Per contribuire a un migliore utilizzo delle risorse, puoi monitorare il tasso di utilizzo della GPU delle tue istanze di macchine virtuali (VM).
Quando conosci i tassi di utilizzo delle GPU, puoi eseguire attività come la configurazione di gruppi di istanze gestite che possono essere utilizzati per scalare automaticamente le risorse.
Per esaminare le metriche della GPU utilizzando Cloud Monitoring, completa i seguenti passaggi:
- Su ogni VM, configura lo script per la generazione di report sulle metriche della GPU. Lo script installa l'agente per la generazione di report sulle metriche della GPU. L'agente viene eseguito a intervalli sulla VM per raccogliere i dati della GPU e li invia a Cloud Monitoring.
- Su ogni VM, esegui lo script.
- Su ogni VM, imposta l'agente per la generazione di report sulle metriche della GPU in modo che si avvii automaticamente insieme al sistema.
- Visualizza i log in Google Cloud Cloud Monitoring.
Ruoli obbligatori
Per monitorare le prestazioni della GPU sulle VM Windows, devi concedere i ruoli IAM (Identity and Access Management) richiesti ai seguenti principi:
- Il service account utilizzato dall'istanza VM.
- Il tuo account utente
Per assicurarti che tu e il service account della VM disponiate delle autorizzazioni necessarie per monitorare le prestazioni della GPU sulle VM Windows, chiedi all'amministratore di concedere a te e al service account della VM i seguenti ruoli IAM nel progetto:
-
Compute Instance Admin (v1) (
roles/compute.instanceAdmin.v1) -
Monitoring Metric Writer (
roles/monitoring.metricWriter)
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
L'amministratore potrebbe anche assegnare a te e al service account della VM le autorizzazioni richieste tramite ruoli personalizzati o altri ruoli predefiniti.
Configura lo script per la generazione di report sulle metriche GPU
Requisiti
In ogni VM, verifica che vengano soddisfatti i seguenti requisiti:
- Ogni VM deve avere GPU collegate.
- In ogni VM deve essere installato un driver GPU.
Scarica lo script
Apri un terminale PowerShell come amministratore e utilizza il
comando Invoke-WebRequest per scaricare lo script.
Invoke-WebRequest è disponibile su PowerShell 3.0 o versioni successive.
Google Cloud consiglia di utilizzare ctrl+v per incollare i blocchi di codice copiati.
mkdir c:\google-scripts cd c:\google-scripts Invoke-Webrequest -uri https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-monitoring/main/windows/gce-gpu-monitoring-cuda.ps1 -outfile gce-gpu-monitoring-cuda.ps1
