本教程介绍如何在两个 Google Cloud 区域之间启用永久性磁盘异步复制作为灾难恢复 (DR) 解决方案,以及如何在发生灾难时启动灾难恢复实例。
在本文档中,灾难是主数据库高可用性 (HA) 集群发生故障或不可用的事件。 当主数据库所在的区域发生故障或无法访问时,主数据库可能会发生故障。
本教程面向数据库架构师、管理员和工程师。
目标
- 为在 Google Cloud上运行的所有 SQL Server AlwaysOn 可用性群组集群节点启用永久性磁盘异步复制。
- 模拟灾难事件并执行完整的灾难恢复过程,以验证灾难恢复配置。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用量来估算费用,请使用价格计算器。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
在本教程中,您需要一个 Google Cloud 项目。您可创建一个新项目,也可选择已创建的项目:
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Google Cloud中的灾难恢复
在 Google Cloud中,灾难恢复旨在提供进程的连续性,尤其是当某个区域出现故障或无法访问时。灾难恢复站点有多个部署选项,它们将由恢复点目标 (RPO) 和恢复时间目标 (RTO) 要求决定。本教程介绍了将虚拟机 (VM) 磁盘从主区域复制到灾难恢复区域的选项之一。
永久性磁盘异步复制的灾难恢复
永久性磁盘异步复制可为跨区域主动-被动灾难恢复提供低 RPO 和 RTO 块存储复制。
永久性磁盘异步复制是一个存储选项,可在两个区域之间异步复制数据。万一发生罕见的区域性服务中断故障,永久性磁盘异步复制使您能够将数据故障切换到次要区域,并在该区域重启工作负载。
永久性磁盘异步复制功能会将数据从挂接到正在运行的工作负载的磁盘(称为主磁盘)复制到位于另一个区域的单独磁盘。接收复制数据的磁盘称为辅助磁盘。
为确保连接到每个 SQL Server 节点的所有磁盘的副本都包含同一时间点的数据,这些磁盘都会添加到一致性组。一致性组使您能够跨多个磁盘执行灾难恢复和灾难恢复测试。
灾难恢复架构
对于永久性磁盘异步复制,下图展示了最小架构,该架构支持主区域中的数据库高可用性以及从主要区域到灾难恢复区域的磁盘复制。
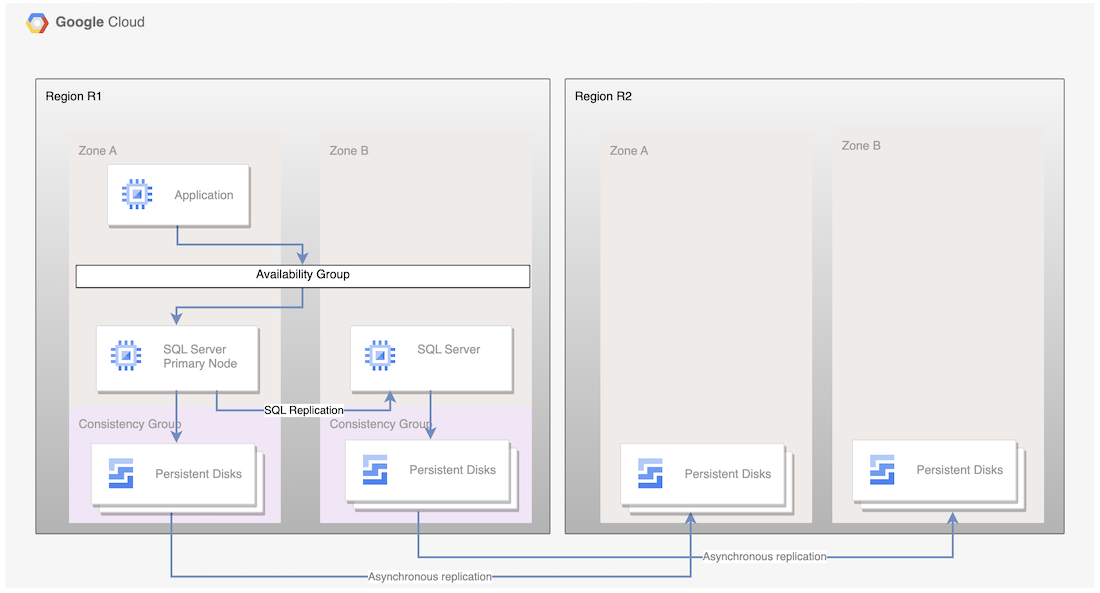
图 1. 使用 Microsoft SQL Server 和永久性磁盘异步复制功能的灾难恢复架构
该架构的工作原理如下:
- Microsoft SQL Server 的两个实例(主实例和备用实例)属于一个可用性组,位于同一区域 (R1),但在不同的可用区(可用区 A 和 B)中。R1 中的两个实例使用同步提交模式来协调各自的状态。使用同步模式是因为它支持高可用性并维持一致的数据状态。
- 这两个 SQL 节点中的磁盘都会添加到一致性组并复制到灾难恢复区域 R2。底层基础架构会以异步方式复制数据。
- 只有磁盘会复制到 R2 区域。在灾难恢复期间,系统会创建新虚拟机,并将现有的复制磁盘挂接到虚拟机,以使节点上线。
灾难恢复过程
灾难恢复过程会在某个区域不可用时启动。灾难恢复过程会设置必须手动或自动执行的操作步骤,从而减少地区故障并在可用地区中建立正在运行的主实例。
基本的数据库灾难恢复过程包含以下步骤:
- 运行主数据库实例的第一个地区 (R1) 不可用。
- 运营团队识别并正式确认灾难,并确定是否需要故障切换。
- 如果需要故障切换,则从主实例到灾难恢复区域的磁盘复制操作会终止。系统会根据磁盘副本创建新的虚拟机并使其上线。
- 灾难恢复区域 (R2) 中新的主数据库已通过验证,并处于在线状态,以便启用连接。
- 用户继续处理新的主数据库,并访问 R2 中的主实例。
虽然这个基本过程会重新创建可正常工作的主数据库,但不创建完整的高可用性架构;而在完整架构中,新的主数据库具有备用节点。

图 2. 使用永久性磁盘异步复制实现灾难恢复后的 SQL Server 部署
回退到已恢复的地区
主要区域 (R1) 恢复在线状态后,您可以计划并执行故障恢复过程。故障恢复过程包括本教程中列出的所有步骤,但在本例中,R2 是源区域,R1 是恢复区域。
