本教學課程說明如何跨兩個 Google Cloud 區域啟用 Hyperdisk Balanced 非同步複製功能,做為災難復原 (DR) 解決方案,以及如何在發生災難時啟動 DR 執行個體。
Microsoft SQL Server 容錯移轉叢集執行個體 (FCI) 是部署於多個 Windows Server 容錯移轉叢集 (WSFC) 節點的單一高可用性 SQL Server 執行個體。在任何時間點,叢集節點都會主動代管 SQL 執行個體。如果發生區域性服務中斷或 VM 問題,WSFC 會自動將執行個體資源的擁有權轉移至叢集中的另一個節點,讓用戶端重新連線。SQL Server FCI 需要將資料放在共用磁碟上,才能在所有 WSFC 節點中存取。
為確保 SQL Server 部署作業能承受區域性服務中斷,請啟用非同步複製功能,將主要區域的磁碟資料複製到次要區域。本教學課程會使用 Hyperdisk Balanced 高可用性多寫入端磁碟,在兩個 Google Cloud 區域之間啟用非同步複製,做為 SQL Server FCI 的災難復原 (DR) 解決方案,並說明如何在發生災難時啟動 DR 執行個體。本文中的「災難」是指主要資料庫叢集發生故障或無法使用,因為叢集所在的區域無法使用 (可能是因為發生天災)。
本教學課程適用於資料庫架構師、管理員和工程師。
災難復原 Google Cloud
災難復原 Google Cloud 是指在區域發生故障或無法存取時,維持資料的持續存取權。災難復原 (DR) 網站有多種部署選項,具體取決於復原點目標 (RPO) 和復原時間目標 (RTO) 的需求。本教學課程涵蓋其中一個選項,也就是將連結至虛擬機器的磁碟從主要區域複製到 DR 區域。
使用 Hyperdisk 非同步複製功能進行災難復原
Hyperdisk 非同步複製是一種儲存空間選項,可提供非同步儲存空間副本,用於在兩個區域之間複製磁碟。如果發生區域性服務中斷 (這種情況相當少見),您可以透過 Hyperdisk Asynchronous Replication 將資料容錯移轉至次要區域,並在該區域重新啟動工作負載。
Hyperdisk 非同步複製功能會將資料從附加至執行中工作負載的磁碟 (稱為主要磁碟),複製到位於其他區域的獨立磁碟。接收複製資料的磁碟稱為次要磁碟。主要磁碟執行的區域稱為主要區域,次要磁碟執行的區域則稱為次要區域。為確保附加至每個 SQL Server 節點的所有磁碟副本都包含相同時間點的資料,這些磁碟會新增至一致性群組。一致性群組可讓您跨多個磁碟執行 DR 和 DR 測試。
災難復原架構
下圖顯示 Hyperdisk 非同步複製的最低架構,支援主要區域 R1 中的資料庫 HA,以及從主要區域到次要區域 R2 的磁碟複製。
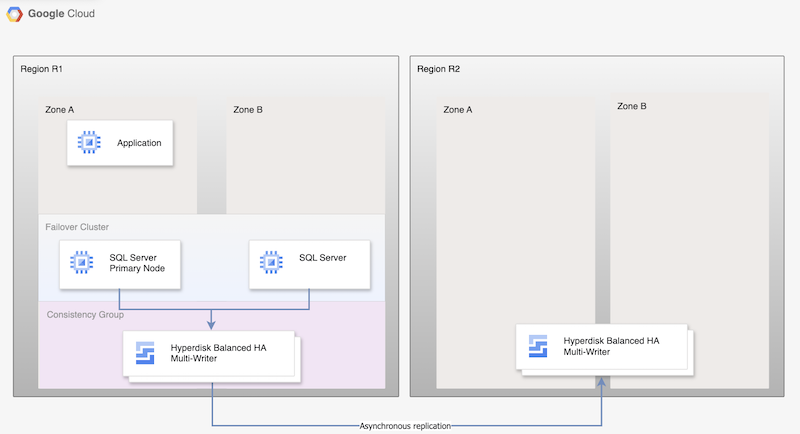
圖 1. 使用 Microsoft SQL Server 和 Hyperdisk 非同步複製功能建構災難復原架構
架構的運作方式如下:
- 兩個 Microsoft SQL Server 執行個體 (主要執行個體和待命執行個體) 屬於 FCI 叢集,且位於主要區域 (R1),但位於不同區域 (區域 A 和區域 B)。兩個執行個體共用一個 Hyperdisk Balanced High Availability 磁碟,因此兩部 VM 都能存取資料。如需操作說明,請參閱「設定 SQL Server FCI 叢集,並使用 Hyperdisk Balanced 高可用性多寫入端模式」
- SQL 節點的磁碟會新增至一致性群組,並複製到 DR 區域 R2。Compute Engine 會以非同步方式將資料從 R1 複製到 R2。
