Introducción a la búsqueda vectorial
En este documento, se proporciona una descripción general de la búsqueda vectorial en BigQuery. La búsqueda de vectores es una técnica para comparar objetos similares con incorporaciones y se usa para potenciar los productos de Google, como la Búsqueda de Google, YouTube y Google Play. Puedes usar la búsqueda de vectores para realizar búsquedas a gran escala. Cuando usas índices de vectores con la búsqueda de vectores, puedes aprovechar tecnologías fundamentales, como el índice de archivos invertidos (IVF) y el algoritmo ScaNN.
La búsqueda vectorial se basa en embeddings. Las incorporaciones son vectores numéricos de alta dimensión que representan una entidad determinada, como un fragmento de texto o un archivo de audio. Los modelos de aprendizaje automático (AA) usan incorporaciones para codificar la semántica de esas entidades a fin de facilitar el razonamiento y la comparación. Por ejemplo, una operación común en los modelos de agrupamiento en clústeres, clasificación y recomendación es medir la distancia entre vectores en un espacio de incorporaciones para encontrar elementos que sean más semánticamente similares.
Este concepto de similitud y distancia semánticas en un espacio de incorporación se demuestra visualmente cuando consideras cómo se pueden trazar diferentes elementos. Por ejemplo, términos como gato, perro y león, que representan tipos de animales, se agrupan cerca en este espacio debido a sus características semánticas compartidas. Del mismo modo, términos como automóvil, camión y el término más genérico vehículo formarían otro clúster. Esto se muestra en la siguiente imagen:
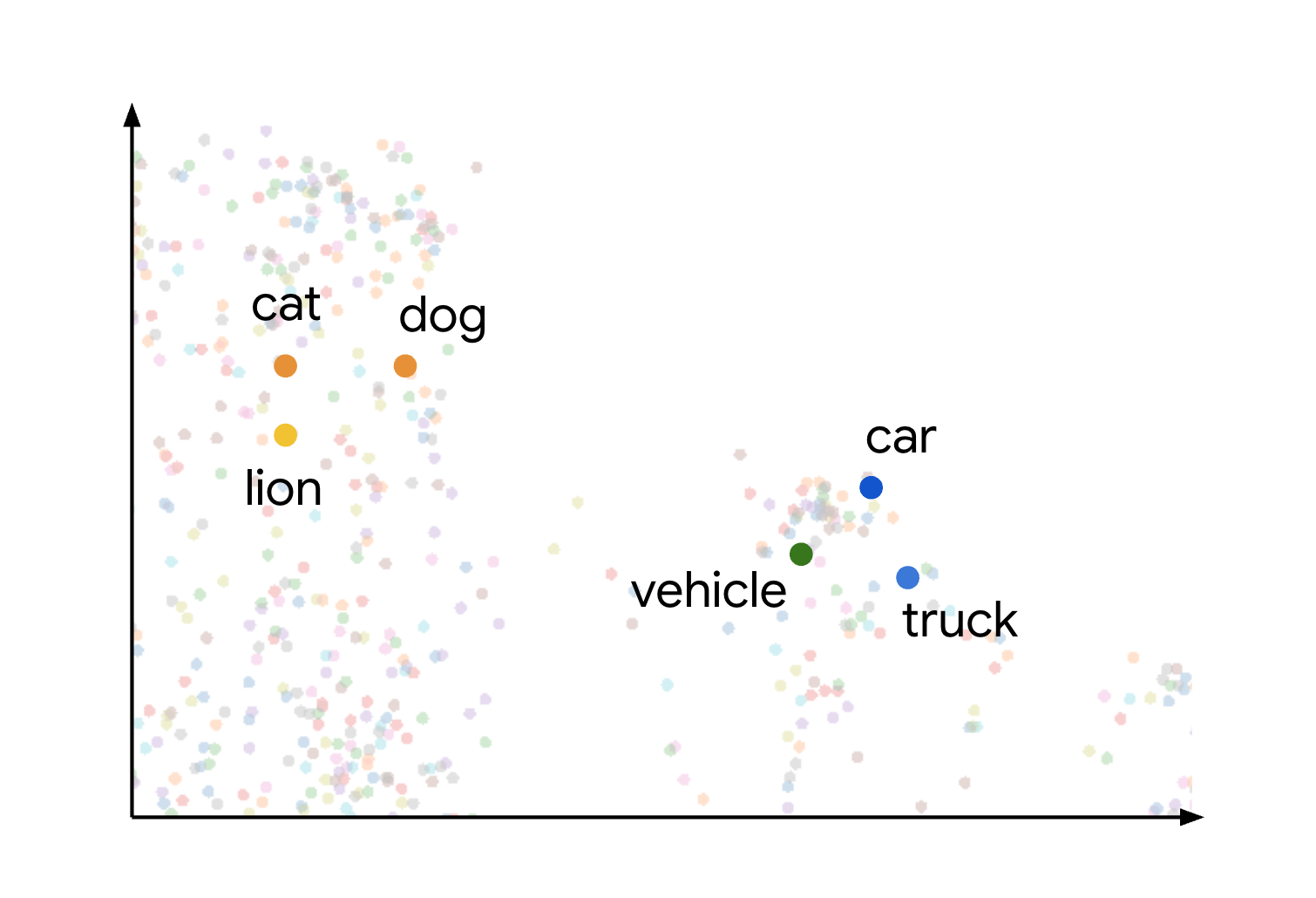
Puedes ver que los clústeres de animales y vehículos están muy separados entre sí. La separación entre los grupos ilustra el principio de que, cuanto más cerca estén los objetos en el espacio de incorporación, más similares serán semánticamente, y las distancias más grandes indican una mayor disimilitud semántica.
