本文档介绍了如何配置临时图表,以显示项目收集的时序数据。Metrics Explorer 只能显示数值时序数据。
选择要显示的数据
如需配置要在图表中显示哪些时序,您可以通过从菜单中进行选择来构建查询,也可以编写查询。编写查询时,您需要选择查询语言,然后使用查询编辑器或基于文本的界面:
Prometheus Query Language (PromQL) 查询会指定时序以及这些时序的分组和校准方式。PromQL 界面支持编辑器,并提供建议。
通常无法将 PromQL 查询转换为其他界面可使用的形式。当您切换到 PromQL 标签页或从 PromQL 标签页切换时,未保存的查询会被舍弃。
Monitoring 过滤条件查询会指定时序,但不包含分组或校准语句。
您可以使用 Monitoring 过滤条件指定 Monitoring 可以绘制图表的任何时序。例如,如需为虚拟机上运行的进程的数量绘制图表,您必须使用指定函数的 Monitoring 过滤条件。
Monitoring 过滤条件并不总是可以转换为其他界面所需的形式。因此,如果您切换到其他界面,查询可能会被舍弃。
查询通常会指定指标类型、资源类型和过滤条件:
指标类型用于标识要从资源收集的测量结果。指标类型包括对要测量的内容以及如何解释测量结果的说明。指标类型有时称为“指标”。指标的一个示例是“CPU 利用率”。如需了解概念性信息,请参阅指标类型。
资源类型用于指定从中捕获指标数据的资源。资源类型有时称为“受监控的资源类型”或“资源”。资源的一个示例是“Compute Engine 虚拟机 (VM) 实例”。 如需了解概念性信息,请参阅受监控的资源。
PromQL 查询包含分组和对齐语句。但是,当您编写 Monitoring 过滤条件或使用菜单来选择要绘制图表的时序时,可以使用菜单配置分组和对齐设置。
使用菜单构建查询
使用菜单构建查询是默认配置。通常,如果您选择指标和过滤条件,然后切换到其他界面,系统会保留您的选择并针对该界面重新设置格式。也就是说,通过菜单构建的查询可以转换为 PromQL 查询。
您可以通过选择 tune 构建器从其他界面返回到菜单驱动的界面。但是,查询会被舍弃。也就是说,PromQL 查询无法转换为等效的菜单驱动形式。
如需使用菜单构建查询,请执行以下操作:
-
在 Google Cloud 控制台中,前往 leaderboard Metrics Explorer 页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
- 在 Google Cloud 控制台的工具栏中,选择您的 Google Cloud 项目。对于 App Hub 配置,请选择 App Hub 宿主项目或管理项目。
