このチュートリアルでは、障害復旧(DR)ソリューションとして 2 つの Google Cloud リージョンで Microsoft SQL Server データベース システムをデプロイして管理する方法について説明します。また、障害が発生したデータベース インスタンスから正常に稼働しているインスタンスにフェイルオーバーする方法について説明します。このドキュメントにおいては、障害とはプライマリ データベースで障害が発生したり、利用不能になるイベントを意味します。
プライマリ データベースは、配置されているリージョンに障害が発生したり、アクセスできなくなったりした場合に障害となる可能性があります。リージョンが利用可能で正常に動作している場合でも、システムエラーが原因でプライマリ データベースに障害が発生することがあります。この場合、障害復旧はクライアントが処理を継続するために、セカンダリ データベースを利用できるようにするプロセスです。
このチュートリアルは、データベース アーキテクト、管理者、エンジニアを対象としています。
目標
- Microsoft SQL Server の AlwaysOn 可用性グループを使用して、Google Cloud にマルチリージョン障害復旧環境をデプロイします。
- 障害イベントをシミュレートし、完全な障害復旧プロセスを実行して障害復旧構成を検証します。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
このチュートリアルでは Google Cloud プロジェクトが必要です。新しいプロジェクトを作成することも、すでに作成済みのプロジェクトを選択することもできます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
障害復旧について
Google Cloudの障害復旧(DR)は、特にリージョンで障害が発生した場合やアクセスできなくなった場合に、処理の継続性を提供することが目的です。データベース管理システムなどのシステムの場合、少なくとも 2 つのリージョンにシステムをデプロイして DR を実装します。この設定では、1 つのリージョンが使用不可能になってもシステムは引き続き動作します。
データベース システムの障害復旧
プライマリ データベース インスタンスで障害発生時にセカンダリ データベースに切り替えるプロセスをデータベースの障害復旧(データベース DR)といいます。このコンセプトの詳細については、Microsoft SQL Server の障害復旧をご覧ください。セカンダリ データベースの状態は、プライマリ データベースが使用不能になった時点か、プライマリ データベースの最近のトランザクションの一部が欠落している時点において、プライマリ データベースの状態と一致することが理想的です。
障害復旧アーキテクチャ
Microsoft SQL Server について、次の図で、データベース DR をサポートする最小限のアーキテクチャを示しています。
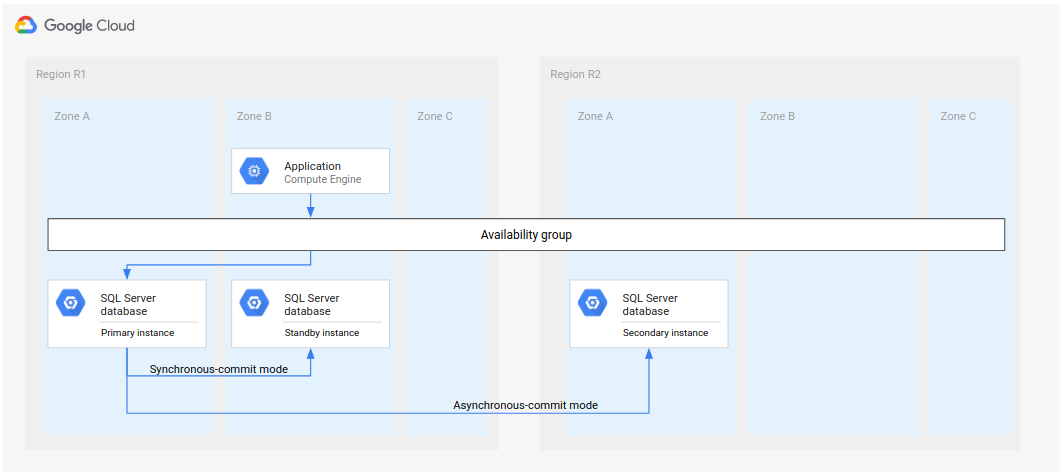
図 1. Microsoft SQL Server を使用した標準障害復旧アーキテクチャ。
このアーキテクチャは次のように機能します。
- Microsoft SQL Server の 2 つのインスタンス(プライマリ インスタンスとスタンバイ インスタンス)は同じリージョン(R1)にありますが、ゾーンは異なります(ゾーン A と B)。R1 の 2 つのインスタンスは、同期 commit モードを使用して状態を調整しています。同期モードは高可用性を実現し、一貫したデータ状態を維持する目的で使用されます。
- Microsoft SQL Server の 1 つのインスタンス(セカンダリまたは障害復旧インスタンス)が 2 番目のリージョン(R2)に配置されます。DR を実施する際には、非同期 commit モードを使用して、R2 のセカンダリ インスタンスが R1 のプライマリ インスタンスと同期します。非同期モードが使用される理由は、そのパフォーマンスにあります(プライマリ インスタンスでの commit 処理の速度が低下しません)。
上の図で、アーキテクチャは可用性グループを示しています。可用性グループがリスナーで使用される場合、クライアントが以下によって配信されるとクライアントに同じ接続文字列が提供されます。
- プライマリ インスタンス
