Este tutorial explica o processo de implementação de uma base de dados MySQL 5.6 no Google Cloud através do dispositivo de blocos replicados distribuídos (DRBD) e do Compute Engine. O DRBD é um sistema de armazenamento replicado distribuído para a plataforma Linux.
Este tutorial é útil se for um administrador de sistemas, um programador, um engenheiro, um administrador de bases de dados ou um engenheiro de DevOps. Pode querer gerir a sua própria instância do MySQL em vez de usar o serviço gerido por vários motivos, incluindo:
- Está a usar instâncias de várias regiões do MySQL.
- Tem de definir parâmetros que não estão disponíveis na versão gerida do MySQL.
- Quer otimizar o desempenho de formas que não são configuráveis na versão gerida.
O DRBD oferece replicação ao nível do dispositivo de blocos. Isto significa que não tem de configurar a replicação no próprio MySQL e usufrui imediatamente das vantagens do DRBD, por exemplo, suporte para o equilíbrio de carga de leitura e ligações seguras.
O tutorial usa o seguinte:
Não são necessários conhecimentos avançados para usar estes recursos, embora este documento faça referência a capacidades avançadas, como o clustering do MySQL, a configuração do DRBD e a gestão de recursos do Linux.
Arquitetura
O Pacemaker é um gestor de recursos de cluster. O Corosync é um pacote de comunicação e participação de cluster usado pelo Pacemaker. Neste tutorial, vai usar o DRBD para replicar o disco do MySQL da instância principal para a instância de reserva. Para que os clientes se possam ligar ao cluster do MySQL, também implementa um balanceador de carga interno.
Implementa um cluster gerido pelo Pacemaker de três instâncias de computação. Instala o MySQL em duas das instâncias, que servem como instâncias principal e de espera. A terceira instância funciona como um dispositivo de quórum.
Num cluster, cada nó vota no nó que deve ser o nó ativo, ou seja, o que executa o MySQL. Num cluster de dois nós, basta um voto para determinar o nó ativo. Nesse caso, o comportamento do cluster pode originar problemas de split-brain ou tempo de inatividade. Os problemas de divisão de cérebro ocorrem quando ambos os nós assumem o controlo porque só é necessário um voto num cenário de dois nós. O tempo de inatividade ocorre quando o nó que é encerrado é o que está configurado para ser sempre o principal em caso de perda de conetividade. Se os dois nós perderem a conetividade entre si, existe o risco de mais do que um nó do cluster assumir que é o nó ativo.
A adição de um dispositivo de quórum evita esta situação. Um dispositivo de quórum funciona como um árbitro, cuja única função é emitir um voto. Desta forma, numa situação em que as instâncias database1 e database2 não conseguem comunicar, este nó do dispositivo de quorum pode comunicar com uma das duas instâncias e ainda é possível alcançar uma maioria.
O diagrama seguinte mostra a arquitetura do sistema descrito aqui.

Preparação
Nesta secção, configura uma conta de serviço, cria variáveis de ambiente e reserva endereços IP.
Configure uma conta de serviço para as instâncias do cluster
Abra o Cloud Shell:
Crie a conta de serviço:
gcloud iam service-accounts create mysql-instance \ --display-name "mysql-instance"Anexe as funções necessárias para este tutorial à conta de serviço:
gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/compute.instanceAdmin.v1 gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/compute.viewer gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/iam.serviceAccountUser
Crie variáveis de ambiente do Cloud Shell
Crie um ficheiro com as variáveis de ambiente necessárias para este tutorial:
cat <<EOF > ~/.mysqldrbdrc # Cluster instance names DATABASE1_INSTANCE_NAME=database1 DATABASE2_INSTANCE_NAME=database2 QUORUM_INSTANCE_NAME=qdevice CLIENT_INSTANCE_NAME=mysql-client # Cluster IP addresses DATABASE1_INSTANCE_IP="10.140.0.2" DATABASE2_INSTANCE_IP="10.140.0.3" QUORUM_INSTANCE_IP="10.140.0.4" ILB_IP="10.140.0.6" # Cluster zones and region DATABASE1_INSTANCE_ZONE="asia-east1-a" DATABASE2_INSTANCE_ZONE="asia-east1-b" QUORUM_INSTANCE_ZONE="asia-east1-c" CLIENT_INSTANCE_ZONE="asia-east1-c" CLUSTER_REGION="asia-east1" EOFCarregue as variáveis de ambiente na sessão atual e defina o Cloud Shell para carregar automaticamente as variáveis em futuros inícios de sessão:
source ~/.mysqldrbdrc grep -q -F "source ~/.mysqldrbdrc" ~/.bashrc || echo "source ~/.mysqldrbdrc" >> ~/.bashrc
Reserve endereços IP
No Cloud Shell, reserve um endereço IP interno para cada um dos três nós do cluster:
gcloud compute addresses create ${DATABASE1_INSTANCE_NAME} ${DATABASE2_INSTANCE_NAME} ${QUORUM_INSTANCE_NAME} \ --region=${CLUSTER_REGION} \ --addresses "${DATABASE1_INSTANCE_IP},${DATABASE2_INSTANCE_IP},${QUORUM_INSTANCE_IP}" \ --subnet=default
Criar as instâncias do Compute Engine
Nos passos seguintes, as instâncias do cluster usam o Debian 9 e as instâncias do cliente usam o Ubuntu 16.
