Pour ajouter des disques à vos VM, choisissez l'une des options de stockage de blocs proposées par Compute Engine. Chacune des options de stockage suivantes présente des caractéristiques de prix et de performances uniques :
- Les volumes Google Cloud Hyperdisk sont un espace de stockage réseau pour Compute Engine, avec des performances configurables et des volumes pouvant être redimensionnés de manière dynamique. Ils offrent des performances, une flexibilité et une efficacité nettement supérieures à celles des disques persistants. Un volume Hyperdisk équilibré à haute disponibilité peut répliquer de manière synchrone les données entre les disques situés dans deux zones, offrant ainsi une protection si une zone devient indisponible.
- Les pools de stockage Hyperdisk vous permettent d'acheter de la capacité Hyperdisk et des performances globales, puis de créer des disques pour vos VM à partir de ce pool de stockage.
- Les volumes Persistent Disk offrent un stockage réseau redondant et à hautes performances. Chaque volume Persistent Disk est réparti sur des centaines de disques physiques.
- Par défaut, les VM utilisent un volume Persistent Disk zonal et stockent vos données sur des volumes situés dans une seule zone, telle que
us-west1-c. - Vous pouvez également créer des volumes Persistent Disk régionaux, qui répliquent de manière synchrone les données entre les disques situés dans deux zones et offrent une protection si une zone devient indisponible.
- Par défaut, les VM utilisent un volume Persistent Disk zonal et stockent vos données sur des volumes situés dans une seule zone, telle que
- Les disques SSD locaux sont des disques physiques associés directement au même serveur que votre VM. Ils peuvent offrir de meilleures performances, mais sont éphémères.
Pour obtenir des comparaisons de coût, consultez les tarifs des disques. Si vous ne savez pas quelle option choisir, pour les séries de machines de génération antérieure, la solution la plus courante consiste à ajouter un volume Persistent Disk avec équilibrage à votre VM et pour la dernière série de machines, à ajouter un volume Hyperdisk à votre instance de calcul.
En plus du stockage de blocs, Compute Engine propose des options de stockage de fichiers et d'objets. Pour examiner et comparer les options de stockage, consultez la section Examiner les options de stockage.
Introduction
Par défaut, chaque VM Compute Engine possède un seul disque persistant de démarrage contenant le système d'exploitation. Les données du disque de démarrage sont généralement stockées sur un volume Persistent Disk ouHyperdisk Balanced. Si vos applications nécessitent davantage d'espace de stockage, vous pouvez provisionner un ou plusieurs des volumes de stockage suivants sur votre VM.
Pour en savoir plus sur chaque option de stockage, consultez le tableau suivant :
| Persistent Disk avec équilibrage |
Persistent Disk SSD |
Persistent Disk standard |
Persistent Disk Extreme |
Volume Hyperdisk équilibré | Hyperdisk ML | Hyperdisk Extreme | Hyperdisk Throughput | Disques SSD locaux | |
|---|---|---|---|---|---|---|---|---|---|
| Type de stockage | Stockage de blocs économique et fiable | Stockage de blocs rapide et fiable | Stockage de blocs efficace et fiable | Option de stockage de blocs sur Persistent Disk aux performances optimales avec IOPS personnalisables | Hautes performances pour les charges de travail exigeantes à moindre coût | Stockage offrant le débit le plus élevé optimisé pour les charges de travail de machine learning. | Option de stockage de blocs la plus rapide avec IOPS personnalisables | Stockage de blocs économique et orienté débit avec débit personnalisable | Stockage de blocs local hautes performances |
| Capacité minimale par disque | Zonal : 10 Gio Régional : 10 Gio |
Zonal : 10 Gio Régional : 10 Gio |
Zonal : 10 Gio Régional : 200 Gio |
500 Gio | Zonal et régional : 4 Gio | 4 Gio | 64 Gio | 2 Tio | 375 Gio, 3 Tio avec Z3 |
| Capacité maximale par disque | 64 Tio | 64 Tio | 64 Tio | 64 Tio | 64 Tio | 64 Tio | 64 Tio | 32 Tio | 375 Gio, 3 Tio avec Z3 |
| Incrément de capacité | 1 Gio | 1 Gio | 1 Gio | 1 Gio | 1 Gio | 1 Gio | 1 Gio | 1 Gio | Variable selon le type de machine† |
| Capacité maximale par VM | 257 Ti0* | 257 Ti0* | 257 Ti0* | 257 Ti0* | 512 Ti0* | 512 Ti0* | 512 Ti0* | 512 Ti0* | 36 Ti0 |
| Champ d'application de l'accès | Zone | Zone | Zone | Zone | Zone | Zone | Zone | Zone | Instance |
| Redondance des données | Zonal et multizonal | Zonal et multizonal | Zonal et multizonal | Zonal | Zonal et multizonal | Zonal | Zonal | Zonal | Aucun |
| Chiffrement au repos | Oui | Oui | Oui | Oui | Oui | Oui | Oui | Oui | Oui |
| Clés de chiffrement personnalisées | Oui | Oui | Oui | Oui | Oui‡ | Oui | Oui | Oui | Non |
| Procédures | Ajouter un Persistent Disk Extreme | Ajouter un disque SSD local | |||||||
En plus des options de stockage proposées par Google Cloud, vous pouvez déployer des solutions de stockage alternatives sur vos VM.
- Créez un serveur de fichiers ou un système de fichiers distribués sur Compute Engine que vous utiliserez comme système de fichiers en réseau avec les fonctionnalités de NFSv3 et SMB3.
- Installez un disque RAM dans la mémoire de la VM pour créer un volume de stockage de blocs offrant un débit élevé et une faible latence.
Les ressources de stockage de blocs ont des caractéristiques de performances différentes. Tenez compte de vos exigences en matière de taille d'espace de stockage et de performances lorsque vous déterminez le type de stockage de blocs approprié pour vos VM.
Pour en savoir plus sur les limites de performances, consultez les pages suivantes :
- Limites de performances des disques Persistent Disk
- Limites de performances des disques SSD locaux
- Limites de performances des disques Hyperdisk
Persistent Disk
Les volumes de disque persistant sont des périphériques de stockage réseau durables auxquels vos instances de VM peuvent accéder, au même titre que des disques physiques sur un ordinateur ou un serveur. Les données de chaque volume Persistent Disk sont réparties sur plusieurs disques physiques. Compute Engine gère les disques physiques et la distribution des données pour assurer la redondance et des performances optimales à votre place.
Les volumes Persistent Disk sont hébergés indépendamment de votre VM. Vous pouvez donc dissocier ou déplacer des volumes Persistent Disk pour conserver vos données même après avoir supprimé vos VM. Les performances des volumes Persistent Disk évoluent automatiquement en fonction de la taille. Vous pouvez donc redimensionner vos volumes Persistent Disk existants ou ajouter des volumes Persistent Disk à une VM pour répondre à vos besoins en termes de performances et d'espace de stockage.
