Contrôler l'accès aux ressources avec IAM
Ce document explique comment afficher, accorder et révoquer les contrôles d'accès pour les ensembles de données BigQuery et pour les ressources qu'ils contiennent : tables, vues et routines. Bien que les modèles soient également des ressources au niveau de l'ensemble de données, vous ne pouvez pas accorder l'accès à des modèles individuels à l'aide de rôles IAM.
Vous pouvez accorder l'accès aux ressources Google Cloud à l'aide de stratégies d'autorisation, également appelées stratégies IAM (Identity and Access Management), qui sont associées aux ressources. Vous ne pouvez associer qu'une seule stratégie d'autorisation à chaque ressource. La stratégie d'autorisation contrôle l'accès à la ressource elle-même, ainsi qu'à tous ses descendants qui héritent de la stratégie d'autorisation.
Pour en savoir plus sur les stratégies d'autorisation, consultez la section Structure des stratégies dans la documentation IAM.
Dans ce document, nous partons du principe que vous connaissez Identity and Access Management (IAM) dans Google Cloud.
Limites
- Les listes de contrôle d'accès (LCA) des routines ne sont pas incluses dans les routines répliquées.
- Les routines dans les ensembles de données externes ou associés ne sont pas compatibles avec les contrôles d'accès.
- Les tables des ensembles de données externes ou associés ne sont pas compatibles avec les contrôles d'accès.
- Il n'est pas possible de définir des contrôles d'accès aux routines avec Terraform.
- Vous ne pouvez pas définir de contrôles d'accès de routine avec le SDK Google Cloud.
- Il n'est pas possible de définir des contrôles d'accès de routine à l'aide du langage de contrôle de données (LCD) BigQuery.
- Data Catalog n'est pas compatible avec les contrôles d'accès de routine. Si un utilisateur a accordé un accès conditionnel au niveau des routines, il ne verra pas ses routines dans le panneau latéral BigQuery. Pour contourner ce problème, accordez plutôt un accès au niveau de l'ensemble de données.
- La vue
INFORMATION_SCHEMA.OBJECT_PRIVILEGESn'affiche pas les contrôles d'accès pour les routines.
Avant de commencer
Attribuez aux utilisateurs des rôles IAM (Identity and Access Management) incluant les autorisations nécessaires pour effectuer l'ensemble des tâches du présent document.
Rôles requis
Pour obtenir les autorisations nécessaires pour modifier les stratégies IAM associées aux ressources, demandez à votre administrateur de vous accorder le rôle IAM Propriétaire de données BigQuery (roles/bigquery.dataOwner) sur le projet.
Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.
Ce rôle prédéfini contient les autorisations requises pour modifier les stratégies IAM des ressources. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour modifier les stratégies IAM pour les ressources :
-
Pour obtenir la stratégie d'accès d'un ensemble de données :
bigquery.datasets.get -
Pour définir la stratégie d'accès d'un ensemble de données :
bigquery.datasets.update -
Pour obtenir la stratégie d'accès d'un ensemble de données (consoleGoogle Cloud uniquement) :
bigquery.datasets.getIamPolicy -
Pour définir la règle d'accès d'un ensemble de données (console uniquement), procédez comme suit :
bigquery.datasets.setIamPolicy -
Pour obtenir la stratégie d'une table ou d'une vue :
bigquery.tables.getIamPolicy -
Pour définir la stratégie d'une table ou d'une vue :
bigquery.tables.setIamPolicy -
Pour obtenir la stratégie d'accès d'une routine :
bigquery.routines.getIamPolicy -
Pour définir la stratégie d'accès d'une routine :
bigquery.routines.setIamPolicy -
Pour créer l'outil bq ou des tâches SQL BigQuery (facultatif), procédez comme suit :
bigquery.jobs.create
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Utiliser les contrôles d'accès aux ensembles de données
Vous pouvez autoriser l'accès à un ensemble de données en attribuant à un compte principal IAM un rôle prédéfini ou personnalisé qui détermine ce que le compte principal peut faire avec l'ensemble de données. On parle alors d'association d'une règle d'autorisation à une ressource. Une fois l'accès accordé, vous pouvez consulter les contrôles d'accès de l'ensemble de données et révoquer l'accès à l'ensemble de données.
Accorder l'accès à un ensemble de données
Vous ne pouvez pas accorder l'accès à un ensemble de données lorsque vous le créez à l'aide de l'UI Web BigQuery ou de l'outil de ligne de commande bq. Vous devez d'abord créer l'ensemble de données, puis accorder l'accès à cet ensemble.
L'API vous permet d'accorder l'accès lors de la création d'un ensemble de données en appelant la méthode datasets.insert avec une ressource d'ensemble de données définie.
Un projet est la ressource parente d'un ensemble de données, et un ensemble de données est la ressource parente des tables et des vues, des routines et des modèles. Lorsque vous attribuez un rôle au niveau du projet, le rôle et ses autorisations sont hérités par l'ensemble de données et par les ressources de l'ensemble de données. De même, lorsque vous accordez un rôle au niveau de l'ensemble de données, le rôle et ses autorisations sont hérités par les ressources de l'ensemble de données.
Vous pouvez autoriser l'accès à un ensemble de données en accordant une autorisation de rôle IAM pour accéder à l'ensemble de données ou en accordant un accès conditionnel à l'aide d'une condition IAM. Pour en savoir plus sur l'octroi d'un accès conditionnel, consultez Contrôler l'accès avec les conditions IAM.
Pour accorder à un rôle IAM l'accès à un ensemble de données sans utiliser de conditions, sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le volet Explorateur, développez votre projet et sélectionnez un ensemble de données à partager.
Cliquez sur Partage > Autorisations.
Cliquez sur Ajouter un compte principal.
Dans le champ Nouveaux comptes principaux, saisissez un compte principal.
Dans la liste Sélectionner un rôle, sélectionnez un rôle prédéfini ou personnalisé.
Cliquez sur Enregistrer.
Pour revenir aux informations sur l'ensemble de données, cliquez sur Fermer.
SQL
Pour autoriser les comptes principaux à accéder aux ensembles de données, utilisez l'instruction LDC GRANT :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
GRANT `ROLE_LIST` ON SCHEMA RESOURCE_NAME TO "USER_LIST"
Remplacez les éléments suivants :
ROLE_LIST: rôle ou liste de rôles (séparés par des virgules) que vous souhaitez attribuer.RESOURCE_NAME: nom de l'ensemble de données auquel vous accordez l'accès.USER_LIST: liste d'utilisateurs (séparés par une virgule) auxquels le rôle est attribué.Pour obtenir la liste des formats valides, consultez
user_list.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
L'exemple suivant attribue le rôle de lecteur de données BigQuery à myDataset :
GRANT `roles/bigquery.dataViewer`
ON SCHEMA `myProject`.myDataset
TO "user:user@example.com", "user:user2@example.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Pour écrire les informations existantes sur l'ensemble de données (y compris les contrôles d'accès) dans un fichier JSON, utilisez la commande
bq show:bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre projet.
- DATASET : par le nom de votre ensemble de données
- PATH_TO_FILE : chemin d'accès au fichier JSON sur votre ordinateur local.
