インデックス登録されたデータを検索する
このページでは、BigQuery でテーブルデータを検索する例を示します。データをインデックスに登録すると、BigQuery で SEARCH 関数や、=、IN、LIKE、STARTS_WITH などその他の関数と演算子を使用するクエリを最適化できるようになります。
SQL クエリでは、一部のデータがまだインデックスに登録されていない場合でも、取り込まれたすべてのデータから正しい結果が返されます。ただし、インデックスを使用することにより、クエリのパフォーマンスが大幅に向上します。スキャンされるデータが少ないために検索結果の数がテーブル内の合計行数に対してごく少なくなる場合に、処理されたバイト数とスロットのミリ秒数が最大限削減されます。クエリにインデックスが使用されたかどうかを確認するには、検索インデックスの使用をご覧ください。
検索インデックスを作成する
次の Logs というテーブルを使用して、SEARCH 関数のさまざまな使用方法を示します。このサンプル テーブルは非常に小さなものですが、実際には、SEARCH を使用して得られるパフォーマンスはテーブルのサイズに合わせて向上します。
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
テーブルは次のようになります。
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
デフォルトのテキスト アナライザを使用して、Logs テーブルに検索インデックスを作成します。
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
検索インデックスの詳細については、検索インデックスを管理するをご覧ください。
SEARCH 関数を使用する
SEARCH 関数は、データに対してトークン化された検索を行います。SEARCH は、ルックアップを最適化するためにインデックスとともに使用するように設計されています。SEARCH 関数を使用すると、テーブル全体を検索することも、検索対象を特定の列に制限することもできます。
テーブル全体を検索する
次のクエリは、Logs テーブルのすべての列で値 bar を検索し、表記の大文字小文字を問わず、この値を含む行を返します。検索インデックスではデフォルトのテキスト アナライザを使用するため、SEARCH 関数で指定する必要はありません。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
次のクエリは、Logs テーブルのすべての列で値 `94.60.64.181` を検索し、この値を含む行を返します。バッククォートを使用すると完全一致検索を行うため、Logs テーブル中の 181.94.60.64 を含む最後の行は結果に含まれません。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
列のサブセットを検索する
SEARCH を使用すると、データを検索する列のサブセットを簡単に指定できます。次のクエリは、Logs テーブルの Message 列で値 94.60.64.181 を検索し、この値を含む行を返します。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
次のクエリは、Logs テーブルの Source 列と Message 列の両方を検索します。いずれかの列の値 94.60.64.181 を含む行が返されます。
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
検索から列を除外する
テーブルに多数の列があり、その大部分を検索する場合は、検索から除外する列のみを指定する方が簡単です。次のクエリは、Logs テーブルの Message 列を除くすべての列を検索します。Message 以外の列の値 94.60.64.181 を含む行を返します。
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
別のテキスト アナライザを使用する
次の例では、NO_OP_ANALYZER テキスト アナライザを使用するインデックスを持つ contact_info というテーブルを作成します。
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
次のクエリでは、name 列で Kim を検索し、email 列で kim を検索します。検索インデックスではデフォルトのテキスト アナライザを使用しないため、アナライザの名前を SEARCH 関数に渡す必要があります。
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
NO_OP_ANALYZER はテキストを変更しないため、SEARCH 関数は完全一致の場合にのみ TRUE を返します。
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
テキスト アナライザのオプションを構成する
LOG_ANALYZER と PATTERN_ANALYZER のテキスト アナライザをカスタマイズするには、構成オプションに JSON 形式の文字列を追加します。テキスト アナライザは、SEARCH 関数、CREATE
SEARCH INDEX DDL ステートメント、TEXT_ANALYZE 関数で構成できます。
次の例では、LOG_ANALYZER テキスト アナライザを使用するインデックスを持つ complex_table というテーブルを作成します。ここでは JSON 形式の文字列を使用して、アナライザ オプションを構成します。
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
次の表に、さまざまなテキスト アナライザを使用した SEARCH 関数の呼び出し例とその結果を示します。最初の表では、デフォルトのテキスト アナライザである LOG_ANALYZER を使用して SEARCH 関数を呼び出しています。
| 関数呼び出し | 戻り値 | 理由 |
|---|---|---|
| SEARCH('foobarexample', NULL) | ERROR | search_terms が「NULL」です。 |
| SEARCH('foobarexample', '') | ERROR | search_terms にトークンが含まれていません。 |
