VM에 디스크를 추가하려면 Compute Engine에서 제공하는 블록 스토리지 옵션 중 하나를 선택합니다. 다음 스토리지 옵션은 각각 고유한 가격과 성능 특성을 가지고 있습니다.
- Google Cloud Hyperdisk 볼륨은 동적으로 크기를 조정할 수 있는 볼륨 및 구성 가능한 성능을 포함하는 Compute Engine의 네트워크 스토리지입니다. 영구 디스크에 비해 성능, 유연성, 효율성이 상당히 높습니다. Hyperdisk 균형 고가용성은 두 영역에 있는 디스크 간에 데이터를 동기식으로 복제할 수 있으므로 영역을 사용할 수 없을 때 보호 기능을 제공합니다.
- Hyperdisk Storage Pool을 사용하면 Hyperdisk 용량과 성능을 집계하여 구매한 다음 이 스토리지 풀에서 VM용 디스크를 만들 수 있습니다.
- 영구 디스크 볼륨은 고성능 중복 네트워크 스토리지를 제공합니다. 각 Persistent Disk 볼륨은 수백 개의 물리적 디스크 간에 스트라이프로 구성됩니다.
- 기본적으로 VM은 영역별 Persistent Disk를 사용하고
us-west1-c와 같이 단일 영역 내에 있는 볼륨에 데이터를 저장합니다. - 또한 두 영역에 배치된 디스크 간에 데이터를 동기식으로 복제하고 영역이 사용 불가능할 때 보호 기능을 제공하는 리전 Persistent Disk 볼륨을 만들 수 있습니다.
- 기본적으로 VM은 영역별 Persistent Disk를 사용하고
- 로컬 SSD 디스크는 VM과 동일한 서버에 직접 연결되는 물리적 드라이브입니다. 더 나은 성능을 제공할 수 있지만 일시적입니다.
비용 비교는 디스크 가격 책정을 참조하세요. 어떤 옵션을 사용해야 할지 잘 모르겠다면 가장 일반적인 솔루션을 사용하면 됩니다. 즉, 이전 세대 머신 시리즈의 경우 VM에 균형 있는 영구 디스크 볼륨을 추가하고, 최신 머신 계열의 경우에는 컴퓨팅 인스턴스에 Hyperdisk 볼륨을 추가합니다.
Compute Engine은 블록 스토리지 외에 파일 및 객체 스토리지 옵션도 제공합니다. 스토리지 옵션을 검토하고 비교하려면 스토리지 옵션 검토를 참고하세요.
소개
기본적으로, 각 Compute Engine VM에는 운영체제가 포함된 단일 부팅 디스크가 있습니다. 부팅 디스크 데이터는 일반적으로 Persistent Disk 또는Hyperdisk 균형 볼륨에 저장됩니다. 애플리케이션에 추가 저장 공간이 필요하면 다음 스토리지 볼륨 중 하나 이상을 VM에 프로비저닝할 수 있습니다.
각 스토리지 옵션에 대해 자세히 알아보려면 다음 표를 검토하세요.
| 균형있는 영구 디스크 |
SSD 영구 디스크 |
표준 영구 디스크 |
익스트림 Persistent Disk |
하이퍼디스크 균형 | Hyperdisk ML | 하이퍼디스크 익스트림 | 하이퍼디스크 처리량 | 로컬 SSD | |
|---|---|---|---|---|---|---|---|---|---|
| 스토리지 유형 | 비용 효율적이고 안정적인 블록 스토리지 | 빠르고 안정적인 블록 스토리지 | 효율적이고 안정적인 블록 스토리지 | IOPS를 맞춤설정할 수 있는 최고 성능의 영구 디스크 블록 스토리지 옵션 | 저렴한 비용으로 까다로운 워크로드를 처리할 수 있는 고성능 | 머신러닝 워크로드에 최적화된 최고 처리량 스토리지 | IOPS를 맞춤설정할 수 있는 가장 빠른 블록 스토리지 옵션 | 맞춤설정 가능한 처리량을 제공하는 비용 효율적이고 처리량이 우수한 블록 스토리지 | 고성능 로컬 블록 스토리지 |
| 디스크당 최소 용량 | 지역: 10GiB 지역: 10GiB |
지역: 10GiB 지역: 10GiB |
지역: 10GiB 지역: 200GiB |
500GiB | 영역 및 리전: 4GiB | 4GiB | 64GiB | 2TiB | 375GiB, 3TiB(Z3 사용) |
| 디스크당 최대 용량 | 64TiB | 64TiB | 64TiB | 64TiB | 64TiB | 64TiB | 64TiB | 32TiB | 375GiB, 3TiB(Z3 사용) |
| 용량 증가 | 1GiB | 1GiB | 1GiB | 1GiB | 1GiB | 1GiB | 1GiB | 1GiB | 머신 유형에 따라 다름† |
| VM당 최대 용량 | 257TiB* | 257TiB* | 257TiB* | 257TiB* | 512TiB* | 512TiB* | 512TiB* | 512TiB* | 36TiB |
| 액세스 범위 | 영역 | 영역 | 영역 | 영역 | 영역 | 영역 | 영역 | 영역 | 인스턴스 |
| 데이터 중복 | 영역 및 멀티 영역 | 영역 및 멀티 영역 | 영역 및 멀티 영역 | 영역 | 영역 및 멀티 영역 | 영역 | 영역 | 영역 | 없음 |
| 저장 데이터 암호화 | 예 | 예 | 예 | 예 | 예 | 예 | 예 | 예 | 예 |
| 커스텀 암호화 키 | 예 | 예 | 예 | 예 | 예‡ | 예 | 예 | 예 | 아니요 |
| 방법 | 익스트림 영구 디스크 추가 | 로컬 SSD 추가 | |||||||
Google Cloud에서 제공하는 저장소 옵션 외에도 VM에 대체 저장소 솔루션을 배포할 수 있습니다.
- Compute Engine에 파일 서버 또는 분산 파일 시스템을 생성하여 NFSv3 및 SMB3 기능이 있는 네트워크 파일 시스템으로 사용할 수 있습니다.
- VM 메모리 내에 RAM 디스크를 마운트하여 처리량이 높고 지연 시간이 낮은 블록 스토리지 볼륨을 생성할 수 있습니다.
블록 스토리지 리소스마다 성능 특성이 다릅니다. 저장소 크기와 성능 요구사항을 고려하여 VM에 적합한 블록 스토리지 유형을 결정하세요.
성능 한도에 대한 자세한 내용은 다음을 참조하세요.
Persistent Disk
영구 디스크 볼륨은 데스크톱 또는 서버의 물리적 디스크와 같이 가상 머신(VM) 인스턴스가 액세스할 수 있는 내구성이 있는 네트워크 스토리지 기기입니다. 각 영구 디스크 볼륨의 데이터는 여러 물리적 디스크에 분산됩니다. Compute Engine은 중복을 보장하고 성능을 최적화하기 위해 물리적 디스크 및 데이터 분산을 관리합니다.
영구 디스크 볼륨은 VM과는 별개의 위치에 존재하므로 VM을 삭제한 후에도 영구 디스크 볼륨을 분리하거나 이동하여 데이터를 보존할 수 있습니다. 영구 디스크 성능은 크기에 따라 자동으로 확장되므로 기존 영구 디스크 볼륨의 크기를 조절하거나 영구 디스크 볼륨을 VM에 추가하여 성능 및 저장공간 요구사항을 충족할 수 있습니다.
