Panoramica dello spazio di archiviazione BigQuery
Questa pagina descrive il componente di archiviazione di BigQuery.
Lo spazio di archiviazione BigQuery è ottimizzato per l'esecuzione di query analitiche su set di dati di grandi dimensioni. Supporta inoltre l'importazione di streaming con velocità effettiva elevata e le letture con velocità effettiva elevata. Comprendere lo spazio di archiviazione BigQuery può aiutarti a ottimizzare i tuoi carichi di lavoro.
Panoramica
Una delle caratteristiche principali dell'architettura di BigQuery è la separazione tra archiviazione e calcolo. In questo modo, BigQuery può scalare in modo indipendente sia lo spazio di archiviazione sia il calcolo, in base alla domanda.
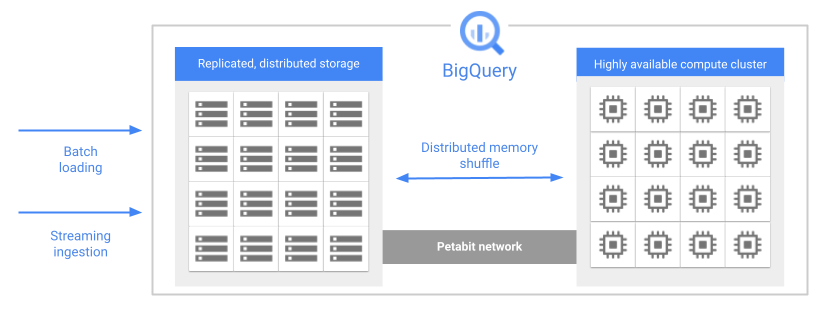
Quando esegui una query, il motore di query distribuisce il lavoro in parallelo su più worker, che eseguono la scansione delle tabelle pertinenti nello spazio di archiviazione, elaborano la query e raccolgono i risultati. BigQuery esegue le query completamente in memoria, utilizzando una rete a livello di petabit per garantire che i dati vengano spostati estremamente rapidamente ai nodi di lavoro.
Ecco alcune funzionalità chiave dello spazio di archiviazione BigQuery:
Gestito. Lo spazio di archiviazione BigQuery è un servizio completamente gestito. Non è necessario eseguire il provisioning delle risorse di archiviazione né prenotare unità di archiviazione. BigQuery alloca automaticamente lo spazio di archiviazione quando carichi i dati nel sistema. Paghi solo per la quantità di spazio di archiviazione che utilizzi. Il modello di prezzi di BigQuery prevede costi distinti per il computing e lo spazio di archiviazione. Per informazioni dettagliate sui prezzi, consulta Prezzi di BigQuery.
Durevole. Lo spazio di archiviazione BigQuery è progettato per garantire una durabilità annuale del 99,999999999% (11 nove). BigQuery replica i dati su più zone di disponibilità per proteggerli dalla perdita di dati a causa di guasti a livello di macchina o di guasti a livello di zona. Per ulteriori informazioni, consulta Affidabilità: pianificazione di scenari di calamità.
Crittografati. BigQuery cripta automaticamente tutti i dati prima che vengano scritti su disco. Puoi fornire la tua chiave di crittografia o lasciare che sia Google a gestirla. Per ulteriori informazioni, consulta Crittografia at-rest.
Efficiente. Lo spazio di archiviazione BigQuery utilizza un formato di codifica efficiente ottimizzato per i carichi di lavoro di analisi. Per scoprire di più sul formato di archiviazione di BigQuery, consulta il post del blog Informazioni su Capacitor, il formato di archiviazione colonnare di nuova generazione di BigQuery.
Dati tabella
La maggior parte dei dati archiviati in BigQuery è costituita da dati tabulari. I dati delle tabelle includono tabelle standard, cloni di tabelle, istantanee di tabelle e viste materializzate. Ti viene addebitato lo spazio di archiviazione utilizzato per queste risorse. Per maggiori informazioni, consulta Prezzi di archiviazione.
Le tabelle standard contengono dati strutturati. Ogni tabella ha uno schema e ogni colonna dello schema ha un tipo di dati. BigQuery archivia i dati in formato a colonne. Consulta la sezione Disposizione dello spazio di archiviazione in questo documento.
