使用调优和评估提高模型性能
本文档介绍了如何创建引用 Vertex AI gemini-1.5-flash-002 模型的 BigQuery ML 远程模型。然后,本文档还会介绍如何使用监督式调优来借助新的训练数据对模型进行调优,随后是使用 ML.EVALUATE 函数 评估函数。
调优可以帮助您应对需要自定义托管 Vertex AI 模型的场景,例如模型的预期行为难以在提示中简洁定义,或者提示无法产生一致性足够好的预期结果。监督式调优还会通过以下方式影响模型:
- 引导模型返回特定的响应样式,例如更简洁或更详细。
- 训练模型的新行为,例如以特定角色来响应提示。
- 使模型使用新信息自行更新。
在本教程中,我们的目标是让模型生成的文本样式和内容与提供的标准答案内容尽可能接近。
所需权限
如需创建连接,您需要以下 Identity and Access Management (IAM) 角色:
roles/bigquery.connectionAdmin
如需向连接的服务账号授予权限,您需要以下权限:
resourcemanager.projects.setIamPolicy
如需使用 BigQuery ML 创建模型,您需要以下 IAM 权限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
如需运行推理,您需要以下权限:
- 表的
bigquery.tables.getData权限 - 模型的
bigquery.models.getData权限 bigquery.jobs.create
- 表的
准备工作
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Connection, Vertex AI, and Compute Engine APIs.
费用
在本文档中,您将使用 Google Cloud 的以下收费组件:
- BigQuery: You incur costs for the queries that you run in BigQuery.
- BigQuery ML: You incur costs for the model that you create and the processing that you perform in BigQuery ML.
- Vertex AI: You incur costs for calls to and
supervised tuning of the
gemini-1.0-flash-002model.
您可使用价格计算器根据您的预计使用情况来估算费用。
如需了解详情,请参阅以下资源:
创建数据集
创建 BigQuery 数据集以存储您的机器学习模型:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集。
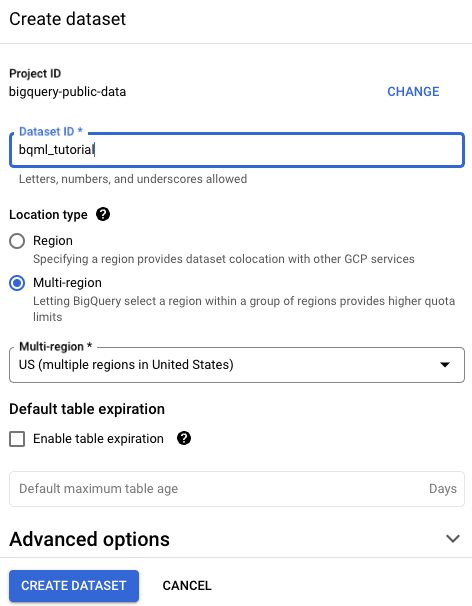
在创建数据集页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
公共数据集存储在
US多区域中。为简单起见,请将数据集存储在同一位置。保持其余默认设置不变,然后点击创建数据集。
创建连接
创建 Cloud 资源连接并获取连接的服务账号。在上一步中创建的数据集所在的位置创建连接。
从下列选项中选择一项:
控制台
转到 BigQuery 页面。
如需创建连接,请点击 添加,然后点击与外部数据源的连接。
在连接类型列表中,选择 Vertex AI 远程模型、远程函数和 BigLake(Cloud 资源)。
在连接 ID 字段中,输入连接的名称。
点击创建连接。
点击转到连接。
在连接信息窗格中,复制服务账号 ID 以在后续步骤中使用。
bq
在命令行环境中,创建连接:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
--project_id参数会替换默认项目。替换以下内容:
REGION:您的连接区域PROJECT_ID:您的 Google Cloud 项目 IDCONNECTION_ID:您的连接的 ID
当您创建连接资源时,BigQuery 会创建一个唯一的系统服务账号,并将其与该连接相关联。
问题排查:如果您收到以下连接错误,请更新 Google Cloud SDK:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
检索并复制服务账号 ID 以在后续步骤中使用:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
输出类似于以下内容:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Terraform
使用 google_bigquery_connection 资源。
如需向 BigQuery 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为客户端库设置身份验证。
以下示例会在 US 区域中创建一个名为 my_cloud_resource_connection 的 Cloud 资源连接:
如需在 Google Cloud 项目中应用 Terraform 配置,请完成以下部分中的步骤。
准备 Cloud Shell
- 启动 Cloud Shell。
-
设置要在其中应用 Terraform 配置的默认 Google Cloud 项目。
您只需为每个项目运行一次以下命令,即可在任何目录中运行它。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
如果您在 Terraform 配置文件中设置显式值,则环境变量会被替换。
准备目录
每个 Terraform 配置文件都必须有自己的目录(也称为“根模块”)。
-
在 Cloud Shell 中,创建一个目录,并在该目录中创建一个新文件。文件名必须具有
.tf扩展名,例如main.tf。在本教程中,该文件称为main.tf。mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
如果您按照教程进行操作,可以在每个部分或步骤中复制示例代码。
将示例代码复制到新创建的
main.tf中。(可选)从 GitHub 中复制代码。如果端到端解决方案包含 Terraform 代码段,则建议这样做。
- 查看和修改要应用到您的环境的示例参数。
- 保存更改。
-
初始化 Terraform。您只需为每个目录执行一次此操作。
terraform init
(可选)如需使用最新的 Google 提供程序版本,请添加
-upgrade选项:terraform init -upgrade
应用更改
-
查看配置并验证 Terraform 将创建或更新的资源是否符合您的预期:
terraform plan
根据需要更正配置。
-
通过运行以下命令并在提示符处输入
yes来应用 Terraform 配置:terraform apply
等待 Terraform 显示“应用完成!”消息。
- 打开您的 Google Cloud 项目以查看结果。在 Google Cloud 控制台的界面中找到资源,以确保 Terraform 已创建或更新它们。