- スタンバイ インスタンス(ゾーン障害の後)
- セカンダリ インスタンス(リージョン障害の後、およびセカンダリ インスタンスが新しいプライマリ インスタンスになった後)
上に示したアーキテクチャのバリアントでは、最初のリージョン(R1)の 2 つのインスタンスを同じゾーンにデプロイします。このアプローチによってパフォーマンスが向上する可能性がありますが、可用性は高くありません。DR プロセスを開始するために、1 つのゾーンの停止が必要になる可能性があります。
基本的な障害復旧プロセス
リージョンが利用できなくなり、プライマリ データベースがフェイルオーバーして別の運用リージョンで処理を再開すると、DR プロセスが開始されます。リージョン障害を軽減し、使用可能なリージョンで実行するプライマリ インスタンスを確立するために、DR プロセスは手動または自動で実行されるべき運用ステップを規定します。
基本的なデータベース DR プロセスは、次の手順で構成されます。
- プライマリ データベース インスタンスを実行している最初のリージョン(R1)が使用できなくなります。
- オペレーション チームが障害を認識して正式に応答し、フェイルオーバーが必要かどうかを判断します。
- フェイルオーバーが必要な場合は、2 番目のリージョン(R2)のセカンダリ データベース インスタンスが新しいプライマリ インスタンスに設定されます。
- クライアントは、新しいプライマリ データベースで処理を再開し、R2 のプライマリ インスタンスにアクセスします。
この基本的なプロセスは、稼働中のプライマリ データベースを再度確立しますが、完全なプライマリ DR アーキテクチャを確立しません。このアーキテクチャでは、新しいプライマリには、スタンバイとセカンダリのデータベース インスタンスがあります。
完全な障害復旧プロセス
完全な DR プロセスでは、フェイルオーバー後に完全な DR アーキテクチャを確立するためのステップを追加することで、基本的な DR プロセスを拡張します。次の図は、データベースの完全な DR アーキテクチャを示しています。
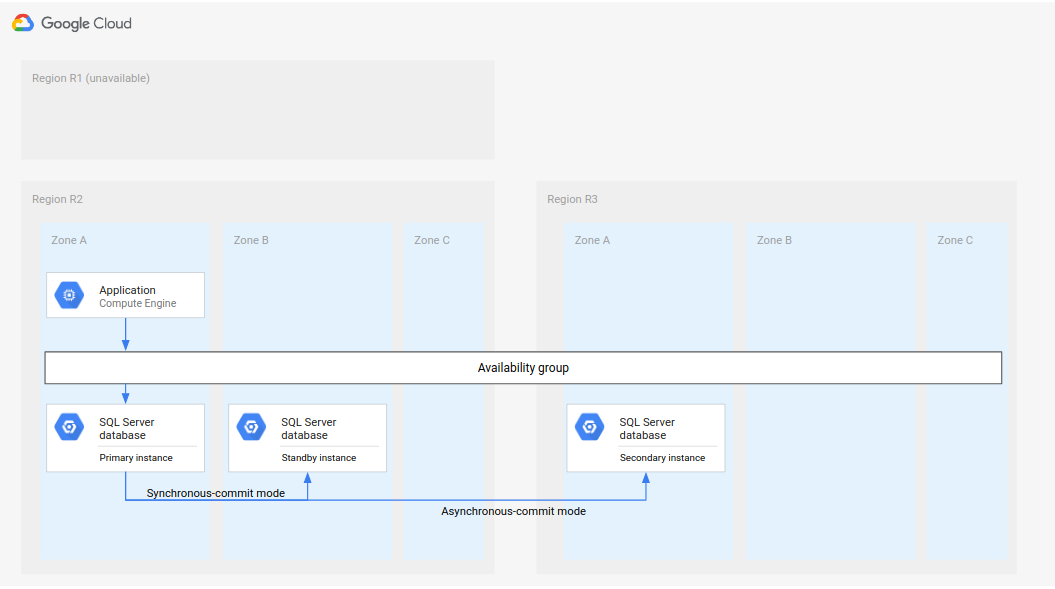
図 2.使用できないプライマリ リージョン(R1)での障害復旧。
このデータベースの完全な DR アーキテクチャは、次のように機能します。
- プライマリ データベース インスタンスを実行している最初のリージョン(R1)が使用できなくなります。
- オペレーション チームが障害を認識して正式に応答し、フェイルオーバーが必要かどうかを判断します。
- フェイルオーバーが必要な場合は、2 番目のリージョン(R2)のセカンダリ データベース インスタンスがプライマリ インスタンスに設定されます。
- 別のセカンダリ インスタンス(新しいスタンバイ インスタンス)が作成され、R2 で起動され、プライマリ インスタンスに追加されます。スタンバイ インスタンスは、プライマリ インスタンスとは異なるゾーンにあります。プライマリ データベースは、高可用性を備えた 2 つのインスタンス(プライマリとスタンバイ)で構成されるようになりました。
- 3 番目のリージョン(R3)では、新しいセカンダリ(スタンバイ)データベース インスタンスが作成され開始されます。このセカンダリ インスタンスは、R2 の新しいプライマリ インスタンスに非同期で接続されます。この時点で元の障害復旧アーキテクチャが再作成され、稼働を開始します。
復元したリージョンへのフォールバック
オンラインに復帰した後、最初のリージョン(R1)は新しいセカンダリ データベースをホストできます。R1 の復旧が十分に速ければ、R3(3 番目のリージョン)ではなく、R1 の完全復旧プロセスのステップ 5 を実装できます。この場合 3 番目のリージョンは必要ありません。
次の図は、R1 が時間内に使用可能になった場合のアーキテクチャを示しています。
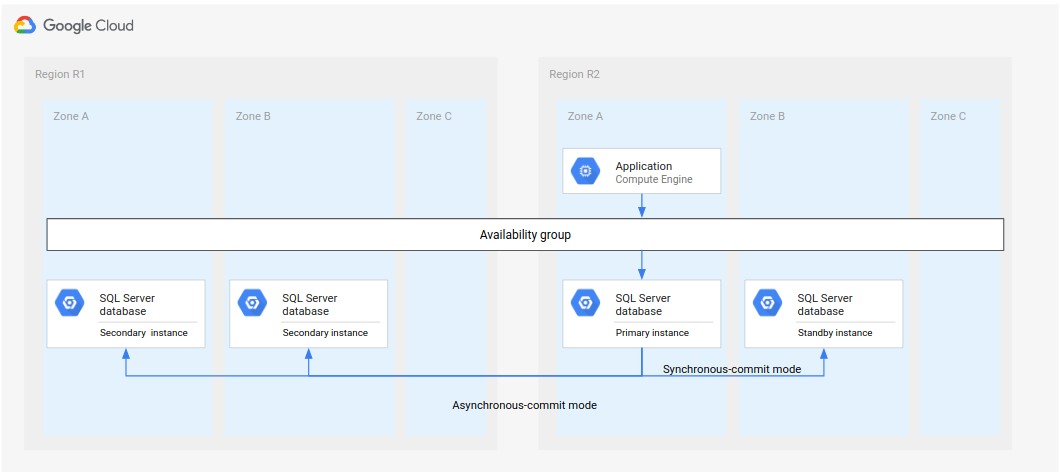
図 3.障害が発生したリージョン R1 が再度利用可能になった後の障害復旧。
このアーキテクチャーでのリカバリー手順は、R1 が R3 の代わりにセカンダリインスタンスのロケーションになるという違いを除いて、前に完全な障害復旧プロセスで概説した手順と同じです。
SQL Server のエディションの選択
