Para adicionar discos às suas VMs, escolha uma das opções de armazenamento em blocos oferecidas pelo Compute Engine. Cada uma tem características únicas de preço e desempenho:
- Os volumes do Google Cloud Hyperdisk são armazenamento de rede para o Compute Engine, com desempenho configurável e volumes que podem ser redimensionados dinamicamente. Eles oferecem desempenho, flexibilidade e eficiência significativamente mais altos em comparação ao Persistent Disk. O Hyperdisk equilibrado de alta disponibilidade pode replicar dados de forma síncrona entre discos localizados em duas zonas, oferecendo proteção se uma zona ficar indisponível.
- Com os pools de armazenamento de Hyperdisk, é possível comprar a capacidade e o desempenho do Hyperdisk de forma agregada e criar discos para suas VMs usando esse pool de armazenamento.
- Os volumes de disco permanente fornecem armazenamento em rede redundante e de alto desempenho. Cada volume de Persistent Disk é removido por centenas de discos físicos.
- Por padrão, as VMs usam discos permanentes zonais e armazenam
dados em volumes localizados em uma única zona, como
us-west1-c. - Também é possível criar discos permanentes regionais, que replicam dados de maneira síncrona entre discos localizados em duas zonas e fornecem proteção se uma zona ficar indisponível.
- Por padrão, as VMs usam discos permanentes zonais e armazenam
dados em volumes localizados em uma única zona, como
- Os discos SSD locais são unidades físicas anexadas diretamente ao mesmo servidor que sua VM. Eles podem oferecer um desempenho melhor, mas são temporários.
Para ver uma comparação de preços, consulte Preços de discos. Se você não tem certeza de qual opção usar, para séries de máquinas de gerações anteriores, a solução mais comum é adicionar um volume de disco permanente equilibrado à VM. Para as séries de máquinas mais recentes, adicione um volume de Hyperdisk à instância da computação.
Além do armazenamento em blocos, o Compute Engine oferece opções de armazenamento de arquivos e objetos. Para analisar e comparar as opções de armazenamento, consulte Analisar as opções de armazenamento.
Introdução
Por padrão, cada VM do Compute Engine tem um único disco de inicialização que contém o sistema operacional. Normalmente, os dados do disco de inicialização são armazenados em um disco permanente ou Hyperdisk equilibrado. Quando os aplicativos precisarem de mais espaço de armazenamento, será possível provisionar um ou mais de um dos volumes de armazenamento a seguir para a VM.
Para saber mais sobre cada opção de armazenamento, consulte a tabela a seguir:
| Disco permanente equilibrado |
Disco permanente SSD |
Disco permanente padrão |
Disco permanente extremo |
Hiperdisco equilibrado | Hyperdisk ML | Hiperdisco extremo | Capacidade de processamento do hiperdisco | SSDs locais | |
|---|---|---|---|---|---|---|---|---|---|
| Tipo de armazenamento | Armazenamento em blocos econômico e confiável | Armazenamento em blocos rápido e confiável | Armazenamento em blocos eficiente e confiável | Opção de armazenamento em blocos de disco permanente com melhor performance com IOPS personalizáveis | Alto desempenho para cargas de trabalho exigentes com um custo menor | Armazenamento de maior capacidade otimizado para cargas de trabalho de machine learning. | Opção de armazenamento em blocos mais rápida com IOPS personalizáveis | Armazenamento em blocos econômico e orientado para capacidade de processamento com capacidade personalizável | Armazenamento em blocos local de alto desempenho |
| Capacidade mínima por disco | Por zona: 10 GiB Regional: 10 GiB |
Por zona: 10 GiB Regional: 10 GiB |
Por zona: 10 GiB Regional: 200 GiB |
500 GiB | Zonal e regional: 4 GiB | 4 GiB | 64 GiB | 2 TiB | 375 GiB, 3 TiB com Z3 |
| Capacidade máxima por disco | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 32 TiB | 375 GiB, 3 TiB com Z3 |
| Aumento de capacidade | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | Depende do tipo de máquina† |
| Capacidade máxima por VM | 257 TiB* | 257 TiB* | 257 TiB* | 257 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 36 TiB |
| Escopo de acesso | Zona | Zona | Zona | Zona | Zona | Zona | Zona | Zona | Instância |
| Redundância de dados | Zonal e multizonal | Zonal e multizonal | Zonal e multizonal | Zonal | Zonal e multizonal | Zonal | Zonal | Zonal | Nenhum |
| Criptografia em repouso | Sim | Sim | Sim | Sim | Sim | Sim | Sim | Sim | Sim |
| Chaves de criptografia personalizadas | Sim | Sim | Sim | Sim | Sim‡ | Sim | Sim | Sim | Não |
| Instruções | Adicionar um disco permanente extremo | Adicionar um SSD local | |||||||
Além das opções de armazenamento oferecidas pelo Google Cloud, é possível implantar soluções alternativas nas suas VMs.
- Crie um servidor de arquivos ou sistema de arquivos distribuídos no Compute Engine para usar como um sistema de arquivos de rede com recursos NFSv3 e SMB3.
- Monte um disco de RAM na memória da VM para criar um volume de armazenamento em blocos com alta capacidade de processamento e baixa latência.
Os recursos de armazenamento em blocos têm características de desempenho diferentes. Considere os requisitos de tamanho do armazenamento e de desempenho ao determinar o tipo correto de armazenamento em blocos para suas VMs.
Para mais informações sobre limites de desempenho, consulte:
- Limites de desempenho do Persistent Disk
- Limites de desempenho do SSD local
- Limites de desempenho de hiperdisco
Persistent Disk
Os volumes do Persistent Disk são dispositivos de armazenamento de rede duráveis que podem ser acessados por instâncias de máquina virtual (VM) igual a discos físicos em um computador ou servidor. Os dados armazenados em cada volume do Persistent Disk são distribuídos em vários discos físicos. O Compute Engine gerencia os discos físicos e a distribuição de dados para garantir a redundância e otimizar o desempenho.
Os volumes do Persistent Disk estão localizados de maneira independente da VM. Portanto, é possível remover ou mover volumes do Persistent Disk para manter os dados mesmo depois de excluir as VMs. O desempenho do disco permanente é dimensionado automaticamente de acordo com o tamanho, para que você possa redimensionar os volumes de disco permanente existentes ou adicionar mais volumes a uma VM para atender aos requisitos de desempenho e espaço de armazenamento.