- 非同步複製只會將磁碟上的資料複製到 R2,不會複製 VM 中繼資料。在 DR 期間,系統會建立新的 VM,並將現有的複製磁碟連接至 VM,以便讓節點上線。
災難復原程序
災難復原程序會規定區域無法使用後,您必須採取哪些作業步驟,才能在其他區域恢復工作負載。
基本的資料庫災難復原程序包含下列步驟:
- 執行主要資料庫執行個體的第一個區域 (R1) 無法使用。
- 營運團隊會確認並正式承認發生災害,並決定是否需要容錯移轉。
- 如需容錯移轉,您必須終止主要和次要磁碟之間的複製作業。系統會從磁碟副本建立新的 VM,並將其上線。
- R2 災難復原區域的資料庫會經過驗證並上線。R2 中的資料庫會成為新的主要資料庫,可啟用連線。
- 使用者會在新的主要資料庫上繼續處理作業,並存取 R2 中的主要執行個體。
雖然這個基本程序會重新建立可運作的主要資料庫,但不會建立完整的 HA 架構,因為新的主要資料庫不會進行複製。
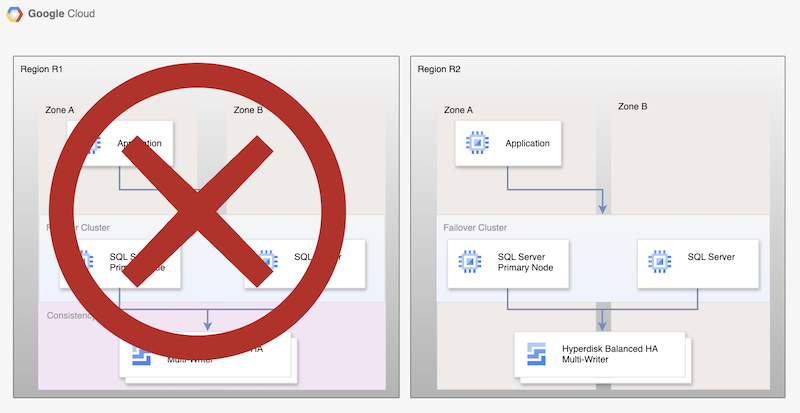
圖 2:使用永久磁碟非同步複製功能進行災難復原後,部署 SQL Server
改用復原的區域
主要區域 (R1) 恢復連線後,您就可以規劃及執行容錯回復程序。容錯回復程序包含本教學課程中列出的所有步驟,但在此情況下,R2 是來源,R1 是復原區域。
選擇 SQL Server 版本
本教學課程支援下列 Microsoft SQL Server 版本:
- SQL Server 2016 Enterprise 和 Standard 版
- SQL Server 2017 Enterprise 和 Standard 版
- SQL Server 2019 Enterprise 和 Standard 版
- SQL Server 2022 Enterprise 和 Standard 版
本教學課程使用 SQL Server 容錯移轉叢集執行個體,搭配 Hyperdisk Balanced High Availability 磁碟。
如果您不需要 SQL Server Enterprise 功能,可以使用 SQL Server Standard 版:
SQL Server 2016、2017、2019 和 2022 版的映像檔已安裝 Microsoft SQL Server Management Studio,因此您不需要另外安裝。不過,在實際執行環境中,建議您在每個區域的獨立 VM 上安裝一個 Microsoft SQL Server Management Studio 執行個體。如果您設定高可用性環境,請為每個區域安裝一次 Microsoft SQL Server Management Studio,確保在其他區域無法使用時,該環境仍可運作。
設定 Microsoft SQL Server 的災難復原
本教學課程使用 Microsoft SQL Server Enterprise 的 sql-ent-2022-win-2022 映像檔。
如需完整清單,請參閱「OS 映像檔」。
設定雙例項高可用性叢集
如要在兩個區域之間設定 SQL Server 的磁碟複製功能,請先在一個區域中建立兩個執行個體的高可用性叢集。一個執行個體做為主要執行個體,另一個執行個體則做為待命執行個體。如要完成這個步驟,請按照「使用 Hyperdisk Balanced 高可用性多寫入端模式設定 SQL Server FCI 叢集」中的操作說明進行。
