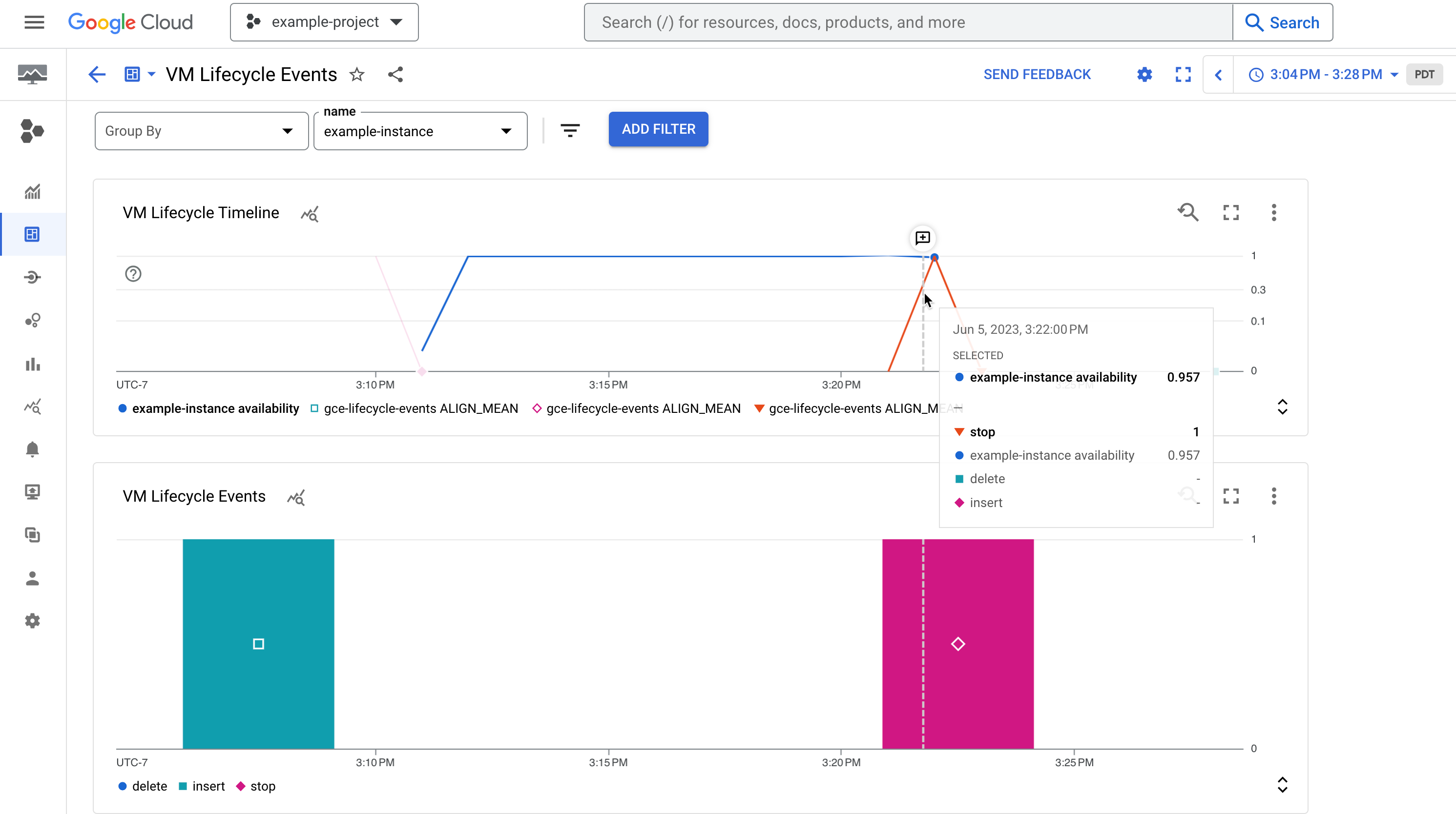 Abbildung 1. Ein Beispieldashboard, das die Verfügbarkeit einer Instanz und ihre Lifecycle-Events zeigt, z. B. eine beendete Instanz.
Abbildung 1. Ein Beispieldashboard, das die Verfügbarkeit einer Instanz und ihre Lifecycle-Events zeigt, z. B. eine beendete Instanz.Logbasierten Messwert erstellen
Erstellen Sie einen benutzerdefinierten logbasierten Messwert, um VM-Lifecycle-Events zu erfassen. Bei diesem Messwert werden Audit-Logs verwendet, um zu erfassen, wie oft ein bestimmtes VM-Lifecycle-Event aufgetreten ist.
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle Logs Writer (
roles/logging.logWriter) für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen des Messwerts benötigen. Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
So erstellen Sie einen benutzerdefinierten logbasierten Messwert:
Rufen Sie in der Google Cloud Console die Seite Logbasierte Messwerte auf.
Klicken Sie auf Messwert erstellen.
