您可以通过查看磁盘性能状态指标来检查 Persistent Disk 或 Google Cloud Hyperdisk 卷的健康状况。此指标表示磁盘性能是否可能会受到 Compute Engine 中的不利事件的影响。
影响磁盘性能状态的问题也可能会显示在项目的 Personal Service Health (PSH) 信息中心或 Google Cloud Service Health 信息中心内。
本文档讨论了磁盘性能状态以及如何使用该状态来排查性能问题。
何时检查磁盘的健康状况
如果您发现磁盘存在性能问题,请通过查看磁盘性能状态指标来检查磁盘的健康状况。磁盘性能状态指标每分钟更新一次,表示整个前一分钟内的磁盘性能。如需了解检查磁盘健康状况的步骤,请参阅查看磁盘性能状态。
下表总结了磁盘性能状态的可能值。
| 状态 | 含义 |
|---|---|
Healthy |
磁盘性能符合预期。 |
Degraded |
您可能会暂时观察到 I/O 延迟时间高于预期。 |
Severely degraded |
出现较高 I/O 延迟时间或其他错误。 |
如果性能状态不是 Healthy,请参阅了解每种状态以了解后续步骤。
如果性能状态为 Healthy,则表示磁盘正常运行,您需要检查导致性能问题的其他原因。您应检查应用或操作系统错误,并确保磁盘已正确优化。如需了解优化准则,请参阅优化 Hyperdisk 和优化 Persistent Disk。
磁盘健康状况与其他磁盘性能指标的关系
性能状态指标所指示的磁盘健康状况显示的是从 Google 角度来看的磁盘内部状态。如果磁盘的状态为 Degraded 或 Severely Degraded,则根本原因始终在 Compute Engine 基础架构中。
您通常无法通过修改工作负载来更改磁盘的健康状况。不过,在极少数情况下,对工作负载的更改可能会触发内部问题,因此您可以通过修改工作负载来缓解问题。
如需了解其他可用的磁盘性能指标,请参阅查看磁盘性能指标。
不影响磁盘性能状态的场景
磁盘性能状态与以下因素导致的性能问题无关:
- 磁盘优化不完整或不足
- 与磁盘和机器类型相关联的性能限制(如果所选机器类型无法满足工作负载的性能要求)
- 工作负载流量导致磁盘负载增加
- 用户、应用或操作系统错误
- 磁盘已满或已损坏
- 对于 Hyperdisk 和 Extreme Persistent Disk 卷,预配 IOPS 或吞吐量不足。
在这些情况下,您有责任提高性能,例如优化磁盘、扩容工作负载、更改机器类型以及预配更多容量、IOPS 或吞吐量。
在 Cloud Monitoring 中查看磁盘的健康状况
如需查看磁盘的健康状况,请在 Metrics Explorer 中创建图表。
所需的角色和权限
如需获得检查磁盘性能状态指标所需的权限,请让您的管理员向您授予项目的以下 IAM 角色:
-
Monitoring Viewer (
roles/monitoring.viewer) -
将图表保存到信息中心:Monitoring Editor (
roles/monitoring.editor)
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
在 Metrics Explorer 中创建图表
如需创建图表,请使用菜单驱动的界面或 PromQL 构建查询。
菜单驱动的界面
如需在图表中查看一个或多个磁盘的健康状况,请按照以下说明操作。
-
在 Google Cloud 控制台中,前往 leaderboard Metrics Explorer 页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
- 在 Google Cloud 控制台的工具栏中,选择您的 Google Cloud 项目。对于 App Hub 配置,请选择 App Hub 宿主项目或已启用应用的文件夹的管理项目。