Tipos de disco permanente
Ao configurar um disco permanente, selecione um dos tipos de disco a seguir:
- Discos permanentes equilibrados (
pd-balanced)- Alternativa aos discos permanentes de desempenho (pd-ssd)
- Equilíbrio de desempenho e custo. Para a maioria dos formatos de VM, exceto os muito grandes, esses discos têm as mesmas IOPS máximas que os discos permanentes SSD e IOPS por GiB mais baixos. Esse tipo de disco oferece níveis de desempenho adequados para a maioria dos aplicativos de uso geral a uma faixa de preços igual à dos discos permanentes padrão e de desempenho (pd-ssd).
- Com respaldo das unidades de estado sólido (SSD).
- Discos permanentes de desempenho (SSD) (
pd-ssd)- Ideal para aplicativos empresariais e bancos de dados de alto desempenho que exigem menos latência e mais IOPS do que os discos permanentes padrão.
- Com respaldo das unidades de estado sólido (SSD).
- Discos permanentes padrão (
pd-standard)- Ideal para grandes cargas de trabalho de processamento de dados que usam principalmente E/Ss sequenciais.
- Com respaldo dos drives de disco rígido padrão (HDD)
- Discos permanentes extremos (
pd-extreme)- Oferece alto desempenho consistente para cargas de trabalho de acesso aleatório e capacidade de processamento em massa.
- Desenvolvido para cargas de trabalho de banco de dados de última geração.
- Permite provisionar os IOPS de destino.
- Com respaldo das unidades de estado sólido (SSD).
- Disponível com um número limitado de tipos de máquinas.
Se você criar um disco no console do Google Cloud, o tipo de disco padrão será
pd-balanced. Se você criar um disco usando a CLI gcloud ou a
API Compute Engine, o tipo de disco padrão será pd-standard.
Para informações sobre o suporte do tipo de máquina, consulte:
Durabilidade do disco permanente
A durabilidade do disco representa a probabilidade de perda de dados, por design, para um disco típico em um ano típico, usando um conjunto de suposições sobre falhas de hardware, a probabilidade de eventos catastróficos, práticas de isolamento e processos de engenharia nos data centers do Google e nas codificações internas usadas por cada tipo de disco. Os eventos de perda de dados no disco permanente são extremamente raros e têm sido historicamente o resultado de falhas de hardware coordenadas, bugs de software ou uma combinação dos dois. O Google também toma muitas medidas para reduzir o risco de corrupção de dados silenciosa em todo o setor. Um erro humano de um cliente do Google Cloud, como quando um cliente exclui acidentalmente um disco, está fora do escopo de durabilidade do disco permanente.
Há um risco muito pequeno de perda de dados que ocorre com um disco permanente regional devido às codificações e à replicação de dados internos. Os discos permanentes regionais fornecem o dobro de réplicas dos discos permanentes zonais. Com as réplicas distribuídas entre duas zonas na mesma região, eles fornecem alta disponibilidade e Pode ser usada para recuperação de desastres se um data center inteiro for perdido e não puder ser recuperado (embora isso nunca tenha ocorrido). As réplicas adicionais em uma segunda zona podem ser acessadas imediatamente se uma zona principal ficar indisponível durante uma interrupção longa.
A tabela abaixo mostra a durabilidade para o design de cada tipo de disco. 99,999% de durabilidade significa que, com 1.000 discos, você provavelmente ficaria cem anos sem perder um único.
| Disco permanente padrão zonal | Disco permanente equilibrado de zona | Disco permanente SSD por zona | Disco permanente extremo por zona | Disco permanente padrão regional | Disco permanente equilibrado regional | Disco permanente SSD regional |
|---|---|---|---|---|---|---|
| Melhor que 99,99% | Melhor que 99,999% | Melhor que 99,999% | Melhor que 99,9999% | Melhor que 99,999% | Melhor que 99,9999% | Melhor que 99,9999% |
Disco permanente zonal
Facilidade de usar
O Compute Engine faz a maioria das tarefas de gerenciamento de disco para que você não precise lidar com particionamento, matrizes de disco redundantes ou gerenciamento de subvolumes. Geralmente, não é necessário criar volumes lógicos maiores. No entanto, é possível estender a capacidade do Persistent Disk secundário anexado para 257 TiB por VM e aplicar essas práticas aos seus volumes do Persistent Disk se você quiser. Você economiza tempo e aprimora o desempenho quando formata os discos permanentes com um único sistema de arquivos e sem tabelas de partição.
Se for necessário separar os dados em vários volumes exclusivos, crie mais discos em vez de dividir os discos atuais em várias partições.
Quando você precisar de mais espaço nos volumes de disco permanente, redimensione os discos em vez de reparticionar e formatar.
Desempenho
O desempenho do Persistent Disk é previsível e aumenta ou diminui de forma linear com a capacidade provisionada até que os limites das vCPUs provisionadas de uma VM sejam atingidos. Para mais informações sobre otimização e limites de dimensionamento de desempenho, consulte Configurar discos para atender aos requisitos de desempenho.
Os discos permanentes padrão são eficientes e econômicos para processar operações sequenciais de leitura ou gravação. No entanto, eles não são otimizados para processar altas taxas de operações aleatórias de entrada ou saída por segundo (IOPS, na sigla em inglês). Se os aplicativos exigirem altas taxas de IOPS aleatórias, use discos permanentes SSD ou extremos. O Disco permanente SSD foi projetado para latências de milissegundos com um dígito. A latência alcançada é específica para cada aplicativo.
O Compute Engine otimiza automaticamente o desempenho e o escalonamento nos volumes do Persistent Disk. Você não precisa segmentar vários discos juntos ou pré-aquecê-los para atingir o melhor desempenho. Quando você precisar de mais espaço em disco ou de um melhor desempenho, bastará redimensionar os discos e, possivelmente, adicionar mais vCPUs para aumentar o espaço de armazenamento, a capacidade e a taxa de IOPS. O desempenho do Persistent Disk é baseado na capacidade total dele anexada a uma VM e no número de vCPUs que há nela.
No caso dos dispositivos de inicialização, é possível usar um disco permanente padrão para reduzir os custos. Pequenos volumes de disco permanente de 10 GiB podem funcionar para casos de uso básicos de gerenciamento de inicialização e pacotes. No entanto, para garantir um desempenho consistente para uso mais geral do dispositivo de inicialização, use um disco permanente balanceado como disco de inicialização.
