This document describes how to scale a managed instance group (MIG) based on the serving capacity of an external Application Load Balancer or an internal Application Load Balancer. This means that autoscaling adds or removes VM instances in the group when the load balancer indicates that the group has reached a configurable fraction of its fullness, where fullness is defined by the target capacity of the selected balancing mode of the backend instance group.
You can also scale a MIG based on its CPU utilization or on Monitoring metrics.
Limitations
You can autoscale a managed instance group based on the serving capacity of an external Application Load Balancer and an internal Application Load Balancer. Other types of load balancers are not supported.
Before you begin
- Review the autoscaler limitations.
- Read about autoscaler fundamentals.
-
If you haven't already, set up authentication.
Authentication verifies your identity for access to Google Cloud services and APIs. To run
code or samples from a local development environment, you can authenticate to
Compute Engine by selecting one of the following options:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Install the Google Cloud CLI. After installation, initialize the Google Cloud CLI by running the following command:
gcloud initIf you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
- Set a default region and zone.
REST
To use the REST API samples on this page in a local development environment, you use the credentials you provide to the gcloud CLI.
Install the Google Cloud CLI. After installation, initialize the Google Cloud CLI by running the following command:
gcloud initIf you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
For more information, see Authenticate for using REST in the Google Cloud authentication documentation.
-
Scaling based on HTTP(S) load balancing serving capacity
Compute Engine provides support for load balancing within your instance groups. You can use autoscaling in conjunction with load balancing by setting up an autoscaler that scales based on the load of your instances.
An external or internal HTTP(S) load balancer distributes requests
to backend services according to its URL map. The load balancer can have one or
more backend services, each supporting
instance group or network endpoint group (NEG) backends. When
backends are instance groups, the HTTP(S) load balancer offers two
balancing modes:
UTILIZATION and RATE. With UTILIZATION, you can specify a maximum target
for average backend utilization of instances in the instance group. With RATE,
you must specify a target number of requests per second on a per-instance basis
or a per-group basis. (Only zonal instance groups support specifying a maximum
rate for the whole group. Regional managed instance groups do not support
defining a maximum rate per group.)
The balancing mode and the target capacity that you specify define the conditions under which Google Cloud determines when a backend VM is at full capacity. Google Cloud attempts to send traffic to healthy VMs that have remaining capacity. If all VMs are already at capacity, the target utilization or rate is exceeded.
When you attach an autoscaler to an instance group backend of an HTTP(S) load balancer, the autoscaler scales the managed instance group to maintain a fraction of the load balancing serving capacity.
For example, assume the load balancing serving capacity of a managed instance group is defined as 100 RPS per instance. If you create an autoscaler with the HTTP(S) load balancing policy and set it to maintain a target utilization level of 0.8 or 80%, the autoscaler adds or removes instances from the managed instance group to maintain 80% of the serving capacity, or 80 RPS per instance.
The following diagram shows how the autoscaler interacts with a managed instance group and backend service:
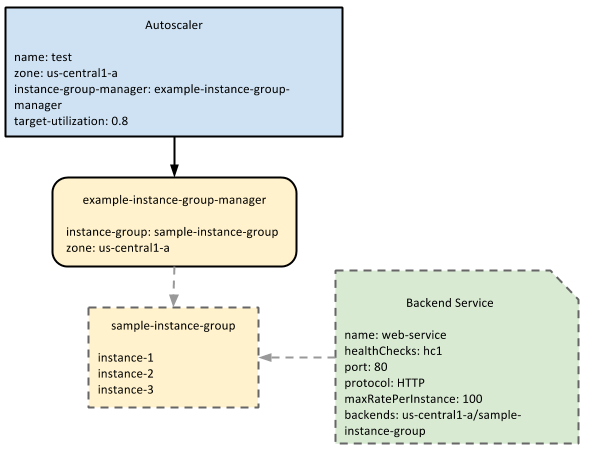
maxRatePerInstance value.