在查询窗格的工具栏中,执行以下操作:
在指标元素中,展开选择指标菜单。
选择指标菜单包含一些功能,可帮助您查找可用的指标类型:
如需查找特定指标类型,请使用 filter_list 过滤条件栏。例如,如果您输入
util,则菜单仅会显示包含util的条目。如果条目通过不区分大小写的“包含”测试,则会进行显示。如需显示所有指标类型(甚至是没有数据的指标类型),请点击 活跃。默认情况下,菜单仅会显示有数据的指标类型。
从资源菜单、指标类别菜单和指标菜单中进行选择,然后点击应用。
例如,如需为 Compute Engine 虚拟机的 CPU 利用率绘制图表,您可以选择虚拟机实例、实例、CPU 利用率,然后点击应用。
资源菜单会列出从中收集数据的资源。如果未针对资源写入指标,请选择未指定。
选择资源类型和指标后,图表会显示该对的所有可用时序:
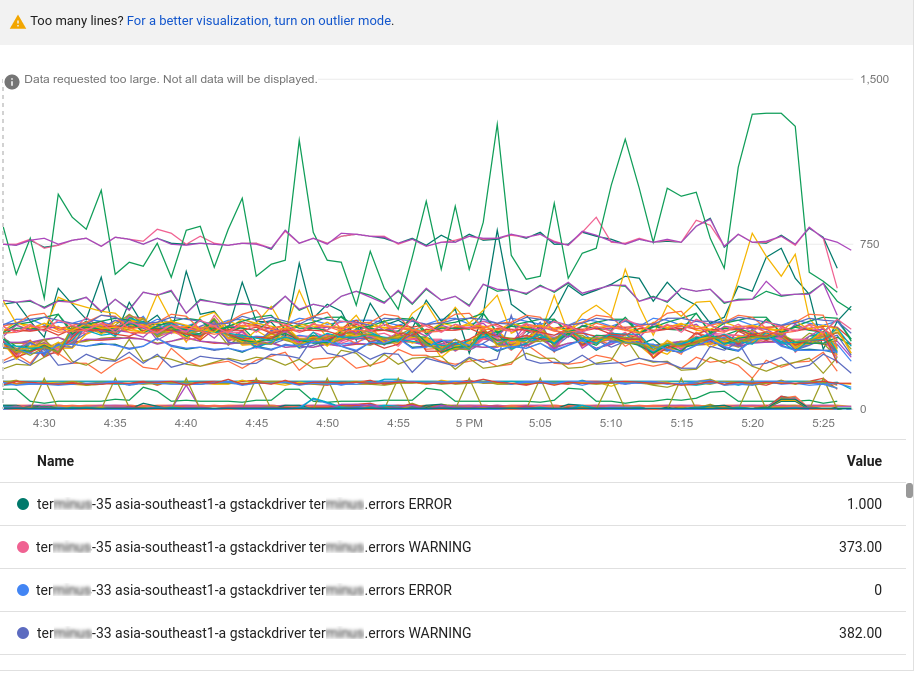
上述图表中包含的数据过多,无法显示;图表只能显示 50 个线条。该图表提示数据太多,无法显示。如需减少数据量,请在查询工具栏中使用排序和限制元素。如需了解详情,请参阅显示离群值。
您还可以使用过滤和聚合选项来减少图表数据量。这些方法使图表对诊断和分析更有用,并且提高了界面本身的性能和响应速度。
可选:添加过滤条件以限制显示哪些时序。下一部分将介绍过滤选项。
可选:配置时序的分组和校准方式。如需了解详情,请参阅选择如何显示绘制成图表的数据。
过滤已绘制成图表的数据
过滤条件可确保仅为满足某组条件的时序绘制图表。应用过滤条件时,您可以减少图表中的线条数量,从而提高图表的性能。另一个可以提高图表响应速度的方式是配置聚合选项,以及对显示的时序进行排序并限制其数量。如需了解详情,请参阅显示离群值。
过滤条件由标签、比较条件和值组成。例如,如需匹配其 zone 标签以 "us-central1" 开头的所有时序,您可以使用过滤条件 zone=~"us-central1.*",该过滤条件使用正则表达式执行比较。比较条件运算符有四种:
- 等于,
= - 不等于,
!= - 正则表达式匹配,
=~ - 正则表达式不匹配,
!=~
按项目 ID 或资源容器进行过滤时,您必须使用等于运算符 (=)。按其他标签进行过滤时,您可以使用任何受支持的比较条件。通常,您可以按指标和资源标签以及资源组进行过滤。
如果您提供多个过滤条件,则相应图表仅会显示符合所有条件(逻辑 AND)的时序。
如需在使用 Google Cloud 控制台的菜单驱动界面时添加过滤条件,请执行以下操作:
在过滤条件元素中,点击添加过滤条件,然后从菜单中进行选择。
如需更改比较,请从比较条件菜单中选择一个值。
在值字段中,输入或选择一个值:
对于直接比较(
