Per aggiungere dischi alle VM, scegli una delle opzioni di archiviazione a blocchi offerte da Compute Engine. Ognuna delle opzioni di archiviazione riportate di seguito ha caratteristiche uniche in termini di prezzo e prestazioni:
- I volumi Google Cloud Hyperdisk sono archiviazione di rete per Compute Engine, con prestazioni configurabili e volumi che possono essere ridimensionati in modo dinamico. Offrono prestazioni, flessibilità ed efficienza notevolmente superiori rispetto ai Persistent Disk. Hyperdisk Balanced High Availability può replicare in modo sincrono i dati tra i dischi situati in due zone, offrendo protezione se una zona diventa non disponibile.
- I pool di archiviazione Hyperdisk ti consentono di acquistare la capacità e le prestazioni di Hyperdisk in modo aggregato, quindi di creare dischi per le tue VM da questo pool di archiviazione.
- I volumi di Persistent Disk forniscono archiviazione di rete redundante e ad alte prestazioni. Ogni volume del disco permanente è strutturato in strisce su centinaia di dischi fisici.
- Per impostazione predefinita, le VM utilizzano i dischi permanenti a livello di zona e archiviano i dati su volumi all'interno di un'unica zona, ad esempio
us-west1-c. - Puoi anche creare volumi di Persistent Disk geografica, che replicano in modo sincrono i dati tra i dischi situati in due zone e forniscono protezione se una zona non è disponibile.
- Per impostazione predefinita, le VM utilizzano i dischi permanenti a livello di zona e archiviano i dati su volumi all'interno di un'unica zona, ad esempio
- I dischi SSD locali sono unità fisiche collegate direttamente allo stesso server della VM. Possono offrire prestazioni migliori, ma sono effimere.
Per i confronti dei costi, consulta la pagina relativa ai prezzi dei dischi. Se non sai con sicurezza quale opzione utilizzare, per le serie di macchine di generazione precedente, la soluzione più comune è aggiungere un volume del disco permanente bilanciato alla VM e per le serie di macchine più recenti, aggiungere un volume Hyperdisk all'istanza di calcolo.
Oltre all'archiviazione a blocchi, Compute Engine offre opzioni di archiviazione di file e oggetti. Per esaminare e confrontare le opzioni di archiviazione, consulta Esaminare le opzioni di archiviazione.
Introduzione
Per impostazione predefinita, ogni VM Compute Engine ha un singolo disco di avvio che contiene il sistema operativo. I dati del disco di avvio vengono in genere archiviati su un volume Persistent Disk oHyperdisk bilanciato. Quando le tue applicazioni richiedono spazio di archiviazione aggiuntivo, puoi eseguire il provisioning di uno o più dei seguenti volumi di archiviazione nella tua VM.
Per scoprire di più su ciascuna opzione di archiviazione, consulta la seguente tabella:
| Disco permanente bilanciato |
Disco permanente SSD |
Disco permanente standard |
Disco permanente Extreme |
Hyperdisk bilanciato | Hyperdisk ML | Hyperdisk Extreme | Velocità effettiva Hyperdisk | SSD locali | |
|---|---|---|---|---|---|---|---|---|---|
| Tipo di archiviazione | Archiviazione a blocchi affidabile e conveniente | Archiviazione a blocchi rapida e affidabile | Archiviazione a blocchi efficiente e affidabile | Opzione di archiviazione a blocchi Persistent Disk con le massime prestazioni con IOPS personalizzabili | Prestazioni elevate per carichi di lavoro impegnativi a un costo inferiore | Spazio di archiviazione con velocità effettiva massima ottimizzato per i carichi di lavoro di machine learning. | L'opzione di archiviazione a blocchi più veloce con IOPS personalizzabili | Archiviazione a blocchi conveniente e orientata al throughput con throughput personalizzato | Archiviazione a blocchi locale ad alte prestazioni |
| Capacità minima per disco | A livello di zona: 10 GiB A livello di regione: 10 GiB |
A livello di zona: 10 GiB A livello di regione: 10 GiB |
A livello di zona: 10 GiB A livello di regione: 200 GiB |
500 GiB | A livello di zona e di regione: 4 GiB | 4 GiB | 64 GiB | 2 TiB | 375 GiB, 3 TiB con Z3 |
| Capacità massima per disco | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 32 TiB | 375 GiB, 3 TiB con Z3 |
| Incremento della capacità | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | Dipende dal tipo di macchina† |
| Capacità massima per VM | 257 TiB* | 257 TiB* | 257 TiB* | 257 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 36 TiB |
| Ambito di accesso | Zona | Zona | Zona | Zona | Zona | Zona | Zona | Zona | Istanza |
| Ridondanza dei dati | A livello di zona e multizonale | A livello di zona e multizonale | A livello di zona e multizonale | A livello di zona | A livello di zona e multizonale | A livello di zona | A livello di zona | A livello di zona | Nessuno |
| Crittografia dei dati inattivi | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| Chiavi di crittografia personalizzate | Sì | Sì | Sì | Sì | Sì‡ | Sì | Sì | Sì | No |
| Guida illustrativa | Aggiungi un disco permanente estremo | Aggiungere un'unità SSD locale | |||||||
Oltre alle opzioni di archiviazione fornite da Google Cloud, puoi implementare soluzioni di archiviazione alternative sulle tue VM.
- Crea un file server o un file system distribuito su Compute Engine da utilizzare come file system di rete con funzionalità NFSv3 e SMB3.
- Monta un disco RAM all'interno della memoria della VM per creare un volume di archiviazione a blocchi con un elevato throughput e una bassa latenza.
Le risorse di archiviazione a blocchi hanno caratteristiche di prestazioni diverse. Tieni conto delle dimensioni dello spazio di archiviazione e dei requisiti di prestazioni quando determini il tipo di archiviazione a blocchi corretto per le tue VM.
Per informazioni sui limiti delle prestazioni, consulta:
- Limiti di prestazioni dei dischi permanenti
- Limiti di prestazioni delle unità SSD locali
- Limiti di prestazioni di Hyperdisk
Persistent Disk
I volumi Persistent Disk sono dispositivi di archiviazione di rete durevoli a cui le tue istanze di macchine virtuali (VM) possono accedere come se si trattasse di dischi fisici su un computer desktop o un server. I dati su ciascun volume Persistent Disk sono distribuiti su più dischi fisici. Compute Engine gestisce i dischi fisici e la distribuzione dei dati per garantire ridondanza e prestazioni ottimali.
I volumi dei Persistent Disk si trovano in modo indipendente dalla VM, perciò puoi scollegarli o spostarli per conservare i dati anche dopo aver eliminato le VM. Le prestazioni dei Persistent Disk scalano in maniera automatica insieme alla dimensione, perciò puoi ridimensionare i volumi Persistent Disk esistenti o aggiungerne altri a una VM per soddisfare le tue esigenze di prestazioni e spazio di archiviazione.
