如需向虚拟机添加磁盘,请选择 Compute Engine 提供的某种块存储选项。以下每种存储选项都具有不同的价格和性能特征:
- Google Cloud Hyperdisk 卷是 Compute Engine 的网络存储,具有可配置的性能和可动态调整大小的卷。与 Persistent Disk 相比,它们可提供明显更高的性能、灵活性和效率。 Hyperdisk Balanced 高可用性可以在两个可用区中的磁盘之间同步复制数据,以便在某个可用区不可用时提供保护。
- Hyperdisk 存储池使您能够以聚合方式购买的 Hyperdisk 容量和性能,然后从此存储池为虚拟机创建磁盘。
- Persistent Disk 卷提供高性能和冗余网络存储。每个 Persistent Disk 卷跨数百个物理磁盘条带化。
- 默认情况下,虚拟机使用可用区级 Persistent Disk,并将数据存储在单个可用区(例如
us-west1-c)内的卷上。 - 您还可以创建区域级 Persistent Disk 卷,以便在两个可用区中的磁盘之间同步复制数据,并在某个可用区不可用时提供保护。
- 默认情况下,虚拟机使用可用区级 Persistent Disk,并将数据存储在单个可用区(例如
- 本地 SSD 磁盘是直接挂接到与您的虚拟机相同的服务器的物理硬盘。它们可以提供更好的性能,但时间很短。
如需了解费用比较,请参阅磁盘价格。 如果您不确定使用哪个选项,对于早期代系的机器系列,最常见的解决方案是向虚拟机添加平衡永久性磁盘卷,对于最新机器系列,请向计算实例添加 Hyperdisk 卷。
除了块存储之外,Compute Engine 还提供文件和对象存储选项。如需查看和比较存储选项,请参阅查看存储选项。
简介
默认情况下,每个 Compute Engine 虚拟机都有一个包含操作系统的启动磁盘。启动磁盘数据通常存储在 Persistent Disk 或平衡 Balanced 卷上。当您的应用需要额外的存储空间时,您可以为虚拟机预配以下一个或多个存储卷。
如需详细了解每种存储方案,请参阅下表:
| 平衡 Persistent Disk |
SSD Persistent Disk |
标准 Persistent Disk |
极端 Persistent Disk |
平衡 Hyperdisk | Hyperdisk ML | Hyperdisk Extreme | Hyperdisk Throughput | 本地 SSD | |
|---|---|---|---|---|---|---|---|---|---|
| 存储类型 | 经济实惠、可靠的块存储 | 快速、可靠的块存储 | 高效、可靠的块存储 | 最高性能的 Persistent Disk 块存储选项,IOPS 可自定义 | 满足要求苛刻的工作负载的高性能,成本更低 | 吞吐量最高的存储空间,专为机器学习工作负载进行了优化。 | 具有可自定义的 IOPS 的最快块存储选项 | 经济实惠且以吞吐量为导向的块存储,吞吐量可自定义 | 高性能本地块存储 |
| 每个磁盘的最小容量 | 可用区级:10 GiB 区域级:10 GiB |
可用区级:10 GiB 区域级:10 GiB |
可用区级:10 GiB 区域级:200 GiB |
500 GiB | 可用区级和区域级:4 GiB | 4 GiB | 64 GiB | 2 TiB | 375 GiB、3 TiB(使用 Z3) |
| 每个磁盘的最大容量 | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 32 TiB | 375 GiB, 3 TiB(使用 Z3) |
| 容量增量 | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 取决于机器类型† |
| 每个虚拟机的容量上限 | 257 TiB* | 257 TiB* | 257 TiB* | 257 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 36 TiB |
| 访问范围 | 可用区 | 可用区 | 可用区 | 可用区 | 可用区 | 可用区 | 可用区 | 可用区 | 实例 |
| 数据冗余 | 可用区级和多可用区级 | 可用区级和多可用区级 | 可用区级和多可用区级 | 可用区级 | 可用区级和多可用区级 | 可用区级 | 可用区级 | 可用区级 | 无 |
| 静态加密 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 |
| 自定义加密密钥 | 是 | 是 | 是 | 是 | 是‡ | 是 | 是 | 是 | 否 |
| 操作方法 | 添加极端 Persistent Disk | 添加本地 SSD | |||||||
除了 Google Cloud 提供的存储选项外,您还可以在虚拟机上部署替代存储解决方案。
- 在 Compute Engine 上创建文件服务器或分布式文件系统,以充当具有 NFSv3 和 SMB3 功能的网络文件系统。
- 在虚拟机内存中装载 RAM 磁盘以创建具有高吞吐量和低延迟时间的块存储卷。
块存储资源具有不同的性能特征。在确定虚拟机的正确块存储类型时,请考虑您的存储大小和性能要求。
