Work with Salesforce Data Cloud data in BigQuery
Data Cloud users can access their Data Cloud data natively in BigQuery. You can analyze Data Cloud data with BigQuery Omni and perform cross-cloud analytics with the data in Google Cloud. In this document, we provide instructions on accessing your Data Cloud data and several analytical tasks you can perform with that data in BigQuery.
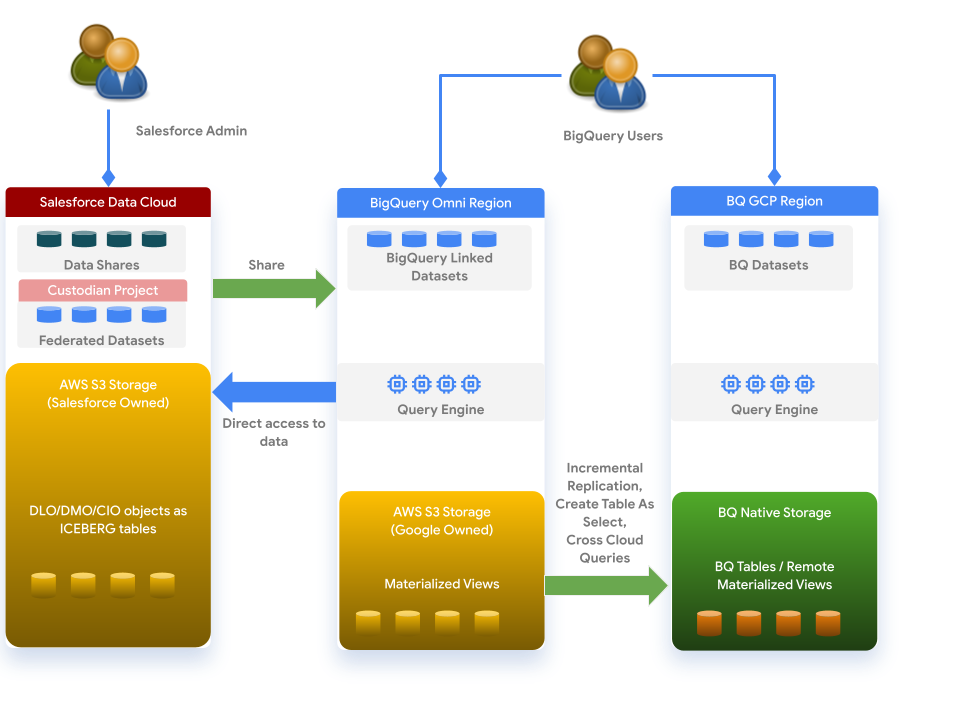
Data Cloud works with BigQuery based on the following architecture:
Before you begin
Before working with Data Cloud data, you must be a Data Cloud user. If you have VPC Service Controls enabled on your project, you will need additional permissions.
Required roles
The following roles and permissions are required:
- Analytics Hub Subscriber (
roles/analyticshub.subscriber) - BigQuery Admin (
roles/bigquery.admin)
Share Data From Data Cloud
This documentation demonstrates how to share data from Data Cloud to BigQuery - BYOL Data Shares - Zero-ETL Integration with BigQuery.
Link Data Cloud dataset to BigQuery
To access a Data Cloud dataset in BigQuery, you must first link the dataset to BigQuery with the following steps:
In the Google Cloud console, go to the BigQuery page.
Click Salesforce Data Cloud
Data Cloud datasets are displayed. You can find the dataset by name using the following naming pattern:
listing_DATA_SHARE_NAME_TARGET_NAME
DATA_SHARE_NAME: the name of the data share in the Data Cloud.TARGET_NAME: the name of the BigQuery target in the Data Cloud.
Click the dataset you want to add to BigQuery.
Click Add dataset to project.
Specify the name of the linked dataset.
Once the linked dataset is created, you can explore the dataset and the tables in it. All of the tables' metadata is retrieved from Data Cloud dynamically. All the objects inside the dataset are views that map to the Data Cloud objects. BigQuery supports three types of Data Cloud objects:
- Data Lake Objects (DLO)
- Data Model Objects (DMO)
- Calculated Insights Objects (CIO)
All of these objects are represented as views in BigQuery. These views point to hidden tables that are stored in Amazon S3.