Tipi di Persistent Disk
Quando configuri un disco permanente, puoi selezionare uno dei seguenti tipi di disco:
- Dischi permanenti bilanciati (
pd-balanced)- Un'alternativa ai dischi permanenti prestazionali (pd-ssd)
- Equilibrio tra prestazioni e costi. Per la maggior parte delle forme di VM, ad eccezione di quelle molto grandi, questi dischi hanno lo stesso numero massimo di IOPS per i dischi permanenti SSD e un numero inferiore di IOPS per GiB. Questo tipo di disco offre livelli di prestazioni adatti alla maggior parte delle applicazioni per uso generico a una tariffa massima compresa tra quella dei dischi permanenti standard e quella dei dischi permanenti prestazionali (pd-ssd).
- Supportato da unità a stato solido (SSD).
- Dischi permanenti prestazionali (SSD) (
pd-ssd)- Adatti per applicazioni aziendali e database ad alte prestazioni che richiedono una latenza inferiore e più IOPS rispetto a quelli forniti dai dischi permanenti standard.
- Supportato da unità a stato solido (SSD).
- Dischi permanenti standard (
pd-standard)- Adatti per carichi di lavoro di elaborazione dati di grandi dimensioni che utilizzano principalmente I/O sequenziali.
- Supportato da unità disco rigido (HDD) standard.
- Extreme Persistent Disk (
pd-extreme)- Offrono prestazioni costantemente elevate sia per carichi di lavoro ad accesso casuale che per velocità effettiva complessiva.
- Progettato per carichi di lavoro di database di fascia alta.
- Consente di eseguire il provisioning delle IOPS target.
- Supportato da unità a stato solido (SSD).
- Disponibile con un numero limitato di tipi di macchine.
Se crei un disco nella console Google Cloud, il tipo di disco predefinito è
pd-balanced. Se crei un disco utilizzando l'interfaccia a riga di comando gcloud o l'API Compute Engine, il tipo di disco predefinito è pd-standard.
Per informazioni sul supporto dei tipo di macchina, consulta quanto segue:
Resistenza di Persistent Disk
La durabilità del disco rappresenta la probabilità di perdita di dati, per impostazione predefinita, per un disco tipico in un anno tipico, utilizzando un insieme di ipotesi su guasti hardware, probabilità di eventi catastrofici, pratiche di isolamento e procedimenti di progettazione nei data center di Google e le codifiche interne utilizzate da ogni tipo di disco. Gli eventi di perdita di dati di Persistent Disk sono estremamente rari e storicamente sono stati il risultato di guasti hardware coordinati, bug software o una combinazione di entrambi. Google adotta inoltre molte misure per ridurre il risico a livello di settore della corruzione silenziosa dei dati. Un errore umano da parte di un cliente Google Cloud, ad esempio l'eliminazione accidentale di un disco, non rientra nell'ambito della durabilità di Persistent Disk.
Esiste un rischio molto ridotto di perdita di dati con un disco regionale permanente a causa della codifica e della replica dei dati interni. I dischi permanenti regionali forniscono il doppio delle repliche rispetto ai Persistent Disk zonali, con le repliche distribuite tra due zone nella stessa regione, quindi offrono alta disponibilità e possono essere utilizzati per il ripristino di emergenza se un intero data center viene perso e non può essere recuperato (anche se non è mai successo). È possibile accedere immediatamente alle repliche aggiuntive in una seconda zona se una zona principale non è disponibile durante un'interruzione prolungata.
La tabella seguente mostra la durata del design di ciascun tipo di disco. La durabilità del 99,999% significa che con 1000 dischi probabilmente passerebbero cento anni senza che ne venga perso uno.
| Persistent Disk standard a livello di zona | Persistent Disk bilanciato a livello di zona | Disco permanente SSD zonale | Persistent Disk con carico estremo a livello di zona | Persistent Disk standard regionale | Persistent Disk bilanciato a livello di regione | Disco permanente SSD a livello di regione |
|---|---|---|---|---|---|---|
| Migliore del 99,99% | Migliore del 99,999% | Migliore del 99,999% | Migliore del 99,9999% | Migliore del 99,999% | Migliore del 99,9999% | Migliore del 99,9999% |
Disco permanente a livello di zona
Facilità di utilizzo
Compute Engine gestisce per te la maggior parte delle attività di gestione dei dischi, in modo che non debba occuparti di partizionamento, array di dischi ridondanti o gestione di sottovolumi. In genere, non è necessario creare volumi logici più grandi, ma puoi estendere la capacità del Persistent Disk secondario collegato a 257 TiB per VM e applicare queste best practice ai volumi del Persistent Disk, se vuoi. Puoi risparmiare tempo e ottenere le migliori prestazioni se formatti i Persistent Disk permanente con un singolo file system e senza tabelle di partizione.
Se devi separare i dati in più volumi univoci, crea dischi aggiuntivi invece di suddividere i dischi esistenti in più partizioni.
Quando hai bisogno di spazio aggiuntivo sui volumi dei Persistent Disk, ridimensiona i dischi anziché ripartizionarli e formattarli.
Prestazioni
Le prestazioni di Persistent Disk sono prevedibili e aumentano in modo lineare con la capacità di cui è stato eseguito il provisioning fino a raggiungere i limiti delle vCPU di cui è stato eseguito il provisioning per una VM. Per ulteriori informazioni sull'ottimizzazione e sui limiti di scalabilità delle prestazioni, consulta Configurare i dischi per soddisfare i requisiti di prestazioni.
I volumi dei dischi permanenti standard sono efficienti ed economici per la gestione di operazioni di lettura/scrittura sequenziali, ma non sono ottimizzati per gestire alte velocità di operazioni di input/output casuali al secondo (IOPS). Se le tue app richiedono un numero elevato di IOPS casuali, utilizza Persistent Disk SSD o Extreme. Il disco permanente SSD è progettato per latenze in millisecondi a una sola cifra. La latenza osservata è specifica per l'applicazione.
Compute Engine ottimizza automaticamente le prestazioni e la scalabilità dei volumi su Persistent Disk. Non è necessario raggruppare più dischi o preriscaldarli per ottenere le migliori prestazioni. Quando hai bisogno di più spazio su disco o di prestazioni migliori, ridimensiona i dischi e, se necessario, aggiungi altre vCPU per aumentare lo spazio di archiviazione, la velocità effettiva e le IOPS. Le prestazioni di Persistent Disk si basano sulla capacità totale di Persistent Disk collegata a una VM e sul numero di vCPU della VM.
Per i dispositivi di avvio, puoi ridurre i costi utilizzando un Persistent Disk standard. Volumi Persistent Disk di piccole dimensioni da 10 GB possono essere utilizzati per casi d'uso di base di avvio e gestione dei pacchetti. Tuttavia, per garantire prestazioni coerenti per un uso più generale del dispositivo di avvio, utilizza un Persistent Disk con carico bilanciato come disco di avvio.