如需了解性能限制,请参阅:
Persistent Disk
Persistent Disk 卷是持久性网络存储设备,虚拟机 (VM) 实例可以像访问桌面设备或服务器中的物理磁盘一样访问它们。每个 Persistent Disk 卷上的数据分布在多个物理磁盘中。Compute Engine 为您管理物理磁盘和数据分布,以确保冗余和最佳性能。
Persistent Disk 卷的位置与虚拟机无关,因此即使在删除虚拟机后,您也可以分离或移动 Persistent Disk 卷以保留数据。Persistent Disk 性能会随大小自动调节,因此您可以调整现有 Persistent Disk 卷的大小或向虚拟机添加更多 Persistent Disk 卷,以满足您的性能和存储空间需求。
Persistent Disk 类型
配置永久性磁盘时,您可以选择以下某种磁盘类型:
- 均衡永久性磁盘 (
pd-balanced)- 性能 (pd-ssd) 永久性磁盘的替代方案
- 性能与费用的平衡。对于大多数虚拟机形式(非常大的磁盘类型除外),这些磁盘具有与 SSD 永久性磁盘相同的最大 IOPS,并且每 GiB 的 IOPS 更低。这种磁盘类型提供的性能适合大多数通用应用,价位介于标准永久性磁盘和性能 (pd-ssd) 永久性磁盘之间。
- 以固态硬盘 (SSD) 作为支持。
- 性能 (SSD) 永久性磁盘 (
pd-ssd)- 适用于需要比标准永久性磁盘更短延迟时间和更多 IOPS 的企业应用和高性能数据库。
- 以固态硬盘 (SSD) 作为支持。
- 标准永久性磁盘 (
pd-standard)- 适用于主要使用顺序 I/O 的大型数据处理工作负载。
- 以标准硬盘 (HDD) 作为支持。
- 极端永久性磁盘 (
pd-extreme)- 为随机访问工作负载和批量吞吐量提供始终如一的优越性能。
- 专为高端数据库工作负载而设计。
- 允许您预配目标 IOPS。
- 以固态硬盘 (SSD) 作为支持。
- 适用于有限数量的机器类型。
如果您在 Google Cloud 控制台中创建磁盘,则默认磁盘类型为 pd-balanced。如果您使用 gcloud CLI 或 Compute Engine API 创建磁盘,则默认磁盘类型为 pd-standard。
如需了解机器类型支持,请参阅以下内容:
Persistent Disk 的耐用性
磁盘耐用性通过一组关于硬件故障、灾难性事件的可能性、Google 数据中心的隔离实践和工程流程以及每种磁盘类型使用的内部编码的假设,来表示典型年份中典型磁盘的数据丢失概率。Persistent Disk 数据丢失事件非常罕见,且在记录中一直是由于协调硬件故障、软件错误或两者结合所造成的。Google 还采取了许多措施来降低业界范围的静默数据损坏风险。 Google Cloud 客户的人为错误(例如客户意外删除磁盘)不在 Persistent Disk 耐用性的支持范围内。
由于其内部数据编码和复制机制,区域级永久性磁盘发生数据丢失的风险极小。区域级 Persistent Disk 提供的副本数量是可用区级 Persistent Disk 数量的两倍,这些副本分布在同一区域内的两个可用区之间,因此可提供高可用性,并且如果整个数据中心丢失且无法恢复(虽然从未发生过这种情况),则可将其用于灾难恢复。如果主可用区在长时间服务中断期间不可用,则可立即访问第二个可用区中的副本。
下表显示了每种磁盘类型的设计耐用性。99.999% 的耐用性意味着,如果有 1,000 个磁盘,您可能一百年都不会丢失一个磁盘。
| 可用区级标准 Persistent Disk | 可用区级平衡 Persistent Disk | 可用区级 SSD Persistent Disk | 可用区级极端 Persistent Disk | 区域级标准 Persistent Disk | 区域级平衡 Persistent Disk | 区域级 SSD Persistent Disk |
|---|---|---|---|---|---|---|
| 高于 99.99% | 高于 99.999% | 高于 99.999% | 高于 99.9999% | 高于 99.999% | 高于 99.9999% | 高于 99.9999% |
可用区级 Persistent Disk
易用性
Compute Engine 可为您处理大多数磁盘管理任务,因此您无需处理分区、冗余磁盘阵列或子卷管理。通常,您不需要创建更大的逻辑卷,但是您可以将辅助挂接 Persistent Disk 的容量扩展到每个虚拟机 257 TiB,并根据需要将这些做法应用于 Persistent Disk 卷。 如果将 Persistent Disk 卷的格式设置为具有单个文件系统但无分区表,则可以节省时间并获得最佳性能。
如果需要将数据分别存储到多个唯一卷中,请创建额外磁盘,而不是将现有磁盘划分为多个分区。
当您在 Persistent Disk 卷上需要额外空间时,请调整磁盘大小,而不是重新分区和设置格式。
性能
Persistent Disk 性能是可预测的,可随预配容量线性调节,直到达到虚拟机的预配 vCPU 限制。如需详细了解性能调节限制和优化,请参阅配置磁盘以满足性能要求。
