このドキュメントでは、Compute Engine インスタンスの予期しないシャットダウンおよび再起動について一般的な原因と防止方法を説明します。
インスタンスのシャットダウンおよび再起動は、システム イベントまたは管理アクティビティによって発生する可能性があります。システム イベントによるシャットダウンおよび再起動は、Google システムまたはインスタンスのオペレーティング システムによって引き起こされます。管理アクティビティによるシャットダウンおよび再起動は、ユーザーまたはサービス アカウントが生成した API 呼び出しによって引き起こされます。インスタンス内部で開始された再起動を除き、すべてのシャットダウンおよび再起動は、ログに記録されます。
始める前に
-
まだ設定していない場合は、認証を設定します。認証とは、 Google Cloud サービスと API にアクセスするために ID を確認するプロセスです。ローカル開発環境からコードまたはサンプルを実行するには、次のいずれかのオプションを選択して Compute Engine に対する認証を行います。
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
After installing the Google Cloud CLI, initialize it by running the following command:
gcloud initIf you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
- Set a default region and zone.
Google Cloud コンソールで、[ログ エクスプローラ] ページに移動します。
[クエリ] フィールドに次のクエリを入力します。
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")VM_NAMEは、シャットダウンや再起動が発生した VM の名前に置き換えます。探しているイベントが 1 時間以上前に発生している場合は、時計のアイコンをクリックしてカスタム期間を入力し、カスタムの期間を設定します。
[クエリを実行] をクリックします。結果は、[クエリ結果] セクションに表示されます。
各結果の横にある 展開矢印をクリックすると、詳細情報が表示されます。
シャットダウンと再起動に関連する
methodとprincipalEmailフィールドの詳細と、それらを防ぐ方法については、Cloud Audit Logs の確認をご覧ください。Cloud Audit Logs を表示するには、
gcloud logging readコマンドを使用します。gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'次のように置き換えます。
TIME: クエリを実行する時間の長さ。たとえば、1hは、過去 1 時間のログエントリをクエリします。日付と時刻の形式については、gcloud topic datetimes をご覧ください。VM_NAME: シャットダウンまたは再起動した VM の名前。
結果が表示されます。
シャットダウンと再起動に関連する
methodとprincipalEmailフィールドの詳細と、それらを防ぐ方法については、Cloud Audit Logs の確認をご覧ください。Cloud Audit Logs の
methodフィールドを確認し、次の表に示すメソッドと照合します。方法 シャットダウン タイプ 説明 compute.instances.repair.recreateInstanceシステム イベント VM がマネージド インスタンス グループ(MIG)に属している場合、VM の状態が
RUNNINGから変化したが、MIG がその状態の変更を開始していない場合、MIG は VM を再作成します。MIG によって開始されないインスタンスの状態の変更は次のとおりです。
- ハードウェアの障害。
- プリエンプティブル インスタンスの終了。
- VM インスタンスがライブ マイグレーションに設定されていない場合のインフラストラクチャ メンテナンス イベント。
- 次のいずれかの方法による MIG インスタンスの削除。
