¿Qué es la generación mejorada por recuperación (RAG)?
La generación mejorada por recuperación (RAG) es un marco de trabajo de IA que combina las fortalezas de los sistemas tradicionales de recuperación de información (como la búsqueda y las bases de datos) con las capacidades de los modelos de lenguaje grandes (LLM) generativos. Cuando combinas tus datos y el conocimiento del mundo con las habilidades lingüísticas de los LLM, la generación basada en datos es más precisa, actualizada y relevante para tus necesidades específicas. Consulta este libro electrónico para descubrir la "Verdad empresarial".
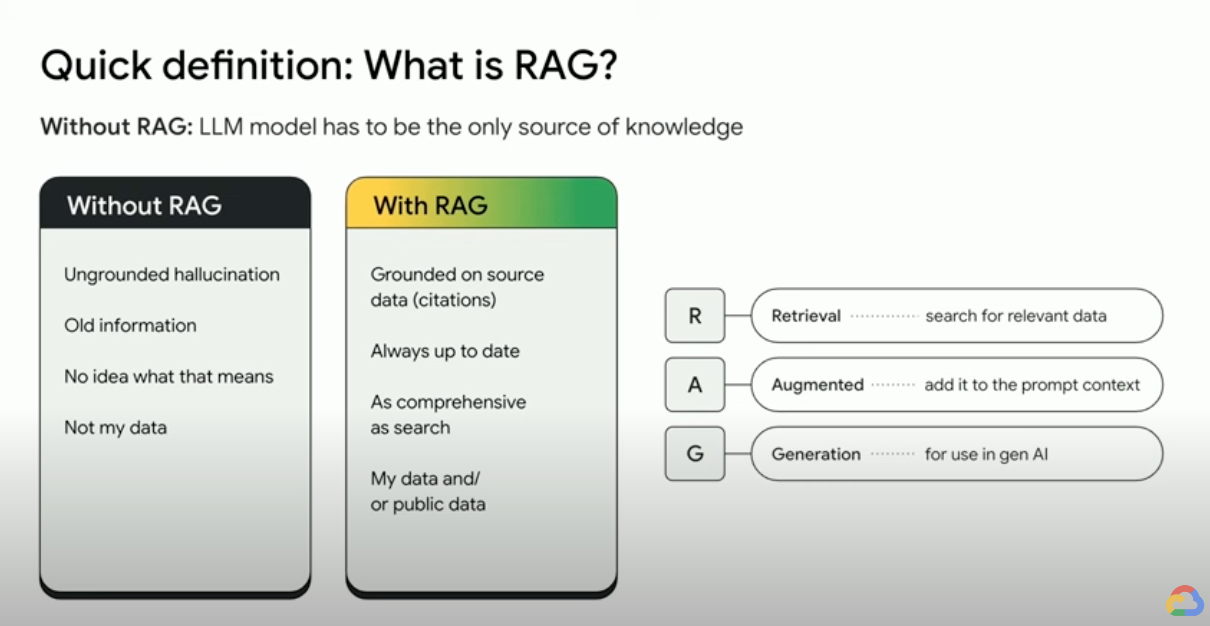
¿Cómo funciona la generación mejorada por recuperación?
Las RAG operan con algunos pasos principales para ayudar a mejorar los resultados de la IA generativa:
- Recuperación y procesamiento previo: Las RAG aprovechan algoritmos de búsqueda potentes para realizar consultas en datos externos, como páginas web, bases de conocimiento y bases de datos. Una vez recuperada, la información relevante se somete a un procesamiento previo, lo que incluye la tokenización, la lematización y la eliminación de palabras irrelevantes.
- Generación fundamentada: la información recuperada preprocesada se incorpora sin problemas al LLM previamente capacitado. Esta integración mejora el contexto del LLM y le proporciona una comprensión más integral del tema. Este contexto aumentado permite que el LLM genere respuestas más precisas, informativas y atractivas.
¿Por qué usar la RAG?
