Ce tutoriel explique comment explorer et visualiser des données à l'aide de la bibliothèque cliente BigQuery pour Python et de Pandas dans une instance de notebook Jupyter géré sur Vertex AI Workbench. Les outils de visualisation de données peuvent vous aider à analyser vos données BigQuery de manière interactive, à les identifier et à communiquer des insights à partir de celles-ci. Ce tutoriel utilise les données de l'ensemble de données public Google Trends de BigQuery.
Objectifs
- Créer une instance de notebook Jupyter géré à l'aide de Vertex AI Workbench.
- Interroger les données BigQuery à l'aide des commandes magiques intégrées aux notebooks.
- Interroger et visualiser des données BigQuery à l'aide de la bibliothèque cliente BigQuery Python et de Pandas.
Coûts
BigQuery est un produit payant. Des coûts d'utilisation vous sont donc facturés lorsque vous y accédez. Le premier To de données de requêtes traitées chaque mois est gratuit. Pour en savoir plus, consultez la page des tarifs de BigQuery.
Vertex AI Workbench est un produit payant, dont les coûts de calcul, de stockage et de gestion entraînent des frais d'utilisation. Pour en savoir plus, consultez la page des tarifs de Vertex AI Workbench.
Avant de commencer
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
BigQuery est automatiquement activé dans les nouveaux projets.
Activez l'API Notebooks.
Présentation des notebooks Jupyter
Un notebook fournit un environnement dans lequel créer et exécuter du code. Il s'agit essentiellement d'un artefact source, enregistré sous forme de fichier IPYNB. Il peut inclure un contenu textuel descriptif, des blocs de code exécutables et des résultats au format HTML interactif.
D'un point de vue structurel, un notebook correspond à une série de cellules. Une cellule est un bloc de texte d'entrée qui est évalué pour produire des résultats. Les cellules peuvent être de trois types :
- Des cellules de code contenant le code à évaluer. La sortie ou les résultats du code exécuté sont affichés en ligne avec le code exécuté.
- Des cellules Markdown contenant du texte de balisage Markdown qui est converti au format HTML pour produire des en-têtes, des listes et du texte formaté.
- Des cellules brutes peuvent être utilisées pour afficher différents formats de code au format HTML ou LaTeX.
L'image suivante montre une cellule Markdown suivie d'une cellule de code Python, puis de la sortie :
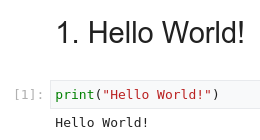
Chaque notebook ouvert est associé à une session en cours d'exécution (également appelée kernel en Python). Cette session exécute tout le code du notebook et gère l'état. L'état inclut les variables avec leurs valeurs, leurs fonctions et leurs classes, ainsi que tous les modules Python existants que vous chargez.
Dans Google Cloud, vous pouvez interroger et explorer des données, développer et entraîner un modèle à l'aide d'un environnement basé sur un notebook Vertex AI Workbench, puis exécuter votre code dans le cadre d'un pipeline. Dans ce tutoriel, vous allez créer une instance de notebook géré sur Vertex AI Workbench, puis explorer les données BigQuery dans l'interface JupyterLab.
Créer une instance de notebooks gérés
Dans cette section, vous allez configurer une instance JupyterLab sur Google Cloud afin de pouvoir créer des notebooks gérés.
Dans la console Google Cloud, accédez à la page Workbench.
Cliquez sur Nouveau notebook.
Dans le champ Nom du notebook, saisissez un nom pour votre instance.
Dans la liste Région, sélectionnez une région pour votre instance.
Dans la section Autorisation, sélectionnez une option permettant de définir les utilisateurs autorisés à accéder à l'instance de notebooks gérés :
- Compte de service : cette option permet d'accorder l'accès à tous les utilisateurs ayant accès au compte de service Compute Engine que vous associez à l'environnement d'exécution. Pour spécifier votre propre compte de service, décochez la case Utiliser le compte de service Compute Engine par défaut, puis saisissez l'adresse e-mail du compte de service que vous souhaitez utiliser. Pour en savoir plus sur les comptes de service, consultez la page Types de comptes de service.
- Un seul utilisateur : cette option n'autorise l'accès qu'à un utilisateur spécifique. Dans le champ Adresse e-mail de l'utilisateur, saisissez l'adresse e-mail du compte utilisateur de l'utilisateur qui utilisera l'instance de notebooks gérés.
