Introduzione alla ricerca vettoriale
Questo documento fornisce una panoramica della ricerca vettoriale in BigQuery. La ricerca vettoriale è una tecnica per confrontare oggetti simili utilizzando gli incorporamenti e viene utilizzata per potenziare i prodotti Google, tra cui la Ricerca Google, YouTube e Google Play. Puoi utilizzare la ricerca vettoriale per eseguire ricerche su larga scala. Quando utilizzi gli indici vettoriali con la ricerca vettoriale, puoi sfruttare tecnologie di base come l'indice di file invertito (IVF) e l'algoritmo ScaNN.
La ricerca vettoriale si basa sugli embedding. Gli incorporamenti sono vettori numerici di alta dimensione che rappresentano una determinata entità, ad esempio un testo o un file audio. I modelli di machine learning (ML) utilizzano gli embedding per codificare la semantica di queste entità in modo da facilitare il ragionamento e il confronto. Ad esempio, un'operazione comune nei modelli di clustering, classificazione e consigli è misurare la distanza tra i vettori in uno spazio di embedding per trovare gli elementi più semanticamente simili.
Questo concetto di similarità e distanza semantica in uno spazio di embedding viene dimostrato visivamente se si considera come potrebbero essere tracciati elementi diversi. Ad esempio, termini come gatto, cane e leone, che rappresentano tutti tipi di animali, sono raggruppati in questo spazio a causa delle loro caratteristiche semantiche condivise. Analogamente, termini come auto, camion e il termine più generico veicolo formerebbero un altro cluster. Come mostrato nell'immagine seguente:
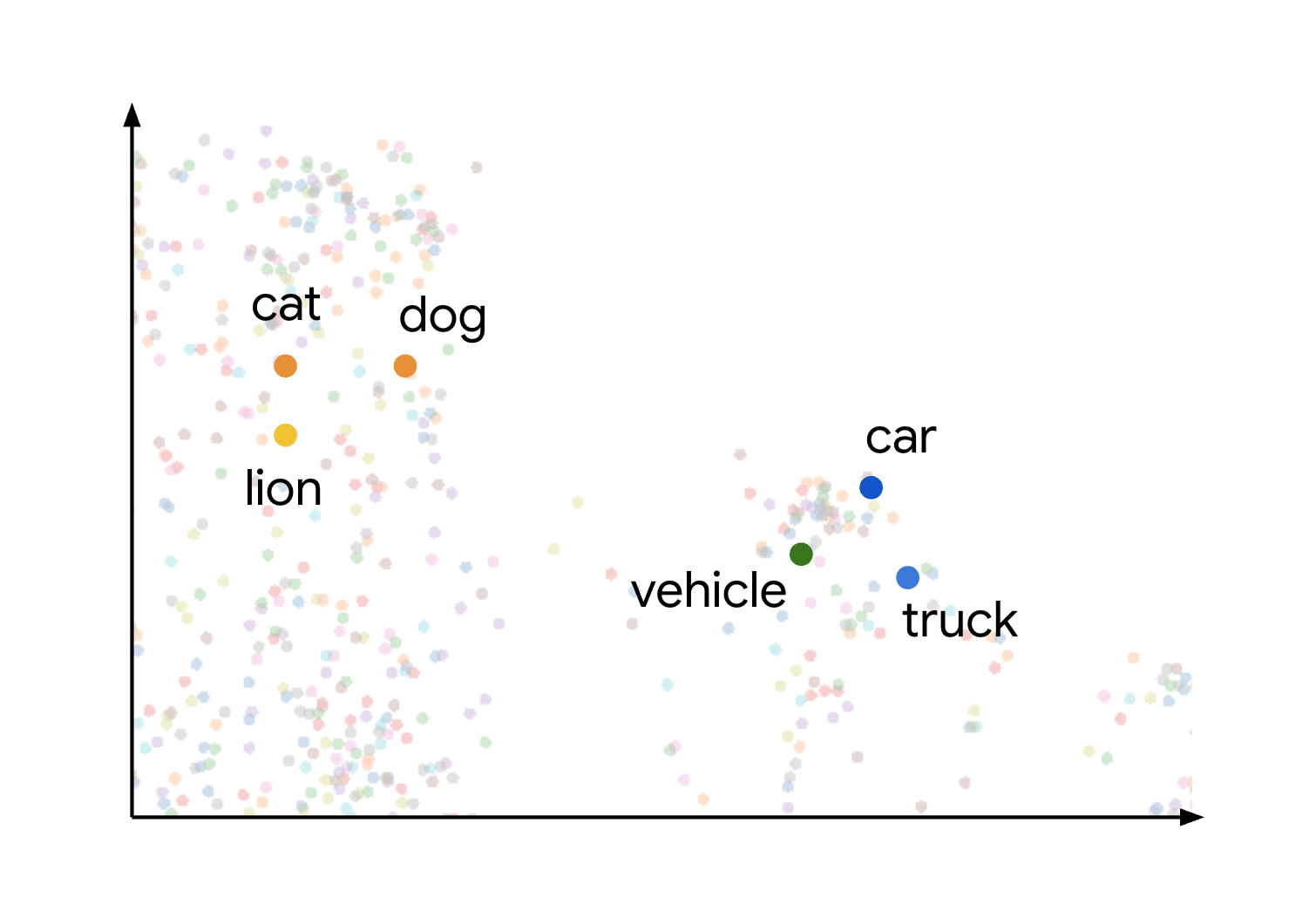
Puoi vedere che i cluster di animali e veicoli sono molto distanti tra loro. La separazione tra i gruppi illustra il principio per cui più gli oggetti sono vicini nello spazio di embedding, più sono semanticamente simili e distanze maggiori indicano una maggiore dissimmetria semantica.