このチュートリアルは、次のバージョンの Microsoft SQL Server に対応しています。
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
- SQL Server 2022 Enterprise Edition
このチュートリアルでは SQL Server の AlwaysOn 可用性グループ機能を使用します。
高可用性(HA)Microsoft SQL Server プライマリ データベースが必要でなく、単一のデータベース インスタンスがプライマリとして十分である場合は、次のバージョンの SQL Server を使用できます。
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
- SQL Server 2022 Standard Edition
SQL Server の 2016 年、2017 年、2019 年、2022 年のバージョンは、Microsoft SQL Server Management Studio がイメージにインストールされています。別途インストールする必要はありません。ただし本番環境では、Microsoft SQL Server Management Studio の 1 つのインスタンスを、各リージョンの個別の VM にインストールすることをおすすめします。HA 環境を設定する場合は、ゾーンごとに Microsoft SQL Server Management Studio をインストールして、他のゾーンが使用できなくなっても、使用を継続できるようにしてください。
マルチリージョン DR 向けに Microsoft SQL Server を設定する
このセクションでは、Microsoft SQL Server に次のイメージを使用します。
- Microsoft SQL Server 2016 Enterprise Edition の場合:
sql-ent-2016-win-2016 - Microsoft SQL Server 2017 Enterprise Edition の場合:
sql-ent-2017-win-2016 - Microsoft SQL Server 2019 Enterprise Edition の場合:
sql-ent-2019-win-2019 - Microsoft SQL Server 2022 Enterprise Edition の場合:
sql-ent-2022-win-2022
イメージの完全なリストについては、イメージをご覧ください。
2 インスタンス高可用性クラスタを設定する
SQL Server のマルチリージョン データベース DR アーキテクチャを設定するには、まず 2 つのインスタンスの高可用性(HA)クラスタを 1 つのリージョンに作成します。一方のインスタンスはプライマリとして機能し、もう一方はセカンダリとして機能します。この手順を行うには、SQL Server AlwaysOn 可用性グループの構成の手順に沿って操作します。このチュートリアルでは、プライマリ リージョン(R1 と呼びます)に us-central1 を使用します。始める前に、以下の注意事項を確認してください。
SQL Server AlwaysOn 可用性グループの構成の手順を行った場合、同じリージョン(
us-central1)に 2 つの SQL Server インスタンスを作成することになります。プライマリ SQL Server インスタンス(node-1)をus-central1-aにデプロイし、スタンバイ インスタンス(node-2)をus-central1-bにデプロイします。このチュートリアルでは図 4 のアーキテクチャを実装しますが、複数のゾーンでドメイン コントローラを設定することをおすすめします。このアプローチにより、HA と DR 対応のデータベース アーキテクチャを確実に設定できます。たとえば、1 つのゾーンでシステム停止が発生しても、そのゾーンは、デプロイされたアーキテクチャでの単一障害点にはなりません。
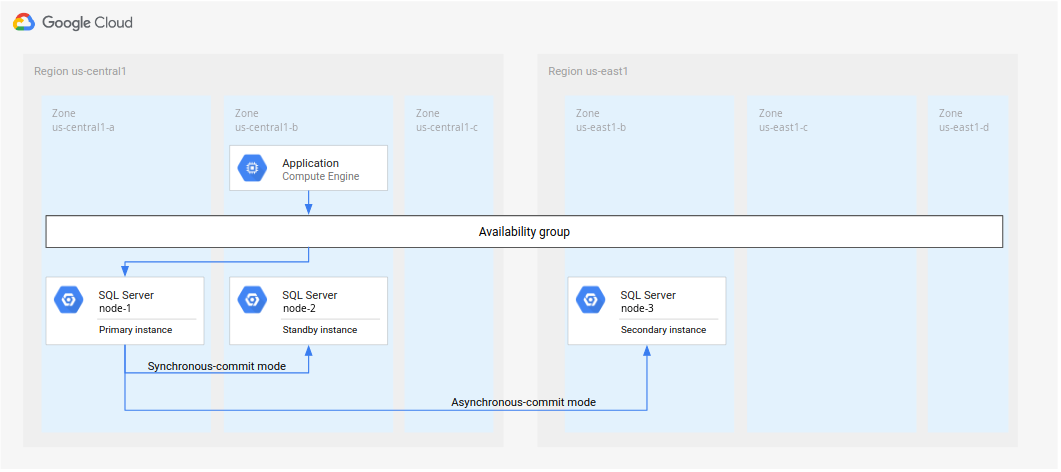
図 4.このチュートリアルで実装されている標準的な障害復旧アーキテクチャ。
障害復旧のためにセカンダリ インスタンスを追加する
次に、3 つ目の SQL Server インスタンス(node-3 という名前のセカンダリ インスタンス)をセットアップし、ネットワークを次のように構成します。