I cloni di tabelle sono copie leggere e scrivibili delle tabelle standard. BigQuery memorizza solo il delta tra un clone di tabella e la relativa tabella di base.
Gli snapshot delle tabelle sono copie di tabelle in un determinato momento. Gli snapshot delle tabelle sono di sola lettura, ma puoi ripristinare una tabella da uno snapshot. BigQuery memorizza solo il delta tra uno snapshot della tabella e la relativa tabella di base.
Le viste materializzate sono viste precalcolate che memorizzano nella cache periodicamente i risultati della query della vista. I risultati memorizzati nella cache vengono archiviati nello spazio di archiviazione BigQuery.
Inoltre, i risultati delle query memorizzati nella cache vengono archiviati come tabelle temporanee. Non ti viene addebitato alcun costo per i risultati delle query memorizzati nella cache in tabelle temporanee.
Le tabelle esterne sono un tipo speciale di tabelle, in cui i dati si trovano in un data store esterno a BigQuery, ad esempio Cloud Storage. Una tabella esterna ha uno schema, come una tabella standard, ma la definizione della tabella fa riferimento al datastore esterno. In questo caso, solo i metadati della tabella vengono conservati nello spazio di archiviazione BigQuery. BigQuery non addebita alcun costo per l'archiviazione delle tabelle esterne, anche se l'archivio dati esterno potrebbe addebitare un costo per l'archiviazione.
BigQuery organizza le tabelle e altre risorse in contenitori logici chiamati set di dati. Il modo in cui raggruppi le risorse BigQuery influisce sulle autorizzazioni, sulle quote, sulla fatturazione e su altri aspetti dei carichi di lavoro BigQuery. Per ulteriori informazioni e best practice, consulta Organizzare le risorse BigQuery.
Il criterio di conservazione dei dati utilizzato per una tabella è determinato dalla configurazione del set di dati che la contiene. Per saperne di più, consulta Conservazione dei dati con viaggio nel tempo e fail-safe.
Metadati
Lo spazio di archiviazione BigQuery contiene anche i metadati relativi alle tue risorse BigQuery. Non ti viene addebitato alcun costo per l'archiviazione dei metadati.
Quando crei un'entità permanente in BigQuery, ad esempio una tabella, una vista o una funzione definita dall'utente (UDF), BigQuery archivia i metadati relativi all'entità. Questo vale anche per le risorse che non contengono alcun dato di tabella, come le funzioni definite dall'utente e le visualizzazioni logiche.
I metadati includono informazioni quali lo schema della tabella, le specifiche di partizione e clustering, le date di scadenza della tabella e altre informazioni. Questo tipo di metadati è visibile all'utente e può essere configurato durante la creazione della risorsa. Inoltre, BigQuery archivia i metadati che utilizza internamente per ottimizzare le query. Questi metadati non sono direttamente visibili agli utenti.
Layout dello spazio di archiviazione
Molti sistemi di database tradizionali archiviano i dati in formato riga, il che significa che le righe vengono archiviate insieme, con i campi di ogni riga visualizzati sequenzialmente su disco. I database orientati alle righe sono efficienti per la ricerca di singoli record. Tuttavia, possono essere meno efficienti nell'eseguire funzioni analitiche su molti record, perché il sistema deve leggere ogni campo quando accede a un record.
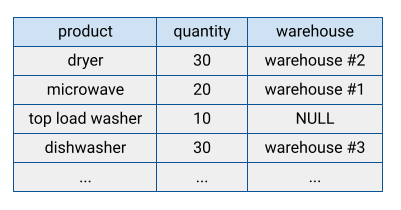
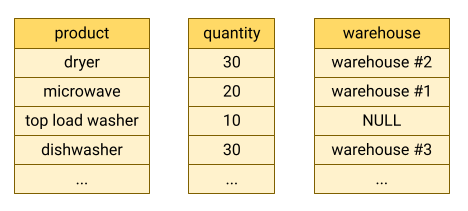
BigQuery archivia i dati delle tabelle in formato a colonne, il che significa che archivia ogni colonna separatamente. I database orientati alle colonne sono particolarmente efficaci nell'analisi di singole colonne di un intero set di dati.