标准 Persistent Disk 卷可以经济高效地处理有序读写操作,但并不适合处理高速率的随机每秒输入/输出操作 (IOPS)。如果应用需要高速率的随机 IOPS,请使用 SSD 或极端 Persistent Disk。SSD Persistent Disk 的设计旨在确保将延迟时间控制在数毫秒以内。观察到的延迟时间因应用而异。
Compute Engine 会自动优化 Persistent Disk 卷的性能和扩缩功能。您无需为了获得最佳性能而绑定多个磁盘或预热磁盘。当您需要更多的磁盘可用空间或更优的性能时,可以调整磁盘大小和添加更多 vCPU,以添加更多存储空间、吞吐量和 IOPS。 Persistent Disk 的性能取决于挂接到虚拟机的 Persistent Disk 总容量和虚拟机具有的 vCPU 数。
对于启动设备,可使用标准 Persistent Disk 来降低费用。小型的 10 GiB Persistent Disk 卷适用于基本启动和软件包管理应用场景。不过,为了确保性能稳定,让启动设备得到更广泛的利用,请使用平衡 Persistent Disk 作为启动磁盘。
每个 Persistent Disk 写入操作都计入虚拟机的累积网络出站流量。这意味着 Persistent Disk 写入操作受到虚拟机的网络出站流量上限的限制。
可靠性
Persistent Disk 具有内置冗余,可保护您的数据免受设备故障的影响,并通过数据中心维护事件确保数据可用性。系统会针对所有 Persistent Disk 操作计算校验和,因此我们可以确保您所读取的内容就是您所写入的内容。
此外,您还可以创建 Persistent Disk 的快照,以防止因用户错误而导致数据丢失。它为增量快照,即使您对附加到正在运行的虚拟机的磁盘创建快照,也只需要几分钟时间。
多写入者模式
您能够以多写入者模式将 SSD Persistent Disk 同时挂接到两个 N2 虚拟机,以便两个虚拟机都能读写该磁盘。
多写入者模式下的 Persistent Disk 可提供共享块存储功能,并为构建高可用性共享文件系统和数据库奠定了基础架构基础。这些专用文件系统和数据库应设计为使用共享块存储,并使用 SCSI Persistent Reservations 等工具处理虚拟机之间的缓存连贯性。
但是,具有多写入者模式的 Persistent Disk 通常不应直接使用,并且请注意,许多文件系统(如 EXT4、XFS 和 NTFS)都不支持使用共享块存储。如需详细了解在虚拟机之间共享 Persistent Disk 的最佳实践,请参阅最佳实践。
如果您需要全托管式文件存储,可以在 Compute Engine 虚拟机上装载 Filestore 文件共享。
如需为新的 Persistent Disk 卷启用多写入者模式,请创建新的 Persistent Disk,并在 gcloud CLI 中指定 --multi-writer 标志或在 Compute Engine API 中指定 multiWriter 属性。如需了解详情,请参阅在虚拟机之间共享 Persistent Disk 卷。
Persistent Disk 加密
数据在虚拟机外部传输到 Persistent Disk 存储空间之前,Compute Engine 会自动加密数据。每个 Persistent Disk 都会使用系统定义的密钥或客户提供的密钥进行加密。 Google 以用户无法控制的方式在多个物理磁盘上分布 Persistent Disk 数据。
删除 Persistent Disk 卷时,Google 会舍弃加密密钥,导致数据无法恢复。此过程是不可逆转的。
如果要控制用于加密数据的加密密钥,请使用自己的加密密钥创建磁盘。
限制
您不能将 Persistent Disk 卷挂接到其他项目中的虚拟机。
在只读模式下,您最多可以将一个平衡永久性磁盘挂接到 10 个虚拟机。
对于具有至少 1 个 vCPU 的自定义机器类型或预定义机器类型,最多可以挂接 128 个 Persistent Disk 卷。
每个 Persistent Disk 卷的大小可达到 64 TiB,因此无需管理磁盘阵列即可创建大型逻辑卷。每个虚拟机只能挂接有限容量的总 Persistent Disk 空间和有限数量的单个 Persistent Disk 卷。预定义机器类型和自定义机器类型具有相同的 Persistent Disk 限制。
大多数虚拟机最多可以挂接 128 个 Persistent Disk 卷,最多可挂接 257 TiB 的总磁盘可用空间。虚拟机的总磁盘可用空间包括了启动磁盘的大小。
共享核心机器类型最多只能挂接 16 个 Persistent Disk 卷和 3 TiB 的总 Persistent Disk 空间。
创建大于 64 TiB 的逻辑卷可能需要注意一些特殊事项。如需详细了解较大的逻辑卷性能,请参阅逻辑卷大小。
区域级 Persistent Disk
区域级 Persistent Disk 卷的存储特性与可用区级 Persistent Disk 类似。但区域级 Persistent Disk 卷可在同一区域中的两个可用区之间提供持久耐用的数据存储和复制功能。
同步磁盘复制简介
在创建新的 Persistent Disk 时,您可以在一个可用区中创建磁盘,也可以在同一区域内的两个可用区之间复制磁盘。