영구 디스크 유형
영구 디스크를 구성할 때 다음 디스크 유형 중 하나를 선택할 수 있습니다.
- 균형 있는 영구 디스크(
pd-balanced)- 성능(pd-ssd) 영구 디스크의 대안
- 성능과 비용 간의 균형. 대용량 VM을 제외한 대부분의 VM 형태에서 이러한 디스크의 최대 IOPS는 SSD 영구 디스크와 같고 1GiB당 IOPS는 낮습니다. 이 디스크 유형은 대부분의 범용 애플리케이션에 적합한 성능 수준을 표준 영구 디스크와 성능(pd-ssd) 영구 디스크 사이의 가격으로 제공합니다
- 솔리드 스테이트 드라이브(SSD)에서 지원합니다.
- 성능(SSD) 영구 디스크(
pd-ssd)- 표준 영구 디스크보다 짧은 지연 시간과 더 많은 IOPS가 필요한 엔터프라이즈 애플리케이션 및 고성능 데이터베이스에 적합합니다.
- 솔리드 스테이트 드라이브(SSD)에서 지원합니다.
- 표준 영구 디스크(
pd-standard)- 순차 I/O를 주로 사용하는 대용량 데이터 처리 워크로드에 적합
- 표준 하드 디스크 드라이브(HDD)에서 지원
- 익스트림 영구 디스크(
pd-extreme)- 임의 액세스 워크로드와 일괄 처리량 모두에 고성능을 일관되게 제공합니다.
- 고급 데이터베이스 워크로드를 위해 설계되었습니다.
- 대상 IOPS를 프로비저닝할 수 있습니다.
- 솔리드 스테이트 드라이브(SSD)에서 지원합니다.
- 제한된 수의 머신 유형으로 사용할 수 있습니다.
Google Cloud 콘솔에서 디스크를 만드는 경우 기본 디스크 유형은 pd-balanced입니다. gcloud CLI 또는 Compute Engine API를 사용하여 디스크를 만드는 경우 기본 디스크 유형은 pd-standard입니다.
머신 유형 지원에 관한 자세한 내용은 다음을 참고하세요.
영구 디스크 내구성
디스크 내구성은 Google 데이터 센터에서 하드웨어 오류, 치명적인 이벤트가 발생할 가능성, 격리 방식, 엔지니어링 프로세스에 대한 가정과 함께 각 디스크 유형에 사용되는 내부 인코딩을 고려해서 일반적인 기간 동안 일반적인 디스크를 사용할 때 기본적으로 데이터 손실이 발생할 가능성을 나타냅니다. 영구 디스크 데이터 손실 이벤트는 발생할 가능성이 매우 낮으며, 지금까지 하드웨어 조정 오류, 소프트웨어 버그 또는 이 둘의 조합의 결과로 발생했습니다. Google은 또한 산업 전반에서 자동 데이터 손상이 발생할 위험을 완화하기 위해 많은 조치를 취하고 있습니다 고객의 실수로 인한 디스크 삭제와 같은 Google Cloud 고객의 작업자 오류는 영구 디스크 내구성의 범위에서 벗어납니다.
내부 데이터 인코딩과 복제로 인해 리전 영구 디스크에서 데이터 손실이 발생할 위험이 매우 적습니다. 리전 영구 디스크는 영역 영구 디스크보다 두 배 더 많은 복제본을 제공하고 동일한 리전의 두 영역 사이에 복제본을 분산하므로 고가용성을 제공하고 전체 데이터 센터가 손실되어 복구할 수 없는 경우(발생 가능성은 희박) 재해 복구에 사용될 수 있습니다. 장기 중단 중에 기본 영역을 사용할 수 없게 되면 두 번째 영역의 추가 복제본에 즉시 액세스할 수 있습니다.
다음 표는 각 디스크 유형의 설계에 대한 내구성을 보여줍니다. 99.999% 내구성은 디스크 1,000개를 디스크 하나가 손실되지 않고 수백 년 동안 사용할 수 있다는 의미입니다.
| 영역별 표준 영구 디스크 | 영역별 균형 있는 영구 디스크 | 영역별 SSD 영구 디스크 | 영역별 익스트림 영구 디스크 | 리전별 표준 영구 디스크 | 리전별로 균형 있는 영구 디스크 | 리전별 SSD 영구 디스크 |
|---|---|---|---|---|---|---|
| 99.99%보다 좋음 | 99.999%보다 좋음 | 99.999%보다 좋음 | 99.9999%보다 좋음 | 99.999%보다 좋음 | 99.9999%보다 좋음 | 99.9999%보다 좋음 |
영역 영구 디스크
사용 편의성
Compute Engine에서 디스크 관리 작업을 대부분 처리하므로 사용자가 파티션 나누기, 중복 디스크 배열, 하위 볼륨 관리를 수행할 필요가 없습니다. 일반적으로 더 큰 논리 볼륨을 만들 필요는 없지만 원하는 경우 보조 연결 영구 디스크 용량을 VM당 257TiB로 확장하고 이 방식을 영구 디스크에 적용할 수 있습니다. 파티션 테이블이 없는 단일 파일 시스템으로 영구 디스크 볼륨을 포맷하면 시간을 절약하고 최고의 성능을 얻을 수 있습니다.
데이터를 여러 개의 고유한 볼륨으로 분리해야 하는 경우 기존 디스크를 여러 파티션으로 나누는 대신 추가 디스크를 생성합니다.
영구 디스크 볼륨에 추가 공간이 필요하면 파티션을 다시 나누고 포맷하는 대신 디스크 크기를 조절합니다.
성능
영구 디스크 성능은 예측 가능하여 VM에서 프로비저닝된 vCPU의 제한에 도달할 때까지 프로비저닝된 용량을 따라 선형적으로 확장됩니다. 성능 확장 제한과 최적화에 대한 자세한 내용은 성능 요구사항을 충족하도록 디스크 구성을 참조하세요.
표준 영구 디스크는 순차 읽기/쓰기 작업을 처리하는 데 효율적이고 경제적이지만 고속 무작위 초당 입출력 작업 수(IOPS)를 처리하는 데는 최적화되어 있지 않습니다. 앱에서 높은 속도의 무작위 IOPS가 필요한 경우 SSD 또는 익스트림 영구 디스크를 사용하세요. SSD 영구 디스크는 한 자릿수의 밀리초 지연 시간을 위해 설계되었습니다. 확인된 지연 시간은 애플리케이션에 따라 다릅니다.
Compute Engine은 영구 디스크 볼륨의 성능 및 확장을 자동으로 최적화합니다. 최적의 성능을 얻기 위해 디스크를 여러 개 스트라이프하거나 미리 가동하지 않아도 됩니다. 추가 디스크 공간이나 더 높은 성능이 필요한 경우 디스크 크기를 조절하고 vCPU를 더 추가하여 저장공간, 처리량, IOPS를 더 늘릴 수 있습니다. 영구 디스크 성능은 VM에 연결된 총 영구 디스크 용량 및 VM에 있는 vCPU 수를 기반으로 합니다.