Ogni operazione di scrittura su disco permanente contribuisce al traffico in uscita della rete cumulativo della tua VM. Ciò significa che le operazioni di scrittura Persistent Disk sono limitate dal limite di uscita in rete per la tua VM.
Affidabilità
Persistent Disk hanno una ridondanza integrata per proteggere i dati da guasti dell'apparecchiatura e per garantire la disponibilità dei dati tramite eventi di manutenzione del datacenter. I checksum vengono calcolati per tutte le operazioni dei Persistent Disk, in modo da garantire che ciò che leggi sia ciò che hai scritto.
Inoltre, puoi creare snapshot del disco permanente per difenderti dalla perdita di dati a causa di errori dell'utente. Gli snapshot sono incrementali e la loro creazione richiede solo pochi minuti, anche se esegui snapshot dei dischi collegati a VM in esecuzione.
Modalità multiautore
Puoi collegare un disco permanente SSD in modalità multi-autore a un massimo di due VM N2 contemporaneamente in modo che entrambe le VM possano leggere e scrivere sul disco.
Persistent Disk in modalità multi-writer offre una funzionalità di archiviazione a blocchi condivisa e rappresenta una base infrastrutturale per la creazione di database e file system con elevata disponibilità. Questi file system e database specializzati devono essere progettati per funzionare con l'archiviazione a blocchi condivisa e gestire la coerenza della cache tra le VM utilizzando strumenti come le prenotazioni permanenti SCSI.
Tuttavia, in genere non è consigliabile utilizzare direttamente Persistent Disk con la modalità multi-autore e tieni presente che molti file system come EXT4, XFS e NTFS non sono progettati per essere utilizzati con lo spazio di archiviazione a blocchi condiviso. Per ulteriori informazioni sulle best practice per la condivisione di Persistent Disk tra VM, consulta la sezione Best practice.
Se hai bisogno di uno spazio di archiviazione file completamente gestito, puoi montare una condivisione file di Filestore sulle tue VM Compute Engine.
Per attivare la modalità multi-autore per i nuovi volumi del Persistent Disk, crea un nuovo Persistent Disk e specifica il flag --multi-writer nella gcloud CLI o la proprietà multiWriter nell'API Compute Engine. Per ulteriori informazioni, consulta
Condividere volumi dei dischi permanenti tra VM.
Crittografia di Persistent Disk
Compute Engine cripta automaticamente i dati prima che viaggino al di fuori della VM verso lo spazio di archiviazione su Persistent Disk. Ogni disco permanente rimane criptato con chiavi definite dal sistema o con chiavi fornite dal cliente. Google distribuisce i dati del Persistent Disk su più dischi fisici in un modo non controllato dagli utenti.
Quando elimini un volume Persistent Disk, Google elimina le chiavi di crittografia, rendendo i dati irrecuperabili. Questa operazione è irreversibile.
Se vuoi controllare le chiavi di crittografia utilizzate per criptare i tuoi dati, crea i tuoi dischi con le tue chiavi di crittografia.
Limitazioni
Non puoi collegare un volume Persistent Disk a una VM in un altro progetto.
Puoi collegare un Persistent Disk bilanciato a un massimo di 10 VM in modalità di sola lettura.
Per i tipi di macchine personalizzate o i tipi di macchine predefinite con un minimo di 1 vCPU, puoi collegare fino a 128 volumi di Persistent Disk.
Ogni volume del disco permanente può raggiungere una dimensione massima di 64 TiB; di conseguenza, non è necessario gestire array di dischi per creare volumi logici di grandi dimensioni. Ogni VM può collegare solo una quantità limitata di spazio totale del Persistent Disk e un numero limitato di singoli volumi del Persistent Disk. I tipi di macchine predefiniti e personalizzati hanno gli stessi limiti per i Persistent Disk.
La maggior parte delle VM può avere fino a 128 volumi di Persistent Disk e fino a 257 TiB di spazio su disco totale collegato. Lo spazio su disco totale di una VM include le dimensioni del disco di avvio.
I tipi di macchine con core condivisi sono limitati a 16 volumi di Persistent Disk e 3 TiB di spazio totale dei Persistent Disk.
La creazione di volumi logici di dimensioni superiori a 64 TiB potrebbe richiedere valutazioni particolari. Per ulteriori informazioni sul rendimento dei volumi logici di grandi dimensioni, consulta Dimensioni dei volumi logici.
Persistent Disk regionale
I volumi dei dischi permanenti a livello di regione hanno qualità di archiviazione simili ai Persistent Disk a livello di zona. Tuttavia, i volumi dei Persistent Disk a livello di regione forniscono archiviazione durevole e replica dei dati tra due zone nella stessa regione.
Informazioni sulla replica sincrona dei dischi
Quando crei un nuovo Persistent Disk, puoi crearlo in una zona o replicarlo in due zone all'interno della stessa regione.
Ad esempio, se crei un disco in una zona, ad esempio in us-west1-a, hai una copia del disco. Questo tipo di disco è chiamato disco a livello di zona.
Puoi aumentare la disponibilità del disco archiviando un'altra copia del disco in una zona diversa all'interno della regione, ad esempio in us-west1-b.
Persistent Disk replicati su due zone nella stessa regione sono chiamati Dischi permanenti a livello di regione. Puoi anche utilizzare Hyperdisk bilanciato con disponibilità elevata per la replica sincrona tra zone di Google Cloud Hyperdisk.
È improbabile che una regione non funzioni del tutto, ma possono verificarsi errori a livello di zona. La replica all'interno della regione in zone diverse, come mostrato nell'immagine seguente, migliora la disponibilità e riduce la latenza del disco. Se entrambe le zone di replica non funzionano, si tratta di un errore a livello di regione.
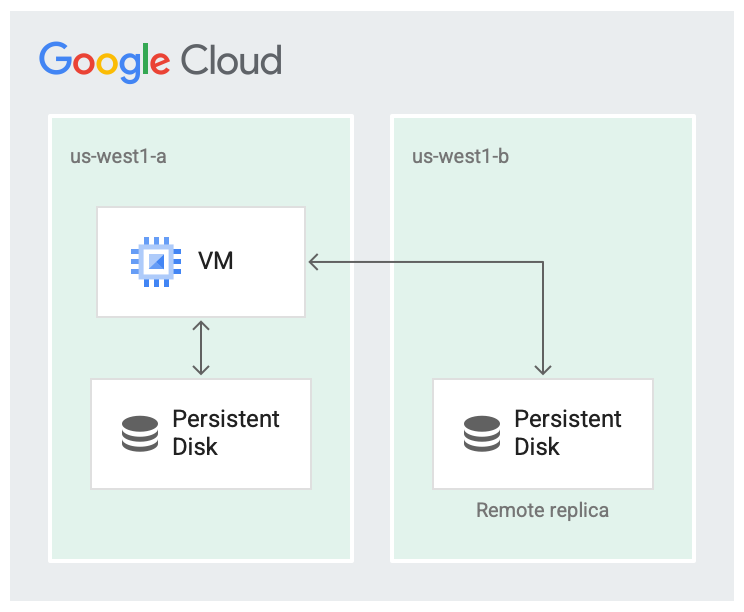
Il disco viene replicato in due zone.