Führen Sie im Abschnitt Messwerttyp folgende Schritte aus:
- Wählen Sie
Counteraus. - Behalten Sie für Verteilung die Standardeinstellung bei.
Geben Sie im Abschnitt Details Folgendes ein:
- Name des logbasierten Messwerts:
vm-lifecycle-events. Sie müssen genau diesen Namen verwenden, damit das Dashboard ordnungsgemäß funktioniert. - Beschreibung: Optional – Geben Sie eine Beschreibung für diesen Messwert ein.
- Einheiten:
1
Geben Sie im Bereich Filterauswahl Folgendes an:
- Wählen Sie im Menü Projekt oder Log-Bucket auswählen die Option „Projektlogs“ aus.
- Geben Sie unter Filter erstellen Folgendes ein:
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
Klicken Sie im Bereich Labels auf Label hinzufügen.
Geben Sie Folgendes an:
- Labelname:
method - Labeltyp:
STRING - Feldname:
protoPayload.methodName - Regulärer Ausdruck:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- Labelname:
Klicken Sie auf Fertig.
Klicken Sie auf Messwert erstellen.
Dashboard verwenden
Auf dem Dashboard werden erst dann Daten angezeigt, wenn auf einer Instanz ein Systemereignis oder eine Administratoraktivität auftritt. Wenn Sie testen möchten, ob das Dashboard funktioniert, führen Sie eine Administratoraktivität aus, z. B. einen
stop- und einenstart-Vorgang:- Führen Sie einen
stop- undstart-Vorgang für eine vorhandene Instanz aus oder erstellen Sie eine neue VM zu Testzwecken.
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle Monitoring Dashboard Viewer (
roles/monitoring.dashboardViewer) für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Verwenden des Dashboards benötigen. Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Öffnen Sie in der Google Cloud Console Dashboards.
Öffnen Sie auf dem Tab Dashboard-Liste das Dashboard
GCE VM Lifecycle Events Monitoring.Wählen Sie die VM aus dem Drop-down-Menü Name aus.
Beschränken Sie die Zeitachse auf einen relevanten Zeitraum.
Weitere Möglichkeiten zum Filtern des Dashboards finden Sie unter Temporären Filter hinzufügen.
Das Dashboard enthält zwei Diagramme mit einer Zeitachse für Systemereignisse und Administratoraktivitäten, die in einer Instanz auftreten:
Das Diagramm VM Lifecycle Timeline (Zeitachse für den VM-Lebenszyklus) enthält Folgendes:
- Der Messwert
compute.googleapis.com/instance/uptime, der angibt, ob die VM zu einem bestimmten Zeitpunkt ausgeführt wurde, wobei 1 aktiv und 0 inaktiv ist. Dieser Messwert gibt die Verfügbarkeit aufgrund von Nutzeraktivitäten und Systemereignissen an und ist kein Hinweis auf das Compute Engine-SLA. - Der logbasierte Messwert
vm-lifecycle-events, mit dem die Anzahl der Lifecycle-Aktionen wiestopoderstartgezählt wird, die zu einem bestimmten Zeitpunkt für die Instanz ausgeführt wurden.
- Der Messwert
Im Ereignisdiagramm wird derselbe
vm-lifecycle-events-Messwert auf Logbasis angezeigt, aber in einer vergrößerten Ansicht, damit er besser lesbar ist. Die X-Achsen sind zwar ausgerichtet, die Farben jedoch nicht.
Massive projektübergreifende Shutdowns von VMs untersuchen
Compute Engine kann mehrere VMs herunterfahren, die mit einem freigegebenen VPC-Hostprojekt verbunden sind, wenn die Abrechnung des Hostprojekts der freigegebenen VPC inaktiv oder deaktiviert ist.
Suchen Sie nach Stoppvorgängen, die von
cloud-cluster-manager@prod.google.cominitiiert wurden, um festzustellen, ob Ihre VMs durch eine Anfrage für massive Shutdowns heruntergefahren wurden.Beim Starten einer betroffenen Instanz wird ein Fehler wie dieser zurückgegeben:
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.So beheben Sie das Problem:
Ermitteln Sie die von den VMs verwendete freigegebene VPC mit dem Befehl
gcloud compute instances describe:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
Die Ausgabe sieht etwa so aus:
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
Überprüfen Sie im Hostprojekt der freigegebenen VPC, ob die Abrechnung deaktiviert wurde.
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"Falls erforderlich aktivieren Sie die Abrechnung für das Hostprojekt.
Informationen dazu, wie Sie verhindern können, dass dieses Problem erneut auftritt, finden Sie unter Verknüpfung zwischen einem Projekt und seinem Rechnungskonto sichern.
Sofern nicht anders angegeben, sind die Inhalte dieser Seite unter der Creative Commons Attribution 4.0 License und Codebeispiele unter der Apache 2.0 License lizenziert. Weitere Informationen finden Sie in den Websiterichtlinien von Google Developers. Java ist eine eingetragene Marke von Oracle und/oder seinen Partnern.
Zuletzt aktualisiert: 2025-10-18 (UTC).
-