Puoi monitorare metriche come l'utilizzo e la memoria GPU dalle tue istanze di macchine virtuali (VM) utilizzando Ops Agent, la soluzione di raccolta dati di telemetria consigliata da Google per Compute Engine. Con Ops Agent puoi gestire le VM GPU come segue:
- Visualizza l'integrità del tuo parco risorse di GPU NVIDIA con le nostre dashboard preconfigurate.
- Ottimizza i costi identificando le GPU sottoutilizzate e consolidando i workload.
- Pianifica la scalabilità osservando le tendenze per decidere quando espandere la capacità delle GPU o eseguire l'upgrade delle GPU esistenti.
- Utilizza le metriche di profilazione di NVIDIA Data Center GPU Manager (DCGM) per identificare i colli di bottiglia e i problemi di prestazioni delle GPU.
- Configura i gruppi di istanze gestite (MIG) per eseguire la scalabilità automatica delle risorse.
- Ricevi avvisi sulle metriche delle tue GPU NVIDIA.
Questo documento illustra le procedure per il monitoraggio delle GPU sulle VM Linux tramite Ops Agent. In alternativa, su GitHub è disponibile uno script per la generazione di report che può essere configurato anche per monitorare l'utilizzo della GPU sulle VM Linux. Visualizza lo script di monitoraggio compute-gpu-monitoring.
Questo script non è più sviluppato attivamente.
Per monitorare le GPU sulle VM Windows, consulta Monitoraggio delle prestazioni delle GPU (Windows).
Panoramica
Ops Agent, versione 2.38.0 o successive, può monitorare automaticamente la memoria utilizzata della GPU e i tassi di utilizzo della memoria GPU sulle VM Linux su cui è installato l'agente. Queste metriche, ottenute dalla NVIDIA Management Library (NVML), vengono monitorate per singola GPU e processo per qualsiasi processo che utilizza le GPU. Per visualizzare le metriche monitorate da Ops Agent, consulta Metriche Agent: gpu.
Puoi anche configurare l'integrazione di NVIDIA Data Center GPU Manager (DCGM) con Ops Agent. Questa integrazione consente a Ops Agent di monitorare le metriche utilizzando i contatori hardware sulla GPU. DCGM fornisce l'accesso alle metriche a livello di dispositivo GPU. Sono incluse le metriche su utilizzo dei blocchi del multiprocessore streaming (SM), occupazione SM, utilizzo della pipe SM, frequenza del traffico PCIe e frequenza del traffico NVLink. Per visualizzare le metriche monitorate da Ops Agent, consulta Metriche delle applicazioni di terze parti: NVIDIA Data Center GPU Manager (DCGM).
Per esaminare le metriche della GPU utilizzando Ops Agent, completa i seguenti passaggi:
- Su ogni VM, verifica di aver soddisfatto i requisiti.
- Su ogni VM, installa Ops Agent.
- (Facoltativo) Su ogni VM, configura l'integrazione di NVIDIA Data Center GPU Manager (DCGM).
- Esamina le metriche in Cloud Monitoring.
Limitazioni
- Ops Agent non monitora l'utilizzo della GPU nelle VM che utilizzano Container-Optimized OS.
Requisiti
In ogni VM, verifica che vengano soddisfatti i seguenti requisiti:
- Ogni VM deve avere GPU collegate.
- In ogni VM deve essere installato un driver GPU.
- Il sistema operativo e la versione di Linux per ogni VM devono supportare Ops Agent. Consulta l'elenco dei sistemi operativi Linux che supportano Ops Agent.
- Assicurati di disporre dell'accesso
sudoper ogni VM.
Installa Ops Agent
Per installare Ops Agent, completa i seguenti passaggi:
Se in precedenza utilizzavi lo
compute-gpu-monitoringscript di monitoraggio per monitorare l'utilizzo della GPU, disattiva il servizio prima di installare Ops Agent. Per disattivare lo script di monitoraggio, esegui questo comando:sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
Installa l'ultima versione di Ops Agent. Per istruzioni dettagliate, consulta Installazione di Ops Agent.
Dopo aver installato Ops Agent, se devi installare o fare l'upgrade dei driver della GPU utilizzando gli script di installazione forniti da Compute Engine, consulta la sezione Limitazioni.
Esamina le metriche NVML in Compute Engine
Puoi esaminare le metriche NVML raccolte da Ops Agent dalle schede Osservabilità per le istanze VM Linux di Compute Engine.
Per visualizzare le metriche di una singola VM, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Istanze VM.
Seleziona una VM per aprire la pagina Dettagli.
Fai clic sulla scheda Osservabilità per visualizzare le informazioni sulla VM.
Seleziona il filtro rapido GPU.
Per visualizzare le metriche di più VM, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Istanze VM.
Fai clic sulla scheda Osservabilità.
Seleziona il filtro rapido GPU.