부팅 기기일 때는 표준 영구 디스크를 사용해 비용을 줄일 수 있습니다. 소형 10GiB 영구 디스크 볼륨은 기본 부팅 및 패키지 관리 사용 사례에 사용할 수 있습니다. 하지만 부팅 기기를 더욱 포괄적으로 사용할 수 있는 일관된 성능을 보장하려면 균형 있는 영구 디스크를 부팅 디스크로 사용합니다.
각 영구 디스크 쓰기 작업은 VM의 누적 네트워크 이그레스 트래픽에 영향을 줍니다. 즉, 영구 디스크 쓰기 작업이 VM의 네트워크 이그레스 상한으로 제한됩니다.
안정성
영구 디스크에는 장비 고장 시 데이터를 보호하고 데이터 센터 유지보수 이벤트를 통해 데이터 가용성을 보장하는 중복 기능이 기본 제공됩니다. 모든 영구 디스크 작업에 대해 체크섬이 계산되므로 현재 읽고 있는 데이터가 사용자가 기록한 데이터임을 보장할 수 있습니다.
또한 영구 디스크 스냅샷을 생성하여 사용자 오류로 인한 데이터 손실을 방지할 수 있습니다. 스냅샷은 증분적이며 실행 중인 VM에 연결된 디스크를 스냅샷으로 작성할 경우에도 몇 분이면 생성됩니다.
멀티 작성자 모드
최대 2개의 N2 VM에 SSD 영구 디스크를 멀티 작성자 모드로 동시에 연결하여 두 VM에서 모두 디스크를 읽고 쓸 수 있습니다.
멀티 작성자 모드의 영구 디스크는 공유 블록 스토리지 기능을 제공하고 가용성이 높은 공유 파일 시스템 및 데이터베이스를 빌드하기 위한 인프라 기초를 제공합니다. 이러한 특수 파일 시스템과 데이터베이스는 공유 블록 스토리지와 함께 작동하고 SCSI 영구 예약과 같은 도구를 사용하여 VM 간의 캐시 일관성을 처리하도록 설계되어야 합니다.
하지만 멀티 작성자 모드의 영구 디스크는 직접 사용해서는 안 되며 EXT4, XFS, NTFS와 같은 많은 파일 시스템은 공유 블록 스토리지와 함께 사용하도록 설계되지 않았다는 점에 유의해야 합니다. VM 간에 Persistent Disk를 공유할 때의 권장사항은 권장사항을 참조하세요.
완전 관리형 파일 스토리지가 필요하면 Compute Engine VM에 Filestore 파일 공유를 마운트할 수 있습니다.
새 영구 디스크 볼륨에 멀티 작성자 모드를 사용 설정하려면 새 영구 디스크를 만들고 gcloud CLI에서 --multi-writer 플래그를 지정하거나 Compute Engine API에서 multiWriter 속성을 지정합니다. 자세한 내용은 VM 간 영구 디스크 볼륨 공유를 참조하세요.
영구 디스크 암호화
Compute Engine은 데이터가 VM 외부에서 영구 디스크 저장공간으로 이동하기 전에 데이터를 자동으로 암호화합니다. 각 영구 디스크는 시스템 정의 키 또는 고객 제공 키를 사용하여 암호화된 상태로 유지됩니다. Google은 사용자가 제어하지 않는 방식으로 영구 디스크 데이터를 여러 물리적 디스크에 분산시킵니다.
영구 디스크 볼륨을 삭제하면 Google은 데이터를 복구할 수 없도록 암호화 키를 삭제합니다. 이 프로세스는 되돌릴 수 없습니다.
데이터를 암호화하는 데 사용되는 암호화 키를 제어하려면 자체 암호화 키를 사용하여 디스크를 생성하세요.
제한사항
영구 디스크 볼륨을 다른 프로젝트의 VM에 연결할 수 없습니다.
균형 있는 영구 디스크를 최대 10개의 VM에 읽기 전용 모드로 연결할 수 있습니다.
vCPU가 최소 1개 있는 커스텀 머신 유형 또는 사전 정의된 머신 유형의 경우 영구 디스크 볼륨을 최대 128개까지 연결할 수 있습니다.
각 영구 디스크 볼륨의 크기는 최대 64TiB일 수 있으므로 대용량 논리 볼륨을 생성하기 위해 디스크 배열을 관리할 필요가 없습니다. 각 VM은 제한된 양의 총 영구 디스크 공간과 제한된 수의 개별 영구 디스크 볼륨에만 연결할 수 있습니다. 사전 정의된 머신 유형 및 커스텀 머신 유형에는 동일한 영구 디스크 제한이 적용됩니다.
대부분의 VM에는 최대 128개의 영구 디스크 볼륨과 최대 257TiB의 총 디스크 공간을 연결할 수 있습니다. VM의 총 디스크 공간에는 부팅 디스크 크기가 포함됩니다.
공유 코어 머신 유형은 16개의 영구 디스크 볼륨과 총 3TiB의 영구 디스크 공간으로 제한됩니다.
64TiB보다 큰 논리 볼륨을 만들려면 특별히 고려해야 할 사항이 있습니다. 더 큰 논리 볼륨의 성능에 대한 자세한 내용은 논리 볼륨 크기를 참조하세요.
리전 영구 디스크
리전 영구 디스크 볼륨은 영역 영구 디스크와 비슷한 스토리지 품질을 갖습니다. 그러나 리전 영구 디스크 볼륨은 내구성 있는 스토리지를 제공하고 동일한 리전의 두 영역 간 데이터 복제를 지원합니다.
동기 디스크 복제 정보
새 Persistent Disk를 만들 때 한 영역에 디스크를 만들거나 동일한 리전 내의 두 영역 간에 디스크를 복제할 수 있습니다.
예를 들어 us-west1-a와 같은 한 영역에 하나의 디스크를 만들면 디스크 복사본이 하나만 생성됩니다. 이를 영역 디스크라고 합니다.
us-west1-b와 같은 리전 내 다른 영역에 디스크의 다른 사본을 저장하면 디스크의 가용성을 높일 수 있습니다.
동일한 리전의 두 개 영역에 복제된 Persistent Disk를 리전 Persistent Disk라고 합니다. Google Cloud Hyperdisk의 영역 간 동기식 복제에 Hyperdisk 균형 고가용성을 사용할 수도 있습니다.
리전 하나가 완전히 실패할 가능성은 없지만 영역 장애가 발생할 수 있습니다. 다음 이미지와 같이 리전 내 서로 다른 영역에 복제하면 가용성을 높이고 디스크 지연 시간을 줄일 수 있습니다. 두 복제 영역이 모두 실패하면 리전 전체 오류로 간주됩니다.
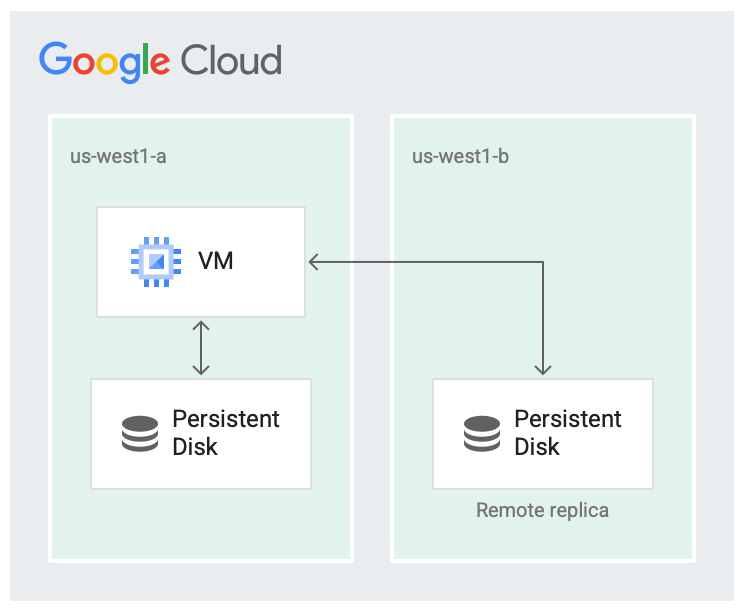
디스크가 두 영역에 복제됩니다.