- 在指标元素中,展开选择指标菜单,在过滤条件栏中输入
VM Instance,然后使用子菜单选择一个特定资源类型和指标:- 在活跃资源菜单中,选择虚拟机实例。
- 在活跃指标类别菜单中,选择实例。
- 在活跃指标菜单中,选择 Disk performance status(磁盘性能状态)。
- 点击应用。
compute.googleapis.com/instance/disk/performance_status。 如需添加用于从查询结果中移除时序的过滤条件,请使用过滤条件元素。
- 配置数据的查看方式。
停用汇总。确保在汇总元素中,将第一个菜单设置为不汇总,并将第二个菜单设置为无。
如需查看特定磁盘的健康状况,请按device_name进行过滤。
如需详细了解如何配置图表,请参阅使用 Metrics Explorer 时选择指标。
PromQL
打开查询编辑器:按照编写 PromQL 查询中的步骤操作。
在查询编辑器中输入查询。 例如,如需查看特定磁盘的性能状态,请输入以下查询:
last_over_time
(compute_googleapis_com:instance_disk_performance_status
{monitored_resource="gce_instance",
project_id ="PROJECT_ID",
device_name="DISK_NAME"}[${__interval}])
将 DISK_NAME 替换为磁盘名称,例如 disk-1。
如果您在图表中查看结果,则每个磁盘都有 3 根线条,每种可能的状态对应 1 根。同样,如果您在表格中查看查询结果,则每个磁盘都在表格中有 3 行。
如果您使用 PromQL 构建了查询,则每行或每根线条的值都将为 1 或 0。对于使用菜单构建的查询,值将为 100% 或 0。
磁盘的当前健康状况由值为 100% 或 1 的行或线条表示。
例如,以下屏幕截图显示名为 a-test-VM 且状态为 Healthy 的磁盘的图表:
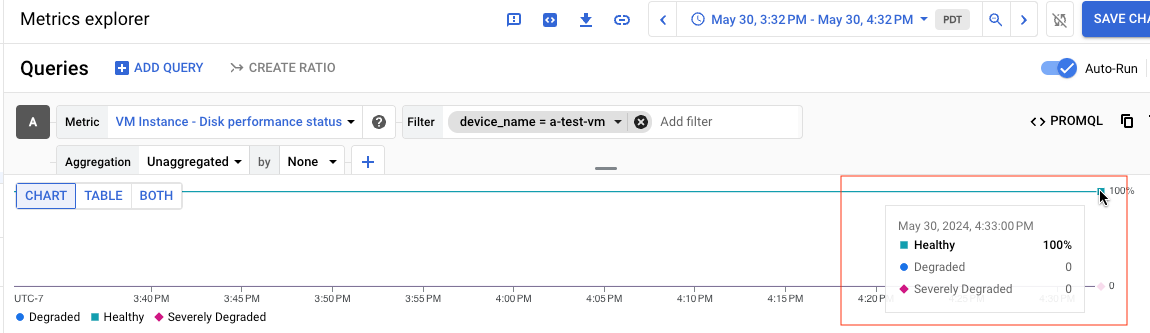
如果您以表格的形式查看查询结果,则下表是状态为 Healthy 磁盘的结果示例:
| performance_status | 值 |
|---|---|
Healthy |
1 |
Degraded |
0 |
Severely Degraded |
0 |
以下屏幕截图显示名为 replica-23509 且状态为“已降级”的磁盘的图表:
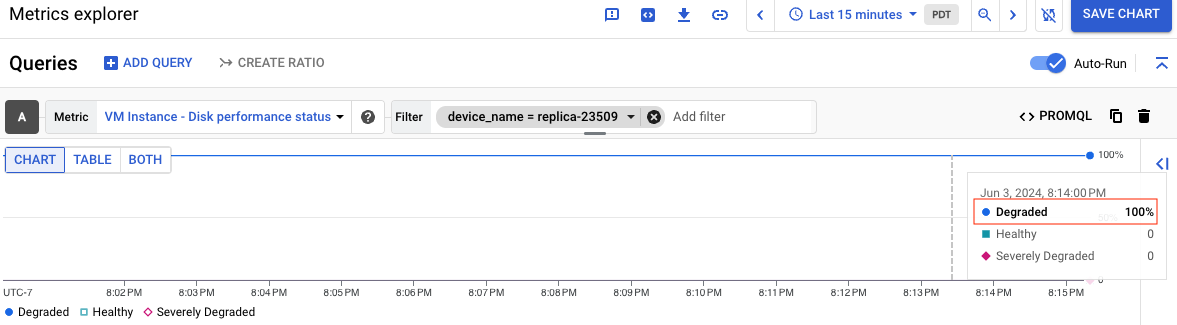
如需了解每种性能状态的含义,请参阅了解每种状态。创建图表后,您可以将图表保存到信息中心以供日后使用。
小数结果
如果您的查询包含小数结果(如下表所示),通常是因为所选显示时段过长。因此,Cloud Monitoring 会随时间的推移汇总数据。如果 Healthy 状态的值为 77%,则表示该磁盘在所选显示时段 77% 的时间内状态为 Healthy。
| performance_status | 值 |
|---|---|
Healthy |
77% |
Degraded |
23% |
Severely Degraded |
0 |
如需更精细地查看磁盘健康状况,请使用几小时或几分钟的显示时段。
了解每种状态
本部分介绍了每种状态的含义以及您可能需要采取进一步操作的情况。
Healthy
Healthy 状态表示从 Google 的角度来看,磁盘正常运行。
如果 Healthy 磁盘存在性能问题,请勿与支持团队联系。请改为按照以下一些建议来排查磁盘问题:
- 查看磁盘性能指标,例如延迟时间和队列深度。
- 检查工作负载的日志和指标,查找异常值和瓶颈。