Types Persistent Disk
Lorsque vous configurez un disque persistant, vous pouvez sélectionner l'un des types de disque suivants :
- Disques persistants avec équilibrage (
pd-balanced)- Alternative aux disques persistants de performance (pd-ssd).
- Équilibre entre performances et coûts. Pour la plupart des formes de VM, à l'exception de celles qui sont très volumineuses, ces disques ont le même nombre maximal d'IOPS que les disques persistants SSD et un nombre inférieur d'IOPS par Gio. Ce type de disque offre des niveaux de performances adaptés à la plupart des applications à usage général, pour un prix situé entre ceux des disques persistants standards et de performance (pd-ssd).
- Reposent sur des disques durs SSD.
- Disques persistants de performance (SSD) (
pd-ssd)- Conviennent aux applications d'entreprise et aux bases de données hautes performances qui nécessitent une latence plus faible et davantage d'IOPS que ce qu'apportent les disques persistants standards.
- Reposent sur des disques durs SSD.
- Disques persistants standards (
pd-standard)- Conviennent aux charges de travail de traitement de données volumineuses utilisant principalement des E/S séquentielles.
- Reposent sur des disques durs standards (HDD).
- Disques persistants extrêmes (
pd-extreme)- Offrent des performances élevées et cohérentes pour les charges de travail d'accès aléatoire et à débit soutenu.
- Solution conçue pour les charges de travail de base de données très exigeantes
- Permettent de provisionner les IOPS cibles.
- Reposent sur des disques durs SSD.
- Disponibles avec un nombre limité de types de machines.
Si vous créez un disque dans la console Google Cloud, le type de disque par défaut est pd-balanced. Si vous créez un disque à l'aide de gcloud CLI ou de l'API Compute Engine, le type de disque par défaut est pd-standard.
Pour en savoir plus sur les types de machines compatibles, consultez les pages suivantes :
Durabilité des disques Persistent Disk
La durabilité du disque représente, de par sa conception, la probabilité de perte de données pour un disque type au cours d'une année type. Elle repose sur un ensemble d'hypothèses sur les défaillances matérielles, la probabilité de sinistres, les pratiques d'isolation et les processus d'ingénierie dans les centres de données Google, ainsi que les encodages internes utilisés par chaque type de disque. Les événements de perte de données sur les disques Persistent Disk sont extrêmement rares et résultent généralement de défaillances matérielles coordonnées, de bugs logiciels ou d'une combinaison des deux. Google prend également de nombreuses mesures pour limiter le risque de corruption des données silencieuses dans l'ensemble du secteur. Une erreur humaine commise par un client Google Cloud, par exemple lorsqu'un client supprime un disque par inadvertance, n'entre pas dans le cadre de la durabilité des disques Persistent Disk.
Le risque très faible d'une perte de données sur un disque persistant régional est dû à ses encodages et à sa réplication de données internes. Les disques Persistent Disk régionaux fournissent deux fois plus d'instances dupliquées que les disques Persistent Disk zonaux, car leurs instances dupliquées sont réparties entre deux zones de la même région, offrant ainsi une haute disponibilité. Ils peuvent être utilisés pour la reprise après sinistre en cas de perte et d'impossibilité de récupération d'un centre de données tout entier (bien que cela n'ait jamais eu lieu). Les instances dupliquées supplémentaires d'une deuxième zone sont accessibles immédiatement si une zone principale devient indisponible pendant une longue interruption.
Le tableau ci-dessous indique la durabilité pour la conception de chaque type de disque. Une durabilité de 99,999 % signifie qu'avec 1 000 disques, vous atteindrez probablement une centaine d'années sans perdre un seul disque.
| Disque Persistent Disk standard zonal | Disque Persistent Disk zonal avec équilibrage | Disque Persistent Disk SSD zonal | Disque Persistent Disk Extreme zonal | Disque Persistent Disk standard régional | Disque Persistent Disk régional avec équilibrage | Disque Persistent Disk SSD régional |
|---|---|---|---|---|---|---|
| Mieux que 99,99 % | Mieux que 99,999 % | Mieux que 99,999 % | Mieux que 99,9999 % | Mieux que 99,999 % | Mieux que 99,9999 % | Mieux que 99,9999 % |
Disque Persistent Disk zonal
Simplicité d'utilisation
Compute Engine assure la plupart des tâches de gestion des disques à votre place pour vous éviter de devoir gérer le partitionnement, les baies de disques redondantes ou les sous-volumes. Généralement, vous n'avez pas besoin de créer de volumes logiques plus importants, mais vous pouvez étendre la capacité de Persistent Disk secondaire à 257 Tio par VM et appliquer ces pratiques à vos volumes Persistent Disk si vous le souhaitez. Toutefois, il est possible de gagner du temps et d'obtenir des performances optimales en formatant vos volumes Persistent Disk avec un seul système de fichiers et aucune table de partition.
Si vous devez séparer vos données en plusieurs volumes uniques, créez des disques supplémentaires plutôt que de diviser vos disques existants en plusieurs partitions.
Si vous avez besoin d'espace supplémentaire sur vos volumes Persistent Disk, il vous suffit de redimensionner vos disques plutôt que de les repartitionner et les formater.
Performances
Les performances des disques persistants sont prévisibles et évoluent de manière linéaire avec la capacité provisionnée jusqu'à ce que les limites d'une VM en matière de processeurs virtuels provisionnés soient atteintes. Pour en savoir plus sur les limites et l'optimisation du scaling des performances, consultez la section Configurer des disques pour répondre aux exigences de performances.
Les volumes Persistent Disk standards sont efficaces et économiques pour la gestion des opérations de lecture/écriture séquentielles, mais ne sont pas optimisés pour gérer des taux élevés d'opérations d'entrée/sortie par seconde (IOPS) aléatoires. Si vos applications nécessitent des taux élevés d'IOPS aléatoires, utilisez des disques Persistent Disk SSD ou Extreme. Les disques Persistent Disk SSD sont conçus pour des latences de l'ordre de la milliseconde. La latence observée est spécifique à chaque application.
Compute Engine optimise automatiquement les performances et le scaling sur les volumes Persistent Disk. La répartition sur plusieurs disques ou le préchauffage des disques n'est pas nécessaire pour obtenir des performances optimales. Lorsque vous avez besoin d'espace disque supplémentaire ou de meilleures performances, redimensionnez vos disques et ajoutez éventuellement des processeurs virtuels pour augmenter l'espace de stockage, le débit et les IOPS. Les performances d'un Persistent Disk sont basées sur la capacité totale du disque persistant attaché à une instance, et sur le nombre de processeurs virtuels disponibles sur la VM.