복제된 시나리오에서는 가상 머신(VM)이 실행 중인 영역인 로컬 영역(us-west1-a)에서 데이터를 사용할 수 있습니다. 그런 다음 데이터는 다른 영역(us-west1-b)에 복제됩니다. 영역 중 하나는 VM이 실행 중인 영역과 같아야 합니다.
영역 서비스 중단이 발생하면 일반적으로 리전 Persistent Disk에서 실행 중인 워크로드를 다른 영역으로 장애 조치할 수 있습니다. 자세한 내용은 리전 Persistent Disk 장애 조치를 참조하세요.
리전 Persistent Disk의 설계 고려사항
Compute Engine에서 강력한 시스템을 설계하고 있거나 고가용성 서비스를 설계하고 있다면 스냅샷을 사용하여 데이터를 백업하는 등의 다른 권장사항과 함께 리전 Persistent Disk를 사용하세요. 또한 리전 Persistent Disk 볼륨은 리전 관리형 인스턴스 그룹과 함께 작동하도록 설계되었습니다.
성능
리전 영구 디스크 볼륨은 영구 디스크 스냅샷을 사용할 때와 비교 시 더 낮은 목표 복구 시간(RPO)과 복구 시간 목표(RTO)가 필요한 워크로드용으로 설계되었습니다.
리전 영구 디스크는 쓰기 성능이 여러 영역의 데이터 중복보다 중요하지 않은 경우에 사용할 수 있는 옵션입니다.
영역 Persistent Disk와 마찬가지로 리전 Persistent Disk도 vCPU 수를 늘려 VM에서 IOPS 및 처리량 성능을 향상시킬 수 있습니다. 이 제한 및 기타 제한에 대한 자세한 내용은 성능 요구사항을 충족하도록 디스크 구성을 참조하세요.
추가 디스크 공간이나 더 높은 성능이 필요한 경우 리전 디스크 크기를 조절하여 추가 저장소 공간, 처리량, IOPS를 추가할 수 있습니다.
안정성
Compute Engine은 사용자가 디스크를 생성하면 선택한 영역으로 리전 영구 디스크의 데이터를 복제합니다. 중복을 보장하기 위해 각 복제본의 데이터는 영역 내의 여러 물리적 머신에 확산됩니다.
영역 영구 디스크와 마찬가지로 영구 디스크의 스냅샷 만들기로 사용자 오류로 인한 데이터 손실을 방지할 수 있습니다. 스냅샷은 증분적이며 실행 중인 VM에 연결된 디스크를 스냅샷으로 작성할 경우에도 몇 분이면 생성됩니다.
제한사항
- 멕시코, 몬트리올, 오사카의 경우 물리적 데이터 센터 1~2곳에 영역 3개가 있습니다. 드문 경우지만 데이터 센터가 파손되면 이 리전에 저장된 데이터가 손실될 수 있으므로 데이터 보호 강화를 위해 비즈니스에 중요한 데이터를 두 번째 리전에 백업하는 것이 좋습니다.
- E2, N1, N2, N2D 머신 유형을 사용하는 VM에만 리전 Persistent Disk를 연결할 수 있습니다.
- Hyperdisk Balanced High Availability는 지원되는 머신 유형에만 연결할 수 있습니다.
- 이미지나 이미지에서 생성된 디스크에서는 리전 Persistent Disk를 만들 수 없습니다.
- 읽기 전용 모드를 사용할 때는 리전 균형 있는 영구 디스크를 최대 10개의 VM 인스턴스에 연결할 수 있습니다.
- 리전 표준 Persistent Disk 최소 크기는 200GiB입니다.
- 리전 Persistent Disk 또는Hyperdisk Balanced High Availability 볼륨의 크기는 늘릴 수만 있고 줄일 수는 없습니다.
- 리전 Persistent Disk 및 Hyperdisk Balanced High Availability 볼륨은 해당 영역 디스크와 성능 특성이 다릅니다. 자세한 내용은 블록 스토리지 성능을 참조하세요.
- 멀티 작성자 모드인 Hyperdisk Balanced High Availability 볼륨을 부팅 디스크로 사용할 수 없습니다.
- 영역 디스크를 클론하여 복제된 디스크를 만드는 경우 두 영역 복제본이 생성 시에 완전히 동기화되지 않습니다. 생성 후에는 평균적으로 3분 이내에 리전 디스크 클론을 사용할 수 있습니다. 그러나 디스크가 완전 복제 상태에 도달하고 복구 지점 목표(RPO)가 0에 근접할 때까지 10분 정도 기다려야 할 수 있습니다. 복제된 디스크가 완전히 복제되었는지 확인하는 방법을 알아보세요.
Google Cloud Hyperdisk
Google Cloud Hyperdisk는 Google의 차세대 블록 스토리지입니다. 스토리지 처리를 오프로드하고 동적으로 확장하여 스토리지 성능을 VM 유형 및 크기와 분리합니다. Hyperdisk는 Persistent Disk에 비해 성능, 유연성, 효율성이 상당히 높습니다.
하이퍼디스크 균형
Compute Engine용 하이퍼디스크 균형은 하이퍼디스크 익스트림의 성능이 필요하지 않은 비즈니스 라인(LOB) 애플리케이션, 웹 애플리케이션, 중간 계층 데이터베이스와 같은 다양한 사용 사례에 적합합니다. 동일한 영역의 여러 VM에서 동시에 동일한 디스크에 대한 쓰기 액세스 권한이 필요한 애플리케이션에도 하이퍼디스크 균형을 사용할 수 있습니다.
하이퍼디스크 균형 볼륨을 사용하면 워크로드의 용량, IOPS, 처리량을 동적으로 조정할 수 있습니다.
Hyperdisk ML
머신러닝 모델을 학습시키거나 서빙하기 위해 가속기를 사용하는 워크로드는 Hyperdisk ML을 사용해야 합니다. Hyperdisk ML 볼륨은 가장 빠르게 맞춤설정 가능한 처리량을 제공하며 20GiB보다 큰 모델에 가장 적합합니다. Hyperdisk ML은 여러 VM에서 동일한 볼륨에 대한 동시 읽기 액세스도 지원합니다.
Hyperdisk ML 볼륨의 용량 및 처리량을 동적으로 조정할 수 있습니다.
하이퍼디스크 익스트림
하이퍼디스크 익스트림은 사용 가능한 가장 빠른 블록 스토리지를 제공합니다. 가장 높은 처리량과 IOPS가 필요한 하이엔드 워크로드에 적합합니다.