向连接的服务账号授予访问权限
向您的服务账号授予 Vertex AI Service Agent 角色,以便服务账号可以访问 Vertex AI。未能授予此角色会导致错误。从下列选项中选择一项:
控制台
前往 IAM 和管理页面。
点击 授予访问权限。
系统随即会打开添加主账号对话框。
在新的主账号字段中,输入您之前复制的服务账号 ID。
点击选择角色
在过滤条件中,输入
Vertex AI Service Agent,然后选择该角色。点击保存。
gcloud
使用 gcloud projects add-iam-policy-binding 命令:
gcloud projects add-iam-policy-binding 'PROJECT_NUMBER' --member='serviceAccount:MEMBER' --role='roles/aiplatform.serviceAgent' --condition=None
请替换以下内容:
PROJECT_NUMBER:您的项目编号MEMBER:您之前复制的服务账号 ID
与您的连接关联的服务账号是 BigQuery 连接委托服务代理的实例,因此允许为其分配服务代理角色。
创建测试表
根据 Hugging Face 的公共 task955_wiki_auto_style_transfer 数据集创建训练和评估数据表。
打开 Cloud Shell。
在 Cloud Shell 中,运行以下命令以创建测试和评估数据表:
python3 -m pip install pandas pyarrow fsspec huggingface_hub python3 -c "import pandas as pd; df_train = pd.read_parquet('hf://datasets/Lots-of-LoRAs/task955_wiki_auto_style_transfer/data/train-00000-of-00001.parquet').drop('id', axis=1); df_train['output'] = [x[0] for x in df_train['output']]; df_train.to_json('wiki_auto_style_transfer_train.jsonl', orient='records', lines=True);" python3 -c "import pandas as pd; df_valid = pd.read_parquet('hf://datasets/Lots-of-LoRAs/task955_wiki_auto_style_transfer/data/valid-00000-of-00001.parquet').drop('id', axis=1); df_valid['output'] = [x[0] for x in df_valid['output']]; df_valid.to_json('wiki_auto_style_transfer_valid.jsonl', orient='records', lines=True);" bq rm -t bqml_tutorial.wiki_auto_style_transfer_train bq rm -t bqml_tutorial.wiki_auto_style_transfer_valid bq load --source_format=NEWLINE_DELIMITED_JSON bqml_tutorial.wiki_auto_style_transfer_train wiki_auto_style_transfer_train.jsonl input:STRING,output:STRING bq load --source_format=NEWLINE_DELIMITED_JSON bqml_tutorial.wiki_auto_style_transfer_valid wiki_auto_style_transfer_valid.jsonl input:STRING,output:STRING
创建基准模型
基于 Vertex AI gemini-1.0-flash-002 模型创建远程模型。
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,运行以下语句以创建远程模型:
CREATE OR REPLACE MODEL `bqml_tutorial.gemini_baseline` REMOTE WITH CONNECTION `LOCATION.CONNECTION_ID` OPTIONS (ENDPOINT ='gemini-1.5-flash-002');
替换以下内容:
LOCATION:连接位置。CONNECTION_ID:BigQuery 连接的 ID。当您在 Google Cloud 控制台中查看连接详情时,
CONNECTION_ID是连接 ID 中显示的完全限定连接 ID 的最后一部分中的值,例如projects/myproject/locations/connection_location/connections/myconnection。
查询需要几秒钟才能完成,之后
gemini_baseline模型会显示在探索器窗格的bqml_tutorial数据集中。由于查询使用CREATE MODEL语句来创建模型,因此没有查询结果。
检查基准模型性能
使用远程模型运行 ML.GENERATE_TEXT 函数,以查看其在不进行任何调优的情况下处理评估数据的表现。
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,运行以下语句:
SELECT ml_generate_text_llm_result, ground_truth FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.gemini_baseline`, ( SELECT input AS prompt, output AS ground_truth FROM `bqml_tutorial.wiki_auto_style_transfer_valid` LIMIT 10 ), STRUCT(TRUE AS flatten_json_output));
如果您检查输出数据并比较
ml_generate_text_llm_result和ground_truth值,则会发现虽然基准模型生成的文本准确反映了标准答案内容中提供的事实,但文本风格却截然不同。
评估基准模型
如需对模型性能执行更详细的评估,请使用 ML.EVALUATE 函数。此函数会计算用于衡量生成文本准确性和质量的模型指标,以查看模型的响应与理想响应的对比情况。
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,运行以下语句:
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.gemini_baseline`, ( SELECT input AS input_text, output AS output_text FROM `bqml_tutorial.wiki_auto_style_transfer_valid` ), STRUCT('text_generation' AS task_type));