Pour les périphériques de démarrage, vous pouvez réduire les coûts à l'aide d'un disque Persistent Disk standard. De petits volumes de Persistent Disk de 10 Gio peuvent fonctionner pour les cas d'utilisation de base pour la gestion des packages et des périphériques de démarrage. Toutefois, pour garantir des performances constantes pour une utilisation plus générale du périphérique de démarrage, utilisez un Persistent Disk avec équilibrage comme disque de démarrage.
Chaque opération d'écriture sur Persistent Disk s'ajoute au trafic réseau sortant de votre VM. Cela signifie que les opérations d'écriture sur le Persistent Disk sont limitées par le plafond de sortie réseau de votre VM.
Fiabilité
Les Persistent Disk sont dotés d'une fonction de redondance intégrée qui protège les données contre les pannes de matériel et qui assure la disponibilité de ces données lors des événements de maintenance du centre de données. Le calcul d'une somme de contrôle pour toutes les opérations du Persistent Disk permet de s'assurer que les données lues sont bien identiques à celles qui ont été écrites.
Vous pouvez également créer des instantanés de Persistent Disk pour vous protéger contre les pertes de données dues aux erreurs des utilisateurs. Les instantanés sont incrémentiels et sont créés en quelques minutes seulement, même sur des disques associés à des VM en cours d'exécution.
Mode écriture simultanée
Vous pouvez installer un Persistent Disk SSD en mode écriture simultanée dans deux VM N2 simultanément, afin que les deux VM puissent lire et écrire sur le disque.
Un Persistent Disk en mode écriture simultanée offre une fonctionnalité de stockage de blocs partagé et constitue une base d'infrastructure pour la création de bases de données et de systèmes de fichiers partagés à disponibilité élevée. Ces systèmes de fichiers et bases de données spécialisés doivent être conçus pour fonctionner avec un stockage de blocs partagé et gérer la cohérence du cache entre les VM à l'aide d'outils tels que les réservations persistantes SCSI.
Toutefois, un disque Persistent Disk en mode écriture simultanée ne doit généralement pas être utilisé directement. Sachez que de nombreux systèmes de fichiers, tels que EXT4, XFS et NTFS, ne sont pas conçus pour être utilisés avec le stockage de blocs partagé. Pour en savoir plus sur les bonnes pratiques lors du partage de disques Persistent Disk entre des VM, consultez la section Bonnes pratiques.
Si vous avez besoin d'un stockage de fichiers entièrement géré, vous pouvez installer un partage de fichiers Filestore sur vos VM Compute Engine.
Pour activer le mode écriture simultanée pour les nouveaux volumes Persistent Disk, créez un disque persistant et spécifiez l'option --multi-writer dans gcloud CLI ou la propriété multiWriter dans l'API Compute Engine. Pour en savoir plus, consultez la page Partager des volumes Persistent Disk entre plusieurs VM.
Chiffrement des disques Persistent Disk
Compute Engine chiffre automatiquement vos données avant leur transfert depuis votre VM vers l'espace de stockage Persistent Disk. Chaque disque Persistent Disk reste chiffré au moyen de clés définies par le système ou de clés fournies par le client. Google distribue les données du disque Persistent Disk sur plusieurs disques physiques, d'une manière que les utilisateurs ne contrôlent pas.
Lorsque vous supprimez un volume Persistent Disk, Google supprime les clés de chiffrement, ce qui rend les données irrécupérables. Ce processus est irréversible.
Si vous souhaitez contrôler les clés de chiffrement utilisées pour chiffrer vos données, créez vos disques avec vos propres clés de chiffrement.
Restrictions
Vous ne pouvez pas associer un volume Persistent Disk à une VM d'un autre projet.
Vous pouvez associer un volume Persistent Disk avec équilibrage à un maximum de 10 VM en mode lecture seule.
Pour les types de machines personnalisés ou les types de machines prédéfinis dotés d'au moins un processeur virtuel, vous pouvez associer jusqu'à 128 volumes Persistent Disk.
Chaque volume Persistent Disk peut atteindre une taille de 64 Tio. Il n'est donc pas nécessaire de gérer des baies de disques pour créer de grands volumes logiques. Chaque VM ne peut être associée qu'à une quantité limitée d'espace Persistent Disk total et à un nombre limité de disques Persistent Disk individuels. Les types de machines prédéfinis et les types de machines personnalisés sont soumis aux mêmes limites Persistent Disk.
La plupart des VM peuvent contenir jusqu'à 128 volumes Persistent Disk et 257 Tio d'espace disque total associés. L'espace disque total d'une VM inclut la taille du disque de démarrage.
Les types de machines à cœur partagé sont limités à 16 volumes Persistent Disk et à 3 Tio d'espace Persistent Disk total.
La création de volumes logiques d'une taille supérieure à 64 Tio peut nécessiter une attention particulière. Pour plus d'informations sur les performances des volumes logiques de plus grande taille, consultez la section Taille de volume logique.
Stockage Persistent Disk régional
Les volumes Persistent Disk régionaux présentent des qualités de stockage équivalentes à celles d'un disque Persistent Disk zonal. Cependant, les volumes Persistent Disk régionaux fournissent un stockage et une réplication durables des données entre deux zones de la même région.
À propos de la réplication synchrone des disques
Lorsque vous créez un volume Persistent Disk, vous pouvez soit le créer dans une zone, soit le répliquer dans deux zones d'une même région.
Par exemple, si vous créez un disque dans une zone, telle que us-west1-a, vous disposez d'une copie du disque. C'est ce que l'on appelle un disque zonal.
Vous pouvez augmenter la disponibilité du disque en stockant une autre copie du disque dans une zone différente de la région, telle que us-west1-b.
Un volume Persistent Disk répliqué sur deux zones de la même région est un volume Persistent Disk régional. Vous pouvez également utiliser un volume Hyperdisk équilibré à haute disponibilité pour la réplication synchrone interzones de Google Cloud Hyperdisk.
Il est peu probable qu'une région soit totalement défaillante, mais des défaillances de zone peuvent se produire. La réplication dans la région sur différentes zones, comme illustré dans l'image suivante, permet de gagner en disponibilité et de réduire la latence des disques. Si les deux zones de réplication sont défaillantes, cela est considéré comme une défaillance à l'échelle de la région.
