BigQuery 儲存空間總覽
本頁面說明 BigQuery 的儲存空間元件。
BigQuery 儲存空間經過最佳化調整,可對大型資料集執行分析式查詢。也支援高處理量的串流擷取和高處理量讀取作業。瞭解 BigQuery 儲存空間有助於您最佳化工作負載。
總覽
BigQuery 架構的一項重要功能,就是將儲存空間和運算資源分開。這可讓 BigQuery 根據需求獨立調度儲存和運算資源。
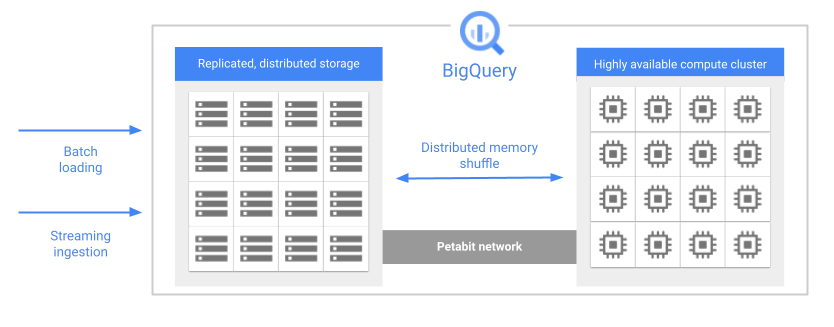
執行查詢時,查詢引擎會將工作平行分派給多個 worker,這些 worker 會掃描儲存空間中的相關資料表、處理查詢,然後收集結果。BigQuery 會使用 PB 等級網路,在記憶體中完整執行查詢,確保資料能快速移至 worker 節點。
以下是 BigQuery 儲存空間的幾項重要功能:
代管。BigQuery 儲存空間是一項全代管服務。您不需要佈建儲存空間資源或保留儲存空間單位。將資料載入系統時,BigQuery 會自動為您分配儲存空間。您只需為使用的儲存空間付費。BigQuery 計費模式會分別收取運算和儲存空間費用。如需價格詳細資訊,請參閱 BigQuery 定價。
耐用性:BigQuery 儲存空間專為達成 99.999999999% (11 9's) 的年度耐用性而設計,BigQuery 會跨多個可用性區複製資料,以免機器層級或區域故障導致資料遺失。詳情請參閱「可靠性:災難復原規劃」。
已加密。BigQuery 會在將所有資料寫入磁碟之前,自動加密資料。您可以提供自己的加密金鑰,也可以讓 Google 管理加密金鑰。詳情請參閱「靜態資料加密」。
高效率。BigQuery 儲存空間採用高效的編碼格式,可針對分析工作負載進行最佳化。如要進一步瞭解 BigQuery 的儲存格式,請參閱「Inside Capacitor, BigQuery's next-generation columnar storage format」(Capacitor 內部:BigQuery 的新一代欄位式儲存格式) 一文。
資料表內容
您儲存在 BigQuery 中的資料大多是表格資料。表格資料包括標準表格、表格複本、表格快照和物化檢視畫面。您只需要為這些資源使用的儲存空間付費。詳情請參閱儲存空間定價。
標準表格包含結構化資料。每個資料表都有一個結構定義,而結構定義中的每個資料欄都有一個資料類型。BigQuery 會以資料欄格式儲存資料。請參閱本文件中的「儲存空間版面配置」。
資料表本機副本是標準資料表的輕量化可寫副本。BigQuery 只會儲存資料表複本與其基礎資料表之間的差異。
資料表快照是資料表的時間點副本。資料表快照為唯讀,但您可以從資料表快照還原資料表。BigQuery 只會儲存資料表快照與其基礎資料表之間的差異。
具體化檢視表是預先運算的檢視表,會定期快取檢視查詢的結果。快取結果會儲存在 BigQuery 儲存空間中。
此外,快取的查詢結果會以暫存資料表的形式儲存。您不需要為儲存在臨時資料表中的快取查詢結果付費。
外部資料表是一種特殊類型的資料表,資料位於 BigQuery 以外的資料儲存空間 (例如 Cloud Storage) 中。外部資料表有資料表結構定義,就像標準資料表一樣,但資料表定義會指向外部資料儲存庫。在這種情況下,BigQuery 儲存空間只會保留資料表中繼資料。BigQuery 不會針對外部資料表儲存空間收費,但外部資料儲存空間可能會收取儲存空間費用。