instances.deleteAPI メソッドgcloud compute instances deleteコマンド
compute.instances.hostErrorシステム イベント ホストエラー(
compute.instances.hostError)は、コンピューティング インスタンスをホストしている物理マシンまたはデータセンター インフラストラクチャで、インスタンスがクラッシュするようなハードウェアまたはソフトウェアの問題が発生したことを意味します。ハードウェア全体の障害やその他のハードウェアの問題でホストエラーが発生すると、インスタンスのライブ マイグレーションが停止することがあります。インスタンスが自動的に再起動するように設定されている場合(デフォルト設定)、Compute Engine は通常、エラーが検出されてから 3 分以内にインスタンスを再起動します。問題によっては、再起動に最大 5.5 分かかります。ホストエラーが通知される前に、コンピューティング インスタンスが応答しなくなる場合があります。ホストエラー回復タイムアウトを設定することで、Compute Engine がインスタンスの再起動または終了を待機する時間を短縮できます。詳細については、可用性ポリシーを設定するをご覧ください。
物理的なハードウェアとソフトウェアの障害は、発生する可能性はありますが、まれな現象です。起こりうる破壊的なシステム イベントからアプリケーションやサービスを保護するため、次の方策を確認してください。
Google は、App Engine や App Engine フレキシブル環境などのマネージド サービスも提供しています。
compute.instances.automaticRestartシステム イベント このイベントは、VM の
automaticRestartホスト メンテナンス ポリシーがtrueに設定されている場合でも、hostErrorイベントまたはterminateOnHostMaintenanceイベントの後に発生します。ログでは、このログの前にhostErrorまたはterminateOnHostMaintenanceログエントリがあります。VM のホスト メンテナンス ポリシーを変更する場合は、インスタンスのオプションの更新をご覧ください。
compute.instances.guestTerminateシステム イベント VM のオペレーティング システムがシャットダウンを開始しました。 compute.instances.terminateOnHostMaintenanceシステム イベント VM の
onHostMaintenanceホスト メンテナンス ポリシーをTERMINATEに設定している場合、Google が VM を別のホストに移動する必要があるメンテナンス イベントが発生すると、VM は Compute Engine により停止されます。VM の
onHostMaintenanceポリシーを変更する場合は、インスタンスのオプションの更新をご覧ください。compute.instances.preemptedシステム イベント Compute Engine が、Spot VM または以前のプリエンプティブル VM をプリエンプトしました。
- Compute Engine は、Spot VM をプリエンプトすると、その終了アクションに基づいて Spot VM を停止または削除します。Spot VM には最大実行時間はありません。
- Compute Engine は、プリエンプティブル VM をプリエンプトすると、その VM を最大実行時間(24 時間)後に停止します。こうした制限を回避するには、代わりに Spot VM を使用します。
Spot VM とプリエンプティブル VM は Compute Engine の余剰のキャパシティを利用する機能であるため、それ以外の場所で容量が必要になると、Compute Engine によってプリエンプトされる可能性があります。ベスト プラクティスに従うことで、プリエンプションの影響を軽減できます。ユーザー制御のランタイムを持つ VM が必要な場合は、代わりに標準 VM を作成します。
compute.instances.stop管理アクティビティ ユーザーまたはサービス アカウントによって VM が停止されました。