Nello scenario di replica, i dati sono disponibili nella zona locale
(us-west1-a), ovvero la zona in cui è in esecuzione la macchina virtuale (VM). I dati vengono poi replicati in un'altra zona (us-west1-b). Una delle zone deve essere la stessa in cui è in esecuzione la VM.
Se si verifica un'interruzione del servizio a livello di zona, in genere puoi eseguire il failover del carico di lavoro in esecuzione su un disco permanente regionale in un'altra zona. Per saperne di più, consulta Failover dei dischi permanenti a livello di regione.
Considerazioni sul design per i dischi permanenti regionali
Se progetti sistemi robusti o servizi ad alta disponibilità su Compute Engine, utilizza i dischi permanenti regionali in combinazione con altre migliori pratiche come il backup dei dati mediante snapshot. I volumi dei dischi permanenti a livello di regione sono progettati anche per funzionare con gruppi di istanze gestite a livello di regione.
Prestazioni
I volumi dei dischi permanenti regionali sono progettati per i carichi di lavoro che richiedono un Recovery Point Objective (RPO) e un Recovery Time Objective (RTO) inferiori rispetto all'utilizzo degli snapshot dei Persistent Disk.
I dischi permanenti a livello di regione sono un'opzione quando le prestazioni di scrittura sono meno critiche rispetto alla ridondanza dei dati in più zone.
Come Persistent Disk a livello di zona, i dischi permanenti a livello di regione possono raggiungere un maggiore numero di IOPS e prestazioni in termini di velocità effettiva sulle VM con un numero maggiore di vCPU. Per ulteriori informazioni su questa e altre limitazioni, consulta Configurare i dischi per soddisfare i requisiti di prestazioni.
Quando hai bisogno di più spazio su disco o di prestazioni migliori, puoi ridimensionare i dischi regionali per aggiungere altro spazio di archiviazione, throughput e IOPS.
Affidabilità
Compute Engine esegue la replica dei dati del Persistent Disk regionale nelle zone selezionate al momento della creazione dei dischi. I dati di ogni replica sono distribuiti su più macchine fisiche all'interno della zona per garantire la ridondanza.
Come per i Persistent Disk a livello di zona, puoi creare snapshot dei dischi permanenti per difenderti dalla perdita di dati a causa di errori dell'utente. Gli snapshot sono incrementali e la loro creazione richiede solo pochi minuti, anche se esegui snapshot dei dischi collegati a VM in esecuzione.
Limitazioni
- Messico, Osaka e Montréal hanno tre zone in uno o due data center fisici. Poiché i dati archiviati in queste regioni possono andare persi nell'improbabile caso in cui i data center vengano distrutti, potresti prendere in considerazione il backup dei dati business-critical in una seconda regione per una protezione dei dati maggiore.
- È possibile collegare un disco permanente regionale solo alle macchine virtuali che utilizzano come machine family E2, N1, N2 e N2D.
- Puoi collegare Hyperdisk bilanciato con disponibilità elevata solo ai tipi di macchine supportati.
- Non puoi creare un Persistent Disk di una regione da un'immagine o da un disco creato da un'immagine.
- Quando utilizzi la modalità di sola lettura, puoi collegare un Persistent Disk bilanciato regionale a un massimo di 10 istanze VM.
- La dimensione minima di un Persistent Disk standard regionale è 200 GiB.
- Puoi solo aumentare le dimensioni di un disco Persistent Disk o volume Hyperdisk bilanciato ad alta disponibilità; non puoi ridurle.
- I volumi Hyperdisk e disco permanente regionale con disponibilità elevata bilanciata hanno caratteristiche di prestazioni diverse rispetto ai dischi zonali corrispondenti. Per ulteriori informazioni, consulta Rendimento dello spazio di archiviazione a blocchi.
- Non puoi utilizzare un volume Hyperdisk bilanciato con disponibilità elevata in modalità multi-writer come disco di avvio.
- Se crei un disco replicato clonando un disco a livello di zona, le due repliche a livello di zona non sono completamente sincronizzate al momento della creazione. Dopo la creazione, puoi utilizzare la copia del disco regionale in media entro 3 minuti. Tuttavia, potresti dover attendere decine di minuti prima che il disco raggiunga uno stato di replica completa e il Recovery Point Objective (RPO) sia vicino allo zero. Scopri come verificare se il disco replicato è completamente replicato.
Google Cloud Hyperdisk
Google Cloud Hyperdisk è l'archiviazione a blocchi di nuova generazione di Google. Scaricando e scalando dinamicamente l'elaborazione dello spazio di archiviazione, disaccoppia le prestazioni dello spazio di archiviazione dal tipo e dalle dimensioni della VM. Hyperdisk offre prestazioni, flessibilità ed efficienza notevolmente superiori rispetto a Persistent Disk.
Hyperdisk bilanciato
Hyperdisk Balanced per Compute Engine è adatto a una vasta gamma di casi d'uso, come applicazioni di business (LOB), applicazioni web e database di livello intermedio che non richiedono le prestazioni di Hyperdisk Extreme. Puoi anche utilizzare Hyperdisk Balanced per le applicazioni in cui più VM nella stessa zona richiedono contemporaneamente l'accesso in scrittura allo stesso disco.
I volumi Hyperdisk bilanciati ti consentono di ottimizzare dinamicamente la capacità, le IOPS e il throughput per i tuoi carichi di lavoro.
Hyperdisk ML
I carichi di lavoro che utilizzano gli acceleratori per addestrare o eseguire modelli di machine learning devono utilizzare Hyperdisk ML. I volumi Hyperdisk ML offrono il throughput personalizzabile più veloce e sono ideali per i modelli di dimensioni superiori a 20 GB. Hyperdisk ML supporta anche l'accesso simultaneo in lettura allo stesso volume da più VM.
Puoi ottimizzare dinamicamente la capacità e il throughput di un volume Hyperdisk ML.
Hyperdisk Extreme
Hyperdisk Extreme offre l'archiviazione a blocchi più rapida disponibile. È adatto per carichi di lavoro di fascia alta che richiedono la massima velocità effettiva e le IOPS più elevate.
I volumi Hyperdisk Extreme ti consentono di ottimizzare dinamicamente la capacità e gli IOPS per i tuoi carichi di lavoro.
Velocità effettiva Hyperdisk
La velocità effettiva Hyperdisk è adatta per le analisi dello scale out, tra cui Hadoop e Kafka, le unità di dati per app sensibili ai costi e l'archiviazione a freddo.