=或!=),请从菜单中选择值或输入一个值,然后点击确定。您可以输入值(例如us-central1-a),也可以创建以starts_with或ends_with开头的过滤条件字符串。例如,如需显示任何us-central1可用区的数据,您可以输入过滤条件字符串starts_with("us-central1")。如需详细了解过滤条件字符串,请参阅 Monitoring 过滤条件。由于菜单条目派生自收到的时序,因此,如果受监控的资源没有为所选指标生成数据,则您必须为标签输入一个值。
对于正则表达式比较(
=~或!=~),请在值字段中输入 RE2 正则表达式,然后点击确定。 例如,正则表达式us-central1-.*可与所有us-central1区域匹配:如需匹配以“a”结尾的任何美国可用区,您可以使用正则表达式
^us.*.a$。注意:您不能使用正则表达式来过滤
project_id资源标签。例如,如需仅查看来自某个
us-central1可用区的时序,请应用zone=~"us-central1.*"过滤条件。
添加多个过滤条件时,请遵循以下几点:
您可以多次使用同一标签,可让您为一系列值指定过滤条件。
所有过滤条件都必须满足;它们共同构成逻辑
AND。
如需修改过滤条件的值或比较条件,请在过滤条件元素上点击 arrow_drop_down 菜单,进行更改,然后点击确定。
如需删除过滤条件,请点击 cancel 取消。
编写 PromQL 查询
如需输入 PromQL 查询,请执行以下操作:
-
在 Google Cloud 控制台中,前往 leaderboard Metrics Explorer 页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
- 在 Google Cloud 控制台的工具栏中,选择您的 Google Cloud 项目。对于 App Hub 配置,请选择 App Hub 宿主项目或管理项目。
- 在查询构建器窗格的工具栏中,选择名为 code MQL 或 code PromQL 的按钮。
- 验证已在语言 (Language) 切换开关中选择 PromQL。语言切换开关位于同一工具栏中,用于设置查询的格式。
- 可选:停用自动运行切换开关。
-
在查询编辑器中输入查询。例如,如需为 Google Cloud 项目中的虚拟机实例的平均 CPU 利用率绘制图表,请使用以下查询:
avg(compute_googleapis_com:instance_cpu_utilization)如需详细了解如何使用 PromQL,请参阅 Cloud Monitoring 中的 PromQL。
点击运行查询。
启用自动运行切换开关后,系统不会显示运行查询按钮。