Cada operação de gravação do Persistent Disk contribui para o tráfego de saída da rede da VM. Isso significa que essas operações são restringidas pelo limite de saída da rede da instância.
Confiabilidade
Os discos permanentes têm redundância incorporada para proteger seus dados contra falhas em equipamentos, bem como garantir a disponibilidade deles durante eventos de manutenção de data center. As somas de verificação são calculadas para todas as operações de disco permanente para garantir que você consiga ler exatamente aquilo que gravou.
Além disso, é possível criar snapshots de discos permanentes para se proteger contra a perda de dados resultante de erros do usuário. Os snapshots são incrementais e levam apenas alguns minutos para serem criados, mesmo quando os discos estão anexados a VMs em execução.
Modo de vários gravadores
É possível anexar um disco permanente SSD no modo de vários gravadores a até duas VMs N2 simultaneamente, para que ambas as instâncias possam ler e gravar no disco.
O Persistent Disk no modo de vários gravadores fornece um recurso de armazenamento em blocos compartilhado e apresenta uma base de infraestrutura para a criação de sistemas de arquivos e bancos de dados compartilhados altamente disponíveis. Esses sistemas de arquivos e bancos de dados especializados precisam ser projetados para trabalhar com armazenamento em blocos compartilhado e lidar com a coerência de cache entre VMs usando ferramentas como SCSI Persistent Reservations.
No entanto, o disco permanente com modo de várias gravações geralmente não deve ser usado diretamente, e você deve estar ciente de que muitos sistemas de arquivos, como EXT4, XFS e NTFS, não foram projetados para serem usados com armazenamento em blocos compartilhado. Para mais informações sobre as práticas recomendadas ao compartilhar discos permanentes entre VMs, consulte Práticas recomendadas.
Se você precisar de um armazenamento de arquivos totalmente gerenciado, monte um compartilhamento de arquivos do Filestore nas suas VMs do Compute Engine.
Para ativar o modo de vários gravadores em novos discos permanentes, crie
um disco permanente e especifique a sinalização --multi-writer na
CLI gcloud ou a propriedade multiWriter na API Compute Engine. Para mais informações, consulte
Compartilhar volumes de disco permanente entre VMs.
Criptografia do disco permanente
O Compute Engine criptografa automaticamente os dados antes que eles saiam da VM para o espaço de armazenamento do disco permanente. Cada disco permanente fica criptografado com chaves definidas pelo sistema ou fornecidas pelo cliente. O Google distribui dados dos discos permanentes por vários discos físicos de maneira não controlada pelos usuários.
Quando você exclui um disco permanente, o Google descarta as chaves de criptografia, tornando os dados irrecuperáveis. Esse processo é irreversível.
Se quiser controlar as chaves usadas para criptografar os dados, crie os discos com as próprias chaves de criptografia.
Restrições
Não é possível anexar um volume de disco permanente a uma VM em outro projeto.
É possível anexar um Persistent Disk equilibrado a um máximo de 10 VMs no modo somente leitura.
Nos tipos de máquina personalizados ou tipos de máquina predefinidos que tenham no mínimo uma vCPU, é possível anexar até 128 discos permanentes.
Cada volume de Persistent Disk pode ter até 64 TiB. Por isso, não é necessário gerenciar matrizes de discos para criar volumes lógicos grandes. É possível anexar apenas uma quantidade limitada de espaço total e um número restrito de volumes individuais do Persistent Disk a cada VM. Os tipos de máquina predefinidos e os tipos de máquina personalizados têm os mesmos limites de discos permanentes.
A maioria das VMs pode ter até 128 volumes do Persistent Disk e até 257 TiB de espaço total em disco anexado. O espaço total em disco para uma VM inclui o tamanho do disco de inicialização.
Os tipos de máquina com núcleo compartilhado são limitados a 16 volumes de Persistent Disk e 3 TiB de espaço total em disco.
A criação de volumes lógicos maiores do que 64 TB pode exigir considerações especiais. Para mais informações sobre um desempenho de volume lógico maior, consulte Tamanho do volume lógico.
Disco permanente regional
Os volumes de disco permanente regional têm qualidades de armazenamento semelhantes ao disco permanente zonal. No entanto, os volumes de Persistent Disk regionais fornecem replicação e armazenamento durável de dados entre duas zonas na mesma região.
Sobre a replicação síncrona de disco
Ao criar um novo Persistent Disk, é possível criar o disco em uma só zona ou replicá-lo em duas zonas na mesma região.
Por exemplo, se você criasse um disco em uma zona, como em us-west1-a, você teria uma cópia do disco. Isso é chamado de disco zonal.
É possível aumentar a disponibilidade do disco armazenando outra cópia dele em uma zona diferente dentro da região, como em us-west1-b.
Os discos permanentes replicados em duas zonas na mesma região são chamados de Persistent Disk regionais. Também é possível usar o Hyperdisk equilibrado de alta disponibilidade para a replicação síncrona entre zonas do Google Cloud Hyperdisk
É improvável que uma região falhe completamente, mas podem ocorrer falhas zonais. A replicação na região em zonas diferentes, conforme mostrado na imagem a seguir, ajuda na disponibilidade e reduz a latência do disco. Se as duas zonas de replicação falharem, isso representará uma falha em toda a região.
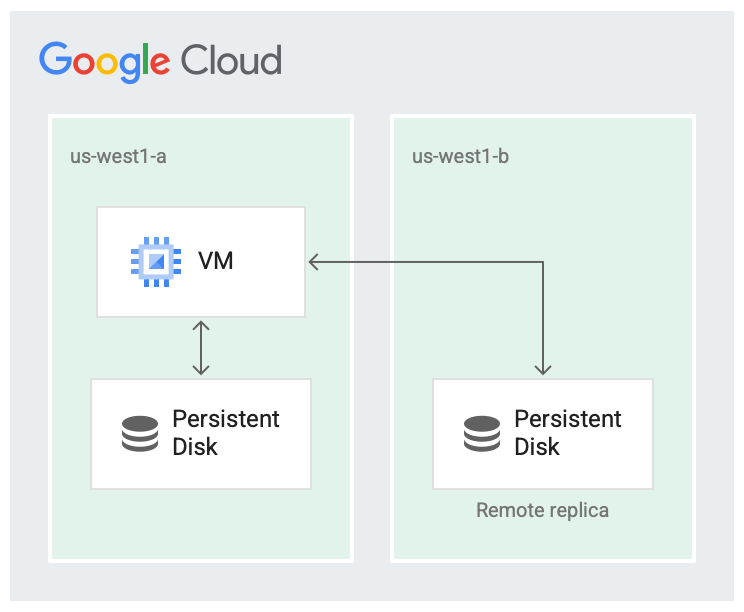
O disco é replicado em duas zonas.