次の手順に進んで、VM を停止したユーザーまたはサービス アカウントを特定します。VM の再起動については、停止したインスタンスの再起動をご覧ください。
compute.instances.delete管理アクティビティまたはシステム イベント ユーザーまたはサービス アカウントによって VM が削除されたか、VM が自動的に削除されるように構成されています。
具体的には、
compute.instances.deleteメソッドのログには、VM に対する次のいずれかのリクエストが示される場合があります。- VM を直接削除するためのユーザーまたはサービス アカウントからのリクエストは、ユーザーまたはサービス アカウントの
compute.instances.deleteメソッドによってのみ示されます。 VM を自動的に削除するリクエストは、
system@google.comからcompute.instances.deleteメソッドで示されますが、自動削除の原因を説明するメソッドは Cloud Audit Logs に表示される場合も、表示されない場合もあります。たとえば、プリエンプション中に自動的に削除されるように構成された Spot VM がプリエンプトされた場合、
system@google.comからcompute.instances.deleteメソッドが表示されますが、compute.instances.preemptedメソッドが表示される場合と表示されない場合があります。compute.instances.deleteメソッドの直前または直後に発生した VM へのリクエストは、Cloud Audit Logs に表示される場合も、表示されない場合もあります。たとえば、VM が削除される直前にホスト メンテナンスのために VM が停止した場合、
compute.instances.deleteメソッドは表示されますが、compute.instances.terminateOnHostMaintenanceメソッドは表示されない場合があります。
次のステップに進んで、VM を削除したユーザーまたはサービス アカウントを特定します。新しい VM の作成方法については、VM の作成と起動をご覧ください。
compute.instances.insert管理アクティビティ ユーザーまたはサービス アカウントによって VM が作成されました。
次のステップに進んで、VM を作成したユーザーまたはサービス アカウントを特定します。新しい VM の作成方法については、VM の作成と起動をご覧ください。
compute.instances.reset管理アクティビティ ユーザーまたはサービス アカウントによって VM がリセットされました。
次の手順に進んで、VM を停止したユーザーまたはサービス アカウントを特定します。
Cloud Audit Logs の
principalEmailフィールドを確認して、シャットダウンや再起動を開始したユーザーまたはサービスを特定します。次の表に、シャットダウンや再起動を開始する共通の Google マネージド サービスを示します。Email 説明 system@google.comシステム イベントによってシャットダウンまたは再起動が発生しました。 project-number@cloudservices.gserviceaccount.comサービス エージェントによってシャットダウンが開始されました。
サービスによってシャットダウンが開始されたプロジェクトを特定するには、サービス アカウントの
project-numberを確認します。リクエストを生成した Google サービスを特定するには、
protoPayload.requestMetadata.callerSuppliedUserAgentフィールドを確認します。ユーザーがシャットダウンや再起動を開始した場合は、そのメールアドレスが
principalEmailフィールドに表示されます。例:cloudysanfrancisco@gmail.com管理者は、ユーザー アカウントの Identity and Access Management 権限を変更することで、ユーザーがプロジェクト VM の状態を変更できないように設定できます。詳細については、リソースへのアクセス権の付与、変更、取り消しをご覧ください。