Facultatif : Pour modifier les paramètres avancés de votre instance, cliquez sur Paramètres avancés. Pour en savoir plus, consultez la page Créer une instance à l'aide des paramètres avancés.
Cliquez sur Créer.
Patientez quelques minutes le temps que l'instance soit créée. Vertex AI Workbench démarre automatiquement l'instance. Lorsque l'instance est prête à l'emploi, Vertex AI Workbench active un lien Ouvrir JupyterLab.
Parcourir les ressources BigQuery dans JupyterLab
Dans cette section, vous allez ouvrir JupyterLab et explorer les ressources BigQuery disponibles dans une instance de notebook géré.
Sur la ligne de l'instance de notebook géré que vous avez créée, cliquez sur Ouvrir JupyterLab.
Si vous y êtes invité, cliquez sur S'authentifier si vous acceptez les conditions. Votre instance de notebooks gérés ouvre JupyterLab dans un nouvel onglet du navigateur.
Dans le menu de navigation de JupyterLab, cliquez sur
 BigQuery dans Notebooks.
BigQuery dans Notebooks.Le volet BigQuery répertorie les projets et les ensembles de données disponibles, dans lesquels vous pouvez effectuer des tâches comme suit :
- Pour afficher la description d'un ensemble de données, double-cliquez sur son nom.
- Pour afficher les tables, les vues et les modèles d'un ensemble de données, développez celui-ci.
- Pour ouvrir une description récapitulative en tant qu'onglet dans JupyterLab, double-cliquez sur une table, une vue ou un modèle.
Remarque : Dans la description récapitulative d'une table, cliquez sur l'onglet Aperçu pour prévisualiser les données d'une table. L'image suivante montre un aperçu de la table
international_top_termsdisponible dans l'ensemble de donnéesgoogle_trendsdu projetbigquery-public-data: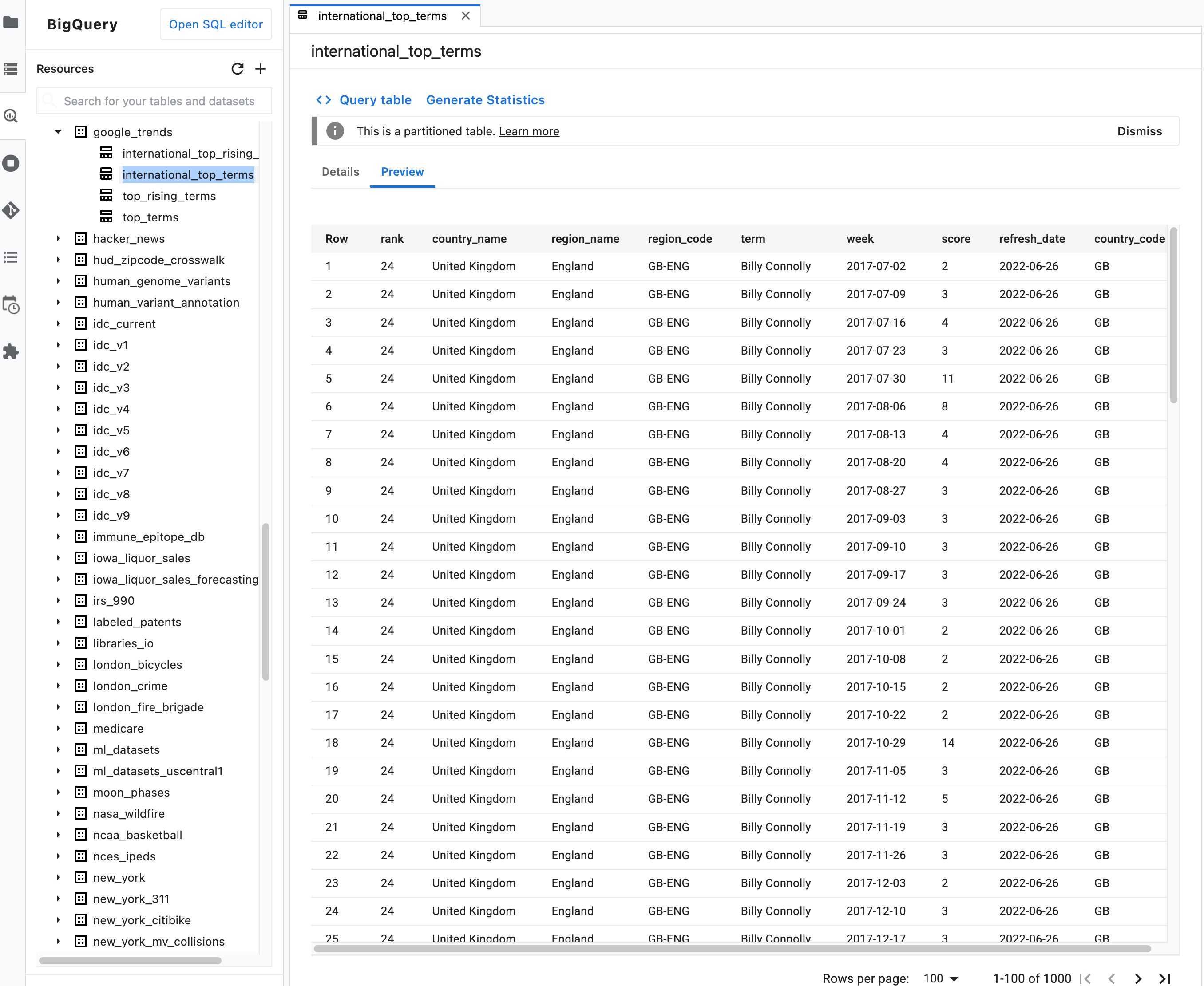