No cenário replicado, os dados estão disponíveis na zona local
(us-west1-a), que é a zona em que a máquina virtual (VM) está sendo executada. Em seguida,
os dados são replicados para outra zona (us-west1-b). Uma das zonas precisa ser
a mesma em que a VM está sendo executada.
Se ocorrer uma interrupção na zona, normalmente é possível fazer o failover da carga de trabalho em execução no Persistent Disk regional para outra zona. Para saber mais, consulte Failover de Persistent Disk regional.
Considerações de design para o Persistent Disk regional
Se você estiver projetando sistemas robustos ou serviços de alta disponibilidade no Compute Engine, use discos permanentes regionais com outras práticas recomendadas, como fazer backup dos dados com snapshots. Os volumes de Persistent Disk regional também foram projetados para funcionar com grupos de instâncias gerenciadas regionais.
Desempenho
Os discos permanentes regionais foram projetados para cargas de trabalho que exigem um objetivo de ponto de recuperação (RPO) e um objetivo de tempo de recuperação (RTO) menores em comparação com o uso de snapshots de Persistent Disk (páginas em inglês).
Os discos permanentes regionais são uma opção quando o desempenho de gravação é menos importante do que a redundância de dados em várias zonas.
Assim como o Persistent Disk zonal, o Persistent Disk regional pode atingir um maior desempenho de IOPS e capacidade de processamento em VMs com um número maior de vCPUs. Para mais informações sobre essa e outras limitações, consulte Configurar discos para atender aos requisitos de desempenho.
Quando você precisa de mais espaço em disco ou de desempenho melhor, é possível redimensionar os discos regionais para adicionar mais espaço de armazenamento, capacidade de processamento e IOPS.
Confiabilidade
O Compute Engine replica os dados no seu disco permanente regional para as zonas que você selecionou quando criou o disco. Os dados de cada réplica são distribuídos por várias máquinas físicas dentro da zona para garantir a redundância.
Assim como os discos permanentes por zona, é possível criar snapshots de discos permanentes para se proteger contra perda de dados devido a um erro do usuário. Os snapshots são incrementais e levam apenas alguns minutos para serem criados, mesmo quando os discos estão anexados a VMs em execução.
Limitações
- No México, em Montreal e em Osaka, temos três zonas instaladas em um ou dois data centers físicos. A destruição de um data center é um evento raro, mas os dados armazenados nessas regiões podem ser perdidos se isso acontecer. Por isso, considere fazer o backup dos dados mais importantes da sua empresa em uma segunda região para aumentar a proteção.
- Só é possível anexar Persistent Disk regionais a VMs que usam tipos de máquina E2, N1, N2 e N2D.
- Você pode anexar o Hyperdisk Balanced High Availability somente a arquivos tipos de máquina compatíveis.
- Não é possível criar um Persistent Disk regional a partir de uma imagem ou de um disco criado a partir de uma imagem.
- Ao usar o modo somente leitura, é possível anexar um Persistent Disk equilibrado regional a, no máximo, 10 instâncias de VM.
- O tamanho mínimo de um disco permanente regional padrão é 200 GB.
- Só é possível aumentar o tamanho do volume do Disco permanente regional ou do Hyperdisk Balanced High Availability; não é possível diminuir o tamanho.
- Os volumes do Disco permanente regional e do Hyperdisk Balanced High Availability têm desempenhos diferentes do que os discos zonais correspondentes. Para mais informações, consulte Desempenho do armazenamento em blocos.
- Não é possível usar um volume do Hyperdisk Balanced High Availability que esteja no modo de vários gravadores como um disco de inicialização.
- Se você criar um disco replicado clonando um disco zonal, as duas réplicas zonais não estarão totalmente sincronizadas no momento da criação. Após a criação, é possível usar o clone de disco regional em média em até três minutos. No entanto, talvez seja necessário aguardar diversos minutos até que o disco atinja um estado totalmente replicado e o objetivo de ponto de recuperação (RPO) esteja próximo de zero. Saiba como Verificar se o disco replicado foi totalmente replicado.
Google Cloud Hyperdisk
O Google Cloud Hyperdisk é o armazenamento em blocos de última geração do Google. Ao descarregar e escalonar dinamicamente o processamento de armazenamento, ele separa o desempenho do armazenamento do tipo e do tamanho da VM. O Hyperdisk oferece desempenho, flexibilidade e eficiência substancialmente mais altos em comparação com o disco permanente.
Hiperdisco equilibrado
O Hyperdisk Balanced para o Compute Engine é adequado para uma ampla variedade de casos de uso, como aplicativos de linha de negócio (LOB), web apps e bancos de dados de nível médio, que não exigem o desempenho do Hyperdisk Extreme. Também é possível usar o Hyperdisk Balanced para apps em que várias VMs na mesma zona exigem simultaneamente acesso de gravação ao mesmo disco.
Com os volumes do Hyperdisk equilibrado, é possível ajustar dinamicamente a capacidade, as IOPS e a capacidade de processamento das suas cargas de trabalho.
Hyperdisk ML
As cargas de trabalho que usam aceleradores para treinar ou oferecer modelos de aprendizado de máquina precisam usar o Hyperdisk ML. Os volumes do Hyperdisk ML oferecem a capacidade de processamento personalizável mais rápida e são os melhores para modelos maiores que 20 GiB. O Hyperdisk ML também oferece suporte a acesso de leitura simultâneo ao mesmo volume em várias VMs.
É possível ajustar dinamicamente a capacidade e a capacidade de processamento de um volume do Hyperdisk ML.
Hiperdisco extremo
O Hyperdisk Extreme oferece o armazenamento em blocos mais rápido disponível. Ela é adequada para cargas de trabalho de última geração que precisam das mais alta capacidade de processamento e IOPS.
Os volumes extremos de Hyperdisk permitem que você ajuste de maneira independente a capacidade e as IOPS das cargas de trabalho.
Capacidade de processamento do hiperdisco
A capacidade de processamento do hiperdisco é ideal para análises de escalonamento horizontal, incluindo Hadoop e Kafka, unidades de dados para aplicativos sensíveis a custos e armazenamento frio.