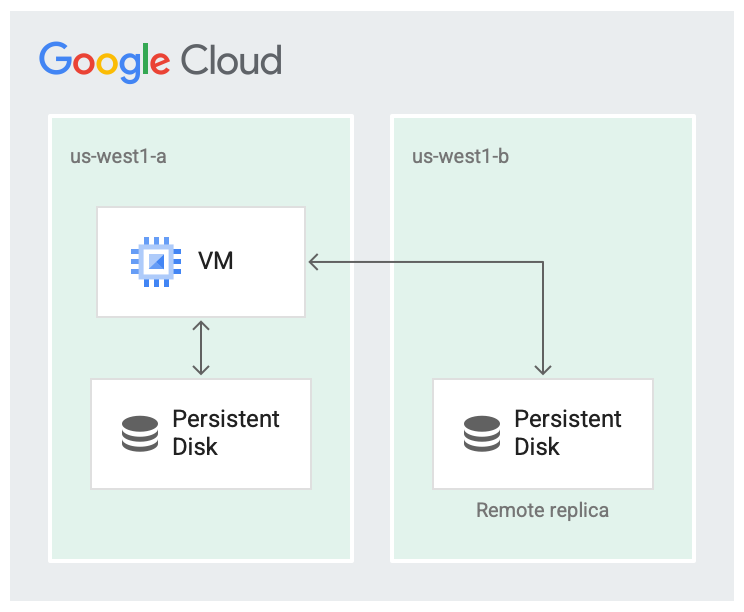
Le disque est répliqué dans deux zones.
Dans le scénario répliqué, les données sont disponibles dans la zone locale (us-west1-a), qui est la zone dans laquelle la machine virtuelle (VM) s'exécute. Ensuite, les données sont répliquées sur une autre zone (us-west1-b). Au moins une des zones doit être la même que celle dans laquelle la VM s'exécute.
En cas d'indisponibilité d'une zone, vous pouvez généralement faire basculer la charge de travail en cours d'exécution sur le volume Persistent Disk régional vers une autre zone. Pour en savoir plus, consultez la page Basculement du disque Persistent Disk régional.
Considérations de conception pour les volumes Persistent Disk régionaux
Si vous concevez des systèmes robustes ou des services à haute disponibilité sur Compute Engine, utilisez des volumes Persistent Disk régionaux en parallèle d'autres bonnes pratiques, telles que la sauvegarde des données à l'aide d'instantanés. Les volumes Persistent Disk régionaux sont également conçus pour fonctionner avec des groupes d'instances gérés régionaux.
Performances
Les volumes Persistent Disk régionaux sont conçus pour des charges de travail nécessitant un objectif de reprise après sinistre (RPO, Recovery Point Objective) et un objectif de temps de récupération (RTO, Recovery Time Objective) inférieurs à ceux des instantanés Persistent Disk.
Les disques Persistent Disk régionaux peuvent être utilisés lorsque les performances des opérations d'écriture sont moins essentielles que la redondance des données sur plusieurs zones.
Tout comme les volumes Persistent Disk zonaux, les volumes Persistent Disk régionaux peuvent atteindre des performances d'IOPS et de débit supérieures sur les VM comportant un plus grand nombre de processeurs virtuels. Pour en savoir plus à ce sujet et sur les autres limites, consultez la section Configurer les disques pour répondre aux exigences de performances.
Lorsque vous avez besoin d'espace disque supplémentaire ou de meilleures performances, vous pouvez redimensionner vos disques régionaux pour augmenter l'espace de stockage, le débit et les IOPS.
Fiabilité
Compute Engine réplique les données de votre disque Persistent Disk régional dans les zones que vous avez sélectionnées lors de la création de vos disques. Les données de chaque instance dupliquée sont réparties sur plusieurs machines physiques dans la zone pour assurer la redondance.
Comme pour les disques Persistent Disk zonaux, vous pouvez créer des instantanés de disques Persistent Disk pour vous protéger contre la perte de données due aux erreurs des utilisateurs. Les instantanés sont incrémentiels et sont créés en quelques minutes seulement, même sur des disques associés à des VM en cours d'exécution.
Limites
- Mexico, Montréal et Osaka comportent trois zones hébergées dans un ou deux centres de données physiques. Étant donné que les données stockées dans ces régions peuvent être perdues dans les rares cas de destruction des centres de données, vous pouvez envisager de sauvegarder les données critiques de votre entreprise dans une deuxième région afin d'améliorer leur protection.
- Vous ne pouvez associer un disque persistant régional qu'aux VM qui utilisent les types de machines E2, N1, N2 et N2D.
- Vous ne pouvez associer les disques Hyperdisk équilibrés à haute disponibilité Balanced qu'aux types de machines compatibles.
- Vous ne pouvez pas créer de disque persistant régional à partir d'une image ou d'un disque créé à partir d'une image.
- Lorsque vous utilisez le mode lecture seule, vous pouvez associer un disque persistant avec équilibrage à un maximum de 10 instances de VM.
- La taille minimale d'un disque persistant standard régional est de 200 Gio.
- Vous ne pouvez qu'augmenter la taille d'un volume de disque persistant régional ouHyperdisk équilibré à haute disponibilité ; vous ne pouvez pas la réduire.
- Les volumes Persistent Disk régionaux et Hyperdisk équilibrés à haute disponibilité ont des caractéristiques de performances différentes de celles des disques zonaux correspondants. Pour en savoir plus, consultez la page Performances des options de stockage de blocs.
- Vous ne pouvez pas utiliser un volume Hyperdisk équilibré à haute disponibilité en mode écriture simultanée comme disque de démarrage.
- Si vous créez un disque répliqué en clonant un disque zonal, les deux instances dupliquées zonales ne sont pas entièrement synchronisées au moment de la création. Une fois créé, vous pouvez utiliser le clone de disque régional dans un délai moyen de trois minutes. Toutefois, vous devrez peut-être attendre quelques dizaines de minutes avant que le disque n'atteigne un état entièrement répliqué et que l'objectif de point de récupération (RPO, Recovery Point Objective) soit proche de zéro. Découvrez comment vérifier si votre disque répliqué est entièrement répliqué.
Google Cloud Hyperdisk
Google Cloud Hyperdisk est la solution de stockage de blocs nouvelle génération de Google. Grâce au déchargement et au scaling horizontal du traitement, les performances de stockage sont dissociées du type et de la taille de la VM. Hyperdisk offre des performances, une flexibilité et une efficacité nettement supérieures à celles des disques persistants.
Volume Hyperdisk équilibré
Hyperdisk avec équilibrage pour Compute Engine convient à un large éventail de cas d'utilisation, tels que les applications métier (LOB), les applications Web et les bases de données de niveau moyen ne nécessitant pas les performances de l'hyperdisque extrême. Vous pouvez également utiliser Hyperdisk équilibré pour les applications dans lesquelles plusieurs VM d'une même zone ont besoin d'un accès en écriture simultané au même disque.
Les volumes Hyperdisk Balanced vous permettent d'ajuster de manière dynamique la capacité, les IOPS et le débit de vos charges de travail.
Hyperdisk ML
Les charges de travail qui utilisent des accélérateurs pour entraîner ou diffuser des modèles de machine learning doivent utiliser Hyperdisk ML. Les volumes Hyperdisk ML offrent le débit personnalisable le plus rapide et conviennent mieux aux modèles de plus de 20 Gio. Hyperdisk ML permet également l'accès en lecture simultanée au même volume à partir de plusieurs VM.
