Buscar datos indexados
En esta página se ofrecen ejemplos de cómo buscar datos de tablas en BigQuery.
Cuando indexas tus datos, BigQuery puede optimizar algunas consultas que usan la función SEARCH u otras funciones y operadores, como =, IN, LIKE y STARTS_WITH.
Las consultas SQL devuelven resultados correctos de todos los datos insertados, aunque algunos de ellos aún no estén indexados. Sin embargo, el rendimiento de las consultas puede mejorar considerablemente con un índice. El ahorro en bytes procesados y milisegundos de ranura se maximiza cuando el número de resultados de búsqueda representa una fracción relativamente pequeña del total de filas de la tabla, ya que se analizan menos datos. Para determinar si se ha usado un índice en una consulta, consulta Uso del índice de búsqueda.
Crear un índice de búsqueda
En la siguiente tabla, llamada Logs, se muestran diferentes formas de usar la función SEARCH. Esta tabla de ejemplo es bastante pequeña, pero en la práctica, las mejoras de rendimiento que obtienes con SEARCH aumentan con el tamaño de la tabla.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
La tabla tiene el siguiente aspecto:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
Crea un índice de búsqueda en la tabla Logs con el analizador de texto predeterminado:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
Para obtener más información sobre los índices de búsqueda, consulta Gestionar índices de búsqueda.
Usar la función SEARCH
La función SEARCH proporciona búsquedas tokenizadas en los datos.
SEARCH se ha diseñado para usarse con un índice para optimizar las búsquedas.
Puedes usar la función SEARCH para buscar en toda una tabla o restringir la búsqueda a columnas específicas.
Buscar en toda una tabla
La siguiente consulta busca en todas las columnas de la tabla Logs el valor bar y devuelve las filas que contienen este valor, independientemente de las mayúsculas y minúsculas. Como el índice de búsqueda usa el analizador de texto predeterminado, no es necesario especificarlo en la función SEARCH.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
La siguiente consulta busca en todas las columnas de la tabla Logs el valor `94.60.64.181` y devuelve las filas que lo contienen. Las comillas inversas permiten hacer una búsqueda exacta, por lo que se omite la última fila de la tabla Logs, que contiene 181.94.60.64.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Buscar en un subconjunto de columnas
SEARCH permite especificar fácilmente un subconjunto de columnas en las que buscar datos. La siguiente consulta busca el valor 94.60.64.181 en la columna Message de la tabla Logs y devuelve las filas que contienen este valor.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
La siguiente consulta busca en las columnas Source y Message de la tabla Logs. Devuelve las filas que contienen el valor 94.60.64.181 de cualquiera de las columnas.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Excluir columnas de una búsqueda
Si una tabla tiene muchas columnas y quieres buscar en la mayoría de ellas, puede ser más fácil especificar solo las columnas que quieres excluir de la búsqueda. La siguiente consulta busca en todas las columnas de la tabla Logs, excepto en la columna Message. Devuelve las filas de cualquier columna que no sea Message
que contenga el valor 94.60.64.181.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
Usar otro analizador de texto
En el siguiente ejemplo se crea una tabla llamada contact_info con un índice que usa el NO_OP_ANALYZER
analizador de texto:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
La siguiente consulta busca Kim en la columna name y kim en la columna email.
Como el índice de búsqueda no usa el analizador de texto predeterminado, debes pasar el nombre del analizador a la función SEARCH.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
La función NO_OP_ANALYZER no modifica el texto, por lo que la función SEARCH solo devuelve TRUE en el caso de las coincidencias exactas:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
Configurar las opciones del analizador de texto
Los analizadores de texto LOG_ANALYZER y PATTERN_ANALYZER se pueden personalizar añadiendo una cadena con formato JSON a las opciones de configuración. Puede configurar analizadores de texto en la SEARCHfunción, la CREATE
SEARCH INDEXinstrucción DDL y la TEXT_ANALYZEfunción.