Com os volumes de capacidade do Hyperdisk, é possível ajustar dinamicamente a capacidade e a capacidade de processamento das cargas de trabalho. É possível alterar o nível de capacidade de processamento provisionada sem inatividade ou interrupção nas cargas de trabalho.
Alta disponibilidade do hiperdisco equilibrada
A Alta disponibilidade do Hyperdisk equilibrada permite a replicação síncrona em séries de máquinas de terceira geração ou mais recentes. A Alta disponibilidade do Hyperdisk equilibrada permite a resiliência de dados com a replicação RPO=0 em duas zonas, semelhante ao Disco permanente regional.
Com os volumes do Hyperdisk equilibrado de alta disponibilidade, é possível ajustar dinamicamente a capacidade, as IOPS e a capacidade de processamento das cargas de trabalho. É possível mudar o desempenho provisionado e os níveis de capacidade sem inatividade ou interrupção nas cargas de trabalho. Use o Hyperdisk Balanced High Availability para quando diferentes VMs na mesma região exigirem simultaneamente acesso de gravação ao mesmo disco.
Os volumes Hyperdisk são criados e gerenciados assim como o Persistent Disk, com a possibilidade extra de definir o nível de capacidade de processamento ou IOPS provisionado e alterar esse valor a qualquer momento. Não há caminho de migração direto do disco permanente para o hiperdisco. Em vez disso, é possível criar um snapshot e restaurá-lo para um novo volume do Hyperdisk.
Para mais informações sobre hiperdisco, consulte Sobre hiperdisco.
Durabilidade do hiperdisco
A durabilidade do disco representa a probabilidade de perda de dados, por padrão, para um disco típico em um ano típico. A durabilidade é calculada usando um conjunto de suposições sobre falhas de hardware, como:
- A probabilidade de eventos catastróficos
- Práticas de isolamento
- Processos de engenharia nos data centers do Google
- As codificações internas usadas por cada tipo de disco
Os eventos de perda de dados de hiperdisco são extremamente raros. O Google também toma muitas medidas para reduzir o risco de corrupção de dados silenciosa em todo o setor.
Um erro humano de um cliente do Google Cloud, como quando um cliente exclui acidentalmente um disco, está fora do escopo de durabilidade do disco permanente.
A tabela abaixo mostra a durabilidade para o design de cada tipo de disco. 99,999% de durabilidade significa que, com 1.000 discos, você provavelmente ficaria cem anos sem perder um único.
| Hiperdisco equilibrado | Hiperdisco extremo | Hyperdisk ML | Capacidade de processamento do hiperdisco |
|---|---|---|---|
| Melhor que 99,999% | Melhor que 99,9999% | Melhor que 99,999% | Melhor que 99,999% |
Criptografia do Hyperdisk
O Compute Engine criptografa automaticamente os dados ao gravar em um volume do Hyperdisk. Também é possível personalizar a criptografia com chaves de criptografia gerenciadas pelo cliente.
Alta disponibilidade do hiperdisco equilibrada
Os discos Hyperdisk equilibrado de alta disponibilidade oferecem armazenamento durável e replicação de dados entre duas zonas na mesma região. Os volumes do Hyperdisk equilibrado de alta disponibilidade têm limites de armazenamento semelhantes aos discos do Hyperdisk equilibrado não replicados.
Se você estiver projetando sistemas robustos ou serviços de alta disponibilidade no Compute Engine, use discos de alta disponibilidade equilibrada do Hyperdisk com outras práticas recomendadas, como fazer backup dos dados com snapshots. Os discos do Hyperdisk equilibrado de alta disponibilidade também foram projetados para funcionar com grupos de instâncias gerenciadas regionais.
No caso improvável de uma interrupção na zona, normalmente é possível fazer o failover da carga de trabalho
em execução em discos de Alta disponibilidade do Hyperdisk equilibrado para outra zona usando a
sinalização --force-attach. A flag --force-attach permite anexar o disco de alta disponibilidade do Hyperdisk equilibrada a
uma instância de espera, mesmo que o disco não possa ser removido da instância de computação
original devido à indisponibilidade. Para saber mais, consulte
Failover de disco regional.
Desempenho
Os discos Hyperdisk equilibrado de alta disponibilidade foram projetados para cargas de trabalho que exigem um objetivo de ponto de recuperação (RPO) e um objetivo de tempo de recuperação (RTO) menores em comparação com o uso de snapshots do Hyperdisk para recuperação.
Os discos Hyperdisk equilibrado de alta disponibilidade são uma opção quando o desempenho de gravação é menos importante do que a redundância de dados em várias zonas.
Os discos do Hyperdisk equilibrado de alta disponibilidade têm IOPS e capacidade de processamento personalizáveis. Para mais informações sobre o desempenho e as limitações do Hyperdisk equilibrado de alta disponibilidade, consulte Sobre o Hyperdisk.
Quando você precisa de mais espaço em disco ou de um melhor desempenho, é possível modificar os discos do Hyperdisk equilibrado de alta disponibilidade para adicionar mais espaço de armazenamento, capacidade de processamento e IOPS.
Confiabilidade
O Compute Engine replica os dados dos discos do Hyperdisk equilibrado de alta disponibilidade para as zonas especificadas quando você criou os discos. Os dados de cada réplica são distribuídos por várias máquinas físicas dentro da zona para garantir a redundância.
Assim como no Hyperdisk, é possível criar snapshots de discos do Hyperdisk equilibrado de alta disponibilidade para se proteger contra a perda de dados devido a um erro do usuário. Os snapshots são incrementais e levam apenas alguns minutos para serem criados, mesmo quando os discos estão anexados a VMs em execução.
Como compartilhar volumes do Hyperdisk entre VMs
Para alguns volumes do Hyperdisk, é possível ativar o acesso simultâneo ao volume em várias VMs ativando o compartilhamento de disco. O compartilhamento de disco é útil para vários casos de uso, como a criação de aplicativos altamente disponíveis ou cargas de trabalho de machine learning grandes em que várias VMs precisam acessar o mesmo modelo ou dados de treinamento.
Para mais informações, consulte Compartilhar um disco entre VMs.