例如,如果您在可用区(例如 us-west1-a)中创建一个磁盘,则您将获得该磁盘的一个副本。这称为可用区级磁盘。您可以通过将磁盘的另一个副本存储在区域内的不同可用区(例如 us-west1-b)中来提高磁盘的可用性。
在同一区域中的两个可用区之间复制的 Persistent Disk 称为区域级 Persistent Disk。您还可以使用 Hyperdisk Balanced 高可用性实现 Google Cloud Hyperdisk 的跨可用区同步复制。
一个区域不太可能全都发生故障,但可用区级故障可能会发生。 如下图所示,在区域内复制到不同可用区有助于提高可用性并缩短磁盘延迟时间。如果两个复制可用区都发生故障,则视为区域范围故障。
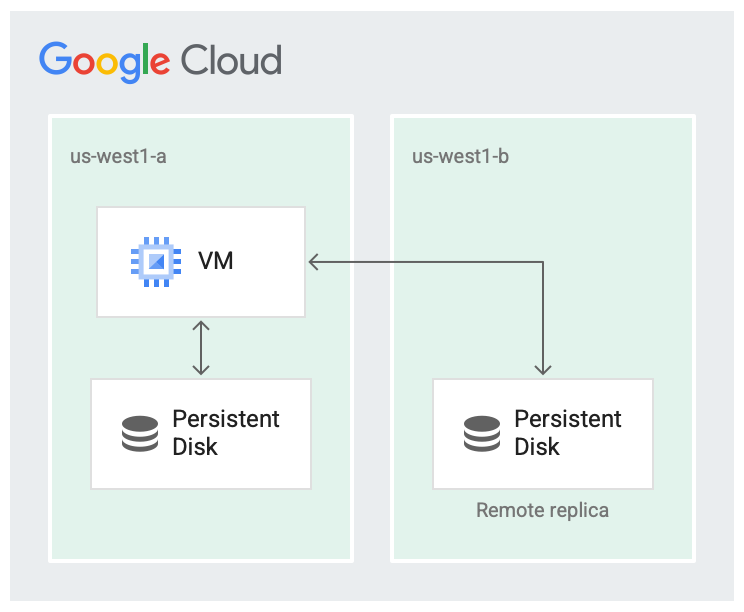
磁盘复制到两个可用区中。
在复制场景中,数据可在本地可用区 (us-west1-a) 中提供,该可用区是运行虚拟机 (VM) 的可用区。然后,数据会复制到另一个可用区 (us-west1-b)。其中一个可用区必须是运行虚拟机的相同可用区。
如果发生可用区级服务中断,您通常可以将区域级 Persistent Disk 上运行的工作负载故障切换到另一个可用区。如需了解详情,请参阅区域级 Persistent Disk 故障切换。
区域级 Persistent Disk 的设计注意事项
如果您要在 Compute Engine 上设计稳健可靠的系统或高可用性服务,请使用结合了其他最佳实践(例如使用快照备份数据)的区域级 Persistent Disk。区域级 Persistent Disk 卷也适用于区域级托管式实例组。
性能
与使用 Persistent Disk 快照相比,区域级 Persistent Disk 卷可用于需要更低恢复点目标 (RPO) 和恢复时间目标 (RTO) 的工作负载。
当多个可用区的数据冗余比写入性能更重要时,可选择区域级 Persistent Disk。
与可用区级 Persistent Disk 一样,区域级 Persistent Disk 可以在配备了更多 vCPU 的虚拟机上实现更高的 IOPS 和吞吐量性能。如需详细了解此限制和其他限制,请参阅配置磁盘以满足性能要求。
当您需要更多的磁盘可用空间或更优的性能时,可以调整区域磁盘大小以添加更多存储空间、吞吐量和 IOPS。
可靠性
Compute Engine 将区域级 Persistent Disk 的数据复制到创建磁盘时所选择的可用区。每个副本的数据分布在该可用区内的多个物理机器中,以确保冗余。
与可用区级 Persistent Disk 类似,您可以创建 Persistent Disk 的快照,以防止因用户错误而导致数据丢失。它为增量快照,即使您对附加到正在运行的虚拟机的磁盘创建快照,也只需要几分钟时间。
限制
- 墨西哥、大阪和蒙特利尔有三个可用区,位于一个或两个 物理数据中心内。 由于这些区域存储的数据可能会在数据中心遭到破坏的少见情况下丢失,您可能需要考虑将业务关键数据备份到第二个区域,以提高数据保护能力。
- 您只能将区域级永久性磁盘挂接到使用 E2、N1、N2 和 N2D 机器类型的虚拟机。
- 您只能将 Hyperdisk Balanced 高可用性挂接到支持的机器类型。
- 您无法通过映像或通过映像创建的磁盘创建区域级永久性磁盘。
- 使用只读模式时,您最多可以将一个区域级平衡永久性磁盘挂接到 10 个虚拟机实例。
- 区域级标准永久性磁盘的大小下限为 200 GiB。
- 您只能增加 区域级 Persistent Disk 或Hyperdisk Balanced 高可用性卷的大小;而无法减小其大小。
- 区域级 Persistent Disk 和 Hyperdisk Balanced 高可用性卷与其对应的可用区级磁盘具有不同的性能特征。如需了解详情,请参阅块存储性能。
- 您无法将处于多写入者模式的 Hyperdisk Balanced 高可用性卷用作启动磁盘。
- 如果您通过克隆可用区级磁盘来创建复制磁盘,则两个可用区级副本在创建时不会完全同步。创建后,您一般可以在 3 分钟内使用区域级磁盘克隆。不过,您可能需要等待几十分钟,磁盘才会完全复制,恢复点目标 (RPO) 才会接近于零。了解如何检查复制磁盘是否已完全复制。
Google Cloud Hyperdisk
Google Cloud Hyperdisk 是 Google 的新一代块存储产品。通过分流和动态扩容存储处理,它可以将存储性能与虚拟机类型和大小分离开来。与 Persistent Disk 相比,Hyperdisk 可显著提高性能、灵活性和效率。
平衡 Hyperdisk
适用于 Compute Engine 的 Hyperdisk Balanced 功能非常适合各种使用场景,例如业务线 (LOB) 应用、Web 应用和中层数据库,这些都不需要 Hyperdisk Extreme 的性能。 对于同一可用区中的多个虚拟机同时需要同一磁盘的写入权限的应用,您也可以使用 Hyperdisk Balanced。
平衡 Hyperdisk 卷可让您动态调整工作负载的容量、IOPS 和吞吐量。
Hyperdisk ML
使用加速器训练或应用机器学习模型的工作负载应使用 Hyperdisk ML。Hyperdisk ML 卷可提供最快的可自定义吞吐量,非常适合大于 20 GiB 的模型。Hyperdisk ML 还支持从多个虚拟机同时对同一卷进行读取访问。
