Para melhorar a utilização dos recursos, acompanhe as taxas de uso da GPU das instâncias de máquina virtual (VM).
Ao conhecer as taxas de uso da GPU, é possível executar tarefas, como configurar grupos de instâncias gerenciadas, que podem ser usadas para escalonar automaticamente os recursos.
Para revisar as métricas da GPU usando o Cloud Monitoring, siga estas etapas:
- Em cada VM, configure o script de relatório de métricas da GPU. Esse script instala o agente de relatório de métricas da GPU. Esse agente é executado em intervalos na instância para coletar dados da GPU e os enviar para o Cloud Monitoring.
- Em cada VM, execute o script.
- Em cada VM, defina o agente de relatório de métricas da GPU para iniciar automaticamente na inicialização.
- Veja os registros no Google Cloud Monitoring.
Funções exigidas
Para monitorar o desempenho da GPU em VMs do Windows, é necessário conceder os papéis necessários do Identity and Access Management (IAM) aos seguintes princípios:
- A conta de serviço usada pela instância de VM
- Sua conta de usuário
Para garantir que você e a conta de serviço da VM tenham as permissões necessárias para monitorar o desempenho da GPU em VMs do Windows, peça ao administrador para conceder a você e à conta de serviço da VM os seguintes papéis do IAM no projeto:
-
Administrador da instância da computação (v1) (
roles/compute.instanceAdmin.v1) -
Gravador de métricas do Monitoring ()
roles/monitoring.metricWriter
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
O administrador também pode conceder a você e à conta de serviço da VM as permissões necessárias por meio de papéis personalizados ou de outros papéis predefinidos.
Como configurar o script de relatório de métricas da GPU
Requisitos
Em cada uma das VMs, verifique se você atende aos requisitos a seguir:
- Cada VM precisa ter GPUs conectadas.
- Cada VM precisa ter um driver de GPU instalado.
Faça o download do script
Abra um terminal do PowerShell como administrador e use o
comando Invoke-WebRequest para fazer o download do script.
Invoke-WebRequest está disponível no PowerShell 3.0 ou posterior.
O Google Cloud recomenda o uso de ctrl+v para colar os blocos de código copiados.
mkdir c:\google-scripts cd c:\google-scripts Invoke-Webrequest -uri https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-monitoring/main/windows/gce-gpu-monitoring-cuda.ps1 -outfile gce-gpu-monitoring-cuda.ps1
Executar o script
cd c:\google-scripts .\gce-gpu-monitoring-cuda.ps1
Configurar o agente para iniciar automaticamente na inicialização
Para garantir que o agente do agente de relatórios de métricas da GPU esteja configurado para execução na inicialização do sistema, use o comando a seguir para adicionar o agente ao Programador de tarefas do Windows.
$Trigger= New-ScheduledTaskTrigger -AtStartup $Trigger.ExecutionTimeLimit = "PT0S" $User= "NT AUTHORITY\SYSTEM" $Action= New-ScheduledTaskAction -Execute "PowerShell.exe" -Argument "C:\google-scripts\gce-gpu-monitoring-cuda.ps1" $settingsSet = New-ScheduledTaskSettingsSet # Set the Execution Time Limit to unlimited on all versions of Windows Server $settingsSet.ExecutionTimeLimit = 'PT0S' Register-ScheduledTask -TaskName "MonitoringGPUs" -Trigger $Trigger -User $User -Action $Action -Force -Settings $settingsSet
Analisar métricas no Cloud Monitoring
No Console do Google Cloud, acesse a página do Metrics Explorer.
Abra o menu Selecionar uma métrica.
No menu Recurso, selecione Instância de VM.
No menu Categoria da métrica, selecione Personalizada.