编写 Monitoring 过滤条件查询
如果您想执行以下任一操作,则必须使用直接过滤模式,该模式可让您输入 Monitoring 过滤条件:
- 显示服务等级目标 (SLO)。
- 显示在虚拟机 (VM) 上运行的进程数。
- 显示您尚无其数据的自定义指标。
- 根据您尚无其数据的标签过滤时序。
Monitoring 过滤条件(或等效的指标过滤条件)是 Monitoring 用于识别要绘制成图表的时序的表达式。例如,以下表达式生成的图表显示了其名称包含 nginx 的进程数:
select_process_count("monitoring.regex.full_match(\".*nginx.*\")")
resource.type="gce_instance"
您还可以使用 Monitoring 过滤条件按资源和指标类型标识时序。以下表达式生成的图表显示了 us-east1-b 可用区中所有 Google Cloud 虚拟机实例的日志条目数:
metric.type="logging.googleapis.com/log_entry_count"
resource.type="gce_instance"
resource.label."zone"="us-east1-b"
要输入 Monitoring 过滤条件,请执行以下操作:
-
在 Google Cloud 控制台中,前往 leaderboard Metrics Explorer 页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
- 在 Google Cloud 控制台的工具栏中,选择您的 Google Cloud 项目。对于 App Hub 配置,请选择 App Hub 宿主项目或管理项目。
点击指标元素上的 help_outline 帮助,然后选择直接过滤模式。
系统会删除指标和过滤条件元素,并创建一个过滤条件元素,以便您输入文本。
如果您在切换到直接过滤模式之前选择了资源类型、指标或过滤条件,则这些设置会显示在过滤条件元素中。
在过滤条件元素的文本区域中,输入 Monitoring 过滤表达式。如需了解语法信息,请参阅以下文档:
如果您使用直接过滤模式,但没有可满足过滤条件的数据,系统会显示错误。常见错误消息包括
Chart definition invalid和No data is available for the selected timeframe.可选:配置时序的分组和校准方式。如需了解详情,请参阅选择如何显示绘制成图表的数据。
如需返回菜单驱动的界面,请点击 tune 退出直接过滤模式。
选择如何显示已绘制成图表的数据