Applicable load balancing configurations
You can set one of three options for your load balancing serving capacity. When you first create the backend, you can choose among maximum backend utilization, maximum requests per second per instance, or maximum requests per second of the whole group. Autoscaling only works with maximum backend utilization and maximum requests per second/instance because the value of these settings can be controlled by adding or removing instances. For example, if you set a backend to handle 10 requests per second per instance, and the autoscaler is configured to maintain 80% of that rate, then the autoscaler can add or remove instances when the requests per second per instance changes.
Autoscaling does not work with maximum requests per group because this setting is independent of the number of instances in the instance group. The load balancer continuously sends the maximum number of requests per group to the instance group, regardless of how many instances are in the group.
For example, if you set the backend to handle 100 maximum requests per group per second, the load balancer sends 100 requests per second to the group, whether the group has two instances or 100 instances. Because this value cannot be adjusted, autoscaling does not work with a load balancing configuration that uses the maximum number of requests per second per group.
Enable autoscaling based on load balancing serving capacity
Console
- Go to the Instance groups page in the Google Cloud console.
- If you have an instance group, select it, and then click Edit. If you don't have an instance group, click Create instance group.
- Click Group size & autoscaling to expand the section.
- In the Autoscaling mode list, make sure that On: add and remove instances to the group is selected.
- Specify the minimum and maximum numbers of instances that you want the autoscaler to create in this group.
- In the Autoscaling signals section, click Add a signal.
- Set the Signal type to HTTP load balancing utilization.
Enter the Target HTTP load balancing utilization value in percentage. For example, for 60% HTTP load balancing utilization, enter
60.You can use the Initialization period field to set the initialization period, which tells the autoscaler how long it takes for your application to initialize. Specifying an accurate initialization period improves autoscaler decisions. For example, when scaling out, the autoscaler ignores data from VMs that are still initializing because those VMs might not yet represent normal usage of your application. The default initialization period is 60 seconds.
Save your changes.
gcloud
To enable an autoscaler that scales on serving capacity, use the
set-autoscaling
sub-command. For example, the following command creates an autoscaler that
scales the target managed instance group to maintain 60% of the serving
capacity. Along with the --target-load-balancing-utilization parameter,
the --max-num-replicas parameter is also required when creating an
autoscaler:
gcloud compute instance-groups managed set-autoscaling example-managed-instance-group \
--max-num-replicas 20 \
--target-load-balancing-utilization 0.6 \
--cool-down-period 90
You can use the --cool-down-period flag to set the initialization period, which tells the
autoscaler how long it takes for your application to initialize. Specifying an accurate
initialization period improves autoscaler decisions. For example, when scaling out, the
autoscaler ignores data from VMs that are still initializing because those VMs
might not yet represent normal usage of your application. The default initialization
period is 60 seconds.
You can verify that your autoscaler was successfully created by using the
instance-groups managed describe sub-command:
gcloud compute instance-groups managed describe example-managed-instance-group
For a list of available gcloud commands and flags, see the
gcloud reference.
REST
To create an autoscaler, use the
autoscalers.insert method
for a zonal MIG or the
regionAutoscalers.insert method
for a regional MIG.
The following example creates an autoscaler for a zonal MIG:
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/autoscalers/
Your request body must contain the name, target, and autoscalingPolicy
fields. autoscalingPolicy must define loadBalancingUtilization.
You can use the coolDownPeriodSec field to set the initialization period, which tells the
autoscaler how long it takes for your application to initialize. Specifying an accurate
initialization period improves autoscaler decisions. For example, when scaling out, the
autoscaler ignores data from VMs that are still initializing because those VMs
might not yet represent normal usage of your application. The default initialization
period is 60 seconds.
{
"name": "example-autoscaler",
"target": "zones/us-central1-f/instanceGroupManagers/example-managed-instance-group",
"autoscalingPolicy": {
"maxNumReplicas": 20,
"loadBalancingUtilization": {
"utilizationTarget": 0.8
},
"coolDownPeriodSec": 90
}
}
For more information about enabling autoscaling based on load balancing serving capacity, complete the tutorial, Globally autoscaling a web service on Compute Engine.
What's next
- Learn about managing autoscalers.
- Learn how autoscalers make decisions.
- Learn how to use multiple autoscaling signals to scale your group.