Pools de armazenamento de hiperdisco
Os pools de armazenamento de Hyperdisk facilitam a redução do custo total de propriedade (TCO) do armazenamento em blocos e simplificam o gerenciamento do armazenamento em blocos. Com os pools de armazenamento de Hyperdisk, é possível compartilhar um pool de capacidade e desempenho em até 1.000 discos em um único projeto. Como os pools de armazenamento oferecem provisionamento fino e redução de dados, você pode alcançar maior eficiência. Os pools de armazenamento simplificam a migração da SAN no local para a nuvem e também facilitam o fornecimento de cargas de trabalho com a capacidade e o desempenho necessários.
Você cria um pool de armazenamento com a capacidade e o desempenho estimados para todas as cargas de trabalho em um projeto em uma zona específica. Em seguida, crie discos nesse pool de armazenamento e anexe-os às VMs. Também é possível criar um disco no pool de armazenamento como parte da criação de uma nova VM. Cada pool de armazenamento contém um tipo de disco, como a capacidade de processamento de Hyperdisk. Há dois tipos de pools de armazenamento de Hyperdisk:
- Pool de armazenamento equilibrado de Hyperdisk: para cargas de trabalho de uso geral que são melhor atendidas por discos do Hyperdisk equilibrado.
- Pool de armazenamento de capacidade de processamento do Hyperdisk: para streaming, dados frios e cargas de trabalho de análise que são melhor atendidas por discos de capacidade de processamento do Hyperdisk
Opções de provisionamento de capacidade
A capacidade do pool de armazenamento de Hyperdisk pode ser provisionada de duas maneiras:
- Provisionamento de capacidade padrão
- Com o provisionamento de capacidade padrão, você cria discos no pool de armazenamento até que o tamanho total de todos os discos atinja a capacidade provisionada. Os discos em um pool de armazenamento com provisionamento de capacidade padrão consomem capacidade de maneira semelhante aos discos que não são do pool, em que a capacidade é consumida quando você cria os discos.
- Provisionamento avançado de capacidade
O provisionamento de capacidade avançado permite compartilhar um pool de provisionamento fino e capacidade de armazenamento com dados reduzidos em todos os discos de um pool de armazenamento. Você vai receber cobranças pela capacidade provisionada do pool de armazenamento.
É possível provisionar até 500% da capacidade provisionada do pool de armazenamento para discos em um pool de armazenamento de capacidade avançada. Apenas a quantidade de dados gravada em um disco no pool de armazenamento consome a capacidade do pool. A redução automática de dados pode reduzir ainda mais o consumo da capacidade do pool de armazenamento.
Se a utilização de capacidade de um pool de armazenamento de capacidade avançada atingir 80% da capacidade provisionada, os pools de armazenamento de Hyperdisk vão tentar adicionar capacidade automaticamente ao pool de armazenamento para evitar erros relacionados à capacidade insuficiente.
Exemplo
Suponha que você tenha um pool de armazenamento com 10 TiB de capacidade provisionada.
Com o provisionamento de capacidade padrão:
- É possível provisionar até 10 TiB de capacidade agregada do Hyperdisk ao criar discos no pool de armazenamento. Você vai receber uma cobrança pelos 10 TiB de capacidade provisionada do pool de armazenamento.
- Se você criar um único disco no pool de armazenamento com 5 TiB de tamanho e gravar 2 TiB no disco, a capacidade usada do pool de armazenamento será de 5 TiB.
Com o provisionamento de capacidade avançada:
- É possível provisionar até 50 TiB de capacidade agregada do Hyperdisk ao criar discos no pool de armazenamento. Você vai receber uma cobrança pelos 10 TiB de capacidade provisionada do pool de armazenamento.
- Se você criar um único disco no pool de armazenamento com 5 TiB de tamanho, gravar 3 TiB de dados no disco e a redução de dados reduzir a quantidade de dados gravados para 2 TiB, a capacidade usada do pool de armazenamento será de 2 TiB.
Opções de provisionamento de performance
O desempenho do pool de armazenamento de Hyperdisk pode ser provisionado de duas maneiras:
- Provisionamento de desempenho padrão
O provisionamento de desempenho padrão é a melhor opção para os seguintes tipos de cargas de trabalho:
- Cargas de trabalho que não podem ser concluídas se o desempenho for limitado pelos recursos do pool de armazenamento
- Cargas de trabalho em que os discos no pool de armazenamento provavelmente têm picos de desempenho correlacionados, por exemplo, discos de dados para bancos de dados que estão no pico de utilização todas as manhãs.
O pool de armazenamento de desempenho padrão não se beneficia do provisionamento fino e não reduz significativamente o TCO de desempenho. Com o provisionamento de performance padrão, você cria discos no pool de armazenamento até que o total de IOPS provisionadas ou a capacidade de processamento de todos os discos atinja a quantidade provisionada do pool de armazenamento. Os discos em um pool de armazenamento com provisionamento de desempenho padrão consomem IOPS e capacidade de processamento de maneira semelhante aos discos que não são do pool, em que você provisiona a quantidade de IOPS e capacidade de processamento ao criar os discos. Você vai receber cobranças pelo total de IOPS e capacidade de processamento provisionadas para o pool de armazenamento.
Em um pool de armazenamento de Hyperdisk equilibrado com desempenho padrão, os primeiros 3.000 IOPS e 140 MiBps de capacidade de processamento de cada disco no pool de armazenamento (o valor de referência) não consomem recursos do pool de armazenamento. Quando você cria discos no pool de armazenamento, as IOPS e a capacidade de processamento que excedem os valores de referência consomem IOPS e capacidade do pool de armazenamento.
Além disso, os discos criados em um pool de armazenamento de desempenho padrão não compartilham recursos de desempenho com o restante do pool de armazenamento. A quantidade agregada de desempenho de todos os discos criados no pool de armazenamento não pode exceder o total de IOPS provisionadas ou a capacidade de processamento do pool de armazenamento.
- Provisionamento de desempenho avançado
Os pools de armazenamento com provisionamento de desempenho avançado aproveitam o provisionamento fino para aumentar a eficiência de desempenho e reduzir o TCO de desempenho do armazenamento em blocos. O provisionamento de desempenho avançado permite compartilhar um pool de desempenho provisionado em todos os discos de um pool de armazenamento. O pool de armazenamento aloca dinamicamente recursos de desempenho como os discos que o pool de armazenamento lê e grava dados. Apenas a quantidade de IOPS e capacidade de processamento usadas por um disco no pool de armazenamento consome IOPS e capacidade de processamento do pool de armazenamento. Como os pools de armazenamento de desempenho avançado são pouco provisionados, você pode alocar mais IOPS ou capacidade de processamento para os discos no pool de armazenamento do que você provisionou para o pool de armazenamento, até 500% das IOPS ou da capacidade de processamento provisionada para o pool de armazenamento. Assim como no desempenho padrão, você vai receber uma cobrança pelas IOPS e pela capacidade de processamento provisionadas do pool de armazenamento.