BigQuery 會將資料表和其他資源整理成稱為「資料集」的邏輯容器。您將 BigQuery 資源分組的方式會影響 BigQuery 工作負載的權限、配額、帳單和其他層面。如需更多資訊和最佳做法,請參閱「整理 BigQuery 資源」。
資料表所使用的資料保留政策,取決於包含該資料表的資料集設定。詳情請參閱「透過時間旅行和備援機制保留資料」。
中繼資料
BigQuery 儲存空間也會保留 BigQuery 資源的中繼資料。您不需要為中繼資料儲存空間付費。
在 BigQuery 中建立任何永久實體 (例如表格、檢視或使用者定義函式 (UDF)) 時,BigQuery 會儲存實體的中繼資料。即使是未包含任何資料表資料的資源 (例如 UDF 和邏輯檢視表),也適用這項規定。
中繼資料包含資料表結構定義、分區和叢集規格、資料表到期時間等資訊。使用者可以看到這類中繼資料,而且可以在建立資源時進行設定。此外,BigQuery 會儲存用於內部最佳化查詢的資料,使用者無法直接看到這類中繼資料。
儲存空間配置
許多傳統資料庫系統會以資料列為導向的格式儲存資料,也就是說,資料列會一起儲存,每個資料列中的欄位會依序顯示在磁碟上。以列為導向的資料庫可有效查詢個別記錄。不過,在許多記錄中執行分析函式的效率可能較低,因為系統在存取記錄時必須讀取每個欄位。
BigQuery 會以資料欄式格式儲存資料表資料,也就是說會個別儲存每個資料欄。以資料欄為導向的資料庫在掃描整個資料集的個別資料欄時,效率特別高。
以資料列為導向的資料庫經過最佳化調整,適合用於分析工作負載,這些工作負載會匯總大量記錄的資料。通常,分析查詢只需要讀取資料表中的幾個資料欄。舉例來說,如果您要計算數百萬列資料中某一欄的總和,BigQuery 可以讀取該欄資料,而不需要讀取每列的每個欄位。
以資料欄為導向的資料庫的另一個優點是,資料欄中的資料通常比資料列中的資料有更多重複項目。這項特性可使用長度長度編碼等技術,進一步壓縮資料,進而提升讀取效能。

儲存空間計費模式
您可以依據邏輯或實體 (壓縮) 位元組,或兩者皆是,來支付 BigQuery 資料儲存空間費用。您選擇的儲存空間計費模式會決定儲存空間價格。您選擇的儲存空間計費模式不會影響 BigQuery 效能。無論您選擇哪種計費模式,系統都會以實際位元組儲存資料。
您可以在資料集層級設定儲存空間帳單模式。如果您在建立資料集時未指定儲存空間計費模式,系統預設會使用邏輯儲存空間計費。不過,您可以變更資料集的儲存空間計費模式。如果您變更資料集的儲存空間計費模式,必須等待 14 天,才能再次變更儲存空間計費模式。
變更資料集的計費模式後,變更內容會在 24 小時後生效。變更資料集的計費模式時,長期儲存空間中的任何資料表或資料表分區都不會重設為動態儲存空間。變更資料集的計費模式不會影響查詢效能和查詢延遲時間。
資料集會使用時間旅行和安全防護儲存空間來保留資料。使用實際儲存空間計費時,系統會以有效儲存空間費率分別收取時光旅行和備援儲存空間的費用,但使用邏輯儲存空間計費時,則會將這兩項費用納入基本費率。您可以修改資料集使用的時間回溯視窗,以便平衡實體儲存空間成本與資料保留時間。您無法修改安全防護期間。如要進一步瞭解資料集資料保留機制,請參閱「透過時間旅行和安全防護機制保留資料」。如要進一步瞭解如何預測儲存空間費用,請參閱「預測儲存空間帳單費用」。
如果貴機構有任何位於資料集所在地區的現有固定費率時段承諾,就無法將資料集註冊至實體儲存空間計費方案。這項規定不適用於透過 BigQuery 版本購買的承諾。