Windows Server フェイルオーバー クラスタ ノード用の専用スクリプトを作成します。このスクリプトは、必要な Windows 機能をインストールし、WSFC と SQL Server 用のファイアウォール ルールを作成します。また、データディスクのフォーマットを行い、SQL Server 用のデータフォルダとログフォルダを作成します。
cat << "EOF" > specialize-node.ps1 $ErrorActionPreference = "stop" # Install required Windows features Install-WindowsFeature Failover-Clustering -IncludeManagementTools Install-WindowsFeature RSAT-AD-PowerShell # Open firewall for WSFC netsh advfirewall firewall add rule name="Allow SQL Server health check" dir=in action=allow protocol=TCP localport=59997 # Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022 # Format data disk Get-Disk | Where partitionstyle -eq 'RAW' | Initialize-Disk -PartitionStyle MBR -PassThru | New-Partition -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel 'Data' -Confirm:$false # Create data and log folders for SQL Server md d:\Data md d:\Logs EOF
次の変数を初期化します。
VPC_NAME=
VPC_NAMESUBNET_NAME=SUBNET_NAMEREGION=us-east1 PD_SIZE=200 MACHINE_TYPE=n2-standard-8ここで
VPC_NAME: VPC の名前SUBNET_NAME:us-east1リージョンのサブネットの名前
SQL Server インスタンスを作成します。
gcloud compute instances create node-3 \ --zone $REGION-b \ --machine-type $MACHINE_TYPE \ --subnet $SUBNET_NAME \ --image-family sql-ent-2022-win-2022 \ --image-project windows-sql-cloud \ --tags wsfc,wsfc-node \ --boot-disk-size 50 \ --boot-disk-type pd-ssd \ --boot-disk-device-name "node-3" \ --create-disk=name=node-3-datadisk,size=$PD_SIZE,type=pd-ssd,auto-delete=no \ --metadata enable-wsfc=true \ --metadata-from-file=sysprep-specialize-script-ps1=specialize-node.ps1新しい SQL Server インスタンスに Windows パスワードを設定します。
Google Cloud コンソールで、Compute Engine ページに移動します。
Compute Engine クラスタ
node-3の [接続] 列で、[Windows パスワードを設定] プルダウン リストを選択します。ユーザー名とパスワードを設定します。後で使用できるようにメモしておいてください。
[RDP] をクリックして、
node-3インスタンスに接続します。前の手順で設定したユーザー名とパスワードを入力し、[OK] をクリックします。
インスタンスを Windows ドメインに追加します。
[スタート] ボタンを右クリックするか Win + X を押して、[Windows PowerShell(管理者)] をクリックします。