输出类似于以下内容:
+---------------------+---------------------+-------------------------------------------+--------------------------------------------+
| bleu4_score | rouge-l_precision | rouge-l_recall | rouge-l_f1_score | evaluation_status |
+---------------------+---------------------+---------------------+---------------------+--------------------------------------------+
| 0.15289758194680161 | 0.24925921915413246 | 0.44622484204944518 | 0.30851122211104348 | { |
| | | | | "num_successful_rows": 176, |
| | | | | "num_total_rows": 176 |
| | | | | } |
+---------------------+---------------------+ --------------------+---------------------+--------------------------------------------+
您可以看到,根据评估指标,基准模型的表现不错,但生成的文本与标准答案的相似度较低。这表明有必要执行监督式调优,以了解是否可提升此用例的模型性能。
创建已调参模型
创建一个与创建模型中所创建远程模型非常相似的远程模型,但这次指定 AS SELECT 子句,提供训练数据以对模型进行调优。
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,运行以下语句以创建远程模型:
CREATE OR REPLACE MODEL `bqml_tutorial.gemini_tuned` REMOTE WITH CONNECTION `LOCATION.CONNECTION_ID` OPTIONS ( endpoint = 'gemini-1.5-flash-002', max_iterations = 500, data_split_method = 'no_split') AS SELECT input AS prompt, output AS label FROM `bqml_tutorial.wiki_auto_style_transfer_train`;
替换以下内容:
LOCATION:连接位置。CONNECTION_ID:BigQuery 连接的 ID。当您在 Google Cloud 控制台中查看连接详情时,
CONNECTION_ID是连接 ID 中显示的完全限定连接 ID 的最后一部分中的值,例如projects/myproject/locations/connection_location/connections/myconnection。
查询需要几分钟才能完成,之后
gemini_tuned模型会显示在探索器窗格的bqml_tutorial数据集中。由于查询使用CREATE MODEL语句来创建模型,因此没有查询结果。
检查调优后的模型性能
运行 ML.GENERATE_TEXT 函数以查看调优后模型在评估数据上的表现。
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,运行以下语句:
SELECT ml_generate_text_llm_result, ground_truth FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.gemini_tuned`, ( SELECT input AS prompt, output AS ground_truth FROM `bqml_tutorial.wiki_auto_style_transfer_valid` LIMIT 10 ), STRUCT(TRUE AS flatten_json_output));
如果您检查输出数据,则会发现调优后的模型生成的文本在风格上与标准答案内容更为相似。
评估调优后的模型
使用 ML.EVALUATE 函数查看经过调优的模型的响应与理想响应的对比情况。
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,运行以下语句:
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.gemini_tuned`, ( SELECT input AS prompt, output AS label FROM `bqml_tutorial.wiki_auto_style_transfer_valid` ), STRUCT('text_generation' AS task_type));
输出类似于以下内容:
+---------------------+---------------------+-------------------------------------------+--------------------------------------------+
| bleu4_score | rouge-l_precision | rouge-l_recall | rouge-l_f1_score | evaluation_status |
+---------------------+---------------------+---------------------+---------------------+--------------------------------------------+
| 0.19391708685890585 | 0.34170970869469058 | 0.46793189219384496 | 0.368190192211538 | { |
| | | | | "num_successful_rows": 176, |
| | | | | "num_total_rows": 176 |
| | | | | } |
+---------------------+---------------------+ --------------------+---------------------+--------------------------------------------+
您可以看到,虽然训练数据集仅使用 1,408 个样本,但是性能显著提高,因为评估指标较高。
清理
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.