BigQuery offre un'esperienza end-to-end per la generazione di embedding, l'indicizzazione dei contenuti ed l'esecuzione di ricerche vettoriali. Puoi completare ciascuna di queste attività indipendentemente o in un unico percorso. Per un tutorial che mostra come completare tutte queste attività, consulta Eseguire la ricerca semantica e la generazione basata sul recupero.
Per eseguire una ricerca vettoriale utilizzando SQL, utilizza la
funzione VECTOR_SEARCH.
Facoltativamente, puoi creare un indice di vettori utilizzando
la
istruzione CREATE VECTOR INDEX.
Quando viene utilizzato un indice vettoriale, VECTOR_SEARCH utilizza la tecnica di ricerca del vicino più prossimo approssimativo per migliorare il rendimento della ricerca vettoriale, con il compromesso della riduzione del ricovero e, di conseguenza, la restituzione di risultati più approssimativi. Senza un indice di vettori,
VECTOR_SEARCH utilizza la
ricerca bruta
per misurare la distanza per ogni record. Puoi anche scegliere di utilizzare la ricerca di brute force per ottenere risultati esatti anche quando è disponibile un indice di vettore.
Questo documento si concentra sull'approccio SQL, ma puoi anche eseguire ricerche di vettori utilizzando BigQuery DataFrames in Python. Per un blocco note che illustra l'approccio Python, consulta Creare un'applicazione di ricerca di vettori utilizzando BigQuery DataFrames.
Casi d'uso
La combinazione di generazione di embedding e ricerca vettoriale consente molti casi d'uso interessanti. Ecco alcuni possibili casi d'uso:
- Retrieval-Augmented Generation (RAG): analizza i documenti, esegui ricerche vettoriali sui contenuti e genera risposte riassunte alle domande in linguaggio naturale utilizzando i modelli Gemini, il tutto all'interno di BigQuery. Per un notebook che illustra questo scenario, consulta Creare un'applicazione di ricerca di vettori utilizzando BigQuery DataFrames.
- Consigli di prodotti sostituti o corrispondenti: migliora le applicazioni di e-commerce suggerendo alternative ai prodotti in base al comportamento dei clienti e alla somiglianza dei prodotti.