No Cloud Shell, crie uma instância do MySQL denominada
database1na zonaasia-east1-a:gcloud compute instances create ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --machine-type=n1-standard-2 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=50GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${DATABASE1_INSTANCE_NAME} \ --create-disk=mode=rw,size=300,type=pd-standard,name=disk-1 \ --private-network-ip=${DATABASE1_INSTANCE_NAME} \ --tags=mysql --service-account=mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --scopes="https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly" \ --metadata="DATABASE1_INSTANCE_IP=${DATABASE1_INSTANCE_IP},DATABASE2_INSTANCE_IP=${DATABASE2_INSTANCE_IP},DATABASE1_INSTANCE_NAME=${DATABASE1_INSTANCE_NAME},DATABASE2_INSTANCE_NAME=${DATABASE2_INSTANCE_NAME},QUORUM_INSTANCE_NAME=${QUORUM_INSTANCE_NAME},DATABASE1_INSTANCE_ZONE=${DATABASE1_INSTANCE_ZONE},DATABASE2_INSTANCE_ZONE=${DATABASE2_INSTANCE_ZONE}"Crie uma instância do MySQL denominada
database2na zonaasia-east1-b:gcloud compute instances create ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE} \ --machine-type=n1-standard-2 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=50GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${DATABASE2_INSTANCE_NAME} \ --create-disk=mode=rw,size=300,type=pd-standard,name=disk-2 \ --private-network-ip=${DATABASE2_INSTANCE_NAME} \ --tags=mysql \ --service-account=mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --scopes="https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly" \ --metadata="DATABASE1_INSTANCE_IP=${DATABASE1_INSTANCE_IP},DATABASE2_INSTANCE_IP=${DATABASE2_INSTANCE_IP},DATABASE1_INSTANCE_NAME=${DATABASE1_INSTANCE_NAME},DATABASE2_INSTANCE_NAME=${DATABASE2_INSTANCE_NAME},QUORUM_INSTANCE_NAME=${QUORUM_INSTANCE_NAME},DATABASE1_INSTANCE_ZONE=${DATABASE1_INSTANCE_ZONE},DATABASE2_INSTANCE_ZONE=${DATABASE2_INSTANCE_ZONE}"Crie um nó de quorum para utilização pelo Pacemaker na zona
asia-east1-c:gcloud compute instances create ${QUORUM_INSTANCE_NAME} \ --zone=${QUORUM_INSTANCE_ZONE} \ --machine-type=n1-standard-1 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=10GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${QUORUM_INSTANCE_NAME} \ --private-network-ip=${QUORUM_INSTANCE_NAME}Crie uma instância de cliente MySQL:
gcloud compute instances create ${CLIENT_INSTANCE_NAME} \ --image-family=ubuntu-1604-lts \ --image-project=ubuntu-os-cloud \ --tags=mysql-client \ --zone=${CLIENT_INSTANCE_ZONE} \ --boot-disk-size=10GB \ --metadata="ILB_IP=${ILB_IP}"
Instalar e configurar o DRBD
Nesta secção, instala e configura os pacotes DRBD nas instâncias database1
e database2 e, em seguida, inicia a replicação DRBD de database1
para database2.
Configure o DRBD na base de dados1
Na Google Cloud consola, aceda à página Instâncias de VM:
Na linha da instância
database1, clique em SSH para estabelecer ligação à instância.Crie um ficheiro para obter e armazenar metadados de instâncias em variáveis de ambiente:
sudo bash -c cat <<EOF > ~/.varsrc DATABASE1_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_ZONE" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_ZONE" -H "Metadata-Flavor: Google") QUORUM_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/QUORUM_INSTANCE_NAME" -H "Metadata-Flavor: Google") EOFCarregue as variáveis de metadados a partir do ficheiro:
source ~/.varsrcFormate o disco de dados:
sudo bash -c "mkfs.ext4 -m 0 -F -E \ lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb"Para uma descrição detalhada das opções
mkfs.ext4, consulte a página do manual mkfs.ext4.Instale o DRBD:
sudo apt -y install drbd8-utilsCrie o ficheiro de configuração do DRBD:
sudo bash -c 'cat <<EOF > /etc/drbd.d/global_common.conf global { usage-count no; } common { protocol C; } EOF'Crie um ficheiro de recursos DRBD:
sudo bash -c "cat <<EOF > /etc/drbd.d/r0.res resource r0 { meta-disk internal; device /dev/drbd0; net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } on database1 { disk /dev/sdb; address 10.140.0.2:7789; } on database2 { disk /dev/sdb; address 10.140.0.3:7789; } } EOF"Carregue o módulo de kernel DRBD:
sudo modprobe drbdLimpe o conteúdo do disco
/dev/sdb:sudo dd if=/dev/zero of=/dev/sdb bs=1k count=1024Crie o recurso DRBD
r0:sudo drbdadm create-md r0Apresente o DRBD:
sudo drbdadm up r0Desative o DRBD quando o sistema for iniciado, permitindo que o software de gestão de recursos do cluster inicie todos os serviços necessários pela seguinte ordem:
sudo update-rc.d drbd disable
Configure o DRBD na base de dados2
Agora, instale e configure os pacotes DRBD na instância database2.