Vous pouvez ajuster de manière dynamique la capacité et le débit d'un volume Hyperdisk ML.
Hyperdisk Extreme
Les volumes Hyperdisk Extreme offrent le stockage de blocs le plus rapide disponible. Ils sont adaptés aux charges de travail exigeantes qui nécessitent le débit et les IOPS les plus élevés.
Les volumes Hyperdisk Extreme vous permettent d'ajuster la capacité et les IOPS de vos charges de travail de manière dynamique.
Hyperdisk Throughput
Les volumes Hyperdisk Throughput sont adaptés aux analyses évolutives, y compris Hadoop et Kafka, aux lecteurs de données pour les applications sensibles aux coûts et au stockage à froid.
Les volumes Hyperdisk Throughput vous permettent d'ajuster la capacité et le débit de vos charges de travail de manière dynamique. Vous pouvez modifier le niveau de débit provisionné sans temps d'arrêt ni interruption de vos charges de travail.
Volume Hyperdisk équilibré à haute disponibilité
Un volume Hyperdisk équilibré à haute disponibilité permet une réplication synchrone sur les séries de machines de troisième génération ou ultérieure. Un volume Hyperdisk équilibré à haute disponibilité garantit la résilience des données grâce à une réplication RPO=0 sur deux zones, semblable au volume Persistent Disk régional.
Les volumes Hyperdisk équilibrés à haute disponibilité vous permettent d'ajuster de manière dynamique la capacité, les IOPS et le débit de vos charges de travail. Vous pouvez modifier les niveaux de performances et de capacité provisionnés sans temps d'arrêt ni interruption de vos charges de travail. Utilisez Hyperdisk équilibré à haute disponibilité lorsque différentes VM d'une même région ont besoin d'un accès en écriture simultané au même disque.
Les volumes Hyperdisk sont créés et gérés comme un disque Persistent Disk, avec la possibilité supplémentaire de définir le niveau d'IOPS ou de débit provisionné et de modifier cette valeur à tout moment. Il n'existe pas de chemin de migration direct entre disque Persistent Disk et Hyperdisk. À la place, vous pouvez créer un instantané et le restaurer sur un nouveau volume Hyperdisk.
Pour en savoir plus sur les disques Hyperdisk, consultez la page À propos d'Hyperdisk.
Durabilité des disques Hyperdisk
La durabilité du disque représente la probabilité de perte de données, de par sa conception, pour un disque type au cours d'une année type. La durabilité est calculée à l'aide d'un ensemble d'hypothèses sur les défaillances matérielles, telles que :
- Probabilité d'événements catastrophiques
- Pratiques d'isolation
- Processus d'ingénierie dans les centres de données Google
- Encodages internes utilisés par chaque type de disque
Les événements de perte de données Hyperdisk sont extrêmement rares. Google prend également de nombreuses mesures pour limiter le risque de corruption des données silencieuses dans l'ensemble du secteur.
Une erreur humaine commise par un client Google Cloud, par exemple lorsqu'un client supprime un disque par inadvertance, n'entre pas dans le cadre de la durabilité des disques Hyperdisk.
Le tableau ci-dessous indique la durabilité pour la conception de chaque type de disque. Une durabilité de 99,999 % signifie qu'avec 1 000 disques, vous atteindrez probablement une centaine d'années sans perdre un seul disque.
| Volume Hyperdisk équilibré | Hyperdisk Extreme | Hyperdisk ML | Hyperdisk Throughput |
|---|---|---|---|
| Mieux que 99,999 % | Mieux que 99,9999 % | Mieux que 99,999 % | Mieux que 99,999 % |
Chiffrement des disques Hyperdisk
Compute Engine chiffre automatiquement vos données lors de l'écriture sur un volume Hyperdisk. Vous pouvez également personnaliser le chiffrement avec des clés de chiffrement gérées par le client.
Haute disponibilité sur Hyperdisk équilibré
Les disques Hyperdisk équilibrés à haute disponibilité fournissent un stockage et une réplication durables des données entre deux zones de la même région. Les volumes Hyperdisk équilibrés à haute disponibilité ont des limites de stockage semblables à celles des disques Hyperdisk équilibrés non répliqués.
Si vous concevez des systèmes robustes ou des services à haute disponibilité sur Compute Engine, utilisez des disques Hyperdisk équilibrés à haute disponibilité en parallèle d'autres bonnes pratiques, telles que la sauvegarde des données à l'aide d'instantanés. Les disques Hyperdisk équilibrés à haute disponibilité sont également conçus pour fonctionner avec des groupes d'instances gérés régionaux.
Dans le cas peu probable d'une défaillance de zone, vous pouvez généralement faire basculer la charge de travail en cours d'exécution sur les disques Hyperdisk équilibrés à haute disponibilité vers une autre zone à l'aide de l'option --force-attach. L'option --force-attach vous permet d'associer le disque Hyperdisk équilibré à haute disponibilité à une instance de secours, même si le disque ne peut pas être dissocié de l'instance de calcul d'origine en raison de son indisponibilité. Pour en savoir plus, consultez la page Basculement du disque régional.
Performance
Les disques Hyperdisk équilibrés à haute disponibilité sont conçus pour des charges de travail nécessitant un objectif de point de récupération (RPO, Recovery Point Objective) et un objectif de temps de récupération (RTO, Recovery Time Objective) inférieurs à ceux des instantanés Hyperdisk pour la récupération.
Les disques Hyperdisk équilibrés à haute disponibilité peuvent être utilisés lorsque les performances des opérations d'écriture sont moins essentielles que la redondance des données sur plusieurs zones.
Les disques Hyperdisk équilibrés à haute disponibilité offrent des performances d'IOPS et de débit personnalisables. Pour en savoir plus sur les performances et les limites des volumes Hyperdisk équilibrés à haute disponibilité, consultez la page À propos d'Hyperdisk.
Lorsque vous avez besoin d'espace disque supplémentaire ou de meilleures performances, vous pouvez modifier les disques Hyperdisk équilibrés à haute disponibilité pour augmenter l'espace de stockage, le débit et les IOPS.
Fiabilité
Compute Engine réplique les données de vos disques Hyperdisk équilibrés à haute disponibilité dans les zones que vous avez spécifiées lors de la création des disques. Les données de chaque instance dupliquée sont réparties sur plusieurs machines physiques dans la zone pour assurer la redondance.
Comme pour Hyperdisk, vous pouvez créer des instantanés de disques Hyperdisk équilibrés à haute disponibilité pour vous protéger contre les pertes de données dues aux erreurs des utilisateurs. Les instantanés sont incrémentiels et sont créés en quelques minutes seulement, même sur des disques associés à des VM en cours d'exécution.