Apportez vos modifications à la section
accessdu fichier JSON. Vous pouvez ajouter l'une des entréesspecialGroup:projectOwners,projectWriters,projectReadersetallAuthenticatedUsers. Vous pouvez également ajouter l'un des éléments suivants :userByEmail,groupByEmailetdomain.Par exemple, la section
accessdu fichier JSON d'un ensemble de données ressemblerait à ceci :{ "access": [ { "role": "READER", "specialGroup": "projectReaders" }, { "role": "WRITER", "specialGroup": "projectWriters" }, { "role": "OWNER", "specialGroup": "projectOwners" }, { "role": "READER", "specialGroup": "allAuthenticatedUsers" }, { "role": "READER", "domain": "domain_name" }, { "role": "WRITER", "userByEmail": "user_email" }, { "role": "READER", "groupByEmail": "group_email" } ], ... }
Une fois vos modifications terminées, exécutez la commande
bq updateet incluez le fichier JSON à l'aide de l'option--source. Si l'ensemble de données se trouve dans un projet autre que celui par défaut, ajoutez l'ID de ce projet au nom de l'ensemble de données, en respectant le format suivant :PROJECT_ID:DATASET.bq update
--source PATH_TO_FILE
PROJECT_ID:DATASETPour vérifier les modifications apportées aux contrôles d'accès, saisissez à nouveau la commande
bq showsans écrire les informations dans un fichier :bq show --format=prettyjson PROJECT_ID:DATASET
- Lancez Cloud Shell.
-
Définissez le projet Google Cloud par défaut dans lequel vous souhaitez appliquer vos configurations Terraform.
Vous n'avez besoin d'exécuter cette commande qu'une seule fois par projet et vous pouvez l'exécuter dans n'importe quel répertoire.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Les variables d'environnement sont remplacées si vous définissez des valeurs explicites dans le fichier de configuration Terraform.
-
Dans Cloud Shell, créez un répertoire et un nouveau fichier dans ce répertoire. Le nom du fichier doit comporter l'extension
.tf, par exemplemain.tf. Dans ce tutoriel, le fichier est appelémain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Si vous suivez un tutoriel, vous pouvez copier l'exemple de code dans chaque section ou étape.
Copiez l'exemple de code dans le fichier
main.tfque vous venez de créer.Vous pouvez également copier le code depuis GitHub. Cela est recommandé lorsque l'extrait Terraform fait partie d'une solution de bout en bout.
- Examinez et modifiez les exemples de paramètres à appliquer à votre environnement.
- Enregistrez les modifications.
-
Initialisez Terraform. Cette opération n'est à effectuer qu'une seule fois par répertoire.
terraform init
Vous pouvez également utiliser la dernière version du fournisseur Google en incluant l'option
-upgrade:terraform init -upgrade
-
Examinez la configuration et vérifiez que les ressources que Terraform va créer ou mettre à jour correspondent à vos attentes :
terraform plan
Corrigez les modifications de la configuration si nécessaire.
-
Appliquez la configuration Terraform en exécutant la commande suivante et en saisissant
yeslorsque vous y êtes invité :terraform apply
Attendez que Terraform affiche le message "Apply completed!" (Application terminée).
- Ouvrez votre projet Google Cloud pour afficher les résultats. Dans la console Google Cloud , accédez à vos ressources dans l'interface utilisateur pour vous assurer que Terraform les a créées ou mises à jour.
Terraform
Utilisez les ressources google_bigquery_dataset_iam pour mettre à jour l'accès à un ensemble de données.
Définir la stratégie de contrôle d'accès pour un ensemble de données
L'exemple suivant montre comment utiliser la ressource google_bigquery_dataset_iam_policy pour définir la stratégie IAM de l'ensemble de données mydataset. Cette opération remplace toute règle existante déjà associée à l'ensemble de données :
# This file sets the IAM policy for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". data "google_iam_policy" "iam_policy" { binding { role = "roles/bigquery.admin" members = [ "user:user@example.com", ] } binding { role = "roles/bigquery.dataOwner" members = [ "group:data.admin@example.com", ] } binding { role = "roles/bigquery.dataEditor" members = [ "serviceAccount:bqcx-1234567891011-12a3@gcp-sa-bigquery-condel.iam.gserviceaccount.com", ] } } resource "google_bigquery_dataset_iam_policy" "dataset_iam_policy" { dataset_id = google_bigquery_dataset.default.dataset_id policy_data = data.google_iam_policy.iam_policy.policy_data }
Définir l'appartenance à un rôle pour un ensemble de données
L'exemple suivant montre comment utiliser la ressource google_bigquery_dataset_iam_binding pour définir l'appartenance à un rôle donné pour l'ensemble de données mydataset. Cette opération remplace toute appartenance existante à ce rôle.
Les autres rôles de la stratégie IAM pour l'ensemble de données sont conservés :
# This file sets membership in an IAM role for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". resource "google_bigquery_dataset_iam_binding" "dataset_iam_binding" { dataset_id = google_bigquery_dataset.default.dataset_id role = "roles/bigquery.jobUser" members = [ "user:user@example.com", "group:group@example.com" ] }
Définir l'appartenance à un rôle pour un seul compte principal
L'exemple suivant montre comment utiliser la ressource google_bigquery_dataset_iam_member pour mettre à jour la stratégie IAM de l'ensemble de données mydataset afin d'accorder un rôle à un compte principal. La mise à jour de cette stratégie IAM n'a aucune incidence sur l'accès des autres comptes principaux qui ont reçu ce rôle pour l'ensemble de données.
# This file adds a member to an IAM role for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". resource "google_bigquery_dataset_iam_member" "dataset_iam_member" { dataset_id = google_bigquery_dataset.default.dataset_id role = "roles/bigquery.user" member = "user:user@example.com" }
Pour appliquer votre configuration Terraform dans un projet Google Cloud , suivez les procédures des sections suivantes.
Préparer Cloud Shell
Préparer le répertoire
Chaque fichier de configuration Terraform doit avoir son propre répertoire (également appelé module racine).
Appliquer les modifications
API
Pour appliquer des contrôles d'accès lors de la création d'un ensemble de données, appelez la méthode datasets.insert en spécifiant une ressource d'ensemble de données.
Pour mettre à jour vos contrôles d'accès, appelez la méthode datasets.patch et utilisez la propriété access de la ressource Dataset.
Comme la méthode datasets.update remplace la ressource d'ensemble de données dans son intégralité, il est préférable d'utiliser la méthode datasets.patch.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Définissez la nouvelle liste d'accès en ajoutant la nouvelle entrée à la liste existante avec le typeDatasetMetadataToUpdate. Appelez ensuite la fonction dataset.Update() pour mettre à jour la propriété.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Définissez la nouvelle liste d'accès en ajoutant la nouvelle entrée à la liste existante à l'aide de la méthode Dataset#metadata. Appelez ensuite la fonction Dataset#setMetadata() pour mettre à jour la propriété.Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Définissez la propriétédataset.access_entries
avec les contrôles d'accès pour un ensemble de données. Appelez ensuite la fonction client.update_dataset() pour mettre à jour la propriété.
Rôles prédéfinis qui accordent l'accès aux ensembles de données
Vous pouvez accorder l'accès à un ensemble de données aux rôles IAM prédéfinis suivants.
| Rôle | Description |
|---|---|
Propriétaire de données BigQuery
(roles/bigquery.dataOwner) |
Lorsqu'il est attribué à un ensemble de données, ce rôle accorde les autorisations suivantes :
|
Éditeur de données BigQuery
(roles/bigquery.dataEditor) |
Lorsqu'il est attribué à un ensemble de données, ce rôle accorde les autorisations suivantes :
|
Lecteur de données BigQuery
(roles/bigquery.dataViewer) |
Lorsqu'il est attribué à un ensemble de données, ce rôle accorde les autorisations suivantes :
|
Lecteur de métadonnées BigQuery
(roles/bigquery.metadataViewer) |
Lorsqu'il est attribué à un ensemble de données, ce rôle accorde les autorisations suivantes :
|
Dataset permissions
La plupart des autorisations qui commencent par bigquery.datasets s'appliquent au niveau de l'ensemble de données.
bigquery.datasets.create ne le fait pas. Pour créer des ensembles de données, l'autorisation bigquery.datasets.create doit être accordée à un rôle dans le conteneur parent (le projet).