- Analisi dei log: aiuta i team a gestire in modo proattivo le anomalie nei log e accelera le indagini. Puoi anche utilizzare questa funzionalità per arricchire il contesto per gli LLM, in modo da migliorare il rilevamento delle minacce, la forensistica e i flussi di lavoro per la risoluzione dei problemi. Per un notebook che illustra questo scenario, consulta Rilevamento e indagine di anomalie nei log con embedding di testo e ricerca vettoriale di BigQuery.
- Clustering e targeting:segmenta i segmenti di pubblico con precisione. Ad esempio, una catena di ospedali potrebbe raggruppare i pazienti utilizzando note in linguaggio naturale e dati strutturati oppure un professionista del marketing potrebbe scegliere come target gli annunci in base all'intenzione di query. Per un notebook che illustra questo scenario, consulta Create-Campaign-Customer-Segmentation.
- Risoluzione delle entità e deduplica:ripulisci e consolida i dati. Ad esempio, un'azienda pubblicitaria potrebbe deduplicare i record contenenti informazioni che consentono l'identificazione personale (PII) o un'azienda immobiliare potrebbe identificare gli indirizzi postali corrispondenti.
Prezzi
La funzione VECTOR_SEARCH e l'istruzione CREATE VECTOR INDEX utilizzano
i prezzi di BigQuery Compute.
VECTOR_SEARCH: ti viene addebitato il costo della ricerca di immagini simili utilizzando i prezzi on demand o delle versioni.- On demand: ti viene addebitato il numero di byte scansionati nella tabella di base, nell'indice e nella query di ricerca.
Prezzi delle versioni: ti vengono addebitati gli slot necessari per completare il job all'interno della versione della prenotazione. I calcoli di somiglianza più grandi e complessi comportano costi maggiori.
Dichiarazione
CREATE VECTOR INDEX: non è previsto alcun addebito per l'elaborazione necessaria per creare e aggiornare gli indici di vettori, a condizione che la dimensione totale dei dati della tabella indicizzata sia inferiore al limite per organizzazione. Per supportare l'indicizzazione oltre questo limite, devi fornire la tua prenotazione per la gestione dei job di gestione dell'indice.
Lo spazio di archiviazione è un fattore da considerare anche per gli embedding e gli indici. La quantità di byte memorizzati come embedding e indici è soggetta ai costi di archiviazione attiva.
- Gli indici di vettori comportano costi di archiviazione quando sono attivi.
- Puoi trovare le dimensioni dello spazio di archiviazione dell'indice utilizzando la visualizzazione
INFORMATION_SCHEMA.VECTOR_INDEXES. Se l'indice di vettori non ha ancora raggiunto la copertura del 100%, ti verrà comunque addebitato il costo di tutto ciò che è stato indicizzato. Puoi controllare la copertura dell'indice utilizzando la visualizzazioneINFORMATION_SCHEMA.VECTOR_INDEXES.
Quote e limiti
Per ulteriori informazioni, consulta Limiti degli indici vettoriali.
Limitazioni
Le query che contengono la funzione VECTOR_SEARCH non sono accelerate da
BigQuery BI Engine.
Passaggi successivi
- Scopri di più sulla creazione di un indice di vettori.
- Scopri come eseguire una ricerca di vettori utilizzando la funzione
VECTOR_SEARCH. - Prova il tutorial Cercare gli embedding con la ricerca vettoriale per scoprire come creare un indice vettoriale e poi eseguire una ricerca vettoriale per gli embedding sia con che senza l'indice.
Prova il tutorial Eseguire la ricerca semantica e la generazione basata sul recupero per scoprire come svolgere le seguenti attività:
- Genera incorporamenti di testo.
- Crea un indice vettoriale sugli embedding.
- Esegui una ricerca vettoriale con gli embedding per cercare testo simile.
- Esegui la generazione RAG (Retrieval Augmented Generation) utilizzando i risultati di ricerca vettoriali per aumentare l'input del prompt e migliorare i risultati.
Prova il tutorial Eseguire l'analisi dei PDF in una pipeline di generazione basata sul recupero per scoprire come creare una pipeline RAG in base ai contenuti PDF analizzati.