Esegui lo script:
cd c:\google-scripts .\gce-gpu-monitoring-cuda.ps1
Configura l'agente in modo che si avvii automaticamente insieme al sistema
Per assicurarti che l'agente per la generazione di report sulle metriche GPU sia configurato in modo da iniziare l'esecuzione all'avvio del sistema, utilizza il seguente comando per aggiungerlo a Utilità di pianificazione di Windows.
$Trigger= New-ScheduledTaskTrigger -AtStartup $Trigger.ExecutionTimeLimit = "PT0S" $User= "NT AUTHORITY\SYSTEM" $Action= New-ScheduledTaskAction -Execute "PowerShell.exe" -Argument "C:\google-scripts\gce-gpu-monitoring-cuda.ps1" $settingsSet = New-ScheduledTaskSettingsSet # Set the Execution Time Limit to unlimited on all versions of Windows Server $settingsSet.ExecutionTimeLimit = 'PT0S' Register-ScheduledTask -TaskName "MonitoringGPUs" -Trigger $Trigger -User $User -Action $Action -Force -Settings $settingsSet
Esamina le metriche in Cloud Monitoring
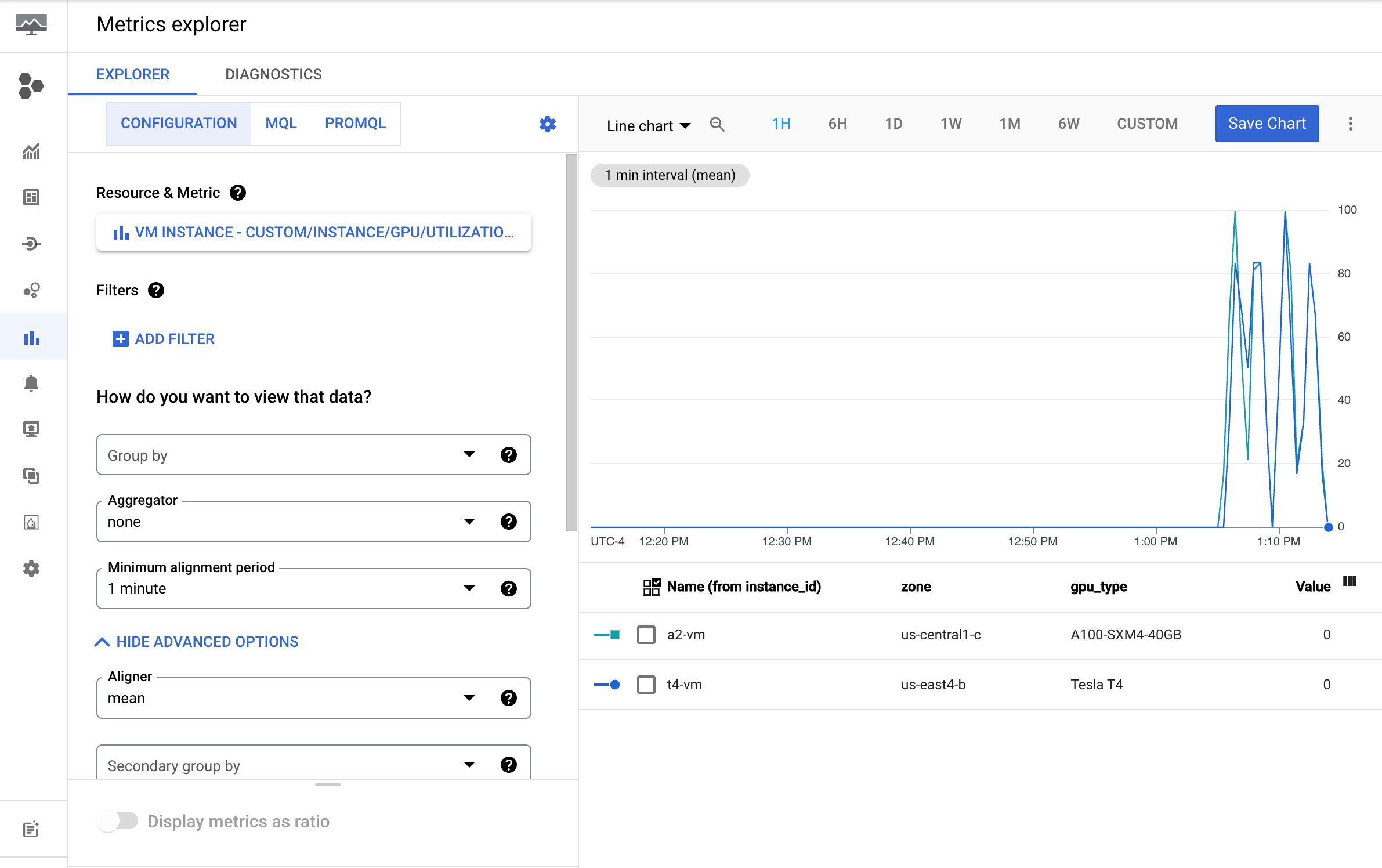
Nella console Google Cloud , vai alla pagina Esplora metriche.
Espandi il menu Seleziona una metrica.
Nel menu Risorsa, seleziona Istanza VM.
Nel menu Categoria metrica, seleziona Personalizzata.
Nel menu Metrica, seleziona la metrica da rappresentare nel grafico. Ad esempio:
custom/instance/gpu/utilization.Fai clic su Applica.
L'utilizzo della GPU dovrebbe essere simile al seguente output:
Metriche disponibili
| Nome metrica | Descrizione |
|---|---|
instance/gpu/utilization |
Percentuale di tempo nell'ultimo periodo di esempio durante il quale uno o più kernel sono stati eseguiti sulla GPU. |
instance/gpu/memory_utilization |
Percentuale di tempo nell'ultimo periodo di esempio in cui è stata letta o scritta la memoria globale (dispositivo). |
instance/gpu/memory_total |
Memoria GPU totale installata. |
instance/gpu/memory_used |
Memoria totale allocata dai contesti attivi. |
instance/gpu/memory_used_percent |
Percentuale di memoria totale allocata dai contesti attivi. Intervalli da 0 a 100. |
instance/gpu/memory_free |
Memoria libera totale. |
instance/gpu/temperature |
Temperatura del core della GPU in gradi Celsius (°C). |
Passaggi successivi
- Per gestire la manutenzione dell'host GPU, consulta Gestione degli eventi di manutenzione dell'host GPU.
- Per migliorare le prestazioni della rete, consulta Utilizza una larghezza di banda di rete superiore.