Este tutorial descreve como ativar a replicação assíncrona do disco persistente (replicação assíncrona do PD) em duas regiões como solução de recuperação de desastres (RD) e como ativar as instâncias de RD em caso de desastre. Google Cloud
Para efeitos deste documento, um desastre é um evento em que um cluster de alta disponibilidade (HA) da base de dados principal falha ou fica indisponível. Uma base de dados principal pode falhar quando a região em que se encontra falha ou se torna inacessível.
Este tutorial destina-se a arquitetos, administradores e engenheiros de bases de dados.
Objetivos
- Ative a replicação assíncrona do disco persistente para todos os nós do cluster do grupo de disponibilidade AlwaysOn do SQL Server em execução no Google Cloud.
- Simule um evento de desastre e execute um processo completo de recuperação de desastres para validar a configuração de recuperação de desastres.
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custos com base na sua utilização projetada,
use a calculadora de preços.
Quando terminar as tarefas descritas neste documento, pode evitar a faturação contínua eliminando os recursos que criou. Para mais informações, consulte o artigo Limpe.
Antes de começar
Para este tutorial, precisa de um Google Cloud projeto. Pode criar um novo ou selecionar um projeto que já criou:
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Recuperação de desastres em Google Cloud
Na Google Cloud, a recuperação de desastres consiste em garantir a continuidade do processamento, especialmente quando uma região falha ou se torna inacessível. Existem várias opções de implementação para o site de recuperação de desastres, que são ditadas pelos requisitos do objetivo de ponto de recuperação (RPO) e do objetivo de tempo de recuperação (RTO). Este tutorial aborda uma das opções em que os discos da máquina virtual (VM) são replicados da região principal para a região de recuperação de desastres (DR).
Recuperação de desastres para a replicação assíncrona do Persistent Disk
A replicação assíncrona do Persistent Disk (replicação assíncrona do PD) oferece replicação de armazenamento de blocos de RPO e RTO baixos para recuperação de desastres ativa-passiva entre regiões.
A replicação assíncrona de PDs é uma opção de armazenamento que oferece replicação assíncrona de dados entre duas regiões. No caso improvável de uma interrupção regional, a replicação assíncrona de PD permite-lhe fazer failover dos seus dados para uma região secundária e reiniciar as suas cargas de trabalho nessa região.
A replicação assíncrona de PD replica dados de um disco anexado a uma carga de trabalho em execução, conhecido como disco principal, para um disco separado localizado noutra região. O disco que recebe os dados replicados é denominado disco secundário.
Para garantir que as réplicas de todos os discos associados a cada nó do SQL Server contêm dados do mesmo momento, os discos são adicionados a um grupo de consistência. Os grupos de consistência permitem-lhe realizar testes de DR e DR em vários discos.
Arquitetura de recuperação de desastres
Para a replicação assíncrona de PD, o diagrama seguinte mostra uma arquitetura mínima que suporta a AD da base de dados numa região principal e a replicação de discos da região principal para a região de RD.