하이퍼디스크 익스트림 볼륨을 사용하면 워크로드에 대해 용량과 IOPS를 동적으로 조정할 수 있습니다.
하이퍼디스크 처리량
하이퍼디스크 처리량은 Hadoop 및 Kafka, 비용에 민감한 앱을 위한 데이터 드라이브, 콜드 스토리지를 비롯한 수평 확장 분석에 적합합니다.
하이퍼디스크 처리량 볼륨을 사용하면 워크로드 용량 및 처리량을 동적으로 조정할 수 있습니다. 다운타임이나 워크로드 중단 없이 프로비저닝된 처리량 수준을 변경할 수 있습니다.
Hyperdisk 균형 고가용성
Hyperdisk 균형 고가용성은 3세대 이상 머신 시리즈에서 동기식 복제를 지원합니다. Hyperdisk 균형 고가용성은 리전 Persistent Disk와 마찬가지로 두 영역 간에 복구 지점 목표가0인 복제로 데이터 복원력을 지원합니다.
Hyperdisk 균형 고가용성 볼륨을 사용하면 워크로드의 용량, IOPS, 처리량을 동적으로 조정할 수 있습니다. 다운타임이나 워크로드 중단 없이 프로비저닝된 성능 및 용량 수준을 변경할 수 있습니다. 동일한 리전의 여러 VM에서 동시에 동일한 디스크에 대한 쓰기 액세스 권한이 필요한 경우 하이퍼디스크 균형 고가용성을 사용하세요.
하이퍼디스크 볼륨은 영구 디스크처럼 생성되고 관리되며, 프로비저닝된 IOPS 또는 처리량 수준을 설정하고 언제든지 이 값을 변경할 수 있는 추가 기능이 있습니다. 영구 디스크에서 하이퍼디스크로의 직접 마이그레이션 경로는 없습니다. 대신 스냅샷을 만들고 이 스냅샷을 새로운 하이퍼디스크 볼륨에 복원할 수 있습니다.
하이퍼디스크에 대한 자세한 내용은 하이퍼디스크 정보를 참조하세요.
하이퍼디스크의 내구성
디스크 내구성은 일반적인 기간 및 일반적인 디스크를 기준으로 기본적인 데이터 손실 가능성을 나타냅니다. 내구성은 다음과 같이 하드웨어 오류에 대한 일련의 가정을 통해 계산됩니다.
- 치명적인 이벤트 가능성
- 격리 방식
- Google 데이터 센터의 엔지니어링 프로세스
- 각 디스크 유형에 사용되는 내부 인코딩
하이퍼디스크 데이터 손실 이벤트는 매우 드뭅니다. Google은 또한 산업 전반에서 자동 데이터 손상이 발생할 위험을 완화하기 위해 많은 조치를 취하고 있습니다
고객의 실수로 인한 디스크 삭제와 같은 Google Cloud 고객의 작업자 오류는 하이퍼디스크 내구성의 범위에서 벗어납니다.
다음 표는 각 디스크 유형의 설계에 대한 내구성을 보여줍니다. 99.999% 내구성은 디스크 1,000개를 디스크 하나가 손실되지 않고 수백 년 동안 사용할 수 있다는 의미입니다.
| 하이퍼디스크 균형 | 하이퍼디스크 익스트림 | Hyperdisk ML | 하이퍼디스크 처리량 |
|---|---|---|---|
| 99.999%보다 좋음 | 99.9999%보다 좋음 | 99.999%보다 좋음 | 99.999%보다 좋음 |
하이퍼디스크 암호화
Compute Engine은 하이퍼디스크 볼륨에 쓰기를 수행할 때 데이터를 자동으로 암호화합니다. 고객 관리 암호화 키를 사용하여 암호화를 맞춤설정할 수도 있습니다.
하이퍼디스크 균형 고가용성
Hyperdisk 균형 고가용성 디스크는 동일한 리전의 두 영역 간 데이터 복제와 내구성 있는 스토리지를 제공합니다. Hyperdisk 균형 고가용성 볼륨에는 복제되지 않은 Hyperdisk 균형 디스크와 유사한 스토리지 한도가 있습니다.
Compute Engine에서 강력한 시스템을 설계하고 있거나 고가용성 서비스를 설계하고 있다면 스냅샷을 사용하여 데이터를 백업하는 등의 다른 권장사항과 함께 Hyperdisk 균형 고가용성 디스크를 사용하세요. Hyperdisk 균형 고가용성 디스크는 리전 관리형 인스턴스 그룹과 함께 작동하도록 설계되었습니다.
드물게 영역 장애가 발생하는 경우 일반적으로 --force-attach 플래그를 사용하여 Hyperdisk 균형 고가용성 디스크에서 실행 중인 워크로드를 다른 영역으로 장애 조치할 수 있습니다. --force-attach 플래그를 사용하면 디스크를 사용할 수 없어 원래 컴퓨팅 인스턴스에서 분리할 수 없더라도 Hyperdisk 균형 고가용성 디스크를 대기 인스턴스에 연결할 수 있습니다. 자세한 내용은 리전 디스크 장애 조치를 참고하세요.
성능
Hyperdisk 균형 고가용성 디스크는 복구에 Hyperdisk 스냅샷을 사용할 때와 비교 시 더 낮은 목표 복구 시간(RPO)과 복구 시간 목표(RTO)가 필요한 워크로드용으로 설계되었습니다.
Hyperdisk 균형 고가용성 디스크는 쓰기 성능이 여러 영역의 데이터 중복보다 중요하지 않은 경우에 사용할 수 있는 옵션입니다.
Hyperdisk 균형 고가용성 디스크는 IOPS 및 처리량 성능을 맞춤설정할 수 있습니다. Hyperdisk 균형 고가용성의 성능과 제한사항에 대한 자세한 내용은 Hyperdisk 정보를 참조하세요.
추가 디스크 공간이나 더 높은 성능이 필요한 경우 Hyperdisk 균형 고가용성 디스크를 수정하여 저장공간, 처리량, IOPS를 추가할 수 있습니다.
안정성
Compute Engine은 사용자가 디스크를 만들 때 지정한 영역으로 Hyperdisk 균형 고가용성 디스크의 데이터를 복제합니다. 중복을 보장하기 위해 각 복제본의 데이터는 영역 내의 여러 물리적 머신에 분산됩니다.
Hyperdisk와 마찬가지로 Hyperdisk 균형 고가용성 디스크의 스냅샷을 만들어 사용자 오류로 인한 데이터 손실을 방지할 수 있습니다. 스냅샷은 증분적이며 실행 중인 VM에 연결된 디스크를 스냅샷으로 작성할 경우에도 몇 분이면 생성됩니다.
VM 간 Hyperdisk 볼륨 공유
특정 Hyperdisk 볼륨의 경우 디스크 공유를 사용 설정하여 여러 VM에서 볼륨에 대한 동시 액세스를 사용 설정할 수 있습니다. 디스크 공유는 가용성이 높은 애플리케이션을 빌드하거나 여러 VM에서 동일한 모델 또는 학습 데이터에 액세스해야 하는 대규모 머신러닝 워크로드와 같은 다양한 사용 사례에 유용합니다.
자세한 내용은 VM 간 디스크 공유를 참조하세요.
