BigQuery Storage Write API の概要
BigQuery Storage Write API は BigQuery のための統合データ取り込み API で、ストリーミング取り込みとバッチ読み込みの機能を 1 つの高性能 API にまとめたものです。Storage Write API を使用すると、レコードを BigQuery にリアルタイムでストリーミングできます。また、任意の数のレコードをバッチ処理して、単一のアトミック操作で commit することもできます。
Storage Write API を使用するメリット
1 回限りの配信セマンティクス。Storage Write API は、ストリーム オフセットを使用して、1 回限りのセマンティクスをサポートします。tabledata.insertAll メソッドとは異なり、Storage Write API は、レコードの追加時にクライアントがストリーム オフセットを提供しても、ストリーム内に同じオフセットを持つ 2 つのメッセージを書き込むことはありません。
ストリームレベルのトランザクション。ストリームへのデータの書き込みとデータの commit を 1 つのトランザクションで実行できます。commit オペレーションが失敗した場合、オペレーションを安全に再試行できます。
ストリーム間でのトランザクション。複数のワーカーが独自のストリームを作成し、個別にデータを処理できます。すべてのワーカーが完了したら、すべてのストリームをトランザクションとして commit できます。
効率的なプロトコル。Storage Write API は、HTTP over REST ではなく gRPC ストリーミングを使用します。このため、以前の insertAll メソッドよりも効率的です。Storage Write API は、プロトコル バッファのバイナリ形式と Apache Arrow カラム形式もサポートしています。これは JSON よりも効率的な転送方式です。書き込みリクエストは非同期ですが、順序指定が保証されます。
スキーマ更新の検出。クライアントのストリーミング中に基になるテーブル スキーマが変更された場合、Storage Write API はクライアントに通知します。クライアントは、更新されたスキーマを使用して再接続するか、引き続き既存の接続に書き込むかを決定できます。
低コスト。Storage Write API は、古い insertAll ストリーミング API よりも大幅に低コストです。さらに、1 か月あたり最大 2 TiB を無料で取り込むことができます。
必要な権限
Storage Write API を使用するには、bigquery.tables.updateData 権限が必要です。
bigquery.tables.updateData 権限は、以下の Identity and Access Management(IAM)事前定義ロールに含まれています。
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
BigQuery での IAM のロールと権限について詳しくは、事前定義ロールと権限をご覧ください。
認証スコープ
Storage Write API を使用するには、次のいずれかの OAuth スコープが必要です。
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
詳細については、認証の概要をご覧ください。
Storage Write API の概要
Storage Write API の中心的な抽象概念は、ストリームです。ストリームによって、BigQuery テーブルにデータが書き込まれます。複数のストリームで同じテーブルに同時に書き込むことができます。
デフォルト ストリーム
Storage Write API は、継続的にデータを受信するストリーミング シナリオ用に設計されたデフォルト ストリームを備えています。これには次のような特徴があります。
- デフォルト ストリームに書き込まれたデータは、すぐにクエリで使用できます。
- デフォルト ストリームは、at-least-once(少なくとも 1 回)セマンティクスをサポートしています。
- デフォルト ストリームを明示的に作成する必要はありません。
以前の tabledata.insertall API から移行する場合は、デフォルトのストリームの使用を検討してください。類似の書き込みセマンティクスがあり、データの復元性に優れ、スケーリングの制限が低くなります。
API フロー:
AppendRows(ループ)
詳細とサンプルコードについては、at-least-once(少なくとも 1 回)セマンティクスにデフォルト ストリームを使用するをご覧ください。
アプリケーションで作成したストリーム
次のいずれかの動作が必要な場合は、ストリームを明示的に作成できます。
- ストリーム オフセットを使用した 1 回限りの書き込みセマンティクス。
- 追加の ACID プロパティのサポート。
一般に、アプリケーションによって作成されたストリームでは、より機能を制御できますが、複雑になります。
ストリームを作成するときには、タイプを指定します。このタイプは、ストリームに書き込まれたデータが読み取りのために BigQuery に表示されるタイミングを制御します。
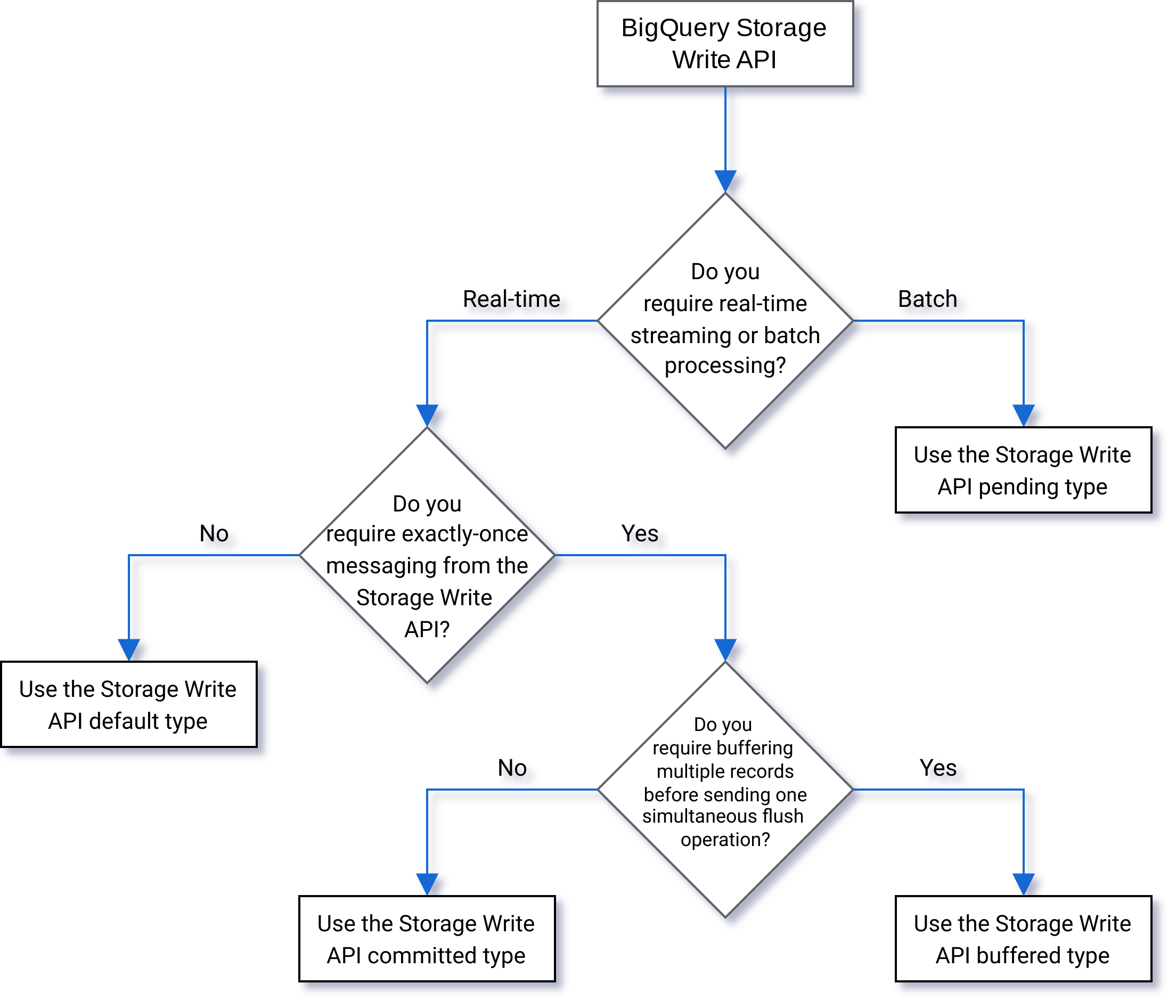
保留タイプ
保留タイプでは、ストリームを commit するまでレコードは保留状態になります。ストリームを commit すると、保留中のすべてのデータが読み取り可能になりますcommit はアトミック オペレーションです。このタイプは、BigQuery の読み込みジョブの代わりにバッチ ワークロードで使用します。詳細については、Storage Write API を使用したデータ読み込みのバッチ処理をご覧ください。
API フロー:
コミットタイプ
コミットタイプでは、ストリームにレコードを書き込むと、すぐにレコードを読み取ることができます。このタイプは、読み取りレイテンシを最小限に抑える必要があるストリーミング ワークロードに使用します。デフォルト ストリームは、コミットタイプの at-least-once(少なくとも 1 回)形式を使用します。詳細については、1 回限りのセマンティクスにコミットタイプを使用するをご覧ください。
API フロー:
CreateWriteStreamAppendRows(ループ)FinalizeWriteStream(省略可)
バッファタイプ
バッファタイプは高度なタイプであり、Apache Beam BigQuery I/O コネクタを除いて、通常は使用すべきではありません。まとめて表示されることを保証する必要がある小さなバッチがある場合は、コミットタイプを使用して各バッチを 1 回のリクエストで送信します。このタイプでは、行レベルで commit が行われ、ストリームをフラッシュして行が commit されるまで、レコードがバッファされます。
API フロー:
CreateWriteStreamAppendRows⇒FlushRows(ループ)FinalizeWriteStream(省略可)
タイプの選択
次のフローチャートを使用して、ワークロードに最適なタイプを決定します。
API の詳細
Storage Write API を使用する場合は、次の点を考慮してください。
AppendRows
AppendRows メソッドは、1 つ以上のレコードをストリームに追加します。AppendRows の最初の呼び出しには、DescriptorProto として指定されたストリーム名とともにデータスキーマを含める必要があります。また、Apache Arrow 形式でデータを取り込む場合は、AppendRows の最初の呼び出しでシリアル化された Arrow スキーマを追加することもできます。各 AppendRows 呼び出しで行のバッチを送信することをおすすめします。一度に 1 行ずつ送信しないでください。
プロトコル バッファ処理
プロトコル バッファは、言語やプラットフォームに依存しない、拡張可能なメカニズムを提供します。これにより、前方互換性および下位互換性のある方法で構造化データがシリアル化されます。また、コンパクトなデータ ストレージを高速かつ効率的に解析できるという利点があります。プロトコル バッファの詳細については、プロトコル バッファの概要をご覧ください。
事前定義されたプロトコル バッファ メッセージを使用して API を直接使用する場合、プロトコル バッファ メッセージでは package 指定子を使用できず、ネストされた型または列挙型はすべて最上位のルート メッセージ内で定義する必要があります。外部メッセージへの参照は使用できません。例については、sample_data.proto をご覧ください。
Java クライアントと Go クライアントは任意のプロトコル バッファをサポートします。これは、クライアント ライブラリがプロトコル バッファ スキーマを正規化するためです。
Apache Arrow の処理