No menu Métrica, selecione a métrica que deve aparecer no gráfico. Por exemplo:
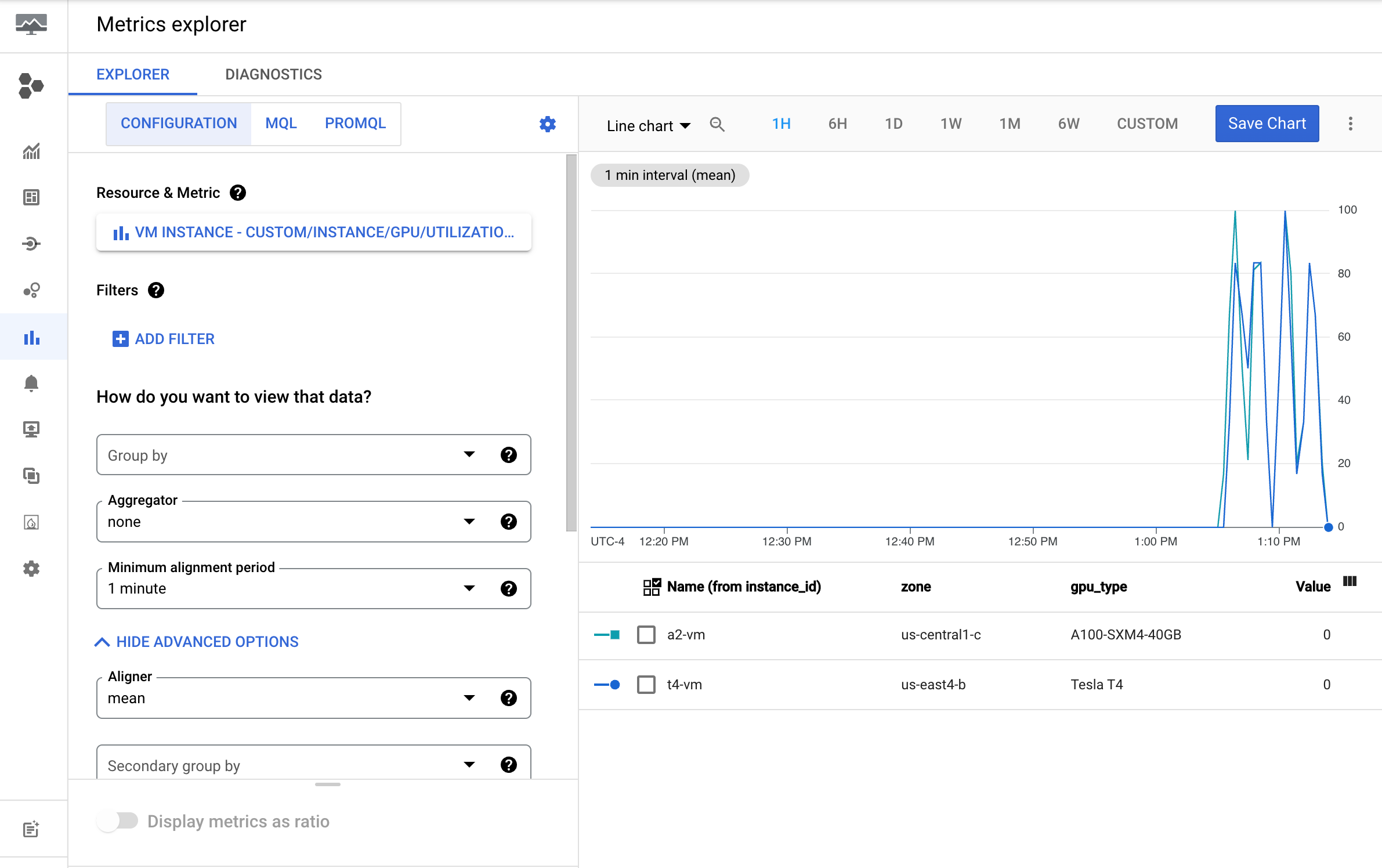
custom/instance/gpu/utilization.Clique em Aplicar.
Sua utilização de GPU será parecida com esta:
Métricas disponíveis
| Nome da métrica | Descrição |
|---|---|
instance/gpu/utilization |
Percentual de tempo durante o período de amostragem anterior em que um ou mais kernels estavam sendo executados na GPU. |
instance/gpu/memory_utilization |
Percentual de tempo durante o período de amostragem anterior em que a memória global (dispositivo) estava sendo lida ou gravada. |
instance/gpu/memory_total |
Memória total da GPU instalada. |
instance/gpu/memory_used |
Memória total alocada por contextos ativos. |
instance/gpu/memory_used_percent |
Porcentagem da memória total alocada por contextos ativos. Varia de 0 a 100. |
instance/gpu/memory_free |
Memória livre total. |
instance/gpu/temperature |
Temperatura da GPU principal em graus Celsius (°C). |
A seguir
- Para lidar com a manutenção do host da GPU, consulte "Como manipular eventos de manutenção do host da GPU".
- Para melhorar o desempenho da rede, consulte Usar uma largura de banda de rede maior.