Google Cloud コンソールで、[ログベースの指標] ページに移動します。
[指標を作成] をクリックします。
- [
Counter] を選択します。 - [Distribution] は選択解除されたデフォルト設定のままにします。
- ログベースの指標の名前:
vm-lifecycle-events。ダッシュボードを正しく機能させるには、この正確な名前を使用する必要があります。 - 説明: 省略可 - この指標の説明を入力します。
- 単位:
1 [フィルタの選択] セクションで、以下の内容を指定します。
- [プロジェクトまたはログバケットを選択] メニューから [プロジェクトのログ] を選択します。
- [ビルドフィルタ] に、次のように入力します。
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
[ラベル] セクションで [ラベルを追加] をクリックします。
以下を指定します。
- ラベル名:
method - ラベルのデータ型:
STRING - フィールド名:
protoPayload.methodName - 正規表現:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- ラベル名:
[完了] をクリックします
[指標を作成] をクリックします。
- 既存のインスタンスで
stopとstartのオペレーションを実行するか、テスト用に新しい VM を作成します。 Google Cloud コンソールで [ダッシュボード] を開きます。
[ダッシュボード リスト] タブで
GCE VM Lifecycle Events Monitoringダッシュボードを開きます。[名前] プルダウン メニューから VM を選択します。
時系列を該当する期間に絞り込みます。
ダッシュボードをフィルタする別の方法については、一時的なフィルタを追加するをご覧ください。
[VM ライフサイクル タイムライン] グラフには、次の情報が表示されます。
- 特定の時点で VM が実行中であったかどうかを示す
compute.googleapis.com/instance/uptime指標(1 は稼働中、0 は停止中)。この指標は、ユーザー アクティビティとシステム イベントの結果としての可用性を反映するものであり、Compute Engine SLA を示すものではありません。 vm-lifecycle-eventsログベースの指標。特定の時点でインスタンスに対して実行されたライフサイクル アクション(stop、startなど)の数をカウントします。
- 特定の時点で VM が実行中であったかどうかを示す
イベントグラフには、同じログベースの指標
vm-lifecycle-eventsが表示されますが、読みやすくなるように拡大表示されます。X 軸は配置が調整されますが、2 つのグラフ間で色は同期されません。gcloud compute instances describeコマンドを使用して、VM が使用する共有 VPC を特定します。gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
出力は次のようになります。
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
課金が無効になっているかどうかを、共有 VPC のホスト プロジェクトで確認します。
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"必要に応じて、ホスト プロジェクトで課金を有効にします。
インスタンスのシャットダウンと再起動の診断
インスタンスのシャットダウンおよび再起動の原因を診断するには、インスタンスのログに対してクエリを実行する必要があります。今後の VM のシャットダウンや再起動の原因をすばやく特定するには、ログを含むダッシュボードを構築します。ログをクエリした後、
methodフィールドとprincipalEmailフィールドを確認して、シャットダウンや再起動を引き起こしたイベントと、ユーザーやサービスを特定します。Cloud Audit Logs のクエリ