Em um pool de armazenamento Hyperdisk equilibrado com provisionamento de desempenho avançado, os discos não têm valor de referência de desempenho. Cada operação de leitura e gravação de um disco do Hyperdisk equilibrado no pool de armazenamento consome recursos do pool.
Quando a utilização de desempenho agregado de todos os discos no pool de armazenamento atinge a quantidade total de desempenho provisionada para o pool de armazenamento, os discos podem encontrar uma disputa de desempenho. Como resultado, o provisionamento avançado de desempenho é mais adequado para cargas de trabalho que não têm horários de pico de uso altamente correlacionados. Se todas as cargas de trabalho atingirem o pico ao mesmo tempo, o pool de armazenamento de desempenho avançado pode atingir os limites de desempenho do pool de armazenamento, o que resulta em contenção de recursos de desempenho.
Se uma contenção por recursos de desempenho for detectada em um pool de armazenamento de desempenho avançado para quaisquer discos nos pools, o recurso de crescimento automático tentará aumentar automaticamente as IOPS ou capacidade de processamento disponíveis para os discos no pool de armazenamento para evitar problemas de desempenho.
Exemplo
Suponha que você tenha um pool de armazenamento Hyperdisk Balanced com 100.000 IOPS provisionadas.
Com o provisionamento de desempenho padrão:
- É possível provisionar até 100.000 IOPS agregados ao criar discos de Hyperdisk Balanced no pool de armazenamento.
- Você vai receber uma cobrança pelas 100.000 IOPS de desempenho provisionadas do pool de armazenamento Hyperdisk Balanced.
Assim como os discos criados fora de um pool de armazenamento, os discos Hyperdisk Balanced em pools de armazenamento de desempenho padrão são provisionados automaticamente com até 3.000 IOPS de referência e 140 MiB/s de capacidade de processamento de valor de referência. O desempenho deste valor de referência não é contabilizado no desempenho provisionado para o pool de armazenamento. Somente quando você adiciona discos ao pool de armazenamento com desempenho provisionado acima do valor de referência é que ele é contabilizado para o desempenho provisionado do pool de armazenamento. Por exemplo:
- Um disco provisionado com 3.000 IOPS usa 0 IOPS do pool, e o pool ainda tem 100.000 IOPS provisionadas disponíveis para outros discos.
- Um disco provisionado com 13.000 IOPS usa 10.000 IOPS de pool, e o pool tem 90.000 IOPS provisionadas restantes que podem ser alocadas para outros discos no pool de armazenamento.
Com o provisionamento de desempenho avançado:
- É possível provisionar até 500.000 IOPS de desempenho agregado do Hyperdisk ao criar discos no pool de armazenamento.
- Você será cobrado por 100.000 IOPS provisionadas pelo pool de armazenamento.
- Se você criar um único disco (
Disk1) no pool de armazenamento que tenha 5.000 IOPS, você não consome nenhuma IOPS das IOPS provisionadas do pool de armazenamento. No entanto, a quantidade de IOPS que você pode provisionar para novos discos criados no pool de armazenamento agora é de 495.000. - Se
Disk1começar a ler e gravar dados e usar o máximo de 5.000 IOPS em um determinado minuto, 5.000 IOPS serão consumidas pelas IOPS provisionadas pelo pool de armazenamento. Todos os outros discos criados no mesmo pool de armazenamento podem usar um máximo agregado de 95.000 IOPS no mesmo minuto sem entrar em conflito.
Como mudar a capacidade e o desempenho provisionados do pool de armazenamento de Hyperdisk
É possível aumentar ou diminuir a capacidade provisionada, as IOPS e a capacidade de processamento do pool de armazenamento conforme as cargas de trabalho são dimensionadas. Com um pool de armazenamento de capacidade ou desempenho avançado, qualquer capacidade ou desempenho adicional fica disponível para todos os discos novos e existentes no pool de armazenamento. Além disso, o Compute Engine tenta modificar automaticamente o pool de armazenamento da seguinte maneira:
- Capacidade avançada: quando o pool de armazenamento atinge 80% da capacidade provisionada usada, o Compute Engine tenta adicionar mais capacidade automaticamente ao pool de armazenamento.
- Desempenho avançado: se o pool de armazenamento tiver contenção prolongada devido a superutilização, o Compute Engine tentará aumentar as IOPS ou a capacidade de processamento do pool de armazenamento.
Informações adicionais sobre o pool de armazenamento do Hyperdisk
Para saber como usar os pools de armazenamento do Hyperdisk, acesse estes links:
- Sobre os pools de armazenamento
- Criar pools de armazenamento
- Adicionar discos a VMs usando um pool de armazenamento
- Gerenciar pools de armazenamento
- Revisar as métricas do pool de armazenamento
Discos SSD locais
Os discos SSD locais são fisicamente anexados ao servidor que hospeda a VM. Os discos SSD locais têm maior capacidade de processamento e menor latência do que os discos permanentes padrão e SSD. Os dados armazenados em um disco SSD local permanecem somente até você interromper ou excluir a instância. É possível anexar vários discos SSD locais à VM, dependendo do número de vCPUs.
O tamanho de cada disco SSD local é fixado em 375 GiB, exceto para VMs Z3 que usam disco SSD local de 3 TiB. Para ter mais armazenamento, adicione vários discos SSD locais à VM ao criá-la. O número máximo de discos SSD locais que podem ser anexados a uma VM depende do tipo de máquina e do número de vCPUs em uso.
Permanência de dados em discos SSD locais
Leia Persistência de dados do SSD local para saber quais eventos preservam os dados do seu SSD local e quais eventos podem fazer com que eles não sejam recuperáveis.
SSDs locais e tipos de máquina
É possível anexar discos SSD locais à maioria dos tipos de máquinas disponíveis no Compute Engine, conforme mostrado na tabela Comparação de séries de máquinas. No entanto, há restrições com relação ao número de discos SSD locais que podem ser anexados com base em cada tipo de máquina. Para mais informações, consulte Escolher um número válido de discos SSD locais.