En el siguiente ejemplo se crea una tabla llamada complex_table con un índice que usa el analizador de texto LOG_ANALYZER. Usa una cadena con formato JSON para configurar las opciones del analizador:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
En las siguientes tablas se muestran ejemplos de llamadas a la función SEARCH con diferentes analizadores de texto y sus resultados. En la primera tabla se llama a la función SEARCH
con el analizador de texto predeterminado, LOG_ANALYZER:
| Llamada de función | Devoluciones | Motivo |
|---|---|---|
| BUSCAR("foobarexample", NULL) | ERROR | search_terms es `NULL`. |
| SEARCH('foobarexample', '') | ERROR | search_terms no contiene ningún token. |
| BUSCAR("foobar-example", "foobar example") | TRUE | "-" y " " son delimitadores. |
| SEARCH("foobar-example", "foobarexample") | FALSO | El valor de search_terms no está dividido. |
| SEARCH("foobar-example", "foobar\\&example") | TRUE | La doble barra inversa escapa el signo et (&), que es un delimitador. |
| BÚSQUEDA("foobar-example", R"foobar\&example") | TRUE | La barra inversa escapa el signo & en una cadena sin formato. |
| SEARCH('foobar-example', '`foobar&example`') | FALSO | Las comillas inversas requieren una coincidencia exacta para foobar&example. |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | Se encuentra una coincidencia exacta. |
| SEARCH('foobar-example', 'example foobar') | TRUE | El orden de los términos no importa. |
| BUSCAR("foobar-example", "foobar example") | TRUE | Los tokens se convierten en minúsculas. |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | Se encuentra una coincidencia exacta. |
| SEARCH('foobar-example', '`foobar`') | FALSO | Las comillas inversas conservan el uso de mayúsculas y minúsculas. |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSO | Las comillas inversas no tienen un significado especial para data_to_search y |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | Se encuentra una coincidencia exacta después del delimitador en data_to_search. |
| BUSCAR('a foobar-example b', '`foobar-example`') | TRUE | Se encuentra una coincidencia exacta entre los delimitadores de espacio. |
| BUSCAR(['foobar', 'example'], 'foobar example') | FALSO | Ninguna entrada de la matriz coincide con todos los términos de búsqueda. |
| SEARCH('foobar=', '`foobar\\=`') | FALSO | search_terms equivale a foobar\=. |
| SEARCH('foobar=', R'`foobar\=`') | FALSO | Es equivalente al ejemplo anterior. |
| SEARCH('foobar=', 'foobar\\=') | TRUE | El signo igual es un delimitador en los datos y en la consulta. |
| SEARCH('foobar=', R'foobar\=') | TRUE | Es equivalente al ejemplo anterior. |
| SEARCH('foobar.example', '`foobar`') | TRUE | Se encuentra una coincidencia exacta. |
| SEARCH('foobar.example', '`foobar.`') | FALSO | `foobar.` no se analiza debido a las comillas inversas; no es |
| SEARCH('foobar..example', '`foobar.`') | TRUE | `foobar.` no se analiza debido a las comillas inversas; se sigue |
En la siguiente tabla se muestran ejemplos de llamadas a la función SEARCH con el analizador de texto NO_OP_ANALYZER y los motivos de los distintos valores devueltos:
| Llamada de función | Devoluciones | Motivo |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | Se encuentra una coincidencia exacta. |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSO | Las comillas inversas no son caracteres especiales para NO_OP_ANALYZER. |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSO | No se distingue entre mayúsculas y minúsculas. |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSO | NO_OP_ANALYZER no tiene delimitadores. |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | NO_OP_ANALYZER no tiene delimitadores. |
Otros operadores y funciones
Puedes optimizar el índice de búsqueda con varios operadores, funciones y predicados.
Optimizar con operadores y funciones de comparación
BigQuery puede optimizar algunas consultas que usan el operador de igualdad (=), el operador IN, el operador LIKE o la función STARTS_WITH para comparar literales de cadena con datos indexados.
Optimizar con predicados de cadena
Los siguientes predicados se pueden optimizar para el índice de búsqueda:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
Optimizar con predicados numéricos
Si el índice de búsqueda se ha creado con tipos de datos numéricos, BigQuery puede optimizar algunas consultas que usen el operador igual (=) o el operador IN con datos indexados. Los siguientes predicados se pueden optimizar para el índice de búsqueda:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
Optimizar las funciones que producen datos indexados
BigQuery admite la optimización de los índices de búsqueda cuando se aplican determinadas funciones a los datos indexados.
Si el índice de búsqueda usa el LOG_ANALYZERanalizador de texto predeterminado, puede aplicar las funciones UPPER o LOWER a la columna, como UPPER(column_name) = 'STRING_LITERAL'.
En el caso de los datos de cadena escalar JSON extraídos de una columna JSON indexada, puedes aplicar la función STRING o su versión segura, SAFE.STRING.
Si el valor JSON extraído no es una cadena, la función STRING genera un error y la función SAFE.STRING devuelve NULL.
En el caso de los datos STRING (no JSON) con formato JSON indexados, puedes aplicar las siguientes funciones:
Por ejemplo, supongamos que tiene la siguiente tabla indexada llamada dataset.person_data con las columnas JSON y STRING:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
Las siguientes consultas se pueden optimizar:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
También se optimizan las combinaciones de estas funciones, como UPPER(JSON_VALUE(json_string_expression)) = 'FOO'.
Uso del índice de búsqueda
Para determinar si se ha usado un índice de búsqueda en una consulta, puede consultar los detalles de la tarea o consultar una de las vistas INFORMATION_SCHEMA.JOBS*.
Ver detalles de un trabajo
En Información del trabajo de los Resultados de la consulta, los campos Modo de uso del índice y Motivos por los que no se ha usado el índice proporcionan información detallada sobre el uso del índice de búsqueda.