하이퍼디스크 스토리지 풀
하이퍼디스크 스토리지 풀을 사용하면 블록 스토리지 총소유비용(TCO)을 쉽게 줄이고 블록 스토리지 관리를 간소화할 수 있습니다. Hyperdisk Storage Pool을 사용하면 단일 프로젝트에서 최대 1,000개의 디스크에 걸쳐 용량 및 성능 풀을 공유할 수 있습니다. 스토리지 풀은 씬 프로비저닝 및 데이터 감소 기능을 제공하므로 효율성을 높일 수 있습니다. 스토리지 풀을 사용하면 온프레미스 SAN을 클라우드로 간편하게 마이그레이션할 수 있으며 워크로드에 필요한 용량과 성능을 더 쉽게 제공할 수 있습니다.
특정 영역의 프로젝트에 있는 모든 워크로드의 예상 용량 및 성능으로 스토리지 풀을 만듭니다. 그런 다음 이 스토리지 풀에 디스크를 만들고 디스크를 기존 VM에 연결합니다. 새 VM을 만드는 과정에서 스토리지 풀에 디스크를 만들 수도 있습니다. 각 스토리지 풀에는 Hyperdisk Throughput과 같은 한 가지 유형의 디스크가 포함됩니다. Hyperdisk Storage Pool에는 두 가지 유형이 있습니다.
- Hyperdisk Balanced 스토리지 풀: Hyperdisk Balanced 디스크로 가장 잘 제공되는 범용 워크로드용
- Hyperdisk Throughput 스토리지 풀: Hyperdisk Throughput 디스크로 가장 잘 제공되는 스트리밍, 콜드 데이터, 분석 워크로드용
용량 프로비저닝 옵션
Hyperdisk Storage Pool 용량은 다음 두 가지 방법 중 하나로 프로비저닝할 수 있습니다.
- 표준 용량 프로비저닝
- 표준 용량 프로비저닝의 경우 모든 디스크의 총 크기가 스토리지 풀의 프로비저닝된 용량에 도달할 때까지 스토리지 풀에 디스크를 만듭니다. 표준 용량 프로비저닝이 적용된 스토리지 풀의 디스크는 디스크를 만들 때 용량이 소비되는 풀이 아닌 디스크와 유사하게 용량을 소비합니다.
- 고급 용량 프로비저닝
고급 용량 프로비저닝을 사용하면 스토리지 풀의 모든 디스크에서 씬 프로비저닝 및 데이터 감소 스토리지 용량 풀을 공유할 수 있습니다. 스토리지 풀 프로비저닝 용량에 대한 요금이 청구됩니다.
고급 용량 스토리지 풀의 디스크에 프로비저닝된 스토리지 풀 용량의 최대 500%까지 프로비저닝할 수 있습니다. 스토리지 풀의 디스크에 쓰여진 데이터 양만 스토리지 풀 용량을 소비합니다. 자동 데이터 감소를 사용하면 스토리지 풀 용량 소비를 더욱 줄일 수 있습니다.
고급 용량 스토리지 풀의 용량 사용률이 프로비저닝된 용량의 80%에 도달하면 하이퍼디스크 스토리지 풀은 용량 부족과 관련된 오류를 방지하기 위해 스토리지 풀에 용량을 자동으로 추가하려고 시도합니다.
예시
프로비저닝된 용량이 10TiB인 스토리지 풀이 있다고 가정해 보겠습니다.
표준 용량 프로비저닝을 사용하면 다음과 같은 이점이 있습니다.
- 스토리지 풀에 디스크를 만들 때 최대 10TiB의 집계 하이퍼디스크 용량을 프로비저닝할 수 있습니다. 프로비저닝된 스토리지 풀 용량 10TiB에 대해 요금이 청구됩니다.
- 스토리지 풀에 크기가 5TiB인 단일 디스크를 생성하고 디스크에 2TiB를 쓰면 스토리지 풀의 사용된 용량은 5TiB입니다.
고급 용량 프로비저닝을 사용하면 다음과 같은 이점이 있습니다.
- 스토리지 풀에 디스크를 만들 때 최대 50TiB의 집계 하이퍼디스크 용량을 프로비저닝할 수 있습니다. 프로비저닝된 스토리지 풀 용량 10TiB에 대해 요금이 청구됩니다.
- 스토리지 풀에 크기가 5TiB인 단일 디스크를 생성하고, 디스크에 3TiB의 데이터를 쓰면 데이터 감소로 인해 작성된 데이터 양이 2TiB로 줄어들어 스토리지 풀의 사용된 용량은 2TiB입니다.
성능 프로비저닝 옵션
Hyperdisk Storage Pool 성능은 다음 두 가지 방법 중 하나로 프로비저닝할 수 있습니다.
- 표준 성능 프로비저닝
표준 성능은 다음과 같은 유형의 워크로드에 가장 적합합니다.
- 스토리지 풀 리소스로 인해 성능이 제한되는 경우 실행할 수 없는 워크로드
- 스토리지 풀의 디스크와 상관 관계가 있는 성능 급증이 발생할 가능성이 있는 워크로드(예: 매일 아침 최대 사용률에 도달하는 데이터베이스의 데이터 디스크)
표준 성능 스토리지 풀은 씬 프로비저닝의 이점을 누리지 못하며 성능 TCO를 크게 낮추지 않습니다. 표준 성능 프로비저닝의 경우 모든 디스크의 프로비저닝된 총 IOPS 또는 처리량이 스토리지 풀의 프로비저닝된 양에 도달할 때까지 스토리지 풀에 디스크를 만듭니다. 표준 성능 프로비저닝이 적용된 스토리지 풀의 디스크는 디스크를 만들 때 IOPS 및 처리량을 프로비저닝하는 풀이 아닌 디스크와 마찬가지로 IOPS 및 처리량을 소비합니다. 스토리지 풀에 프로비저닝된 총 IOPS 및 처리량에 대해 요금이 청구됩니다.
표준 성능의 Hyperdisk Balanced 스토리지 풀에서 스토리지 풀에 있는 각 디스크의 처음 3,000 IOPS 및 140MiBps 처리량(기준)은 스토리지 풀 리소스를 소비하지 않습니다. 스토리지 풀에 디스크를 만들 때 기준 값을 초과하는 IOPS 및 처리량은 스토리지 풀의 IOPS 및 처리량을 소비합니다.
표준 성능 스토리지 풀에 생성된 디스크는 나머지 스토리지 풀과 성능 리소스를 공유하지 않습니다. 스토리지 풀의 모든 디스크의 합산 성능 양은 스토리지 풀의 프로비저닝된 총 IOPS 또는 처리량을 초과할 수 없습니다.
- 고급 성능 프로비저닝
고급 성능 프로비저닝이 적용된 스토리지 풀은 씬 프로비저닝을 활용하여 성능 효율성을 높이고 블록 스토리지 성능 TCO를 낮춥니다. 고급 성능 프로비저닝을 사용하면 스토리지 풀의 모든 디스크에 프로비저닝된 성능 풀을 공유할 수 있습니다. 스토리지 풀의 디스크가 데이터를 읽고 쓸 때 스토리지 풀은 성능 리소스를 동적으로 할당합니다. 스토리지 풀의 디스크에서 사용하는 IOPS 및 처리량만 스토리지 풀 IOPS 및 처리량을 소비합니다. 고급 성능 스토리지 풀은 씬 프로비저닝되므로 스토리지 풀에 프로비저닝한 것보다 더 많은 IOPS 또는 처리량(스토리지 풀에 프로비저닝된 IOPS 또는 처리량의 최대 500%)을 스토리지 풀의 디스크에 할당할 수 있습니다. 표준 성능과 마찬가지로 스토리지 풀에서 프로비저닝된 IOPS 및 처리량에 대해 요금이 청구됩니다.