| SEARCH('foobar-example', 'foobar example') | TRUE | 「-」と「 」は区切り文字です。 |
| SEARCH('foobar-example', 'foobarexample') | FALSE | search_terms が分割されていません。 |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | 区切り文字であるアンパサンドが二重バックスラッシュでエスケープされます。 |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | 元の文字列のアンパサンドが 1 つのバックスラッシュでエスケープされます。 |
| SEARCH('foobar-example', '`foobar&example`') | FALSE | バッククォートが使用されているため、foobar&example の完全一致が必要です。 |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | 完全一致が見つかりました。 |
| SEARCH('foobar-example', 'example foobar') | TRUE | キーワードの順序は関係ありません。 |
| SEARCH('foobar-example', 'foobar example') | TRUE | トークンが小文字になります。 |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | 完全一致が見つかりました。 |
| SEARCH('foobar-example', '`foobar`') | FALSE | バッククォートでは大文字と小文字の区別が維持されます。 |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSE | data_to_search に使用するバッククォートは特別な意味を持ちません。 |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | data_to_search の区切り文字の後に、完全一致が見つかりました。 |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | スペース区切り文字の間に完全一致が見つかりました。 |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSE | すべての検索キーワードに一致する単一の配列エントリがありません。 |
| SEARCH('foobar=', '`foobar\\=`') | FALSE | search_terms は foobar\= と同等です。 |
| SEARCH('foobar=', R'`foobar\=`') | FALSE | 上記の例と同じです。 |
| SEARCH('foobar=', 'foobar\\=') | TRUE | データとクエリに使用する等号は区切り文字です。 |
| SEARCH('foobar=', R'foobar\=') | TRUE | 上記の例と同じです。 |
| SEARCH('foobar.example', '`foobar`') | TRUE | 完全一致が見つかりました。 |
| SEARCH('foobar.example', '`foobar.`') | FALSE | `foobar.` は、バッククォートが使用されているため分析されません。 |
| SEARCH('foobar..example', '`foobar.`') | TRUE | `foobar.` は、バッククォートが使用されているため分析されません。直後に「.」が続いています。 |
次の表に、NO_OP_ANALYZER テキスト アナライザを使用した SEARCH 関数の呼び出しの例と、さまざまな戻り値の理由を示ます。
| 関数呼び出し | 戻り値 | 理由 |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | 完全一致が見つかりました。 |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSE | NO_OP_ANALYZER では、バッククォートは特殊文字ではありません。 |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | 大文字と小文字が一致しません。 |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | NO_OP_ANALYZER には区切り文字がありません。 |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | NO_OP_ANALYZER には区切り文字がありません。 |
その他の演算子と関数
検索インデックスの最適化は、複数の演算子、関数、述語を使用して行うことができます。
演算子と比較関数を使用して最適化する
BigQuery では、equal 演算子(=)、IN 演算子、LIKE 演算子または STARTS_WITH 関数を使用するクエリを、文字列リテラルをインデックス登録されたデータと比較するように最適化できます。
文字列述語で最適化する
検索インデックスの最適化の対象となる述語は次のとおりです。
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
数値述語で最適化する
検索インデックスが数値データ型で作成されている場合、BigQuery は、インデックス登録されたデータに対して等価演算子(=)または IN 演算子を使用する一部のクエリを最適化できます。検索インデックスの最適化の対象となる述語は次のとおりです。
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
インデックス データを生成する関数を最適化する
BigQuery では、特定の関数がインデックス登録されたデータに適用される場合の検索インデックスの最適化がサポートされています。検索インデックスでデフォルトの LOG_ANALYZER テキスト アナライザを使用する場合は、UPPER 関数または LOWER 関数を列に適用できます(例: UPPER(column_name) = 'STRING_LITERAL')。