- Ligue-se à instância
database2através de SSH. Crie um ficheiro
.varsrcpara obter e armazenar metadados de instâncias em variáveis de ambiente:sudo bash -c cat <<EOF > ~/.varsrc DATABASE1_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_ZONE" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_ZONE" -H "Metadata-Flavor: Google") QUORUM_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/QUORUM_INSTANCE_NAME" -H "Metadata-Flavor: Google") EOFCarregue as variáveis de metadados do ficheiro:
source ~/.varsrcFormate o disco de dados:
sudo bash -c "mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb"Instale os pacotes DRBD:
sudo apt -y install drbd8-utilsCrie o ficheiro de configuração do DRBD:
sudo bash -c 'cat <<EOF > /etc/drbd.d/global_common.conf global { usage-count no; } common { protocol C; } EOF'Crie um ficheiro de recursos DRBD:
sudo bash -c "cat <<EOF > /etc/drbd.d/r0.res resource r0 { meta-disk internal; device /dev/drbd0; net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } on ${DATABASE1_INSTANCE_NAME} { disk /dev/sdb; address ${DATABASE1_INSTANCE_IP}:7789; } on ${DATABASE2_INSTANCE_NAME} { disk /dev/sdb; address ${DATABASE2_INSTANCE_IP}:7789; } } EOF"Carregue o módulo de kernel DRBD:
sudo modprobe drbdLimpe o disco
/dev/sdb:sudo dd if=/dev/zero of=/dev/sdb bs=1k count=1024Crie o recurso DRBD
r0:sudo drbdadm create-md r0Apresente o DRBD:
sudo drbdadm up r0Desative o DRBD quando o sistema for iniciado, permitindo que o software de gestão de recursos do cluster inicie todos os serviços necessários pela seguinte ordem:
sudo update-rc.d drbd disable
Inicie a replicação DRBD da base de dados1 para a base de dados2
- Ligue-se à instância
database1através de SSH. Substituir todos os recursos
r0no nó principal:sudo drbdadm -- --overwrite-data-of-peer primary r0 sudo mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/drbd0Valide o estado do DRBD:
sudo cat /proc/drbd | grep ============O resultado tem o seguinte aspeto:
[===================>] sync'ed:100.0% (208/307188)M
Montar
/dev/drbdem/srv:sudo mount -o discard,defaults /dev/drbd0 /srv
Instalar o MySQL e o Pacemaker
Nesta secção, instala o MySQL e o Pacemaker em cada instância.
Instale o MySQL em database1
- Ligue-se à instância
database1através de SSH. Atualize o repositório APT com as definições do pacote MySQL 5.6:
sudo bash -c 'cat <<EOF > /etc/apt/sources.list.d/mysql.list deb http://repo.mysql.com/apt/debian/ stretch mysql-5.6\ndeb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.6 EOF'Adicione as chaves GPG ao ficheiro APT
repository.srv:wget -O /tmp/RPM-GPG-KEY-mysql https://repo.mysql.com/RPM-GPG-KEY-mysql sudo apt-key add /tmp/RPM-GPG-KEY-mysqlAtualize a lista de pacotes:
sudo apt updateInstale o servidor MySQL:
sudo apt -y install mysql-serverQuando lhe for pedida uma palavra-passe, introduza
DRBDha2.Pare o servidor MySQL:
sudo /etc/init.d/mysql stopCrie o ficheiro de configuração do MySQL:
sudo bash -c 'cat <<EOF > /etc/mysql/mysql.conf.d/my.cnf [mysqld] bind-address = 0.0.0.0 # You may want to listen at localhost at the beginning datadir = /var/lib/mysql tmpdir = /srv/tmp user = mysql EOF'Crie um diretório temporário para o servidor MySQL (configurado em
mysql.conf):sudo mkdir /srv/tmp sudo chmod 1777 /srv/tmpMova todos os dados do MySQL para o diretório DRBD
/srv/mysql:sudo mv /var/lib/mysql /srv/mysqlAssocie
/var/lib/mysqla/srv/mysqlno volume de armazenamento replicado do DRBD:sudo ln -s /srv/mysql /var/lib/mysqlAltere o proprietário de
/srv/mysqlpara um processo demysql:sudo chown -R mysql:mysql /srv/mysqlRemova os
InnoDBdados iniciais para garantir que o disco está o mais limpo possível:sudo bash -c "cd /srv/mysql && rm ibdata1 && rm ib_logfile*"O InnoDB é um motor de armazenamento para o sistema de gestão de bases de dados MySQL.
Iniciar MySQL:
sudo /etc/init.d/mysql startConceda acesso ao utilizador root para ligações remotas de modo a testar a implementação mais tarde:
mysql -uroot -pDRBDha2 -e "GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'DRBDha2' WITH GRANT OPTION;"Desative o arranque automático do MySQL, que a gestão de recursos do cluster cuida:
sudo update-rc.d -f mysql disable
Instale o Pacemaker na base de dados1
Carregue as variáveis de metadados do ficheiro
.varsrcque criou anteriormente:source ~/.varsrcPare o servidor MySQL:
sudo /etc/init.d/mysql stopInstale o Pacemaker:
sudo apt -y install pcsAtive
pcsd,corosyncepacemakerno início do sistema na instância principal:sudo update-rc.d -f pcsd enable sudo update-rc.d -f corosync enable sudo update-rc.d -f pacemaker enableConfigure
corosyncpara começar antes depacemaker:sudo update-rc.d corosync defaults 20 20 sudo update-rc.d pacemaker defaults 30 10Defina a palavra-passe do utilizador do cluster como
haCLUSTER3para autenticação:sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"Execute o script
corosync-keygenpara gerar uma chave de autorização de cluster de 128 bits e escrevê-la em/etc/corosync/authkey:sudo corosync-keygen -lCopie
authkeypara a instânciadatabase2. Quando lhe for pedida uma frase secreta, primaEnter:sudo chmod 444 /etc/corosync/authkey gcloud beta compute scp /etc/corosync/authkey ${DATABASE2_INSTANCE_NAME}:~/authkey --zone=${DATABASE2_INSTANCE_ZONE} --internal-ip sudo chmod 400 /etc/corosync/authkeyCrie um ficheiro de configuração do cluster Corosync:
sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE1_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum two_node: 1 } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"A secção
totemconfigura o protocolo Totem para uma comunicação fiável. O Corosync usa esta comunicação para controlar a associação ao cluster e especifica como os membros do cluster devem comunicar entre si.As definições importantes na configuração são as seguintes:
transport: especifica o modo de transmissão única (udpu).Bindnetaddr: especifica o endereço de rede ao qual o Corosync está associado.nodelist: define os nós no cluster e como podem ser alcançados. Neste caso, os nósdatabase1edatabase2.quorum/two_node: por predefinição, num cluster de dois nós, nenhum nó adquire um quórum. Pode substituir esta opção especificando o valor "1" paratwo_nodena secçãoquorum.