Le tableau suivant liste toutes les autorisations pour les ensembles de données et la ressource de niveau le plus bas à laquelle l'autorisation peut être appliquée.
| Autorisation | Ressource | Action |
|---|---|---|
bigquery.datasets.create |
Projet | Créer des ensembles de données dans le projet |
bigquery.datasets.get |
Ensemble de données | Obtenez les métadonnées et les contrôles d'accès pour l'ensemble de données. L'affichage des autorisations dans la console nécessite également l'autorisation bigquery.datasets.getIamPolicy. |
bigquery.datasets.getIamPolicy |
Ensemble de données | Requis par la console pour accorder à l'utilisateur l'autorisation d'obtenir les contrôles d'accès d'un ensemble de données. Ne s'ouvre pas. La console nécessite également l'autorisation bigquery.datasets.get pour afficher l'ensemble de données. |
bigquery.datasets.update |
Ensemble de données | Mettez à jour les métadonnées et les contrôles d'accès de l'ensemble de données. La mise à jour des contrôles d'accès dans la console nécessite également l'autorisation bigquery.datasets.setIamPolicy.
|
bigquery.datasets.setIamPolicy |
Ensemble de données | Requis par la console pour autoriser l'utilisateur à définir les contrôles d'accès d'un ensemble de données. Ne s'ouvre pas. La console nécessite également l'autorisation bigquery.datasets.update pour mettre à jour l'ensemble de données. |
bigquery.datasets.delete |
Ensemble de données | Supprimer un ensemble de données |
bigquery.datasets.createTagBinding |
Ensemble de données | Associez des tags à l'ensemble de données. |
bigquery.datasets.deleteTagBinding |
Ensemble de données | Dissociez les tags de l'ensemble de données. |
bigquery.datasets.listTagBindings |
Ensemble de données | Répertorier les tags de l'ensemble de données. |
bigquery.datasets.listEffectiveTags |
Ensemble de données | Lister les tags effectifs (appliqués et hérités) pour l'ensemble de données. |
bigquery.datasets.link |
Ensemble de données | Créez un ensemble de données associé. |
bigquery.datasets.listSharedDatasetUsage |
Projet | Répertorie les statistiques d'utilisation des ensembles de données partagés auxquels vous avez accès dans le projet. Cette autorisation est requise pour interroger la vue INFORMATION_SCHEMA.SHARED_DATASET_USAGE. |
Afficher les contrôles d'accès pour un ensemble de données
Pour afficher les contrôles d'accès définis de manière explicite pour un ensemble de données, choisissez l'une des options suivantes. Pour afficher les rôles hérités d'un ensemble de données, utilisez l'interface utilisateur Web de BigQuery.
Console
Accédez à la page BigQuery.
Dans le volet Explorateur, développez votre projet et sélectionnez un ensemble de données.
Cliquez sur Partage > Autorisations.
Les contrôles d'accès de l'ensemble de données s'affichent dans le volet Autorisations de l'ensemble de données.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Pour obtenir une stratégie existante et l'exporter dans un fichier local au format JSON, utilisez la commande
bq showdans Cloud Shell :bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre projet.
- DATASET : par le nom de votre ensemble de données
- PATH_TO_FILE : chemin d'accès au fichier JSON sur votre ordinateur local
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
SELECT COLUMN_LIST FROM PROJECT_ID.`region-REGION`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_name = "DATASET";
Remplacez les éléments suivants :
- COLUMN_LIST : liste de colonnes séparées par des virgules de la vue
INFORMATION_SCHEMA.OBJECT_PRIVILEGES - PROJECT_ID : ID de votre projet.
- REGION : qualificatif de région
- DATASET : nom d'un ensemble de données dans votre projet
- COLUMN_LIST : liste de colonnes séparées par des virgules de la vue
Cliquez sur Exécuter.
SQL
Interrogez la vue INFORMATION_SCHEMA.OBJECT_PRIVILEGES.
Les requêtes de récupération des contrôles d'accès pour un ensemble de données doivent spécifier l'élément object_name.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Exemple :
Cette requête permet d'obtenir les contrôles d'accès pour mydataset.
SELECT object_name, privilege_type, grantee FROM my_project.`region-us`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_name = "mydataset";
Le résultat doit se présenter sous la forme suivante :
+------------------+-----------------------------+-------------------------+
| object_name | privilege_type | grantee |
+------------------+-----------------------------+-------------------------+
| mydataset | roles/bigquery.dataOwner | projectOwner:myproject |
| mydataset | roles/bigquery.dataViwer | user:user@example.com |
+------------------+-----------------------------+-------------------------+
API
Pour afficher les contrôles d'accès d'un ensemble de données, appelez la méthode datasets.get avec une ressource dataset définie.
Les contrôles d'accès s'affichent dans la propriété access de la ressource dataset.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Appelez la fonctionclient.Dataset().Metadata(). La règle d'accès est disponible dans la propriété Access.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Récupérez les métadonnées de l'ensemble de données à l'aide de la fonctionDataset#getMetadata().
La règle d'accès est disponible dans la propriété "access" de l'objet de métadonnées résultant.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Appelez la fonctionclient.get_dataset().
La règle d'accès est disponible dans la propriété dataset.access_entries.
Révoquer l'accès à un ensemble de données
Pour révoquer l'accès à un ensemble de données, sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le panneau Explorateur, développez votre projet et sélectionnez un ensemble de données.
Dans le panneau des détails, cliquez sur Partage > Autorisations.
Dans la boîte de dialogue Autorisations pour les ensembles de données, développez le compte principal dont vous souhaitez révoquer l'accès.
Cliquez sur Supprimer le compte principal.
Dans la boîte de dialogue Supprimer le rôle pour le compte principal ?, cliquez sur Supprimer.
Pour revenir aux détails de l'ensemble de données, cliquez sur Fermer.
SQL
Pour supprimer l'accès d'un compte principal à un ensemble de données, utilisez l'instruction LCD REVOKE :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
REVOKE `ROLE_LIST` ON SCHEMA RESOURCE_NAME FROM "USER_LIST"
Remplacez les éléments suivants :
ROLE_LIST: rôle ou liste de rôles (séparés par une virgule) que vous souhaitez révoquer.RESOURCE_NAME: nom de la ressource sur laquelle vous souhaitez révoquer l'autorisation.USER_LIST: liste des utilisateurs (séparés par une virgule) dont les rôles seront révoqués.Pour obtenir la liste des formats valides, consultez
user_list.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
L'exemple suivant révoque le rôle Propriétaire de données BigQuery de myDataset :
REVOKE `roles/bigquery.dataOwner`
ON SCHEMA `myProject`.myDataset
FROM "group:group@example.com", "serviceAccount:user@test-project.iam.gserviceaccount.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Pour écrire les informations existantes sur l'ensemble de données (y compris les contrôles d'accès) dans un fichier JSON, utilisez la commande
bq show:bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre projet.