Interroger les données du notebook à l'aide de la commande magique %%bigquery
Dans cette section, vous allez écrire SQL directement dans les cellules de notebook et lire des données de BigQuery dans le notebook Python.
Les commandes magiques basées sur un caractère unique ou double (% ou %%) vous permettent d'utiliser une syntaxe minimale pour interagir avec BigQuery dans le notebook. La bibliothèque cliente BigQuery pour Python est automatiquement installée dans une instance de notebooks gérés. En arrière-plan, la commande magique %%bigquery utilise la bibliothèque cliente BigQuery pour Python pour exécuter la requête concernée, convertir les résultats en objet DataFrame pandas, les enregistrer éventuellement dans une variable, puis afficher les résultats.
Remarque : Depuis la version 1.26.0 du package Python google-cloud-bigquery, l'API BigQuery Storage est utilisée par défaut pour télécharger les résultats des commandes magiques %%bigquery.
Pour ouvrir un fichier notebook, sélectionnez Fichier > Nouveau > Notebook.
Dans la boîte de dialogue Sélectionner le noyau, sélectionnez Python (Local), puis cliquez sur Sélectionner.
Votre nouveau fichier IPYNB s'ouvre.
Pour obtenir le nombre de régions par pays dans l'ensemble de données
international_top_terms, saisissez l'instruction suivante :%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Cliquez sur Exécuter la cellule.
Le résultat ressemble à ce qui suit :
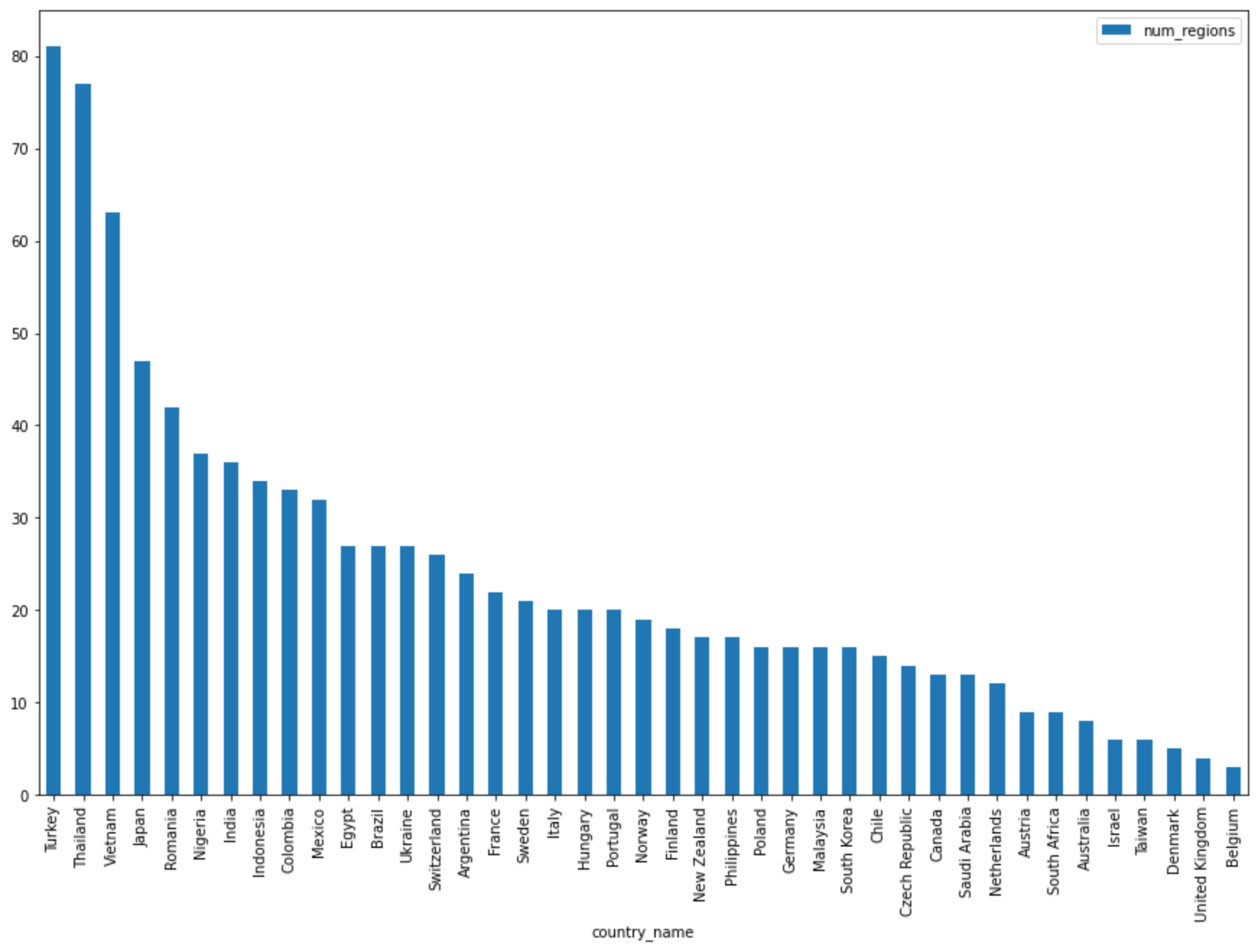
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
Dans la cellule suivante (sous la sortie de la cellule précédente), saisissez la commande suivante pour exécuter la même requête en enregistrant cette fois les résultats dans un nouveau DataFrame pandas nommé