您可以动态调整 Hyperdisk ML 卷的容量和吞吐量。
Hyperdisk Extreme
Hyperdisk Extreme 提供最快的块存储。它适用于需要最高吞吐量和 IOPS 的高端工作负载。
借助 Hyperdisk Extreme 卷,您可以动态地调整工作负载的容量和 IOPS。
Hyperdisk Throughput
Hyperdisk Throughput 非常适合横向扩容分析,包括 Hadoop 和 Kafka、费用敏感型应用的数据硬盘以及冷存储。
借助 Hyperdisk Throughput 卷,您可以针对工作负载动态调整容量和吞吐量。您可以更改预配的吞吐量级别,而无需停机或中断工作负载。
Hyperdisk Balanced 高可用性
Hyperdisk Balanced 高可用性可在第三代或更高版本的机器系列上实现同步复制。Hyperdisk Balanced 高可用性可跨两个可用区通过 RPO=0 复制实现数据弹性,类似于区域级 Persistent Disk。
借助 Hyperdisk Balanced 高可用性卷,您可以动态调整工作负载的容量、IOPS 和吞吐量。您可以更改预配的性能和容量级别,而无需停机或中断工作负载。 如果同一区域中的不同虚拟机同时需要对同一磁盘进行写入访问,请使用 Hyperdisk Balanced 高可用性。
Hyperdisk 卷的创建和管理方式与 Persistent Disk 类似,此外,您还可以设置预配的 IOPS 或吞吐量级别并随时更改该值。从 Persistent Disk 到 Hyperdisk 没有直接迁移路径。您可以改为创建快照并将快照还原到新的 Hyperdisk 卷。
如需详细了解 Hyperdisk,请参阅关于 Hyperdisk。
Hyperdisk 的耐用性
磁盘耐用性根据设计,表示典型磁盘在典型年份中丢失数据的概率。耐用性是使用一组关于硬件故障的假设计算得出,例如:
- 发生灾难性事件的可能性
- 隔离做法
- Google 数据中心的工程流程
- 每种磁盘类型使用的内部编码
Hyperdisk 数据丢失事件极其罕见。Google 还采取了许多措施来降低业界范围的静默数据损坏风险。
Google Cloud 客户的人为错误(例如客户意外删除磁盘)不在 Hyperdisk 耐用性的支持范围内。
下表显示了每种磁盘类型的设计耐用性。99.999% 的耐用性意味着,如果有 1,000 个磁盘,您可能一百年都不会丢失一个磁盘。
| 平衡 Hyperdisk | Hyperdisk Extreme | Hyperdisk ML | Hyperdisk Throughput |
|---|---|---|---|
| 高于 99.999% | 高于 99.9999% | 高于 99.999% | 高于 99.999% |
Hyperdisk 加密
Compute Engine 在写入 Hyperdisk 卷时会自动加密您的数据。您还可以使用客户管理的加密密钥来自定义加密。
Hyperdisk Balanced 高可用性
Hyperdisk Balanced 高可用性磁盘可在同一区域中的两个可用区之间提供持久耐用的数据存储和复制功能。Hyperdisk Balanced 高可用性卷具有与非复制平衡 Hyperdisk 磁盘类似的存储限制。
如果您要在 Compute Engine 上设计稳健可靠的系统或高可用性服务,请使用结合了其他最佳实践(例如使用快照备份数据)的 Hyperdisk Balanced 高可用性磁盘。Hyperdisk Balanced 高可用性磁盘也适用于区域级托管式实例组。
万一发生罕见的可用区级服务中断,您通常可以使用 --force-attach 标志将 Hyperdisk Balanced 高可用性磁盘上运行的工作负载故障切换到另一个可用区。借助 --force-attach 标志,您可以将 Hyperdisk Balanced 高可用性磁盘挂接到备用实例,即使由于磁盘不可用而无法将其与原始计算实例分离也没有问题。如需了解详情,请参阅区域性磁盘故障切换。
性能
与使用 Hyperdisk 快照进行恢复相比,Hyperdisk Balanced 高可用性磁盘适用于需要较低恢复点目标 (RPO) 和恢复时间目标 (RTO) 的工作负载。
当多个可用区的数据冗余比写入性能更重要时,可选择 Hyperdisk Balanced 高可用性磁盘。
Hyperdisk Balanced 高可用性磁盘具有可自定义的 IOPS 和吞吐量性能。如需详细了解 Hyperdisk Balanced 高可用性的性能和限制,请参阅关于 Hyperdisk。
当您需要更多的磁盘可用空间或更优的性能时,可以修改 Hyperdisk Balanced 高可用性磁盘以添加更多存储空间、吞吐量和 IOPS。
可靠性
Compute Engine 将 Hyperdisk Balanced 高可用性磁盘的数据复制到创建磁盘时指定的可用区。每个副本的数据分布在该可用区内的多个物理机器中,以确保冗余。
与 Hyperdisk 类似,您可以创建 Hyperdisk Balanced 高可用性磁盘的快照,以防止因用户错误而导致数据丢失。它为增量快照,即使您对附加到正在运行的虚拟机的磁盘创建快照,也只需要几分钟时间。