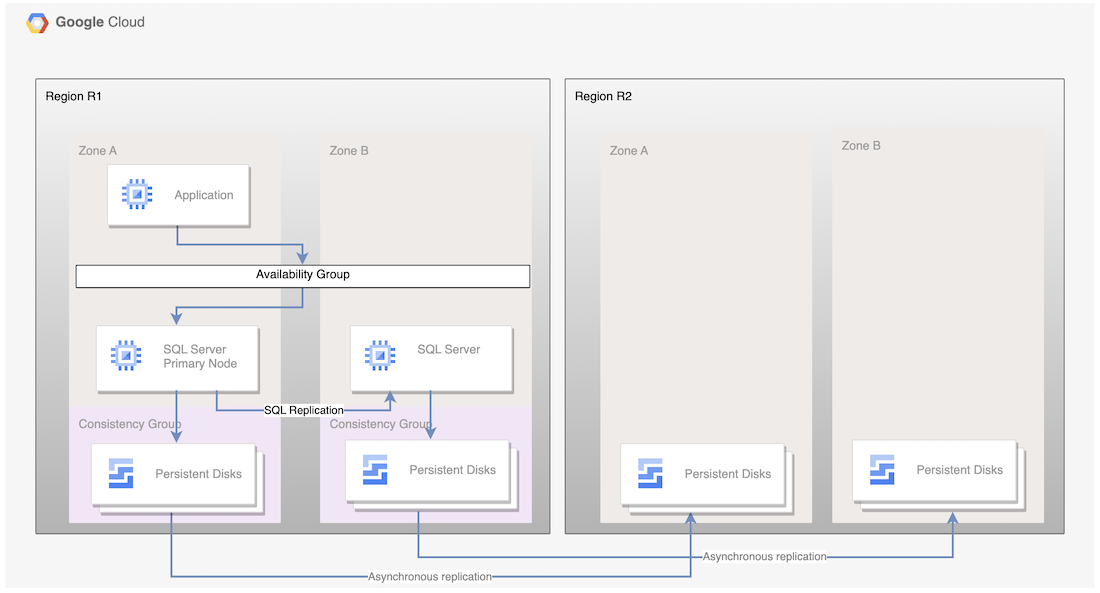
Figura 1. Arquitetura de recuperação de desastres com o Microsoft SQL Server e a replicação assíncrona do PD
Esta arquitetura funciona da seguinte forma:
- Duas instâncias do Microsoft SQL Server, uma instância principal e uma instância de reserva, fazem parte de um grupo de disponibilidade e estão localizadas na mesma região (R1), mas em zonas diferentes (zonas A e B). As duas instâncias em R1 coordenam os respetivos estados através do modo de confirmação síncrona. O modo síncrono é usado porque suporta a alta disponibilidade e mantém um estado de dados consistente.
- Os discos de ambos os nós SQL são adicionados a grupos de consistência e replicados para a região de recuperação de desastres R2. Os dados são replicados de forma assíncrona pela infraestrutura subjacente.
- Apenas os discos são replicados para a região R2. Durante a recuperação de desastres, são criadas novas VMs e os discos replicados existentes são anexados às VMs para colocar os nós online.
Processo de recuperação de desastres
O processo de recuperação de desastres é iniciado quando uma região fica indisponível. O processo de DR prescreve os passos operacionais que têm de ser tomados, manual ou automaticamente, para mitigar a falha da região e estabelecer uma instância primária em execução numa região disponível.
Um processo de recuperação de desastres (RD) de base de dados básico consiste nos seguintes passos:
- A primeira região (R1), que está a executar a instância da base de dados principal, fica indisponível.
- A equipa de operações reconhece e confirma formalmente o desastre e decide se é necessária uma comutação por falha.
- Se for necessária uma comutação por falha, a replicação de discos da região principal para a região de recuperação de desastres é terminada. É criada uma nova VM a partir das réplicas do disco e é colocada online.
- A nova base de dados principal na região de DR (R2) é validada e colocada online, o que permite a conetividade.
- Os utilizadores retomam o processamento na nova base de dados principal e acedem à instância principal no R2.
Embora este processo básico estabeleça novamente uma base de dados principal funcional, não estabelece uma arquitetura de HA completa, em que a nova base de dados principal tem um nó de espera.