regions_by_country. Vous devez spécifier ce nom à l'aide d'un argument avec la commande magique%%bigquery.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Remarque : Pour en savoir plus sur les arguments disponibles pour la commande
%%bigquery, consultez la documentation sur les commandes magiques de la bibliothèque cliente.Cliquez sur Exécuter la cellule.
Dans la cellule suivante, saisissez la commande ci-dessous pour examiner les premières lignes des résultats de la requête que vous venez de lire :
regions_by_country.head()Cliquez sur Exécuter la cellule.
Le DataFrame pandas
regions_by_countryest prêt à être représenté.
Interroger les données dans un notebook à l'aide de la bibliothèque cliente BigQuery directement
Dans cette section, vous allez utiliser la bibliothèque cliente BigQuery pour Python directement afin de lire des données dans le notebook Python.
La bibliothèque cliente vous permet de mieux contrôler vos requêtes et d'utiliser des configurations plus complexes pour les requêtes et les tâches. Les intégrations de la bibliothèque avec Pandas vous permettent de combiner la puissance du SQL déclaratif au code impératif (Python) pour vous aider à analyser, visualiser et transformer vos données.
Remarque : Vous pouvez utiliser de nombreuses bibliothèques de wrangling, de visualisation et d'analyse des données Python, telles que numpy, pandas, matplotlib, etc. Plusieurs de ces bibliothèques sont basées sur un objet DataFrame.
Dans la cellule suivante, saisissez le code Python ci-dessous pour importer la bibliothèque cliente BigQuery pour Python et initialiser un client :
from google.cloud import bigquery client = bigquery.Client()Celui-ci permet d'envoyer des messages à l'API BigQuery et d'en recevoir.
