Next-gen search and RAG with Vertex AI
UK/I AI Customer Engineering, Google Cloud
Generative AI has fundamentally transformed how the world interacts with information, and the search industry is no exception. The search landscape is changing rapidly, driven by the rise of large language models (LLMs). Whether they're interacting with their company's internal data or browsing public websites, users now increasingly expect more intelligent, intuitive, and comprehensive search experiences. At Google Cloud, we've been steadily evolving our capabilities to help developers build their retrieval augmented generation (RAG) solutions and help meet them where they are in their journey.
Gen AI makes search better. LLMs excel at understanding the nuances of language and context-dependent meanings. Their ability to transform lengthy multimodal input (text, images) into numerical representations (embeddings) while preserving semantic relationships over large disparate data has opened up new possibilities for search. Embeddings enable more accurate interpretations of search queries as compared to traditional semantic- and keyword-based search systems.
Search, in turn, makes LLMs better. To unlock the full potential of gen AI, organizations need to ground model response in what we call “enterprise truth” — fresh, real-time data and enterprise systems. The resulting RAG solution is powered by search, where the quality of the grounding is dependent on the quality of search that powers it.
When they leverage LLMs, developers can build more sophisticated gen AI applications that use grounded generation and that are powered by search solutions. LLM-powered summaries direct users to the most relevant search snippets for reference, boosting users’ productivity.
In this blog post, we delve into how the search landscape has shifted over the past year and how Vertex AI is poised to help organizations build search applications for their varied requirements. It consists of three parts: first we introduce emerging search patterns, then we explore the capabilities in Vertex AI Search to enable search applications. In the last section, we discuss when to use what to bring various search applications to life with Vertex AI.
Part 1: Emerging patterns in search
Working with a diverse range of customers across various sectors, we've identified three prominent search patterns:
1. Enhanced semantic search
Organizations across different domains including legal, finance, research, or human resources often have large amounts of unstructured documents, e.g., pdfs, docs, websites, internal Confluence sites, etc. With the advent of generative AI, they are now increasingly exploring RAG-powered solutions to find the right information faster and drive their employees’ productivity. For example, one common search scenario is in financial services, where RAG solutions are helping underwriters skim through extensive policy documents to find relevant information and clauses related to the claims.