- DATASET : par le nom de votre ensemble de données
- PATH_TO_FILE : chemin d'accès au fichier JSON sur votre ordinateur local.
Apportez vos modifications à la section
accessdu fichier JSON. Vous pouvez supprimer n'importe quelle entréespecialGroup:projectOwners,projectWriters,projectReadersetallAuthenticatedUsers. Vous pouvez également supprimer l'un des éléments suivants :userByEmail,groupByEmailetdomain.Par exemple, la section
accessdu fichier JSON d'un ensemble de données ressemblerait à ceci :{ "access": [ { "role": "READER", "specialGroup": "projectReaders" }, { "role": "WRITER", "specialGroup": "projectWriters" }, { "role": "OWNER", "specialGroup": "projectOwners" }, { "role": "READER", "specialGroup": "allAuthenticatedUsers" }, { "role": "READER", "domain": "domain_name" }, { "role": "WRITER", "userByEmail": "user_email" }, { "role": "READER", "groupByEmail": "group_email" } ], ... }
Une fois vos modifications terminées, exécutez la commande
bq updateet incluez le fichier JSON à l'aide de l'option--source. Si l'ensemble de données se trouve dans un projet autre que celui par défaut, ajoutez l'ID de ce projet au nom de l'ensemble de données, en respectant le format suivant :PROJECT_ID:DATASET.bq update
--source PATH_TO_FILE
PROJECT_ID:DATASETPour vérifier les modifications apportées contrôle des accès, saisissez la commande
showsans écrire les informations dans un fichier :bq show --format=prettyjson PROJECT_ID:DATASET
API
Appelez la méthode datasets.patch et utilisez la propriété access de la ressource Dataset pour mettre à jour les contrôles d'accès.
Comme la méthode datasets.update remplace la ressource d'ensemble de données dans son intégralité, il est préférable d'utiliser la méthode datasets.patch.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Définissez la nouvelle liste d'accès en supprimant l'entrée de la liste existante avec le typeDatasetMetadataToUpdate. Appelez ensuite la fonction dataset.Update() pour mettre à jour la propriété.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Mettez à jour la liste d'accès à l'ensemble de données en supprimant l'entrée spécifiée de la liste existante à l'aide de la méthodeDataset#get() pour récupérer les métadonnées actuelles. Modifiez la propriété d'accès pour exclure l'entité souhaitée, puis appelez la fonction Dataset#setMetadata() pour appliquer la liste d'accès mise à jour.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Définissez la propriétédataset.access_entries avec les contrôles d'accès pour un ensemble de données. Appelez ensuite la fonction client.update_dataset() pour mettre à jour la propriété.
Utiliser les contrôles d'accès aux tables et aux vues
Les vues sont traitées comme des ressources de table dans BigQuery. Vous pouvez autoriser l'accès à une table ou une vue en attribuant à un compte principal IAM un rôle prédéfini ou personnalisé qui détermine ce que le compte principal peut faire avec la table ou la vue. On parle alors d'association d'une règle d'autorisation à une ressource. Une fois l'accès accordé, vous pouvez afficher les contrôles d'accès à la table ou à la vue, et révoquer l'accès à la table ou à la vue.
Autoriser l'accès à une table ou à une vue
Pour un contrôle d'accès précis, vous pouvez accorder un rôle IAM prédéfini ou personnalisé sur une table ou une vue spécifique. La table ou la vue hérite également des contrôles d'accès spécifiés au niveau de l'ensemble de données et à un niveau supérieur. Par exemple, si vous accordez à un compte principal le rôle de propriétaire de données BigQuery sur un ensemble de données, ce compte principal dispose également des autorisations de propriétaire de données BigQuery sur les tables et les vues de l'ensemble de données.
Pour accorder l'accès à une table ou une vue, sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le volet Explorateur, développez votre projet et sélectionnez une table ou une vue à partager.
Cliquez sur Partager.
Cliquez sur Ajouter un compte principal.
Dans le champ Nouveaux comptes principaux, saisissez un compte principal.
Dans la liste Sélectionner un rôle, sélectionnez un rôle prédéfini ou personnalisé.
Cliquez sur Enregistrer.
Pour revenir aux détails de la table ou de la vue, cliquez sur Fermer.
SQL
Pour accorder aux comptes principaux l'accès aux tables ou aux vues, utilisez l'instruction LCD GRANT :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
GRANT `ROLE_LIST` ON RESOURCE_TYPE RESOURCE_NAME TO "USER_LIST"
Remplacez les éléments suivants :
ROLE_LIST: rôle ou liste de rôles (séparés par des virgules) que vous souhaitez attribuer.RESOURCE_TYPE: type de ressource auquel le rôle est appliqué.Les valeurs autorisées incluent :
TABLE,VIEW,MATERIALIZED VIEWetEXTERNAL TABLE.RESOURCE_NAME: nom de la ressource sur laquelle vous souhaitez accorder l'autorisationUSER_LIST: liste d'utilisateurs (séparés par une virgule) auxquels le rôle est attribué.Pour obtenir la liste des formats valides, consultez la page
user_list.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
L'exemple suivant accorde le rôle Lecteur de données BigQuery sur myTable :
GRANT `roles/bigquery.dataViewer`
ON TABLE `myProject`.myDataset.myTable
TO "user:user@example.com", "user:user2@example.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Pour accorder l'accès à une table ou à une vue, utilisez la commande
bq add-iam-policy-binding:bq add-iam-policy-binding --member=MEMBER_TYPE:MEMBER --role=ROLE --table=true RESOURCE
Remplacez les éléments suivants :
- MEMBER_TYPE : type de membre, tel que
user,group,serviceAccountoudomain. - MEMBER : adresse e-mail ou nom de domaine du membre.
- ROLE : rôle que vous souhaitez attribuer au membre.
- RESOURCE : nom de la table ou de la vue dont vous souhaitez mettre à jour la stratégie.
- MEMBER_TYPE : type de membre, tel que
- Lancez Cloud Shell.
-
Définissez le projet Google Cloud par défaut dans lequel vous souhaitez appliquer vos configurations Terraform.
Vous n'avez besoin d'exécuter cette commande qu'une seule fois par projet et vous pouvez l'exécuter dans n'importe quel répertoire.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Les variables d'environnement sont remplacées si vous définissez des valeurs explicites dans le fichier de configuration Terraform.
-
Dans Cloud Shell, créez un répertoire et un nouveau fichier dans ce répertoire. Le nom du fichier doit comporter l'extension
.tf, par exemplemain.tf. Dans ce tutoriel, le fichier est appelémain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Si vous suivez un tutoriel, vous pouvez copier l'exemple de code dans chaque section ou étape.
Copiez l'exemple de code dans le fichier
main.tfque vous venez de créer.Vous pouvez également copier le code depuis GitHub. Cela est recommandé lorsque l'extrait Terraform fait partie d'une solution de bout en bout.
- Examinez et modifiez les exemples de paramètres à appliquer à votre environnement.
- Enregistrez les modifications.
-
Initialisez Terraform. Cette opération n'est à effectuer qu'une seule fois par répertoire.
terraform init
Vous pouvez également utiliser la dernière version du fournisseur Google en incluant l'option
-upgrade:terraform init -upgrade
-
Examinez la configuration et vérifiez que les ressources que Terraform va créer ou mettre à jour correspondent à vos attentes :
terraform plan
Corrigez les modifications de la configuration si nécessaire.