I database orientati a colonne sono ottimizzati per i carichi di lavoro di analisi che aggregano i dati su un numero molto elevato di record. Spesso, una query di analisi deve solo leggere alcune colonne di una tabella. Ad esempio, se vuoi calcolare la somma di una colonna su milioni di righe, BigQuery può leggere i dati della colonna senza leggere ogni campo di ogni riga.
Un altro vantaggio dei database orientati a colonne è che i dati all'interno di una colonna tipicamente hanno più ridondanza rispetto ai dati di una riga. Questa caratteristica consente una maggiore compressione dei dati mediante l'utilizzo di tecniche come la codifica run-length, che può migliorare le prestazioni di lettura.
Modelli di fatturazione dello spazio di archiviazione
La fatturazione dello spazio di archiviazione dei dati di BigQuery può essere in byte logici o fisici (compressi) o in una combinazione di entrambi. Il modello di fatturazione dello spazio di archiviazione scelto determina i prezzi dello spazio di archiviazione. Il modello di fatturazione dello spazio di archiviazione scelto non influisce sulle prestazioni di BigQuery. Qualunque sia il modello di fatturazione scelto, i dati vengono archiviati come byte fisici.
Imposti il modello di fatturazione dello spazio di archiviazione a livello di set di dati. Se non specifichi un modello di fatturazione dello spazio di archiviazione quando crei un set di dati, per impostazione predefinita viene utilizzata la fatturazione dello spazio di archiviazione logico. Tuttavia, puoi modificare il modello di fatturazione dello spazio di archiviazione di un set di dati dopo averlo creato. Se modifichi il modello di fatturazione dello spazio di archiviazione di un set di dati, devi attendere 14 giorni prima di poter modificare nuovamente il modello di fatturazione dello spazio di archiviazione.
Quando modifichi il modello di fatturazione di un set di dati, sono necessarie 24 ore prima che la modifica venga applicata. Eventuali tabelle o partizioni di tabelle nello spazio di archiviazione a lungo termine non vengono reimpostate sullo spazio di archiviazione attivo quando modifichi il modello di fatturazione di un set di dati. Le prestazioni e la latenza delle query non sono interessate dalla modifica del modello di fatturazione di un set di dati.
I set di dati utilizzano l'archiviazione time travel e fail-safe per la conservazione dei dati. Lo spazio di archiviazione per il viaggio nel tempo e per la funzionalità di fail-safe viene addebitato separatamente alle tariffe dello spazio di archiviazione attivo se utilizzi la fatturazione dello spazio di archiviazione fisico, ma è incluso nella tariffa di base che ti viene addebitata se utilizzi la fatturazione dello spazio di archiviazione logico. Puoi modificare la finestra di viaggio nel tempo utilizzata per un set di dati in modo da bilanciare i costi di archiviazione fisica con la conservazione dei dati. Non puoi modificare la finestra di sicurezza. Per ulteriori informazioni sulla conservazione dei dati dei set di dati, consulta Conservazione dei dati con viaggio nel tempo e fail-safe. Per ulteriori informazioni sulla previsione dei costi di archiviazione, consulta Previsione della fatturazione dello spazio di archiviazione.
Non puoi registrare un set di dati nella fatturazione dello spazio di archiviazione fisico se la tua organizzazione ha impegni relativi a slot a tariffa fissa precedenti situati nella stessa regione del set di dati. Questo non si applica agli impegni acquistati con una versione di BigQuery.
Ottimizzare lo spazio di archiviazione
L'ottimizzazione dello spazio di archiviazione BigQuery migliora le prestazioni delle query e controlla i costi. Per visualizzare i metadati dello spazio di archiviazione delle tabelle, esegui query sulle seguenti viste INFORMATION_SCHEMA:
Per informazioni sull'ottimizzazione dello spazio di archiviazione, consulta Ottimizzare lo spazio di archiviazione in BigQuery.
Carica i dati
Esistono diversi pattern di base per importare i dati in BigQuery.