Cliquez sur Exécuter la cellule.
Dans la cellule suivante, saisissez le code ci-dessous pour récupérer le pourcentage des principaux termes quotidiens parmi les
top_termsaux États-Unis qui se chevauchent dans le temps avec le nombre de jours d'intervalle. L'idée est ici d'examiner les principaux termes de chaque jour et d'en déterminer le pourcentage qui se chevauchent avec les principaux termes de la veille, deux jours avant, trois jours avant, etc. (pour toutes les paires de dates sur une période d'environ un mois).sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
Le code SQL utilisé est encapsulé dans une chaîne Python, puis transmis à la méthode
query()pour exécuter une requête. La méthodeto_dataframeattend la fin de la requête et télécharge les résultats sur un objet DataFrame pandas à l'aide de l'API BigQuery Storage.Cliquez sur Exécuter la cellule.
Les premières lignes de résultats de la requête s'affichent sous la cellule de code.
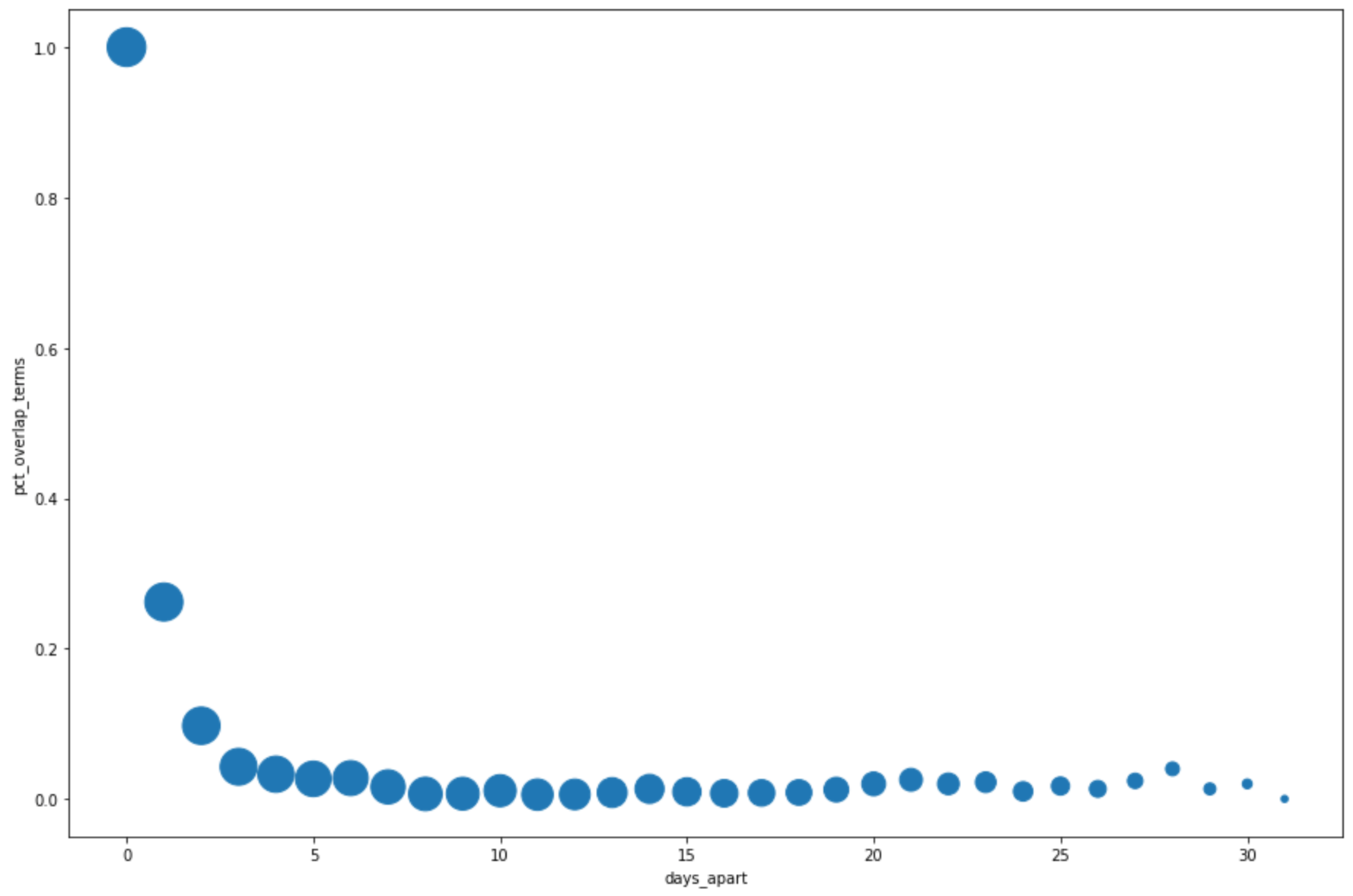
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
Pour en savoir plus sur l'utilisation des bibliothèques clientes BigQuery, consultez le guide de démarrage rapide Utiliser des bibliothèques clientes.