特権昇格を確認するプロンプトが表示されたら [はい] をクリックします。
コンピュータを Active Directory ドメインに追加して再起動します。
Add-Computer -Domain
DOMAIN -RestartDOMAINは、Active Directory ドメインの DNS 名に置き換えます。再起動が完了するまで 1 分ほど待ちます。
セカンダリ インスタンスをフェイルオーバー クラスタに追加する
次に、セカンダリ インスタンス(node-3)を Windows フェイルオーバー クラスタに追加します。
RDP を使用して
node-1インスタンスまたはnode-2インスタンスに接続し、管理者ユーザーとしてログインします。管理者ユーザーとして PowerShell ウィンドウを開き、このチュートリアルのクラスタ環境の変数を設定します。
$node3 = "node-3" $nameWSFC = "
SQLSRV_CLUSTER" # Name of clusterSQLSRV_CLUSTERは、SQL Server クラスタの名前に置き換えます。セカンダリ インスタンスをクラスタに追加します。
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3このコマンドの実行には時間を要する場合があります。プロセスが応答しなくなり、自動的に結果を返さなくなる可能性があるため、場合によっては
Enterを押します。ノードで、AlwaysOn 高可用性機能を有効にします。
Enable-SqlAlwaysOn -ServerInstance $node3 -Force
これで、ノードがフェイルオーバー クラスタの一部になりました。
セカンダリ インスタンスを既存の可用性グループに追加する
次に、SQL Server インスタンス(セカンダリ インスタンス)とデータベースを可用性グループに追加します。
リモート デスクトップを使用して、
node-3に接続します。ドメイン ユーザー アカウントでログインします。SQL Server 構成マネージャーを開きます。
ナビゲーション パネルで [SQL Server Services] を選択します。
サービスのリストで [SQL Server(MSSQLSERVER)] を右クリックし、[プロパティ] を選択します。
[ログオン] でアカウントを変更します。
- アカウント名:
DOMAIN\sql_server。DOMAINは Active Directory ドメインの NetBIOS 名です。 - パスワード: 前に sql_server ドメイン アカウントに選択したパスワードを入力します。
- アカウント名:
[OK] をクリックします。
SQL Server の再起動を求めるプロンプトが表示されたら、[はい] を選択します。
3 つのインスタンス ノード(
node-1、node-2またはnode-3)のいずれかで、Microsoft SQL Server Management Studio を開いてプライマリ インスタンス(node-1)に接続します。- Object Explorer に移動します。
- [接続] プルダウン リストを選択します。
- [データベース エンジン] を選択します。
- [サーバー名] プルダウン リストから、[
node-1] を選択します。クラスタがリストに表示されない場合は、フィールドに入力します。
[新しいクエリ] をクリックします。
次のコマンドをペーストして、ノードに使用するリスナーに IP アドレスを追加し、[実行] をクリックします。
ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY LISTENER 'bookshelf' (ADD IP
('LOAD_BALANCER_IP_ADDRESS', '255.255.255.0'))LOAD_BALANCER_IP_ADDRESSは、us-east1リージョンのロードバランサの IP アドレスに置き換えます。オブジェクト エクスプローラで、[AlwaysOn 高可用性] ノードを開いてから、[可用性グループ] ノードを開きます。
bookshelf-agという名前の可用性グループを右クリックし、[レプリカを追加] を選択します。[概要] ページで、[AlwaysOn 高可用性] ノードをクリックしてから、[可用性グループ] ノードをクリックします。