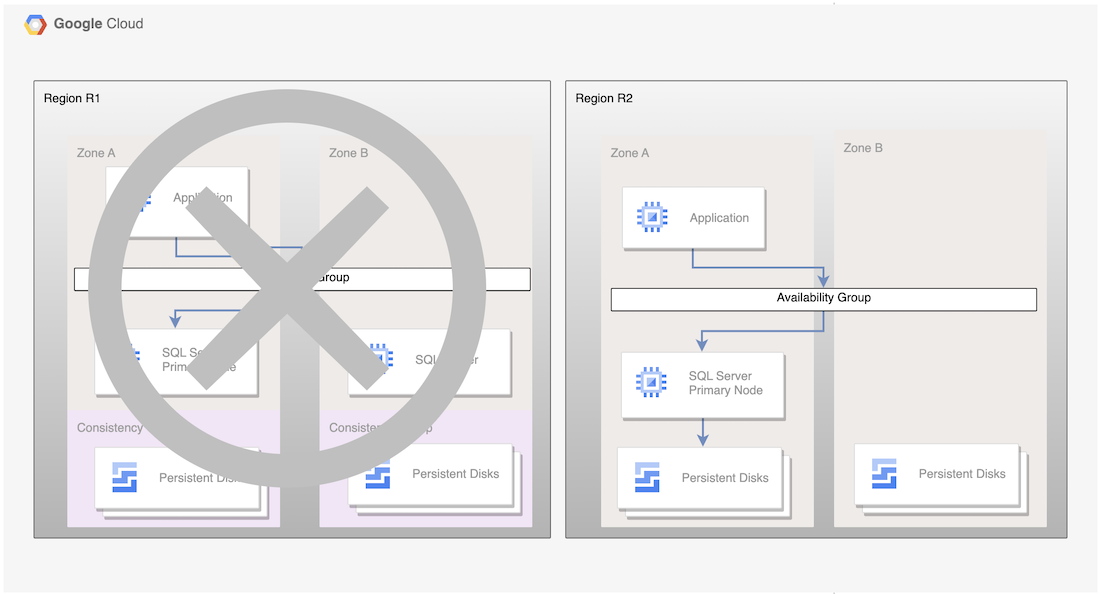
Figura 2. Implementação do SQL Server após a recuperação de desastres com replicação assíncrona do disco persistente
Recorra a uma região recuperada
Quando a região principal (R1) voltar a ficar online, pode planear e executar o processo de recuperação. O processo de reversão consiste em todos os passos descritos neste tutorial, mas, neste caso, R2 é a origem e R1 é a região de recuperação.
Escolha uma edição do SQL Server
Este tutorial suporta as seguintes versões do Microsoft SQL Server:
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
- SQL Server 2022 Enterprise Edition
O tutorial usa a funcionalidade de grupos de disponibilidade AlwaysOn no SQL Server.
Se não precisar de uma base de dados principal do Microsoft SQL Server de HA e uma única instância de base de dados for suficiente como principal, pode usar as seguintes versões do SQL Server:
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
- SQL Server 2022 Standard Edition
As versões de 2016, 2017, 2019 e 2022 do SQL Server têm o Microsoft SQL Server Management Studio instalado na imagem. Não precisa de o instalar separadamente. No entanto, num ambiente de produção, recomendamos que instale uma instância do Microsoft SQL Server Management Studio numa VM separada em cada região. Se configurar um ambiente de HA, deve instalar o Microsoft SQL Server Management Studio uma vez para cada zona para garantir que permanece disponível se outra zona ficar indisponível.
Configure a recuperação de desastres para o Microsoft SQL Server
Este tutorial usa a imagem
sql-ent-2022-win-2022para o Microsoft SQL Server Enterprise.Para ver uma lista completa de imagens, consulte o artigo Imagens do SO.
Configure um cluster de alta disponibilidade de duas instâncias
Para configurar a replicação de discos para a região de recuperação de desastres do SQL Server, primeiro, crie um cluster de alta disponibilidade de duas instâncias numa região. Uma instância funciona como principal e a outra como suplente. Para concluir este passo, siga as instruções em Configurar grupos de disponibilidade AlwaysOn do SQL Server. Este tutorial usa
us-central1para a região principal (denominada R1). Se seguiu os passos em Configurar grupos de disponibilidade AlwaysOn do SQL Server, criou duas instâncias do SQL Server na mesma região (us-central1). Implementou uma instância principal do SQL Server (node-1) emus-central1-ae uma instância de reserva (node-2) emus-central1-b.Ative a replicação assíncrona de disco
Depois de criar e configurar todas as VMs, ative a cópia de discos entre regiões criando um grupo de consistência para todos os discos associados às VMs. Os dados são copiados dos discos de origem para discos em branco recém-criados na região designada.