Caricamento collettivo:carica i dati di origine in una tabella BigQuery con una singola operazione batch. Può essere un'operazione una tantum o puoi automatizzarla in modo che venga eseguita in base a una pianificazione. Un'operazione di caricamento in batch può creare una nuova tabella o aggiungere dati a una tabella esistente.
Streaming: trasmetti continuamente batch di dati più piccoli in modo che siano disponibili per l'esecuzione di query quasi in tempo reale.
Dati generati:utilizza le istruzioni SQL per inserire righe in una tabella esistente o per scrivere i risultati di una query in una tabella.
Per ulteriori informazioni su quando scegliere ciascuno di questi metodi di importazione, consulta Introduzione al caricamento dei dati. Per le informazioni sui prezzi, consulta Prezzi dell'importazione dati.
Leggere i dati dallo spazio di archiviazione BigQuery
La maggior parte delle volte, archivi i dati in BigQuery per eseguire query di analisi su questi dati. Tuttavia, a volte potresti voler leggere i record direttamente da una tabella. BigQuery offre diversi modi per leggere i dati delle tabelle:
API BigQuery: accesso paginato sincrono con il metodo
tabledata.list. I dati vengono letti in modo seriale, una pagina per chiamata. Per ulteriori informazioni, consulta Eseguire la navigazione dei dati della tabella.API BigQuery Storage: accesso in streaming ad alta velocità effettiva che supporta anche la proiezione e il filtraggio delle colonne lato server. Le letture possono essere parallelizzate su più lettori suddividendole in più stream indipendenti.
Esporta: copia asincrona ad alta velocità in Google Cloud Storage, con job di estrazione o con
EXPORT DATAstatement. Se devi copiare i dati in Cloud Storage, esportali con un job di estrazione o con un'istruzioneEXPORT DATA.Copia: copia asincrona dei set di dati in BigQuery. La copia viene eseguita in modo logico quando la posizione di origine e quella di destinazione sono le stesse.
Per informazioni sui prezzi, consulta Prezzi dell'estrazione dei dati.
In base ai requisiti dell'applicazione, puoi leggere i dati della tabella:
- Lettura e copia: se hai bisogno di una copia a riposo in Cloud Storage, esporta i dati con un job di estrazione o un'istruzione
EXPORT DATA. Se vuoi solo leggere i dati, utilizza l'API BigQuery Storage. Se vuoi creare una copia in BigQuery, utilizza un job di copia. - Scalabilità:l'API BigQuery è il metodo meno efficiente e non deve essere utilizzata per letture ad alto volume. Se devi esportare più di 50 TB di
dati al giorno, utilizza l'istruzione
EXPORT DATAo l'API BigQuery Storage. - Tempo per restituire la prima riga: l'API BigQuery è il metodo più rapido per restituire la prima riga, ma deve essere utilizzata solo per leggere piccole quantità di dati. L'API BigQuery Storage è più lenta a restituire la prima riga, ma ha un throughput molto più elevato. Le esportazioni e le copie devono essere completate prima che sia possibile leggere qualsiasi riga, pertanto il tempo necessario per visualizzare la prima riga per questi tipi di job può essere dell'ordine di alcuni minuti.
Eliminazione
Quando elimini una tabella, i dati vengono mantenuti per almeno la durata della
finestra di viaggio nel tempo. Dopodiché, i dati vengono cancellati dal disco entro la Google Cloud tempistica di eliminazione.
Alcune operazioni di eliminazione, come la
istruzione DROP COLUMN,
sono operazioni solo sui metadati. In questo caso, lo spazio di archiviazione viene liberato alla successiva modifica delle righe interessate. Se non modifichi la tabella, non esiste un tempo garantito entro il quale lo spazio di archiviazione viene liberato. Per ulteriori informazioni, consulta la sezione Eliminazione dei dati su Google Cloud.
Passaggi successivi
- Scopri di più su come lavorare con le tabelle.
- Scopri come ottimizzare lo spazio di archiviazione.
- Scopri come eseguire query sui dati in BigQuery.
- Scopri di più su governance e sicurezza dei dati.