Limites de capacidade com discos SSD locais
A capacidade máxima de disco SSD local que você pode ter para uma VM é:
| Tipo de máquina | Tamanho do disco SSD local | Número de discos | Capacidade máxima |
|---|---|---|---|
| Z3 | 3 TiB | 12 | 36 TiB |
c3d-standard-360-lssd |
375 GiB | 32 | 12 TiB |
c3d-highmem-360-lssd |
375 GiB | 32 | 12 TiB |
c3-standard-176-lssd |
375 GiB | 32 | 12 TiB |
| N1, N2 e N2D | 375 GiB | 24 | 9 TiB |
| N1, N2 e N2D | 375 GiB | 16 | 6 TiB |
| A3 | 375 GiB | 16 | 6 TiB |
| C2, C2D, A2 Padrão, M1 e M3 | 375 GiB | 8 | 3 TiB |
| A2 Ultra | 375 GiB | 8 | 3 TiB |
Limitações dos discos SSD locais
O SSD local tem as seguintes limitações:
- Para atingir os limites máximos de IOPS, use uma instância de VM com 32 ou mais vCPUs.
- Não é possível anexar discos SDD locais a instâncias com tipos de máquina de núcleo compartilhado.
- Não é possível anexar discos SSD locais aos tipos de máquina N4, H3, M2 E2 e Tau T2A.
- Não é possível usar chaves de criptografia fornecidas pelo cliente com discos SSD locais. O Compute Engine criptografa automaticamente os dados quando eles são gravados no espaço de armazenamento SSD local.
Desempenho
Os discos SSD locais oferecem IOPS muito altas e baixa latência. Ao contrário do disco permanente, você precisa gerenciar a divisão dos discos SSD locais por conta própria.
O desempenho do SSD local depende de vários fatores. Para mais informações, consulte Desempenho do SSD local e Como otimizar o desempenho do SSD local.
Buckets do Cloud Storage
Os buckets do Cloud Storage são a opção de armazenamento mais flexível, escalonável e durável para suas VMs. Se os aplicativos não exigirem a menor latência de Hyperdisk, Persistent Disks, e SSDs locais, é possível armazenar os dados em um bucket do Cloud Storage.
Conecte sua VM a um bucket do Cloud Storage quando a latência e a capacidade de processamento não forem prioridade e quando você precisar compartilhar dados com facilidade entre várias VMs ou zonas.
Propriedades dos buckets do Cloud Storage
Consulte as seções a seguir para entender o comportamento e as características dos buckets do Cloud Storage.
Desempenho
O desempenho dos buckets do Cloud Storage depende da classe de armazenamento selecionada e do local do bucket em relação à VM.
Usar a classe Standard Storage do Cloud Storage no mesmo local em que sua VM oferece um desempenho comparável ao Hyperdisk ou discos permanentes , mas com maior latência e características de capacidade de processamento menos consistentes. O uso da classe de armazenamento padrão em um local birregional armazena seus dados de maneira redundante em duas regiões. Para um desempenho ideal ao usar uma birregião, sua VM precisa estar localizada em uma das regiões que fazem parte da birregião.
As classes Nearline Storage, Coldline Storage e Archive Storage são principalmente para arquivamento de dados de longo prazo. Ao contrário da classe de armazenamento Standard, essas classes têm durações de armazenamento mínimas e geram custos de recuperação de dados. Por isso, elas são melhores para o armazenamento a longo prazo de dados que são acessados com pouca frequência.
Confiabilidade
Todos buckets do Cloud Storage têm redundância incorporada para proteger seus dados contra falhas em equipamentos, bem como garantir a disponibilidade deles durante eventos de manutenção de datacenter. As somas de verificação são calculadas para todas as operações do Cloud Storage para garantir que você consiga ler exatamente aquilo que gravou.
Flexibilidade
Ao contrário do Hyperdisk ou dos discos permanentes, os buckets do Cloud Storage não estão restritos à zona em que a VM está localizada. Além disso, é possível ler e gravar dados em um bucket a partir de várias VMs simultaneamente. Por exemplo, é possível configurar VMs em várias zonas para ler e gravar dados no mesmo bucket, em vez de replicar os dados para um Hyperdisk ou discos permanentes em várias zonas.
Criptografia do Cloud Storage
O Compute Engine criptografa automaticamente os dados antes de saírem da VM para os buckets do Cloud Storage. Você não precisa criptografar os arquivos nas VMs antes de gravá-los em um bucket.
Assim como os volumes de discos permanentes, é possível criptografar buckets com suas próprias chaves de criptografia.Como gravar e ler dados dos buckets do Cloud Storage
Grave e leia arquivos dos buckets do Cloud Storage usando a
ferramenta de linha de comando gcloud storage
ou uma biblioteca de cliente do Cloud Storage.
Armazenamento do gcloud
Por padrão, a ferramenta de linha de comando gcloud storage está instalada na maioria das VMs que usa
imagens públicas.
Se a VM não tiver a ferramenta de linha de comando gcloud storage, instale-a.
Conecte-se às suas VMs do Linux ou às suas VMs do Windows usando SSH ou outro método de conexão.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.

Se você nunca usou
gcloud storagenessa VM, configure as credenciais com a gcloud CLI.gcloud init
Por outro lado, se a instância estiver configurada para usar uma conta de serviço com um escopo de Cloud Storage, pule esta etapa.
Use a ferramenta
gcloud storagepara criar um bucket e ler e gravar dados neles. Para gravar ou ler dados de um bucket, você precisa ter acesso a ele. Também é possível ler os dados de qualquer bucket que tenha acesso público.Também é possível fazer streaming de dados para o Google Cloud Storage.
Biblioteca de cliente
Se você configurou a VM para usar uma conta de serviço com um escopo do Cloud Storage, utilize a API Cloud Storage para gravar e ler dados dos buckets do Cloud Storage.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.
Instale e configure uma biblioteca de cliente na linguagem que preferir.
Se necessário, siga os exemplos de código de inserção para criar um bucket do Cloud Storage na VM.
Siga os exemplos de código de inserção para gravar e ler dados e inclua o código no app que grava ou lê um arquivo de um bucket do Cloud Storage.
A seguir
- Adicionar um volume do Hyperdisk à VM.
- Adicionar um volume de Persistent Disk à VM.
- Adicione um disco regional à VM.
- Criar uma VM com discos SSD locais.
- Crie um servidor de arquivos ou sistema de arquivos distribuídos.
- Revise as cotas dos discos.
- Monte um disco de RAM na VM.