Ringkasan penyimpanan BigQuery
Halaman ini menjelaskan komponen penyimpanan BigQuery.
Penyimpanan BigQuery dioptimalkan untuk menjalankan kueri analisis pada set data besar. Penyimpanan ini juga mendukung penyerapan streaming dengan throughput tinggi dan pembacaan dengan throughput tinggi. Memahami penyimpanan BigQuery dapat membantu Anda mengoptimalkan workload.
Ringkasan
Salah satu fitur utama arsitektur BigQuery adalah pemisahan penyimpanan dan komputasi. Hal ini memungkinkan BigQuery menskalakan penyimpanan dan komputasi secara independen, sesuai permintaan.
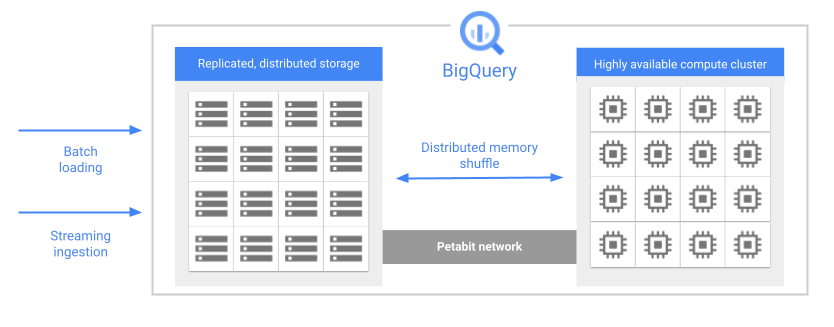
Saat Anda menjalankan kueri, mesin kueri akan mendistribusikan pekerjaan secara paralel ke beberapa worker, yang memindai tabel yang relevan di penyimpanan, memproses kueri, lalu mengumpulkan hasilnya. BigQuery mengeksekusi kueri sepenuhnya dalam memori, menggunakan jaringan petabit untuk memastikan bahwa data bergerak dengan sangat cepat ke worker node.
Berikut beberapa fitur utama penyimpanan BigQuery:
Terkelola. Penyimpanan BigQuery adalah layanan yang terkelola sepenuhnya. Anda tidak perlu menyediakan resource penyimpanan atau memesan unit penyimpanan. BigQuery mengalokasikan penyimpanan secara otomatis untuk Anda saat Anda memuat data ke dalam sistem. Anda hanya membayar sesuai jumlah penyimpanan yang digunakan. Model harga BigQuery mengenakan biaya untuk komputasi dan penyimpanan secara terpisah. Untuk mengetahui detail harga, lihat harga BigQuery.
Andal. Penyimpanan BigQuery dirancang untuk memiliki ketahanan tahunan sebesar 99,999999999% (11 angka 9). BigQuery mereplikasi data Anda di beberapa zona ketersediaan untuk melindungi dari kehilangan data akibat kegagalan tingkat mesin atau kegagalan zona. Untuk mengetahui informasi selengkapnya, lihat Keandalan: Perencanaan bencana.
Dienkripsi. BigQuery secara otomatis mengenkripsi semua data sebelum ditulis ke disk. Anda dapat memberikan kunci enkripsi Anda sendiri atau mengizinkan Google mengelola kunci enkripsinya. Untuk mengetahui informasi selengkapnya, lihat Enkripsi dalam penyimpanan.
Efisien. Penyimpanan BigQuery menggunakan format encoding efisien yang dioptimalkan untuk beban kerja analisis. Jika Anda ingin mempelajari format penyimpanan BigQuery lebih lanjut, lihat postingan blog Menilik Capacitor, format penyimpanan berdasarkan kolom generasi berikutnya dari BigQuery.
Data tabel
Sebagian besar data yang Anda simpan di BigQuery adalah data tabel. Data tabel mencakup tabel standar, clone tabel, snapshot tabel, dan tampilan terwujud. Anda akan dikenai biaya atas penyimpanan yang digunakan untuk resource ini. Untuk mengetahui informasi selengkapnya, lihat Harga penyimpanan.