Work with Data Cloud data
The following examples use a dataset called Northwest Trail Outfitters (NTO) that is hosted in Data Cloud. This dataset consists of three tables that represent the online sales data of the NTO organization:
linked_nto_john.nto_customers__dlllinked_nto_john.nto_products__dlllinked_nto_john.nto_orders__dll
The other dataset used in these examples is offline Point of Sale data. This covers the offline sales, and consists of three tables:
nto_pos.customersnto_pos.productsnto_pos.orders
The following datasets store additional objects:
aws_dataus_data
Run ad-hoc queries
Using BigQuery Omni, you can run ad-hoc queries to analyze the Data Cloud data through the subscribed dataset. The following example shows a simple query that queries the customers table from Data Cloud.
SELECT name__c, age__c FROM `listing_nto_john.nto_customers__dll` WHERE age > 40 LIMIT 1000;
Run cross-cloud queries
Cross-cloud queries let you join any of the tables in the
BigQuery Omni region and tables in the BigQuery
regions. For more information about cross-cloud queries, see this blog
post.
In this example, we retrieve total sales for a customer named john.
-- Get combined sales for a customer from both offline and online sales USING ( SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' UNION ALL SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' ) a SELECT SUM(total_price);
Cross Cloud Data Transfer through CTAS
You can use Create Table As Select (CTAS) to move data from
Data Cloud tables in the BigQuery Omni region to
the US region.
-- Move all the orders for March to the US region CREATE OR REPLACE TABLE us_data.online_orders_march AS SELECT * FROM listing_nto_john.nto_orders__dll WHERE EXTRACT(MONTH FROM order_time) = 3
The destination table is a BigQuery managed table in the US
region. This table can be joined with other tables. This operation incurs
AWS egress costs based on how much data is transferred.
Once the data is moved, you no longer need to pay egress fees for any
queries that run in the online_orders_march table.
Cross cloud materialized views
Cross Cloud Materialized Views
(CCMV)
transfer data from a BigQuery Omni region to a
non-BigQuery Omni BigQuery region incrementally.
Set up a new CCMV that transfers a summary of total sales from online
transactions and replicate that data into the US region.
You can access CCMVs from Ads Data Hub and join it with other Ads Data Hub data. CCMVs act like regular BigQuery Managed Tables for most part.
Create a local materialized view
To create a local materialized view:
-- Create a local materialized view that keeps track of total sales by day CREATE MATERIALIZED VIEW `aws_data.total_sales` OPTIONS (enable_refresh = true, refresh_interval_minutes = 60) AS SELECT EXTRACT(DAY FROM order_time) AS date, SUM(order_total) as sales FROM `listing_nto_john.nto_orders__dll` GROUP BY 1;
Authorize the materialized view
You must authorize materialized views to create a CCMV. You
can either authorize the view (aws_data.total_sales) or the dataset (aws_data). To authorize the materialized view:
In the Google Cloud console, go to the BigQuery page.
Open the source dataset
listing_nto_john.Click Sharing, then click Authorize Datasets.
Enter the dataset name (in this case
listing_nto_john), then click Ok.
Create a replica materialized view
Create a new replica materialized view in the US region. The materialized view
periodically replicates whenever there is a source data change to keep the
replica up to date.
-- Create a replica MV in the us region. CREATE MATERIALIZED VIEW `us_data.total_sales_replica` AS REPLICA OF `aws_data.total_sales`;
Run a query on a replica materialized view
The following example runs a query on a replica materialized view:
-- Find total sales for the current month for the dashboard SELECT EXTRACT(MONTH FROM CURRENT_DATE()) as month, SUM(sales) FROM us_data.total_sales_replica WHERE month = EXTRACT(MONTH FROM date) GROUP BY 1
Using Data Cloud data with INFORMATION_SCHEMA
Data Cloud datasets support BigQuery
INFORMATION_SCHEMA views. The data in INFORMATION_SCHEMA views is
synced regularly from Data Cloud and may be stale. The
SYNC_STATUS column in the TABLES
and SCHEMATA views shows
the last completed sync time, any errors that prevent
BigQuery from providing fresh data, and any
steps that are required to fix the error.
INFORMATION_SCHEMA queries don't reflect datasets that have been recently
created before the initial sync.
Data Cloud datasets are subject to the same
limitations as other
linked datasets, such as only being accessible in INFORMATION_SCHEMA in
dataset-scoped queries.
What's next
Learn about BigQuery Omni.
Learn about cross-cloud joins.
Learn about materialized views.