BigQuery proporciona una experiencia de extremo a extremo para generar incorporaciones, indexar contenido y realizar búsquedas de vectores. Puedes completar cada una de estas tareas de forma independiente o en un solo recorrido. Si quieres ver un instructivo que muestre cómo completar todas estas tareas, consulta Realiza búsquedas semánticas y generación de recuperación aumentada.
Para realizar una búsqueda vectorial con SQL, usa la función VECTOR_SEARCH.
De forma opcional, puedes crear un índice vectorial con la sentencia CREATE VECTOR INDEX.
Cuando se usa un índice vectorial, VECTOR_SEARCH usa la técnica de búsqueda vecino más cercano aproximado para mejorar el rendimiento de la búsqueda vectorial, con la compensación de reducir la recuperación y mostrar resultados más aproximados. Sin un índice de vectores, VECTOR_SEARCH usa la búsqueda de fuerza bruta para medir la distancia de cada registro. También puedes optar por usar la fuerza bruta para obtener resultados exactos, incluso cuando un índice vectorial está disponible.
En este documento, se enfoca en el enfoque de SQL, pero también puedes realizar búsquedas de vectores con BigQuery DataFrames en Python. Para obtener un notebook que ilustre el enfoque de Python, consulta Cómo compilar una aplicación de búsqueda vectorial con BigQuery DataFrames.
Casos de uso
La combinación de la generación de incorporaciones y la búsqueda vectorial habilita muchos casos de uso interesantes. Estos son algunos casos de uso posibles:
- Generación de aumento de recuperación (RAG): Analiza documentos, realiza búsquedas de vectores en el contenido y genera respuestas resumidas a preguntas en lenguaje natural con modelos de Gemini, todo dentro de BigQuery. Para ver un notebook que ilustre esta situación, consulta Cómo compilar una aplicación de búsqueda vectorial con BigQuery DataFrames.
- Recomendar productos sustitutos o similares: Mejora las aplicaciones de comercio electrónico sugiriendo alternativas de productos en función del comportamiento de los clientes y la similitud de los productos.
- Análisis de registros: Ayuda a los equipos a priorizar de forma proactiva las anomalías en los registros y acelerar las investigaciones. También puedes usar esta función para enriquecer el contexto de los LLM, con el fin de mejorar la detección de amenazas, la investigación forense y los flujos de trabajo de solución de problemas. Para ver un notebook que ilustre esta situación, consulta Detección y análisis de anomalías de registros con embeddings de texto y búsqueda vectorial de BigQuery.
- Agrupación y segmentación: Segmenta los públicos con precisión. Por ejemplo, una cadena de hospitales podría agrupar pacientes con notas en lenguaje natural y datos estructurados, o un especialista en marketing podría segmentar anuncios en función del intent de la búsqueda. Para ver un notebook que ilustre esta situación, consulta Create-Campaign-Customer-Segmentation.
- Anulación de la duplicación y resolución de entidades: Limpia y consolida los datos. Por ejemplo, una empresa publicitaria podría anular los registros de información de identificación personal (PII), o una empresa de bienes raíces podría identificar las direcciones de correo que coincidan.
Precios
La función VECTOR_SEARCH y la sentencia CREATE VECTOR INDEX usan los precios de procesamiento de BigQuery.
Función
VECTOR_SEARCH: Se te cobra por la búsqueda de similitudes, con precios según demanda o de ediciones.- Según demanda: Se te cobra por la cantidad de bytes analizados en la tabla base, el índice y la consulta de búsqueda.
Precios de las ediciones: Se te cobra por las ranuras necesarias para completar el trabajo dentro de la edición de tu reserva. Los cálculos de similitud más grandes y complejos generan más cargos.
Declaración de
CREATE VECTOR INDEX: No se aplican cargos por el procesamiento necesario para compilar y actualizar tus índices vectoriales, siempre y cuando el tamaño total de los datos de tablas indexadas esté por debajo del límite por organización. Para admitir la indexación más allá de este límite, debes proporcionar tu propia reserva para controlar los trabajos de administración de índices.
El almacenamiento también es una consideración para las incorporaciones y los índices. La cantidad de bytes almacenados como incorporaciones e índices está sujeta a costos de almacenamiento activo.
- Los índices vectoriales generan costos de almacenamiento cuando están activos.
- Puedes encontrar el tamaño del almacenamiento de índices en la vista
INFORMATION_SCHEMA.VECTOR_INDEXES. Si el índice vectorial aún no tiene una cobertura del 100%, se te cobra por todo lo que se indexó. Puedes verificar la cobertura del índice con la vistaINFORMATION_SCHEMA.VECTOR_INDEXES.
Cuotas y límites
Para obtener más información, consulta Límites de los índices vectoriales.
Limitaciones
BigQuery BI Engine no acelera las consultas que contienen la función VECTOR_SEARCH.
¿Qué sigue?
- Obtén más información sobre cómo crear un índice vectorial.
- Obtén información para realizar una búsqueda vectorial con la función
VECTOR_SEARCH. - Prueba el instructivo Busca incorporaciones con búsqueda vectorial para aprender a crear un índice vectorial y, luego, realiza una búsqueda vectorial para incorporaciones con y sin el índice.
Prueba el instructivo Realiza búsquedas semánticas y generación de recuperación aumentada para aprender a hacer las siguientes tareas:
- Generar incorporaciones de texto.
- Crear un índice vectorial en las incorporaciones.
- Realizar una búsqueda vectorial con las incorporaciones para buscar texto similar.
- Realizar la generación de aumento de recuperación (RAG) con los resultados de la búsqueda vectorial para aumentar la entrada de instrucciones y mejorar los resultados.
Prueba el instructivo Cómo analizar archivos PDF en una canalización de generación mejorada por recuperación para aprender a crear una canalización de RAG basada en contenido de PDF analizado.