Semantic search understands the intent and context of a user query beyond keywords, to find the most relevant results. An example of semantic query is when a user searches for “Google’s Net Zero plans” or “Google’s Carbon Neutrality” against a repository containing Alphabet’s financial data. An LLM-powered semantic search solution understands the user’s query and the relationship between different relevant entities (“Net Zero” or “Carbon Neutrality plans”; and “Google” and “Alphabet”), how the two are related, and can provide relevant search results, often accompanied by a guided summary. In contrast, traditional keyword- or token-based solutions are likely to struggle to find relevant matches in the documents unless the documents directly refer to those keywords.

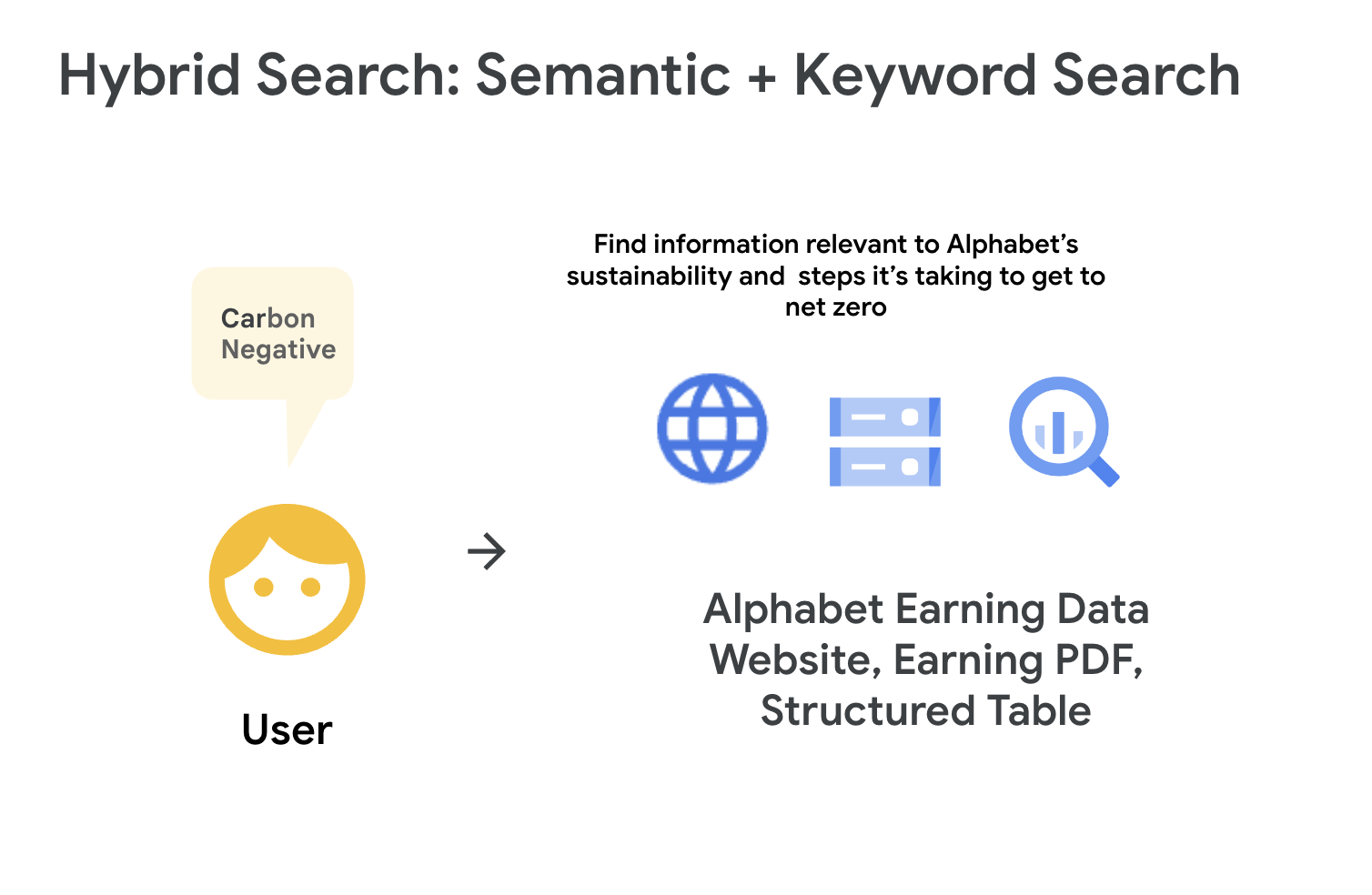
2. Hybrid search solutions
There are certain industries, specifically retail, where users often want to search for a particular product or feature via keyword or search by describing the product, for example, “LED” or “decorative small lights for my balcony”.
For such cases, customers are exploring so-called hybrid search solutions that can deal with a combination of keyword and semantic search as a key functional requirement. Hybrid search allows users to find relevant entities while still benefiting from the flexibility of natural language queries, and caters to diverse user preferences and search intentions.
In the above example of Alphabet’s financial data, users can request for both keyword- or token-based search, e.g., “Carbon” or “Carbon negative” with auto-complete support, or also request more complex queries like “What are Google’s carbon negative plans”. The search system should be able to identify relevant results for user queries beyond the exact keyword match.
Depending on the requirements, customers may start building semantic search applications and if keyword- or token-based search is needed, can explore search solutions that support both keyword and semantic search.
3. Analytical queries (beyond search):
Semantic and hybrid search have been around for quite some time, but with the advent of LLMs the quality of search results and user experience has improved significantly. An emerging pattern is that boundaries between search and analytics have started to blur for users. Developers are exploring search solutions that allow users to ask complex, analytical questions of their data in natural language. For example, the query "Total Carbon Emissions removed for 2024 and 2022?" returns aggregated answers that go beyond simply finding documents that contain those words.

Developing analytical search with natural language is a very complex problem. Understanding disparate complex data sources and associated schema, especially in the case of structured relational data, and being able to produce aggregated results to consistently serve user queries requires a more complex “agentic” workflow. LLM-powered RAG can be one of the enabling components or tools for such agents.
Part 2: Vertex AI: Powering the future of search
Vertex AI offers a comprehensive suite of tools and services to address the above search patterns.