- 如果您使用的是 Persistent Disk,请确保预配容量可以满足磁盘的性能需求。如果您使用的是 Hyperdisk 或 Extreme Persistent Disk 卷,请验证您是否已预配足够的 IOPS 和吞吐量。
- 确保您已按照相关准则优化磁盘。如需了解详情,请参阅优化 Hyperdisk 和优化 Persistent Disk。
Degraded
如果磁盘状态为 Degraded,您通常无需与支持团队联系。Degraded status 通常是由 Compute Engine 基础架构的正常内部维护引起的。
当磁盘状态为 Degraded 时,您可能不会注意到磁盘性能受到任何影响。如果性能问题与 Degraded 状态在时间上相关,则性能问题可能仍与 Degraded 状态无关。
在 Degraded 状态导致性能问题这种不太可能发生的情况下,影响通常是暂时的。磁盘的状态应在几分钟内恢复为 Healthy。
如果磁盘没有性能问题,您可以放心地忽略 Degraded 状态。
如果出现性能问题,该怎么办
如果您的磁盘性能状态为 Degraded,并且您观察到性能问题,请按以下步骤操作:
- 查看 PSH 信息中心,了解是否存在影响磁盘的突发事件。如果存在突发事件,请勿与支持团队联系,因为 Google 已经知晓并正在努力解决问题。
- 如果不存在已知问题,请等待至少 5 分钟,让性能问题自行解决。
如果 5 分钟后,性能问题未解决且状态仍为
Degraded,请确保性能问题不是由于磁盘优化不充分而导致的。例如,检查磁盘的延迟时间和队列深度。性能问题和Degraded状态可能无关,只是巧合。为此,请查看磁盘的指标和性能优化准则。如果性能问题持续存在,并且满足以下所有条件,您可以与支持团队联系以寻求帮助:
- 磁盘状态已超过 5 分钟处于
Degraded - 您有理由认为这不是工作负载问题,因为您已经优化了磁盘并验证没有其他问题,例如瓶颈或应用过载
- PSH 信息中心内没有提醒
- 磁盘状态已超过 5 分钟处于
Google 不建议直接针对 Degraded 状态创建提醒,而是建议针对更高级别的应用状态创建提醒,并使用此指标来调试问题。
Severely Degraded
性能状态为 Severely Degraded 的磁盘存在性能问题。此问题可能是由突发事件或错误导致的,并且可能已在 PSH 信息中心或 Google Cloud Service Health 信息中心内显示。
您需要采取的行动
如果您的磁盘性能状态为 Severely Degraded,请按以下步骤操作:
- 检查 PSH 信息中心和常规 Google Cloud 健康状况信息中心,了解是否存在影响磁盘的突发事件。如果存在突发事件,请勿与支持团队联系,因为 Google 已经知晓并正在努力解决问题。
- 如果这两个信息中心都没有已知问题,请与支持团队联系以寻求帮助。
决策树
下图说明了在磁盘存在性能问题时如何继续操作,并总结了前面各部分中的信息。

如流程图所示,只有在 PSH 和云服务信息中心内没有已知提醒且磁盘状态为 Severely Degraded 时,您才应与支持团队联系。如果磁盘为 Degraded,请仅在满足以下所有条件时与支持团队联系:
- 磁盘已超过 5 分钟处于
Degraded状态 - 排除了工作负载错误或配置错误(例如网络问题)
- 无法在应用、工作负载或磁盘级别执行其他优化
- 您已查看磁盘的所有指标
- 您已检查工作负载和虚拟机 (VM) 日志
后续步骤
- 详细了解如何使用 Metric Explorer 创建图表以及如何通过向图表添加过滤条件来优化查询结果。
- 在 Personal Service Health 信息中心和 Google Service Health 中查看当前和过去的服务健康状况事件
- 如需了解性能优化准则,请参阅优化 Hyperdisk 和优化 Persistent Disk。