Esta configuração permite-lhe configurar o cluster e prepará-lo para mais tarde, quando adicionar um terceiro nó que será um dispositivo de quórum.
Crie o diretório de serviços para
corosync:sudo mkdir -p /etc/corosync/service.dConfigure o
corosyncpara ter em atenção o Pacemaker:sudo bash -c 'cat <<EOF > /etc/corosync/service.d/pcmk service { name: pacemaker ver: 1 } EOF'Ative o serviço
corosyncpor predefinição:sudo bash -c 'cat <<EOF > /etc/default/corosync # Path to corosync.conf COROSYNC_MAIN_CONFIG_FILE=/etc/corosync/corosync.conf # Path to authfile COROSYNC_TOTEM_AUTHKEY_FILE=/etc/corosync/authkey # Enable service by default START=yes EOF'Reinicie os serviços
corosyncepacemaker:sudo service corosync restart sudo service pacemaker restartInstale o pacote do dispositivo de quorum do Corosync:
sudo apt -y install corosync-qdeviceInstale um script de shell para processar eventos de falha do DRBD:
sudo bash -c 'cat << 'EOF' > /var/lib/pacemaker/drbd_cleanup.sh #!/bin/sh if [ -z \$CRM_alert_version ]; then echo "\$0 must be run by Pacemaker version 1.1.15 or later" exit 0 fi tstamp="\$CRM_alert_timestamp: " case \$CRM_alert_kind in resource) if [ \${CRM_alert_interval} = "0" ]; then CRM_alert_interval="" else CRM_alert_interval=" (\${CRM_alert_interval})" fi if [ \${CRM_alert_target_rc} = "0" ]; then CRM_alert_target_rc="" else CRM_alert_target_rc=" (target: \${CRM_alert_target_rc})" fi case \${CRM_alert_desc} in Cancelled) ;; *) echo "\${tstamp}Resource operation "\${CRM_alert_task}\${CRM_alert_interval}" for "\${CRM_alert_rsc}" on "\${CRM_alert_node}": \${CRM_alert_desc}\${CRM_alert_target_rc}" >> "\${CRM_alert_recipient}" if [ "\${CRM_alert_task}" = "stop" ] && [ "\${CRM_alert_desc}" = "Timed Out" ]; then echo "Executing recovering..." >> "\${CRM_alert_recipient}" pcs resource cleanup \${CRM_alert_rsc} fi ;; esac ;; *) echo "\${tstamp}Unhandled \$CRM_alert_kind alert" >> "\${CRM_alert_recipient}" env | grep CRM_alert >> "\${CRM_alert_recipient}" ;; esac EOF' sudo chmod 0755 /var/lib/pacemaker/drbd_cleanup.sh sudo touch /var/log/pacemaker_drbd_file.log sudo chown hacluster:haclient /var/log/pacemaker_drbd_file.log
Instale o MySQL em database2
- Ligue-se à instância
database2através de SSH. Atualize o repositório APT com o pacote MySQL 5.6:
sudo bash -c 'cat <<EOF > /etc/apt/sources.list.d/mysql.list deb http://repo.mysql.com/apt/debian/ stretch mysql-5.6\ndeb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.6 EOF'Adicione as chaves GPG ao repositório APT:
wget -O /tmp/RPM-GPG-KEY-mysql https://repo.mysql.com/RPM-GPG-KEY-mysql sudo apt-key add /tmp/RPM-GPG-KEY-mysqlAtualize a lista de pacotes:
sudo apt updateInstale o servidor MySQL:
sudo apt -y install mysql-serverQuando lhe for pedida uma palavra-passe, introduza
DRBDha2.Pare o servidor MySQL:
sudo /etc/init.d/mysql stopCrie o ficheiro de configuração do MySQL:
sudo bash -c 'cat <<EOF > /etc/mysql/mysql.conf.d/my.cnf [mysqld] bind-address = 0.0.0.0 # You may want to listen at localhost at the beginning datadir = /var/lib/mysql tmpdir = /srv/tmp user = mysql EOF'Remova os dados em
/var/lib/mysqle adicione um link simbólico ao destino do ponto de montagem para o volume DRBD replicado. O volume DRBD (/dev/drbd0) vai ser montado em/srvapenas quando ocorrer uma comutação por falha.sudo rm -rf /var/lib/mysql sudo ln -s /srv/mysql /var/lib/mysqlDesative o arranque automático do MySQL, que a gestão de recursos do cluster cuida:
sudo update-rc.d -f mysql disable
Instale o Pacemaker na base de dados2
Carregue as variáveis de metadados do ficheiro
.varsrc:source ~/.varsrcInstale o Pacemaker:
sudo apt -y install pcsMova o ficheiro
authkeydo Corosync que copiou anteriormente para/etc/corosync/:sudo mv ~/authkey /etc/corosync/ sudo chown root: /etc/corosync/authkey sudo chmod 400 /etc/corosync/authkeyAtive