Tabel standar berisi data terstruktur. Setiap tabel memiliki skema, dan setiap kolom dalam skema memiliki jenis data. BigQuery menyimpan data dalam format berbasis kolom. Lihat Tata letak penyimpanan dalam dokumen ini.
clone tabel adalah salinan tabel standar yang ringan dan dapat ditulis. BigQuery hanya menyimpan delta antara clone tabel dan tabel dasarnya.
Snapshot tabel adalah salinan tabel secara point-in-time. Snapshot tabel bersifat hanya baca, tetapi Anda dapat memulihkan tabel dari snapshot tabel. BigQuery hanya menyimpan delta antara snapshot tabel dan tabel dasarnya.
Tampilan terwujud adalah tampilan yang telah dihitung sebelumnya yang secara berkala menyimpan hasil kueri tampilan ke dalam cache. Hasil yang di-cache disimpan di penyimpanan BigQuery.
Selain itu, hasil kueri yang di-cache disimpan sebagai tabel sementara. Anda tidak akan dikenai biaya untuk hasil kueri yang di-cache yang disimpan dalam tabel sementara.
Tabel eksternal adalah jenis tabel khusus, tempat data berada di penyimpanan data yang berada di luar BigQuery, seperti Cloud Storage. Tabel eksternal memiliki skema tabel, seperti tabel standar, tetapi definisi tabel mengarah ke penyimpanan data eksternal. Dalam hal ini, hanya metadata tabel yang disimpan di penyimpanan BigQuery. BigQuery tidak mengenakan biaya untuk penyimpanan tabel eksternal, meskipun penyimpanan data eksternal mungkin mengenakan biaya untuk penyimpanan.
BigQuery mengatur tabel dan resource lainnya ke dalam container logis yang disebut set data. Cara Anda mengelompokkan resource BigQuery akan memengaruhi izin, kuota, penagihan, dan aspek lainnya dari workload BigQuery Anda. Untuk mengetahui informasi selengkapnya dan praktik terbaik, lihat Mengatur resource BigQuery.
Kebijakan retensi data yang digunakan untuk tabel ditentukan oleh konfigurasi set data yang berisi tabel. Untuk mengetahui informasi selengkapnya, lihat Retensi data dengan perjalanan waktu dan fail-safe.
Metadata
Penyimpanan BigQuery juga menyimpan metadata tentang resource BigQuery Anda. Anda tidak akan ditagih untuk penyimpanan metadata.
Saat Anda membuat entity persisten di BigQuery, seperti tabel, tampilan, atau fungsi yang ditentukan pengguna (UDF), BigQuery akan menyimpan metadata tentang entity tersebut. Hal ini berlaku bahkan untuk resource yang tidak berisi data tabel apa pun, seperti UDF dan tampilan logis.
Metadata mencakup informasi seperti skema tabel, spesifikasi partisi dan pengelompokan, waktu habis masa berlaku tabel, serta informasi lainnya. Jenis metadata ini terlihat oleh pengguna dan dapat dikonfigurasi saat Anda membuat resource. Selain itu, BigQuery menyimpan metadata yang digunakannya secara internal untuk mengoptimalkan kueri. Metadata ini tidak terlihat langsung oleh pengguna.
Tata letak penyimpanan
Banyak sistem database tradisional menyimpan datanya dalam format berorientasi baris. Artinya baris disimpan bersama, dengan kolom di setiap baris muncul secara berurutan di disk. Database berorientasi baris efisien untuk mencari catatan individu. Namun, fungsi tersebut dapat menjadi kurang efisien dalam menjalankan fungsi analisis di banyak kumpulan data, karena sistem harus membaca setiap kolom saat mengakses kumpulan data.
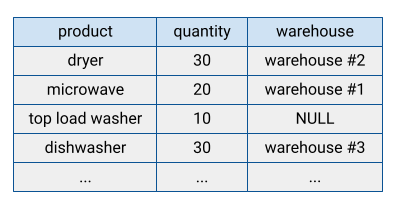
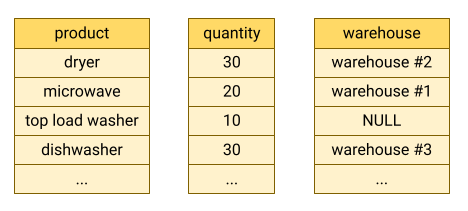
BigQuery menyimpan data tabel dalam format kolom. Artinya, BigQuery menyimpan setiap kolom secara terpisah. Database berorientasi kolom sangat efisien dalam memindai kolom individual di seluruh set data.