Cloud Audit Logs に対してクエリを実行して、シャットダウンまたは再起動の原因となったシステム イベントと管理アクティビティのリストを表示します。
コンソール
gcloud
Cloud Audit Logs の確認
VM がシャットダウンまたは再起動した原因を特定するには、Cloud Audit Logs の
methodフィールドとprincipalEmailフィールドを確認します。VM ライフサイクル イベントのモニタリング
Cloud Monitoring ダッシュボードを構築することで、VM のライフサイクル イベント(シャットダウン、再起動、ホストエラーなど)をモニタリングできます。
このダッシュボードでは、システム イベントと管理アクティビティを可視化できます。詳細については、このドキュメントの監査ログの確認のセクションをご覧ください。
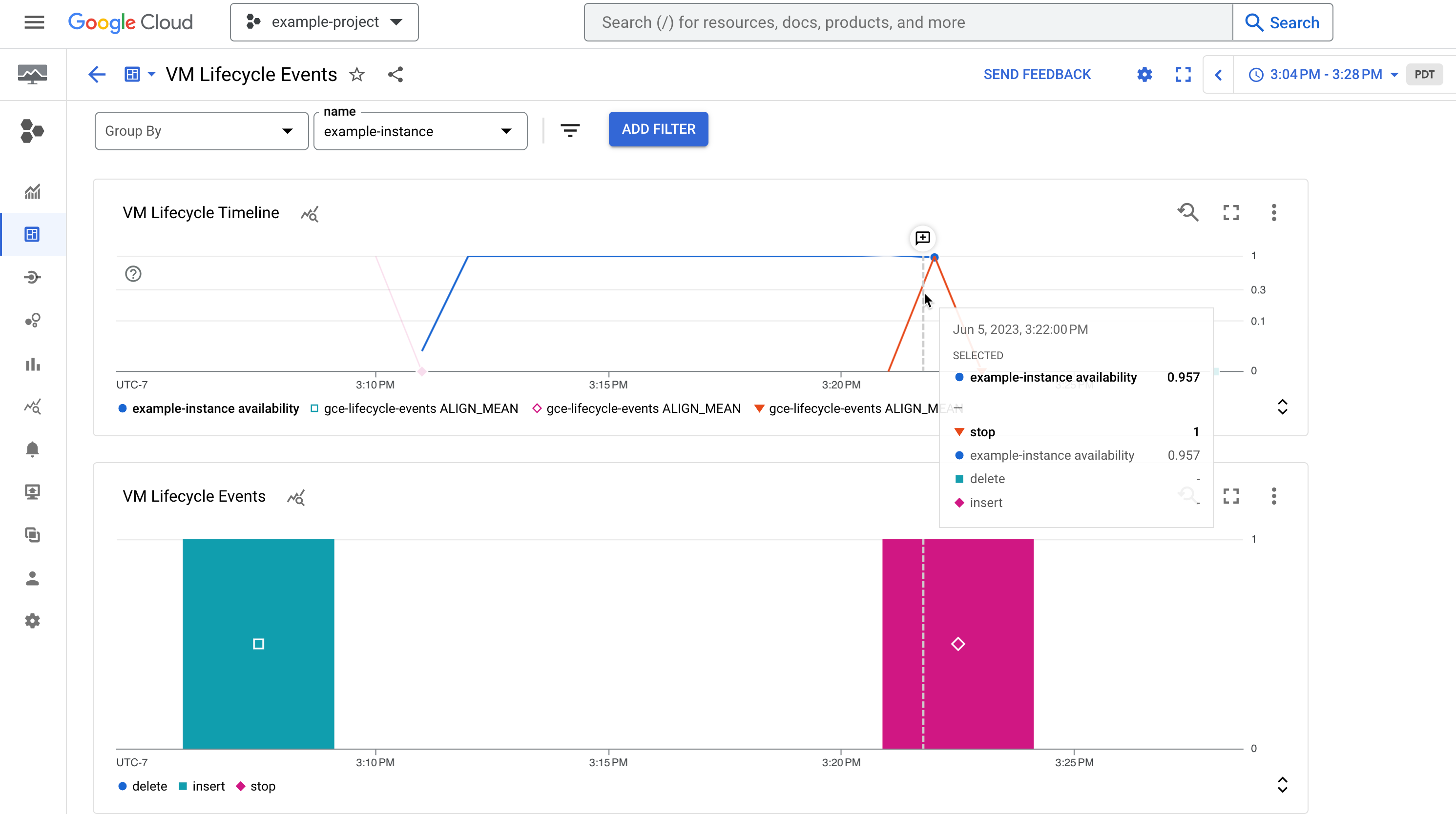 図 1. インスタンスの可用性と、そのライフサイクル イベント(停止したインスタンスなど)を示すダッシュボードの例。
図 1. インスタンスの可用性と、そのライフサイクル イベント(停止したインスタンスなど)を示すダッシュボードの例。ログベースの指標の作成
VM のライフサイクル イベントをキャプチャするには、ユーザー定義のログベースの指標を作成します。この指標は、監査ログを使用して特定の VM ライフサイクル イベントが発生した回数を保持します。
指標の作成に必要な権限を取得するには、プロジェクトに対するログ書き込み(
roles/logging.logWriter)IAM ロールを付与するよう管理者に依頼してください。ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
次の手順で、ユーザー定義のログベースの指標を作成します。
[指標タイプ] セクションで、次の操作を行います。
[詳細] に次のように入力します。
ダッシュボードを使用する
インスタンスにシステム イベントまたは管理アクティビティが発生するまで、ダッシュボードにデータは表示されません。ダッシュボードが機能するかどうかをテストするには、
stopオペレーションやstartオペレーションなどの管理アクティビティを実行します。ダッシュボードを使用するために必要な権限を取得するには、プロジェクトに対するモニタリング ダッシュボード閲覧者(
roles/monitoring.dashboardViewer)IAM ロールを付与するよう管理者に依頼してください。ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
ダッシュボードには、インスタンスで発生するシステム イベントと管理アクティビティのタイムラインを表示する 2 つのグラフが含まれています。
複数のプロジェクトにまたがる大規模な VM シャットダウンの調査
共有 VPC ホスト プロジェクトの課金が無効になっている場合、Compute Engine は共有 VPC ホスト プロジェクトに接続されている複数の VM をシャットダウンすることがあります。
大量シャットダウン リクエストによって VM がシャットダウンされたかどうかを判断するには、
cloud-cluster-manager@prod.google.comによって開始された停止オペレーションを探します。影響を受けるインスタンスを起動すると、次のようなエラーが返されます。
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.この問題を解決するには、次の操作を行います。
この問題の再発を回避するには、プロジェクトと請求先アカウント間のリンクを保護するをご覧ください。
特に記載のない限り、このページのコンテンツはクリエイティブ・コモンズの表示 4.0 ライセンスにより使用許諾されます。コードサンプルは Apache 2.0 ライセンスにより使用許諾されます。詳しくは、Google Developers サイトのポリシーをご覧ください。Java は Oracle および関連会社の登録商標です。
最終更新日 2025-07-21 UTC。
-