(Facoltativo) Configura l'integrazione di NVIDIA Data Center GPU Manager (DCGM)
Ops Agent fornisce inoltre l'integrazione di NVIDIA Data Center GPU Manager (DCGM) per raccogliere le metriche GPU avanzate chiave, come utilizzo dei blocchi del multiprocessore streaming (SM) l'occupazione SM, l'utilizzo della pipe SM, la frequenza di traffico PCIe e la frequenza di traffico NVLink.
Queste metriche avanzate della GPU non vengono raccolte dai modelli NVIDIA P100 e P4.
Per istruzioni dettagliate su come configurare e utilizzare questa integrazione su ogni VM, consulta NVIDIA Data Center GPU Manager (DCGM).
Esamina le metriche DCGM in Cloud Monitoring
Nella console Google Cloud , vai alla pagina Monitoraggio > Dashboard.
Seleziona la scheda Libreria di esempi.
Nel campo Filtro, digita NVIDIA. Viene visualizzata la dashboard Panoramica del monitoraggio delle GPU NVIDIA (GCE e GKE).
Se hai configurato l'integrazione di NVIDIA Data Center GPU Manager (DCGM), viene visualizzata anche la dashboard Metriche DCGM avanzate per il monitoraggio delle GPU NVIDIA (solo GCE).
Per la dashboard richiesta, fai clic su Anteprima. Viene visualizzata la pagina Anteprima dashboard di esempio.
Nella pagina Anteprima dashboard di esempio, fai clic su Importa dashboard di esempio.
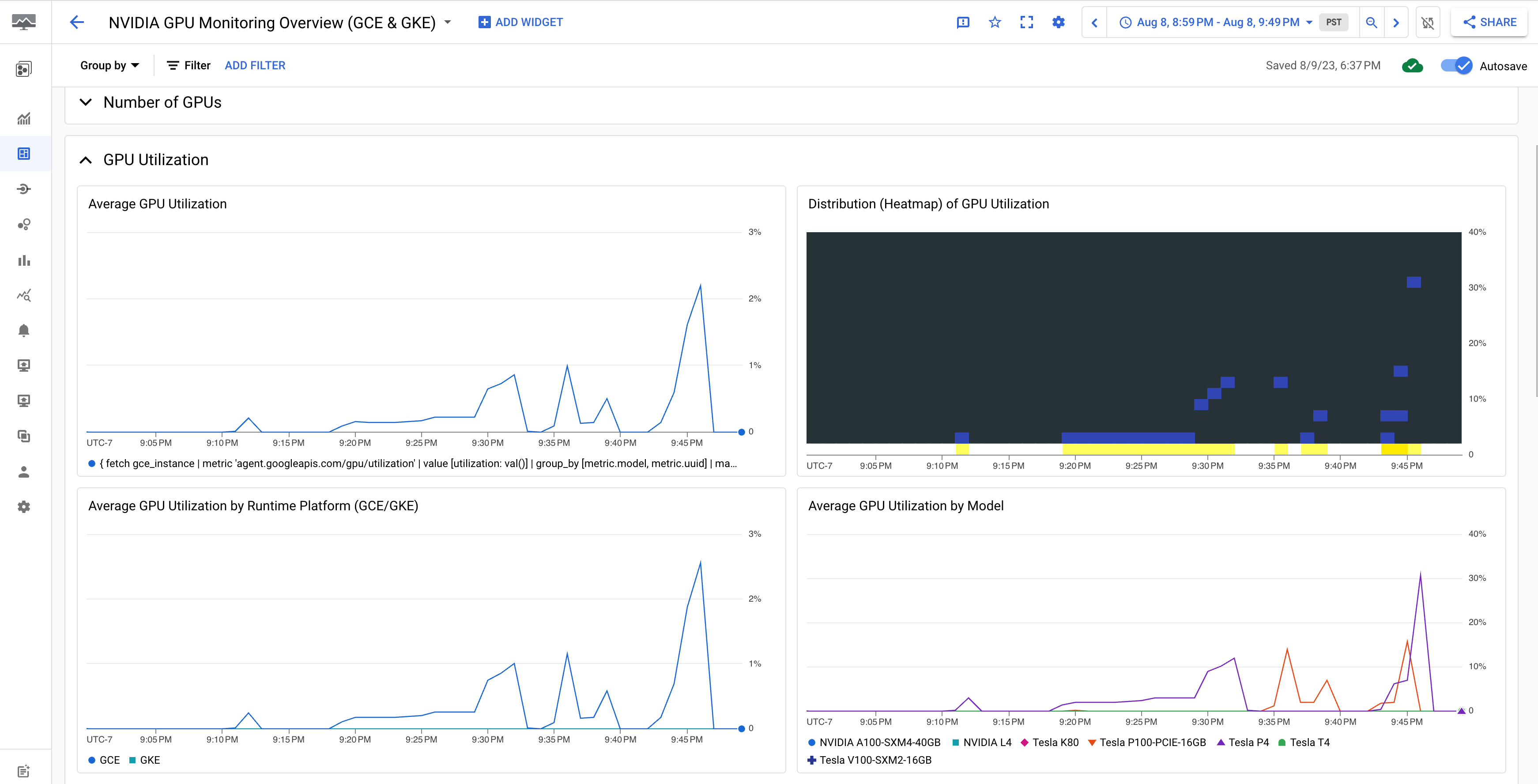
La dashboard Panoramica del monitoraggio delle GPU NVIDIA (GCE e GKE) mostra le metriche della GPU, come l'utilizzo della GPU, la frequenza del traffico NIC e l'utilizzo della memoria GPU.