Database berorientasi kolom dioptimalkan untuk workload analisis yang menggabungkan data pada kumpulan data yang sangat banyak. Sering kali, kueri analisis hanya perlu membaca beberapa kolom dari sebuah tabel. Misalnya, jika Anda ingin menghitung jumlah sebuah kolom pada jutaan baris, BigQuery dapat membaca data kolom tersebut tanpa membaca setiap kolom pada setiap baris.
Keuntungan lain dari database berorientasi kolom adalah data dalam kolom biasanya memiliki lebih banyak redundansi daripada data dalam satu baris. Karakteristik ini memungkinkan kompresi data yang lebih besar menggunakan teknik seperti encoding run-length, yang dapat meningkatkan performa baca.
Model penagihan penyimpanan
Anda dapat ditagih untuk penyimpanan data BigQuery dalam byte logis atau fisik (terkompresi), atau kombinasi keduanya. Model penagihan penyimpanan yang Anda pilih menentukan harga penyimpanan. Model penagihan penyimpanan yang Anda pilih tidak memengaruhi performa BigQuery. Apa pun model penagihan yang Anda pilih, data Anda akan disimpan sebagai byte fisik.
Anda menetapkan model penagihan penyimpanan di tingkat set data. Jika Anda tidak menentukan model penagihan penyimpanan saat membuat set data, set data tersebut akan menggunakan penagihan penyimpanan logis secara default. Namun, Anda dapat mengubah model penagihan penyimpanan set data setelah membuatnya. Jika Anda mengubah model penagihan penyimpanan set data, Anda harus menunggu 14 hari sebelum dapat mengubah model penagihan penyimpanan lagi.
Jika Anda mengubah model penagihan set data, perlu waktu 24 jam agar perubahan diterapkan. Setiap tabel atau partisi tabel dalam penyimpanan jangka panjang tidak direset ke penyimpanan aktif saat Anda mengubah model penagihan set data. Performa kueri dan latensi kueri tidak terpengaruh oleh perubahan model penagihan set data.
Set data menggunakan penyimpanan perjalanan waktu dan fail-safe untuk retensi data. Penyimpanan perjalanan waktu dan fail-safe ditagih secara terpisah dengan tarif penyimpanan aktif saat Anda menggunakan penagihan penyimpanan fisik, tetapi disertakan dalam tarif dasar yang ditagih saat Anda menggunakan penagihan penyimpanan logis. Anda dapat mengubah periode perjalanan waktu yang digunakan untuk set data guna menyeimbangkan biaya penyimpanan fisik dengan retensi data. Anda tidak dapat mengubah periode fail-safe. Untuk mengetahui informasi selengkapnya tentang retensi data set, lihat Retensi data dengan perjalanan waktu dan fail-safe. Untuk informasi selengkapnya tentang perkiraan biaya penyimpanan, lihat Memperkirakan penagihan penyimpanan.
Anda tidak dapat mendaftarkan set data dalam penagihan penyimpanan fisik jika organisasi Anda memiliki komitmen slot tarif tetap lama yang berada di region yang sama dengan set data tersebut. Hal ini tidak berlaku untuk komitmen yang dibeli dengan edisi BigQuery.
Mengoptimalkan penyimpanan
Mengoptimalkan penyimpanan BigQuery akan meningkatkan performa kueri
dan kontrol biaya. Untuk melihat metadata penyimpanan tabel, buat kueri tampilan
INFORMATION_SCHEMA berikut:
Untuk mengetahui informasi tentang cara mengoptimalkan penyimpanan, lihat Mengoptimalkan penyimpanan di BigQuery.
Memuat data
Ada beberapa pola dasar untuk menyerap data ke BigQuery.
Pemuatan batch: Memuat data sumber Anda ke dalam tabel BigQuery dalam satu operasi batch. Operasi ini dapat berupa operasi satu kali atau Anda dapat mengotomatiskannya agar berjalan sesuai jadwal. Operasi pemuatan batch dapat membuat tabel baru atau menambahkan data ke tabel yang ada.