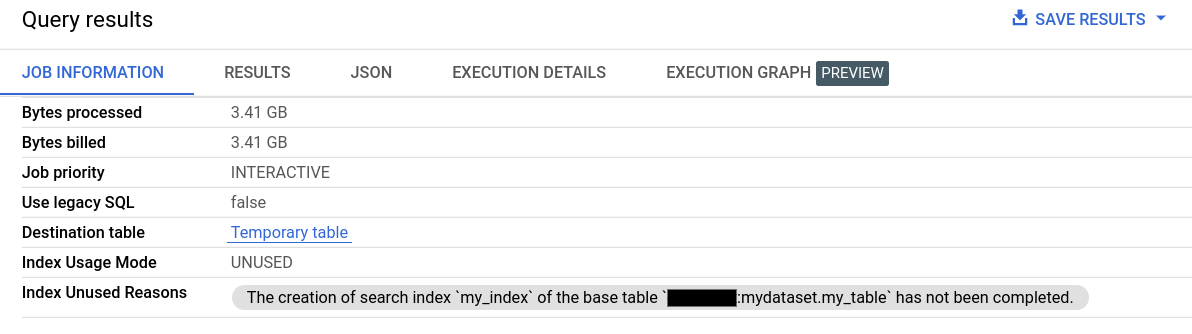
También se puede consultar información sobre el uso del índice de búsqueda a través del campo searchStatistics del método de la API Jobs.Get. El campo indexUsageMode de searchStatistics indica si se ha usado un índice de búsqueda con los siguientes valores:
UNUSED: no se ha usado ningún índice de búsqueda.PARTIALLY_USED: parte de la consulta usó índices de búsqueda y parte no.FULLY_USED: cada funciónSEARCHde la consulta usaba un índice de búsqueda.
Cuando indexUsageMode es UNUSED o PARTIALLY_USED, el campo indexUnusuedReasons
contiene información sobre por qué no se han usado los índices de búsqueda en la consulta.
Para ver searchStatistics de una consulta, ejecuta el comando bq show.
bq show --format=prettyjson -j JOB_ID
Ejemplo
Supongamos que ejecutas una consulta que llama a la función SEARCH en los datos de una tabla. Puedes ver los detalles del trabajo de la consulta para encontrar el ID de trabajo y, a continuación, ejecutar el comando bq show para ver más información:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
El resultado contiene muchos campos, incluido searchStatistics, que tiene un aspecto similar al siguiente. En este ejemplo, indexUsageMode indica que no se ha usado el índice. Esto se debe a que la tabla no tiene un índice de búsqueda. Para solucionar este problema, crea un índice de búsqueda en la tabla. Consulta el campo indexUnusedReason code para ver una lista de todos los motivos por los que no se puede usar un índice de búsqueda en una consulta.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
Consultar vistas INFORMATION_SCHEMA
También puedes ver el uso del índice de búsqueda de varios trabajos de una región en las siguientes vistas:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
La siguiente consulta muestra información sobre el uso del índice de todas las consultas optimizables del índice de búsqueda de los últimos 7 días:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
El resultado es similar al siguiente:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
Prácticas recomendadas
En las siguientes secciones se describen las prácticas recomendadas para hacer búsquedas.
Buscar de forma selectiva
La búsqueda funciona mejor cuando tiene pocos resultados. Las búsquedas deben ser lo más específicas posible.
Optimización de ORDER BY LIMIT
Las consultas que usan SEARCH, =, IN, LIKE o STARTS_WITH en una tabla con particiones muy grande se pueden optimizar si usa una cláusula ORDER BY en el campo con particiones y una cláusula LIMIT.
En las consultas que no contengan la función SEARCH, puede usar otros operadores y funciones para aprovechar la optimización. La optimización se aplica independientemente de si la tabla está indexada o no. Esta opción es útil si buscas un término común.
Por ejemplo, supongamos que la tabla Logs creada anteriormente
tiene particiones en una columna de tipo DATE adicional
llamada day. La siguiente consulta se ha optimizado:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
Acota tu búsqueda
Cuando uses la función SEARCH, busca solo en las columnas de la tabla que creas que contienen los términos de búsqueda. De esta forma, se mejora el rendimiento y se reduce el número de bytes que se deben analizar.
Usar comillas inversas
Cuando usas la función SEARCH con el analizador de texto LOG_ANALYZER,
si incluyes tu consulta de búsqueda entre comillas inversas,
se fuerza una coincidencia exacta. Esto resulta útil si la búsqueda distingue entre mayúsculas y minúsculas o contiene caracteres que no deben interpretarse como delimitadores. Por ejemplo, para buscar la dirección IP 192.0.2.1, usa `192.0.2.1`. Sin las comillas inversas, la búsqueda devuelve cualquier fila que contenga los tokens individuales 192, 0, 2 y 1 en cualquier orden.