选择 SQL Server 版本
本教程支持以下版本的 Microsoft SQL Server:
- SQL Server 2016 Enterprise 版本
- SQL Server 2017 Enterprise 版本
- SQL Server 2019 Enterprise 版本
- SQL Server 2022 Enterprise Edition
本教程使用 SQL Server 中的 AlwaysOn 可用性组功能。
如果您不需要高可用性 Microsoft SQL Server 主数据库,并且使用一个数据库实例作为主数据库实例就已足够,那么可使用以下版本的 SQL Server:
- SQL Server 2016 Standard 版本
- SQL Server 2017 Standard 版本
- SQL Server 2019 Standard 版本
- SQL Server 2022 Standard Edition
SQL Server 的 2016、2017 和 2019 和 2022 版本已在映像中安装 Microsoft SQL Server Management Studio;您不需要单独安装。但在生产环境中,我们建议在每个地区中,您都在一个单独的虚拟机上安装一个 Microsoft SQL Server Management Studio 实例。如果要设置高可用性环境,则应为每个区域安装一次 Microsoft SQL Server Management Studio,确保在另一个区域不可用时它仍然可用。
为 Microsoft SQL Server 设置灾难恢复
本教程使用 Microsoft SQL Server Enterprise 的
sql-ent-2022-win-2022映像。如需查看完整的映像列表,请参阅操作系统映像。
设置具有两个实例的高可用性集群
如需为 SQL Server 设置向灾难恢复区域复制磁盘,请先在一个区域创建一个具有两个实例的高可用性集群。其中一个实例充当主实例,另一个实例充当备用实例。为完成此步骤,请按照配置 SQL Server AlwaysOn 可用性组中的说明进行操作。本教程使用
us-central1作为主区域(称为 R1R1)。如果您按照配置 SQL Server AlwaysOn 可用性组中的步骤进行操作,则将在同一区域 (us-central1) 中创建两个 SQL Server 实例。您将在us-central1-a中部署一个 SQL Server 主实例 (node-1),在us-central1-b中部署一个备用实例 (node-2)。启用磁盘异步复制
创建并配置所有虚拟机后,通过为挂接到虚拟机的所有磁盘创建一致性组,即可启用区域间磁盘复制。系统会将数据从源磁盘复制到指定区域中新创建的空白磁盘。
为 SQL 节点和网域控制器创建一个一致性组。可用区级磁盘的限制之一是一致性组不能跨可用区。
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION
将主虚拟机和备用虚拟机中的磁盘添加到相应的一致性组。
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-1-datadisk \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies node-2-datadisk \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
在配对区域创建空白辅助磁盘
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-1-datadisk-replica \ --zone=$DR_REGION-a \ --size=$PD_SIZE \ --primary-disk=node-1-datadisk \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create node-2-datadisk-replica \ --zone=$DR_REGION-b \ --size=$PD_SIZE \ --primary-disk=node-2-datadisk \ --primary-disk-zone=$REGION-b gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