-
Appliquez la configuration Terraform en exécutant la commande suivante et en saisissant
yeslorsque vous y êtes invité :terraform apply
Attendez que Terraform affiche le message "Apply completed!" (Application terminée).
- Ouvrez votre projet Google Cloud pour afficher les résultats. Dans la console Google Cloud , accédez à vos ressources dans l'interface utilisateur pour vous assurer que Terraform les a créées ou mises à jour.
Pour récupérer la stratégie actuelle, appelez la méthode
tables.getIamPolicy.Modifiez la stratégie pour ajouter des membres ou des contrôles d'accès, ou les deux. Pour connaître le format requis pour la stratégie, consultez la page de référence Stratégie.
Appelez
tables.setIamPolicypour écrire la stratégie mise à jour.
Terraform
Utilisez les ressources google_bigquery_table_iam pour modifier l'accès à une table.
Définir la stratégie de contrôle d'accès pour une table
L'exemple suivant montre comment utiliser la ressource google_bigquery_table_iam_policy pour définir la stratégie IAM de la table mytable. Cette opération remplace toute règle existante déjà associée à la table :
# This file sets the IAM policy for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". data "google_iam_policy" "iam_policy" { binding { role = "roles/bigquery.dataOwner" members = [ "user:user@example.com", ] } } resource "google_bigquery_table_iam_policy" "table_iam_policy" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id policy_data = data.google_iam_policy.iam_policy.policy_data }
Définir l'appartenance à un rôle pour une table
L'exemple suivant montre comment utiliser la ressource google_bigquery_table_iam_binding pour définir l'appartenance à un rôle donné pour la table mytable. Cette opération remplace toute appartenance existante à ce rôle.
Les autres rôles de la stratégie IAM pour la table sont conservés.
# This file sets membership in an IAM role for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". resource "google_bigquery_table_iam_binding" "table_iam_binding" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id role = "roles/bigquery.dataOwner" members = [ "group:group@example.com", ] }
Définir l'appartenance à un rôle pour un seul compte principal
L'exemple suivant montre comment utiliser la ressource google_bigquery_table_iam_member pour mettre à jour la stratégie IAM de la table mytable afin d'accorder un rôle à un compte principal. La mise à jour de cette stratégie IAM n'a aucune incidence sur l'accès des autres comptes principaux qui ont reçu ce rôle pour l'ensemble de données.
# This file adds a member to an IAM role for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". resource "google_bigquery_table_iam_member" "table_iam_member" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id role = "roles/bigquery.dataEditor" member = "serviceAccount:bqcx-1234567891011-12a3@gcp-sa-bigquery-condel.iam.gserviceaccount.com" }
Pour appliquer votre configuration Terraform dans un projet Google Cloud , suivez les procédures des sections suivantes.
Préparer Cloud Shell
Préparer le répertoire
Chaque fichier de configuration Terraform doit avoir son propre répertoire (également appelé module racine).
Appliquer les modifications
API
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Appelez la fonctionIAM().SetPolicy() de la ressource
pour enregistrer les modifications apportées à la stratégie d'accès d'une table ou d'une vue.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Appelez la fonctionTable#getIamPolicy()
pour récupérer la stratégie IAM actuelle d'une table ou d'une vue, modifiez la stratégie en ajoutant de nouvelles liaisons, puis utilisez la
fonction Table#setIamPolicy()
pour enregistrer les modifications apportées à la stratégie d'accès.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Appelez la fonctionclient.set_iam_policy() pour enregistrer les modifications apportées à la stratégie d'accès d'une table ou d'une vue.
Rôles prédéfinis qui accordent l'accès aux tables et aux vues
Les vues sont traitées comme des ressources de table dans BigQuery. Pour un contrôle d'accès précis, vous pouvez attribuer un rôle IAM prédéfini ou personnalisé à une table ou une vue spécifique. La table ou la vue hérite également des contrôles d'accès spécifiés au niveau de l'ensemble de données et à un niveau supérieur. Par exemple, si vous accordez à un compte principal le rôle de propriétaire de données BigQuery sur un ensemble de données, ce compte principal dispose également des autorisations de propriétaire de données sur les tables et les vues de l'ensemble de données.
Les rôles IAM prédéfinis suivants disposent d'autorisations sur les tables ou les vues.
| Rôle | Description |
|---|---|
Propriétaire de données BigQuery
(roles/bigquery.dataOwner) |
Lorsqu'il est accordé sur une table ou une vue, ce rôle accorde les autorisations suivantes :
|
Éditeur de données BigQuery
(roles/bigquery.dataEditor) |
Lorsqu'il est accordé sur une table ou une vue, ce rôle accorde les autorisations suivantes :
|
Lecteur de données BigQuery
(roles/bigquery.dataViewer) |
Lorsqu'il est accordé sur une table ou une vue, ce rôle accorde les autorisations suivantes :
|
Lecteur de métadonnées BigQuery
(roles/bigquery.metadataViewer) |
Lorsqu'il est accordé sur une table ou une vue, ce rôle accorde les autorisations suivantes :
|
Autorisations pour les tables et les vues
Les vues sont traitées comme des ressources de table dans BigQuery. Toutes les autorisations au niveau de la table s'appliquent aux vues.
La plupart des autorisations qui commencent par bigquery.tables s'appliquent au niveau de la table.
bigquery.tables.create et bigquery.tables.list ne le sont pas. Pour créer et lister des tables ou des vues, les autorisations bigquery.tables.create et bigquery.tables.list doivent être accordées à un rôle sur un conteneur parent (l'ensemble de données ou le projet).
Le tableau suivant liste toutes les autorisations pour les tables et les vues, ainsi que la ressource de niveau le plus bas à laquelle elles peuvent être accordées.
| Autorisation | Ressource | Action |
|---|---|---|
bigquery.tables.create |
Ensemble de données | Créez des tables dans l'ensemble de données. |
bigquery.tables.createIndex |
Table | Créez un index de recherche sur la table. |
bigquery.tables.deleteIndex |
Table | Supprimez un index de recherche sur la table. |
bigquery.tables.createSnapshot |
Table | Créez un instantané de la table. La création d'un instantané nécessite plusieurs autorisations supplémentaires au niveau de la table et de l'ensemble de données. Pour en savoir plus, consultez Autorisations et rôles pour la création d'instantanés de table. |
bigquery.tables.deleteSnapshot |
Table | Supprimez un instantané de la table. |
bigquery.tables.delete |
Table | Supprimer une table. |
bigquery.tables.createTagBinding |
Table | Créer des liaisons de tags de ressource sur une table |
bigquery.tables.deleteTagBinding |
Table | Supprimer des liaisons de tags de ressource sur une table. |
bigquery.tables.listTagBindings |
Table | Répertorier les liaisons de tags de ressource sur une table. |
bigquery.tables.listEffectiveTags |
Table | Lister les tags effectifs (appliqués et hérités) pour la table. |
bigquery.tables.export |
Table | Exportez les données du tableau. Pour exécuter une tâche d'exportation, vous devez également disposer des autorisations bigquery.jobs.create. |
bigquery.tables.get |
Table | Obtenir les métadonnées d'une table. |
bigquery.tables.getData |
Table | Interrogez les données de la table. L'exécution d'un job de requête nécessite également des autorisations bigquery.jobs.create. |
bigquery.tables.getIamPolicy |
Table | Obtenez les contrôles d'accès pour la table. |
bigquery.tables.list |
Ensemble de données | Répertorier toutes les tables et les métadonnées des tables dans l'ensemble de données |
bigquery.tables.replicateData |
Table | Répliquer les données d'une table Cette autorisation est requise pour créer des réplications de vues matérialisées. |
bigquery.tables.restoreSnapshot |
Table | Restaurez un instantané de table. |
bigquery.tables.setCategory |
Table | Définissez des tags avec stratégie dans le schéma de la table. |
bigquery.tables.setColumnDataPolicy |
Table | Définir des règles d'accès au niveau des colonnes dans une table. |
bigquery.tables.setIamPolicy |
Table | Définissez des contrôles d'accès à une table. |
bigquery.tables.update |
Table | Mettre à jour une table metadata. bigquery.tables.get est également nécessaire pour mettre à jour les métadonnées de table dans la console. |
bigquery.tables.updateData |
Table | Mettre à jour les données d'une table |
bigquery.tables.updateIndex |
Table | Mettez à jour un index de recherche sur la table. |
Afficher les contrôles d'accès pour une table ou une vue
Pour afficher les contrôles d'accès d'une table ou d'une vue, choisissez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le volet Explorateur, développez votre projet et un ensemble de données, puis sélectionnez une table ou une vue.