La visualizzazione dell'utilizzo della GPU è simile al seguente output:
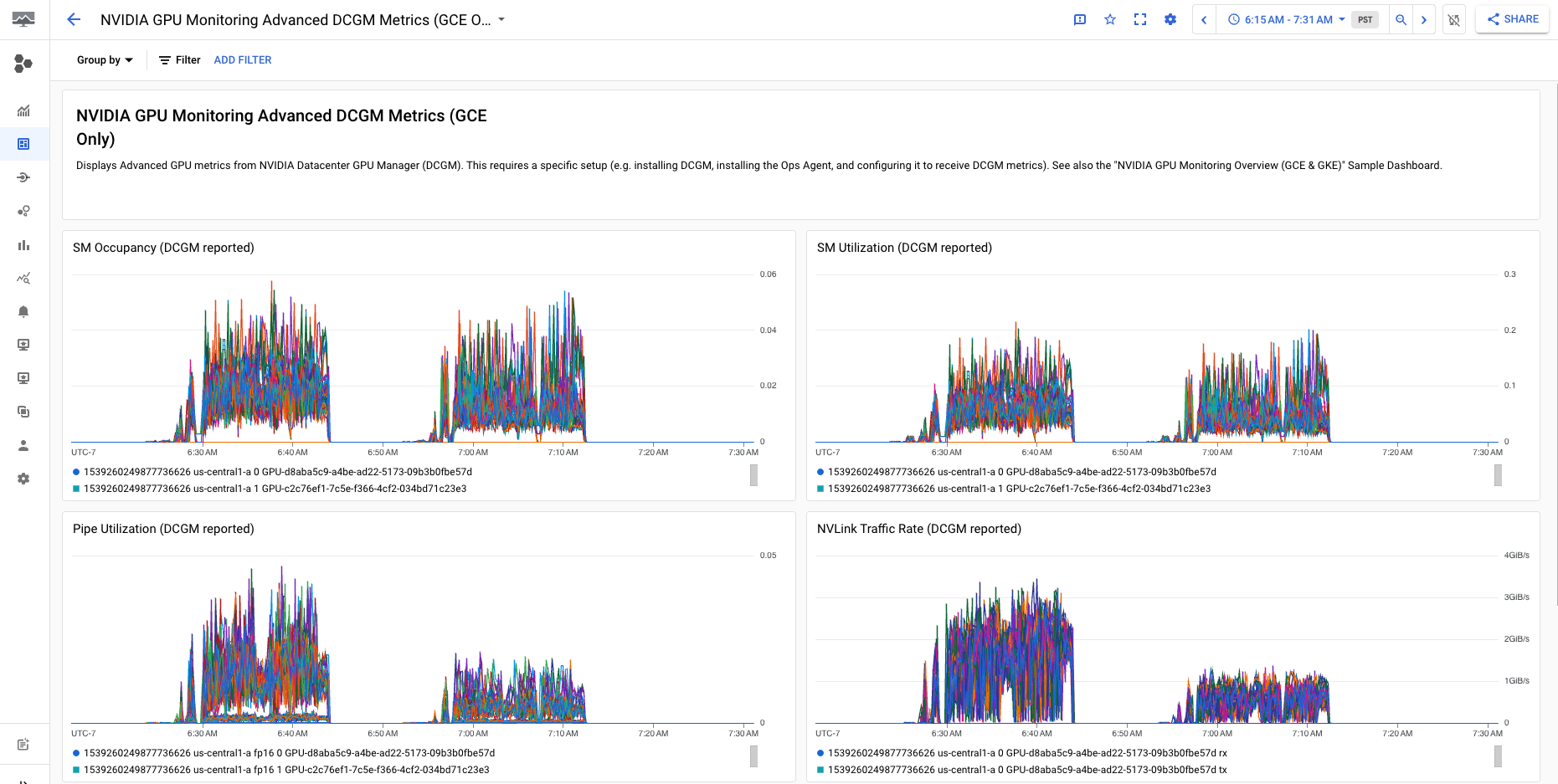
La dashboard Metriche DCGM avanzate per il monitoraggio delle GPU NVIDIA (solo GCE) mostra metriche avanzate chiave come utilizzo SM, occupazione SM, utilizzo della pipe SM, frequenza del traffico PCIe e frequenza del traffico NVLink.
La visualizzazione delle metriche DCGM avanzate è simile al seguente output:
Passaggi successivi
- Per gestire la manutenzione dell'host GPU, consulta Gestione degli eventi di manutenzione dell'host GPU.
- Per migliorare le prestazioni della rete, consulta Utilizza una larghezza di banda di rete superiore.