Partager des volumes Hyperdisk entre des VM
Pour certains volumes Hyperdisk, vous pouvez activer l'accès simultané au volume à partir de plusieurs VM en activant le partage de disque. Le partage de disque est utile dans divers cas d'utilisation, tels que la création d'applications hautement disponibles ou en cas de charges de travail de machine learning volumineuses où plusieurs VM doivent accéder au même modèle ou aux mêmes données d'entraînement.
Pour en savoir plus, consultez la section Partager un disque entre plusieurs VM.
Pools de stockage Hyperdisk
Les pools de stockage Hyperdisk permettent de réduire plus facilement le coût total de possession (TCO) de votre stockage de blocs et de simplifier la gestion du stockage de blocs. Les pools de stockage Hyperdisk vous permettent de partager un pool de capacité et de performances sur un maximum de 1 000 disques dans un même projet. Étant donné que les pools de stockage offrent une allocation dynamique de capacité et une réduction des données, vous pouvez améliorer l'efficacité. Les pools de stockage simplifient la migration de votre SAN sur site vers le cloud, et facilitent également l'apport à vos charges de travail de la capacité et des performances dont elles ont besoin.
Vous créez un pool de stockage avec la capacité et les performances estimées pour toutes les charges de travail d'un projet dans une zone spécifique. Vous créez ensuite des disques dans ce pool de stockage et les associer à des VM existantes. Vous pouvez également créer un disque dans le pool de stockage lors de la création d'une nouvelle VM. Chaque pool de stockage contient un type de disque, tel que "Hyperdisk Throughput". Il existe deux types de pools de stockage Hyperdisk :
- Pool de stockage Hyperdisk Balanced : pour les charges de travail à usage général qui sont mieux diffusées avec des disques Hyperdisk Balanced
- Pool de stockage Hyperdisk Throughput: pour les charges de travail de streaming, de données froides et d'analyse qui sont mieux diffusées avec des disques Hyperdisk Throughput
Options de provisionnement de capacité
La capacité du pool de stockage Hyperdisk peut être provisionnée de deux manières :
- Provisionnement de capacité Standard
- Le provisionnement de capacité Standard vous permet de créer des disques dans le pool de stockage jusqu'à ce que la taille totale de tous les disques atteigne la capacité provisionnée du pool de stockage. Les disques d'un pool de stockage avec le provisionnement de capacité Standard consomment de la capacité de la même manière que les disques hors pool, où la capacité est consommée lorsque vous créez les disques.
- Provisionnement de capacité Advanced
Le provisionnement de capacité Advanced vous permet de partager un pool de capacité de stockage bénéficiant de l'allocation dynamique de capacité et de la réduction des données sur tous les disques d'un pool de stockage. La capacité provisionnée du pool de stockage vous est facturée.
Vous pouvez provisionner jusqu'à 500 % de la capacité provisionnée du pool de stockage sur les disques d'un pool de stockage de capacité Advanced. Seule la quantité de données écrites sur un disque dans le pool de stockage consomme la capacité du pool de stockage. La réduction automatique des données peut réduire encore davantage la consommation de la capacité du pool de stockage.
Si l'utilisation de la capacité d'un pool de stockage de capacité Advanced atteint 80 % de la capacité provisionnée, les pools de stockage Hyperdisk tentent d'ajouter automatiquement de la capacité au pool de stockage pour éviter les erreurs liées à une capacité insuffisante.
Exemple
Supposons que vous disposez d'un pool de stockage avec 10 Tio de capacité provisionnée.
Avec le provisionnement de capacité Standard :
- Vous pouvez provisionner jusqu'à 10 Tio de capacité Hyperdisk globale lorsque vous créez des disques dans le pool de stockage. Les 10 Tio de capacité provisionnée du pool de stockage vous sont facturés.
- Si vous créez un seul disque de 5 Tio dans le pool de stockage et écrivez 2 Tio sur le disque, la capacité utilisée du pool de stockage est de 5 Tio.
Avec le provisionnement de capacité Advanced :
- Vous pouvez provisionner jusqu'à 50 Tio de capacité Hyperdisk globale lorsque vous créez des disques dans le pool de stockage. Les 10 Tio de capacité provisionnée du pool de stockage vous sont facturés.
- Si vous créez un seul disque de 5 Tio dans le pool de stockage, que vous écrivez 3 Tio de données sur le disque, et que la réduction des données réduit la quantité de données écrites à 2 Tio, la capacité utilisée du pool de stockage est de 2 Tio.
Options de provisionnement des performances
Les performances du pool de stockage Hyperdisk peuvent être provisionnées de deux manières :
- Provisionnement de performances standard
Les performances standards sont la meilleure option pour les types de charges de travail suivants:
- Charges de travail qui ne peuvent pas aboutir si les performances sont limitées par les ressources du pool de stockage
- Charges de travail pour lesquelles les disques du pool de stockage sont susceptibles de présenter des pics de performances corrélés, par exemple, les disques de données pour les bases de données qui atteignent leur pic d'utilisation chaque matin.
Les pools de stockage de performances standards ne bénéficient pas de l'allocation dynamique de capacité et ne réduiront pas sensiblement votre TCO en termes de performances. Avec le provisionnement de performances standard, vous créez des disques dans le pool de stockage jusqu'à ce que le nombre total d'IOPS ou de débit provisionnés de tous les disques atteigne la quantité provisionnée du pool de stockage. Les disques d'un pool de stockage avec le provisionnement de performances standard consomment des IOPS et un débit de la même manière que les disques hors pool, où vous provisionnez la quantité d'IOPS et le débit lorsque vous créez les disques. Le nombre total d'IOPS et le débit provisionnés pour le pool de stockage vous sont facturés.
Dans un pool de stockage Hyperdisk Balanced avec des performances standard, les 3 000 premières IOPS et les 140 Mio/s de débit de chaque disque du pool de stockage (la valeur de référence) ne consomment pas de ressources de pool de stockage. Lorsque vous créez des disques dans le pool de stockage, les IOPS et le débit dépassant les valeurs de référence consomment des IOPS et du débit du pool de stockage.
Les disques créés dans un pool de stockage de performances Standard ne partagent pas les ressources de performances avec le reste du pool de stockage. La quantité globale de performances de tous les disques du pool de stockage ne peut pas dépasser le total des IOPS ou du débit provisionnés du pool de stockage.
- Provisionnement des performances avancées
Les pools de stockage avec provisionnement des performances avancées exploitent l'allocation dynamique de capacité pour améliorer l'efficacité des performances et réduire le coût total de possession des performances de stockage de blocs. Le provisionnement de performances avancé vous permet de partager un pool de performances provisionnées sur tous les disques d'un pool de stockage. Le pool de stockage alloue dynamiquement des ressources de performances lorsque les disques du pool de stockage lisent et écrivent des données. Seule la quantité d'IOPS et de débit utilisés par un disque dans le pool de stockage consomme les IOPS et le débit du pool de stockage. Comme les pools de stockage aux performances avancées sont exclusivement provisionnés, vous pouvez allouer plus d'IOPS ou de débit aux disques du pool de stockage que celui que vous avez provisionné pour le pool de stockage (jusqu'à 500% des IOPS ou du débit provisionnés pour le pool de stockage). Comme pour les performances standard, vous êtes facturé pour les IOPS et le débit provisionnés pour le pool de stockage.