Cliquez sur Partager.
Les contrôles d'accès aux tables ou aux vues s'affichent dans le volet Partager.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Pour obtenir une règle d'accès existante et l'exporter dans un fichier local au format JSON, utilisez la commande
bq get-iam-policydans Cloud Shell :bq get-iam-policy \ --table=true \ PROJECT_ID:DATASET.RESOURCE > PATH_TO_FILE
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre projet.
- DATASET : par le nom de votre ensemble de données
- RESOURCE : nom de la table ou de la vue dont vous souhaitez afficher la règle
- PATH_TO_FILE : chemin d'accès au fichier JSON sur votre ordinateur local
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
SELECT COLUMN_LIST FROM PROJECT_ID.`region-REGION`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_schema = "DATASET" AND object_name = "TABLE";
Remplacez les éléments suivants :
- COLUMN_LIST : liste de colonnes séparées par des virgules de la vue
INFORMATION_SCHEMA.OBJECT_PRIVILEGES - PROJECT_ID : ID de votre projet.
- REGION : qualificatif de région
- DATASET : nom d'un ensemble de données contenant la table ou la vue
- TABLE : nom de la table ou de la vue
- COLUMN_LIST : liste de colonnes séparées par des virgules de la vue
Cliquez sur Exécuter.
SQL
Interrogez la vue INFORMATION_SCHEMA.OBJECT_PRIVILEGES.
Les requêtes de récupération des contrôles d'accès pour une table ou une vue doivent spécifier object_schema et object_name.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Exemple :
SELECT object_name, privilege_type, grantee FROM my_project.`region-us`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_schema = "mydataset" AND object_name = "mytable";
+------------------+-----------------------------+--------------------------+
| object_name | privilege_type | grantee |
+------------------+-----------------------------+--------------------------+
| mytable | roles/bigquery.dataEditor | group:group@example.com|
| mytable | roles/bigquery.dataOwner | user:user@example.com|
+------------------+-----------------------------+--------------------------+
API
Pour récupérer la stratégie actuelle, appelez la méthode tables.getIamPolicy.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Appelez la fonctionIAM().Policy() de la ressource. Appelez ensuite la fonction Roles() pour obtenir la stratégie d'accès d'une table ou d'une vue.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Récupérez la stratégie IAM d'une table ou d'une vue à l'aide de la fonctionTable#getIamPolicy().
Les détails de la règle d'accès sont disponibles dans l'objet de règle renvoyé.
Révoquer l'accès à une table ou à une vue
Pour révoquer l'accès à une table ou une vue, sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le panneau Explorateur, développez votre projet et un ensemble de données, puis sélectionnez une table ou une vue.
Dans le panneau des détails, cliquez sur Partager.
Dans la boîte de dialogue Partager, développez le compte principal dont vous souhaitez révoquer l'accès.
Cliquez sur Supprimer.
Dans la boîte de dialogue Supprimer le rôle pour le compte principal ?, cliquez sur Supprimer.
Pour revenir aux détails de la table ou de la vue, cliquez sur Fermer.
SQL
Pour supprimer l'accès aux tables ou aux vues des comptes principaux, utilisez l'instruction LCD REVOKE :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
REVOKE `ROLE_LIST` ON RESOURCE_TYPE RESOURCE_NAME FROM "USER_LIST"
Remplacez les éléments suivants :
ROLE_LIST: rôle ou liste de rôles (séparés par une virgule) que vous souhaitez révoquer.RESOURCE_TYPE: type de ressource à partir duquel le rôle est révoquéLes valeurs autorisées incluent
TABLE,VIEW,MATERIALIZED VIEWetEXTERNAL TABLE.RESOURCE_NAME: nom de la ressource sur laquelle vous souhaitez révoquer l'autorisation.USER_LIST: liste des utilisateurs (séparés par une virgule) dont les rôles seront révoqués.Pour obtenir la liste des formats valides, consultez la page
user_list.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
L'exemple suivant révoque le rôle Propriétaire de données BigQuery sur myTable :
REVOKE `roles/bigquery.dataOwner`
ON TABLE `myProject`.myDataset.myTable
FROM "group:group@example.com", "serviceAccount:user@myproject.iam.gserviceaccount.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Pour révoquer l'accès à une table ou à une vue, utilisez la commande
bq remove-iam-policy-binding:bq remove-iam-policy-binding --member=MEMBER_TYPE:MEMBER --role=ROLE --table=true RESOURCE
Remplacez les éléments suivants :
- MEMBER_TYPE : type de membre, tel que
user,group,serviceAccountoudomain - MEMBER : adresse e-mail ou nom de domaine du membre
- ROLE : rôle que vous souhaitez révoquer pour le membre.
- RESOURCE : nom de la table ou de la vue dont vous souhaitez modifier la stratégie
- MEMBER_TYPE : type de membre, tel que
Pour récupérer la stratégie actuelle, appelez la méthode
tables.getIamPolicy.Modifiez la stratégie pour supprimer des membres ou des liaisons, ou les deux. Pour connaître le format requis pour la stratégie, consultez la page de référence Stratégie.
Appelez
tables.setIamPolicypour écrire la stratégie mise à jour.
API
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Appelez la fonctionpolicy.Remove()
pour supprimer l'accès.
Appelez ensuite la fonction IAM().SetPolicy() pour enregistrer les modifications apportées à la stratégie d'accès d'une table ou d'une vue.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Récupérez la stratégie IAM actuelle pour une table ou une vue à l'aide de la méthodeTable#getIamPolicy().
Modifiez la stratégie pour supprimer le rôle ou le compte principal souhaité, puis appliquez la stratégie mise à jour à l'aide de la méthode Table#setIamPolicy().
Utiliser les contrôles d'accès pour les routines
Pour envoyer des commentaires ou demander de l'aide concernant cette fonctionnalité, envoyez un e-mail à l'adresse bq-govsec-eng@google.com.
Vous pouvez autoriser l'accès à une routine en attribuant à un compte principal IAM](/iam/docs/principal-identifiers#allow) un rôle prédéfini ou personnalisé qui détermine ce que le compte principal peut faire avec la routine. Il s'agit également d'associer une stratégie d'autorisation à une ressource. Une fois l'accès accordé, vous pouvez afficher les contrôles d'accès à la routine et révoquer l'accès à la routine.