I volumi con velocità effettiva Hyperdisk ti consentono di ottimizzare dinamicamente la capacità e la velocità effettiva per i tuoi carichi di lavoro. Puoi modificare il livello di throughput provisionato senza tempi di inattività o interruzioni dei carichi di lavoro.
Hyperdisk bilanciato con disponibilità elevata
Hyperdisk bilanciato con disponibilità elevata consente la replica sincrona sulle serie di macchine di terza generazione o successive. La disponibilità elevata bilanciata Hyperdisk consente la resilienza dei dati con la replica RPO=0 in due zone, in modo simile al disco permanente regionale.
I volumi Hyperdisk bilanciati con disponibilità elevata ti consentono di ottimizzare dinamicamente la capacità, le IOPS e il throughput per i tuoi carichi di lavoro. Puoi modificare i livelli di prestazioni e capacità di cui è stato eseguito il provisioning senza tempi di inattività o interruzioni dei carichi di lavoro. Utilizza Hyperdisk bilanciato con disponibilità elevata quando diverse VM nella stessa regione richiedono contemporaneamente l'accesso in scrittura allo stesso disco.
I volumi Hyperdisk vengono creati e gestiti come Persistent Disk, con la possibilità aggiuntiva di impostare il livello di IOPS o di throughput di cui è stato eseguito il provisioning e di modificarlo in qualsiasi momento. Non esiste un percorso di migrazione diretto da Persistent Disk a Hyperdisk. In alternativa, puoi creare uno snapshot e recuperarlo in un nuovo volume Hyperdisk.
Per ulteriori informazioni su Hyperdisk, consulta la pagina Informazioni su Hyperdisk.
Durabilità di Hyperdisk
La durabilità del disco rappresenta la probabilità di perdita di dati, per progettazione, per un disco tipico in un anno tipico. La durabilità viene calcolata utilizzando un insieme di ipotesi sui guasti hardware, ad esempio:
- La probabilità di eventi catastrofici
- Pratiche di isolamento
- Processi di ingegneria nei data center di Google
- Le codifiche interne utilizzate da ciascun tipo di disco
Gli eventi di perdita di dati Hyperdisk sono estremamente rari. Google adotta inoltre molte misure per ridurre il rischio di corruzioni silenti dei dati a livello di settore.
Un errore umano da parte di un cliente Google Cloud, ad esempio l'eliminazione accidentale di un disco, non rientra nell'ambito della durabilità di Hyperdisk.
La tabella seguente mostra la durata del design di ciascun tipo di disco. La durabilità del 99,999% significa che con 1000 dischi probabilmente passerebbero cento anni senza che ne venga perso uno.
| Hyperdisk bilanciato | Hyperdisk Extreme | Hyperdisk ML | Velocità effettiva Hyperdisk |
|---|---|---|---|
| Migliore del 99,999% | Migliore del 99,9999% | Migliore del 99,999% | Migliore del 99,999% |
Crittografia Hyperdisk
Compute Engine cripta automaticamente i dati al momento della scrittura in un volume Hyperdisk. Puoi anche personalizzare la crittografia con le chiavi di crittografia gestite dal cliente.
Hyperdisk bilanciato con disponibilità elevata
I dischi Hyperdisk bilanciati con disponibilità elevata forniscono archiviazione durevole e replica dei dati tra due zone nella stessa regione. I volumi Hyperdisk bilanciato con disponibilità elevata hanno limiti di archiviazione simili ai dischi Hyperdisk bilanciato non replicati.
Se stai progettando sistemi robusti o servizi ad alta disponibilità su Compute Engine, utilizza i dischi Hyperdisk bilanciati ad alta disponibilità combinati con altre migliori pratiche come il backup dei dati utilizzando gli snapshot. I dischi Hyperdisk bilanciati con disponibilità elevata sono progettati anche per funzionare con gruppi di istanze gestite a livello di area geografica.
Nell'improbabile caso di un'interruzione del servizio a livello di zona, in genere puoi eseguire il failover del carico di lavoro in esecuzione su dischi Hyperdisk bilanciati con disponibilità elevata in un'altra zona utilizzando il flag --force-attach. Il flag --force-attach ti consente di collegare il disco Hyper-V con disponibilità elevata bilanciata a un'istanza di standby anche se il disco non può essere scollegato dall'istanza di calcolo originale a causa della sua non disponibilità. Per saperne di più, consulta
Failover dei dischi a livello di regione.
Prestazioni
I dischi Hyperdisk bilanciati con disponibilità elevata sono progettati per i carichi di lavoro che richiedono un Recovery Point Objective (RPO) e un Recovery Time Objective (RTO) inferiori rispetto all'utilizzo degli snapshot Hyperdisk per il recupero.
I dischi Hyperdisk bilanciati con disponibilità elevata sono un'opzione quando le prestazioni di scrittura sono meno critiche rispetto alla ridondanza dei dati in più zone.
I dischi Hyperdisk bilanciati con disponibilità elevata hanno prestazioni IOPS e throughput personalizzabili. Per ulteriori informazioni sulle prestazioni e sui limiti di Hyperdisk bilanciato con disponibilità elevata, consulta Informazioni su Hyperdisk.
Quando hai bisogno di più spazio su disco o di prestazioni migliori, puoi modificare i dischi Hyperdisk bilanciati con disponibilità elevata per aggiungere altro spazio di archiviazione, velocità effettiva e IOPS.
Affidabilità
Compute Engine esegue la replica dei dati dei dischi Hyperdisk con disponibilità elevata bilanciata nelle zone specificate al momento della creazione dei dischi. I dati di ogni replica sono distribuiti su più macchine fisiche all'interno della zona per garantire la ridondanza.
Come per Hyperdisk, puoi creare istantanee dei dischi Hyperdisk bilanciati con disponibilità elevata per difenderti dalla perdita di dati a causa di errori dell'utente. Gli snapshot sono incrementali e la loro creazione richiede solo pochi minuti, anche se esegui snapshot dei dischi collegati a VM in esecuzione.
Condivisione di volumi Hyperdisk tra VM
Per alcuni volumi Hyperdisk, puoi attivare l'accesso simultaneo al volume da più VM attivando la condivisione del disco. La condivisione dei dischi è utile per una serie di casi d'uso, ad esempio la creazione di applicazioni ad alta disponibilità o di carichi di lavoro di machine learning di grandi dimensioni in cui più VM devono accedere allo stesso modello o ai dati di addestramento.
Per ulteriori informazioni, consulta Condividere un disco tra VM.