pcsd,corosyncepacemakerno início do sistema na instância em espera:sudo update-rc.d -f pcsd enable sudo update-rc.d -f corosync enable sudo update-rc.d -f pacemaker enableConfigure
corosyncpara começar antes depacemaker:sudo update-rc.d corosync defaults 20 20 sudo update-rc.d pacemaker defaults 30 10Defina a palavra-passe do utilizador do cluster para autenticação. A palavra-passe é a mesma (
haCLUSTER3) que usou para a instânciadatabase1.sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"Crie o ficheiro de configuração
corosync:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE2_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum two_node: 1 } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"Crie o diretório do serviço Corosync:
sudo mkdir /etc/corosync/service.dConfigure o
corosyncpara ter em atenção o Pacemaker:sudo bash -c 'cat <<EOF > /etc/corosync/service.d/pcmk service { name: pacemaker ver: 1 } EOF'Ative o serviço
corosyncpor predefinição:sudo bash -c 'cat <<EOF > /etc/default/corosync # Path to corosync.conf COROSYNC_MAIN_CONFIG_FILE=/etc/corosync/corosync.conf # Path to authfile COROSYNC_TOTEM_AUTHKEY_FILE=/etc/corosync/authkey # Enable service by default START=yes EOF'Reinicie os serviços
corosyncepacemaker:sudo service corosync restart sudo service pacemaker restartInstale o pacote do dispositivo de quorum do Corosync:
sudo apt -y install corosync-qdeviceInstale um script de shell para processar eventos de falha do DRBD:
sudo bash -c 'cat << 'EOF' > /var/lib/pacemaker/drbd_cleanup.sh #!/bin/sh if [ -z \$CRM_alert_version ]; then echo "\$0 must be run by Pacemaker version 1.1.15 or later" exit 0 fi tstamp="\$CRM_alert_timestamp: " case \$CRM_alert_kind in resource) if [ \${CRM_alert_interval} = "0" ]; then CRM_alert_interval="" else CRM_alert_interval=" (\${CRM_alert_interval})" fi if [ \${CRM_alert_target_rc} = "0" ]; then CRM_alert_target_rc="" else CRM_alert_target_rc=" (target: \${CRM_alert_target_rc})" fi case \${CRM_alert_desc} in Cancelled) ;; *) echo "\${tstamp}Resource operation "\${CRM_alert_task}\${CRM_alert_interval}" for "\${CRM_alert_rsc}" on "\${CRM_alert_node}": \${CRM_alert_desc}\${CRM_alert_target_rc}" >> "\${CRM_alert_recipient}" if [ "\${CRM_alert_task}" = "stop" ] && [ "\${CRM_alert_desc}" = "Timed Out" ]; then echo "Executing recovering..." >> "\${CRM_alert_recipient}" pcs resource cleanup \${CRM_alert_rsc} fi ;; esac ;; *) echo "\${tstamp}Unhandled \$CRM_alert_kind alert" >> "\${CRM_alert_recipient}" env | grep CRM_alert >> "\${CRM_alert_recipient}" ;; esac EOF' sudo chmod 0755 /var/lib/pacemaker/drbd_cleanup.sh sudo touch /var/log/pacemaker_drbd_file.log sudo chown hacluster:haclient /var/log/pacemaker_drbd_file.logVerifique o estado do cluster Corosync:
sudo corosync-cmapctl | grep "members...ip"O resultado tem o seguinte aspeto:
runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(10.140.0.2) runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(10.140.0.3)
Iniciar o cluster
- Ligue-se à instância
database2através de SSH. Carregue as variáveis de metadados do ficheiro
.varsrc:source ~/.varsrcAutentique-se nos nós do cluster:
sudo pcs cluster auth --name mysql_cluster ${DATABASE1_INSTANCE_NAME} ${DATABASE2_INSTANCE_NAME} -u hacluster -p haCLUSTER3Inicie o cluster:
sudo pcs cluster start --allValide o estado do cluster:
sudo pcs statusO resultado tem o seguinte aspeto:
Cluster name: mysql_cluster WARNING: no stonith devices and stonith-enabled is not false Stack: corosync Current DC: database2 (version 1.1.16-94ff4df) - partition with quorum Last updated: Sat Nov 3 07:24:53 2018 Last change: Sat Nov 3 07:17:17 2018 by hacluster via crmd on database2 2 nodes configured 0 resources configured Online: [ database1 database2 ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Configurar o Pacemaker para gerir recursos de cluster
Em seguida, configure o Pacemaker com os recursos DRBD, de disco, MySQL e de quorum.