Building and managing RAG systems can be complex and can be quite nuanced. Developers need to develop and maintain several RAG building blocks like data connectors, data processing, chunking, annotating, vectorization with embeddings, indexing, query rewriting, retrieval, reranking, along with LLM-powered summarization. Designing, building and maintaining this pipeline can be time- and resource-intensive. Being able to scale each of the components to handle bursty search traffic and coping with a large corpus of varied and frequently updated data can also be challenging. Speaking of scale, as the queries per second ramp up, many vector databases degrade both their recall and latency metrics.
Vertex AI Search leverages decades of Google's expertise in information retrieval and brings together the power of deep information retrieval, state-of-the-art natural language processing, and the latest in LLM processing to understand user intent and return the most relevant results for the user. No matter where you are in the development journey, Vertex AI Search provides several options to bring your enterprise truth to life from out-of-the-box to DIY RAG.
Why Vertex AI Search for out-of-the-box RAG:
The out-of-the-box solution based on Vertex AI Search brings Google-quality search to building end-to-end, state-of-the-art semantic and hybrid search applications, with features such as:
-
Built-in connectors to several data sources: Cloud Storage, BigQuery, websites, Confluence, Jira, Salesforce, Slack and many more
-
A state-of-the-art document layout parser capable of keeping chunks of data organized across pages, containing embedded tables, annotating embedded images, and that can track heading ancestry as metadata for each chunk
-
“Hybrid search” — a combination of keyword (sparse) and LLM (dense) based embeddings to handle any user query. Sparse vectors tend to directly map words to numbers and dense vectors are designed to better represent the meaning of a piece of text.
-
Advanced neural matching between user queries and document snippets to help retrieve highly relevant and ranked results for the user. Neural matching allows a retrieval engine to learn the relationships between a query’s intentions and highly relevant documents, allowing Vertex AI Search to recognize the context of a query instead of the simple similarity search.
-
LLM-powered summaries with citations that are designed to scale to your search traffic. Vertex AI Search supports custom LLM instruction templates, making it easy to create powerful engaging search experiences with minimal effort.
-
Support for building a RAG search engine grounded on the user’s own data in minutes from the console. Developers can also use the API to programmatically build and test the OOTB agent.
Explore this notebook (Part I) to see the Vertex AI Agent Builder SDK in action.
For greater customization
The Vertex AI Search SDK further allows developers to integrate it with open-source LLMs or other custom components, tailoring the search pipeline to their specific needs. As mentioned above, building end-to-end RAG solutions can be complex; as such, developers might want to rely on Vertex AI Search as a grounding source for search results retrieval and ranking, and leverage custom LLMs for the guided summary. Vertex AI Search also provides grounding in Google Search.
Find an example for Grounding Responses for Gemini mode Example notebook in Part II here.
Developers might already be building their LLM application with frameworks like Langchain/ LLamaIndex. Vertex AI Search has native integration with LangChain and other frameworks, allowing developers to retrieve search results and/or grounded generation. It can also be linked as an available tool in Vertex AI Gemini SDK. Likewise, Vertex AI Search can be a retrieval source for the new Grounded Generation API powered by Gemini “high-fidelity mode,” which is fine-tuned for grounded generation.
Here is a Notebook example for leveraging Vertex AI Search from LangChain in Part III here.
Vertex AI DIY Builder APIs for end-to-end RAG
Vertex AI provides the essential building blocks for developers who want to construct their own end-to-end RAG solutions. These include APIs for document parsing, chunking, LLM text and multimodal vector embeddings, versatile vector database options (Vertex AI Vector Search, AlloyDB, BigQuery Vector DB), reranking APIs, and grounding checks.

-
Learn more about the Build your own RAG workflow with DIY APIs here.
-
Use LlamaIndex on Vertex to assemble your own RAG search engine using these DIY APIs.
-
Follow along with this notebook DIY RAG with LangChain example.
It’s also worth noting that Gemini 1.5 Pro available on Vertex AI supports a 2M token input context window — around 2000 pages worth of context — all while maintaining SOTA reasoning capabilities. Recently Google Deepmind and University of Michigan published comprehensive research on choosing between RAG or long-context windows. Gemini 1.5 Pro adheres well to the given system instructions and contextual information to guide users with their queries. With the long context window, multimodal reasoning and its caching ability, developers can quickly start with Gemini 1.5 Pro to test and prototype their semantic information retrieval use case. Then, once they scale up their source data or usage profiles, they can use RAG, possibly in concert with a long context window.