[レプリカに接続] ページで、[接続] をクリックして、既存のセカンダリ レプリカ
node-2に接続します。[レプリカの指定] ページで、[レプリカを追加] をクリックし、新しいノード
node-3を追加します。自動フェイルオーバーによって同期コミットが発生するため、[自動フェイルオーバー] は選択しないでください。このような設定はリージョンの境界を超えるため、おすすめしません。[データ同期の選択] ページで、[Automatic Seeding] を選択します。
リスナーが存在しないため、[検証] ページで警告が生成されますが、無視しても問題ありません。
ウィザードの手順を完了します。
node-1 と node-2 のフェイルオーバー モードは自動的に設定されますが、node-3 では手動での設定が必要です。この違いは、高可用性と障害復旧を区別する 1 つの方法になります。
可用性グループが使用可能になりました。高可用性のために 2 つのノードを構成し、障害復旧用に 3 つ目のノードを構成しました。
障害復旧のシミュレーション
このセクションでは、このチュートリアルによる障害復旧アーキテクチャをテストし、またオプション DR の実装も検討します。
停止をシミュレーションして DR フェイルオーバーを実行する
プライマリ リージョンで障害または停止をシミュレーションします。
node-1の Microsoft SQL Server Management Studio で、node-1に接続します。テーブルを作成します。後の手順でレプリカを追加した後に、このテーブルが存在するかどうかを確認して、レプリカが正常に動作することを検証します。
USE bookshelf GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GOCloud Shell で、プライマリ リージョン(
us-central1)にある両方のサーバーをシャットダウンします。gcloud compute instances stop node-2 --zone us-central1-b --quiet gcloud compute instances stop node-1 --zone us-central1-a --quiet
node-3の Microsoft SQL Server Management Studio で、node-3に接続します。フェイルオーバーを実行し、可用性モードを同期 commit に設定します。ノードが非同期 commit モードのため、フェイルオーバーの強制が必要です。
ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO処理を再開できます。
node-3がプライマリ インスタンスになりました。(省略可)
node-3に新しいテーブルを作成します。レプリカを新しいプライマリと同期した後、このテーブルがレプリカに複製されているかどうかを確認します。USE bookshelf GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
この時点で node-3 がプライマリですが、元のリージョンにフォールバックするか、新しいセカンダリ インスタンスとスタンバイ インスタンスを設定して、完全な DR アーキテクチャを再作成することをおすすめします。次のセクションでは、これらの選択肢について説明します。
(省略可)トランザクションを完全に複製する DR アーキテクチャを再作成する
このユースケースは、プライマリに障害が発生する前にすべてのトランザクションがプライマリ データベースからセカンダリ データベースに複製される障害に対処します。この理想的なシナリオではデータが失われることはありません。障害が発生した時点で、セカンダリの状態がプライマリと整合しています。
このシナリオでは次の 2 つの方法で完全な DR アーキテクチャを再作成できます。
- 元のプライマリと元のスタンバイ(使用可能な場合)にフォールバックする。
- 元のプライマリとスタンバイが利用できない場合に、
node-3に新しいスタンバイとセカンダリを作成する。
アプローチ 1: 元のプライマリとスタンバイにフォールバックする
Cloud Shell で、元の(古い)プライマリとスタンバイを起動します。