この機能に関するフィードバックやサポートのリクエストを行う場合は、bq-write-api-feedback@google.com 宛てにメールをお送りください。Apache Arrow は、データ処理用のユニバーサルな列形式と多言語ツールボックスです。Apache Arrow は、フラットなデータと階層データを対象に、言語に依存しないカラム型メモリ形式を提供します。この形式は、最新のハードウェアで効率的な分析オペレーションを実行できるように構成されています。Apache Arrow の詳細については、Apache Arrow をご覧ください。Storage Write API は、シリアル化された矢印スキーマと AppendRowsRequest クラスのデータを使用して、矢印の取り込みをサポートしています。Python クライアント ライブラリには、Apache Arrow の取り込みのサポートが組み込まれています。他の言語では、未加工の AppendRows API を呼び出して、Apache Arrow 形式でデータを取り込む必要がある場合があります。
FinalizeWriteStream
FinalizeWriteStream メソッドはストリームをファイナライズして、新しいデータを追加できないようにします。このメソッドは、Pending タイプでは必須です。また、Committed タイプと Buffered タイプでは省略可能です。デフォルト ストリームはこのメソッドをサポートしていません。
エラー処理
エラーが発生した場合に返される google.rpc.Status のエラーの詳細に、StorageError が含まれることがあります。StorageErrorCode で特定のエラータイプを確認します。Google API エラーモデルの詳細については、エラーをご覧ください。
接続
Storage Write API は、双方向接続を使用する gRPC API です。AppendRows メソッドはストリームへの双方向接続を作成します。デフォルト ストリームでは複数の接続を開くことができます。これらの追加は非同期であるため、一連の書き込みを同時に送信できます。各双方向接続のレスポンス メッセージは、リクエストの送信順序のとおりに到着します。
アプリケーションによって作成されたストリームに設定できるアクティブな接続は 1 つだけです。アクティブな接続の数を制限し、可能な限り多くのデータ書き込みに 1 つの接続を使用することをおすすめします。Java または Go でデフォルト ストリームを使用する場合は、Storage Write API 多重化を使用して、共有接続で複数の宛先テーブルに書き込むことができます。
通常、1 つの接続で少なくとも 1 MB/秒のスループットがサポートされます。上限は、ネットワーク帯域幅、データのスキーマ、サーバーの負荷などの要因によって異なります。接続がスループットの上限に達すると、処理中のリクエストの数が減少するまで、受信リクエストが拒否されるかキューに入れられることがあります。さらに多くのスループットが必要な場合は、追加の接続を作成します。
接続が長時間アイドル状態になると、BigQuery は gRPC 接続を終了します。この場合、レスポンス コードは HTTP 409 です。サーバーの再起動やその他の理由で gRPC 接続が終了することもあります。接続エラーが発生した場合は、新しい接続を作成します。接続が終了すると、Java と Go のクライアント ライブラリは自動的に再接続します。
クライアント ライブラリのサポート
Storage Write API のクライアント ライブラリは複数のプログラミング言語で存在し、基盤となる gRPC ベースの API 構造体を公開します。この API は、双方向ストリーミングなどの高度な機能を活用します。この機能をサポートするには、追加の開発作業が必要になる場合があります。そのため、この API には、これらのインタラクションを簡素化し、デベロッパーの懸念を軽減する上位レベルの抽象化がいくつか用意されています。可能であれば、これらの他のライブラリ抽象化を利用することをおすすめします。
このセクションでは、生成された API を超える追加機能がデベロッパーに提供されている言語とライブラリについて詳しく説明します。
Storage Write API に関連するコードサンプルについては、すべての BigQuery コードサンプルをご覧ください。
Java クライアント
Java クライアント ライブラリは、次の 2 つのライター オブジェクトを提供します。