开始磁盘复制。系统会将数据从主磁盘复制到灾难恢复区域中新创建的空白磁盘。
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-1-datadisk \ --zone=$REGION-a \ --secondary-disk=node-1-datadisk-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication node-2-datadisk \ --zone=$REGION-b \ --secondary-disk=node-2-datadisk-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
此时,应在区域之间复制数据。每个磁盘的复制状态应为
Active。模拟灾难恢复
在本部分中,您将测试本教程中设置的灾难恢复架构。
模拟中断并执行灾难恢复故障切换
在灾难恢复故障切换期间,您需要在灾难恢复区域中创建新的虚拟机,并将复制的磁盘挂接到这些虚拟机。为了简化故障切换,您可以在灾难恢复区域中使用其他虚拟私有云 (VPC) 进行恢复,以便使用相同的 IP 地址。
在开始故障切换移之前,请确保
node-1是您创建的 AlwaysOn 可用性组的主节点。启动域控制器和主 SQL Server 节点,以避免任何数据同步问题,因为这两个节点由两个单独的一致性组保护。如需模拟服务中断,请按以下步骤操作:创建恢复 VPC。
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR = $(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
终止数据复制。
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
停止主要区域中的来源虚拟机。
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
使用磁盘副本在灾难恢复区域中创建虚拟机。这些虚拟机将拥有来源虚拟机的 IP 地址。
NODE1IP=$(gcloud compute instances describe node-1 --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2 --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=auto-delete=yes,boot=no,device-name=node-1-datadisk-replica,mode=rw,name=node-1-datadisk-replica gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica
我们模拟了突发状况,并故障切换到了灾难恢复区域。现在,我们可以测试辅助实例是否正常运行。
验证 SQL Server 连接
创建虚拟机后,验证数据库是否已成功恢复,以及服务器是否按预期运行。为了测试数据库,您将从已恢复的数据库中运行一个 SELECT 查询。
- 使用远程桌面连接到 SQL Server 虚拟机。
- 打开 SQL Server Management Studio。
- 在“连接到服务器”对话框中,验证服务器名称是否设置为
NODE-1,然后选择连接。 在文件菜单中,依次选择文件 > 新建 > 查询,使用当前连接。
USE [bookshelf]; SELECT * FROM Books;
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请执行以下操作:
删除项目
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud 架构中心。