- Ligue-se à instância
database1através de SSH. Use o utilitário
pcsdo Pacemaker para colocar várias alterações numa fila num ficheiro e, posteriormente, enviar essas alterações para a base de informações do cluster (CIB) de forma atómica:sudo pcs cluster cib clust_cfgDesative o STONITH, porque vai implementar o dispositivo de quorum mais tarde:
sudo pcs -f clust_cfg property set stonith-enabled=falseDesative as definições relacionadas com o quórum. Vai configurar o nó do dispositivo de quorum mais tarde.
sudo pcs -f clust_cfg property set no-quorum-policy=stopImpeça que o Pacemaker mova novamente os recursos após uma recuperação:
sudo pcs -f clust_cfg resource defaults resource-stickiness=200Crie o recurso DRBD no cluster:
sudo pcs -f clust_cfg resource create mysql_drbd ocf:linbit:drbd \ drbd_resource=r0 \ op monitor role=Master interval=110 timeout=30 \ op monitor role=Slave interval=120 timeout=30 \ op start timeout=120 \ op stop timeout=60Certifique-se de que apenas uma função principal está atribuída ao recurso DRBD:
sudo pcs -f clust_cfg resource master primary_mysql mysql_drbd \ master-max=1 master-node-max=1 \ clone-max=2 clone-node-max=1 \ notify=trueCrie o recurso do sistema de ficheiros para montar o disco DRBD:
sudo pcs -f clust_cfg resource create mystore_FS Filesystem \ device="/dev/drbd0" \ directory="/srv" \ fstype="ext4"Configure o cluster para colocar o recurso DRBD com o recurso de disco na mesma VM:
sudo pcs -f clust_cfg constraint colocation add mystore_FS with primary_mysql INFINITY with-rsc-role=MasterConfigure o cluster para apresentar o recurso de disco apenas depois de o DRBD primário ser promovido:
sudo pcs -f clust_cfg constraint order promote primary_mysql then start mystore_FSCrie um serviço MySQL:
sudo pcs -f clust_cfg resource create mysql_service ocf:heartbeat:mysql \ binary="/usr/bin/mysqld_safe" \ config="/etc/mysql/my.cnf" \ datadir="/var/lib/mysql" \ pid="/var/run/mysqld/mysql.pid" \ socket="/var/run/mysqld/mysql.sock" \ additional_parameters="--bind-address=0.0.0.0" \ op start timeout=60s \ op stop timeout=60s \ op monitor interval=20s timeout=30sConfigure o cluster para colocar o recurso MySQL juntamente com o recurso de disco na mesma VM:
sudo pcs -f clust_cfg constraint colocation add mysql_service with mystore_FS INFINITYCertifique-se de que o sistema de ficheiros DRBD precede o serviço MySQL na ordem de arranque:
sudo pcs -f clust_cfg constraint order mystore_FS then mysql_serviceCrie o agente de alerta e adicione o patch ao ficheiro de registo como destinatário:
sudo pcs -f clust_cfg alert create id=drbd_cleanup_file description="Monitor DRBD events and perform post cleanup" path=/var/lib/pacemaker/drbd_cleanup.sh sudo pcs -f clust_cfg alert recipient add drbd_cleanup_file id=logfile value=/var/log/pacemaker_drbd_file.logConfirme as alterações ao cluster:
sudo pcs cluster cib-push clust_cfgCertifique-se de que todos os recursos estão online:
sudo pcs statusO resultado tem o seguinte aspeto:
Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1
Configurar um dispositivo de quorum
- Ligue-se à instância
qdeviceatravés de SSH. Instale o
pcse ocorosync-qnetd:sudo apt update && sudo apt -y install pcs corosync-qnetdInicie o daemon do sistema de configuração do Pacemaker ou Corosync (
pcsd) e ative-o no início do sistema:sudo service pcsd start sudo update-rc.d pcsd enableDefina a palavra-passe do utilizador do cluster (
haCLUSTER3) para autenticação:sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"Verifique o estado do dispositivo de quorum:
sudo pcs qdevice status net --fullO resultado tem o seguinte aspeto:
QNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 0 Connected clusters: 0 Maximum send/receive size: 32768/32768 bytes
Configure as definições do dispositivo de quorum na base de dados1
- Ligue-se ao nó
database1através de SSH. Carregue as variáveis de metadados do ficheiro
.varsrc:source ~/.varsrcAutentique o nó do dispositivo de quorum para o cluster:
sudo pcs cluster auth --name mysql_cluster ${QUORUM_INSTANCE_NAME} -u hacluster -p haCLUSTER3Adicione o dispositivo de quorum ao cluster. Use o algoritmo
ffsplit, que garante que o nó ativo é decidido com base em 50% dos votos ou mais:sudo pcs quorum device add model net host=${QUORUM_INSTANCE_NAME} algorithm=ffsplitAdicione a definição de quórum a
corosync.conf:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE1_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum device { votes: 1 model: net net { tls: on host: ${QUORUM_INSTANCE_NAME} algorithm: ffsplit } } } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"Reinicie o serviço
corosyncpara recarregar a nova definição do dispositivo de quorum:sudo service corosync restartInicie o daemon do dispositivo de quorum
corosynce inicie-o no arranque do sistema:sudo service corosync-qdevice start sudo update-rc.d corosync-qdevice defaults
Configure as definições do dispositivo de quórum na base de dados2
- Ligue-se ao nó
database2através de SSH. Carregue as variáveis de metadados do ficheiro
.varsrc:source ~/.varsrcAdicione uma definição de quórum a
corosync.conf:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE2_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum device { votes: 1 model: net net { tls: on host: ${QUORUM_INSTANCE_NAME} algorithm: ffsplit } } } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"Reinicie o serviço
corosyncpara recarregar a nova definição do dispositivo de quorum:sudo service corosync restartInicie o daemon do dispositivo de quorum do Corosync e configure-o para o iniciar no arranque do sistema:
sudo service corosync-qdevice start sudo update-rc.d corosync-qdevice defaults
Validar o estado do cluster
O passo seguinte é verificar se os recursos do cluster estão online.