Visualiser les données BigQuery
Dans cette section, vous allez utiliser des fonctionnalités de traçage pour visualiser les résultats des requêtes que vous avez précédemment exécutées dans votre notebook Jupyter.
Dans la cellule suivante, saisissez le code ci-dessous afin d'utiliser la méthode
DataFrame.plot()pandas pour créer un graphique à barres qui représente les résultats de la requête qui renvoie le nombre de régions par pays.regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))Cliquez sur Exécuter la cellule.
La réponse est semblable à ce qui suit :
Dans la cellule suivante, saisissez le code ci-dessous afin d'utiliser la méthode
DataFrame.plot()pandas pour créer un nuage de points qui permet de visualiser les résultats de la requête en pourcentage de chevauchement dans les principaux termes de recherche par jours d'intervalle :pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )Cliquez sur Exécuter la cellule.
La réponse est semblable à ce qui suit : La taille de chaque point reflète le nombre de paires de dates par intervalle de plusieurs jours dans les données. Par exemple, il y a davantage de paires à un jour d'intervalle qu'à plus de 30 jours d'intervalle, car les principaux termes de recherche sont affichés quotidiennement sur une période d'environ un mois.
Pour en savoir plus sur la visualisation des données, consultez la documentation de Pandas.
Utiliser la commande magique %bigquery_stats pour obtenir des statistiques et des visualisations pour toutes les colonnes de table
Dans cette section, vous utilisez un raccourci de notebook pour obtenir des statistiques récapitulatives et des visualisations pour tous les champs d'une table BigQuery.
La bibliothèque cliente BigQuery propose une commande magique, %bigquery_stats, que vous pouvez appeler avec un nom de table spécifique pour obtenir un aperçu de la table et des statistiques détaillées sur chacune des colonnes de la table.
Dans la cellule suivante, saisissez le code suivant pour exécuter cette analyse dans la table