Accorder l'accès à une routine
Pour un contrôle d'accès précis, vous pouvez accorder un rôle IAM prédéfini ou personnalisé sur une routine spécifique. La routine hérite également des contrôles d'accès spécifiés au niveau de l'ensemble de données et à un niveau supérieur. Par exemple, si vous accordez à un compte principal le rôle de propriétaire de données BigQuery sur un ensemble de données, ce compte principal dispose également des autorisations de propriétaire de données sur les routines de l'ensemble de données.
Sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le volet Explorateur, développez votre projet et votre ensemble de données, puis Routines, et sélectionnez une routine.
Cliquez sur Partager.
Cliquez sur Ajouter des membres.
Dans le champ Nouveaux membres, saisissez un compte principal.
Dans la liste Sélectionner un rôle, sélectionnez un rôle prédéfini ou personnalisé.
Cliquez sur Enregistrer.
Pour revenir aux informations sur la routine, cliquez sur OK.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Pour écrire les informations existantes sur la routine (y compris les contrôles d'accès) dans un fichier JSON, utilisez la commande
bq get-iam-policy:bq get-iam-policy \ PROJECT_ID:DATASET.ROUTINE \ > PATH_TO_FILE
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre projet.
- DATASET : nom de l'ensemble de données contenant la routine que vous souhaitez mettre à jour
- ROUTINE : nom de la ressource à mettre à jour.
- PATH_TO_FILE : chemin d'accès au fichier JSON sur votre ordinateur local.
Apportez vos modifications à la section
bindingsdu fichier JSON. Une liaison associe un ou plusieurs comptes principaux à un seulrole. Les comptes principaux peuvent être des comptes utilisateur, des comptes de service, des groupes Google ou des domaines. Par exemple, la sectionbindingsdu fichier JSON d'une routine ressemblerait à ceci :{ "bindings": [ { "role": "roles/bigquery.dataViewer", "members": [ "user:user@example.com", "group:group@example.com", "domain:example.com", ] }, ], "etag": "BwWWja0YfJA=", "version": 1 }
Pour mettre à jour la règle d'accès, utilisez la commande
bq set-iam-policy:bq set-iam-policy PROJECT_ID:DATASET.ROUTINE PATH_TO_FILE
Pour vérifier les modifications apportées aux contrôles d'accès, saisissez à nouveau la commande
bq get-iam-policysans écrire les informations dans un fichier :bq get-iam-policy --format=prettyjson \\ PROJECT_ID:DATASET.ROUTINE
Pour récupérer la stratégie actuelle, appelez la méthode
routines.getIamPolicy.Modifiez la stratégie pour ajouter des comptes principaux, des liaisons ou les deux. Pour connaître le format requis pour la stratégie, consultez la page de référence Stratégie.
Appelez
routines.setIamPolicypour écrire la stratégie mise à jour.
API
Rôles prédéfinis qui accordent l'accès aux routines
Pour un contrôle d'accès précis, vous pouvez accorder un rôle IAM prédéfini ou personnalisé sur une routine spécifique. La routine hérite également des contrôles d'accès spécifiés au niveau de l'ensemble de données et à un niveau supérieur. Par exemple, si vous accordez à un compte principal le rôle de propriétaire des données sur un ensemble de données, ce compte principal dispose également des autorisations de propriétaire des données sur les routines de l'ensemble de données par héritage.
Les rôles IAM prédéfinis suivants disposent d'autorisations sur les routines.
| Rôle | Description |
|---|---|
Propriétaire de données BigQuery
(roles/bigquery.dataOwner) |
Lorsqu'il est accordé sur une routine, ce rôle accorde les autorisations suivantes :
Vous ne devez pas accorder le rôle Propriétaire des données au niveau de la routine. Le rôle Éditeur de données accorde également toutes les autorisations pour la routine et est un rôle moins permissif. |
Éditeur de données BigQuery
(roles/bigquery.dataEditor) |
Lorsqu'il est accordé sur une routine, ce rôle accorde les autorisations suivantes :
|
Lecteur de données BigQuery
(roles/bigquery.dataViewer) |
Lorsqu'il est accordé sur une routine, ce rôle accorde les autorisations suivantes :
|
Lecteur de métadonnées BigQuery
(roles/bigquery.metadataViewer) |
Lorsqu'il est accordé sur une routine, ce rôle accorde les autorisations suivantes :
|
Autorisations pour les routines
La plupart des autorisations qui commencent par bigquery.routines s'appliquent au niveau de la routine.
bigquery.routines.create et bigquery.routines.list ne le sont pas. Pour créer et lister des routines, les autorisations bigquery.routines.create et bigquery.routines.list doivent être accordées à un rôle sur le conteneur parent (l'ensemble de données).
Le tableau suivant répertorie toutes les autorisations pour les routines et la ressource de niveau le plus bas à laquelle elles peuvent être accordées.
| Autorisation | Ressource | Description |
|---|---|---|
bigquery.routines.create |
Ensemble de données | Créez une routine dans l'ensemble de données. Cette autorisation nécessite également bigquery.jobs.create pour exécuter un job de requête contenant une instruction CREATE FUNCTION. |
bigquery.routines.delete |
Routine | Supprimer une routine. |
bigquery.routines.get |
Routine | Référencez une routine créée par un autre utilisateur. Cette autorisation nécessite également bigquery.jobs.create pour exécuter une tâche de requête qui fait référence à la routine. Vous avez également besoin d'une autorisation pour accéder aux ressources auxquelles la routine fait référence, telles que les tables ou les vues. |
bigquery.routines.list |
Ensemble de données | Répertorier les routines de l'ensemble de données et afficher les métadonnées des routines |
bigquery.routines.update |
Routine | Mettre à jour des définitions et des métadonnées de routine |
bigquery.routines.getIamPolicy |
Routine | Obtenez les contrôles d'accès pour la routine. |
bigquery.routines.setIamPolicy |
Routine | Définissez des contrôles d'accès pour la routine. |
Afficher les contrôles d'accès pour une routine
Pour afficher les paramètres d'accès d'une routine, choisissez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le volet Explorateur, développez votre projet, l'ensemble de données et Routines, puis sélectionnez une routine.
Cliquez sur Partager.
Les contrôles d'accès de la routine s'affichent dans le volet Partager.
bq
La commande bq get-iam-policy ne permet pas d'afficher les contrôles d'accès à une routine.
SQL
La vue INFORMATION_SCHEMA.OBJECT_PRIVILEGES n'affiche pas les contrôles d'accès pour les routines.
API
Pour récupérer la stratégie actuelle, appelez la méthode routines.getIamPolicy.
Révoquer l'accès à une routine
Pour révoquer l'accès à une routine, sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Dans le panneau Explorateur, développez votre projet, un ensemble de données et Routines, puis sélectionnez une routine.
Dans le panneau des détails, cliquez sur Partage > Autorisations.
Dans la boîte de dialogue Autorisations pour les routines, développez le compte principal dont vous souhaitez révoquer l'accès.
Cliquez sur Supprimer le compte principal.
Dans la boîte de dialogue Supprimer le rôle pour le compte principal ?, cliquez sur Supprimer.
Cliquez sur Fermer.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Pour écrire les informations existantes sur la routine (y compris les contrôles d'accès) dans un fichier JSON, utilisez la commande
bq get-iam-policy:bq get-iam-policy --routine PROJECT_ID:DATASET.ROUTINE > PATH_TO_FILE
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre projet.
- DATASET : nom de l'ensemble de données contenant la routine que vous souhaitez mettre à jour
- ROUTINE : nom de la ressource à mettre à jour.