- Ligue-se à instância
database1através de SSH. Valide o estado do cluster:
sudo pcs statusO resultado tem o seguinte aspeto:
Cluster name: mysql_cluster Stack: corosync Current DC: database1 (version 1.1.16-94ff4df) - partition with quorum Last updated: Sun Nov 4 01:49:18 2018 Last change: Sat Nov 3 15:48:21 2018 by root via cibadmin on database1 2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledMostrar o estado do quórum:
sudo pcs quorum statusO resultado tem o seguinte aspeto:
Quorum information ------------------ Date: Sun Nov 4 01:48:25 2018 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/24 Quorate: Yes Votequorum information ---------------------- Expected votes: 3 Highest expected: 3 Total votes: 3 Quorum: 2 Flags: Quorate Qdevice Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 A,V,NMW database1 (local) 2 1 A,V,NMW database2 0 1 QdeviceMostrar o estado do dispositivo de quorum:
sudo pcs quorum device statusO resultado tem o seguinte aspeto:
Qdevice information ------------------- Model: Net Node ID: 1 Configured node list: 0 Node ID = 1 1 Node ID = 2 Membership node list: 1, 2 Qdevice-net information ---------------------- Cluster name: mysql_cluster QNetd host: qdevice:5403 Algorithm: Fifty-Fifty split Tie-breaker: Node with lowest node ID State: Connected
Configurar um balanceador de carga interno como o IP do cluster
Abra o Cloud Shell:
Crie um grupo de instâncias não gerido e adicione-lhe a instância
database1:gcloud compute instance-groups unmanaged create ${DATABASE1_INSTANCE_NAME}-instance-group \ --zone=${DATABASE1_INSTANCE_ZONE} \ --description="${DATABASE1_INSTANCE_NAME} unmanaged instance group" gcloud compute instance-groups unmanaged add-instances ${DATABASE1_INSTANCE_NAME}-instance-group \ --zone=${DATABASE1_INSTANCE_ZONE} \ --instances=${DATABASE1_INSTANCE_NAME}Crie um grupo de instâncias não gerido e adicione-lhe a instância
database2:gcloud compute instance-groups unmanaged create ${DATABASE2_INSTANCE_NAME}-instance-group \ --zone=${DATABASE2_INSTANCE_ZONE} \ --description="${DATABASE2_INSTANCE_NAME} unmanaged instance group" gcloud compute instance-groups unmanaged add-instances ${DATABASE2_INSTANCE_NAME}-instance-group \ --zone=${DATABASE2_INSTANCE_ZONE} \ --instances=${DATABASE2_INSTANCE_NAME}Crie uma verificação de funcionamento para
port 3306:gcloud compute health-checks create tcp mysql-backend-healthcheck \ --port 3306Crie um serviço de back-end interno regional:
gcloud compute backend-services create mysql-ilb \ --load-balancing-scheme internal \ --region ${CLUSTER_REGION} \ --health-checks mysql-backend-healthcheck \ --protocol tcpAdicione os dois grupos de instâncias como back-ends ao serviço de back-end:
gcloud compute backend-services add-backend mysql-ilb \ --instance-group ${DATABASE1_INSTANCE_NAME}-instance-group \ --instance-group-zone ${DATABASE1_INSTANCE_ZONE} \ --region ${CLUSTER_REGION} gcloud compute backend-services add-backend mysql-ilb \ --instance-group ${DATABASE2_INSTANCE_NAME}-instance-group \ --instance-group-zone ${DATABASE2_INSTANCE_ZONE} \ --region ${CLUSTER_REGION}Crie uma regra de encaminhamento para o balanceador de carga:
gcloud compute forwarding-rules create mysql-ilb-forwarding-rule \ --load-balancing-scheme internal \ --ports 3306 \ --network default \ --subnet default \ --region ${CLUSTER_REGION} \ --address ${ILB_IP} \ --backend-service mysql-ilbCrie uma regra de firewall para permitir uma verificação de funcionamento de um balanceador de carga interno:
gcloud compute firewall-rules create allow-ilb-healthcheck \ --direction=INGRESS --network=default \ --action=ALLOW --rules=tcp:3306 \ --source-ranges=130.211.0.0/22,35.191.0.0/16 --target-tags=mysqlPara verificar o estado do seu equilibrador de carga, aceda à página Equilíbrio de carga na consola do Google Cloud .
Clique em
mysql-ilb:
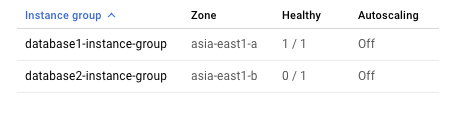
Uma vez que o cluster só permite que uma instância execute o MySQL em qualquer momento, apenas uma instância está em bom estado do ponto de vista do equilibrador de carga interno.