Crie um grupo de consistência para os nós SQL e o controlador de domínio. Uma das limitações de um disco zonal é que os grupos de consistência não podem abranger várias zonas.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION
Adicione os discos das VMs primárias e de espera aos grupos de consistência correspondentes.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-1-datadisk \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies node-2-datadisk \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
Crie discos secundários em branco na região sincronizada
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-1-datadisk-replica \ --zone=$DR_REGION-a \ --size=$PD_SIZE \ --primary-disk=node-1-datadisk \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create node-2-datadisk-replica \ --zone=$DR_REGION-b \ --size=$PD_SIZE \ --primary-disk=node-2-datadisk \ --primary-disk-zone=$REGION-b gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
Inicie a replicação do disco. Os dados são replicados do disco principal para o disco em branco criado recentemente na região de recuperação de desastres.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-1-datadisk \ --zone=$REGION-a \ --secondary-disk=node-1-datadisk-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication node-2-datadisk \ --zone=$REGION-b \ --secondary-disk=node-2-datadisk-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
Neste momento, os dados devem estar a ser replicados entre regiões. O estado da replicação de cada disco deve indicar
Active.Simule uma recuperação de desastres
Nesta secção, testa a arquitetura de recuperação de desastres configurada neste tutorial.
Simule uma indisponibilidade e execute uma comutação por falha de recuperação de desastres
Durante uma comutação por falha de DR, cria novas VMs na região de DR e anexa os discos replicados às mesmas. Para simplificar a comutação por falha, pode usar uma nuvem virtual privada (VPC) diferente na região de recuperação de desastres para a recuperação, de modo a usar o mesmo endereço IP.
Antes de iniciar a comutação por falha, certifique-se de que
node-1é o nó principal do grupo de disponibilidade AlwaysOn que criou. Apresente o controlador de domínio e o nó do SQL Server principal para evitar problemas de sincronização de dados, uma vez que os dois nós estão protegidos por dois grupos de consistência separados. Para simular uma indisponibilidade, siga estes passos:Crie uma VPC de recuperação.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR = $(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
Termine a replicação de dados.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
Pare as VMs de origem na região principal.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
Crie VMs na região de RD com réplicas de discos. Estas VMs têm o endereço IP da VM de origem.
NODE1IP=$(gcloud compute instances describe node-1 --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2 --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=auto-delete=yes,boot=no,device-name=node-1-datadisk-replica,mode=rw,name=node-1-datadisk-replica gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica
Simulámos uma indisponibilidade e mudámos para a região de recuperação de desastres. Agora, podemos testar se a instância secundária está a funcionar corretamente ou não.
Valide a conetividade do SQL Server
Depois de criar as VMs, verifique se as bases de dados foram recuperadas com êxito e se o servidor está a funcionar como esperado. Para testar a base de dados, vai executar uma consulta de seleção a partir da base de dados recuperada.
- Estabeleça ligação à VM do SQL Server através do Ambiente de Trabalho Remoto.
- Abra o SQL Server Management Studio.
- Na caixa de diálogo Ligar ao servidor, verifique se o nome do servidor está definido como
NODE-1e selecione Ligar. No menu Ficheiro, selecione Ficheiro > Novo > Consulta com a ligação atual.
USE [bookshelf]; SELECT * FROM Books;
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial:
Elimine o projeto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
O que se segue?
- Explore arquiteturas de referência, diagramas e práticas recomendadas sobre o Google Cloud. Consulte o nosso Centro de arquitetura na nuvem.