고급 성능 프로비저닝이 적용된 Hyperdisk Balanced 스토리지 풀에서는 디스크에 기준 성능이 없습니다. 스토리지 풀에 있는 Hyperdisk Balanced 디스크의 모든 읽기 및 쓰기 작업은 풀 리소스를 소비합니다.
스토리지 풀의 모든 디스크의 합산 성능 사용률이 스토리지 풀에 프로비저닝된 총 성능 양에 도달하면 디스크에 성능 경합이 발생할 수 있습니다. 따라서 고급 성능 프로비저닝은 사용량이 높은 시간과 상관성이 높지 않은 워크로드에 가장 적합합니다. 워크로드가 모두 동시에 급증하면 고급 성능 스토리지 풀이 스토리지 풀의 성능 한도에 도달하여 성능 리소스 경합이 발생할 수 있습니다.
고급 성능 스토리지 풀에서 풀의 디스크에 대한 성능 리소스 경합이 감지되면 자동 증가 기능에서 성능 문제를 방지하기 위해 스토리지 풀의 디스크에 사용 가능한 IOPS 또는 처리량을 자동으로 늘리려고 시도합니다.
예시
100,000의 프로비저닝된 IOPS가 있는 하이퍼디스크 균형 스토리지 풀이 있다고 가정해 보겠습니다.
표준 성능 프로비저닝을 사용하면 다음과 같은 이점이 있습니다.
- 스토리지 풀에 하이퍼디스크 균형 디스크를 만들 때 최대 100,000의 집계 IOPS를 프로비저닝할 수 있습니다.
- 프로비저닝된 하이퍼디스크 균형 스토리지 풀 성능의 IOPS 100,000에 대해 요금이 청구됩니다.
스토리지 풀 외부에서 만든 디스크와 마찬가지로 표준 성능 스토리지 풀의 하이퍼디스크 균형 디스크는 최대 3,000의 기준 IOPS와 140MiB/s의 기준 처리량으로 자동 프로비저닝됩니다. 이 기준 성능은 스토리지 풀에 대해 프로비저닝된 성능에 포함되지 않습니다. 기준보다 높은 프로비저닝된 성능으로 스토리지 풀에 디스크를 추가하는 경우에만 스토리지 풀의 프로비저닝된 성능에 반영됩니다. 예를 들면 다음과 같습니다.
- 3,000 IOPS로 프로비저닝된 디스크는 0 풀 IOPS를 사용하며 풀의 다른 디스크에 사용 가능한 100,000 IOPS는 여전히 제공됩니다.
- IOPS 13,000으로 프로비저닝된 디스크는 10,000 풀 IOPS를 사용하며 풀에는 스토리지 풀의 다른 디스크에 할당할 수 있는 프로비저닝된 IOPS가 90,000 남아 있습니다.
고급 성능 프로비저닝을 사용하면 다음과 같은 이점이 있습니다.
- 스토리지 풀에 디스크를 만들 때 최대 500,000 IOPS의 집계 하이퍼디스크 성능을 프로비저닝할 수 있습니다.
- 스토리지 풀에서 프로비저닝된 100,000 IOPS의 요금이 부과됩니다.
- 스토리지 풀에서 5,000 IOPS의 단일 디스크(
Disk1)를 만드는 경우 스토리지 풀 프로비저닝 IOPS에서 IOPS를 소비하지 않습니다. 그러나 스토리지 풀에서 만든 새 디스크에 프로비저닝할 수 있는 IOPS의 양은 이제 495,000입니다. Disk1에서 데이터 읽기 및 쓰기를 시작하고 지정된 1분 동안 최대 5,000 IOPS를 사용하는 경우 스토리지 풀의 프로비저닝된 IOPS에서 5,000 IOPS를 사용합니다. 동일한 스토리지 풀에서 만든 다른 디스크는 경합 없이 같은 1분 동안 집계된 IOPS를 최대 95,000 사용할 수 있습니다.
Hyperdisk Storage Pool 프로비저닝된 용량 및 성능 변경
워크로드가 확장됨에 따라 스토리지 풀의 프로비저닝된 용량, IOPS, 처리량을 늘리거나 줄일 수 있습니다. 고급 용량 또는 고급 성능 스토리지 풀을 사용하면 스토리지 풀의 기존 및 새 디스크에서 추가 용량 또는 성능을 사용할 수 있습니다. 또한 Compute Engine은 다음과 같이 스토리지 풀을 자동으로 수정하려고 시도합니다.
- 고급 용량: 스토리지 풀이 사용된 스토리지 풀 프로비저닝 용량의 80% 에 도달하면 Compute Engine이 스토리지 풀에 자동으로 용량을 추가하려고 시도합니다.
- 고급 성능: 스토리지 풀에서 과도한 사용으로 인해 장기적인 경합이 발생하면 Compute Engine은 스토리지 풀의 IOPS 또는 처리량을 늘리려고 시도합니다.
Hyperdisk Storage Pool에 관한 추가 정보
Hyperdisk Storage Pool 사용에 관한 자세한 내용은 다음 링크를 참고하세요.
로컬 SSD 디스크
로컬 SSD 디스크는 VM을 호스팅하는 서버에 물리적으로 연결됩니다. 로컬 SSD 디스크의 처리량은 표준 영구 디스크 또는 SSD 영구 디스크보다 높고 지연 시간은 짧습니다. 로컬 SSD 디스크에 저장한 데이터는 VM이 중지되거나 삭제될 때까지만 유지됩니다. vCPU 수에 따라 VM에 여러 로컬 SSD 디스크를 연결할 수 있습니다.
크기가 3TiB인 Local SSD 디스크를 사용하는 Z3 VM을 제외하고 각 Local SSD 디스크의 크기는 375GiB로 고정됩니다. 스토리지를 늘리려면 VM을 만들 때 VM에 여러 개의 로컬 SSD 디스크를 추가합니다. VM에 연결할 수 있는 로컬 SSD 디스크 의 최대 수는 머신 유형과 사용 중인 vCPU 수에 따라 다릅니다.
로컬 SSD 디스크의 데이터 지속성
로컬 SSD 데이터 지속성을 검토하고 로컬 SSD 데이터를 보존하는 이벤트와 로컬 SSD 데이터를 복구할 수 없는 이벤트를 알아보세요.
로컬 SSD 및 머신 유형
머신 시리즈 비교 표와 같이 Compute Engine에서 사용 가능한 대부분의 머신 유형에 로컬 SSD 디스크를 연결할 수 있습니다. 하지만 각 머신 유형에 따라 연결할 수 있는 로컬 SSD 디스크 수에는 제약조건이 따릅니다. 자세한 내용은 유효한 로컬 SSD 디스크 수 선택을 참조하세요.