在虚拟机之间共享 Hyperdisk 卷
对于某些 Hyperdisk 卷,您可以通过启用磁盘共享,从多个虚拟机能够同时访问该卷。磁盘共享适用于各种应用场景,例如构建高可用性应用或大型机器学习工作负载,其中的多个虚拟机需要相同模型或训练数据的访问权限。
如需了解详情,请参阅在虚拟机之间共享磁盘。
Hyperdisk 存储池
借助 Hyperdisk 存储池,您可以更轻松地降低块存储总拥有成本 (TCO),并简化块存储管理。借助 Hyperdisk 存储池,您可以在单个项目中最多 1,000 个磁盘之间共享一个容量和性能池。由于存储池提供精简预配和数据缩减功能,因此您可以提高效率。存储池可简化将本地 SAN 迁移到云的过程,同时能够更轻松地为工作负载提供所需的容量和性能。
您可以创建一个存储池,此存储池具有为特定可用区的项目中所有工作负载预估的容量和性能。然后,您可以在此存储池中创建磁盘,并将磁盘挂接到现有虚拟机。您还可以在创建新虚拟机时在存储池中创建磁盘。每个存储池都包含一种类型的磁盘,例如 Hyperdisk Throughput。Hyperdisk 存储池有两种类型:
- Hyperdisk Balanced 存储池:适用于 Hyperdisk Balanced 磁盘最适合提供服务的通用工作负载
- Hyperdisk Throughput 存储池:适用于 Hyperdisk Throughput 磁盘最适合提供服务的流式工作负载、冷数据工作负载和分析工作负载
容量预配选项
可以通过以下两种方式之一预配 Hyperdisk 存储池容量:
- 标准容量预配
- 使用标准容量预配时,您可以在存储池中创建磁盘,直到所有磁盘的总大小达到存储池的预配容量。使用标准容量预配的存储池中的磁盘消耗容量的方式与非池磁盘类似,在您创建磁盘时会消耗容量。
- 高级容量预配
通过高级容量预配,您可以在存储池中的所有磁盘之间共享一个精简预配和数据缩减的存储容量池。您需要支付存储池预配容量的费用。
您最多可以将存储池预配容量的 500% 预配给高级容量存储池中的磁盘。只有写入存储池中磁盘的数据量才会消耗存储池容量。自动减少数据量可以进一步减少存储池容量的消耗。
如果高级容量存储池的容量利用率达到预配容量的 80%,则 Hyperdisk 存储池会尝试自动向存储池添加容量,以防止出现与容量不足相关的错误。
示例
假设您有一个预配容量为 10 TiB 的存储池。
使用标准容量预配:
- 在存储池中创建磁盘时,最多可预配 10 TiB 的汇总 Hyperdisk 容量。您需要支付 10 TiB 存储池预配容量的费用。
- 如果在存储池中创建单个大小为 5 TiB 的磁盘并将 2 TiB 的数据写入该磁盘,则存储池的已用容量为 5 TiB。
使用高级容量预配:
- 在存储池中创建磁盘时,最多可预配 50 TiB 的汇总 Hyperdisk 容量。您需要支付 10 TiB 存储池预配容量的费用。
- 如果在存储池中创建单个大小为 5 TiB 的磁盘,并且将 3 TiB 的数据写入该磁盘,数据缩减会将写入的数据量减少到 2 TiB,则存储池的已用容量为 2 TiB。
性能预配选项
可以通过以下两种方式之一预配 Hyperdisk 存储池性能:
- 标准性能预配
标准性能最适合以下类型的工作负载:
- 性能受存储池资源限制时无法成功的工作负载
- 存储池中的磁盘可能存在相关性能高峰的工作负载,例如,数据库的数据磁盘,这些磁盘每天早上都会达到峰值利用率。
标准性能存储池无法受益于精简预配,并且不会显著降低性能 TCO。使用标准性能预配时,您可以在存储池中创建磁盘,直到所有磁盘的总预配 IOPS 或吞吐量达到存储池的预配容量。具有标准性能预配的存储池中的磁盘消耗 IOPS 和吞吐量的方式与非池磁盘类似,在您创建磁盘时会预配 IOPS 和吞吐量。您需要为存储池的预配总 IOPS 和吞吐量付费。
在具有标准性能的 Hyperdisk Balanced 存储池中,存储池中每个磁盘的前 3,000 IOPS 和 140 MiBps 吞吐量(基准值)不会消耗存储池资源。在存储池中创建磁盘时,任何超出基准值的 IOPS 和吞吐量都会消耗存储池中的 IOPS 和吞吐量。
在标准性能存储池中创建的磁盘不会与存储池的其余部分共享性能资源。存储池中所有磁盘的总体性能不能超过存储池的总预配 IOPS 或吞吐量。
- 高级性能预配
具有高级性能预配的存储池可利用精简预配来提高性能效率并降低块存储性能 TCO。通过高级性能预配,您可以在存储池中的所有磁盘之间共享一个预配性能池。当存储池中的磁盘读取和写入数据时,存储池会动态分配性能资源。只有存储池中磁盘使用的 IOPS 和吞吐量才会消耗存储池 IOPS 和吞吐量。由于高级性能存储池采用精细预配,因此您可以为存储池中的磁盘分配比为存储池预配的 IOPS 或吞吐量更多的 IOPS 或吞吐量,最多可达到为存储池预配的 IOPS 或吞吐量的 500%。与标准性能类似,您需要为存储池的预配 IOPS 和吞吐量付费。
在具有高级性能预配的 Hyperdisk Balanced 存储池中,磁盘没有基准性能。存储池中 Hyperdisk Balanced 磁盘的每次读写操作都会消耗存储池资源。