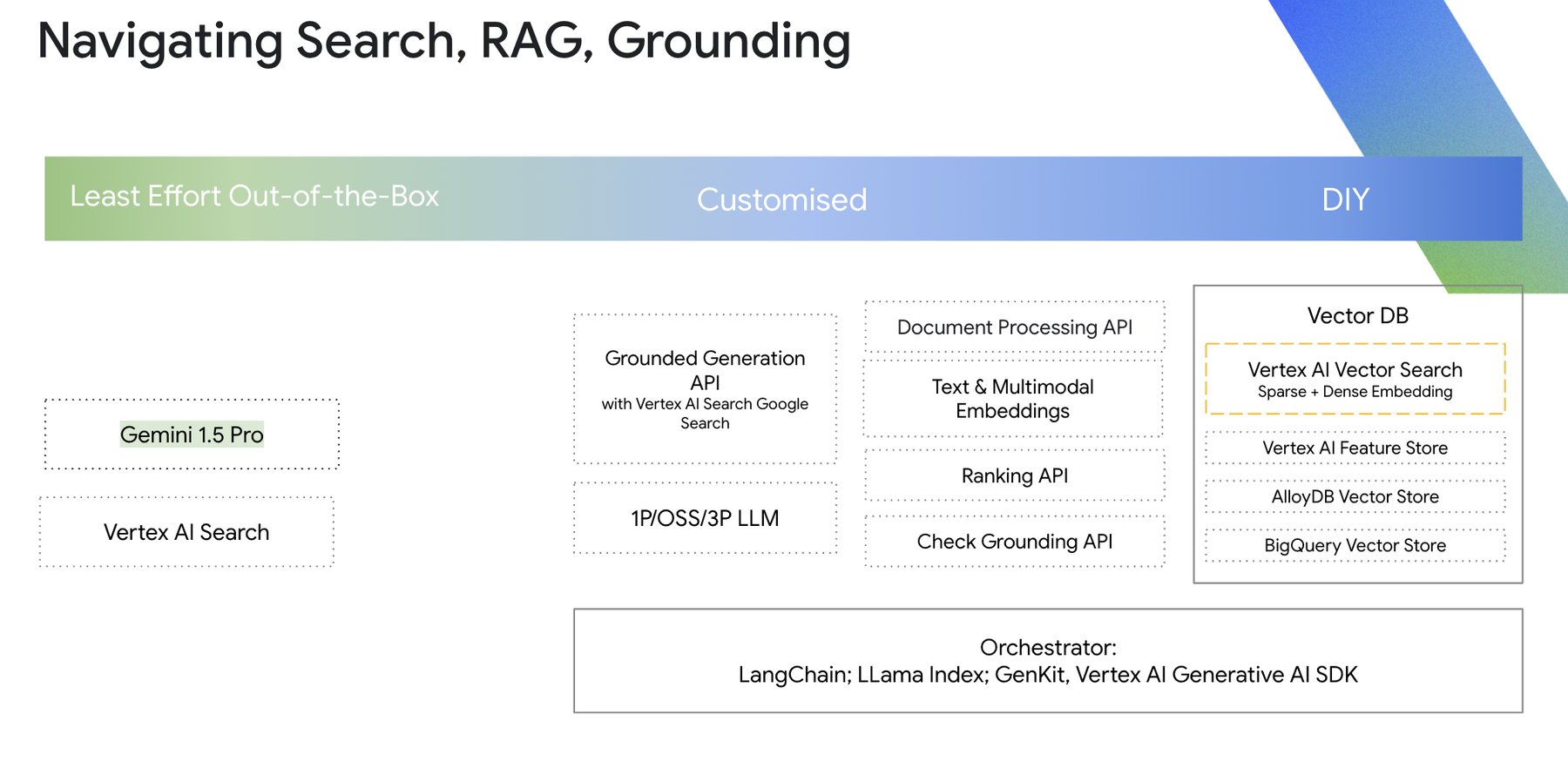
Based on where developers are in their journey and their orchestration framework of choice, they can select Vertex AI Search out-of-the-box plus DIY APIs to build end-to-end RAG applications. Understanding your organization’s appetite towards building, maintaining and scaling RAG applications can also help guide a particular solution path.