Pool di archiviazione Hyperdisk
I pool di archiviazione Hyperdisk semplificano la riduzione del costo totale di proprietà (TCO) dell'archiviazione a blocchi e semplificano la gestione dell'archiviazione a blocchi. Con i pool di archiviazione Hyperdisk, puoi condividere un pool di capacità e prestazioni su un massimo di 1000 dischi in un singolo progetto. Poiché i pool di archiviazione offrono il thin provisioning e la riduzione dei dati, puoi ottenere un'efficienza maggiore. I pool di archiviazione semplificano la migrazione della SAN on-premise al cloud e semplificano anche la fornitura ai carichi di lavoro della capacità e delle prestazioni di cui hanno bisogno.
Creazione di un pool di archiviazione con la capacità e le prestazioni stimate per tutti i workload di un progetto in una zona specifica. Poi crei i dischi in questo pool di archiviazione e li colleghi alle VM esistenti. Puoi anche creare un disco nel pool di archiviazione durante la creazione di una nuova VM. Ogni pool di archiviazione contiene un tipo di disco, ad esempio Hyperdisk Throughput. Esistono due tipi di pool di archiviazione Hyperdisk:
- Pool di archiviazione Hyperdisk Balanced: per i carichi di lavoro generici gestiti al meglio dai dischi Hyperdisk Balanced
- Pool di archiviazione Hyperdisk Throughput: per i carichi di lavoro di streaming, dati non attivi e analisi che sono gestiti al meglio dai dischi Hyperdisk Throughput
Opzioni di provisioning della capacità
La capacità del pool di archiviazione Hyperdisk può essere sottoposta a provisioning in due modi:
- Provisioning della capacità standard
- Con il provisioning della capacità standard, crei dischi nel pool di archiviazione fino a quando le dimensioni totali di tutti i dischi non raggiungono la capacità di provisioning del pool di archiviazione. I dischi di un pool di archiviazione con provisioning della capacità standard consumano capacità in modo simile ai dischi non appartenenti al pool, dove la capacità viene consumata quando crei i dischi.
- Provisioning della capacità avanzata
Il provisioning avanzato della capacità ti consente di condividere un pool di capacità di archiviazione con thin provisioning e con dati ridotti su tutti i dischi di un pool di archiviazione. Ti viene addebitato il costo della capacità sottoposta a provisioning del pool di archiviazione.
Puoi eseguire il provisioning di fino al 500% della capacità di provisioning del pool di archiviazione su dischi in un pool di archiviazione con capacità avanzata. Solo la quantità di dati scritta su un disco nel pool di archiviazione ne consuma la capacità. La riduzione automatica dei dati può ridurre ulteriormente il consumo della capacità del pool di archiviazione.
Se l'utilizzo della capacità di un pool di archiviazione con capacità avanzata raggiunge l'80% della capacità di provisioning, i pool di archiviazione Hyperdisk tentano di aggiungere automaticamente capacità al pool di archiviazione per evitare errori correlati a una capacità insufficiente.
Esempio
Supponiamo che tu abbia un pool di archiviazione con 10 TiB di capacità di provisioning.
Con il provisioning della capacità standard:
- Puoi eseguire il provisioning di fino a 10 TiB di capacità Hyperdisk aggregata quando crei i dischi nel pool di archiviazione. Ti viene addebitato il costo per i 10 TiB di capacità del pool di archiviazione sottoposta a provisioning.
- Se crei un singolo disco nel pool di archiviazione di dimensioni pari a 5 TiB e scrivi 2 TiB sul disco, la capacità utilizzata del pool di archiviazione è pari a 5 TiB.
Con il provisioning della capacità avanzata:
- Puoi eseguire il provisioning di fino a 50 TiB di capacità Hyperdisk aggregata quando crei i dischi nel pool di archiviazione. Ti viene addebitato il costo per i 10 TiB di capacità del pool di archiviazione sottoposta a provisioning.
- Se crei un singolo disco nel pool di archiviazione di dimensioni pari a 5 TiB, scrivi 3 TiB di dati sul disco e la riduzione dei dati riduce la quantità di dati scritti a 2 TiB, la capacità utilizzata del pool di archiviazione è pari a 2 TiB.
Opzioni di provisioning delle prestazioni
Il provisioning delle prestazioni del pool di archiviazione Hyperdisk può essere eseguito in due modi:
- Provisioning prestazioni standard
Le prestazioni standard sono l'opzione migliore per i seguenti tipi di workload:
- Carichi di lavoro che non possono essere completati se le prestazioni sono limitate dalle risorse del pool di archiviazione
- Carichi di lavoro in cui è probabile che i dischi nel pool di archiviazione presentino picchi di prestazioni correlati, ad esempio dischi di dati per database che registrano un picco di utilizzo ogni mattina.
Il pool di archiviazione per le prestazioni standard non sfrutta il thin provisioning e non riduce in modo significativo il TCO per le prestazioni. Con il provisioning delle prestazioni standard, crei dischi nel pool di archiviazione finché le IOPS o il throughput totali di tutti i dischi non raggiungono l'importo riservato del pool di archiviazione. I dischi di un pool di archiviazione con provisioning delle prestazioni standard consumano IOPS e throughput in modo simile ai dischi non appartenenti a pool, in cui è possibile eseguire il provisioning della quantità di IOPS e throughput al momento della creazione dei dischi. Ti viene addebitato il costo delle IOPS e del throughput totali sottoposte a provisioning per il pool di archiviazione.
In un pool di archiviazione bilanciato Hyperdisk con prestazioni standard, i primi 3000 IOPS e 140 MiBps di throughput di ciascun disco nel pool di archiviazione (la quota di base) non consumano le risorse del pool di archiviazione. Quando crei dischi nel pool di archiviazione, eventuali IOPS e throughput superiori ai valori di riferimento consumeranno IOPS e throughput del pool di archiviazione.
I dischi creati in un pool di archiviazione con prestazioni standard non condividono le risorse per le prestazioni con il resto del pool di archiviazione. La quantità aggregata delle prestazioni di tutti i dischi nel pool di archiviazione non può superare le IOPS o il throughput totali di cui è stato eseguito il provisioning del pool di archiviazione.
- Provisioning delle prestazioni avanzate
I pool di archiviazione con provisioning per le prestazioni avanzate sfruttano il thin provisioning per aumentare l'efficienza delle prestazioni e ridurre il TCO delle prestazioni dell'archiviazione a blocchi. Il provisioning delle prestazioni avanzate ti consente di condividere un pool di prestazioni riservate su tutti i dischi di un pool di archiviazione. Il pool di archiviazione alloca dinamicamente le risorse di prestazioni man mano che i dischi nel pool leggono e scrivono dati. Solo la quantità di IOPS e throughput utilizzata da un disco nel pool di archiviazione consuma le IOPS e il throughput del pool di archiviazione. Poiché i pool di archiviazione con prestazioni avanzate sono sottoposti a provisioning a livello granulare, puoi allocare ai dischi del pool di archiviazione più IOPS o una velocità effettiva superiore a quella che hai eseguito per il pool di archiviazione, fino al 500% delle IOPS o della velocità effettiva sottoposte a provisioning per il pool di archiviazione. Come per le prestazioni standard, ti viene addebitato il costo delle IOPS e della velocità effettiva sottoposte a provisioning del pool di archiviazione.