Dans un pool de stockage Hyperdisk Balanced avec provisionnement des performances avancées, les disques n'ont pas de performances de référence. Chaque opération de lecture et d'écriture d'un disque Hyperdisk Balanced dans le pool de stockage consomme des ressources du pool.
Lorsque l'utilisation globale des performances de tous les disques du pool de stockage atteint la quantité totale de performances provisionnées pour le pool de stockage, les disques peuvent faire face à un conflit de performances. Par conséquent, le provisionnement avancé des performances est le plus adapté aux charges de travail dont les pics d'utilisation ne sont pas fortement corrélés. Si toutes vos charges de travail enregistrent des valeurs maximales en même temps, le pool de stockage aux performances avancées peut atteindre les limites de performances du pool de stockage, ce qui entraîne un conflit de ressources de performances.
Si une contention de ressources de performances est détectée dans un pool de stockage aux performances avancées pour l'un des disques du pool, la fonctionnalité de croissance automatique tente d'augmenter automatiquement les IOPS ou le débit disponibles pour les disques du pool de stockage afin d'éviter les problèmes de performances.
Exemple
Supposons que vous disposiez d'un pool de stockage Hyperdisk équilibré avec 100 000 IOPS provisionnés.
Avec le provisionnement de performances standard:
- Vous pouvez provisionner jusqu'à 100 000 IOPS globaux lorsque vous créez des disques Hyperdisk équilibrés dans le pool de stockage.
- Les 100 000 IOPS de performances provisionnées du pool de stockage Hyperdisk équilibré vous sont facturés.
Comme les disques créés en dehors d'un pool de stockage, les disques Hyperdisk Balanced dans les pools de stockage de performances standards sont automatiquement provisionnés avec jusqu'à 3 000 IOPS de référence et 140 Mo/s de débit de référence. Ces performances de référence ne sont pas comptabilisées dans les performances provisionnées pour le pool de stockage. Ce n'est que lorsque vous ajoutez des disques au pool de stockage avec des performances provisionnées supérieures à celles de référence qu'ils sont comptabilisés dans les performances provisionnées pour le pool de stockage, par exemple :
- Un disque provisionné avec 3 000 IOPS utilise 0 IOPS du pool et 100 000 IOPS provisionnées sont toujours disponibles pour les autres disques.
- Un disque provisionné avec 13 000 IOPS utilise 10 000 IOPS du pool et le pool dispose de 90 000 IOPS provisionnées restantes que vous pouvez allouer à d'autres disques du pool de stockage.
Avec le provisionnement des performances avancées :
- Vous pouvez provisionner jusqu'à 500 000 IOPS de performances Hyperdisk globales lorsque vous créez des disques dans le pool de stockage.
- Les 100 000 IOPS provisionnés par le pool de stockage vous sont facturés.
- Si vous créez un seul disque (
Disk1) dans le pool de stockage avec 5 000 IOPS, vous ne consommez aucun IOPS des IOPS provisionnées du pool de stockage. Toutefois, le nombre d'IOPS que vous pouvez provisionner pour les nouveaux disques créés dans le pool de stockage est désormais de 495 000. - Si
Disk1commence à lire et à écrire des données, et s'il utilise son maximum de 5 000 IOPS par minute donnée, 5 000 IOPS sont consommés à partir des IOPS provisionnés du pool de stockage. Tous les autres disques que vous avez créés dans le même pool de stockage peuvent utiliser un maximum agrégé de 95 000 IOPS au cours de la même minute sans entrer en conflit.
Modifier la capacité et les performances provisionnées du pool de stockage Hyperdisk
Vous pouvez augmenter ou diminuer la capacité, les IOPS et le débit provisionnés pour votre pool de stockage à mesure que vos charges de travail évoluent. Avec un pool de stockage à capacité avancée ou aux performances avancées, toute capacité ou performance supplémentaire est disponible pour tous les disques existants et nouveaux du pool de stockage. De plus, Compute Engine tente de modifier automatiquement le pool de stockage comme suit:
- Capacité avancée : lorsque le pool de stockage atteint 80 % de la capacité provisionnée utilisée, Compute Engine tente d'ajouter automatiquement plus de capacité au pool de stockage.
- Performances avancées : si le pool de stockage subit une forte contention en raison d'une surutilisation, Compute Engine tente d'augmenter les IOPS ou le débit du pool de stockage.
Informations supplémentaires concernant le pool de stockage Hyperdisk
Pour en savoir plus sur l'utilisation des pools de stockage Hyperdisk, utilisez les liens suivants :
- À propos des pools de stockage
- Créer des pools de stockage
- Ajouter des disques aux VM à l'aide d'un pool de stockage
- Gérer les pools de stockage
- Examiner les métriques des pools de stockage
Disques SSD locaux
Les disques SSD locaux sont rattachés physiquement au serveur qui héberge votre VM. Ils ont un débit supérieur et une latence moindre par rapport aux disques Persistent Disk standards ou aux disques Persistent Disk SSD. Les données que vous stockez sur un disque SSD local ne sont conservées que jusqu'à ce que la VM soit arrêtée ou supprimée. Vous pouvez associer plusieurs disques SSD locaux à votre VM, en fonction du nombre de vCPU.
La taille de chaque disque SSD local est fixée à 375 Gio, à l'exception des VM Z3 qui utilisent un disque SSD local de 3 Tio. Pour augmenter l'espace de stockage, ajoutez plusieurs disques SSD locaux à votre VM lors de sa création. Le nombre maximal de disques SSD locaux que vous pouvez associer à une VM dépend du type de machine et du nombre de processeurs virtuels utilisés.
Persistance des données sur les disques SSD locaux
Veuillez lire la section Persistance des données sur les disques SSD locaux pour savoir quels événements conservent vos données de disques SSD locaux et quels événements peuvent les rendre irrécupérables.
Disques SSD locaux et types de machines
Vous pouvez associer des disques SSD locaux à la plupart des types de machines disponibles sur Compute Engine, comme indiqué dans le tableau Comparaison des séries de machines. Il existe toutefois certaines contraintes sur le nombre de disques SSD locaux que vous pouvez associer, en fonction du type de machine. Pour en savoir plus, consultez la page Choisir un nombre valide de disques SSD locaux.