로컬 SSD 디스크의 용량 제한
VM에 사용할 수 있는 최대 로컬 SSD 디스크 용량은 다음과 같습니다.
| 머신 유형 | 로컬 SSD 디스크 크기 | 디스크 수 | 최대 용량 |
|---|---|---|---|
| Z3 | 3TiB | 12 | 36TiB |
c3d-standard-360-lssd |
375GiB | 32 | 12TiB |
c3d-highmem-360-lssd |
375GiB | 32 | 12TiB |
c3-standard-176-lssd |
375GiB | 32 | 12TiB |
| N1, N2, N2D | 375GiB | 24 | 9TiB |
| N1, N2, N2D | 375GiB | 16 | 6TiB |
| A3 | 375GiB | 16 | 6TiB |
| C2, C2D, A2 스탠더드, M1 및 M3 | 375GiB | 8 | 3TiB |
| A2 울트라 | 375GiB | 8 | 3TiB |
로컬 SSD 디스크의 제한사항
로컬 SSD에는 다음과 같은 제한사항이 있습니다.
- 최대 IOPS 한도에 도달하려면 vCPU가 32개 이상 있는 VM을 사용합니다.
- 공유 코어 머신 유형의 VM에서 로컬 SSD 디스크를 연결할 수 없습니다.
- N4, H3, M2 E2, Tau T2A 머신 유형에는 로컬 SSD 디스크를 연결할 수 없습니다.
- 로컬 SSD 디스크에서는 고객 제공 암호화 키를 사용할 수 없습니다. Compute Engine은 데이터가 로컬 SSD 스토리지에 작성되면 데이터를 자동으로 암호화합니다.
성능
로컬 SSD 디스크는 매우 높은 IOPS와 짧은 지연 시간을 제공합니다. 영구 디스크와 달리 개발자가 로컬 SSD 디스크의 스트라이핑을 직접 관리해야 합니다.
로컬 SSD 성능은 여러 요인에 따라 달라집니다. 자세한 내용은 로컬 SSD 성능 및 로컬 SSD 성능 최적화를 참조하세요.
Cloud Storage 버킷
Cloud Storage 버킷은 VM에 가장 적합한 유연성과 내구성을 갖춘 확장 가능한 스토리지 옵션입니다. 앱에서 Hyperdisk Persistent Disk, 로컬 SSD 의 지연 시간 단축을 요구하지 않는 경우 Cloud Storage 버킷에 데이터를 저장할 수 있습니다.
지연 시간과 처리량이 중요하지 않은 경우와 여러 VM 또는 영역 간에 데이터를 쉽게 공유해야 하는 경우 VM을 Cloud Storage 버킷에 연결합니다.
Cloud Storage 버킷 속성
다음 섹션을 검토하여 Cloud Storage 버킷의 동작과 특성을 이해합니다.
성능
Cloud Storage 버킷의 성능은 선택한 스토리지 클래스 및 VM과 관련된 버킷의 위치에 따라 달라집니다.
VM과 동일한 위치에서 Cloud Storage Standard Storage 클래스를 사용하면 Hyperdisk 또는 Persistent Disk 와 비슷한 성능을 제공하지만 지연 시간이 더 길고 일관성이 떨어지는 처리량 특성이 있습니다. 이중 리전에서 Standard 스토리지 클래스를 사용하면 데이터가 두 리전 간에 중복 저장됩니다. 이중 리전을 사용할 때 최적의 성능을 얻으려면 VM이 이중 리전의 일부인 리전 중 하나에 있어야 합니다.
Nearline Storage, Coldline Storage, Archive Storage 클래스는 주로 장기 데이터 보관처리에 사용됩니다. Standard Storage 클래스와 달리 이 클래스는 최소 저장 기간이 있으며 데이터 검색 비용이 발생합니다. 따라서 자주 액세스하지 않는 데이터의 장기 스토리지로 적합합니다.
안정성
모든 Cloud Storage 버킷에는 장비 고장 시 데이터를 보호하고, 데이터 센터 유지보수 이벤트를 통해 데이터 가용성을 보장하는 중복 기능이 내장되어 있습니다. 모든 Cloud Storage 작업에 대해 체크섬이 계산되므로 현재 읽고 있는 데이터가 사용자가 기록한 데이터임을 보장할 수 있습니다.
유연성
Hyperdisk 또는 Persistent Disk와 달리 Cloud Storage 버킷은 VM이 있는 영역으로 제한되지 않습니다. 또한 여러 VM에서 버킷으로 데이터를 동시에 읽고 쓸 수 있습니다. 예를 들어 여러 영역의 Hyperdisk 또는Persistent Disk 볼륨에 데이터를 복제하지 않고 동일한 버킷에서 데이터를 읽고 쓰도록 여러 영역에서 VM을 구성할 수 있습니다.
Cloud Storage 암호화
Compute Engine은 데이터가 VM 외부에서 Cloud Storage 버킷으로 이동하기 전에 해당 데이터를 자동으로 암호화합니다. 버킷에 쓰기 전에 VM의 파일을 암호화할 필요가 없습니다.
Persistent Disk 볼륨과 마찬가지로 자체 암호화 키로 버킷을 암호화할 수 있습니다.Cloud Storage 버킷에서 데이터 읽기 및 쓰기
gcloud storage 명령줄 도구 또는 Cloud Storage 클라이언트 라이브러리를 사용하여 Cloud Storage 버킷에서 파일을 읽고 씁니다.
gcloud 스토리지
기본적으로 gcloud storage 명령줄 도구는 공개 이미지가 사용되는 대부분의 VM에 설치됩니다.
VM에 gcloud storage 명령줄 도구가 없으면 설치할 수 있습니다.
SSH 또는 다른 연결 방법을 사용하여 Linux VM에 연결하거나 Windows VM에 연결합니다.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.

이전에 이 VM에서
gcloud storage를 사용한 적이 없는 경우 gcloud CLI를 사용하여 사용자 인증 정보를 설정합니다.gcloud init
Cloud Storage 범위가 있는 서비스 계정을 사용하도록 VM을 구성한 경우에는 이 단계를 건너뛰어도 됩니다.
gcloud storage도구를 사용하여 버킷을 만들고, 버킷에 데이터를 쓰고, 해당 버킷에서 데이터를 읽습니다. 특정 버킷에서 데이터를 읽거나 쓰려면 버킷에 대한 액세스 권한이 있어야 합니다. 또는 공개적으로 액세스할 수 있는 버킷에서 데이터를 읽을 수 있습니다.원하는 경우 Cloud Storage에 데이터를 스트리밍할 수도 있습니다.
클라이언트 라이브러리
Cloud Storage 범위가 있는 서비스 계정을 사용하도록 VM을 구성한 경우 Cloud Storage API를 사용하여 Cloud Storage 버킷에서 데이터를 읽고 쓸 수 있습니다.
VM에 연결합니다.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.
원하는 언어의 클라이언트 라이브러리를 설치 및 구성합니다.
필요한 경우 삽입 코드 샘플을 따라 VM에서 Cloud Storage 버킷을 만듭니다.
데이터 쓰기 및 데이터 읽기 삽입 코드 샘플을 따라 Cloud Storage 버킷에서 파일을 읽거나 쓰는 코드를 앱에 포함합니다.
다음 단계
- VM에 Hyperdisk 볼륨 추가
- VM에 Persistent Disk 볼륨 추가
- VM에 리전 디스크 추가
- 로컬 SSD 디스크로 VM 만들기
- 파일 서버 또는 분산 파일 시스템 만들기
- 디스크 할당량 검토
- VM에 RAM 디스크 마운트