In un pool di archiviazione Hyperdisk bilanciato con provisioning delle prestazioni avanzate, i dischi non hanno prestazioni di riferimento. Ogni operazione di lettura e scrittura di un disco Hyperdisk bilanciato nel pool di archiviazione consuma le risorse del pool.
Quando l'utilizzo aggregato delle prestazioni di tutti i dischi nel pool raggiunge la quantità totale di prestazioni di cui è stato eseguito il provisioning per il pool di archiviazione, i dischi possono affrontare un conflitto di prestazioni. Di conseguenza, il provisioning delle prestazioni avanzate è più adatto per i carichi di lavoro che non hanno orari di picco di utilizzo altamente correlati. Se tutti i picchi dei tuoi workload si verificano contemporaneamente, il pool di archiviazione ad alte prestazioni può raggiungere i limiti di prestazioni del pool di archiviazione, con conseguente competizione per le risorse di rendimento.
Se viene rilevata una contesa per le risorse di prestazioni in un pool di archiviazione con prestazioni avanzate per i dischi al suo interno, la funzionalità di crescita automatica tenta di aumentare automaticamente le IOPS o la velocità effettiva disponibili per i dischi nel pool di archiviazione per evitare problemi di prestazioni.
Esempio
Supponiamo che tu abbia un pool di archiviazione bilanciato Hyperdisk con 100.000 IOPS sottoposte a provisioning.
Con il provisioning delle prestazioni standard:
- Puoi eseguire il provisioning di un massimo di 100.000 IOPS aggregate quando crei dischi Hyperdisk bilanciati nel pool di archiviazione.
- Ti viene addebitato il costo delle 100.000 IOPS di prestazioni del pool di archiviazione bilanciato Hyperdisk sottoposto a provisioning.
Come i dischi creati al di fuori di un pool di archiviazione, i dischi Hyperdisk Balanced nei pool di archiviazione con prestazioni standard vengono sottoposti a provisioning automatico con fino a 3000 IOPS di base e 140 MiB/s di throughput di base. Questo rendimento di riferimento non viene conteggiato nel rendimento di cui è stato eseguito il provisioning per il pool di archiviazione. Solo quando aggiungi dischi al pool di archiviazione con prestazioni di cui è stato eseguito il provisioning superiori alla linea di base, queste vengono conteggiate ai fini del calcolo delle prestazioni di cui è stato eseguito il provisioning per il pool di archiviazione, ad esempio:
- Un disco sottoposto a provisioning con 3000 IOPS utilizza 0 IOPS del pool e il pool ha ancora 100.000 IOPS di provisioning disponibili per altri dischi.
- Un disco sottoposto a provisioning con 13.000 IOPS utilizza 10.000 IOPS del pool e il pool ha 90.000 IOPS di provisioning rimanenti che puoi allocare ad altri dischi nel pool di archiviazione.
Con il provisioning delle prestazioni avanzate:
- Puoi eseguire il provisioning di un massimo di 500.000 IOPS di prestazioni Hyperdisk aggregate quando crei i dischi nel pool di archiviazione.
- Ti vengono addebitate 100.000 IOPS sottoposte a provisioning dal pool di archiviazione.
- Se crei un singolo disco (
Disk1) nel pool di archiviazione con 5000 IOPS, non consumi alcuna IOPS dalle IOPS sottoposte a provisioning del pool di archiviazione. Tuttavia, la quantità di IOPS che puoi eseguire il provisioning per i nuovi dischi creati nel pool di archiviazione ora è pari a 495.000. - Se
Disk1inizia a leggere e scrivere dati e utilizza il massimo di 5000 IOPS in un determinato minuto, vengono consumate 5000 IOPS dalle IOPS sottoposte a provisioning del pool di archiviazione. Tutti gli altri dischi creati nello stesso pool di archiviazione possono utilizzare un massimo aggregato di 95.000 IOPS nello stesso minuto senza generare conflitti.
Modifica della capacità e delle prestazioni del pool dello spazio di archiviazione Hyperdisk sottoposto a provisioning
Puoi aumentare o diminuire la capacità, le IOPS e il throughput di cui è stato eseguito il provisioning per il pool di archiviazione man mano che i carichi di lavoro aumentano. Con un pool di archiviazione con capacità avanzata o prestazioni avanzate, qualsiasi capacità o prestazioni aggiuntive sono disponibili per tutti i dischi esistenti e nuovi nel pool di archiviazione. Inoltre, Compute Engine tenta di modificare automaticamente il pool di archiviazione come segue:
- Capacità avanzata: quando il pool di archiviazione raggiunge l'80% della capacità provisionata utilizzata, Compute Engine tenta di aggiungere automaticamente altra capacità al pool di archiviazione.
- Prestazioni avanzate: se il pool di archiviazione presenta una contesa prolungata a causa di un utilizzo eccessivo, Compute Engine tenta di aumentare le IOPS o la velocità effettiva del pool di archiviazione.
Ulteriori informazioni sul pool di archiviazione Hyperdisk
Per informazioni sull'utilizzo dei pool di archiviazione Hyperdisk, utilizza i seguenti link:
- Informazioni sui pool di archiviazione
- Creare pool di archiviazione
- Aggiungere dischi alle VM utilizzando un pool di archiviazione
- Gestire i pool di archiviazione
- Esaminare le metriche del pool di archiviazione
Dischi SSD locali
I dischi SSD locali sono collegati fisicamente al server che ospita la VM. I dischi SSD locali hanno una velocità effettiva superiore e una latenza inferiore rispetto ai Persistent Disk standard o ai dischi permanenti SSD. I dati archiviati su un disco SSD locale vengono mantenuti solo fino a quando la VM non viene arrestata o eliminata. Puoi collegare più dischi SSD locali alla VM, a seconda del numero di vCPU.
La dimensione di ogni disco SSD locale è fissa a 375 GiB, ad eccezione delle VM Z3 che utilizzano un disco SSD locale di 3 TiB. Per aumentare lo spazio di archiviazione, aggiungi più dischi SSD locali alla VM durante la creazione. Il numero massimo di dischi SSD locali che puoi collegare a una VM dipende dal tipo di macchina e dal numero di vCPU in uso.
Persistenza dei dati sui dischi SSD locali
Consulta la sezione Persistenza dei dati dell'SSD locale per scoprire quali eventi preservano i dati dell'SSD locale e quali possono causare la perdita dei dati dell'SSD locale.
SSD locali e tipi di macchine
Puoi collegare i dischi SSD locali alla maggior parte dei tipi di macchine disponibili su Compute Engine, come mostrato nella tabella Confronto delle serie di macchine. Tuttavia, esistono limitazioni al numero di dischi SSD locali che puoi collegare in base a ciascun tipo di macchina. Per saperne di più, consulta Scegliere un numero valido di dischi SSD locali.