- PATH_TO_FILE : chemin d'accès au fichier JSON sur votre ordinateur local.
Dans le fichier de stratégie, la valeur de
versionreste1. Ce numéro fait référence à la version du schéma de la stratégie IAM, et non à la version de la stratégie. La valeur deetagcorrespond au numéro de version de la règle.Apportez vos modifications à la section
accessdu fichier JSON. Vous pouvez supprimer n'importe quelle entréespecialGroup:projectOwners,projectWriters,projectReadersetallAuthenticatedUsers. Vous pouvez également supprimer l'un des éléments suivants :userByEmail,groupByEmailetdomain.Par exemple, la section
accessdu fichier JSON d'une routine ressemblerait à ceci :{ "bindings": [ { "role": "roles/bigquery.dataViewer", "members": [ "user:user@example.com", "group:group@example.com", "domain:google.com", ] }, ], "etag": "BwWWja0YfJA=", "version": 1 }
Pour mettre à jour la règle d'accès, utilisez la commande
bq set-iam-policy:bq set-iam-policy --routine PROJECT_ID:DATASET.ROUTINE PATH_TO_FILE
Pour vérifier les modifications apportées contrôle des accès, saisissez à nouveau la commande
get-iam-policysans écrire les informations dans un fichier :bq get-iam-policy --routine --format=prettyjson PROJECT_ID:DATASET.ROUTINE
Pour récupérer la stratégie actuelle, appelez la méthode
routines.getIamPolicy.Modifiez la stratégie pour ajouter des comptes principaux ou des liaisons, ou les deux. Pour connaître le format requis pour la stratégie, consultez la page de référence Stratégie.
API
Afficher les contrôles d'accès hérités pour une ressource
Vous pouvez examiner les rôles IAM hérités d'une ressource à l'aide de l'UI Web BigQuery. Vous devez disposer des autorisations appropriées pour afficher l'héritage dans la console. Pour examiner l'héritage d'un ensemble de données, d'une table, d'une vue ou d'une routine :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le volet Explorateur, sélectionnez l'ensemble de données, ou développez-le et sélectionnez une table, une vue ou une routine.
Pour un ensemble de données, cliquez sur Partage. Pour une table, une vue ou une routine, cliquez sur Partager.
Vérifiez que l'option Afficher les rôles hérités dans le tableau est activée.

Développez un rôle dans le tableau.
Dans la colonne Héritage, l'icône hexagonale indique si le rôle a été hérité d'une ressource parente.
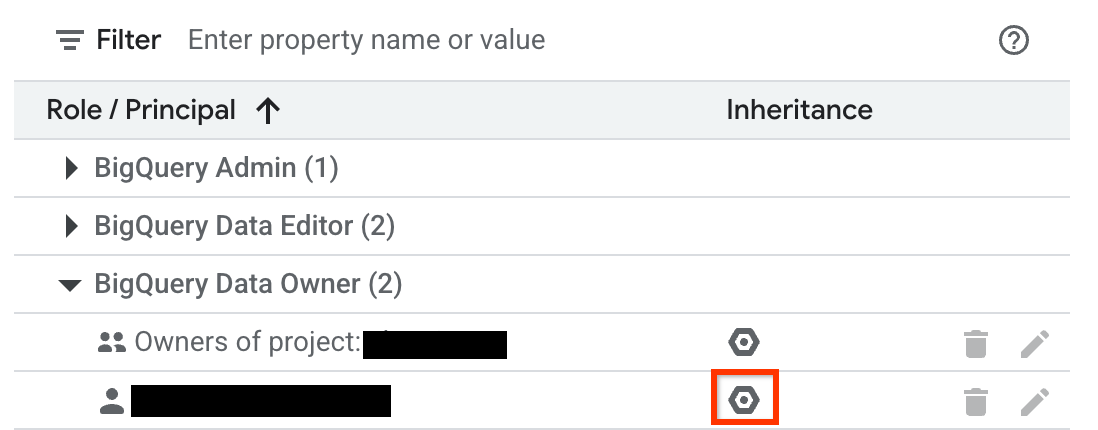
Refuser l'accès à une ressource
Les stratégies de refus IAM vous permettent de définir des garde-fous pour l'accès aux ressources BigQuery. Vous pouvez définir des règles de refus qui empêchent certains comptes principaux d'utiliser certaines autorisations, quels que soient les rôles qui leur sont attribués.
Pour savoir comment créer, mettre à jour et supprimer des règles de refus, consultez Refuser l'accès aux ressources.
Cas particuliers
Tenez compte des scénarios suivants lorsque vous créez des stratégies de refus IAM pour quelques autorisations BigQuery :
L'accès aux ressources autorisées (vues, routines, ensembles de données ou procédures stockées) vous permet de créer, supprimer ou manipuler une table, ainsi que de lire et de modifier ses données, même si vous n'êtes pas autorisé directement à effectuer ces opérations. Il permet également d'obtenir des données ou des métadonnées de modèle et d'appeler d'autres procédures stockées sur la table sous-jacente. Cette fonctionnalité implique que les ressources autorisées disposent des autorisations suivantes :
bigquery.tables.getbigquery.tables.listbigquery.tables.getDatabigquery.tables.updateDatabigquery.tables.createbigquery.tables.deletebigquery.routines.getbigquery.routines.listbigquery.datasets.getbigquery.models.getDatabigquery.models.getMetadata
Pour refuser l'accès à ces ressources autorisées, ajoutez l'une des valeurs suivantes au champ
deniedPrincipallorsque vous créez la stratégie de refus :Valeur Cas d'utilisation principalSet://goog/public:allBloque tous les comptes principaux, y compris les ressources autorisées. principalSet://bigquery.googleapis.com/projects/PROJECT_NUMBER/*Bloque toutes les ressources BigQuery autorisées dans le projet spécifié. PROJECT_NUMBERest un identifiant unique généré automatiquement pour votre projet de typeINT64.Pour exempter certains comptes principaux de la stratégie de refus, spécifiez-les dans le champ
exceptionPrincipalsde votre stratégie de refus. Par exemple,exceptionPrincipals: "principalSet://bigquery.googleapis.com/projects/1234/*".BigQuery met en cache les résultats des requêtes d'un propriétaire de job pendant 24 heures. Il peut y accéder sans avoir besoin de l'autorisation
bigquery.tables.getDatasur la table contenant les données. Par conséquent, l'ajout d'une stratégie de refus IAM à l'autorisationbigquery.tables.getDatane bloque pas l'accès aux résultats mis en cache pour le propriétaire de job tant que le cache n'a pas expiré. Pour bloquer l'accès du propriétaire de job aux résultats mis en cache, créez une stratégie de refus distincte sur l'autorisationbigquery.jobs.create.Pour éviter tout accès non souhaité aux données lorsque vous utilisez des règles de refus pour bloquer les opérations de lecture de données, nous vous recommandons également d'examiner et de révoquer tous les abonnements existants au niveau de l'ensemble de données.
Pour créer une stratégie de refus IAM permettant d'afficher les contrôles d'accès aux ensembles de données, refusez les autorisations suivantes :
bigquery.datasets.getbigquery.datasets.getIamPolicy
Pour créer une stratégie de refus IAM permettant de mettre à jour les contrôles d'accès aux ensembles de données, refusez les autorisations suivantes :
bigquery.datasets.updatebigquery.datasets.setIamPolicy
Étapes suivantes
Découvrez comment utiliser la méthode projects.testIamPermissions pour tester l'accès des utilisateurs à une ressource.