当存储池中所有磁盘的总体性能利用率达到为存储池预配的总性能量时,这些磁盘可能会出现性能争用。因此,高级性能预配最适合使用高峰期不高度相关的工作负载。如果您的工作负载同时达到峰值,高级性能存储池可能会达到存储池的性能上限,导致性能资源争用。
如果在高级性能存储池中针对存储池中的任何磁盘检测到性能资源争用情况,则自动扩容功能会尝试自动提高存储池中磁盘可用的 IOPS 或吞吐量,以防止出现性能问题。
示例
假设您有一个预配的 IOPS 为 100,000 的 Hyperdisk Balanced 存储池。
使用标准性能预配:
- 在存储池中创建 Hyperdisk Balanced 磁盘时,最多可预配 100,000 总体 IOPS。
- 您需要为 100,000 IOPS 的 Hyperdisk Balanced 存储池预配性能付费。
与在存储池外部创建的磁盘一样,标准性能存储池中的 Hyperdisk Balanced 磁盘会自动预配高达 3,000 基准 IOPS 和 140 MiB/s 基准吞吐量。此基准性能不会计入存储池的预配性能。只有当您向预配性能高于基准的存储池添加磁盘时,才会计入存储池的预配性能,例如:
- 预配了 3,000 IOPS 的磁盘使用了 0 存储池 IOPS,并且该存储池仍有 100,000 预配的 IOPS 可供其他磁盘使用。
- 预配了 13,000 IOPS 的磁盘使用了 10,000 存储池 IOPS,并且该存储池还有 90,000 预配的 IOPS 可分配给存储池中的其他磁盘。
使用高级性能预配:
- 在存储池中创建磁盘时,最多可预配 500,000 IOPS 的总体 Hyperdisk 性能。
- 您需要为存储池预配的 100,000 IOPS 付费。
- 如果您在具有 5,000 IOPS 的存储池中创建单个磁盘 (
Disk1),则不会消耗存储池预配的 IOPS 中的任何 IOPS。不过,您现在可以为存储池中创建的新磁盘预配的 IOPS 数为 495,000。 - 如果
Disk1开始读写数据,并且在给定一分钟内使用了其 5,000 IOPS 的上限,则会从存储池预配的 IOPS 中消耗 5,000 IOPS。您在同一存储池中创建的任何其他磁盘都可以在同一分钟内使用总计 95,000 IOPS 的上限,而不会发生争用。
更改 Hyperdisk 存储池预配容量和性能
随着工作负载的扩缩,您可以增加或减少存储池的预配容量、IOPS 和吞吐量。使用高级容量存储池或高级性能存储池时,存储池中的所有现有磁盘和新磁盘都可以使用任何额外的容量或性能。此外,Compute Engine 会尝试自动修改存储池,如下所示:
- 高级容量:当存储池的已用存储池预配容量达到 80% 时,Compute Engine 会尝试自动向存储池增加更多容量。
- 高级性能:如果存储池因利用率过高而出现较长时间的争用,Compute Engine 会尝试提高存储池的 IOPS 或吞吐量。
有关 Hyperdisk 存储池的更多信息
如需了解如何使用 Hyperdisk 存储池,请使用以下链接:
本地 SSD 磁盘
本地 SSD 磁盘以物理方式挂接到托管虚拟机的服务器。 与标准永久性磁盘或 SSD 永久性磁盘相比,本地 SSD 磁盘的吞吐量更高,延迟时间更短。您存储在本地 SSD 磁盘上的数据仅在停止或删除虚拟机之前保留。您可以将多个本地 SSD 磁盘挂接到虚拟机,具体取决于 vCPU 的数量。
每个本地 SSD 磁盘的大小固定为 375 GiB,但 Z3 虚拟机使用的是大小为 3 TiB 的本地 SSD 磁盘。如需更多存储空间,请在创建虚拟机时将多个本地 SSD 磁盘添加到虚拟机。可挂接到虚拟机的本地 SSD 磁盘的最大数量取决于机器类型和使用的 vCPU 数量。
本地 SSD 磁盘上的数据持久性
请查看本地 SSD 数据持久性,了解哪些事件会保留您的本地 SSD 数据,以及哪些事件会导致您的本地 SSD 数据无法恢复。
本地 SSD 和机器类型
您可以将本地 SSD 磁盘挂接到 Compute Engine 上可用的大多数机器类型,如机器系列比较表中所示。不过,根据每种机器类型,您可以挂接的本地 SSD 磁盘数量会受到相应的限制。如需了解详情,请参阅选择有效的本地 SSD 磁盘数量。
本地 SSD 磁盘的容量限制
虚拟机的本地 SSD 磁盘容量上限为:
| 机器类型 | 本地 SSD 磁盘大小 | 磁盘数量 | 最大容量 |
|---|---|---|---|
| Z3 | 3 TiB | 12 | 36 TiB |
c3d-standard-360-lssd |
375 GiB | 32 | 12 TiB |
c3d-highmem-360-lssd |
375 GiB | 32 | 12 TiB |
c3-standard-176-lssd |
375 GiB | 32 | 12 TiB |
| N1、N2 和 N2D | 375 GiB | 24 | 9 TiB |
| N1、N2 和 N2D | 375 GiB | 16 | 6 TiB |
| A3 | 375 GiB | 16 | 6 TiB |
| C2、C2D、A2 标准、M1 和 M3 | 375 GiB | 8 | 3 TiB |
| A2 Ultra | 375 GiB | 8 | 3 TiB |
本地 SSD 磁盘的限制
本地 SSD 具有以下限制:
- 如需达到 IOPS 上限,请使用具有 32 个或更多 vCPU 的虚拟机。