StreamWriter: プロトコル バッファ形式のデータを受け入れます。JsonStreamWriter: JSON 形式のデータを受け入れ、プロトコル バッファに変換してからネットワーク経由で送信します。JsonStreamWriterはスキーマの自動更新もサポートしています。テーブル スキーマが変更されると、ライターは新しいスキーマに自動的に再接続します。これにより、クライアントは新しいスキーマを使用してデータを送信できるようになります。
両方のライターでプログラミング モデルは類似しています。主な違いはペイロードをフォーマットする方法です。
ライター オブジェクトは、Storage Write API 接続を管理します。ライター オブジェクトは自動的にリクエストをクリーンアップし、リージョン ルーティング ヘッダーをリクエストに追加し、接続エラーの後に再接続します。gRPC API を直接使用する場合は、これらの詳細を処理する必要があります。
Go クライアント
Go クライアントはクライアント サーバー アーキテクチャを活用し、proto2 を使用してプロトコル バッファ形式のメッセージをエンコードします。Go クライアントの使用方法とサンプルコードについて詳しくは、Go のドキュメントをご覧ください。
Python クライアント
Python クライアントは、gRPC API をラップする下位レベルのクライアントです。このクライアントを使用するには、指定したタイプの API フローに沿って、データをプロトコル バッファとして送信する必要があります。
Python で動的プロト メッセージ生成を使用しないでください。このライブラリのパフォーマンスは標準以下です。
Python でプロトコル バッファを使用する方法については、Python チュートリアルのプロトコル バッファの基本をご覧ください。
Storage Write API を使用してデータを取り込むプロトコルとして、Apache Arrow 取り込み形式を使用することもできます。詳細については、Apache Arrow 形式を使用してデータを取り込むをご覧ください。
NodeJS クライアント
NodeJS クライアント ライブラリは JSON 入力を受け取り、自動再接続をサポートします。このクライアントの使用方法について詳しくは、ドキュメントをご覧ください。
利用不能な状況への対処
指数バックオフで再試行すると、ランダムなエラーや短時間のサービスが利用不能な状況を軽減できますが、このような利用不能な状況が長引く場合に行が削除されないようにするために、慎重に検討する必要があります。特に、クライアントが行をずっと挿入できない場合は、どのように対処すればよいでしょうか。
その答えは、要件によって異なります。たとえば、BigQuery がオペレーション分析に使用されており、ある程度の行の欠落が許容されている場合、クライアントは数回の再試行後にあきらめてデータを破棄できます。一方、財務データなど、すべての行がビジネスにとって不可欠な場合は、後で挿入できるようにデータを保持する戦略が必要になります。
永続的なエラーに対処する一般的な方法の 1 つは、後で評価して挿入できるように、Pub/Sub トピックに行をパブリッシュすることです。もう 1 つの一般的な方法は、クライアント上でデータを一時的に保持することです。どちらの方法でも、クライアントが阻害されていない状態を維持しつつ、サービスが再び利用可能になった後ですべての行を挿入できます。
パーティション分割テーブルへのストリーミング
Storage Write API は、パーティション分割テーブルへのデータのストリーミングをサポートしています。
データがストリーミングされると、最初に __UNPARTITIONED__ パーティションに配置されます。十分な量のパーティショニングされていないデータが収集されると、BigQuery はデータを再パーティショニングし、適切なパーティションに配置します。しかし、対象のデータが __UNPARTITIONED__ パーティションから移動するまでに要する時間を定義するサービスレベル契約(SLA)は存在しません。
取り込み時間パーティション分割テーブルと時間単位列パーティション分割テーブルの場合、いずれかの疑似列(優先するデータ型に応じて _PARTITIONTIME または _PARTITIONDATE)を使用して __UNPARTITIONED__ パーティションから NULL 値を除外することで、パーティション分割されていないデータをクエリから除外できます。
取り込み時間パーティショニング