Limites de capacité avec des disques SSD locaux
La capacité maximale d'un disque SSD local pour une VM est définie comme suit :
| Type de machine | Taille du disque SSD local | Nombre de disques | Capacité maximale |
|---|---|---|---|
| Z3 | 3 Tio | 12 | 36 Ti0 |
c3d-standard-360-lssd |
375 Gio | 32 | 12 Tio |
c3d-highmem-360-lssd |
375 Gio | 32 | 12 Tio |
c3-standard-176-lssd |
375 Gio | 32 | 12 Tio |
| N1, N2 et N2D | 375 Gio | 24 | 9 Tio |
| N1, N2 et N2D | 375 Gio | 16 | 6 Tio |
| A3 | 375 Gio | 16 | 6 Tio |
| C2, C2D, A2 standard, M1 et M3 | 375 Gio | 8 | 3 Tio |
| A2 ultra | 375 Gio | 8 | 3 Tio |
Limites des disques SSD locaux
Le disque SSD local présente les limites suivantes :
- Pour atteindre les limites maximales d'IOPS, utilisez une VM comportant au moins 32 vCPU.
- Les VM avec des types de machines à cœur partagé ne peuvent pas associer de disques SSD locaux.
- Vous ne pouvez pas associer de disques SSD locaux aux types de machines N4, H3, M2 E2 et Tau T2A.
- Vous ne pouvez pas utiliser les clés de chiffrement fournies par le client avec des disques SSD locaux. Compute Engine chiffre automatiquement vos données lorsqu'elles sont écrites dans l'espace de stockage d'un disque SSD local.
Performances
Les disques SSD locaux offrent un nombre très élevé d'IOPS et une faible latence. Contrairement au disque persistant, vous devez gérer vous-même la répartition sur les disques SSD locaux.
Les performances des disques SSD locaux dépendent de plusieurs facteurs. Pour en savoir plus, consultez les pages Performances des disques SSD locaux et Optimiser les performances des disques SSD locaux.
Buckets Cloud Storage
Les buckets Cloud Storage sont une option de stockage flexible, évolutive et durable pour vos VM. Si vos applications ne nécessitent pas la latence réduite qu'offrent les volumes Hyperdisk, Persistent Disks, et les disques SSD locaux, vous pouvez stocker vos données dans un bucket Cloud Storage.
Connectez votre VM à un bucket Cloud Storage lorsque la latence et le débit ne sont pas des critères essentiels et lorsque vous devez partager facilement des données entre plusieurs VM ou zones.
Propriétés des buckets Cloud Storage
Consultez les sections suivantes pour comprendre le comportement et les caractéristiques des buckets Cloud Storage.
Performances
Les performances des buckets Cloud Storage dépendent de la classe de stockage que vous sélectionnez et de la zone où se situe le bucket par rapport à votre VM.
L'utilisation de la classe de stockage standard de Cloud Storage dans le même emplacement que votre VM offre des performances comparables à celles d'un volume Hyperdisk ou Persistent Disks , mais avec une latence plus élevée et des caractéristiques de débit moins cohérentes. L'utilisation de la classe de stockage standard dans un emplacement birégional stocke vos données de manière redondante dans deux régions. Pour optimiser les performances lors de l'utilisation d'un emplacement birégional, vos VM doivent être situées dans l'une des régions de l'emplacement birégional.
Les classes de stockage Nearline, Coldline et Archive sont principalement destinées à l'archivage des données à long terme. Contrairement à la classe de stockage standard, ces classes ont des durées de stockage minimales et entraînent des coûts de récupération des données. Par conséquent, elles conviennent mieux au stockage à long terme de données rarement utilisées.
Fiabilité
Tous les buckets Cloud Storage sont dotés d'une fonction de redondance intégrée qui protège vos données contre les pannes de matériel et assure la disponibilité de celles-ci lors des événements de maintenance du centre de données. Le calcul d'une somme de contrôle pour toutes les opérations Cloud Storage permet de s'assurer que les données lues sont bien identiques à celles qui ont été écrites.
Flexibilité
Contrairement aux volumes Hyperdisk ou Persistent Disks, les buckets Cloud Storage ne sont pas limités à la zone dans laquelle se situe votre VM. Vous pouvez également lire et écrire des données dans un bucket à partir de plusieurs VM simultanément. Par exemple, vous pouvez configurer des VM dans plusieurs zones pour lire et écrire des données dans le même bucket au lieu de répliquer les données sur un volume Hyperdisk ou Persistent Disk dans plusieurs zones.
Chiffrement dans Cloud Storage
Compute Engine chiffre automatiquement vos données avant leur transfert depuis votre VM vers les buckets Cloud Storage. Vous n'avez pas besoin de chiffrer les fichiers sur vos VM avant de les écrire dans un bucket.
Comme pour les volumes Persistent Disk, vous pouvez chiffrer les buckets avec vos propres clés de chiffrement.Écrire et lire des données dans des buckets Cloud Storage
Écrivez et lisez des fichiers dans des buckets Cloud Storage à l'aide de l'outil de ligne de commande gcloud storage ou d'une bibliothèque cliente Cloud Storage.
gcloud storage
Par défaut, l'outil de ligne de commande gcloud storage est installé sur la plupart des VM utilisant des images publiques.
Si l'outil de ligne de commande gcloud storage n'est pas disponible sur votre VM, vous pouvez l'installer.
Connectez-vous à vos VM Linux ou connectez-vous à vos VM Windows à l'aide de SSH ou d'une autre méthode de connexion.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.

Si vous n'avez jamais utilisé
gcloud storagesur cette VM auparavant, utilisez gcloud CLI pour configurer les identifiants.gcloud init
Si votre VM est configurée pour utiliser un compte de service avec un champ d'application Cloud Storage, vous pouvez également ignorer cette étape.
L'outil
gcloud storagevous permet de créer un bucket, d'écrire des données dessus et de lire des données à partir de ces buckets. Pour écrire ou lire des données dans un bucket spécifique, vous devez avoir accès à ce bucket. Vous pouvez lire des données à partir de n'importe quel bucket accessible au public.En option, vous pouvez également diffuser des données vers Cloud Storage.
Bibliothèque cliente
Si vous avez configuré votre VM pour utiliser un compte de service avec un champ d'application Cloud Storage, vous pouvez utiliser l'API Cloud Storage pour écrire et lire des données dans des buckets Cloud Storage.
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.
Installez et configurez une bibliothèque cliente pour votre langage préféré.
Si nécessaire, suivez les exemples de code à insérer pour créer un bucket Cloud Storage sur la VM.
Suivez les exemples de code à insérer pour écrire et lire des données, et incluez dans votre application du code permettant d'accéder en lecture et/ou en écriture à un fichier stocké dans un bucket Cloud Storage.
Étape suivante
- Ajoutez un volume Hyperdisk à votre VM.
- Ajoutez un volume Persistent Disk à votre VM.
- Ajoutez un disque régional à votre VM.
- Créez une VM avec des disques SSD locaux.
- Créez un serveur de fichiers ou un système de fichiers distribués.
- Vérifiez les quotas des disques.
- Installez un disque RAM sur votre VM.