- 具有共享核心机器类型的虚拟机无法挂接本地 SSD 磁盘。
- 您不能将本地 SSD 磁盘挂接到 N4、H3、M2 E2 和 Tau T2A 机器类型。
- 您不能将客户提供的加密密钥用于本地 SSD 磁盘。Compute Engine 在数据写入本地 SSD 存储空间时会自动加密数据。
性能
本地 SSD 磁盘提供极高的 IOPS 和极低的延迟。与永久性磁盘不同,您必须自行管理本地 SSD 磁盘的分割。
本地 SSD 性能取决于多种因素。如需了解详情,请参阅本地 SSD 性能和优化本地 SSD 性能。
Cloud Storage 存储桶
Cloud Storage 存储桶是适用于虚拟机的一种存储方案,该方案的灵活性、可扩缩性和耐用性最强。如果应用不需要 Hyperdisk、Persistent Disks、和本地 SSD 带来的低延迟优势, 您可以将数据存储在 Cloud Storage 存储桶中。
如果延迟时间和吞吐量不是优先考虑项,并且您必须在多个虚拟机或可用区之间轻松共享数据,请将虚拟机连接到 Cloud Storage 存储桶。
Cloud Storage 存储桶的属性
请参阅以下部分,了解 Cloud Storage 存储桶的行为和特征。
性能
Cloud Storage 存储桶的性能取决于您选择的存储类别以及存储桶相对于虚拟机的位置。
在虚拟机所在位置使用 Cloud Storage Standard Storage 类别虽然可以提供与 Hyperdisk 或 Persistent Disk 相当的性能,但延迟时间较长且吞吐量一致性较低。在双区域使用 Standard Storage 类别可以将数据冗余地存储在两个区域中。为了在使用双区域时获得最佳性能,您的虚拟机应位于双区域中的其中一个区域。
Nearline Storage、Coldline Storage 和 Archive Storage 类别主要用于长期数据归档。与 Standard Storage 类别不同,这些类别存储期限最短,并且会产生数据检索费用。 因此,它们最适合长期存储不经常访问的数据。
可靠性
所有 Cloud Storage 存储桶都具有内置冗余功能,可保护您的数据免受设备故障的影响,并通过数据中心维护事件确保数据可用性。系统会针对所有 Cloud Storage 操作计算校验和,以帮助确保您所读取的内容就是您所写入的内容。
灵活性
与 Hyperdisk 或 Persistent Disk不同,Cloud Storage 存储桶不限于虚拟机所在的可用区。此外,您可以同时从多个虚拟机对存储桶读取和写入数据。例如,您可以将多个可用区中的虚拟机配置为在同一个存储桶中读取和写入数据,而不是将数据复制到 Hyperdisk 或 Persistent Disk 卷。
Cloud Storage 加密
数据在虚拟机外部传输到 Cloud Storage 存储桶之前,Compute Engine 会自动加密数据。在虚拟机上将文件写入存储桶之前,无需进行加密。
就像 Persistent Disk 卷一样,您可以使用自己的加密密钥加密存储桶。对 Cloud Storage 存储桶执行数据读写操作
使用 gcloud storage 命令行工具或 Cloud Storage 客户端库从 Cloud Storage 存储桶写入和读取文件。
gcloud storage
默认情况下,gcloud storage 命令行工具安装在使用公共映像的大多数虚拟机上。
如果您的虚拟机没有 gcloud storage 命令行工具,您可以安装它。
使用 SSH 或其他连接方法连接到您的 Linux 虚拟机或连接到 Windows 虚拟机。
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.

如果您以前从未在此虚拟机上使用过
gcloud storage,请使用 gcloud CLI 设置凭据。gcloud init
或者,如果您的虚拟机配置为使用具有 Cloud Storage 范围的服务账号,则可以跳过此步骤。
使用
gcloud storage工具创建存储桶、将数据写入存储桶,以及从这些存储桶读取数据。如需在特定存储桶中写入或读取数据,您必须具有对该存储桶的访问权限。您能够从任何可公开访问的存储桶读取数据。或者,您也可以将数据流式传输到 Cloud Storage。
客户端库
如果您已将虚拟机配置为使用具有 Cloud Storage 范围的服务账号,则可以使用 Cloud Storage API 对 Cloud Storage 存储桶执行数据写入和读取操作。
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.
根据您的首选语言安装并配置客户端库。
如有必要,请按照插入代码示例在虚拟机上创建 Cloud Storage 存储桶。
按照插入代码示例写入数据和读取数据,并在应用中添加用于对 Cloud Storage 存储桶执行文件写入或读取操作的代码。
后续步骤
- 将 Hyperdisk 卷添加到虚拟机。
- 将 Persistent Disk 卷添加到虚拟机。
- 向虚拟机添加区域性磁盘。
- 创建具有本地 SSD 磁盘的虚拟机。
- 创建文件服务器或分布式文件系统。
- 查看磁盘配额。
- 在虚拟机上装载 RAM 磁盘。