取り込み時間パーティション分割テーブルにストリーミングすると、Storage Write API は現在のシステムの UTC 時間から宛先パーティションを推測します。
日次パーティション分割テーブルにデータをストリーミングする場合は、リクエストの一部としてパーティション デコレータを指定することで、日付の推定をオーバーライドできます。tableID パラメータにデコレータを含めます。たとえば、次のように table1$20250601 パーティション デコレータを使用して、table1 テーブルの 2025-06-01 に対応するパーティションにストリーミングできます。
パーティション デコレータを使用してストリーミングする場合、過去 31 日間から将来の 16 日間のパーティションにストリーミングできます。この範囲に含まれない日付のパーティションに書き込むには、特定のパーティションにデータを書き込むで説明するように、読み込みジョブまたはクエリジョブを使用します。
パーティション デコレータを使用したストリーミングは、デフォルトのストリームを使用する日単位のパーティション分割テーブルでのみサポートされています。時間単位、月単位、年単位のパーティション分割テーブルや、アプリケーションで作成されたストリームではサポートされていません。
時間単位列パーティショニング
時間単位列パーティション分割テーブルにストリーミングすると、BigQuery はテーブルの事前定義された DATE、DATETIME、または TIMESTAMP パーティショニング列の値に基づいて、データを自動的に正しいパーティションに配置します。パーティショニング列で参照されるデータが過去 10 年間、向こう 1 年間の範囲内にある場合、時間単位列で分割されたテーブルにデータをストリーミングできます。
整数範囲パーティショニング
整数範囲でパーティション分割されたテーブルにストリーミングすると、BigQuery はテーブルの事前定義された INTEGER パーティショニング列の値に基づいて、データを自動的に正しいパーティションに配置します。
Fluent Bit Storage Write API 出力プラグイン
Fluent Bit Storage Write API 出力プラグインを使用すると、JSON レコードを BigQuery に取り込むプロセスが自動化されるため、コードを記述する必要がなくなります。このプラグインを使用すると、互換性のある入力プラグインを構成し、構成ファイルを設定するだけで、データのストリーミングを開始できます。Fluent Bit は、オープンソースのクロスプラットフォーム ログプロセッサとフォワーダーです。入力プラグインと出力プラグインを使用して、さまざまな種類のデータソースとシンクを処理します。
このプラグインは以下の対象をサポートしています。
- デフォルト タイプを使用する at-least-once セマンティクス。
- コミットタイプを使用する exactly-once セマンティクス。
- デフォルト ストリームの動的スケーリング(バックプレッシャーが示されている場合)。
Storage Write API プロジェクトの指標
Storage Write API を使用してデータの取り込みをモニタリングする指標については、INFORMATION_SCHEMA.WRITE_API_TIMELINE ビューを使用するか、Google Cloud 指標をご覧ください。
最近ストリーミングされたデータに対してデータ操作言語(DML)を使用する
UPDATE ステートメント、DELETE ステートメント、MERGE ステートメントなどのデータ操作言語(DML)を使用すると、BigQuery Storage Write API によって BigQuery テーブルに最近書き込まれた行を変更できます。最近の書き込みとは、30 分以内に行われたものを指します。
DML を使用してストリーミング データを変更する方法の詳細については、データ操作言語の使用をご覧ください。
制限事項
- 最近ストリーミングされたデータに対して DML ステートメントの変更を実行することに関するサポートは、insertAll ストリーミング API を使用してストリーミングされたデータには拡張されません。
- 最近ストリーミングされたデータに対して、マルチステートメント トランザクション内で DML ステートメントの変更を実行することはサポートされていません。
Storage Write API の割り当て
Storage Write API の割り当てと上限については、BigQuery Storage Write API の割り当てと上限をご覧ください。