Let’s explore how the above options can be leveraged to build the different search scenarios we discussed.
Part 3: Search patterns with Vertex AI
Enabling semantic and hybrid search
-
Vertex AI Search (either OOTB or DIY APIs) can be leveraged to build both semantic and hybrid search solutions.
-
If developers/ data scientists have advanced knowledge of embeddings to train their own sparse and dense embeddings, Vertex AI Search provides the ability to customize embeddings. This gives developers the flexibility to bring embeddings suitable for their hybrid search or multimodal search needs. They can also explore search tuning to further improve the search results. This can also come in handy if the organization has industry-specific or company-specific queries that are less well addressed by general LLMs.
-
For hybrid search, embeddings can significantly influence the search results. Hybrid Search uses both dense embeddings (e.g., text-embeddings-gecko) and sparse embeddings (e.g., BM25, SPLADE), letting users search based on a combination of keyword search and semantic search.
-
For developers who prefer a DIY RAG solution, they can explore Vertex AI Vector Search, which is based on vector search technology developed by Google Research. Vector Search can search at scale, with high queries per second (QPS), high recall, low latency, and cost efficiency.
Vector Search supports custom embeddings along with sparse and dense embeddings (in Preview). Vertex AI's recent support for both sparse and dense embeddings within Vector Search empowers developers to create hybrid search applications that blend keyword-based and semantic search capabilities. With Vector Search they can leverage the same infrastructure that provides a foundation for Google products such as Google Search, YouTube, and Play.
Tackling analytical queries
Building solutions to tackle analytical queries is also complex and challenging due to various factors like understanding complex data schemas and types, handling time ranges and relevant entities for filtering, and the frequent requirement for deterministic outputs. Agents using RAG and natural language to SQL could be a viable solution in this scenario. At Google Cloud, we’re constantly innovating in this space and provide components to help build analytical search-like systems. Check out the OpenDataQnA Analytic Agent on Github to see one such solution. The following Google Cloud capabilities can help developers build an analytical query agents workflow:
-
Function calling: Generative models can provide different responses at different times for the same prompts, potentially leading to inconsistencies. Function calling is a feature of Gemini models that makes it easier for developers to get structured data outputs from generative models. It can allow developers to deterministically control elements of the AI's response.
For analytical-like search solutions, developers can potentially make structured, unstructured or blended Vertex AI Search retrieval tools available to Gemini for reasoning. They can create custom functions to help identify relevant attributes like table/column names needed and to build relevant SQL queries or custom aggregation metrics, making these custom APIs available as tool configs to Gemini, which in turn leads to more deterministic responses for user queries. Gemini’s function calling can enhance consistency for analytical queries. Here is an example of leveraging function calling for structured data exploration.
-
Vertex AI Agent Builder: Alternatively, for low-code options, developers can also explore Vertex AI Agent Builder. An agent app typically consists of many agents, where each agent is defined to handle specific tasks. The agent data is provided to the LLM, so it has the information it needs to answer questions and execute tasks. Using Vertex AI data stores, agents can find answers for an end user's questions from your data. Data stores are a collection of websites and documents, each of which reference the organization’s data. Using Vertex AI Agent tools, developers can connect agent apps to external systems.
-
BigQuery data canvas: BigQuery data canvas makes data analytics faster and easier with a unified, natural language-driven experience that centralizes data discovery, preparation, querying, and visualization. This can help with ad hoc analysis, exploratory data analysis tasks.

Unlock your data with RAG, grounding and search in Vertex AI
To summarize, based on the search and business requirements and their development framework preference, developers can navigate through the various options that Vertex AI provides, from the out-of-the-box solution, to DIY, to meet them where they are in their RAG journey. For these use cases, Vertex AI offers:
-
Google-quality search: Benefit from Google's expertise in search technology and infrastructure with Vertex AI Search out-of-the-box.
-
Comprehensive RAG solutions: Simplify the development of custom RAG applications with Vertex AI Search as a grounding tool/ LangChain retriever.
-
Flexibility and customization: Tailor your search experience to your specific needs by leveraging Vertex AI Search and Vertex AI DIY APIs.
*UK/I AI Customer Engineering (alphabetically): Bipul Kumar, Christian Silva, Mandie Quartly, Megha Agarwal, Sam Weeks, Tuba Islam