本部分介绍了如何通过设置聚合字段来显示所选数据。聚合包括校准时间序列中的数据点,以及将不同的时间序列组合在一起。如需详细了解聚合,请参阅过滤和聚合:处理时间序列。
- 如需了解视图选项,请参阅设置图表显示选项。
- 如需详细了解与图表本身的交互,请参阅研究已绘制成图表的数据。
如果您使用 PromQL 选择了要绘制成图表的数据,则本部分的内容不适用。
合并时间序列
您可以通过组合不同的时间序列来减少为指标返回的数据量。如需组合多个时序,您通常需要指定一个或多个标签和一个函数。系统会将所有指定标签的值都相同的时序分组,然后您指定的函数会将这些时序组合为一个新时序。
聚合元素中的设置可以更改图表显示的时序数量。此元素的默认设置由您选择的指标类型决定。如需修改显示内容,请执行以下任一操作:
如需显示每个时序,请确保在聚合元素中,将第一个菜单设置为未聚合,并将第二个菜单设置为无。
如需组合时序,请在聚合元素中执行以下操作:
展开第一个菜单,然后选择一个函数。
图表会刷新并显示单个时序。例如,如果您选择平均值,则显示的时序是所有时序的平均值。
函数菜单支持常见的代数函数,例如平均值、最小值、最大值和总和。计数时序选项用于统计与指标和过滤条件设置匹配的时序数量。百分位选项(例如,第 99 百分位)是派生自与指标和过滤条件设置匹配的时序的统计值。
如需组合具有相同标签值的时序,请展开第二个菜单,然后选择一个或多个标签。
图表会刷新,并针对每个唯一标签值组合显示一个时序。例如,如需显示每个可用区的时序,请将第二个菜单设置为可用区。
如需配置数据点之间的间隔,请点击 add 添加查询元素,选择最小时间间隔,然后输入值。
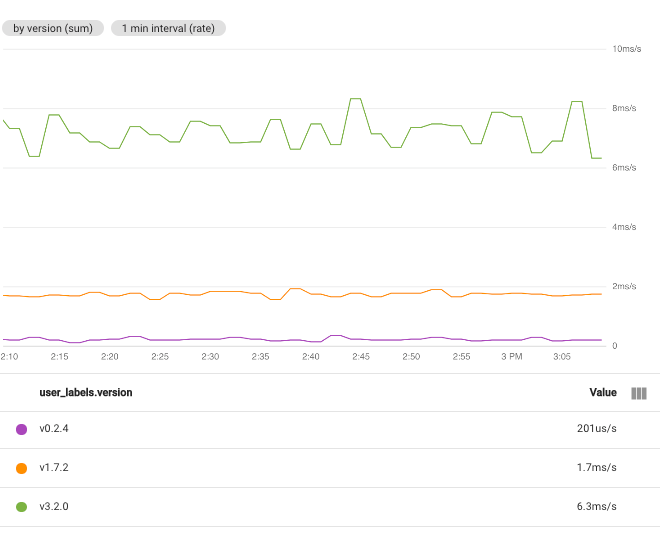
例如,如果您将函数设置为求和并选择标签 user_labels.version,则标签 user_labels.version 的每个值都有一个时序。每个时序中的数据点都是根据特定版本的各个时序的所有值之和计算得出的:
如果您选择多个标签,系统会组合所选标签的值相同的时序。生成的图表显示每个标签组合的一个时间序列。为标签指定的顺序并不重要。 以下屏幕截图显示了按 user_labels.version 和 system_labels.machine_image 标签组合时序的图表:
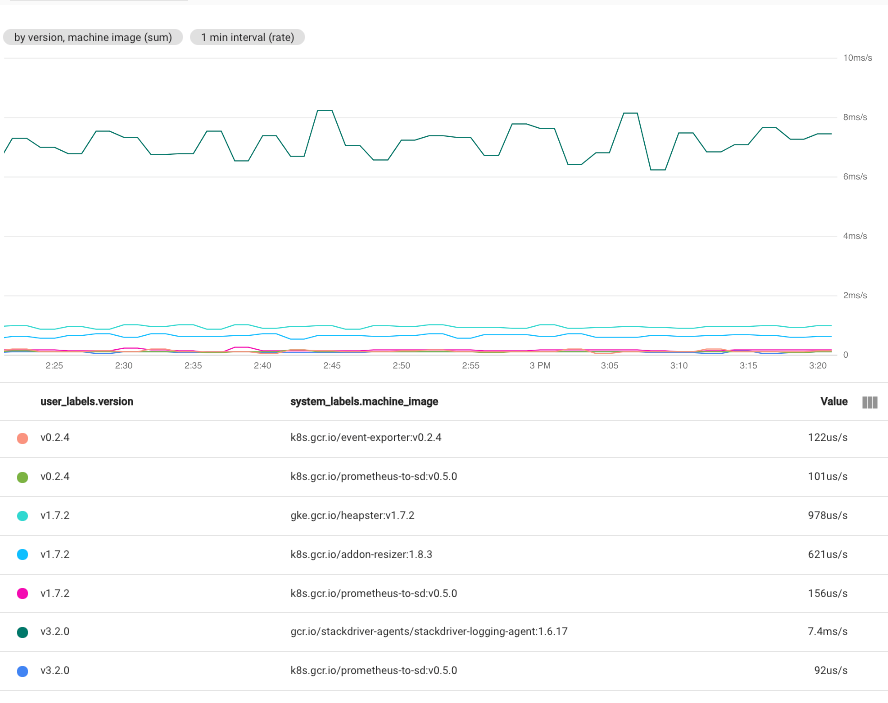
如图所示,图表会针对每对标签值显示一个时序。实际上,每个标签组合都有一个时序,意味着这种方法创建的数据可以超过有效放置在单个图表上的数据。
显示所有时序
如需显示所有时序,请在聚合元素中,将第一个菜单设置为未聚合,并将第二个菜单设置为无。
校准时间序列