本教學課程使用 us-central1 做為主要區域 R1。如果您已按照「使用 Hyperdisk Balanced 高可用性多重寫入器模式設定 SQL Server FCI 叢集」一文中的步驟操作,您會在同一個區域 (us-central1) 中建立兩個 SQL Server 執行個體。您會在 us-central1-a 中部署主要 SQL Server 執行個體 (node-1),並在 us-central1-b 中部署待命執行個體 (node-2)。
啟用磁碟非同步複製功能
建立及設定所有 VM 後,請完成下列步驟,啟用兩個區域之間的磁碟複製功能:
為 SQL Server 節點和託管見證與網域控制站角色的節點建立一致性群組。一致性群組的限制之一是無法跨區域,因此您必須將每個節點加入個別的一致性群組。
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
將主要和待命 VM 的磁碟新增至對應的一致性群組。
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
在次要區域中建立空白次要磁碟。
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
開始複製磁碟。資料會從主要磁碟複製到 DR 區域中新建立的空白磁碟。
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
此時,資料應該會在區域之間複製。
每個磁碟的複製狀態應為「Active」。
模擬災難復原
在本節中,您將測試本教學課程中設定的災難復原架構。
模擬服務中斷情形,並執行災難復原容錯移轉
在容錯移轉期間,您會在 DR 區域中建立新的 VM,並將複製的磁碟連接至這些 VM。為簡化容錯移轉程序,您可以在 DR 區域使用不同的虛擬私有雲 (VPC) 進行復原,這樣就能使用相同的 IP 位址。
開始容錯移轉前,請確認 node-1 是您建立的 AlwaysOn 可用性群組的主要節點。啟動網域控制站和主要 SQL Server 節點,以免發生資料同步問題,因為這兩個節點受到兩個不同的一致性群組保護。如要模擬中斷,請按照下列步驟操作:
建立復原 VPC。
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
終止或停止資料複製作業。
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
停止主要區域中的來源 VM。
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
重新命名現有 VM,避免專案中出現重複名稱。
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
使用次要磁碟在 DR 區域中建立 VM。這些 VM 會使用來源 VM 的 IP 位址。
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
您已模擬服務中斷,並容錯移轉至 DR 區域。現在可以測試次要執行個體是否正常運作。
確認 SQL Server 連線
建立 VM 後,請確認資料庫已成功復原,且伺服器運作正常。如要測試資料庫,請從復原的資料庫執行查詢。
- 使用遠端桌面連線至 SQL Server VM。
- 開啟 SQL Server Management Studio。
- 在「連線到伺服器」對話方塊中,確認伺服器名稱已設為
node-1,然後選取「連線」。 在檔案選單中,依序選取「檔案」>「新增」>「查詢」,並使用目前的連線。
USE [bookshelf]; SELECT * FROM Books;