RAG ofrece varias ventajas en la mejora de los métodos tradicionales de generación de texto, especialmente cuando se trata de información fáctica o respuestas basadas en datos. Estas son algunas razones clave por las que usar RAG puede ser beneficioso:
Acceso a información nueva
Los LLM se limitan a sus datos previamente entrenados. Esto genera respuestas desactualizadas y potencialmente inexactas. La RAG supera esto proporcionando información actualizada a los LLM.
Fundamentación basada en hechos
Los LLMs son herramientas poderosas para generar texto creativo y atractivo, pero a veces pueden tener dificultades con la exactitud fáctica. Esto se debe a que los LLMs se entrenan con cantidades enormes de datos de texto, que pueden contener imprecisiones o sesgos.
Proporcionar “hechos” al LLM como parte de la instrucción de entrada puede mitigar las “alucinaciones de la IA generativa”. El punto crucial de este enfoque es garantizar que los hechos más relevantes se proporcionen al LLM y que la salida del LLM se base por completo en esos hechos, al tiempo que se responde la pregunta del usuario y se cumplen las instrucciones del sistema y las restricciones de seguridad.
Usar la ventana de contexto largo (LCW) de Gemini es una excelente forma de proporcionar materiales de origen al LLM. Si necesitas proporcionar más información de la que cabe en el LCW o si necesitas aumentar el rendimiento, puedes usar un enfoque de RAG que reducirá la cantidad de tokens, lo que te ahorrará tiempo y dinero.
Buscar con bases de datos de vectores y reclasificadores de relevancia
Las RAG suelen recuperar hechos a través de la búsqueda, y los motores de búsqueda modernos ahora aprovechan las bases de datos vectoriales para recuperar documentos relevantes de forma eficiente. Las bases de datos de vectores almacenan documentos como embeddings en un espacio de alta dimensión, lo que permite una recuperación rápida y precisa basada en la similitud semántica. Las embeddings multimodales se pueden usar para imágenes, audio y video, entre otros, y estas embeddings de medios se pueden recuperar junto con embeddings de texto o incorporaciones de varios idiomas.
Los motores de búsqueda avanzados, como Agent Search de Gemini Enterprise Agent Platform, usan la búsqueda semántica y la búsqueda de palabras clave en conjunto (llamada búsqueda híbrida), y un reclasificador que califica los resultados de la búsqueda para garantizar que los resultados principales que se muestran sean los más relevantes. Además, las búsquedas funcionan mejor con una consulta clara y enfocada sin errores ortográficos; por lo tanto, antes de la búsqueda, los motores de búsqueda sofisticados transformarán una consulta y corregirán los errores ortográficos.
Relevancia, exactitud y calidad
El mecanismo de recuperación en RAG es de vital importancia. Necesitas la mejor búsqueda semántica además de una base de conocimiento seleccionada para garantizar que la información recuperada sea relevante para la consulta o el contexto de entrada. Si la información que recuperaste es irrelevante, tu generación podría ser fundamentada, pero fuera del tema o incorrecta.
A través del ajuste o la ingeniería de instrucciones del LLM para generar texto basado completamente en el conocimiento recuperado, la RAG ayuda a minimizar las contradicciones y las incoherencias en el texto generado. Esto mejora significativamente la calidad del texto generado y la experiencia del usuario.
La evaluación de modelos en Gemini Enterprise Agent Platform ahora califica el texto generado por el LLM y los fragmentos recuperados según métricas como la coherencia, la fluidez, la fundamentación, la seguridad, el cumplimiento de instrucciones y la calidad de las respuestas a preguntas, entre otras. Estas métricas te ayudan a medir el texto fundamentado que obtienes del LLM (para algunas métricas, es una comparación con una respuesta de verdad fundamental que proporcionaste). Implementar estas evaluaciones te brinda una medición de referencia y puedes optimizar la calidad de RAG mediante la configuración de tu motor de búsqueda, la selección de los datos de origen, la mejora de las estrategias de análisis o segmentación del diseño de origen, o el perfeccionamiento de la pregunta del usuario antes de la búsqueda. Un enfoque de RAG Ops basado en métricas como este te ayudará a escalar la colina hacia un RAG de alta calidad y una generación fundamentada.