校准是将 Monitoring 接收到的时间序列数据转换为在固定时间间隔内具有数据点的新时间序列的过程。校准过程包括收集在固定时间段内收到的所有数据点、应用函数以组合这些数据点,以及为结果分配时间戳。该函数可能会计算所有样本的平均值,或者提取所有样本的最大值。
设置校准时间间隔
如需指定要组合的数据点的固定时间长度,请点击查询窗格中的 add 添加查询元素,选择最小时间间隔,然后完成对话框。
例如,假设某个指标的采样周期为一分钟。如果图表配置为显示 1 小时的数据,则图表可以显示全部 60 个数据点。如果最小时间间隔字段设置为 10 minutes,则图表会显示 6 个数据点。但是,如果您现在将图表配置为显示一周的数据,则图表中要显示的数据点过多,因此系统会自动修改组合数据点的时间间隔。在此示例中,修改后的时间间隔为一小时。
以下屏幕截图展示了特定 Google Cloud 项目中 Compute Engine 虚拟机实例的 CPU 利用率。在此图中,最小时间间隔字段设置为 1 minute:
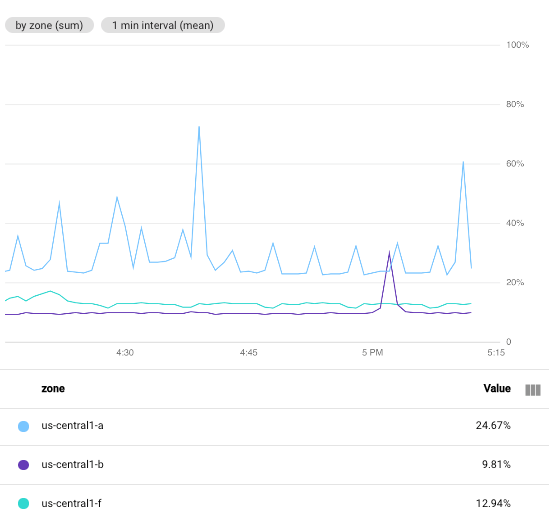
为便于比较,以下屏幕截图展示了将时间间隔从 1 minute 更改为 5 minutes 的效果:
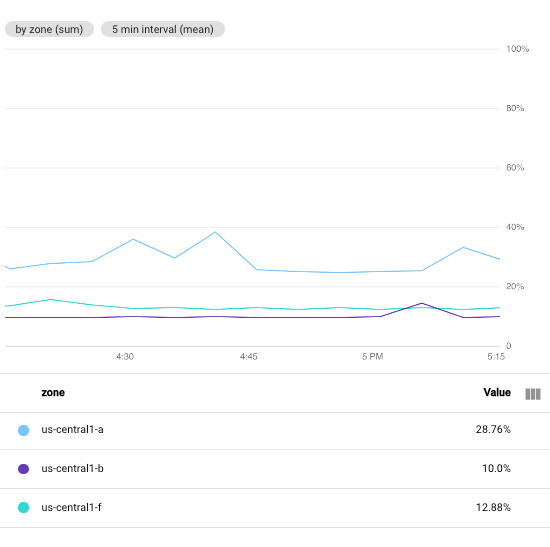
通过增加此时间段,生成的图表的点数会减少,每个时间序列的 60 点数将减少到每个时间序列 10 个点。增加最小时间间隔字段后,系统会组合更多数据点,这会使已绘制的数据效果更流畅。
设置校准函数
当您选择用于聚合的函数时,Cloud Monitoring 会为您选择校准函数。Cloud Monitoring 会根据您选择的指标类型和聚合函数选择确定最优校准函数。但是,您可以指定校准函数并替换 Cloud Monitoring 所做的选择。
如需指定校准函数,请执行以下操作:
- 在聚合元素中,展开第一个菜单,然后选择配置校准器。系统会添加校准函数和分组元素。
- 展开校准函数元素,然后进行选择。
虽然大多数受支持的校准函数会执行常见的数学函数,但有些函数会执行更复杂的操作:
下一个更早:如需仅保留校准时间段内的最新样本,请选择下一个更早。此函数通常用于拨测,如果您仅关注最新值,这是一个不错的选择。
此函数仅适用于实测指标。
百分位:要在折线图、堆叠面积图或堆叠条形图上显示分布指标,您必须选择要显示分布中的哪个百分位。指定此百分位的一种方法是选择一个百分位函数。您可以选择第 5、第 50、第 95 和第 99 百分位。使用校准时间段内的所有数据点来计算指定的百分位,从而确定校准数据点。
此函数仅适用于具有分布数据类型的实测指标和增量指标。
增量:如需将累计指标或增量指标转换为每个校准时间段一个样本的增量指标,请使用此函数。使用此函数时可能会发生数据插值。 如需查看示例,请参阅种类、类型和转换。