gcloud compute instances start node-1 --zone us-central1-a --quiet gcloud compute instances start node-2 --zone us-central1-b --quietMicrosoft SQL Server Management Studio で、
node-1とnode-2をセカンダリ レプリカとして追加します。node-3で、2 つのサーバーを非同期コミットモードで追加します。USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOnode-1で、データベースを再度同期します。USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GOnode-2で、データベースを再度同期します。USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO
node-1を再度プライマリにします。node-3で、node-1の可用性モードを同期 commit に変更します。インスタンスnode-1が再びプライマリになります。USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOnode-1で、node-1をプライマリに、他の 2 つのノードをセカンダリに変更します。USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
すべてのコマンドが成功すると、次の図に示すように、node-1 がプライマリになり、他のノードはセカンダリになります。
アプローチ 2: 新しいプライマリとスタンバイを設定する
元のプライマリ インスタンスとスタンバイ インスタンスを障害から復元できない場合、復元に時間がかかりすぎる場合、リージョンにアクセスできない場合があります。一つの方法は、次の図に示すように、node-3 をプライマリのままにして、新しいスタンバイ インスタンスと新しいセカンダリ インスタンスを作成することです。
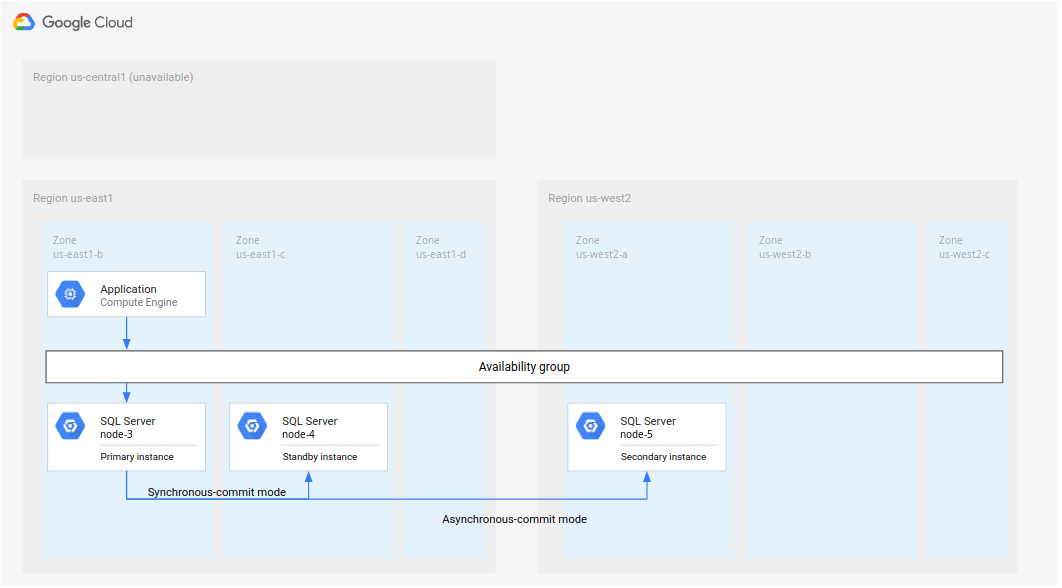
図 5. 元のプライマリ リージョン R1 が使用できない場合の障害復旧。
この実装では、次のことを行う必要があります。
node-3をus-east1でプライマリのままにします。新しいスタンバイ インスタンス(
node-4)をus-east1の別のゾーンに追加します。この手順により新しいデプロイが高可用性として確立されます。別のリージョン(
us-west2など)に新しいセカンダリ インスタンス(node-5)を作成します。この手順では障害復旧のために新しいデプロイを設定します。これでデプロイの全体が完了です。データベース アーキテクチャは HA と DR を完全にサポートしています。
(省略可)トランザクションがない場合にフォールバックを実行する
理想的ではない障害としては、プライマリで commit された 1 つ以上のトランザクションが、障害発生時にセカンダリに複製されない場合です(ハード障害とも呼ばれます)。フェイルオーバーでは、複製されていない commit されたトランザクションはすべて失われます。
このシナリオのフェイルオーバーの手順をテストするには、ハード障害を発生させる必要があります。ハード障害を発生させる最も良い方法は次のとおりです。
- ネットワークを変更して、プライマリ インスタンスとセカンダリ インスタンスの間の接続がないようにします。
- プライマリを変更する(例: テーブルを追加する、データを挿入する)
- 前述のフェイルオーバー プロセスを順に実行して、セカンダリを新しいプライマリにします。
フェイルオーバー プロセスのステップは、理想的なシナリオと同じですが、ネットワーク接続の中断後にプライマリに追加されたテーブルは、セカンダリでは表示されません。
ハード障害に対処する唯一の方法は、可用性グループからレプリカ(node-1 と node-2)を削除して、これらのレプリカを再度同期することです。同期することでセカンダリの状態に変化します。障害発生前に複製されなかったトランザクションは失われます。