Limiti di capacità con i dischi SSD locali
La capacità massima del disco SSD locale che puoi avere per una VM è:
| Tipo di macchina | Dimensioni del disco SSD locale | Numero di dischi | Capacità massima |
|---|---|---|---|
| Z3 | 3 TiB | 12 | 36 TiB |
c3d-standard-360-lssd |
375 GiB | 32 | 12 TiB |
c3d-highmem-360-lssd |
375 GiB | 32 | 12 TiB |
c3-standard-176-lssd |
375 GiB | 32 | 12 TiB |
| N1, N2 e N2D | 375 GiB | 24 | 9 TiB |
| N1, N2 e N2D | 375 GiB | 16 | 6 TiB |
| A3 | 375 GiB | 16 | 6 TiB |
| C2, C2D, A2 Standard, M1 e M3 | 375 GiB | 8 | 3 TiB |
| A2 Ultra | 375 GiB | 8 | 3 TiB |
Limitazioni dei dischi SSD locali
L'unità SSD locale presenta le seguenti limitazioni:
- Per raggiungere i limiti massimi di IOPS, utilizza una VM con almeno 32 vCPU.
- Le VM con tipi di macchina con core condivisi non possono collegare dischi SSD locali.
- Non puoi collegare dischi SSD locali ai tipi di macchine N4, H3, M2, E2 e Tau T2A.
- Non puoi utilizzare le chiavi di crittografia fornite dal cliente con i dischi SSD locali. Compute Engine cripta automaticamente i dati quando vengono scritti nello spazio di archiviazione SSD locale.
Prestazioni
I dischi SSD locali offrono IOPS molto elevati e bassa latenza. A differenza di Persistent Disk, devi gestire autonomamente lo striping sui dischi SSD locali.
Le prestazioni dell'unità SSD locale dipendono da diversi fattori. Per ulteriori informazioni, consulta Prestazioni delle SSD locali e Ottimizzazione delle prestazioni delle SSD locali.
Bucket Cloud Storage
I bucket Cloud Storage sono l'opzione di archiviazione più flessibile, scalabile e durevole per le tue VM. Se le tue app non richiedono la latenza inferiore di Hyperdisk, dischi permanenti, e SSD locali, puoi archiviare i tuoi dati in un bucket Cloud Storage.
Collega la VM a un bucket Cloud Storage quando la latenza e il throughput non sono una priorità e devi condividere facilmente i dati tra più VM o zone.
Proprietà dei bucket Cloud Storage
Consulta le sezioni seguenti per comprendere il comportamento e le caratteristiche degli bucket Cloud Storage.
Prestazioni
Le prestazioni dei bucket Cloud Storage dipendono dalla classe di archiviazione selezionata e dalla posizione del bucket rispetto alla VM.
L'utilizzo della classe di archiviazione standard di Cloud Storage nella stessa posizione della VM offre prestazioni paragonabili a quelle di Hyperdisk o Dischi permanenti , ma con una latenza più elevata e caratteristiche di throughput meno coerenti. L'utilizzo della classe di archiviazione Standard in una regione doppia archivia i dati in modo ridondante in due regioni. Per prestazioni ottimali quando utilizzi una doppia regione, le VM devono trovarsi in una delle regioni che fanno parte della doppia regione.
Le classi Nearline Storage, Coldline Storage e Archive Storage sono principalmente destinate all'archiviazione a lungo termine dei dati. A differenza della classe di archiviazione Standard, queste classi hanno durate minime di archiviazione e comportano costi di recupero dei dati. Di conseguenza, sono ideali per l'archiviazione a lungo termine dei dati a cui si accede raramente.
Affidabilità
Tutti i bucket Cloud Storage dispongono di ridondanza integrata per proteggere i dati da guasti dell'apparecchiatura e per garantire la disponibilità dei dati tramite eventi di manutenzione del data center. I checksum vengono calcolati per tutte le operazioni di Cloud Storage per garantire che ciò che leggi sia ciò che hai scritto.
Flessibilità
A differenza di Hyperdisk o Disco permanente, i bucket Cloud Storage non sono limitati alla zona in cui si trova la VM. Inoltre, puoi leggere e scrivere dati in un bucket da più VM contemporaneamente. Ad esempio, puoi configurare le VM in più zone in modo che leggano e scrivano i dati nello stesso secchio anziché replicare i dati in un Hyperdisk o dischi permanenti in più zone.
Crittografia di Cloud Storage
Compute Engine cripta automaticamente i dati prima che viaggino al di fuori della tua VM verso i bucket Cloud Storage. Non è necessario criptare i file sulle VM prima di scriverli in un bucket.
Come per i volumi dei Persistent Disk, puoi criptare i bucket con le tue chiavi di crittografia.Scrittura e lettura dei dati dai bucket Cloud Storage
Scrivi e leggi file dai bucket Cloud Storage utilizzando lo strumento a riga di comando gcloud storage o una libreria client di Cloud Storage.
gcloud storage
Per impostazione predefinita, lo strumento a riga di comando gcloud storage è installato sulla maggior parte delle VM che utilizzano immagini pubbliche.
Se la tua VM non dispone dello strumento a riga di comando gcloud storage, puoi installarlo.
Connettiti alle VM Linux o Connettiti alle VM Windows tramite SSH o un altro metodo di connessione.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.

Se non hai mai utilizzato
gcloud storagesu questa VM, usa la gcloud CLI per configurare le credenziali.gcloud init
In alternativa, se la VM è configurata per utilizzare un account di servizio con un ambito Cloud Storage, puoi saltare questo passaggio.
Utilizza lo strumento
gcloud storageper creare un bucket, scrivere dati nei bucket e leggere i dati da questi bucket. Per scrivere o leggere dati da un bucket specifico, devi disporre dell'accesso al bucket. Puoi leggere i dati da qualsiasi bucket accessibile pubblicamente.Se vuoi, puoi anche trasmettere i dati in streaming in Cloud Storage.
Libreria client
Se hai configurato la VM per utilizzare un account di servizio con un ambito Cloud Storage, puoi utilizzare l'API Cloud Storage per scrivere e leggere i dati dai bucket Cloud Storage.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.
Installa e configura una libreria client per il linguaggio che preferisci.
Se necessario, segui gli esempi di codice di inserimento per creare un bucket Cloud Storage sulla VM.
Segui gli esempi di codice di inserimento per scrivere dati e leggere dati e includi nella tua app il codice che scrive o legge un file da un bucket Cloud Storage.
Passaggi successivi
- Aggiungi un volume Hyperdisk alla tua VM.
- Aggiungi un volume su Persistent Disk alla tua VM.
- Aggiungi un disco regionale alla tua VM.
- Crea una VM con dischi SSD locali.
- Crea un file server o un file system distribuito.
- Esamina le quote per i dischi.
- Monta un disco RAM sulla VM.