RAG, agentes y chatbots
RAG y la fundamentación pueden integrarse en cualquier aplicación o agente de LLM que necesite acceso a datos nuevos, privados o especializados. Mediante el acceso a información externa, los chatbots y los agentes conversacionales con tecnología de RAG aprovechan el conocimiento externo para proporcionar respuestas más integrales, informativas y contextuales, lo que mejora la experiencia general del usuario.
Tus datos y tu caso de uso son lo que diferencia lo que estás creando con la IA generativa. RAG y la conexión llevan tus datos a LLM de forma eficiente y escalable.
¿Qué productos y servicios de Google Cloud están relacionados con la RAG?
Los siguientes productos de Google Cloud están relacionados con la generación mejorada por recuperación:
 Motor RAG de Gemini Enterprise Agent PlatformMarco de trabajo de datos para desarrollar aplicaciones de LLM adaptadas al contexto y facilitar la Generación mejorada por recuperación.
Motor RAG de Gemini Enterprise Agent PlatformMarco de trabajo de datos para desarrollar aplicaciones de LLM adaptadas al contexto y facilitar la Generación mejorada por recuperación.- Búsqueda de agentes en Agent Platform de Gemini EnterpriseAgent Search es la Búsqueda de Google para tus datos, un compilador de RAG y búsqueda completamente administrado y listo para usar.
 Vector Search en Gemini Enterprise Agent PlatformEl índice de vectores de alto rendimiento que potencia la búsqueda de agentes; permite la búsqueda y recuperación híbrida y semántica de grandes colecciones de incorporaciones con alta recuperación a una alta tasa de consultas.
Vector Search en Gemini Enterprise Agent PlatformEl índice de vectores de alto rendimiento que potencia la búsqueda de agentes; permite la búsqueda y recuperación híbrida y semántica de grandes colecciones de incorporaciones con alta recuperación a una alta tasa de consultas. BigQueryGrandes conjuntos de datos que puedes usar para entrenar modelos de aprendizaje automático, incluidos modelos para la búsqueda de vectores en Agent Platform.
BigQueryGrandes conjuntos de datos que puedes usar para entrenar modelos de aprendizaje automático, incluidos modelos para la búsqueda de vectores en Agent Platform.- API de generación fundamentadaEl modo de alta fidelidad de Gemini se basa en la Búsqueda de Google o en los datos integrados, o puedes usar tu propio motor de búsqueda.
 AlloyDB AIEjecuta modelos en Agent Platform y accede a ellos en tu aplicación con consultas en SQL conocidas. Usa modelos de Google, como Gemini, o tus propios modelos personalizados.
AlloyDB AIEjecuta modelos en Agent Platform y accede a ellos en tu aplicación con consultas en SQL conocidas. Usa modelos de Google, como Gemini, o tus propios modelos personalizados.
Lecturas adicionales
Obtén más información con estos recursos para usar la generación aumentada por recuperación.
- RAG con la tecnología de la Búsqueda de Google
- RAG con bases de datos en Google Cloud
- APIs para crear tus propios sistemas de búsqueda y generación mejorada por recuperación (RAG)
- Cómo usar RAG en BigQuery para reforzar los LLM
- Muestra de código y guía de inicio rápido para familiarizarse con la RAG
- Infraestructura para una aplicación de IA generativa compatible con RAG mediante el uso de GKE
Da el siguiente paso
Comienza a desarrollar en Google Cloud con el crédito gratis de $300 y los más de 20 productos del nivel Siempre gratuito.
¿Necesitas ayuda para comenzar?
Comunicarse con VentasTrabaja con un socio confiable
Buscar un socioSigue explorando
Ver todos los productos


