Estabelecer ligação ao cluster a partir do cliente MySQL
- Ligue-se à instância
mysql-clientatravés de SSH. Atualize as definições do pacote:
sudo apt-get updateInstale o cliente MySQL:
sudo apt-get install -y mysql-clientCrie um ficheiro de script que crie e preencha uma tabela com dados de amostra:
cat <<EOF > db_creation.sql CREATE DATABASE source_db; use source_db; CREATE TABLE source_table ( id BIGINT NOT NULL AUTO_INCREMENT, timestamp timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, event_data float DEFAULT NULL, PRIMARY KEY (id) ); DELIMITER $$ CREATE PROCEDURE simulate_data() BEGIN DECLARE i INT DEFAULT 0; WHILE i < 100 DO INSERT INTO source_table (event_data) VALUES (ROUND(RAND()*15000,2)); SET i = i + 1; END WHILE; END$$ DELIMITER ; CALL simulate_data() EOFCrie a tabela:
ILB_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/ILB_IP" -H "Metadata-Flavor: Google") mysql -u root -pDRBDha2 "-h${ILB_IP}" < db_creation.sql
Testar o cluster
Para testar a capacidade de HA do cluster implementado, pode realizar os seguintes testes:
- Encerre a instância
database1para testar se a base de dados principal consegue fazer a ativação pós-falha para a instânciadatabase2. - Inicie a instância
database1para ver sedatabase1consegue voltar a juntar-se ao cluster com êxito. - Encerre a instância
database2para testar se a base de dados principal consegue fazer a ativação pós-falha para a instânciadatabase1. - Inicie a instância
database2para ver sedatabase2consegue voltar a juntar-se ao cluster com êxito e se a instânciadatabase1continua a ter a função principal. - Crie uma partição de rede entre
database1edatabase2para simular um problema de divisão cerebral.
Abra o Cloud Shell:
Parar a instância
database1:gcloud compute instances stop ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE}Verifique o estado do cluster:
gcloud compute ssh ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE} \ --command="sudo pcs status"O resultado tem o seguinte aspeto. Verifique se as alterações de configuração que fez foram aplicadas:
2 nodes configured 4 resources configured Online: [ database2 ] OFFLINE: [ database1 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database2 ] Stopped: [ database1 ] mystore_FS (ocf::heartbeat:Filesystem): Started database2 mysql_service (ocf::heartbeat:mysql): Started database2 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledInicie a instância
database1:gcloud compute instances start ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE}Verifique o estado do cluster:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"O resultado tem o seguinte aspeto:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database2 ] Slaves: [ database1 ] mystore_FS (ocf::heartbeat:Filesystem): Started database2 mysql_service (ocf::heartbeat:mysql): Started database2 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledParar a instância
database2:gcloud compute instances stop ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE}Verifique o estado do cluster:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"O resultado tem o seguinte aspeto:
2 nodes configured 4 resources configured Online: [ database1 ] OFFLINE: [ database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Stopped: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledInicie a instância
database2:gcloud compute instances start ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE}Verifique o estado do cluster:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"O resultado tem o seguinte aspeto:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledCrie uma partição de rede entre
database1edatabase2:gcloud compute firewall-rules create block-comms \ --description="no MySQL communications" \ --action=DENY \ --rules=all \ --source-tags=mysql \ --target-tags=mysql \ --priority=800Após alguns minutos, verifique o estado do cluster. Tenha em atenção que o nó
database1mantém a sua função principal, porque a política de quórum é o nó com o ID mais baixo primeiro em caso de partição de rede. Entretanto, o serviçodatabase2MySQL é interrompido. Este mecanismo de quórum evita o problema de divisão de cérebro quando ocorre a partição de rede.gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"O resultado tem o seguinte aspeto:
2 nodes configured 4 resources configured Online: [ database1 ] OFFLINE: [ database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Stopped: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1Elimine a regra de firewall de rede para remover a partição de rede. (Prima
Yquando lhe for pedido.)gcloud compute firewall-rules delete block-commsVerifique se o estado do cluster voltou ao normal:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"O resultado tem o seguinte aspeto:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1Ligue-se à instância
mysql-clientatravés de SSH.Na shell, consulte a tabela que criou anteriormente:
ILB_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/ILB_IP" -H "Metadata-Flavor: Google") mysql -uroot "-h${ILB_IP}" -pDRBDha2 -e "select * from source_db.source_table LIMIT 10"A saída deve apresentar 10 registos do seguinte formulário, validando a consistência dos dados no cluster:
+----+---------------------+------------+ | id | timestamp | event_data | +----+---------------------+------------+ | 1 | 2018-11-27 21:00:09 | 1279.06 | | 2 | 2018-11-27 21:00:09 | 4292.64 | | 3 | 2018-11-27 21:00:09 | 2626.01 | | 4 | 2018-11-27 21:00:09 | 252.13 | | 5 | 2018-11-27 21:00:09 | 8382.64 | | 6 | 2018-11-27 21:00:09 | 11156.8 | | 7 | 2018-11-27 21:00:09 | 636.1 | | 8 | 2018-11-27 21:00:09 | 14710.1 | | 9 | 2018-11-27 21:00:09 | 11642.1 | | 10 | 2018-11-27 21:00:09 | 14080.3 | +----+---------------------+------------+
Sequência de comutação por falha
Se o nó principal no cluster ficar inativo, a sequência de comutação por falha tem o seguinte aspeto:
- O dispositivo de quorum e o nó de espera perdem a conetividade com o nó principal.
- O dispositivo de quorum vota no nó de espera e o nó de espera vota em si próprio.
- O quórum é adquirido pelo nó de espera.
- O nó de espera é promovido a principal.
- O novo nó principal faz o seguinte:
- Promove o DRBD para principal
- Monta o disco de dados do MySQL a partir do DRBD
- Inicia o MySQL
- Fica em bom estado para o balanceador de carga
- O balanceador de carga começa a enviar tráfego para o novo nó principal.