同時接続とスループットの割り当て使用量は、Google Cloud コンソールの [割り当て] ページでモニタリングできます。
スループットを計算する
1 億件のエンドポイントからログを収集して、1 分あたり 1,500 件のログレコードを作成するとします。この場合、スループットを 100 million * 1,500 / 60 seconds = 2.5 GB per second として見積もることができます。このスループットを処理できるだけの十分な割り当てがあることを事前に確認しておく必要があります。
Storage Write API の料金
料金については、データ取り込みの料金をご覧ください。
使用例
エンドポイント ログのイベントデータを処理するパイプラインがあるとします。イベントは継続的に生成され、できるだけ早く BigQuery でのクエリで使用できるようにする必要があります。このユースケースではデータの更新頻度が最重要であるため、BigQuery にデータを取り込むには Storage Write API が最適です。エンドポイントを無駄のないものにするための推奨アーキテクチャは、BigQuery に直接ストリーミングする Dataflow ストリーミング パイプラインで消費されるイベントから Pub/Sub にイベントを送信することです。
このアーキテクチャの信頼性に関する主な懸念事項は、BigQuery にレコードを挿入できない場合の対処方法です。各レコードが重要であり、失われることができない場合は、挿入する前にデータをバッファする必要があります。上記の推奨アーキテクチャでは、Pub/Sub がメッセージ保持機能を備えたバッファの役割を果たすことができます。Dataflow パイプラインは、切り捨て型指数バックオフを使用して BigQuery ストリーミング挿入を再試行するように構成する必要があります。バッファとしての Pub/Sub の容量を使い切ると(BigQuery が長期間使用できない場合やネットワーク障害が発生した場合など)、データをクライアントで維持する必要があり、クライアントでは可用性の復元後に永続レコードの挿入を再開するためのメカニズムが必要です。この状況に対処する方法の詳細については、Google Pub/Sub 信頼性ガイドのブログ投稿をご覧ください。
もう 1 つの処理の失敗ケースとして、ポイズン レコードがあります。ポイズン レコードは、再試行不可能なエラーでレコードの挿入に失敗したために BigQuery によって拒否されたレコードか、最大再試行回数後に正常に挿入されなかったレコードです。両方のタイプのレコードを、さらに調査するために Dataflow パイプラインによって「デッドレター キュー」に保存する必要があります。
exactly-once セマンティクスが必要な場合は、クライアントによって提供されるレコード オフセットを使用して、コミット型で書き込みストリームを作成します。これによって重複が回避され、オフセット値が次に追加されたオフセットに一致する場合にのみ、書き込みオペレーションが実行されます。オフセットを指定しないと、レコードがストリームの現在の末尾に追加され、失敗した追加を再試行すると、レコードがストリーム内に複数回表示される可能性があります。
exactly-once 保証が不要な場合は、デフォルト ストリームへの書き込みによりスループットが向上し、書き込みストリームの作成の割り当て上限にもカウントされません。
ネットワークのスループットを見積もり、スループットを提供するための十分な割り当てがあることを前もって確認します。
ワークロードによって非常に不均一にデータが生成または処理されている場合、クライアントでの負荷の急増を抑制し、一定のスループットで BigQuery にストリーミングしてみてください。これにより、キャパシティ プランニングを簡素化できます。それができない場合は、短時間の急増中にスループットが割り当てを超過した場合に 429(リソース不足)エラーを処理できるように準備してください。
Storage Write API の使用方法の詳細な例については、Storage Write API を使用したデータのストリーミングをご覧ください。
次のステップ
- Storage Write API を使用したデータのストリーミング
- Storage Write API を使用したデータ読み込みのバッチ処理
- サポートされているプロトコル バッファと Arrow データタイプ
- Storage Write API のベスト プラクティス