node-1 をセカンダリ インスタンスとして追加するには、前述した node-3 を追加するのと同じ手順に沿って操作します(フェイルオーバー クラスタにセカンダリ インスタンスを追加するを参照)。ただし、node-1 ではなく、node-3 がプライマリになっている点が異なります。node-3 のインスタンスを可用性グループに追加するサーバーの名前に置き換える必要があります。同じ VM(node-1 と node-2)を再利用する場合は、サーバーを Windows Server フェイルオーバー クラスタに追加する必要はありません。SQL Server インスタンスを可用性グループに再度追加する処理のみを行います。
この時点で node-3 はプライマリ、node-1 と node-2 はセカンダリです。node-1 にフォールバックして、node-2 をスタンバイにし、node-3 をセカンダリにできるようになりました。これでシステムは障害前の状態と同じになりました。
自動フェイルオーバー
セカンダリ インスタンスにプライマリとして自動的にフェイルオーバーすると、問題が発生する場合があります。元のプライマリが再び使用可能になった後、一部のクライアントがセカンダリにアクセスして、他のクライアントが復元されたプライマリに書き込みを行うと、スプリット ブレインの状況が発生します。この場合、プライマリとセカンダリが並行して更新され、異なる状態となる可能性があります。このような状況を回避するために、このチュートリアルでは手動フェイルオーバーの手順について説明します。手動フェイルオーバーでは、フェイルオーバーをするかどうか(またはそのタイミング)を決定できます。
自動フェイルオーバーを実装する場合は、構成された 1 つのインスタンスのみをプライマリとし、変更可能にする必要があります。スタンバイ インスタンスまたはセカンダリ インスタンスでは、クライアントには書き込み権限を提供しないでください(状態複製用のプライマリを除く)。また、短期間にフェイルオーバーが連続して繰り返されることは回避する必要があります。たとえば、5 分ごとにフェイルオーバーすることは、信頼できる障害復旧戦略とは言えません。自動フェイルオーバー プロセスの場合は、このような問題のある状況に対する予防策に組み込むことができます。また、必要に応じてデータベース管理者による支援を得て、複雑な判断を下せるようにすることもできます。
代替デプロイ アーキテクチャ
このチュートリアルでは、次の図に示すように、フェイルオーバーにおいてプライマリ インスタンスとなるセカンダリ インスタンスを有する障害復旧アーキテクチャを設定します。
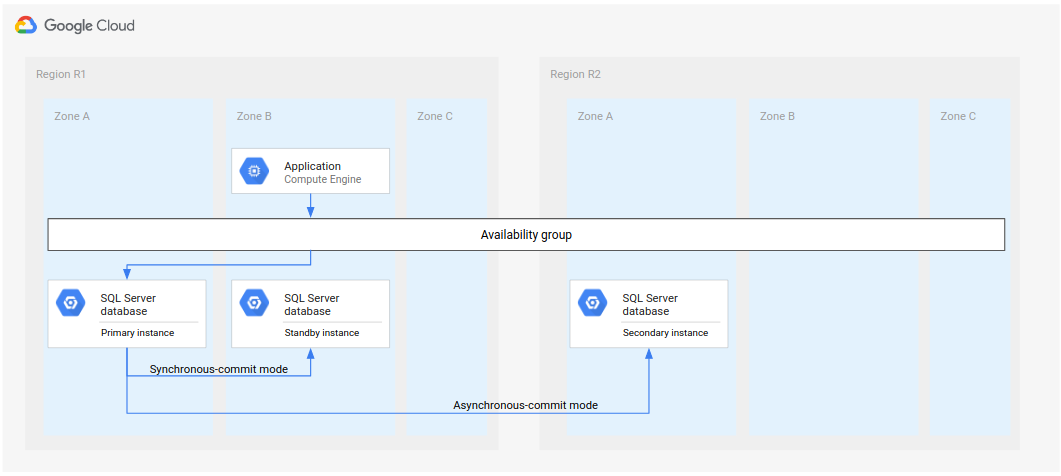
図 6. Microsoft SQL Server を使用した標準障害復旧アーキテクチャ。
つまりフェイルオーバーの場合、フォールバックが可能になるまで、またはスタンバイ(HA の場合)とセカンダリ(DR の場合)を構成するまで、結果のデプロイには単一のインスタンスが存在します。
別のデプロイ アーキテクチャでは、2 つのセカンダリ インスタンスを構成します。どちらのインスタンスもプライマリのレプリカです。フェイルオーバーが発生した場合、セカンダリのうちの 1 つをスタンバイとして構成できます。次の図は、フェイルオーバーの前後のデプロイ アーキテクチャを示しています。

図 7. 2 つのセカンダリ インスタンスを持つ標準的な障害復旧アーキテクチャ。
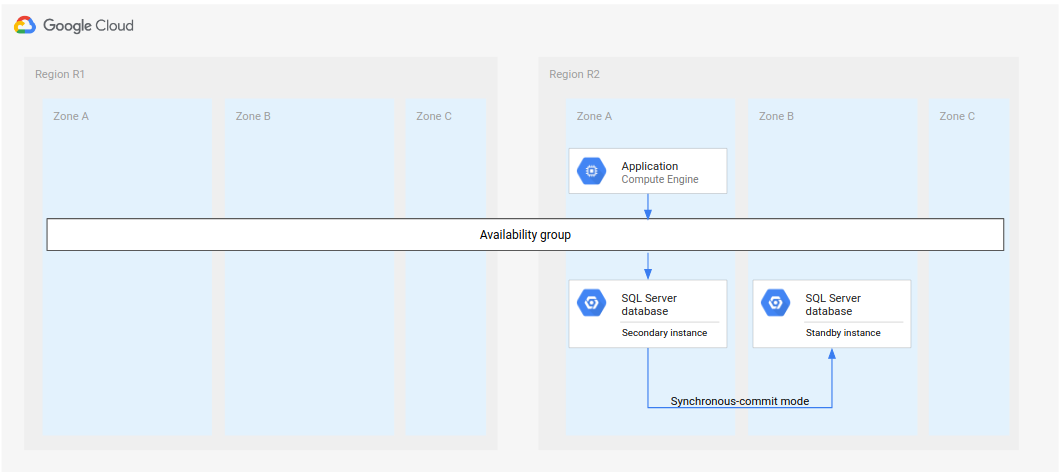
図 8.フェイルオーバー後の 2 つのセカンダリ インスタンスを持つ標準的な障害復旧アーキテクチャ。
2 つのセカンダリのいずれかをスタンバイ(図 8)にする必要がありますが、新しいスタンバイをゼロから作成して構成するよりもはるかに高速です。
2 つのセカンダリ インスタンスを使用するこのアーキテクチャに似たセットアップで DR に対応することもできます。2 番目のリージョンに 2 つのセカンダリを用意する(図 7)だけでなく、3 番目のリージョンにさらに 2 つのセカンダリをデプロイできます。この設定により、プライマリ リージョンでの障害発生後に適用する、HA と DR に対応したデプロイ アーキテクチャを効率的に作成できます。
クリーンアップ
このチュートリアルで使用したリソースについて Google Cloud アカウントに課金されないようにするには:
プロジェクトを削除する
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。