最佳化調整儲存空間
最佳化 BigQuery 儲存空間可提升查詢效能並控管成本。如要查看資料表儲存空間中繼資料,請查詢下列 INFORMATION_SCHEMA 檢視畫面:
如要瞭解如何最佳化儲存空間,請參閱「在 BigQuery 中最佳化儲存空間」。
載入資料
將資料匯入 BigQuery 時,有幾種基本模式可供選擇。
批次載入:在一項批次作業中,將來源資料載入 BigQuery 資料表。這項操作可以是一次性操作,也可以自動化,以便定期執行。批次載入作業可建立新資料表,或將資料附加至現有資料表。
串流:持續串流較小批次的資料,以便近乎即時查詢資料。
產生的資料:使用 SQL 陳述式將資料列插入現有資料表,或將查詢結果寫入資料表。
如要進一步瞭解何時應選擇上述每一種擷取方法,請參閱載入資料簡介。如需定價資訊,請參閱「資料擷取定價」。
從 BigQuery 儲存空間讀取資料
您通常會將資料儲存在 BigQuery 中,以便對該資料執行分析查詢。不過,有時您可能會想要直接從資料表讀取記錄。BigQuery 提供多種方式讀取資料表資料:
BigQuery API:使用
tabledata.list方法的同步分頁存取。資料會以序列方式讀取,每次叫用一個頁面。詳情請參閱「瀏覽資料表資料」。BigQuery Storage API:串流高輸送量存取,也支援伺服器端資料欄投影和篩選。您可以將讀取作業分割成多個不相交的串流,藉此在多個讀取器之間並行執行讀取作業。
匯出:使用擷取作業或
EXPORT DATA陳述式,以非同步方式將資料複製到 Google Cloud Storage。如果您需要複製 Cloud Storage 中的資料,請使用擷取工作或EXPORT DATA陳述式匯出資料。複製:在 BigQuery 中非同步複製資料集。如果來源和目的地位置相同,系統會以邏輯方式執行複製作業。
如需價格資訊,請參閱「資料提取定價」。
根據應用程式需求,您可以讀取表格資料:
- 讀取和複製:如果您需要在 Cloud Storage 中使用靜止副本,請使用擷取工作或
EXPORT DATA陳述式匯出資料。如果您只想讀取資料,請使用 BigQuery Storage API。如果您想在 BigQuery 中建立副本,請使用複製作業。 - 規模: BigQuery API 是效率最低的方法,不應用於大量讀取作業。如果您每天需要匯出超過 50 TB 的資料,請使用
EXPORT DATA陳述式或 BigQuery Storage API。 - 傳回第一列的時間:BigQuery API 是傳回第一列最快的方法,但只能用於讀取少量資料。BigQuery Storage API 的回傳第一列速度較慢,但傳輸量更高。匯出和複製作業必須完成,才能讀取任何資料列,因此這類工作的第一列資料列的時間可能會以分鐘為單位。
刪除
刪除資料表時,資料至少會保留至時間回溯期結束。完成後,系統會在 Google Cloud 刪除時間表內從磁碟清除資料。部分刪除作業 (例如 DROP COLUMN 陳述式) 僅為中繼資料作業。在這種情況下,系統會在您下次修改受影響的資料列時釋出儲存空間。如果您不修改資料表,系統無法保證在多久內釋出儲存空間。詳情請參閱「在 Google Cloud上刪除資料」。
後續步驟
- 瞭解如何使用資料表。
- 瞭解如何最佳化儲存空間。
- 瞭解如何在 BigQuery 中查詢資料。
- 瞭解資料安全性和治理。