Streaming: Melakukan streaming batch data yang lebih kecil secara terus-menerus, sehingga data tersedia untuk dikueri mendekati real-time.
Data yang dihasilkan: Menggunakan pernyataan SQL untuk menyisipkan baris ke dalam tabel yang ada atau menulis hasil kueri ke tabel.
Untuk mengetahui informasi selengkapnya tentang waktu yang tepat untuk memilih setiap metode penyerapan ini, lihat Pengantar pemuatan data. Untuk mengetahui informasi harga, lihat Harga penyerapan data.
Membaca data dari penyimpanan BigQuery
Biasanya, Anda menyimpan data di BigQuery untuk menjalankan kueri analisis pada data tersebut. Namun, terkadang Anda mungkin ingin membaca data langsung dari tabel. BigQuery menyediakan beberapa cara untuk membaca data tabel:
BigQuery API: Akses dengan penomoran halaman sinkron dengan metode
tabledata.list. Data dibaca secara serial, yaitu satu halaman per pemanggilan. Untuk mengetahui informasi selengkapnya, lihat Menjelajahi data tabel.BigQuery Storage API: Akses throughput tinggi streaming yang juga mendukung proyeksi dan pemfilteran kolom sisi server. Operasi baca dapat diparalelkan di banyak pembaca dengan menyegmentasikannya menjadi beberapa aliran data yang terpisah.
Ekspor: Penyalinan throughput tinggi asinkron ke Google Cloud Storage, baik dengan tugas ekstrak maupun pernyataan
EXPORT DATA. Jika Anda perlu menyalin data di Cloud Storage, ekspor data dengan tugas ekstrak atau pernyataanEXPORT DATA.Salinan: Penyalinan set data secara asinkron dalam BigQuery. Penyalinan dilakukan secara logis jika lokasi sumber dan tujuannya sama.
Untuk mengetahui informasi harga, lihat Harga ekstraksi data.
Berdasarkan persyaratan aplikasi, Anda dapat membaca data tabel:
- Membaca dan menyalin: Jika Anda memerlukan salinan dalam penyimpanan di
Cloud Storage, ekspor data dengan tugas ekstrak atau
pernyataan
EXPORT DATA. Jika Anda hanya ingin membaca data, gunakan BigQuery Storage API. Jika Anda ingin membuat salinan dalam BigQuery, gunakan tugas penyalinan. - Skala: BigQuery API adalah metode yang paling tidak efisien dan tidak boleh
digunakan untuk pembacaan bervolume tinggi. Jika Anda perlu mengekspor lebih dari 50 TB
data per hari, gunakan pernyataan
EXPORT DATAatau BigQuery Storage API. - Waktu untuk menampilkan baris pertama: BigQuery API adalah metode tercepat untuk menampilkan baris pertama, tetapi hanya boleh digunakan untuk membaca data dalam jumlah kecil. BigQuery Storage API lebih lambat untuk menampilkan baris pertama, tetapi memiliki throughput yang jauh lebih tinggi. Ekspor dan salinan harus selesai sebelum baris dapat dibaca, sehingga waktu untuk menampilkan baris pertama untuk jenis tugas ini dapat berada dalam urutan menit.
Penghapusan
Jika Anda menghapus tabel, data akan tetap ada setidaknya selama durasi
periode perjalanan waktu Anda. Setelah itu, data akan dibersihkan
dari disk dalam
linimasa penghapusanGoogle Cloud .
Beberapa operasi penghapusan, seperti
pernyataan DROP COLUMN,
adalah operasi khusus metadata. Dalam hal ini, penyimpanan akan dikosongkan saat berikutnya
Anda mengubah baris yang terpengaruh. Jika Anda tidak mengubah tabel, tidak ada
jaminan waktu penyimpanan dikosongkan. Untuk informasi selengkapnya, lihat
Penghapusan data di Google Cloud.
Langkah berikutnya
- Pelajari cara menggunakan tabel.
- Pelajari cara mengoptimalkan penyimpanan.
- Pelajari cara membuat kueri data di BigQuery.
- Pelajari tata kelola dan keamanan data.