此函数仅适用于累计指标和增量指标。
速率:如需将累计指标或增量指标转换为实测指标,请使用此函数。如果选择此函数,您可以将时序视为通过增量函数进行转换,然后除以校准时间段。例如,如果原始时序的单位为 MiB 且校准时间段的单位为秒,则图表的单位为 MiB/秒。如需了解详情,请参阅种类、类型和转换。
此函数仅适用于累计指标和增量指标。
如需详细了解可用的校准函数,请参阅 API 参考文档中的 Aligner。
次要分组和对齐
如果您有多个已经表示聚合的时间序列,则可以通过选择二次聚合器将图表上的所有时间序列减少为单个时间序列。例如,如果按可用区对数据进行分组,则图表会针对每个可用区显示一个时间序列。如需创建包含单个时间序列的图表,请使用二次聚合字段。
对于某些指标类型,您可以选择转换数据。如果此选项可用,并且您将转换字段设置为除 None 以外的值,则所有其他字段都是二次聚合设置。
二次聚合字段可配置时,如需访问这些字段,请执行以下操作:
- 点击 add 添加查询元素,然后选择二次聚合。
- 配置二次聚合元素。
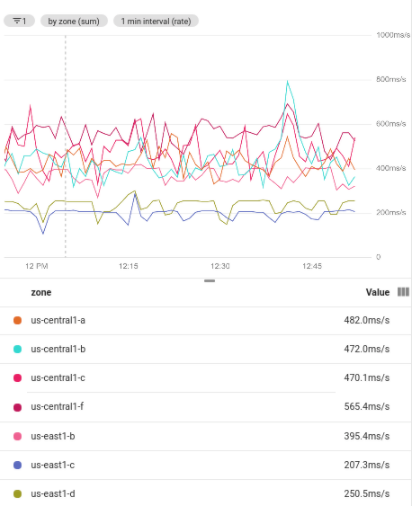
以下屏幕截图显示了对过滤的数据集进行分组所形成的几个时间序列。进行分组时需要执行聚合操作;同时,每组数据线都会聚合成一条数据线。以下屏幕截图显示了按地区分组的时间序列:
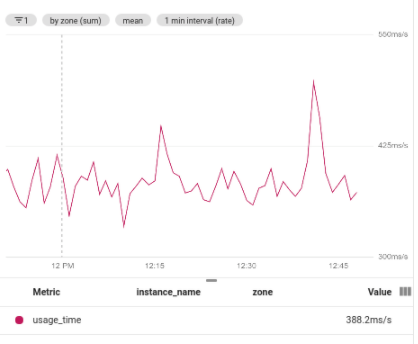
以下屏幕截图显示了使用二次聚合查找分组时间序列中的平均值的结果:
配置图例列的名称
通过图例别名字段,您可以为图表上的时序自定义说明。这些说明显示在图表的工具提示上以及 Name 列中的图表图例上。默认情况下,系统会根据时间序列中不同标签的值创建图例中的说明。由于这些标签由系统选择,生成的结果可能对您来说没有什么用处。如需构建说明的模板,请使用此字段。
您可以在图例别名字段中输入纯文本和模板。添加模板时,请添加一个会在图例显示时评估的表达式。
如需向图表添加图例模板,请执行以下操作:
- 在显示窗格中,展开 expand_more 图例别名。
- 点击 add 显示模板变量建议,然后从菜单中选择一个条目。例如,如果您选择
zone,则系统会添加模板${resource.labels.zone}。
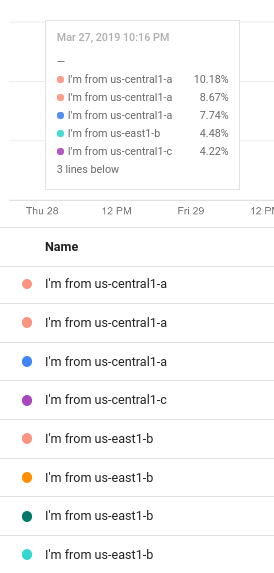
例如,以下屏幕截图显示了包含纯文本和表达式 ${resource.labels.zone} 的图例模板:

在图表图例中,通过模板生成的值显示在标题为名称的列中以及提示中:
您可以将图例模板配置为包含多个文本字符串和模板;但是,提示上的可用显示空间有限。