インデックス登録された JSON 列から抽出された JSON スカラー文字列の場合、STRING 関数またはその安全なバージョン SAFE.STRING を適用できます。抽出された JSON 値が文字列でない場合、STRING 関数はエラーを生成し、SAFE.STRING 関数は NULL を返します。
インデックス登録された JSON 形式の STRING(JSON ではない)データの場合、次の関数を適用できます。
たとえば次のように、dataset.person_data という名前で JSON 列と STRING 列がある、インデックス登録されたテーブルがあるとします。
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
以下のクエリは最適化の対象となります。
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
これらの関数の組み合わせも最適化されます(UPPER(JSON_VALUE(json_string_expression)) = 'FOO' など)。
検索インデックスの使用
クエリで検索インデックスが使用されたかどうかを確認するには、ジョブの詳細を表示するか、INFORMATION_SCHEMA.JOBS* ビューのいずれかをクエリします。
ジョブの詳細を表示
[クエリ結果] の [ジョブ情報] にある [インデックス使用モード] フィールドと [インデックスが使用されない理由] フィールドに、検索インデックスの使用状況に関する詳細情報が表示されます。
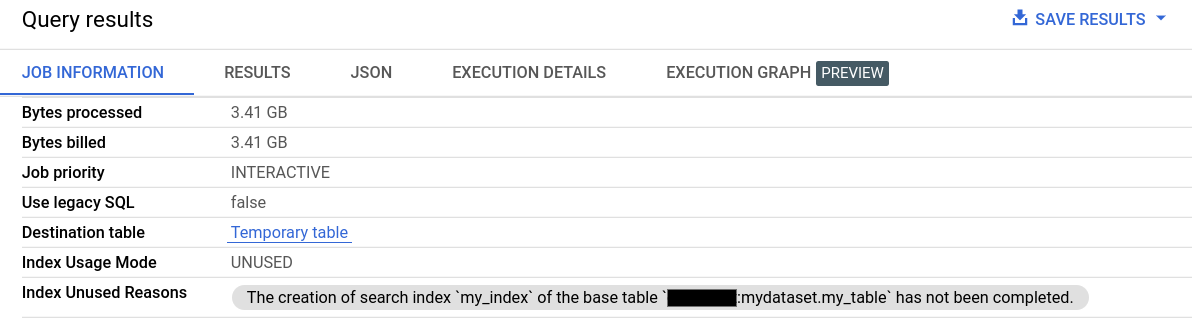
検索インデックスの使用に関する情報は、Jobs.Get API メソッドの searchStatistics フィールドでも確認できます。searchStatistics の indexUsageMode フィールドは、次の値の検索インデックスが使用されたかどうかを示します。
UNUSED: 検索インデックスは使用されていません。PARTIALLY_USED: クエリの一部では検索インデックスが使用され、一部では使用されていません。FULLY_USED: クエリ内のすべてのSEARCH関数で検索インデックスが使用されています。
indexUsageMode が UNUSED または PARTIALLY_USED の場合、indexUnusuedReasons フィールドには、クエリで検索インデックスが使用されなかった理由を示す情報が含まれます。
クエリの searchStatistics を表示するには、bq show コマンドを実行します。
bq show --format=prettyjson -j JOB_ID
例
テーブル内のデータに対して SEARCH 関数を呼び出すクエリを実行するとします。クエリのジョブの詳細を表示してジョブ ID を確認し、bq show コマンドを実行して詳細情報を確認できます。
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
出力には、以下に示すような searchStatistics など、多くのフィールドが含まれます。この例では、indexUsageMode はインデックスが使用されていないことを示しています。これは、テーブルに検索インデックスがないためです。この問題を解決するには、テーブルに検索インデックスを作成します。クエリで検索インデックスが使用されない理由の一覧については、indexUnusedReason code フィールドをご覧ください。
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
INFORMATION_SCHEMA ビューをクエリする
次のビューで、リージョン内の複数のジョブの検索インデックスの使用状況を確認することもできます。
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
次のクエリは、過去 7 日間のすべての検索インデックス最適化可能クエリのインデックス使用状況に関する情報を表示します。
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
次のような結果になります。
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
ベスト プラクティス
以降のセクションでは、検索のベスト プラクティスについて説明します。
選択的に検索
検索は、検索結果が少ない場合に特に効果的です。できるだけ具体的な検索を行ってください。
ORDER BY LIMIT の最適化
非常に大きなパーティション分割テーブルに対して SEARCH、=、IN、LIKE、STARTS_WITH を使用するクエリは、パーティション分割フィールドで ORDER BY 句と LIMIT 句を使用することにより最適化できます。SEARCH 関数を含まないクエリでは、最適化機能を利用するために、その他の演算子と関数を使用できます。この最適化は、テーブルにインデックスが登録されているかどうかにかかわらず適用されます。これは、一般的な用語を検索する場合に便利です。たとえば、以前に作成した Logs テーブルが day という追加の DATE 型の列でパーティション分割されたとします。次のクエリが最適化されます。
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
検索のスコープの設定
SEARCH 関数を使用すると、テーブル中で検索キーワードが含まれると想定される列のみを検索します。これにより、パフォーマンスが向上し、スキャンが必要なバイト数が削減されます。
バッククォートの使用
LOG_ANALYZER テキスト アナライザで SEARCH 関数を使用する場合は、検索クエリをバッククォートで囲むと完全一致になります。これは、検索で大文字と小文字を区別する場合や、区切り文字として解釈すべきでない文字が含まれている場合に有用です。たとえば、IP アドレス 192.0.2.1 を検索するには、`192.0.2.1` を使用します。バッククォートがない場合、検索では、任意の順序で個々のトークン 192、0、2、1 を含む行が返されます。