top_termsdes États-Unis :%bigquery_stats bigquery-public-data.google_trends.top_termsCliquez sur Exécuter la cellule.
Pendant un certain temps, une image apparaît avec différentes statistiques sur chacune des sept variables de la table
top_terms. L'image suivante montre une partie d'un exemple de résultat :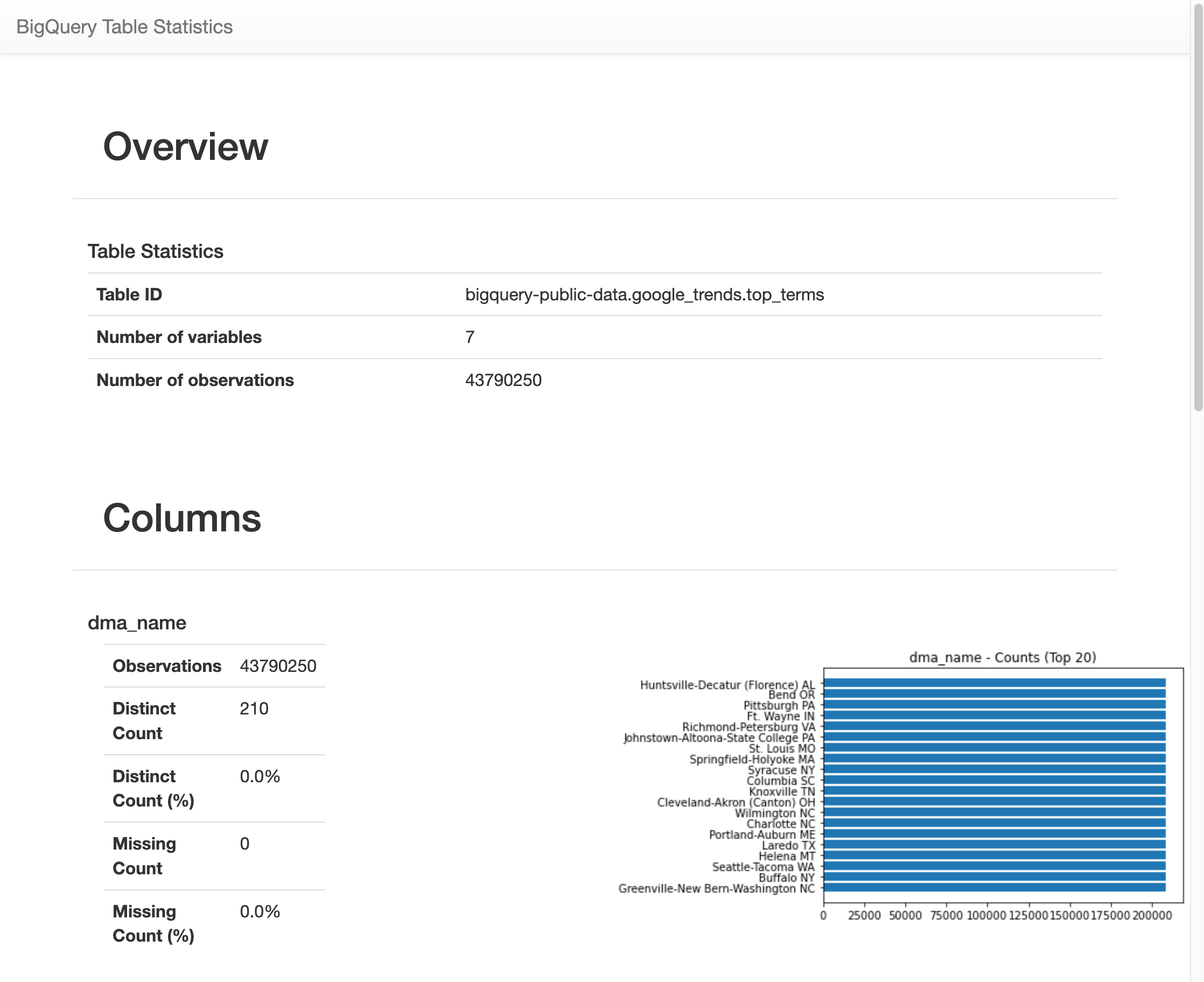
Afficher l'historique des requêtes et réutiliser les requêtes
Pour afficher l'historique de vos requêtes sous forme d'onglet dans JupyterLab, procédez comme suit :
Dans le menu de navigation de JupyterLab, cliquez sur
BigQuery dans Notebooks pour ouvrir le volet BigQuery.Dans le volet BigQuery, faites défiler la page vers le bas et cliquez sur Historique des requêtes.
Une liste de vos requêtes s'ouvre dans un nouvel onglet, dans lequel vous pouvez effectuer les tâches suivantes :
- Pour afficher les détails d'une requête, tels que son ID de tâche, sa date d'exécution et sa durée, cliquez sur la requête.
- Pour modifier la requête, exécutez-la à nouveau ou copiez-la dans votre notebook pour une utilisation ultérieure, puis cliquez sur Ouvrir la requête dans l'éditeur.
Enregistrer et télécharger le notebook
Dans cette section, vous allez enregistrer votre notebook et le télécharger si vous souhaitez l'utiliser ultérieurement après avoir nettoyé les ressources utilisées dans ce tutoriel.
- Sélectionnez Fichier > Enregistrer le notebook.
- Sélectionnez Fichier > Télécharger pour télécharger une copie locale de votre notebook sous forme de fichier IPYNB sur votre ordinateur.
Effectuer un nettoyage
Le moyen le plus simple d'éviter la facturation consiste à supprimer le projet Cloud que vous avez créé pour ce tutoriel.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Pour en savoir plus sur l'écriture de requêtes pour BigQuery, consultez la page Exécuter des tâches de requête interactives et par lot.
- Pour en savoir plus sur Vertex AI Workbench, consultez la page Vertex AI Workbench.